Bereksperimen dengan perbaikan untuk
model peramalan
Guess.js , saya mulai melihat dengan seksama pembelajaran mendalam: jaringan saraf berulang (RNNs), khususnya LSTMs, karena
"efektivitas tidak masuk akal" mereka di daerah di mana Guess.js bekerja. Pada saat yang sama, saya mulai bermain-main dengan convolutional neural networks (CNNs), yang juga sering digunakan untuk deret waktu. CNN biasanya digunakan untuk mengklasifikasikan, mengenali, dan mendeteksi gambar.
 Mengelola MK.js dengan TensorFlow.js
Mengelola MK.js dengan TensorFlow.jsKode sumber untuk artikel ini dan MK.js ada di GitHub saya. Saya belum memposting dataset pelatihan, tetapi Anda dapat membuat sendiri dan melatih model seperti yang dijelaskan di bawah ini!
Setelah bermain dengan CNN, saya ingat
percobaan yang saya lakukan beberapa tahun yang lalu ketika pengembang browser merilis
getUserMedia API. Di dalamnya, kamera pengguna berfungsi sebagai pengontrol untuk memainkan klon JavaScript kecil Mortal Kombat 3. Anda dapat menemukan game itu di
repositori GitHub . Sebagai bagian dari percobaan, saya menerapkan algoritma penentuan posisi dasar yang mengklasifikasikan gambar ke dalam kelas berikut:
- Pukulan kiri atau kanan
- Tendangan kiri atau kanan
- Langkah ke kiri dan ke kanan
- Jongkok
- Tidak satu pun di atas
Algoritma ini sangat sederhana sehingga saya bisa menjelaskannya dalam beberapa kalimat:
Algoritma memotret latar belakang. Segera setelah pengguna muncul dalam bingkai, algoritma menghitung perbedaan antara latar belakang dan bingkai saat ini dengan pengguna. Jadi itu menentukan posisi sosok pengguna. Langkah selanjutnya adalah menampilkan tubuh pengguna putih di atas hitam. Setelah itu, histogram vertikal dan horizontal dibangun, menjumlahkan nilai untuk setiap piksel. Berdasarkan perhitungan ini, algoritma menentukan posisi tubuh saat ini.
Video menunjukkan cara kerja program. Kode sumber
GitHub .
Meskipun klon MK kecil bekerja dengan sukses, algoritma ini jauh dari sempurna. Diperlukan bingkai dengan latar belakang. Untuk operasi yang tepat, latar belakang harus berwarna sama selama pelaksanaan program. Keterbatasan seperti itu berarti bahwa perubahan cahaya, bayangan dan hal-hal lain akan mengganggu dan memberikan hasil yang tidak akurat. Akhirnya, algoritma tidak mengenali tindakan; ia hanya mengklasifikasikan bingkai baru sebagai posisi tubuh dari set yang telah ditentukan.
Sekarang, berkat kemajuan dalam API web, yaitu WebGL, saya memutuskan untuk kembali ke tugas ini dengan menerapkan TensorFlow.js.
Pendahuluan
Pada artikel ini, saya akan membagikan pengalaman saya dalam membuat algoritma untuk mengklasifikasikan posisi tubuh menggunakan TensorFlow.js dan MobileNet. Pertimbangkan topik-topik berikut:
- Pengumpulan data pelatihan untuk klasifikasi gambar
- Augmentasi Data dengan imgaug
- Transfer Pembelajaran dengan MobileNet
- Klasifikasi biner dan klasifikasi N-primer
- Melatih model klasifikasi gambar TensorFlow.js di Node.js dan menggunakannya di browser
- Beberapa kata tentang mengklasifikasikan tindakan dengan LSTM
Dalam artikel ini, kita akan mengurangi masalah untuk menentukan posisi tubuh berdasarkan satu frame, berbeda dengan mengenali tindakan dengan urutan frame. Kami akan mengembangkan model pembelajaran mendalam dengan seorang guru, yang, berdasarkan gambar dari webcam pengguna, menentukan gerakan seseorang: menendang, kaki, atau tidak ada yang seperti ini.
Pada akhir artikel, kita akan dapat membangun model untuk bermain
MK.js :

Untuk memahami artikel dengan lebih baik, pembaca harus terbiasa dengan konsep dasar pemrograman dan JavaScript. Pemahaman dasar tentang pembelajaran yang mendalam juga bermanfaat, tetapi tidak perlu.
Pengumpulan data
Keakuratan model pembelajaran mendalam sangat tergantung pada kualitas data. Kita perlu berusaha mengumpulkan kumpulan data yang luas, seperti dalam produksi.
