Fatal 43 detik, yang menyebabkan penurunan layanan setiap hariSebuah
insiden terjadi pada GitHub minggu lalu yang menurunkan layanan selama 24 jam dan 11 menit. Insiden itu tidak mempengaruhi seluruh platform, tetapi hanya beberapa sistem internal, yang menyebabkan tampilan informasi yang ketinggalan zaman dan tidak konsisten. Pada akhirnya, data pengguna tidak hilang, tetapi rekonsiliasi manual beberapa detik penulisan ke database masih berlangsung. Untuk sebagian besar kerusakan, GitHub juga tidak dapat menangani webhooks, membuat dan menerbitkan Halaman GitHub.
Kami semua di GitHub ingin dengan tulus meminta maaf atas masalah yang Anda semua temui. Kami tahu tentang kepercayaan Anda pada GitHub dan bangga menciptakan sistem berkelanjutan yang mendukung ketersediaan platform kami yang tinggi. Kami telah mengecewakan Anda dengan insiden ini dan sangat menyesalinya. Meskipun kami tidak dapat mengatasi masalah karena degradasi platform GitHub untuk waktu yang lama, kami dapat menjelaskan alasan atas apa yang terjadi, berbicara tentang pelajaran yang dipetik dan langkah-langkah yang akan memungkinkan perusahaan untuk melindungi dirinya sendiri dari kegagalan seperti itu di masa depan.
Latar belakang
Sebagian besar layanan pengguna GitHub bekerja di
pusat data kami sendiri. Topologi pusat data dirancang untuk menyediakan jaringan perbatasan yang andal dan dapat diperluas di depan beberapa pusat data regional yang menyediakan pekerjaan komputasi dan sistem penyimpanan data. Meskipun tingkat redundansi dibangun ke dalam komponen fisik dan logis proyek, masih mungkin bahwa situs tidak akan dapat berinteraksi satu sama lain selama beberapa waktu.
