Pendahuluan
Empat bulan telah berlalu sejak publikasi artikel tentang upaya saya pada implementasi
pohon awalan tingkat rendah. Terlepas dari semua upaya saya, langit-langit di mana implementasi saya sebelumnya dari pohon awalan ternyata mampu adalah ~ 80 ribu kata per detik. Saya kemudian menghabiskan banyak waktu dan energi, tetapi hasilnya akan cocok hanya sebagai pekerjaan laboratorium dalam ilmu komputer.
Banyak yang kemudian mengatakan kepada saya: “Jangan menciptakan sepeda yang sudah kami temukan! Gunakan solusi turnkey. " Kesulitannya adalah saya tidak bisa menggunakan sesuatu yang paling tidak saya mengerti secara umum.
Saya pikir saya mengerti pohon awalan, dan inilah yang berhasil saya capai.
Prinsip kerja
Saya tidak tahu bahasa Inggris dengan baik, jadi dari banyak artikel yang saya baca tentang topik pohon awalan, beberapa informasi mungkin tidak sampai ke saya. Oleh karena itu, saya datang dengan cara mengatur semuanya, hanya memahami prinsip dasar pohon awalan. Bagi mereka yang tidak tahu, saya akan mencoba menggambarkannya lebih jelas daripada yang tertulis di Wikipedia. Jadi saya menjelaskan apa yang saya lakukan kepada istri saya.
Pohon awalan adalah struktur logis untuk menyimpan data yang dapat direpresentasikan sebagai indeks kartu buku di perpustakaan. Setiap kotak memiliki nomor. Setiap kotak sesuai dengan huruf alfabet tertentu. Di dalamnya ada nomor-nomor dari laci-laci berikut, yang bisa Anda temukan yang berikut dan seterusnya. Ketika tidak ada apa pun di dalam kotak, ini berarti bahwa huruf kotak ini adalah yang terakhir dalam kata. Masalahnya adalah bahwa beberapa kotak tetap hampir kosong, karena mengandung 1 atau 2 angka, dan ruang yang tersisa kosong.
Untuk mengatasi masalah ini, banyak varietas pohon awalan telah muncul, termasuk: HAT-trie, tri-array ganda, trip tripple-array. Justru fakta bahwa saya tidak dapat sepenuhnya memahami prinsip kerja mereka yang mendorong saya ke pohon sesederhana file kartu perpustakaan.
Terakhir kali saya berhasil menerapkan implementasi konsumsi memori yang agak ekonomis dari pohon awalan sederhana. Melanjutkan metafora ini dengan indeks kartu perpustakaan, saya membuat laci di lemari arsip saya dengan berbagai ukuran, untuk alfabet penuh, kotak ini adalah yang terbesar, untuk 1 huruf yang terkecil.
Saya berhasil menerapkan skema PHP yang persis sama di C.
1. Setiap huruf dari kata sesuai dengan tabel yang ditetapkan dikodekan dengan angka dari 2 hingga 95. Misalnya, kata "abv" dikodekan dengan tiga angka: 11, 12, 13. Untuk kinerja maksimum, array dua dimensi dari nomor 1 byte
uint8_t abc[256][256] = {}; Untuk mengonversi suatu program, ia membaca satu baris dengan 1 byte, ia mencoba untuk mengambil nilai setiap byte dalam array kami. Sebagai contoh, kode digit adalah 1 = 49, jadi kami melihat
abc[49][0]; . Jika ada nilai selain '\ 0', maka ini adalah kode dari surat kami, ingat dan pergi ke byte berikutnya. Dalam kasus kami, kata "abv" terdiri dari urutan 6 byte, dua byte per huruf: 208, 176, 208, 177, 208, 178. Karena pengkodean utf-8 dirancang sehingga byte pertama dari karakter byte tunggal tidak pernah bersamaan dengan byte pertama multi-byte , dalam array kami
abc[208][0] = 0; .
Namun, untuk pasangan byte ada beberapa kecocokan:
/* [11] */ abc[208][176] = 11; /* [12] */ abc[208][177] = 12; /* [13] */ abc[208][178] = 13;
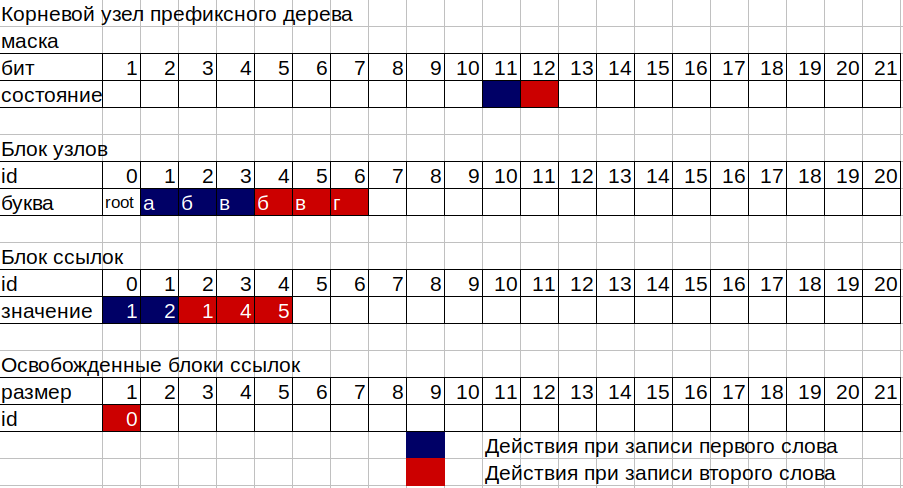
2. Sekarang kita perlu menuliskan angka 11, 12 dan 13 di kotak-kotak pohon kita. Pohon ini terdiri dari 2 blok memori non-eksplosif yang terpisah, yang pertama adalah blok node, yang kedua adalah blok tautan, serta dua konter node sibuk dan sel yang ditempati dari blok tautan. Setiap simpul pohon terdiri dari 16 byte, 12 bit bitmask, dan 4 byte untuk menyimpan id dari blok tautan. Topeng memungkinkan Anda untuk menyimpan angka dari 2 hingga 96 bit. Bit pertama dari mask digunakan untuk menandai akhir kata pada node ini. Setiap node dapat sesuai dengan id dari blok tautan jika setidaknya 1 huruf ditulis dalam node ini, atau tidak sesuai jika node adalah "daun" dalam hal pohon, yaitu, sebuah kata berakhir di atasnya. Disajikan di perpustakaan, laci kosong.
