
Pada Konferensi AI,
Vladimir Ivanov vivanov879 , Sr. akan berbicara tentang penggunaan pembelajaran yang diperkuat
Insinyur pembelajaran dalam di Nvidia . Pakar tersebut terlibat dalam pembelajaran mesin di departemen pengujian: “Saya menganalisis data yang kami kumpulkan selama pengujian video game dan perangkat keras. Untuk ini saya menggunakan pembelajaran mesin dan visi komputer. Bagian utama dari pekerjaan ini adalah analisis gambar, pembersihan data sebelum pelatihan, markup data dan visualisasi solusi yang diperoleh. "
Dalam artikel hari ini, Vladimir menjelaskan mengapa pembelajaran yang diperkuat digunakan dalam mobil otonom dan berbicara tentang bagaimana agen dilatih untuk bertindak dalam lingkungan yang berubah - menggunakan contoh video game.
Dalam beberapa tahun terakhir, umat manusia telah mengumpulkan sejumlah besar data. Beberapa dataset dibagikan dan ditata secara manual. Sebagai contoh, dataset CIFAR, di mana setiap gambar ditandatangani, di mana kelas itu berada.
Ada kumpulan data di mana Anda perlu menetapkan kelas tidak hanya untuk gambar secara keseluruhan, tetapi untuk setiap piksel dalam gambar. Seperti, misalnya, di CityScapes.

Apa yang menyatukan tugas-tugas ini adalah bahwa jaringan syaraf pembelajaran hanya perlu mengingat pola dalam data. Oleh karena itu, dengan jumlah data yang cukup besar, dan dalam kasus CIFAR adalah 80 juta gambar, jaringan saraf sedang belajar untuk menggeneralisasi. Sebagai hasilnya, dia mengatasi dengan baik klasifikasi gambar yang belum pernah dia lihat sebelumnya.
Tapi bertindak dalam kerangka teknik pengajaran dengan guru, yang berfungsi untuk menandai gambar, tidak mungkin untuk memecahkan masalah di mana kita ingin tidak memprediksi tanda, tetapi untuk membuat keputusan. Seperti, misalnya, dalam kasus mengemudi otonom, di mana tugasnya adalah mencapai titik akhir rute dengan aman dan andal.
Dalam masalah klasifikasi, kami menggunakan teknik mengajar dengan guru - ketika setiap gambar diberikan kelas tertentu. Tetapi bagaimana jika kita tidak memiliki markup seperti itu, tetapi ada agen dan lingkungan di mana dia dapat melakukan tindakan tertentu? Sebagai contoh, biarkan itu menjadi permainan video, dan kita bisa mengklik panah kontrol.