Pada 21 Oktober, jam 10:52 UTC, jadwal perbaikan untuk mengganti peralatan optik 100G yang salah mengakibatkan hilangnya komunikasi antara simpul jaringan di Pantai Timur (Pantai Timur AS) dan pusat data utama di Pantai Timur. Koneksi di antara mereka dipulihkan setelah 43 detik, tetapi pemutusan yang singkat ini menyebabkan serangkaian peristiwa yang menyebabkan 24 jam dan 11 menit degradasi layanan.
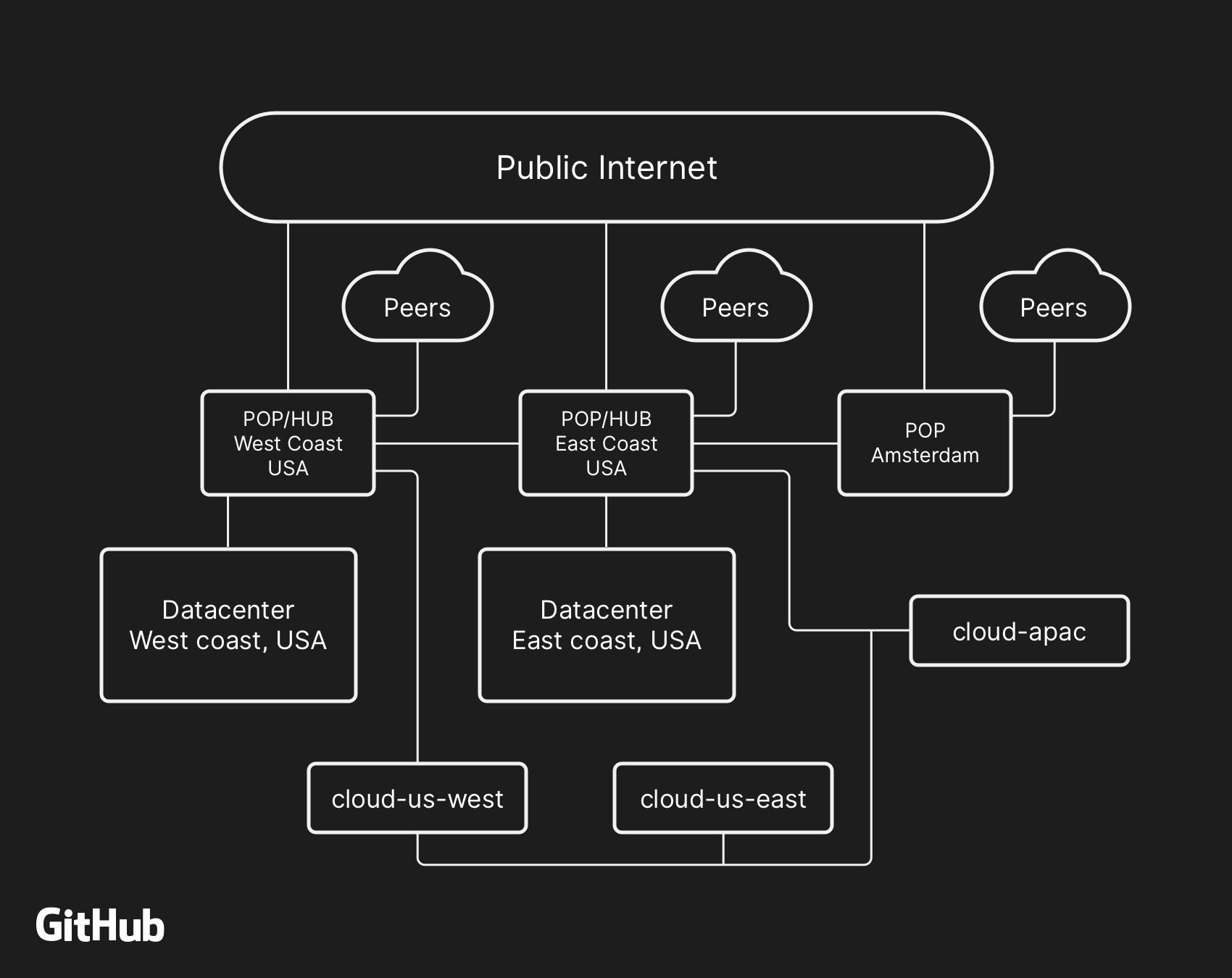 Arsitektur jaringan tingkat tinggi GitHub, termasuk dua pusat data fisik, 3 POPs, dan penyimpanan cloud di beberapa wilayah, terhubung melalui peering
Arsitektur jaringan tingkat tinggi GitHub, termasuk dua pusat data fisik, 3 POPs, dan penyimpanan cloud di beberapa wilayah, terhubung melalui peeringDi masa lalu, kami membahas bagaimana kami menggunakan
MySQL untuk menyimpan metadata GitHub , serta pendekatan kami untuk menyediakan
ketersediaan tinggi untuk MySQL . GitHub mengelola beberapa cluster MySQL mulai dari ukuran ratusan gigabyte hingga hampir lima terabyte. Setiap cluster memiliki lusinan replika baca untuk menyimpan metadata selain Git, sehingga aplikasi kami menyediakan permintaan kumpulan, masalah, otentikasi, pemrosesan latar belakang, dan fitur tambahan di luar repositori objek Git. Data yang berbeda di berbagai bagian aplikasi disimpan dalam kelompok yang berbeda menggunakan segmentasi fungsional.
Untuk meningkatkan kinerja dalam skala besar, aplikasi langsung menulis ke server utama yang sesuai untuk setiap cluster, tetapi dalam sebagian besar kasus mendelegasikan permintaan baca ke subset dari server replika. Kami menggunakan
Orchestrator untuk mengelola topologi cluster MySQL dan secara otomatis gagal. Selama proses ini, Orchestrator memperhitungkan sejumlah variabel dan dirakit di atas
Raft untuk konsistensi. Orchestrator berpotensi dapat mengimplementasikan topologi yang tidak didukung aplikasi, jadi Anda perlu memastikan bahwa konfigurasi Orchestrator Anda memenuhi harapan tingkat aplikasi.