Model kita harus bisa mengenali pukulan dan tendangan. Ini berarti bahwa kami harus mengumpulkan gambar dari tiga kategori:
- Tendangan
- Tendangan
- Lainnya
Dalam percobaan ini, dua sukarelawan (
@lili_vs dan
@gsamokovarov ) membantu saya mengumpulkan foto. Kami merekam 5 video QuickTime di MacBook Pro saya, masing-masing berisi 2-4 tendangan dan 2-4 tendangan.
Kemudian kami menggunakan ffmpeg untuk mengekstraksi masing-masing frame dari video dan menyimpannya sebagai gambar
jpg :
ffmpeg -i video.mov $filename%03d.jpgUntuk menjalankan perintah di atas, Anda harus
menginstal ffmpeg di komputer.
Jika kita ingin melatih model, kita harus memberikan data input dan data output yang sesuai, tetapi pada tahap ini kita hanya memiliki banyak gambar tiga orang dalam pose berbeda. Untuk menyusun data, Anda perlu mengklasifikasikan frame dalam tiga kategori: pukulan, tendangan, dan lainnya. Untuk setiap kategori, direktori terpisah dibuat di mana semua gambar yang sesuai dipindahkan.
Dengan demikian, di setiap direktori harus ada sekitar 200 gambar yang mirip dengan yang di bawah ini:

Harap dicatat bahwa akan ada lebih banyak gambar di direktori Lainnya, karena relatif sedikit bingkai berisi foto pukulan dan tendangan, dan di frame yang tersisa orang berjalan, membalikkan atau mengontrol video. Jika kita memiliki terlalu banyak gambar satu kelas, maka kita berisiko mengajar model yang bias terhadap kelas khusus ini. Dalam hal ini, ketika mengklasifikasikan gambar dengan dampak, jaringan saraf masih dapat menentukan kelas "Lainnya". Untuk mengurangi bias ini, Anda dapat menghapus beberapa foto dari direktori Lainnya dan melatih model pada jumlah gambar yang sama dari setiap kategori.
Untuk kenyamanan, kami menetapkan angka dalam nomor katalog dari
1 hingga
190 , sehingga gambar pertama akan menjadi
1.jpg , yang kedua
2.jpg , dll.
Jika kita melatih model hanya dalam 600 foto yang diambil di lingkungan yang sama dengan orang yang sama, kita tidak akan mencapai tingkat akurasi yang sangat tinggi. Untuk mendapatkan hasil maksimal dari data kami, yang terbaik adalah membuat beberapa sampel tambahan menggunakan augmentasi data.
Augmentasi Data
Augmentasi Data adalah teknik yang meningkatkan jumlah titik data dengan mensintesis poin baru dari set yang ada. Biasanya, augmentasi digunakan untuk meningkatkan ukuran dan keragaman set pelatihan. Kami mentransfer gambar asli ke pipa transformasi yang membuat gambar baru. Anda tidak dapat mendekati transformasi terlalu agresif: hanya pukulan tangan lainnya yang dihasilkan dari pukulan.
Transformasi yang dapat diterima adalah rotasi, inversi warna, blur, dll. Ada alat open source yang sangat baik untuk augmentasi data. Pada saat menulis artikel ini dalam JavaScript, tidak ada terlalu banyak opsi, jadi saya menggunakan perpustakaan yang diimplementasikan dengan Python -
imgaug . Ini memiliki satu set augmenter yang dapat diterapkan secara probabilistik.
Berikut adalah logika augmentasi data untuk percobaan ini:
np.random.seed(44) ia.seed(44) def main(): for i in range(1, 191): draw_single_sequential_images(str(i), "others", "others-aug") for i in range(1, 191): draw_single_sequential_images(str(i), "hits", "hits-aug") for i in range(1, 191): draw_single_sequential_images(str(i), "kicks", "kicks-aug") def draw_single_sequential_images(filename, path, aug_path): image = misc.imresize(ndimage.imread(path + "/" + filename + ".jpg"), (56, 100)) sometimes = lambda aug: iaa.Sometimes(0.5, aug) seq = iaa.Sequential( [ iaa.Fliplr(0.5),
Script ini menggunakan metode
main dengan tiga
for loop - satu untuk setiap kategori gambar. Dalam setiap iterasi, di setiap loop, kami memanggil metode
draw_single_sequential_images : argumen pertama adalah nama file, yang kedua adalah path, yang ketiga adalah direktori tempat menyimpan hasil.
Setelah itu, kami membaca gambar dari disk dan menerapkan serangkaian transformasi padanya. Saya telah mendokumentasikan sebagian besar transformasi dalam cuplikan kode di atas, jadi kami tidak akan mengulanginya.
