Salah satu tugas paling penting dalam bidang ilmu data bukan hanya pembangunan model yang mampu membuat prediksi berkualitas tinggi, tetapi juga kemampuan untuk menafsirkan prediksi tersebut.
Jika kita tidak hanya tahu bahwa klien cenderung membeli suatu produk, tetapi juga memahami apa yang mempengaruhi pembeliannya, kita akan dapat membangun strategi perusahaan di masa depan yang bertujuan untuk meningkatkan efisiensi penjualan.
Atau model meramalkan bahwa pasien akan segera jatuh sakit. Keakuratan prediksi semacam itu tidak terlalu tinggi, karena Ada banyak faktor yang tersembunyi dari model, tetapi penjelasan alasan mengapa model membuat prediksi seperti itu dapat membantu dokter memperhatikan gejala baru. Dengan demikian, dimungkinkan untuk memperluas batas penerapan model jika akurasinya sendiri tidak terlalu tinggi.
Dalam posting ini saya ingin berbicara tentang teknik
SHAP , yang memungkinkan Anda untuk melihat di bawah kap berbagai model.
Jika dengan model linier menjadi semakin tidak jelas, semakin besar nilai absolut koefisien di bawah prediktor, semakin penting prediktor ini, maka menjelaskan pentingnya fitur peningkatan gradien yang sama terasa lebih sulit.
Mengapa ada kebutuhan untuk perpustakaan seperti itu

Di tumpukan sklearn, dalam paket xgboost, lightGBM, ada metode bawaan untuk menilai pentingnya fitur (fitur penting) untuk "model kayu":
- Keuntungan
Ukuran ini menunjukkan kontribusi relatif dari setiap fitur ke model. untuk perhitungan, kita pergi melalui setiap pohon, melihat setiap simpul pohon yang fitur mengarah ke partisi simpul dan berapa banyak ketidakpastian model menurun sesuai dengan metrik (Gini pengotor, perolehan informasi).
Untuk setiap fitur, kontribusinya terhadap semua pohon dirangkum.
- Penutup
Memperlihatkan jumlah pengamatan untuk setiap fitur. Misalnya, Anda memiliki 4 fitur, 3 pohon. Misalkan fitur 1 pada simpul pohon masing-masing berisi 10, 5, dan 2 pengamatan di pohon 1, 2, dan 3. Kemudian, untuk fitur ini, kepentingannya adalah 17 (10 + 5 + 2).
- Frekuensi
Memperlihatkan seberapa sering fitur ini muncul di simpul pohon, yaitu jumlah total pohon yang terbagi menjadi simpul untuk setiap fitur di setiap pohon dipertimbangkan.
Masalah utama dalam semua pendekatan ini adalah tidak jelas bagaimana tepatnya fitur ini mempengaruhi prediksi model. Sebagai contoh, kami belajar bahwa tingkat pendapatan penting untuk menilai solvabilitas klien bank untuk membayar pinjaman. Tapi bagaimana tepatnya? Berapa prediksi model penerimaan bias lebih tinggi?
Tentu saja, kita dapat membuat beberapa prediksi dengan mengubah tingkat pendapatan. Tetapi apa yang harus dilakukan dengan fitur lain? Bagaimanapun, kita menemukan diri kita dalam situasi yang kita butuhkan untuk mendapatkan pemahaman tentang pengaruh pendapatan
secara independen dari fitur-fitur lain, dengan nilai rata-rata mereka.
Ada semacam rata-rata nasabah bank "dalam ruang hampa." Bagaimana model prediksi berubah dengan perubahan pendapatan?
Di sini perpustakaan
SHAP datang untuk menyelamatkan.
Kami menghitung pentingnya fitur menggunakan SHAP
Di perpustakaan
SHAP , untuk menilai pentingnya
fitur, nilai-nilai Shapley dihitung (dengan nama seorang ahli matematika Amerika dan namanya perpustakaan).
