Ini adalah tutorial perpustakaan TensorFlow. Anggap itu sedikit lebih dalam daripada di artikel tentang pengakuan angka tulisan tangan. Ini adalah tutorial tentang metode optimasi. Di sini Anda tidak dapat melakukannya tanpa matematika. Tidak apa-apa jika Anda benar-benar melupakannya. Ingat. Tidak akan ada bukti formal dan kesimpulan yang kompleks, hanya minimum yang diperlukan untuk pemahaman intuitif. Untuk mulai dengan, sedikit latar belakang tentang bagaimana algoritma ini dapat bermanfaat dalam mengoptimalkan jaringan saraf.

Enam bulan lalu, seorang teman meminta saya untuk menunjukkan cara membuat jaringan saraf dengan Python. Perusahaannya memproduksi instrumen untuk pengukuran geofisika. Beberapa probe berbeda selama pengeboran mengukur serangkaian sinyal yang terkait dengan parameter lingkungan di sekitar sumur. Dalam beberapa kasus kompleks, secara akurat menghitung parameter lingkungan dari sinyal untuk waktu yang lama bahkan pada komputer yang kuat, dan perlu untuk menafsirkan hasil pengukuran di lapangan. Ada ide untuk menghitung beberapa ratus ribu kasus pada sebuah cluster, dan untuk melatih jaringan saraf pada mereka. Karena jaringan saraf sangat cepat, dapat digunakan untuk menentukan parameter yang konsisten dengan sinyal yang diukur, tepat dalam proses pengeboran. Detail ada di artikel:
Kushnir, D., Velker, N., Bondarenko, A., Dyatlov, G., & Dashevsky, Y. (2018, 29 Oktober). Simulasi Real-Time Alat Tahanan Azimuthal Dalam dalam Model Kesalahan 2D Menggunakan Jaringan Saraf Tiruan (Rusia). Masyarakat Insinyur Perminyakan. doi: 10.2118 / 192573-RU
Suatu malam, saya menunjukkan bagaimana keras dapat menerapkan jaringan saraf sederhana, dan seorang teman di tempat kerja mulai berlatih tentang data yang dihitung. Setelah beberapa hari, kami mendiskusikan hasilnya. Dari sudut pandang saya, dia tampak menjanjikan, tetapi seorang teman mengatakan bahwa dia membutuhkan perhitungan dengan keakuratan perangkat. Dan jika rata - rata kesalahan kuadrat ternyata sekitar 1, maka 1e-3 diperlukan. 3 pesanan lebih sedikit. Seribu kali.
Eksperimen dengan arsitektur jaringan saraf, normalisasi data, dan pendekatan optimasi hampir tidak menghasilkan apa-apa. Beberapa minggu kemudian, seorang teman menelepon dan mengatakan bahwa dia menginstal MatLab dan menyelesaikan masalah dengan metode Levenberg-Marquardt (selanjutnya kita akan memanggil LM ). Itu dioptimalkan untuk waktu yang lama (beberapa hari), itu tidak berfungsi pada GPU, tetapi hasilnya adalah yang benar. Itu terdengar seperti sebuah tantangan.
Pencarian cepat untuk pengoptimal LM siap pakai untuk keras atau TensorFlow gagal. Saya hanya menemukan perpustakaan pyrenn, tetapi fungsinya bagi saya buruk. Saya memutuskan untuk mengimplementasikannya sendiri. Sekilas, semuanya tampak sederhana, dan dua malam sudah cukup. Butuh waktu lebih lama. Ada dua masalah:
- TensorFlow. Banyak artikel, tetapi hampir semua level "tapi mari kita menulis
halo pengakuan tulisan tangan dunia ." - Matematika Saya lupa banyak, dan penulis artikel matematika sama sekali tidak peduli dengan orang-orang seperti saya: rumus padat tanpa penjelasan, "jelas!" dan sebagainya.
Akibatnya, ia menulis artikel untuk mereka yang lupa matematika dan ingin memahami TensorFlow sedikit lebih dalam, tetapi tanpa hardcore. Artikel ini memiliki banyak teks dan kode kecil. Pilihan sebaliknya, ketika ada sedikit teks dan banyak kode, ada di sini Jupyter Notebook Levenberg-Marquardt .