Untuk setiap gambar, 16 gambar lainnya dibuat. Berikut ini contoh penampilan mereka:

Harap perhatikan bahwa dalam skrip di atas kami skala gambar ke
100x56 piksel. Kami melakukan ini untuk mengurangi jumlah data dan, dengan demikian, jumlah perhitungan yang dilakukan model kami selama pelatihan dan evaluasi.
Bangunan model
Sekarang bangun model untuk klasifikasi!
Karena kita berurusan dengan gambar, kita menggunakan jaringan saraf convolutional (CNN). Arsitektur jaringan ini dikenal cocok untuk pengenalan gambar, deteksi objek, dan klasifikasi.
Transfer Belajar
Gambar di bawah ini menunjukkan CNN VGG-16 yang populer, yang digunakan untuk mengklasifikasikan gambar.
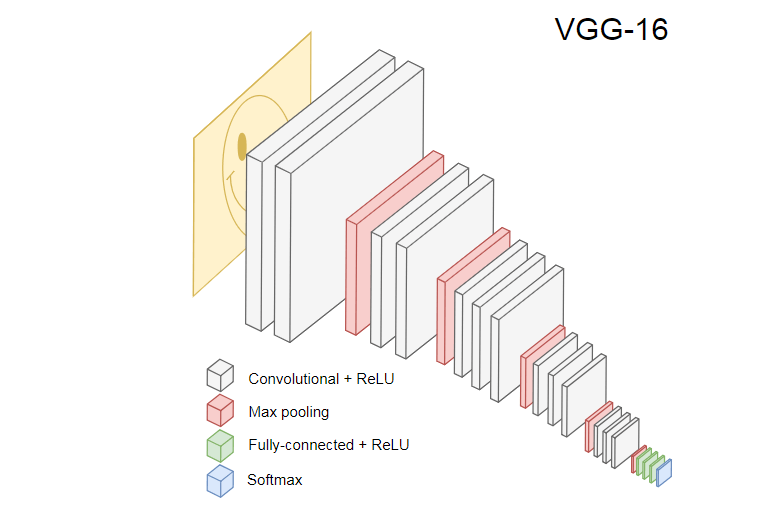
VGG-16 Neural Network mengenali 1000 kelas gambar. Ini memiliki 16 layer (tidak termasuk layer pooling dan output). Jaringan multilayer seperti itu sulit dilatih dalam praktik. Ini akan membutuhkan kumpulan data besar dan banyak pelatihan.
Lapisan tersembunyi dari pelatihan CNN mengenali berbagai elemen gambar dari set pelatihan, mulai dari tepi, beralih ke elemen yang lebih kompleks, seperti bentuk, objek individu, dan sebagainya. CNN terlatih dalam gaya VGG-16 untuk mengenali set besar gambar harus memiliki lapisan tersembunyi yang telah belajar banyak fitur dari set pelatihan. Fitur-fitur tersebut akan umum untuk sebagian besar gambar dan, karenanya, digunakan kembali dalam tugas yang berbeda.
Transfer pembelajaran memungkinkan Anda menggunakan kembali jaringan yang ada dan terlatih. Kita dapat mengambil output dari salah satu lapisan jaringan yang ada dan mentransfernya sebagai input ke jaringan saraf baru. Dengan demikian, dengan mengajarkan jaringan saraf yang baru dibuat, dari waktu ke waktu dapat diajarkan untuk mengenali fitur-fitur baru dari tingkat yang lebih tinggi dan dengan benar mengklasifikasikan gambar dari kelas yang model asli belum pernah lihat sebelumnya.
Untuk tujuan kami, ambil jaringan saraf MobileNet dari paket
@ tensorflow-models / mobilenet . MobileNet sama kuatnya dengan VGG-16, tetapi jauh lebih kecil, yang mempercepat distribusi langsung, yaitu propagasi jaringan (propagasi maju), dan mengurangi waktu pengunduhan di browser. MobileNet dilatih tentang
dataset klasifikasi gambar
ILSVRC-2012-CLS .
Saat mengembangkan model dengan transfer pembelajaran, kami memiliki dua pilihan:
- Keluaran dari mana model sumber model digunakan sebagai input untuk model target.
- Berapa banyak lapisan dari model target yang akan kita latih, jika ada.
Poin pertama sangat penting. Bergantung pada lapisan yang dipilih, kita akan mendapatkan fitur pada tingkat abstraksi yang lebih rendah atau lebih tinggi sebagai input ke jaringan saraf kita.
Kami tidak akan melatih lapisan MobileNet. Kami
global_average_pooling2d_1 output dari
global_average_pooling2d_1 dan meneruskannya sebagai input ke model mungil kami. Mengapa saya memilih lapisan khusus ini? Secara empiris. Saya melakukan beberapa tes, dan lapisan ini berfungsi dengan baik.
