Sintesis dan pengeditan gambar terkontrol menggunakan TL-GAN baru Contoh sintesis terkontrol dalam model TL-GAN saya (GAN laten-ruang transparan, jaringan generatif-contentive dengan ruang tersembunyi transparan)
Contoh sintesis terkontrol dalam model TL-GAN saya (GAN laten-ruang transparan, jaringan generatif-contentive dengan ruang tersembunyi transparan)Semua kode dan demo online tersedia di
halaman proyek .
Kami melatih komputer untuk mengambil foto seperti yang dijelaskan
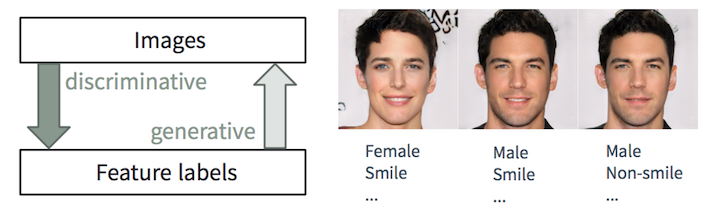 Tugas Diskriminan dan Generatif
Tugas Diskriminan dan GeneratifSangat mudah bagi seseorang untuk
mendeskripsikan gambar, kita belajar melakukannya sejak usia sangat muda. Dalam pembelajaran mesin, ini adalah tugas klasifikasi / regresi
diskriminan , yaitu prediksi fitur dari gambar input. Kemajuan terbaru dalam metode ML / AI, terutama dalam model pembelajaran yang mendalam, mulai unggul dalam tugas-tugas ini, kadang-kadang mencapai atau melampaui kemampuan manusia, seperti yang ditunjukkan dalam tugas-tugas seperti pengenalan objek visual (misalnya, dari AlexNet ke ResNet menurut klasifikasi ImageNet) dan deteksi / segmentasi objek (mis., dari RCNN ke YOLO dalam dataset COCO), dll.
Namun demikian, tugas terbalik untuk
menciptakan gambar yang realistis dari deskripsi jauh lebih rumit dan membutuhkan pelatihan bertahun-tahun dalam desain grafis. Dalam pembelajaran mesin, ini adalah tugas
generatif , yang jauh lebih rumit daripada tugas diskriminatif, karena model generatif harus menghasilkan lebih banyak informasi (misalnya, gambar penuh pada tingkat detail dan variasi tertentu) berdasarkan pada data awal yang lebih kecil.
Terlepas dari kerumitan pembuatan aplikasi seperti itu,
model generatif (dengan beberapa kontrol) sangat berguna dalam banyak kasus:
- Pembuatan konten : Bayangkan bahwa perusahaan periklanan secara otomatis membuat gambar menarik yang cocok dengan konten dan gaya halaman web tempat gambar-gambar ini dimasukkan. Perancang mencari inspirasi dengan memesan algoritma untuk menghasilkan 20 pola sepatu yang terkait dengan tanda "istirahat", "musim panas" dan "bersemangat". Gim baru ini memungkinkan Anda menghasilkan avatar realistis dari deskripsi sederhana.
- Pengeditan cerdas berdasarkan konten : fotografer mengubah ekspresi wajah, jumlah kerutan dan tatanan rambut dalam foto dalam beberapa klik. Seorang seniman di studio Hollywood mengonversi bidikan yang diambil pada malam berawan, seolah-olah diambil pada pagi yang cerah, dengan sinar matahari di sisi kiri layar.
- Augmentasi Data : Pengembang drone dapat mensintesis video realistis untuk skenario kecelakaan tertentu untuk meningkatkan set data pelatihan. Bank dapat mensintesis jenis data penipuan tertentu dengan buruk yang disajikan dalam kumpulan data yang ada untuk meningkatkan sistem anti-penipuan.
Pada artikel ini, kita akan membahas tentang karya terbaru kami yang disebut
Transparent Latent-space GAN (TL-GAN) , yang memperluas fungsionalitas model paling modern, menyediakan antarmuka baru. Kami sedang mengerjakan dokumen yang akan memiliki lebih banyak detail teknis.
Tinjauan Model Generatif
Komunitas pembelajaran yang mendalam dengan cepat meningkatkan model generatif. Tiga tipe yang menjanjikan dapat dibedakan di antaranya:
model autoregresif ,
variabel autoencoder (VAE) dan
jaringan permusuhan generatif (GAN) , yang ditunjukkan pada gambar di bawah ini. Jika Anda tertarik dengan detailnya, silakan baca
artikel blog OpenAI yang bagus.