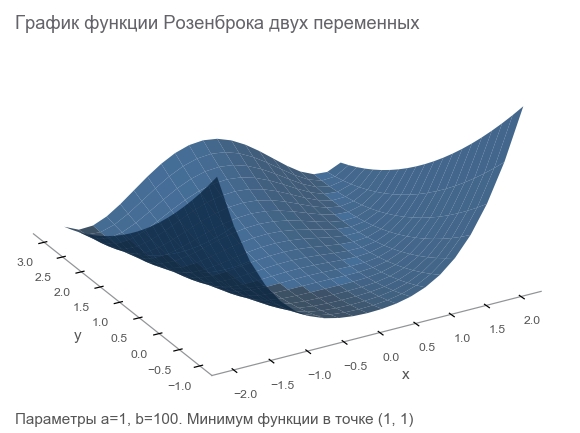
Mengenal fitur Rosenbrock
Kami akan menghasilkan data pelatihan dengan fungsi Rosenbrock , yang sering digunakan sebagai tolok ukur untuk algoritma optimasi:
f ( x , y ) = ( a - x ) 2 + b ( y - x 2 ) 2
Kenapa dia baik?
- Jadwal yang indah. Ini disebut Lembah Rosenbrock dan fungsi pisang Rosenbrock yang tidak dapat diterjemahkan.
- Minimum global adalah di dalam lembah datar panjang, sempit, parabola. Menemukan lembah itu sepele, dan minimum global sulit.
- Ada opsi multidimensi. Tidak mudah menghasilkan fungsi yang baik untuk banyak variabel.
Kami akan mulai menulis kode dari itu dengan menghubungkan perpustakaan yang diperlukan untuk pekerjaan lebih lanjut:
import numpy as np import tensorflow as tf import math def rosenbrock(x, y, a, b): return (a - x)**2 + b*(y - x**2)**2
Kami nyatakan masalahnya
Karena kita berbicara tentang alat pengukur, mari kita terus menggunakan analogi. Perangkat kami di dunia fiksi dapat mengukur koordinat ( x , y ) dan tinggi z . Fisikawan mempelajari dunia dan berkata: " Ya, ini Rosenbrock! Mengetahui koordinat, Anda dapat menghitung ketinggian secara akurat, Anda tidak perlu mengukurnya. " Dengan kata lain, para ilmuwan memberi kami sebuah model z = r o s e n b r o c k ( x , y , a , b ) yang tergantung pada parameter ( a , b ) . Parameter ini, meskipun konstan dalam dunia fiksi, tidak diketahui. Mereka perlu ditemukan.
Kami melakukan serangkaian percobaan yang memberi m poin (x1,y1,z1),(x2,y2,z2),...,(xm,ym,zm) :
Cara pertama untuk mengoptimalkan adalah mencoba dan menebak parameternya. Kami menggunakan perpustakaan Numpy:
x, y = data_points[:, 0], data_points[:, 1] z = data_points[:, 2]
Bagaimana memahami betapa salahnya kita? Hitung residu - ukuran kesalahan. m poin memberi m residual - Anda memerlukan indikator integral. Kami mengurutkan setiap residual dalam kotak dan menghitung rata-rata:
MSE(a,b)= frac1m summi=1(zi− widehatzi)2
Ukuran kedekatan ini disebut mean squared error (selanjutnya disebut sebagai mse ):
[Out]: 3868.2291666666665
Dengan meminimalkan mse , kami memecahkan masalah kuadrat terkecil ( minimalisasi kuadrat linier ):
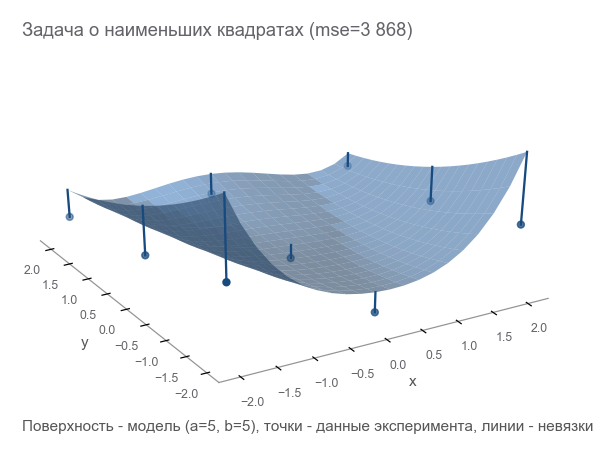
Dapat dilihat bahwa parameter tidak menebak sama sekali.
Kami merumuskan masalah pada TensorFlow
Model memiliki bentuk z=rosenbrock(x,y,a,b) . Kami membawanya ke formulir y=f(x,p) (biasanya matematika menulis beta bukannya p tetapi programmer tidak menggunakan beta). Sekarang model memiliki bentuk y=rosenbrock(x,p) dimana y - tinggi x Apakah vektor koordinat dua elemen (komponen), dan p - vektor parameter.