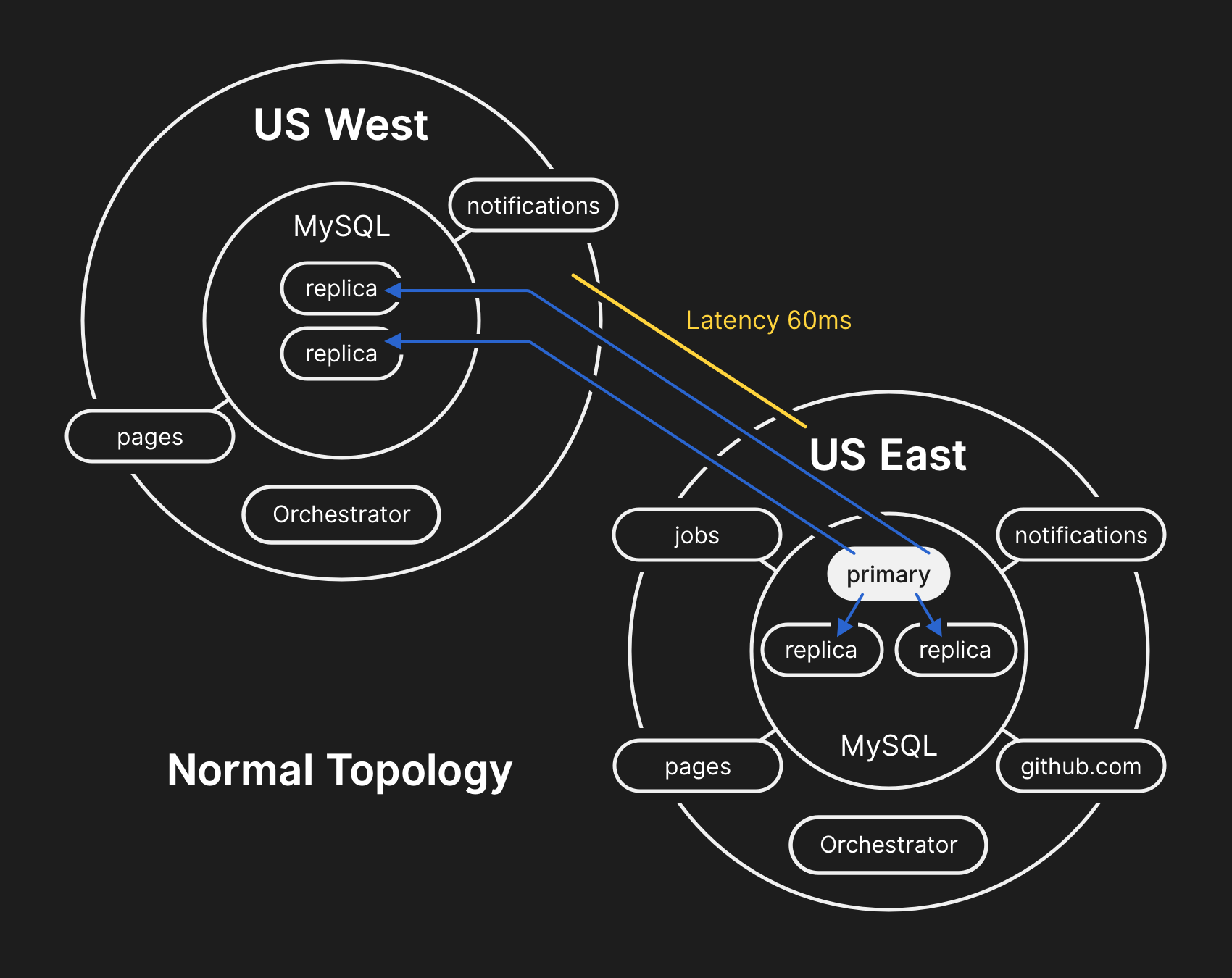 Dalam topologi tipikal, semua aplikasi membaca secara lokal dengan latensi rendah.