 Perbandingan jaringan generatif. Gambar dari kursus STAT946F17 di University of Waterloo
Perbandingan jaringan generatif. Gambar dari kursus STAT946F17 di University of WaterlooSaat ini, gambar dengan
kualitas terbaik dihasilkan oleh jaringan GAN (fotorealistik dan beragam, dengan detail meyakinkan dalam resolusi tinggi). Lihatlah jaringan pg-GAN (
GAN yang tumbuh secara progresif ) dari Nvidia yang menakjubkan. Karenanya, dalam artikel ini kita akan fokus pada model GAN.
 Pg-GAN sintetis yang dihasilkan oleh Nvidia. Tidak ada gambar yang terkait dengan kenyataan.
Pg-GAN sintetis yang dihasilkan oleh Nvidia. Tidak ada gambar yang terkait dengan kenyataan.Manajemen Masalah Model GAN
 Pembuatan gambar acak dan terkontrolVersi asli GAN
Pembuatan gambar acak dan terkontrolVersi asli GAN dan banyak model populer berdasarkan itu (seperti
DC-GAN dan
pg-GAN ) adalah model pengajaran
tanpa guru . Setelah pelatihan, jaringan saraf generatif mengambil noise acak sebagai input dan menciptakan gambar fotorealistik yang hampir tidak dapat dibedakan dari set data pelatihan. Namun, kami tidak dapat mengontrol fitur tambahan dari gambar yang dihasilkan. Di sebagian besar aplikasi (misalnya, dalam skenario yang dijelaskan di bagian pertama), pengguna ingin membuat pola dengan
atribut yang berubah -
ubah (misalnya, usia, warna rambut, ekspresi wajah, dll.) Idealnya, konfigurasi setiap fungsi dengan lancar.
Berbagai varian GAN telah dibuat untuk sintesis terkontrol tersebut. Mereka dapat secara kondisional dibagi menjadi dua jenis: jaringan gaya transfer dan generator kondisional.
Jaringan Transfer Gaya
Jaringan transfer gaya
CycleGAN dan
pix2pix dilatih untuk mentransfer gambar dari satu area (domain) ke area lain: misalnya, dari kuda ke zebra, dari sketsa ke gambar berwarna. Akibatnya, kami tidak dapat dengan lancar mengubah tanda tertentu antara dua keadaan yang terpisah (misalnya, menambahkan sedikit jenggot di wajah). Selain itu, satu jaringan dirancang untuk satu jenis transmisi, sehingga sepuluh jaringan saraf yang berbeda akan diperlukan untuk mengonfigurasi sepuluh fungsi.
Kondisi Generator
Generator
bersyarat -
GAN bersyarat ,
AC-GAN dan Stack-GAN - dalam proses pelatihan, secara simultan mempelajari gambar dan label objek, yang memungkinkan Anda untuk menghasilkan gambar dengan pengaturan atribut. Ketika Anda ingin menambahkan fitur baru ke proses pembuatan, Anda perlu melatih ulang seluruh model GAN, yang membutuhkan sumber daya dan waktu komputasi yang sangat besar (misalnya, dari beberapa hari hingga beberapa minggu pada GPU K80 yang sama dengan serangkaian hyperparameter yang ideal). Selain itu, untuk menyelesaikan pelatihan, perlu bergantung pada satu set data yang berisi semua label objek yang ditentukan pengguna, dan tidak menggunakan label yang berbeda dari beberapa set data.
Jaringan kompetitif generatif kami dengan ruang tersembunyi transparan (
Transparent Latent-space GAN , TL-GAN) menggunakan pendekatan yang berbeda untuk generasi yang dikendalikan - dan menyelesaikan masalah ini. Ini menawarkan kemampuan untuk
mengkonfigurasi satu atau lebih fitur dengan menggunakan jaringan tunggal . Selain itu, Anda dapat secara efektif menambahkan fitur kustom baru dalam waktu kurang dari satu jam.
TL-GAN: Pendekatan Baru dan Efektif untuk Sintesis dan Penyuntingan Terkendali
Membuat ruang tersembunyi misterius transparan ini
Ambil model pvGAN dari Nvidia, yang menghasilkan gambar fotorealistik resolusi tinggi dari wajah, seperti yang ditunjukkan pada bagian sebelumnya. Semua fitur dari gambar 1024 × 1024px yang dihasilkan ditentukan secara eksklusif oleh vektor noise 512-dimensi dalam ruang tersembunyi (sebagai representasi dimensi-rendah dari konten gambar). Oleh karena itu,
jika kita memahami apa yang merupakan ruang tersembunyi (mis., Membuatnya transparan), maka kita dapat sepenuhnya mengendalikan proses pembuatan .