Pemrogram sering menganggap vektor sebagai array satu dimensi. Ini tidak sepenuhnya benar. Array angka adalah sarana untuk merepresentasikan vektor. Anda dapat mewakili vektor sebagai larik dimensi N , array dua dimensi 1 kaliN , dan bahkan sebuah array N kali1 dalam kasus di mana fakta bahwa vektor adalah vektor kolom (misalnya, untuk mengalikan matriks dengan itu) adalah penting:
beginbmatrixx1vdotsxN endbmatrix
TensorFlow menggunakan konsep tensor . Tensor , seperti array, dapat berupa satu dimensi (untuk merepresentasikan vektor ), dua dimensi (untuk matriks atau vektor kolom ) dan dimensi yang lebih besar.
Kode TensorFlow tidak berbeda dalam bentuk dengan kode Numpy. Konten tersebut sangat besar. Kode numpy menghitung nilai mse. Kode TensorFlow sama sekali tidak melakukan perhitungan, ia membentuk grafik aliran data yang dapat dihitung oleh mse. Momen yang sangat toleran otak adalah pekerjaan dari fungsi rosenbrock . Kami menggunakannya dalam kedua kasus. Tetapi ketika kita melewati array Numpy, ia melakukan perhitungan sesuai dengan rumus dan mengembalikan angka. Dan ketika kita mentransfer tensor ke TensorFlow, ia membentuk subgraph dari aliran data dan mengembalikan edge -nya dalam bentuk tensor. Mukjizat polimorfisme, tetapi jangan menyalahgunakannya:
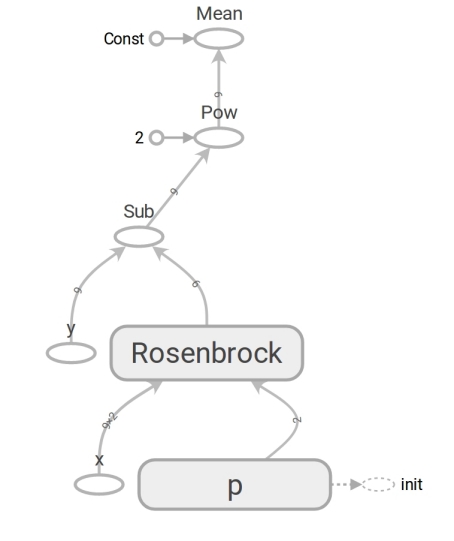
Berkat keberadaan grafik aliran data seperti itu, TensorFlow khususnya dapat menghitung turunan secara otomatis (menggunakan teknik diferensiasi otomatis mode balik ).
Momen matematika. Blok "untuk mereka yang lupa" akan disembunyikan di spoiler.
Derivatif (angka yang dimasukkan - angka tersisa)Kemungkinan besar Anda ingat definisi turunan dari fungsi skalar (mengembalikan angka) dari satu variabel: untuk f: mathbbR rightarrow mathbbR turunan f pada intinya x in mathbbR didefinisikan sebagai:
f′(x)= limh hingga0 fracf(x+h)−f(x)h
Derivatif adalah cara mengukur perubahan . Dalam kasus skalar, turunan menunjukkan seberapa banyak fungsi akan berubah f jika x ubah ke nilai kecil varepsilon :
f(x+ varepsilon) kira−kiraf(x)+ varepsilonf′(x)
Untuk kenyamanan, kami menyatakan y=f(x) , dan turunannya y oleh x kami akan menulis caranya frac partialy partialx . Catatan seperti itu menekankan hal itu frac partialy partialx - tingkat perubahan antar variabel x dan y . Lebih khusus lagi, jika x ubah ke varepsilon lalu y ubah menjadi sekitar varepsilon frac partialy partialx . Anda juga dapat menulisnya seperti ini:
x rightarrowx+ Deltax Rightarrowy rightarrow approxy+ frac partialy partialx Deltax
Dibaca sebagai: "berubah x pada x+ Deltax berubah y di sekitar y+ Deltax frac partialy partialx ". Catatan seperti itu dengan jelas menyoroti hubungan antara perubahan x dan berubah y .
Kami membangun grafik aliran data, mari kita jalankan perhitungan mse:
[Out]: 3868.2291666666665
Hasilnya sama dengan Numpy. Jadi mereka tidak salah.
Mulai optimalkan
Sayangnya, tidak mungkin untuk menebak parameternya. Tapi kemudian kita:
- Kami menetapkan kriteria optimalitas - nilai minimum mse.