Definisi model
Tugas awal adalah untuk mengklasifikasikan gambar menjadi tiga kelas: tangan, kaki, dan gerakan lainnya. Pertama, mari kita selesaikan masalah yang lebih kecil: kita akan menentukan apakah ada serangan tangan di bingkai atau tidak. Ini adalah masalah klasifikasi biner yang khas. Untuk tujuan ini, kita dapat mendefinisikan model berikut:
import * as tf from '@tensorflow/tfjs'; const model = tf.sequential(); model.add(tf.layers.inputLayer({ inputShape: [1024] })); model.add(tf.layers.dense({ units: 1024, activation: 'relu' })); model.add(tf.layers.dense({ units: 1, activation: 'sigmoid' })); model.compile({ optimizer: tf.train.adam(1e-6), loss: tf.losses.sigmoidCrossEntropy, metrics: ['accuracy'] });
Kode tersebut mendefinisikan model sederhana, lapisan dengan
1024 unit dan aktivasi
ReLU , serta satu unit output yang melewati
sigmoid aktivasi
sigmoid . Yang terakhir memberikan angka dari
0 hingga
1 , tergantung pada kemungkinan serangan tangan dalam bingkai ini.
Mengapa saya memilih
1024 unit untuk tingkat kedua dan kecepatan pelatihan
1e-6 ? Yah, saya mencoba beberapa opsi berbeda dan melihat bahwa opsi seperti itu paling berhasil. Metode Tombak tampaknya bukan pendekatan terbaik, tetapi sebagian besar ini adalah bagaimana pengaturan hiperparameter dalam pembelajaran yang mendalam - berdasarkan pada pemahaman kami tentang model, kami menggunakan intuisi untuk memperbarui parameter ortogonal dan secara empiris memverifikasi cara kerja model.
Metode
compile mengkompilasi lapisan bersama-sama, menyiapkan model untuk pelatihan dan evaluasi. Di sini kami mengumumkan bahwa kami ingin menggunakan algoritma pengoptimalan
adam . Kami juga menyatakan bahwa kami akan menghitung kerugian (loss) dari cross entropy, dan mengindikasikan bahwa kami ingin mengevaluasi keakuratan model. TensorFlow.js kemudian menghitung akurasi menggunakan rumus:
Accuracy = (True Positives + True Negatives) / (Positives + Negatives)Jika Anda mentransfer pelatihan dari model MobileNet asli, Anda harus mengunduhnya terlebih dahulu. Karena tidak praktis untuk melatih model kami pada lebih dari 3.000 gambar dalam browser, kami akan menggunakan Node.js dan memuat jaringan saraf dari file.
Unduh MobileNet di
sini . Katalog berisi file
model.json , yang berisi arsitektur model - lapisan, aktivasi, dll. File yang tersisa berisi parameter model. Anda dapat memuat model dari file menggunakan kode ini:
export const loadModel = async () => { const mn = new mobilenet.MobileNet(1, 1); mn.path = `file://PATH/TO/model.json`; await mn.load(); return (input): tf.Tensor1D => mn.infer(input, 'global_average_pooling2d_1') .reshape([1024]); };
Perhatikan bahwa dalam metode
loadModel kami mengembalikan fungsi yang menerima tensor satu dimensi sebagai input dan mengembalikan
mn.infer(input, Layer) . Metode
infer mengambil tensor dan layer sebagai argumen. Lapisan menentukan lapisan tersembunyi yang kita inginkan dari keluaran. Jika Anda membuka
model.json dan
global_average_pooling2d_1 , Anda akan menemukan nama seperti itu di salah satu layer.
Sekarang Anda perlu membuat kumpulan data untuk melatih model. Untuk melakukan ini, kita harus melewati semua gambar melalui metode inferensia di MobileNet dan memberi mereka label:
1 untuk gambar dengan guratan dan
0 untuk gambar tanpa guratan:
const punches = require('fs') .readdirSync(Punches) .filter(f => f.endsWith('.jpg')) .map(f => `${Punches}/${f}`); const others = require('fs') .readdirSync(Others) .filter(f => f.endsWith('.jpg')) .map(f => `${Others}/${f}`); const ys = tf.tensor1d( new Array(punches.length).fill(1) .concat(new Array(others.length).fill(0))); const xs: tf.Tensor2D = tf.stack( punches .map((path: string) => mobileNet(readInput(path))) .concat(others.map((path: string) => mobileNet(readInput(path)))) ) as tf.Tensor2D;
Dalam kode di atas, pertama-tama kita membaca file dalam direktori dengan dan tanpa hits. Kemudian kita menentukan tensor satu dimensi yang berisi label keluaran. Jika kita memiliki
n gambar dengan guratan dan
m gambar lainnya, tensor akan memiliki
n elemen dengan nilai 1 dan elemen
m dengan nilai 0.