 Motivasi TL-GAN: Memahami Ruang Tersembunyi untuk Mengelola Proses Pembuatan
Motivasi TL-GAN: Memahami Ruang Tersembunyi untuk Mengelola Proses PembuatanBereksperimen dengan jaringan pg-GAN pra-terlatih, saya menemukan bahwa ruang tersembunyi sebenarnya memiliki dua sifat yang baik:
- Itu diisi dengan baik, yaitu, sebagian besar titik di ruang menghasilkan gambar yang masuk akal.
- Ini cukup kontinu, yaitu, interpolasi antara dua titik dalam ruang tersembunyi biasanya mengarah pada transisi yang mulus dari gambar yang sesuai.
Intuition mengatakan bahwa dalam ruang tersembunyi ada arah yang memprediksi atribut yang kita butuhkan (misalnya, seorang pria / wanita). Jika demikian, maka vektor-vektor satuan dari arahan ini akan menjadi sumbu untuk mengendalikan proses pembangkitan (wajah yang lebih maskulin atau feminin).
Pendekatan: Perluasan Sumbu Fitur
Untuk menemukan sumbu atribut ini dalam ruang tersembunyi,
kami membuat koneksi antara vektor tersembunyi z dan tag label y menggunakan pelatihan guru berpasangan
( z , y ) . Sekarang masalahnya adalah bagaimana mendapatkan pasangan ini, karena set data yang ada hanya berisi gambar
x dan label objek yang sesuai
y .
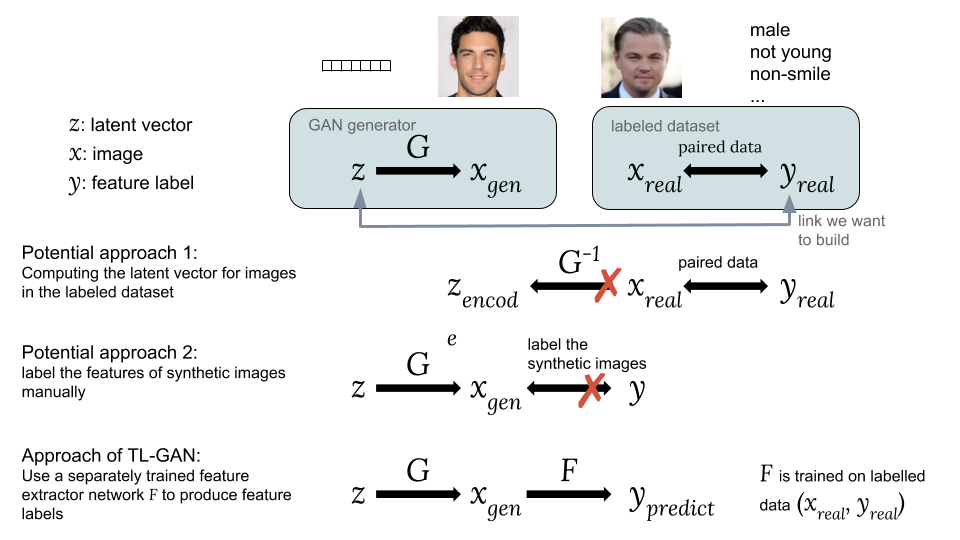 Cara mengaitkan vektor tersembunyi z dengan label tag yKemungkinan pendekatan:Salah satu opsi adalah untuk menghitung vektor tersembunyi yang sesuai z gambar x r e a l dari dataset yang ada dengan label yang menarik bagi kami y r e a l . Namun, GAN tidak menyediakan cara mudah untuk menghitung z e n c o d e = G - 1 x r e a l , yang membuatnya sulit untuk menerapkan ide ini.
Cara mengaitkan vektor tersembunyi z dengan label tag yKemungkinan pendekatan:Salah satu opsi adalah untuk menghitung vektor tersembunyi yang sesuai z gambar x r e a l dari dataset yang ada dengan label yang menarik bagi kami y r e a l . Namun, GAN tidak menyediakan cara mudah untuk menghitung z e n c o d e = G - 1 x r e a l , yang membuatnya sulit untuk menerapkan ide ini.