- Parameter variabel ditentukan: vektor p dengan komponen a , b Fungsi Rosenbrock.
- Kami belum memikirkan keterbatasan, tetapi belum ada.
Pada langkah terakhir, kami membuat grafik aliran data dengan tensor loss hingga ( fungsi hilang ). Tujuan optimasi adalah untuk menemukan nilai vektor parameter p di mana nilai fungsi kerugian minimal. Kami beruntung, grafik fungsi ini sangat sederhana (cekung dan tanpa minimum lokal):
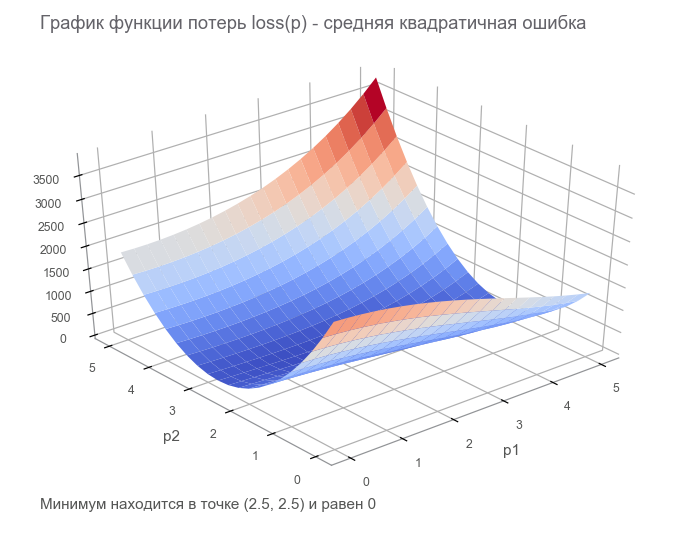
Memulai dengan optimasi. Untuk memulai, kami menulis siklus umum:
Kami mengoptimalkan dengan metode penurunan gradien tercepat (SGD)
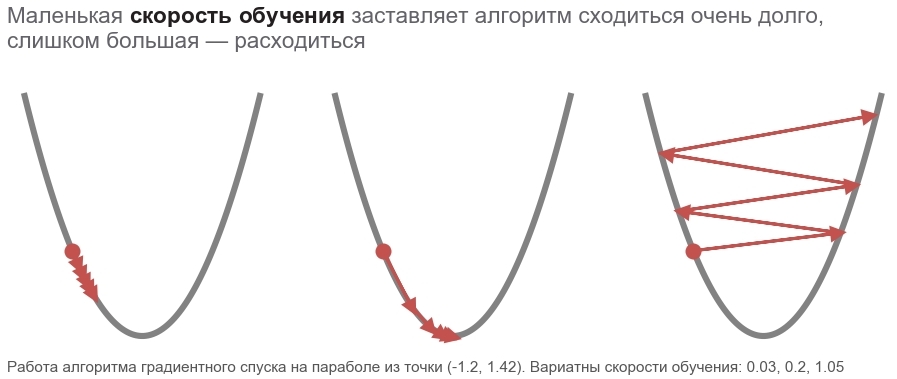
Tindakan metode ini dapat dibandingkan dengan mengendarai pemain ski yang berani, yang selalu menempatkan lereng (ke arah yang paling curam). Dalam hal ini, hanya kemiringan pada titik lokasi yang diperhitungkan. Dan jika kemiringannya kuat, maka pemain ski itu terbang jauh sebelum perubahan berikutnya. Dengan kemiringan yang lemah, ia bergerak dalam langkah-langkah kecil. Mungkin cara terbang menjadi pohon ( Algoritma menyimpang ), dan terjebak dalam lubang ( minimum lokal ).

Anda dapat menulis sebagai berikut (ubah boldsymbolp pada boldsymbolp−... ):
boldsymbolp rightarrow boldsymbolp− alpha[ nablaploss( boldsymbolp)]
Berminyak boldsymbolp menekankan bahwa ini adalah titik lokasi aktual - nilai vektor parameter pada langkah saat ini. Pada langkah pertama, ini adalah dugaan kami (5, 5). Ada dua poin menarik dalam rumus: alpha - Tingkat pembelajaran ( learning rate ), nablaploss - gradien ( gradien ) dari fungsi yang hilang oleh vektor parameter.