Dalam
xs kami
infer hasil pemanggilan metode
infer untuk gambar individual. Perhatikan bahwa untuk setiap gambar, kami memanggil metode
readInput . Berikut implementasinya:
export const readInput = img => imageToInput(readImage(img), TotalChannels); const readImage = path => jpeg.decode(fs.readFileSync(path), true); const imageToInput = image => { const values = serializeImage(image); return tf.tensor3d(values, [image.height, image.width, 3], 'int32'); }; const serializeImage = image => { const totalPixels = image.width * image.height; const result = new Int32Array(totalPixels * 3); for (let i = 0; i < totalPixels; i++) { result[i * 3 + 0] = image.data[i * 4 + 0]; result[i * 3 + 1] = image.data[i * 4 + 1]; result[i * 3 + 2] = image.data[i * 4 + 2]; } return result; };
readInput pertama-tama memanggil fungsi
readImage , dan setelah itu mendelegasikan panggilannya ke
imageToInput . Fungsi
readImage membaca gambar dari disk dan kemudian menerjemahkan jpg dari buffer menggunakan paket
jpeg-js . Dalam
imageToInput kami mengonversi gambar ke tensor tiga dimensi.
Akibatnya, untuk setiap
i dari
0 hingga
TotalImages harus
ys[i] sama dengan
1 jika
xs[i] sesuai dengan gambar dengan klik, dan
0 sebaliknya.
Pelatihan model
Sekarang modelnya siap untuk pelatihan! Panggil metode
fit :
await model.fit(xs, ys, { epochs: Epochs, batchSize: parseInt(((punches.length + others.length) * BatchSize).toFixed(0)), callbacks: { onBatchEnd: async (_, logs) => { console.log('Cost: %s, accuracy: %s', logs.loss.toFixed(5), logs.acc.toFixed(5)); await tf.nextFrame(); } } });
Panggilan kode di atas
fit dengan tiga argumen:
xs , ys dan objek konfigurasi. Di objek konfigurasi, kami menetapkan berapa era model, ukuran paket, dan panggilan balik yang akan dihasilkan TensorFlow.js setelah memproses setiap paket yang akan dilatih.
Ukuran paket menentukan
xs dan
ys untuk melatih model dalam satu era. Untuk setiap era, TensorFlow.js akan memilih subset dari
xs dan elemen terkait dari
ys , melakukan distribusi langsung, menerima output dari layer dengan aktivasi
sigmoid , dan kemudian, berdasarkan pada loss, melakukan optimasi menggunakan algoritma
adam .
Setelah memulai skrip pelatihan, Anda akan melihat hasil yang mirip dengan yang di bawah ini:
Biaya: 0,84212, akurasi: 1,00000
eta = 0,3> ---------- acc = 1,00 loss = 0,84 Biaya: 0,79740, akurasi: 1,00000
eta = 0,2 => --------- acc = 1,00 kerugian = 0,80 Biaya: 0,81533, akurasi: 1,00000
eta = 0,2 ==> -------- acc = 1.00 loss = 0.82 Biaya: 0.64303, akurasi: 0.50000
eta = 0,2 ===> ------- acc = 0,50 kerugian = 0,64 Biaya: 0,51377, akurasi: 0,00000
eta = 0,2 ====> ------ acc = 0,00 kerugian = 0,51 Biaya: 0,46473, akurasi: 0,50000
eta = 0,1 =====> ----- acc = 0,50 kerugian = 0,46 Biaya: 0,50872, akurasi: 0,00000
eta = 0,1 ======> ---- acc = 0,00 kerugian = 0,51 Biaya: 0,62556, akurasi: 1,00000
eta = 0,1 =======> --- acc = 1,00 kerugian = 0,63 Biaya: 0,65133, akurasi: 0,50000
eta = 0,1 ========> - acc = 0,50 kerugian = 0,65 Biaya: 0,63824, akurasi: 0,50000
eta = 0,0 ===========>
293ms 14675us / langkah - acc = 0,60 kerugian = 0,65
Epoch 3/50
Biaya: 0,44661, akurasi: 1,00000
eta = 0,3> ---------- acc = 1,00 loss = 0,45 Biaya: 0,78060, akurasi: 1,00000
eta = 0,3 => --------- acc = 1,00 kerugian = 0,78 Biaya: 0,79208, akurasi: 1,00000
eta = 0,3 ==> -------- acc = 1,00 kerugian = 0,79 Biaya: 0,49072, akurasi: 0,50000
eta = 0,2 ===> ------- acc = 0,50 kerugian = 0,49 Biaya: 0,62232, akurasi: 1,00000
eta = 0,2 ====> ------ acc = 1,00 kerugian = 0,62 Biaya: 0,82899, akurasi: 1,00000
eta = 0,2 =====> ----- acc = 1,00 kerugian = 0,83 Biaya: 0,67629, akurasi: 0,50000
eta = 0,1 ======> ---- acc = 0,50 kerugian = 0,68 Biaya: 0,62621, akurasi: 0,50000
eta = 0,1 =======> --- acc = 0,50 kerugian = 0,63 Biaya: 0,46077, akurasi: 1,00000
eta = 0,1 ========> - acc = 1,00 kerugian = 0,46 Biaya: 0,62076, akurasi: 1,00000
eta = 0,0 ===========>
304ms 15221us / step - acc = 0.85 kerugian = 0.63
Perhatikan bagaimana akurasi meningkat seiring waktu dan kerugian berkurang.