Opsi kedua adalah menghasilkan gambar sintetis x g e n menggunakan GAN dari vektor tersembunyi acak z bagaimana x g e n = G ( z ) . Masalahnya adalah bahwa gambar sintetis tidak ditandai, sehingga sulit untuk menggunakan set data tag yang dapat diakses.Inovasi utama dari model TL-GAN kami adalah
pelatihan ekstraktor terpisah (pengklasifikasi untuk label diskrit atau regressor untuk kontinu) dengan model
Y = f ( x ) menggunakan set data tag yang ada (
x r e a l ,
y r e a l ), dan kemudian meluncurkan sekelompok GAN-generator terlatih
G dengan jaringan ekstraksi fitur
F . Ini memungkinkan Anda untuk memprediksi label fitur.
y p r e d gambar sintetis
x g e n menggunakan jaringan ekstraksi fitur terlatih (extractor). Dengan demikian, melalui gambar sintetis, koneksi dibuat antara
z dan
y bagaimana
x g e n = G ( z ) dan
y p r e d = F ( x g e n ) .
Sekarang kami memiliki vektor dan fitur tersembunyi yang dipasangkan. Anda dapat melatih model regressor
y = A ( z ) untuk membuka semua sumbu fitur untuk mengontrol proses pembuatan gambar.
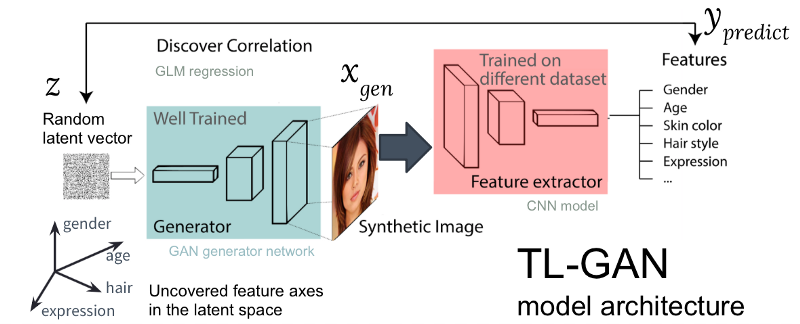 Gambar: Arsitektur model TL-GAN kami
Gambar: Arsitektur model TL-GAN kamiGambar di atas menunjukkan arsitektur model TL-GAN, yang berisi lima langkah:
- Studi distribusi . Kami memilih model GAN yang terlatih dan jaringan generatif. Saya mengambil pg-GAN (dari Nvidia) yang terlatih, yang memberikan generasi wajah dengan kualitas terbaik.
- Klasifikasi . Kami memilih model pra-terlatih untuk mengekstraksi sifat-sifat (ekstraktor dapat berupa jaringan saraf convolutional atau model lain dari visi komputer) atau melatih ekstraktor kami sendiri menggunakan satu set data yang ditandai. Saya melatih jaringan saraf convolutional sederhana menggunakan kit CelebA (lebih dari 30.000 wajah dengan 40 tag).
- Generasi . Kami membuat beberapa vektor tersembunyi acak, melewati generator GAN terlatih untuk membuat gambar sintetis, kemudian menggunakan fitur extractor terlatih untuk menghasilkan fitur pada setiap gambar.
- Korelasi . Kami menggunakan model linier umum (GLM) untuk menerapkan regresi antara vektor dan fitur tersembunyi. Kemiringan garis regresi menjadi sumbu sifat .
- Penelitian Kita mulai dengan satu vektor tersembunyi, pindahkan sepanjang satu atau beberapa sumbu tanda, dan pelajari bagaimana hal ini memengaruhi pembuatan gambar.
Saya telah sangat mengoptimalkan proses: pada model GAN yang sudah dilatih sebelumnya, mengidentifikasi sumbu fitur
hanya membutuhkan waktu satu jam pada mesin dengan satu GPU. Ini dicapai melalui beberapa trik teknik, termasuk mentransfer pelatihan, mengurangi ukuran gambar, penyimpanan awal gambar sintetik, dll.
Hasil
Mari kita lihat bagaimana ide sederhana ini bekerja.