Masalah seperti ini harus diselesaikan dengan pelatihan penguatan. Dalam pernyataan umum masalah, kami ingin mempelajari cara melakukan urutan tindakan yang benar. Sangat penting bahwa agen memiliki kemampuan untuk melakukan tindakan berulang kali, sehingga menjelajahi lingkungan di mana dia berada. Dan alih-alih jawaban yang benar, apa yang harus dilakukan dalam situasi tertentu, ia menerima hadiah untuk tugas yang diselesaikan dengan benar. Misalnya, dalam hal taksi otonom, pengemudi akan menerima bonus untuk setiap perjalanan yang dilakukan.
Mari kita kembali ke contoh sederhana - gim video. Ambil sesuatu yang sederhana, seperti permainan tenis meja Atari.
Kami akan mengontrol tablet di sebelah kiri. Kami akan bermain melawan pemain komputer yang diprogram pada aturan di sebelah kanan. Karena kita bekerja dengan gambar, dan jaringan saraf adalah yang paling sukses dalam mengekstraksi informasi dari gambar, mari kita terapkan gambar ke input dari jaringan saraf tiga lapis dengan ukuran kernel 3x3. Di pintu keluar, dia harus memilih salah satu dari dua tindakan: menggerakkan papan ke atas atau ke bawah.
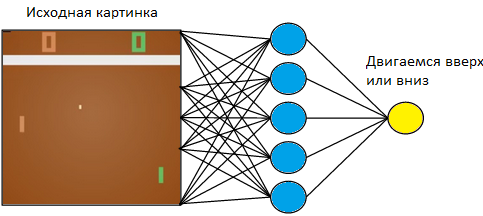
Kami melatih jaringan saraf untuk melakukan tindakan yang mengarah pada kemenangan. Teknik pelatihannya adalah sebagai berikut. Kami membiarkan jaringan saraf memainkan beberapa putaran tenis meja. Kemudian kita mulai menyortir game yang dimainkan. Dalam permainan di mana ia menang, kami menandai foto-foto yang berlabel "Atas" di mana ia mengangkat raket, dan "Turun" di mana ia menurunkannya. Dalam permainan yang hilang, kami melakukan yang sebaliknya. Kami menandai foto-foto itu di mana dia menurunkan papan dengan label "Atas", dan di mana dia mengangkatnya, "Bawah". Dengan demikian, kami mengurangi masalah dengan pendekatan yang sudah kami ketahui - pelatihan dengan seorang guru. Kami memiliki serangkaian gambar dengan tag.
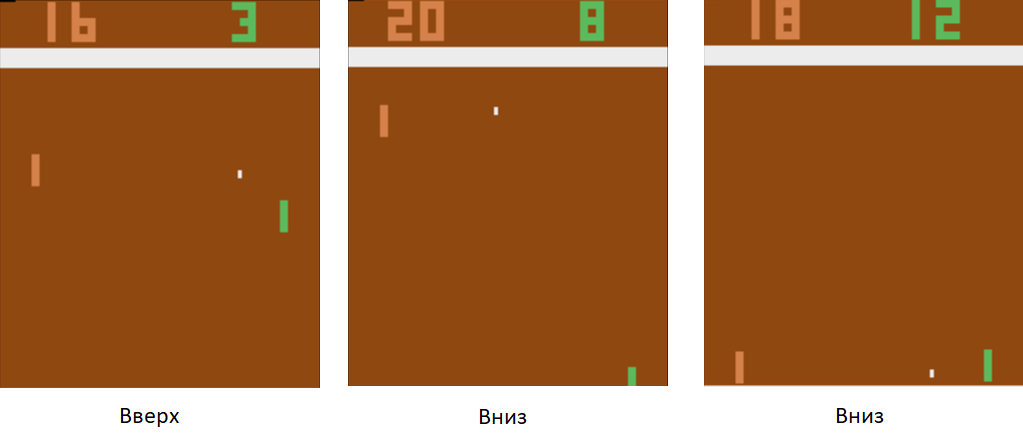
Dengan menggunakan teknik pelatihan ini, dalam beberapa jam, agen kami akan belajar untuk mengalahkan pemain komputer yang diprogram pada aturan.
Apa yang harus dilakukan dengan mengemudi mandiri? Faktanya adalah tenis meja adalah permainan yang sangat sederhana. Dan itu dapat menghasilkan ribuan frame per detik. Di jaringan kami sekarang hanya ada 3 lapisan. Karena itu, proses pembelajaran cepat kilat. Gim ini menghasilkan banyak data, dan kami langsung memprosesnya. Dalam hal mengemudi otonom, mengumpulkan data jauh lebih lama dan lebih mahal. Mobil itu mahal, dan dengan satu mobil kita hanya akan menerima 60 frame per detik. Selain itu, harga kesalahan meningkat. Dalam video game, kami bisa bermain game demi game di awal pelatihan. Tetapi kita tidak sanggup merusak mobil.
Dalam hal ini, mari kita bantu jaringan saraf pada awal pelatihan. Kami memperbaiki kamera di mobil, memasukkan driver berpengalaman dan kami akan merekam foto dari kamera. Untuk setiap gambar, kami berlangganan sudut kemudi mobil. Kami akan melatih jaringan saraf untuk menyalin perilaku pengemudi berpengalaman. Karena itu, kami mengurangi tugas menjadi pengajaran yang sudah diketahui bersama seorang guru.
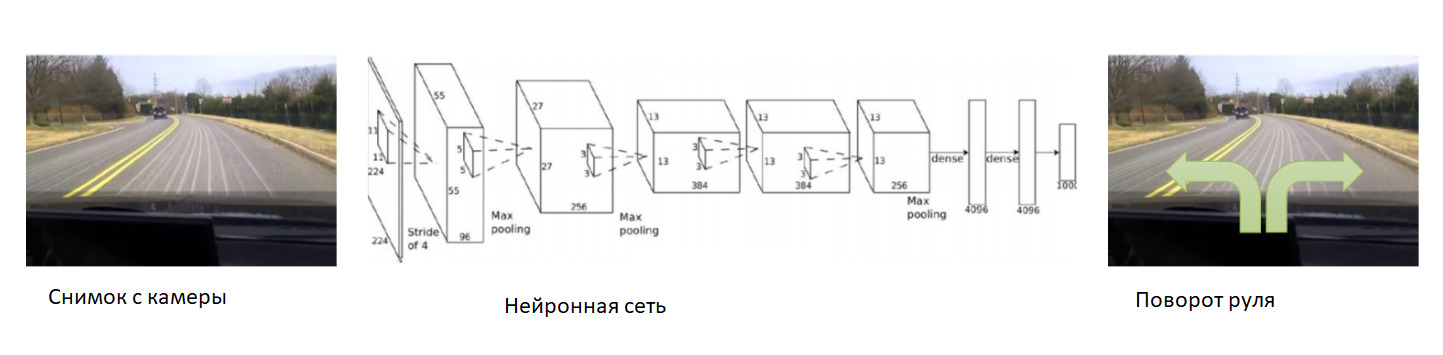
Dengan set data yang cukup besar dan beragam, yang akan mencakup berbagai lanskap, musim, dan kondisi cuaca, jaringan saraf akan belajar cara mengontrol mobil secara akurat.
Namun, ada masalah dengan data. Mereka sangat panjang dan mahal untuk dikumpulkan. Mari kita gunakan simulator di mana semua fisika gerakan mobil akan diimplementasikan - misalnya, DeepDrive. Kita bisa mempelajarinya tanpa takut kehilangan mobil.