Pada set data saya, model setelah pelatihan menunjukkan akurasi 92%. Ingatlah bahwa keakuratan mungkin tidak terlalu tinggi karena set kecil data pelatihan.
Menjalankan model di browser
Pada bagian sebelumnya, kami melatih model klasifikasi biner. Sekarang jalankan di browser dan sambungkan ke
MK.js !
const video = document.getElementById('cam'); const Layer = 'global_average_pooling2d_1'; const mobilenetInfer = m => (p): tf.Tensor<tf.Rank> => m.infer(p, Layer); const canvas = document.getElementById('canvas'); const scale = document.getElementById('crop'); const ImageSize = { Width: 100, Height: 56 }; navigator.mediaDevices .getUserMedia({ video: true, audio: false }) .then(stream => { video.srcObject = stream; });
Ada beberapa deklarasi dalam kode di atas:
video HTML5 videoLayer MobileNet,mobilenetInfer — , MobileNet . MobileNetcanvas HTML5 canvas ,scale — canvas ,
Setelah itu, kami mendapatkan aliran video dari kamera pengguna dan menetapkannya sebagai sumber untuk elemen tersebut video.Langkah selanjutnya adalah menerapkan filter skala abu-abu yang menerima canvasdan mengubah isinya: const grayscale = (canvas: HTMLCanvasElement) => { const imageData = canvas.getContext('2d').getImageData(0, 0, canvas.width, canvas.height); const data = imageData.data; for (let i = 0; i < data.length; i += 4) { const avg = (data[i] + data[i + 1] + data[i + 2]) / 3; data[i] = avg; data[i + 1] = avg; data[i + 2] = avg; } canvas.getContext('2d').putImageData(imageData, 0, 0); };
Sebagai langkah selanjutnya, kita akan menghubungkan model dengan MK.js: let mobilenet: (p: any) => tf.Tensor<tf.Rank>; tf.loadModel('http://localhost:5000/model.json').then(model => { mobileNet .load() .then((mn: any) => mobilenet = mobilenetInfer(mn)) .then(startInterval(mobilenet, model)); });
Dalam kode di atas, pertama-tama kita memuat model yang telah kita latih di atas, dan kemudian mengunduh MobileNet. Kami melewati MobileNet ke dalam metode mobilenetInferuntuk mendapatkan cara menghitung output dari lapisan jaringan tersembunyi. Setelah itu, kami memanggil metode startIntervaldengan dua jaringan sebagai argumen. const startInterval = (mobilenet, model) => () => { setInterval(() => { canvas.getContext('2d').drawImage(video, 0, 0); grayscale(scale .getContext('2d') .drawImage( canvas, 0, 0, canvas.width, canvas.width / (ImageSize.Width / ImageSize.Height), 0, 0, ImageSize.Width, ImageSize.Height )); const [punching] = Array.from(( model.predict(mobilenet(tf.fromPixels(scale))) as tf.Tensor1D) .dataSync() as Float32Array); const detect = (window as any).Detect; if (punching >= 0.4) detect && detect.onPunch(); }, 100); };
Bagian yang paling menarik dimulai dari metode ini startInterval! Pertama, kami menjalankan interval di mana semua orang 100msmemanggil fungsi anonim. Di dalamnya, canvasvideo dengan bingkai saat ini ditampilkan pertama di atasnya . Kemudian kami mengurangi ukuran bingkai 100x56dan menerapkan filter skala abu-abu untuk itu.Langkah selanjutnya adalah mentransfer frame ke MobileNet, mendapatkan output dari lapisan tersembunyi yang diinginkan dan mentransfernya sebagai input ke metode predictmodel kami. Itu mengembalikan tensor dengan satu elemen. Dengan menggunakan, dataSynckita mendapatkan nilai dari tensor dan menetapkannya ke konstanta punching.Akhirnya, kami memeriksa: jika kemungkinan serangan tangan melebihi 0.4, maka kami memanggil metode onPunchobjek global Detect. MK.js menyediakan objek global dengan tiga metode:onKick, onPunchdan onStandyang dapat kita gunakan untuk mengontrol salah satu karakter.Selesai!