Memindahkan vektor tersembunyi di sepanjang sumbu objek
Pertama, saya memeriksa apakah sumbu fitur yang terdeteksi dapat digunakan untuk mengontrol fitur yang sesuai dari gambar yang dihasilkan. Untuk melakukan ini, buat vektor acak
z 0 di ruang tersembunyi GAN dan menghasilkan gambar sintetis
x 0 melewatinya melalui jaringan generatif
x 0 = G ( z 0 ) . Lalu kami memindahkan vektor tersembunyi di sepanjang satu sumbu fitur
kamu (vektor satuan dalam ruang tersembunyi, katakanlah, sesuai dengan jenis kelamin wajah) di kejauhan
λ ke posisi baru
x 1 = x 0 + λ u dan menghasilkan gambar baru
x 1 = G ( z 1 ) . Idealnya, fitur yang sesuai dari gambar baru harus berubah ke arah yang diharapkan.
Hasil memindahkan vektor sepanjang beberapa poros atribut (jenis kelamin, usia, dll.) Disajikan di bawah ini. Ini bekerja dengan sangat baik! Anda dapat
dengan lancar mengubah gambar antara pria / wanita, pria muda / pria tua, dll.
 Hasil pertama memindahkan vektor tersembunyi di sepanjang sumbu fitur kusut
Hasil pertama memindahkan vektor tersembunyi di sepanjang sumbu fitur kusutMengungkap sumbu fitur yang berkorelasi
Dalam contoh di atas, kerugian dari metode asli terlihat, yaitu sumbu atribut yang bingung. Misalnya, ketika Anda perlu mengurangi rambut wajah, wajah yang dihasilkan menjadi lebih feminin, yang bukan hasil yang diharapkan. Masalahnya adalah bahwa jenis kelamin dan jenggot secara inheren
berkorelasi . Perubahan dalam satu sifat mengarah ke perubahan yang lain. Hal serupa terjadi dengan fitur lain, seperti rambut dan rambut keriting. Seperti yang ditunjukkan pada gambar di bawah ini, sumbu asli atribut "jenggot" di ruang tersembunyi tidak tegak lurus dengan sumbu "lantai".
Untuk mengatasi masalah tersebut, saya menggunakan teknik aljabar linier sederhana. Secara khusus, ia memproyeksikan sumbu jenggot ke arah yang baru, ortogonal ke sumbu lantai, yang secara efektif menghilangkan korelasinya dan, dengan demikian, berpotensi mengurai kedua tanda ini pada wajah yang dihasilkan.
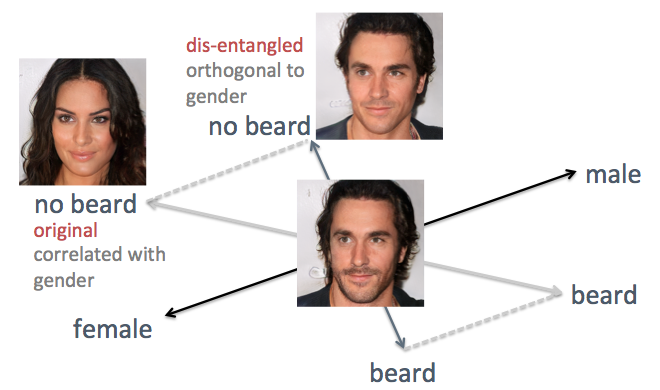 Mengungkap sumbu fitur berkorelasi dengan teknik aljabar linier
Mengungkap sumbu fitur berkorelasi dengan teknik aljabar linierSaya menerapkan metode ini ke orang yang sama. Kali ini, sumbu gender dan usia dipilih sebagai yang mendukung, memproyeksikan semua sumbu lainnya sehingga mereka menjadi ortogonal terhadap gender dan usia. Wajah dihasilkan dengan menggerakkan vektor tersembunyi di sepanjang sumbu fitur yang baru dibuat (ditunjukkan pada gambar di bawah). Seperti yang diharapkan, sekarang tanda-tanda seperti gaya rambut dan jenggot tidak memengaruhi lantai.
 Peningkatan hasil pemindahan vektor tersembunyi di sepanjang sumbu fitur yang tidak terurai
Peningkatan hasil pemindahan vektor tersembunyi di sepanjang sumbu fitur yang tidak teruraiPengeditan interaktif yang fleksibel
Untuk melihat seberapa fleksibel model TL-GAN kami dapat mengontrol proses pembuatan gambar, saya membuat antarmuka grafis interaktif dengan perubahan halus dalam nilai-nilai objek di sepanjang sumbu yang berbeda, seperti yang ditunjukkan di bawah ini.
Pengeditan interaktif dengan TL-GANDan lagi, model ini bekerja sangat baik jika Anda mengubah gambar di sepanjang sumbu tanda!