Untuk menilai pentingnya fitur, prediksi model dievaluasi
dengan dan
tanpa fitur ini.
Sedikit prasejarah

Makna Shapley berasal dari teori permainan.
Pertimbangkan skenario: sekelompok orang bermain kartu. Bagaimana cara mendistribusikan dana hadiah di antara mereka sesuai dengan kontribusi mereka?
Sejumlah asumsi dibuat:
- Jumlah hadiah untuk setiap pemain sama dengan jumlah total hadiah
- Jika dua pemain memberikan kontribusi yang sama untuk permainan, mereka menerima hadiah yang sama.
- Jika seorang pemain belum memberikan kontribusi, dia tidak akan menerima hadiah.
- Jika seorang pemain telah menghabiskan dua pertandingan, maka total hadiahnya terdiri dari jumlah hadiah untuk setiap pertandingan
Kami menyajikan fitur model sebagai pemain, dan kumpulan hadiah sebagai prediksi akhir model.
Mari kita lihat sebuah contoh.
Rumus untuk menghitung nilai Shapley untuk fitur ke-i:
$$ menampilkan $$ \ mulai {persamaan *} \ phi_ {i} (p) = \ sum_ {S \ subseteq N / \ {i \}} \ frac {| S |! (n - | S | -1) !} {n!} (p (S \ cup \ {i \}) - p (S)) \ end {persamaan *} $$ menampilkan $$
Di sini:
p (S \ cup \ {i \}) Merupakan prediksi model dengan fitur i-th,
- ini adalah prediksi model tanpa fitur i-th,
- jumlah fitur,
- seperangkat fitur yang sewenang-wenang tanpa fitur ke-i
Nilai Shapley untuk fitur ke-i dihitung untuk setiap sampel data (misalnya, untuk setiap klien dalam sampel) pada semua kemungkinan kombinasi fitur (termasuk tidak adanya semua fitur), maka nilai yang diperoleh dijumlahkan modulo dan kepentingan akhir dari fitur ke-i diperoleh.
Perhitungan ini sangat mahal, oleh karena itu, di bawah tenda, berbagai algoritma untuk mengoptimalkan perhitungan digunakan, untuk lebih jelasnya, lihat tautan di atas pada github.
Ambil contoh vanilla dari
dokumentasi xgboost .
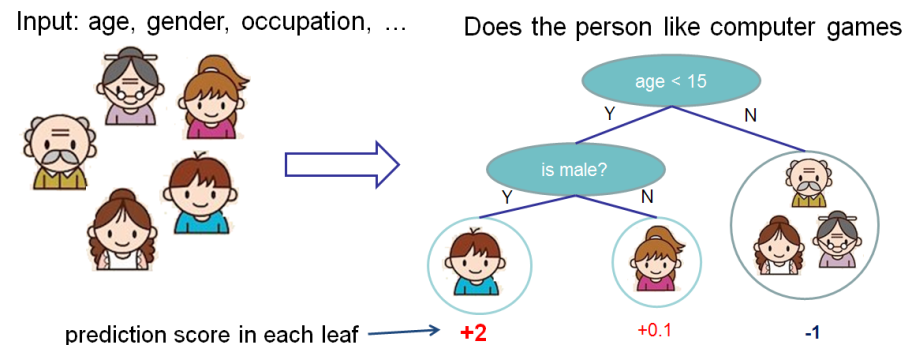
Kami ingin mengevaluasi pentingnya fitur untuk memprediksi apakah seseorang menyukai game komputer.
Dalam contoh ini, untuk kesederhanaan, kami memiliki dua fitur: usia (usia) dan jenis kelamin (jenis kelamin). Gender (gender) mengambil nilai 0 dan 1.
Ambil Bobby (bocah laki-laki di simpul paling kiri dari pohon) dan hitung nilai Shapley untuk umur fitur (umur).
Kami memiliki dua set fitur S:
\ {\} - tidak ada fitur
\ {gender \} - hanya ada fitur gender.