Inilah hasilnya!
Pengenalan tendangan dan lengan dengan klasifikasi-N
Pada bagian selanjutnya, kita akan membuat model yang lebih cerdas: jaringan saraf yang mengenali pukulan, tendangan, dan gambar lainnya. Kali ini, mari kita mulai dengan menyiapkan set pelatihan: const punches = require('fs') .readdirSync(Punches) .filter(f => f.endsWith('.jpg')) .map(f => `${Punches}/${f}`); const kicks = require('fs') .readdirSync(Kicks) .filter(f => f.endsWith('.jpg')) .map(f => `${Kicks}/${f}`); const others = require('fs') .readdirSync(Others) .filter(f => f.endsWith('.jpg')) .map(f => `${Others}/${f}`); const ys = tf.tensor2d( new Array(punches.length) .fill([1, 0, 0]) .concat(new Array(kicks.length).fill([0, 1, 0])) .concat(new Array(others.length).fill([0, 0, 1])), [punches.length + kicks.length + others.length, 3] ); const xs: tf.Tensor2D = tf.stack( punches .map((path: string) => mobileNet(readInput(path))) .concat(kicks.map((path: string) => mobileNet(readInput(path)))) .concat(others.map((path: string) => mobileNet(readInput(path)))) ) as tf.Tensor2D;
Seperti sebelumnya, kita pertama-tama membaca katalog dengan gambar pukulan dengan tangan, kaki, dan gambar lainnya. Setelah ini, tidak seperti yang terakhir kali, kami membentuk hasil yang diharapkan dalam bentuk tensor dua dimensi, dan bukan satu dimensi. Jika kita memiliki n gambar dengan tendangan, gambar m dengan tendangan dan k gambar lain, maka tensor ysakan memiliki nelemen dengan nilai [1, 0, 0], melemen dengan nilai [0, 1, 0]dan kelemen dengan nilai [0, 0, 1].Vektor nelemen di mana ada n - 1elemen dengan nilai 0dan satu elemen dengan nilai 1, kita sebut vektor kesatuan (vektor satu-panas).Setelah itu, kita membentuk tensor inputxsmenumpuk output setiap gambar dari MobileNet.Di sini Anda harus memperbarui definisi model: const model = tf.sequential(); model.add(tf.layers.inputLayer({ inputShape: [1024] })); model.add(tf.layers.dense({ units: 1024, activation: 'relu' })); model.add(tf.layers.dense({ units: 3, activation: 'softmax' })); await model.compile({ optimizer: tf.train.adam(1e-6), loss: tf.losses.sigmoidCrossEntropy, metrics: ['accuracy'] });
Hanya dua perbedaan dari model sebelumnya adalah:- Jumlah unit di lapisan output
- Aktivasi di lapisan output
Ada tiga unit di lapisan output, karena kami memiliki tiga kategori gambar yang berbeda:- Pemogokan tangan
- Tendangan
- Lainnya
Aktivasi dipicu pada tiga unit ini softmax, yang mengubah parameternya menjadi tensor dengan tiga nilai. Mengapa tiga unit untuk lapisan output? Masing-masing dari tiga nilai untuk tiga kelas dapat diwakili oleh dua bit: 00, 01, 10. Jumlah nilai dari tensor yang dibuat softmaxadalah 1, yaitu, kita tidak akan pernah mendapatkan 00, jadi kita tidak akan dapat mengklasifikasikan gambar dari salah satu kelas.Setelah melatih model selama 500berabad - abad, saya mencapai akurasi sekitar 92%! Ini tidak buruk, tetapi jangan lupa bahwa pelatihan dilakukan pada kumpulan data kecil.Langkah selanjutnya adalah menjalankan model di browser! Karena logika sangat mirip dengan menjalankan model untuk klasifikasi biner, lihat langkah terakhir, di mana tindakan dipilih berdasarkan pada output dari model: const [punch, kick, nothing] = Array.from((model.predict( mobilenet(tf.fromPixels(scaled)) ) as tf.Tensor1D).dataSync() as Float32Array); const detect = (window as any).Detect; if (nothing >= 0.4) return; if (kick > punch && kick >= 0.35) { detect.onKick(); return; } if (punch > kick && punch >= 0.35) detect.onPunch();