Gradien (vektor masuk - angka kiri)Pertimbangkan fungsi yang mengambil vektor sebagai input dan menghasilkan skalar: f: mathbbRN rightarrow mathbbR . Derivatif f pada intinya x in mathbbRN sekarang disebut gradien dan merupakan vektor [ nablaxf(x)] in mathbbRN (dibaca sebagai "nabla") terdiri dari turunan parsial :
nablaxy=( frac partialy partialx1, frac partialy partialx2,..., frac partialy partialxN)
Untuk kasus ini, catatan ketergantungan perubahan fungsi pada perubahan argumen memiliki bentuk berikut:
x rightarrowx+ Deltax Rightarrowy rightarrow approxy+ nablaxy cdot Deltax
Catatan telah berubah sedikit untuk memperhitungkan itu x , Deltax dan nablaxy - vektor dalam mathbbRN , dan y - skalar. Saat mengalikan vektor nablaxy dan Deltax produk skalar digunakan (jumlah produk komponen).
[Out]: step: 1, current loss: 3868.2291666666665 step: 2, current loss: 1381.5379689135807 [...] ENDED ON STEP: 582, FINAL LOSS: 9.698531012270816e-11 PARAMETERS: [2.50000205 2.49999959]
Butuh 582 langkah:
Gerakan ke arah anti-gradienMengapa kita bergerak ke arah yang berlawanan dengan gradien? Ingat entri dengan produk skalar: x rightarrowx+ Deltax Rightarrowy rightarrow approxy+ nablaxy cdot Deltax . Minimalkan y . Karena perilaku fungsi hanya diketahui di lingkungan kecil melalui turunan, perlu untuk bergerak dalam langkah-langkah kecil, tetapi optimal, meminimalkan produk nablaxy cdot Deltax . Menurut definisi sekolah, produk skalar dari dua vektor adalah jumlah yang sama dengan produk dari panjang vektor-vektor ini oleh cosinus sudut di antara mereka : a cdotb= kiri|a kanan| kiri|b kanan|cos sudut(a,b) . Untuk vektor dengan panjang tetap, produk ini mencapai minimum dengan cosinus -1, mis. pada sudut 180 derajat, ketika vektor diarahkan ke arah yang berlawanan. Dengan demikian, produk skalar minimum nablaxy cdot Deltax tercapai saat Deltax dalam arah anti-gradien .
Kami mengoptimalkan dengan metode Adam
Kami tidak akan melangkah lebih jauh ke metode gradien, tetapi ada banyak variasi. Anda dapat membacanya di artikel Metode Pengoptimalan Jaringan Saraf Tiruan . Di TensorFlow, banyak pengoptimal sudah diterapkan. Sebagai contoh, Adam:
[Out]: step: 1, current loss: 3868.2291666666665 step: 2, current loss: 34205.72916492336 [...] ENDED ON STEP: 317, FINAL LOSS: 2.424142714263483e-12 PARAMETERS: [2.49999969 2.50000008]
Dikelola dalam 317 langkah. Jauh lebih cepat.
Kami mengoptimalkan dengan metode Newton
Tindakan metode orde kedua dapat dibandingkan dengan mengendarai snowboarder freeride rasional yang merenungkan titik berikutnya dari rutenya untuk waktu yang lama dan memperhitungkan tidak hanya kemiringan di lokasi, tetapi juga kelengkungan.
Faktanya, kedua metode gradient descent dan second-order mencoba menebak ( memperkirakan ) fungsi pada titik saat ini. Metode gradien hanya fokus pada kemiringan grafik fungsi pada titik - turunan pertama. Metode orde kedua, selain bias, memperhitungkan kelengkungan akun, turunan kedua: "jika kelengkungan berlanjut, lalu di mana minimumnya?" Kami menghitung dan pergi ke sana:
Untuk membangun perkiraan seperti itu dan menghitung estimasi titik minimum, Anda dapat menggunakan seri Taylor . Untuk kasus satu dimensi, aproksimasi oleh polinomial orde kedua pada titik tersebut a terlihat seperti ini:
f(x) kira−kiraf(a)+ fracf′(a)(x−a)1!+ fracf″(a)(x−a)22!