Situasi ketika tidak ada nilai fitur
Model yang berbeda bekerja secara berbeda dengan situasi di mana tidak ada fitur untuk sampel data, yaitu, untuk semua fitur nilainya NULL.
Dalam hal ini, akan dipertimbangkan bahwa model rata-rata prediksi atas cabang-cabang pohon, yaitu, prediksi tanpa fitur akan
.
Jika kita menambah pengetahuan usia, maka prediksi modelnya adalah
.
Akibatnya, nilai Shapley untuk kasus tidak adanya fitur:
\ frac {| S |! (n - | S | -1)!} {n!} (p (S \ cup \ {i \}) - p (S)) = \ frac {1 (2-0 -1)!} {2!} (1,025) = 0,5125
Situasi saat kita mengenal gender
Untuk bobby untuk
prediksi tanpa fitur fitur, hanya dengan fitur jenis kelamin yang sama
. Jika kita tahu umur, maka prediksi adalah pohon paling kiri, yaitu 2.
Akibatnya, nilai Shapley untuk kasus ini:
$$ menampilkan $$ \ mulai {persamaan *} \ frac {| S |! (n - | S | -1)!} {n!} (p (S \ cup \ {i \}) - p (S) ) = \ frac {1 (2-1-1)!} {2!} (1.975) = 0.9875 \ end {persamaan *} $$ menampilkan $$
Ringkaslah
Nilai total Shapley untuk usia fitur (usia):
$$ tampilan $$ \ mulai {persamaan *} \ phi_ {Usia Bobby} = 0,9875 + 0,5125 = 1,5 \ akhir {persamaan *} $$ menampilkan $$
Contoh bisnis nyata
Perpustakaan SHAP memiliki fungsi visualisasi yang kaya yang membantu dengan mudah dan mudah menjelaskan model untuk bisnis dan analis itu sendiri, untuk mengevaluasi kecukupan model.
Di salah satu proyek, saya menganalisis arus keluar karyawan dari perusahaan. Sebagai model, xgboost digunakan.
Kode dalam python:
import shap shap_test = shap.TreeExplainer(best_model).shap_values(df) shap.summary_plot(shap_test, df, max_display=25, auto_size_plot=True)
Grafik yang dihasilkan dari pentingnya fitur:
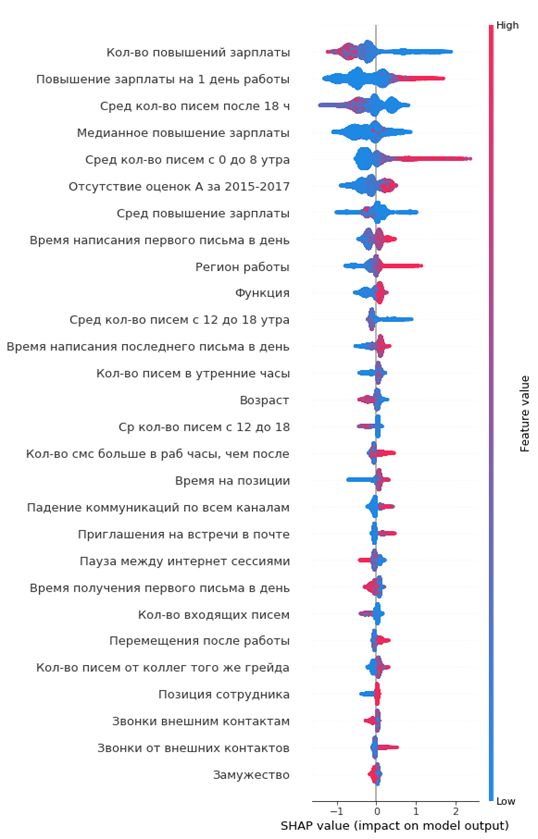
Cara membacanya:
- nilai di sebelah kiri dari garis vertikal tengah adalah kelas negatif (0), ke kanan - positif (1)
- semakin tebal garis pada grafik, semakin banyak titik pengamatan tersebut
- semakin merah poin pada grafik, semakin tinggi nilai fitur di dalamnya
Dari grafik, Anda dapat menarik kesimpulan menarik dan memeriksa kecukupannya:
- semakin rendah kenaikan gaji karyawan, semakin tinggi kemungkinan keberangkatannya
- ada daerah kantor di mana arus keluar lebih tinggi
- semakin muda karyawan, semakin tinggi kemungkinan keberangkatannya
- ...