Dalam simulator ini, kami memiliki akses ke semua indikator mobil dan dunia. Selain itu, semua orang, mobil, kecepatan dan jarak mereka ditandai di sekitar.

Dari sudut pandang insinyur, dalam simulator seperti itu, Anda dapat dengan aman mencoba teknik pelatihan baru. Apa yang harus dilakukan seorang peneliti? Misalnya, mempelajari berbagai opsi untuk gradient descent dalam mempelajari masalah dengan penguatan. Untuk menguji hipotesis sederhana, saya tidak ingin menembak burung pipit dari meriam dan menjalankan agen di dunia maya yang kompleks, dan kemudian menunggu berhari-hari pada suatu waktu untuk hasil simulasi. Dalam hal ini, mari kita gunakan kekuatan komputasi kita lebih efisien. Biarkan agen lebih sederhana. Ambil contoh, model laba-laba berkaki empat. Dalam simulator Mujoco, tampilannya seperti ini:

Kami memberinya tugas berlari dengan kecepatan setinggi mungkin dalam arah yang diberikan - misalnya, ke kanan. Jumlah parameter yang diamati untuk seekor laba-laba adalah vektor 39-dimensi, yang mencatat posisi dan kecepatan semua anggota tubuhnya. Berbeda dengan jaringan saraf untuk tenis meja, di mana hanya ada satu neuron di output, ada delapan di output (karena laba-laba dalam model ini memiliki 8 sendi).
Dalam model sederhana seperti itu, berbagai hipotesis tentang teknik pengajaran dapat diuji. Sebagai contoh, mari kita bandingkan kecepatan belajar untuk berjalan, tergantung pada jenis jaringan saraf. Biarkan itu menjadi jaringan saraf single-layer, jaringan saraf tiga-layer, jaringan convolutional dan jaringan berulang:
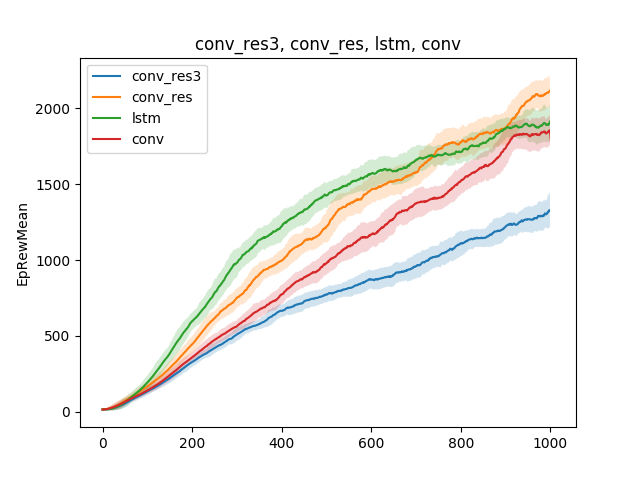
Kesimpulannya dapat ditarik sebagai berikut: karena model laba-laba dan tugasnya cukup sederhana, hasil pelatihan hampir sama untuk model yang berbeda. Jaringan tiga lapis terlalu rumit, dan karenanya belajar lebih buruk.
Terlepas dari kenyataan bahwa simulator bekerja dengan model laba-laba sederhana, tergantung pada tugas yang diajukan kepada laba-laba, pelatihan dapat berlangsung selama berhari-hari. Dalam hal ini, mari kita hidupkan beberapa ratus laba-laba pada satu permukaan pada saat yang sama, bukan satu dan belajar dari data yang akan kita terima dari semua orang. Jadi kami akan mempercepat pelatihan beberapa ratus kali. Berikut ini contoh mesin Flex.
Satu-satunya hal yang telah berubah dalam hal optimasi jaringan saraf adalah pengumpulan data. Saat kami hanya menjalankan satu spider, kami menerima data secara berurutan. Berjalan satu demi satu.

Sekarang mungkin saja terjadi bahwa beberapa laba-laba baru saja memulai lomba, sementara yang lain telah berlari untuk waktu yang lama.
Kami akan mempertimbangkan ini selama optimasi jaringan saraf. Kalau tidak, semuanya tetap sama. Hasilnya, kami mendapat akselerasi dalam latihan ratusan kali, sesuai dengan jumlah laba-laba yang secara bersamaan di layar.
Karena kita memiliki simulator yang efektif, mari kita coba untuk menyelesaikan masalah yang lebih kompleks. Misalnya, berlari di medan yang kasar.