Minimum tercapai pada x=a− fracf′(a)f″(a) . Kasus multidimensi terlihat lebih serius:
Matriks Hessian (vektor yang dimasukkan - angka kiri)Matriks Hessian adalah matriks persegi yang terdiri dari turunan kedua:
\ boldsymbol {H} y_ {x} = \ begin {bmatrix} \ frac {\ partial ^ 2t} {\ partial x_1 ^ 2} & \ frac {\ partial ^ 2y} {\ partial x_1 \ partial x_2} & \ cdots & \ frac {\ partial ^ 2y} {\ partial x_1 \ partial x_N} \\ \ frac {\ partial ^ 2y} {\ partial x_2 \ partial x_1} & \ frac {\ partial ^ 2y} {\ partial x_2 ^ 2} & \ cdots & \ frac {\ partial ^ 2y} {\ partial x_2 \ partial x_N} \\ \ vdots & \ vdots & \ ddots & \ vdots \\ \ frac {\ partial ^ 2y} {\ partial x_N \ \ partial x_1} & \ frac {\ partial ^ 2th} {\ partial x_N \ partial x_2} & \ cdots & \ frac {\ partial ^ 2y} {\ partial x_N ^ 2} \ end {bmatrix}
Perkiraan polinomial orde kedua untuk fungsi vektor melalui gradien dan matriks Hessian pada suatu titik a terlihat seperti ini:
f(x) kira−kiraf(a)+(xa) intercal[ nablaxf(a)]+ frac12!(xa) intercal[ boldsymbolHfx(a)](xa)
Minimum tercapai pada x=a−[ boldsymbolHfx(a)]−1[ nablaxf(a)] . Bentuknya hampir bertepatan dengan kasus satu dimensi: kami mengganti turunan pertama dengan gradien, yang kedua dengan matriks Hessian dan membuat koreksi untuk bekerja dengan vektor. Tidak mungkin untuk membagi vektor dengan matriks, oleh karena itu, perkalian dengan matriks invers digunakan. T berarti transpos . Rumus menyiratkan bahwa secara default vektor adalah kolom. Transpose mengubah vektor kolom menjadi vektor baris . Ketika menerapkan pada TensorFlow, ini harus diperhitungkan, tetapi dalam arah yang berlawanan: secara default, vektor adalah string (tensor satu dimensi). Untuk jaga-jaga: transposisi bukan rotasi 90 derajat, itu adalah transformasi baris menjadi kolom dalam urutan yang sama.
Jadi, langkah metode Newton memiliki bentuk berikut:
boldsymbolp rightarrow boldsymbolp−[ boldsymbolHlossp( boldsymbolp)]−1[ nablaploss( boldsymbolp)]
TensorFlow memiliki segalanya untuk mengimplementasikan metode ini:
[Out]: step: 1, current loss: 3868.2291666666665 step: 2, current loss: 105.04357496954218 step: 4, current loss: 9.96663526704236 ENDED ON STEP: 6, FINAL LOSS: 5.882202372519996e-20 PARAMETERS: [2.5 2.5]
Cukup 6 langkah:
Dioptimalkan oleh algoritma Gauss-Newton
Metode Newton memiliki satu kelemahan - matriks Hessian. Berkat TensorFlow kita dapat menghitungnya dalam satu baris kode. Menurut wiki, Johann Karl Friedrich Gauss membuat penyebutan pertama tentang metodenya pada 1809. Perhitungan matriks Hessian untuk beberapa parameter untuk metode kuadrat terkecil dapat memakan banyak waktu. Sekarang kita dapat mengasumsikan bahwa algoritma Gauss-Newton menggunakan perkiraan matriks Hessian melalui matriks Jacobi untuk menyederhanakan perhitungan. Tetapi dari sudut pandang sejarah, ini tidak benar: Ludwig Otto Hesse (yang mengembangkan matriks yang dinamai menurut namanya) lahir pada tahun 1811 - 2 tahun setelah penyebutan algoritma yang pertama. Dan Carl Gustav Jacobi berusia 5 tahun.
Algoritma Gauss-Newton tidak bekerja dengan fungsi kerugian. Ini bekerja dengan fungsi residual r(p) . Fungsi ini mengambil vektor input parameter p dan mengembalikan vektor residual . Dalam kasus kami, vektor p terdiri dari 2 komponen (parameter a dan b Fungsi Rosenbrock), dan vektor sisa dari m komponen (sesuai dengan jumlah percobaan). Fungsi vektor dari argumen vektor diperoleh. Turunannya:
Matriks Jacobi (vektor yang dimasukkan - vektor dirilis)Pertimbangkan fungsi yang mengambil vektor sebagai input dan menghasilkan vektor juga: f: mathbbRN rightarrow mathbbRM . Derivatif f pada intinya x sekarang memiliki ukuran N kaliM , disebut matriks Jacobi , dan terdiri dari semua kombinasi turunan parsial:
\ boldsymbol {J} y_ {x} = \ begin {pmatrix} \ frac {\ partial y_ {1}} {\ partial x_ {1}} & \ cdots & \ frac {\ partial y_ {1}} {\ parsial x_ {N}} \\ \ vdots & \ ddots & \ vdots \\ \ frac {\ partial y_ {M}} {\ partial x_ {1}} & \ cdots & \ frac {\ partial y_ {M}} {\ partial x_ {N}} \ end {pmatrix}
Anda mungkin memperhatikan bahwa baris matriks Jacobi adalah gradien komponen y . Barang (i,j) matriks frac partialy partialx sama dengan frac partialyi partialxj dan memberi tahu kami berapa banyak yang akan berubah yi saat berubah xj pada nilai kecil. Seperti pada kasus sebelumnya, Anda dapat menulis:
x rightarrowx+ Deltax Rightarrowy rightarrow approxy+ boldsymbolJyx Deltax
Di sini boldsymbolJyx matriks N kaliM , dan Deltax vektor ukuran N dengan demikian produk boldsymbolJyx Deltax Merupakan produk dari matriks oleh vektor, menghasilkan vektor ukuran M .