Anda dapat langsung membentuk potret karyawan yang keluar: dia tidak menerima kenaikan gaji, dia cukup muda, lajang, untuk waktu yang lama di posisi yang sama, tidak ada kenaikan nilai, tidak ada peringkat tahunan yang tinggi, dia mulai berkomunikasi sedikit dengan kolega.
Sederhana dan nyaman!
Anda dapat menjelaskan prediksi untuk karyawan tertentu:

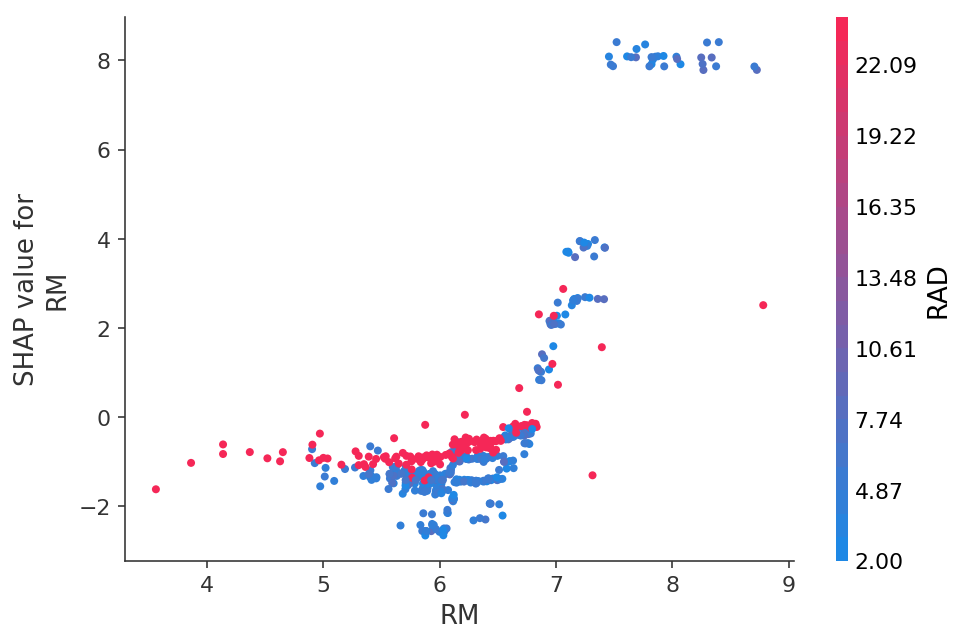
Atau lihat ketergantungan prediksi pada fitur tertentu dalam bentuk grafik 2D:
Anda bahkan dapat memvisualisasikan prediksi jaringan saraf dalam gambar:

Kesimpulan
Saya sendiri belajar tentang nilai-nilai SHAP sekitar enam bulan yang lalu dan ini sepenuhnya menggantikan metode lain untuk menilai pentingnya fitur.
Keuntungan utama:
- visualisasi dan interpretasi yang nyaman
- perhitungan jujur tentang pentingnya fitur
- kemampuan untuk mengevaluasi fitur-fitur untuk subsampel data tertentu (misalnya, bagaimana pelanggan kami berbeda dari pelanggan lain dalam sampel) dilakukan dengan filter sederhana dari dataset dalam panda dan analisisnya dalam bentuk, secara harfiah beberapa baris kode