Ringkasan
Proyek ini menunjukkan metode baru untuk mengelola model generatif tanpa guru, seperti GAN (jaringan permusuhan generatif). Menggunakan generator GAN pra-terlatih (pg-GAN dari Nvidia), saya membuat ruang tersembunyi transparan dengan menunjukkan sumbu fitur signifikan. Ketika vektor bergerak di sepanjang sumbu tersebut dalam ruang tersembunyi, gambar yang sesuai ditransformasikan sepanjang fitur ini, memberikan sintesis dan pengeditan yang terkontrol.
Metode ini memiliki keunggulan yang jelas:
- Efisiensi: untuk menambahkan tag tuner baru untuk generator, Anda tidak perlu melatih ulang model GAN, jadi menambahkan tuner untuk 40 tag membutuhkan waktu kurang dari satu jam.
- Fleksibilitas: Anda dapat menggunakan ekstraktor fitur apa pun yang dilatih pada dataset apa pun, menambahkan lebih banyak fitur ke GAN yang terlatih.
Beberapa kata tentang etika
Pekerjaan ini memungkinkan Anda untuk mengontrol pembuatan gambar secara detail, tetapi masih sangat tergantung pada karakteristik set data. Pelatihan foto-foto bintang-bintang Hollywood berarti bahwa model tersebut akan menghasilkan foto-foto sebagian besar orang kulit putih dan menarik. Ini akan mengarah pada fakta bahwa pengguna akan dapat membuat wajah yang hanya mewakili sebagian kecil umat manusia. Jika Anda menggunakan layanan ini sebagai aplikasi nyata, disarankan untuk memperluas set data asli untuk memperhitungkan keragaman pengguna kami.
Meskipun alat ini dapat sangat membantu dalam proses kreatif, Anda perlu mengingat tentang kemungkinan menggunakannya untuk tujuan yang tidak pantas. Jika kita membuat wajah realistis dari jenis apa pun, maka sejauh mana kita dapat mempercayai orang yang kita lihat di layar? Hari ini penting untuk membahas masalah-masalah semacam ini. Seperti yang kita lihat dalam contoh teknologi
Deepfake baru- baru ini, AI berkembang pesat, jadi penting bagi umat manusia untuk memulai diskusi tentang cara terbaik menyebarkan aplikasi tersebut.
Demo dan kode online
Semua kode dan demo online untuk pekerjaan ini tersedia di
halaman GitHub .
Jika Anda ingin bermain dengan model di browser
Anda tidak perlu mengunduh kode, model, atau data. Cukup ikuti instruksi di
bagian Readme
ini . Anda dapat mengubah wajah di browser seperti yang ditunjukkan dalam video.
Jika Anda ingin mencoba kodenya
Buka saja halaman Readme dari repositori GitHub. Kode dikompilasi pada Anaconda Python 3.6 dengan Tensorflow dan Keras.
Jika Anda ingin berkontribusi
Selamat datang Jangan ragu untuk mengirimkan permintaan kumpulan atau melaporkan masalah di GitHub.
Tentang saya
Baru-baru ini saya menerima gelar PhD dalam bidang neurobiologi komputasi dan kognitif dari Brown University dan gelar master dalam ilmu komputer, dengan spesialisasi dalam pembelajaran mesin. Di masa lalu, saya mempelajari bagaimana neuron di otak secara kolektif memproses informasi untuk mencapai fungsi tingkat tinggi seperti persepsi visual. Saya suka pendekatan algoritmik untuk analisis, simulasi, dan implementasi intelijen, serta penggunaan AI untuk memecahkan masalah dunia nyata yang kompleks. Saya aktif mencari pekerjaan sebagai peneliti ML / AI di industri teknologi.
Ucapan Terima Kasih
Pekerjaan ini dilakukan dalam tiga minggu sebagai proyek untuk
program beasiswa AI InSight . Saya berterima kasih kepada direktur program
Emmanuel Amaisen dan
Matt Rubashkin untuk kepemimpinan umum, terutama Emmanuel atas sarannya dan mengedit artikel tersebut. Saya juga berterima kasih kepada semua karyawan Insight untuk lingkungan belajar yang sangat baik dan peserta program AI Insight lainnya yang banyak saya pelajari.
Terima kasih khusus kepada Rubin Xia untuk banyak tip dan inspirasi ketika saya memutuskan ke arah mana untuk mengembangkan proyek ini, dan untuk bantuan yang sangat besar dalam menyusun dan mengedit artikel ini.