Agar tidak bingung dalam kelimpahan karakter, kami menganggap itu boldsymbolJr - Matriks Jacobi dari fungsi residual pada titik saat ini boldsymbolp . Kemudian algoritma Gauss-Newton dapat ditulis sebagai berikut:
boldsymbolp rightarrow boldsymbolp−[ boldsymbolJ rintercal boldsymbolJr]−1 boldsymbolJ rintercalr( boldsymbolp)
Merekam dalam bentuk benar-benar bertepatan dengan rekaman metode Newton. Hanya alih-alih matriks Hessian digunakan boldsymbolJ rintercal boldsymbolJr bukannya gradien boldsymbolJ rintercalr( boldsymbolp) . Selanjutnya, kita akan melihat mengapa pendekatan seperti itu dapat digunakan. Sementara itu, mari kita lanjutkan ke implementasi di TensorFlow:
[Out]: step: 1, current loss: 3868.2291666666665 step: 2, current loss: 14.653025157673625 step: 4, current loss: 4.3918079172783016e-07 ENDED ON STEP: 4, FINAL LOSS: 3.374364957618591e-17 PARAMETERS: [2.5 2.5]
Cukup 4 langkah. Kurang dari untuk metode Newton.
Seperti dapat dilihat dari kode, fungsi kerugian tidak digunakan dalam optimisasi, hanya untuk kriteria berhenti dan masuk. Bagaimana algoritma pengoptimalan mengetahui fungsi mana yang harus diminimalkan? Jawabannya mengejutkan: tidak mungkin! Gauss-Newton hanya meminimalkan kesalahan kuadrat rata-rata .
Perbaiki bagian matematika dari artikel
Kami mengulangi semua matematika yang kami butuhkan. Mari kita perbaiki sedikit agar lebih fokus hanya pada pemrograman dan TensorFlow. Anda mungkin perlu pensil untuk melacak urutan tindakan matematika.
Ada modelnya y=f(x,p) dimana x - vektor p - vektor parameter dimensi n , dan y - skalar. Dari percobaan yang diterima m poin (x1,y1),...,(xm,ym) ( pasangan data ). Fungsi residual vektor hanya bergantung pada vektor parameter: r(p)=(r1(p),...rm(p)) dimana rk(p)=yk− widehatyk=yk−f(xk,p) . , p , xk,yk ? , xk,yk , .
p , ( sum of squared error — sse residual sum-of-squares — rss ) . mse sse , m . . :
loss(p)=r21(p)+⋯+r2m(p)=m∑k=1r2k(p)
p (p) .
, . — . — , r2 2r∂r∂p . :
∇ploss=(m∑k=12rk∂rk∂p1,⋯,m∑k=12rk∂rk∂pn)
. :
[Hlossp]ij=∂2loss∂pi∂pj=m∑k=1(2∂rk∂pi∂rk∂pj+2rk∂2rk∂pi∂pj)
. , , (uv)′=u′v+uv′ .
Hebat! .
, , , — 2rk∂2rk∂pi∂pj . , , rk , . — . , ? -.
:
Jr=(∂r1∂p1⋯∂r1∂pn⋮⋱⋮∂rm∂p1⋯∂pm∂pn)
, , . Perhatikan bahwa:
2Jr⊺
"" . ( ). , — , .
( ):
, , - — , mse .
. , , . , . , .
, : " . - ! ". , , , ( supervised learning ). , . : ( training set ) — ; — ( prediction model ) ; — , .
( multi-layer perceptron neural network mlp ). , , :
- ( starting values ) . Xavier'a, .
- ( overfitting ). — . , . — .
- ( scaling of the input ). , .