Pertama-tama kita memanggil MobileNet dengan bingkai yang diperkecil dalam nuansa abu-abu, kemudian kita mentransfer hasil dari model terlatih kita. Model mengembalikan tensor satu dimensi, yang kita konversi menjadi Float32Arrayc dataSync. Pada langkah selanjutnya kita gunakan Array.fromuntuk melemparkan array yang diketik ke array JavaScript. Lalu kami mengekstrak probabilitas bahwa tembakan dengan tangan, tendangan, atau tidak ada apa pun ada di bingkai.Jika probabilitas hasil ketiga melebihi 0.4, kami kembali. Jika tidak, jika probabilitas tendangan lebih tinggi 0.32, kami mengirim perintah tendangan ke MK.js. Jika probabilitas tendangan lebih tinggi 0.32dan lebih tinggi dari probabilitas tendangan, maka kirim aksi tendangan tersebut.Secara umum, itu saja! Hasilnya ditunjukkan di bawah ini:
Pengakuan tindakan
Jika Anda mengumpulkan kumpulan data yang besar dan beragam tentang orang-orang yang memukul dengan tangan dan kaki, maka Anda dapat membangun model yang bekerja sangat baik pada frame individual. Tetapi apakah itu cukup? Bagaimana jika kita ingin melangkah lebih jauh dan membedakan dua jenis tendangan yang berbeda: dari belokan dan dari belakang (tendangan belakang).Seperti dapat dilihat pada frame di bawah ini, pada titik waktu tertentu dari sudut tertentu, kedua pukulan terlihat sama:
 Tetapi jika Anda melihat kinerjanya, gerakannya benar-benar berbeda:
Tetapi jika Anda melihat kinerjanya, gerakannya benar-benar berbeda: Bagaimana Anda bisa melatih jaringan saraf untuk menganalisis urutan frame, dan bukan hanya satu frame?Untuk tujuan ini, kita dapat menjelajahi kelas lain dari jaringan saraf, yang disebut jaringan saraf berulang (RNNs). Misalnya, RNN sangat bagus untuk bekerja dengan deret waktu:
Bagaimana Anda bisa melatih jaringan saraf untuk menganalisis urutan frame, dan bukan hanya satu frame?Untuk tujuan ini, kita dapat menjelajahi kelas lain dari jaringan saraf, yang disebut jaringan saraf berulang (RNNs). Misalnya, RNN sangat bagus untuk bekerja dengan deret waktu:- Natural Language Processing (NLP), di mana setiap kata tergantung pada sebelumnya dan selanjutnya
- Memprediksi halaman berikutnya berdasarkan riwayat penelusuran Anda
- Pengenalan Bingkai
Menerapkan model seperti itu berada di luar cakupan artikel ini, tetapi mari kita lihat contoh arsitektur untuk mendapatkan gambaran tentang bagaimana semua ini akan bekerja bersama.Kekuatan RNN
Diagram di bawah ini menunjukkan model pengakuan tindakan: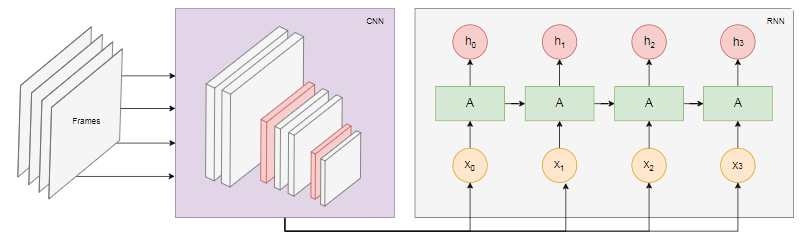 Kami mengambil
Kami mengambil nframe terakhir dari video dan mentransfernya ke CNN. Output CNN untuk setiap frame ditransmisikan sebagai input RNN. Jaringan saraf berulang akan menentukan hubungan antara frame individu dan mengenali tindakan apa yang sesuai.Kesimpulan
Pada artikel ini, kami mengembangkan model klasifikasi gambar. Untuk tujuan ini, kami mengumpulkan kumpulan data: kami mengekstraksi bingkai video dan secara manual membaginya menjadi tiga kategori. Kemudian data ditambah dengan menambahkan gambar menggunakan imgaug .Setelah itu, kami menjelaskan apa itu transfer pembelajaran dan menggunakan model MobileNet yang terlatih dari paket @ tensorflow-models / mobilenet untuk tujuan kami . Kami memuat MobileNet dari file dalam proses Node.js dan melatih lapisan padat tambahan tempat data diumpankan dari lapisan MobileNet yang tersembunyi. Setelah pelatihan, kami mencapai akurasi lebih dari 90%!Untuk menggunakan model ini di browser, kami mengunduhnya bersama dengan MobileNet dan mulai mengkategorikan frame dari webcam pengguna setiap 100 ms. Kami menghubungkan model dengan gameMK.js dan menggunakan output model untuk mengontrol salah satu karakter.Akhirnya, kami melihat bagaimana meningkatkan model dengan menggabungkannya dengan jaringan saraf berulang untuk mengenali tindakan.Saya harap Anda menikmati proyek kecil ini tidak kurang dari yang saya lakukan!