3. Ambil topeng dari simpul (root) pertama. trie-> node [0] .mask; Kami menghitung bit yang diangkat dalam topeng ini, mulai dari yang kedua (yang pertama untuk kata akhir bendera). Jika tidak ada bit dalam topeng yang dinaikkan, mis. Karena node kosong, maka kita memerlukan blok tautan ukuran 1 untuk menyimpan nomor 11 kita, ambil nomor dari penghitung referensi tautan blok dan tambah nilainya satu per satu (karena kita perlu ukuran 1). Kami mengambil nomor dari penghitung simpul dan juga meningkatkan nilai yang lama sebesar 1. Kami menulis id blok tautan, yang merupakan angka yang diperoleh dari penghitung blok tautan, di simpul akar kami. Dan dalam id ini dari blok link, tulis id dari node baru, yaitu nomor yang diperoleh dari penghitung node. Sekarang, selain simpul akar (id 0), kita memiliki simpul huruf "a" (id 1). Untuk menulis angka 12 yang sesuai dengan huruf "b", kami melakukan hal yang sama, tetapi dengan simpul huruf "a".
4. Pada huruf terakhir "c" kita tidak memerlukan tempat di blok tautan, karena kita akan memiliki simpul terakhir pada cabang atau simpul - lembar. Node seperti itu hanya memiliki 1 bit pada mask yang diangkat.
5. Bagian tersulit dari pekerjaan pohon terjadi ketika ditulis ke simpul di mana beberapa huruf telah ditulis. Dalam hal ini, skema operasi adalah sebagai berikut:
Misalkan kita ingin menambahkan kata "bvg" (12, 13, 14) ke pohon kami, di mana kata "abv" (11, 12, 13) sudah ditulis. Kami menghitung bit di topeng simpul akar ke bit surat yang menarik bagi kami. Kami memiliki huruf "b" dengan kode 12, yang berarti bahwa bit dari huruf ini adalah 12, dalam mask dari 1 hingga 12 bit bit 11 dari huruf "a" telah dimunculkan. Jadi kita memiliki ukuran saat ini dari blok tautan untuk simpul akar 1. Kita menulis huruf kedua, jadi sekarang kita membutuhkan blok tautan dengan ukuran 2. Di sini registri blok yang dibebaskan berperan, di mana id dan ukuran bagian dalam blok tautan tidak lagi digunakan oleh node pohon. ID lama kami dari blok tautan untuk simpul akar ukuran 1 baru saja masuk ke registri bagian bebas ukuran 1, karena simpul akar kami memerlukan ukuran yang lebih besar. Registri kami tidak memiliki bagian yang sesuai dengan ukuran 2 dan kami kembali mengambil nilai dari penghitung blok tautan sebagai id baru dari blok tautan, menambah penghitung dengan 2. Pada alamat baru dari blok tautan dalam urutan yang sama di mana bit berada di masker simpul, kami menulis nilai id simpul dari blok lama tautan untuk huruf "a" dari kata pertama dan nilai simpul yang baru dibuat dari huruf "b" dari kata kedua.
Kecepatan kerja
Drum roll berbunyi ... Ingat hasil terakhir? Sekitar 80 ribu kata per detik. Pohon itu dibuat dari kamus semua kata-kata Rusia OpenCorpora 3 039 982 kata. Dan inilah yang terjadi sekarang:
yatrie creation time: 4.588216s (666k wps) yatrie search time 1 mln. rounds: 0.565618s (1.76m wps)
UPDATE 11/01/2018:Dalam versi 0.0.2, dimungkinkan untuk meningkatkan kecepatan hampir 2 kali dengan mengganti fungsi penuh dengan fungsi makro, serta mengubah struktur masker simpul ke topeng uint32_t [3], sebelumnya itu adalah topeng uint8_t [12].
Juga menambahkan macro LIKELY () UNLIKELY () untuk memprediksi hasil yang diharapkan di blok if (), jika memungkinkan.
UPDATE 11/05/2018:Memutar sedikit lagi. Saya berhasil membuatnya bekerja dengan baik bahkan ketika mengkompilasi -O3 dan -Ofast. Kecepatan pencarian di pohon adalah ~ 0,2 μs atau 0,2c per 1 juta pengulangan. Rupanya kecepatan ini diperoleh karena transisi ke format topeng yang berbeda. Sebelumnya, ada 12 byte 8 bit, dan sekarang 3 int32 dan fungsi yang sangat cepat untuk menghitung bit di int32.
Seberapa kompak ini?
Kamus OpenCorpora yang ditentukan membutuhkan ~ 84MB, yang tidak lebih buruk dari libdatrie, yang menghasilkan ~ 80MB.
→
Kode SumberSelamat datang