9 . 500:
500 . — ( learner ), ( outcome measurement ) ( features ) .
( network diagram ). MatLab:
( input ). ( weights ) 2x10, ( bias ) 10, ( activation ). () ( hidden layer ) 10 . , , ( output ).
, , ( ):
:
. "" , - . 41 . , .
, . - dari :
Adam
Adam . mse :
[Out]: step: 1, current loss: 671.4242576535694 [...] ENDED ON STEP: 40000, FINAL LOSS: 0.22862158574440725 VALIDATION LOSS: 0.29000289644978866
. : , , .
2 . :
:
. , 4 . 4 tf.concat .
. tf.while_loop , , , stack .
: . tf.reshape (-1,) .
. - . — TensorFlow . — - - . -. Levenberg-Marquardt Jupyter Notebook rosenbrock_train.py . , TensorFlow . - , ( ) , , .
-
hess_approx grad_approx -. , . :
- :
- :
, , , . - , :
, - .
[Out]: step: 1, current loss: 548.8468777701685 step: 2, current loss: 49648941.340197295 InvalidArgumentError: Input is not invertible.
- . , . - , .
, .
-
. Matlab trainlm . . MathWorks.
- : . - :
( ). , -. , . , LM -.
:
mu = tf.placeholder(tf.float64, shape=[1]) n = tf.add_n(parms_sizes) I = tf.eye(n, dtype=tf.float64)
? LM - . , . , , . — , mse . , :
[Out]: step: 1, mu: 3.0 current loss: 692.6211687622557 [...] ENDED ON STEP: 100, FINAL LOSS: 0.012346989371823602 VALIDATION LOSS: 0.01859463694102034
100 LM mse 10 , 40 .
. , . , rosenbrock_train.py .
2D . . . , " " ( curse of dimentionality , Bellman, 1961). . .
:
rosenbrock_train.py get_rand_rosenbrock_points .
-
- : " ! 4 , 300! ". , ( ) -. , , . - . . : ? , . . , - :
- 10 000 6D .
- 3 12, 10, 8 (311 ).
- .
- 3.5 .
. - 2 . LM . 20 .
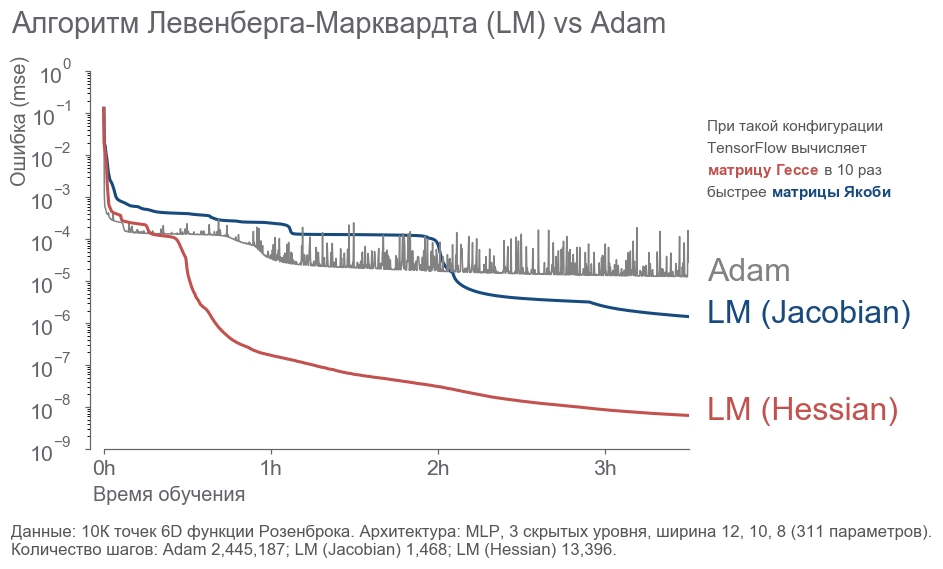
rosenbrock_train.py . . , .
Kesimpulan
, . " ", , . , . , 273 . - , .
, :
- .
- ( ) -:
[1] Petros Drineas, Ravi Kannan, and Michael W. Mahoney. 2006. Fast Monte Carlo Algorithms for Matrices I: Approximating Matrix Multiplication. SIAM J. Comput. 36, 1 (July 2006), 132-157. DOI= http://dx.doi.org/10.1137/S0097539704442684
[2] Adelman, M., & Silberstein, M. (2018). Faster Neural Network Training with Approximate Tensor Operations. CoRR, abs/1805.08079.
, - . , . "".