Karena lingkungan dalam kasus ini menjadi lebih agresif, mari kita ubah dan rumit tugas selama pelatihan. Sulit dipelajari, tetapi mudah dalam pertempuran. Misalnya, setiap beberapa menit untuk mengubah medan. Selain itu, mari kita arahkan agen eksternal ke agen. Misalnya, mari kita melempar bola ke arahnya dan menghidupkan dan mematikan angin. Kemudian agen itu belajar berlari bahkan pada permukaan yang belum pernah dia temui. Misalnya naik tangga.

Karena kita telah begitu efektif belajar menjalankan dalam simulasi, mari kita periksa teknik pelatihan penguatan dalam disiplin kompetitif. Misalnya, dalam shooting game. Platform VizDoom menawarkan dunia tempat Anda dapat menembak, mengumpulkan senjata, dan memulihkan kesehatan. Dalam game ini kita juga akan menggunakan jaringan saraf. Hanya sekarang dia akan memiliki lima jalan keluar: empat untuk gerakan dan satu untuk menembak.
Agar pelatihan menjadi efektif, mari kita lakukan secara bertahap. Dari yang sederhana hingga yang kompleks. Pada input, jaringan saraf menerima gambar, dan sebelum mulai melakukan sesuatu secara sadar, ia harus belajar untuk memahami apa yang terdiri dari dunia. Belajar dalam skenario sederhana, dia akan belajar untuk memahami benda apa yang menghuni dunia dan bagaimana berinteraksi dengan mereka. Mari kita mulai dengan tanda hubung:
Setelah menguasai skenario ini, agen akan memahami bahwa ada musuh, dan mereka harus ditembak, karena Anda mendapatkan poin untuk mereka. Kemudian kami akan melatihnya dalam skenario di mana kesehatan terus menurun, dan Anda perlu mengisinya kembali.

Di sini dia akan belajar bahwa dia sehat dan perlu diisi ulang, karena dalam kasus kematian agen menerima hadiah negatif. Selain itu, ia akan belajar bahwa jika Anda bergerak ke arah subjek, Anda dapat mengumpulkannya. Dalam skenario pertama, agen tidak bisa bergerak.
Dan dalam skenario terakhir, ketiga, mari kita biarkan dia menembak dengan bot yang diprogram pada aturan dari permainan sehingga dia dapat mengasah keterampilannya.

Selama pelatihan dalam skenario ini, pemilihan ganjaran yang benar yang diterima agen sangat penting. Misalnya, jika Anda memberikan hadiah hanya untuk lawan yang kalah, sinyalnya akan sangat jarang: jika ada beberapa pemain di sekitarnya, maka kami akan menerima poin setiap beberapa menit. Karena itu, mari kita gunakan kombinasi hadiah yang sebelumnya. Agen akan menerima hadiah untuk setiap tindakan yang bermanfaat, apakah itu meningkatkan kesehatan, memilih kartrid atau memukul lawan.
Akibatnya, agen yang dilatih dengan hadiah yang dipilih dengan baik lebih kuat daripada lawannya yang lebih banyak menuntut komputasi. Pada 2016, sistem seperti itu memenangkan kompetisi VizDoom dengan selisih lebih dari setengah poin dari posisi kedua. Tim runner-up juga menggunakan jaringan saraf, hanya dengan sejumlah besar lapisan dan informasi tambahan dari mesin permainan selama pelatihan. Misalnya, informasi tentang apakah ada musuh di bidang visi agen.
Kami telah memeriksa pendekatan untuk memecahkan masalah, di mana penting untuk membuat keputusan. Tetapi banyak tugas dengan pendekatan ini akan tetap tidak terselesaikan. Misalnya, game pencarian Montezuma Revenge.
Di sini Anda perlu mencari kunci untuk membuka pintu ke kamar tetangga. Kami jarang mendapatkan kunci, dan kami jarang membuka kamar. Penting juga untuk tidak terganggu oleh benda asing. Jika Anda melatih sistem seperti yang kami lakukan dalam tugas sebelumnya, dan memberikan hadiah untuk musuh yang babak belur, itu hanya akan melumpuhkan tengkorak yang berputar berulang-ulang dan tidak akan memeriksa peta. Jika Anda tertarik, saya dapat berbicara tentang memecahkan masalah seperti itu di artikel terpisah.
Anda dapat mendengarkan pidato Vladimir Ivanov di Konferensi AI pada 22 November . Program dan tiket terperinci tersedia di
situs web resmi acara tersebut.
Baca wawancara dengan Vladimir di
sini .