Dalam topologi tipikal, semua aplikasi membaca secara lokal dengan latensi rendah.Kronik kejadian itu
10.21.2018, 22:52 UTC
Selama pemisahan jaringan yang disebutkan di atas, Orchestrator di pusat data utama memulai proses penghapusan pilihan kepemimpinan menurut algoritma konsensus Raft. Pusat data Pantai Barat dan simpul awan publik Orchestrator di Pantai Timur berhasil mencapai konsensus - dan mulai mengusahakan kegagalan cluster untuk meneruskan catatan ke pusat data barat. Orchestrator mulai membuat topologi klaster basis data di Barat. Setelah tersambung kembali, aplikasi segera mengirim traffic tulis ke server primer baru di US West.
Pada server database di pusat data timur, ada catatan untuk waktu singkat yang tidak direplikasi ke pusat data barat. Karena cluster basis data di kedua pusat data sekarang berisi catatan yang tidak ada di pusat data lain, kami tidak dapat mengembalikan server primer dengan aman ke pusat data timur.
10.21.2018, 22:54 UTC
Sistem pemantauan internal kami mulai menghasilkan peringatan yang menunjukkan banyak kerusakan sistem. Pada saat ini, beberapa insinyur merespons dan berupaya menyortir notifikasi yang masuk. Pada pukul 23:02, para insinyur dari kelompok respons pertama menentukan bahwa topologi untuk banyak kelompok basis data berada dalam kondisi yang tidak terduga. Saat menanyakan API Orchestrator, topologi replikasi basis data ditampilkan, hanya berisi server dari pusat data barat.
10.21.2018, 23:07 UTC
Pada titik ini, tim tanggapan memutuskan untuk secara manual memblokir alat penyebaran internal untuk mencegah perubahan tambahan. Pada 23:09, grup mengatur situs menjadi
kuning . Tindakan ini secara otomatis menetapkan status insiden aktif dan mengirimkan peringatan kepada koordinator insiden. Pada pukul 23:11, koordinator bergabung dengan pekerjaan itu dan dua menit kemudian memutuskan untuk
mengubah status menjadi merah .
10.21.2018, 23:13 UTC
Pada saat itu, jelas bahwa masalah tersebut mempengaruhi beberapa kelompok basis data. Pengembang tambahan dari kelompok teknik database terlibat dalam pekerjaan ini. Mereka mulai memeriksa keadaan saat ini untuk menentukan tindakan apa yang perlu diambil untuk secara manual mengkonfigurasi database Pantai Timur AS sebagai primer untuk setiap cluster dan membangun kembali topologi replikasi. Ini tidak mudah, karena pada titik ini klaster basis data barat telah menerima catatan dari tingkat aplikasi selama hampir 40 menit. Selain itu, di kluster timur, ada beberapa detik rekaman yang tidak direplikasi ke barat dan tidak memungkinkan replikasi catatan baru kembali ke timur.
Melindungi privasi dan integritas data pengguna adalah prioritas utama GitHub. Oleh karena itu, kami memutuskan bahwa lebih dari 30 menit data yang direkam di pusat data barat membuat kami hanya memiliki satu solusi untuk situasi ini untuk menyimpan data ini: maju ke depan (gagal maju). Namun, aplikasi di timur, yang bergantung pada penulisan informasi ke cluster MySQL barat, saat ini tidak dapat menangani penundaan tambahan karena transfer sebagian besar panggilan database mereka bolak-balik. Keputusan ini akan mengarah pada fakta bahwa layanan kami akan menjadi tidak cocok untuk banyak pengguna. Kami percaya bahwa penurunan kualitas layanan dalam jangka panjang layak untuk memastikan konsistensi data pengguna kami.
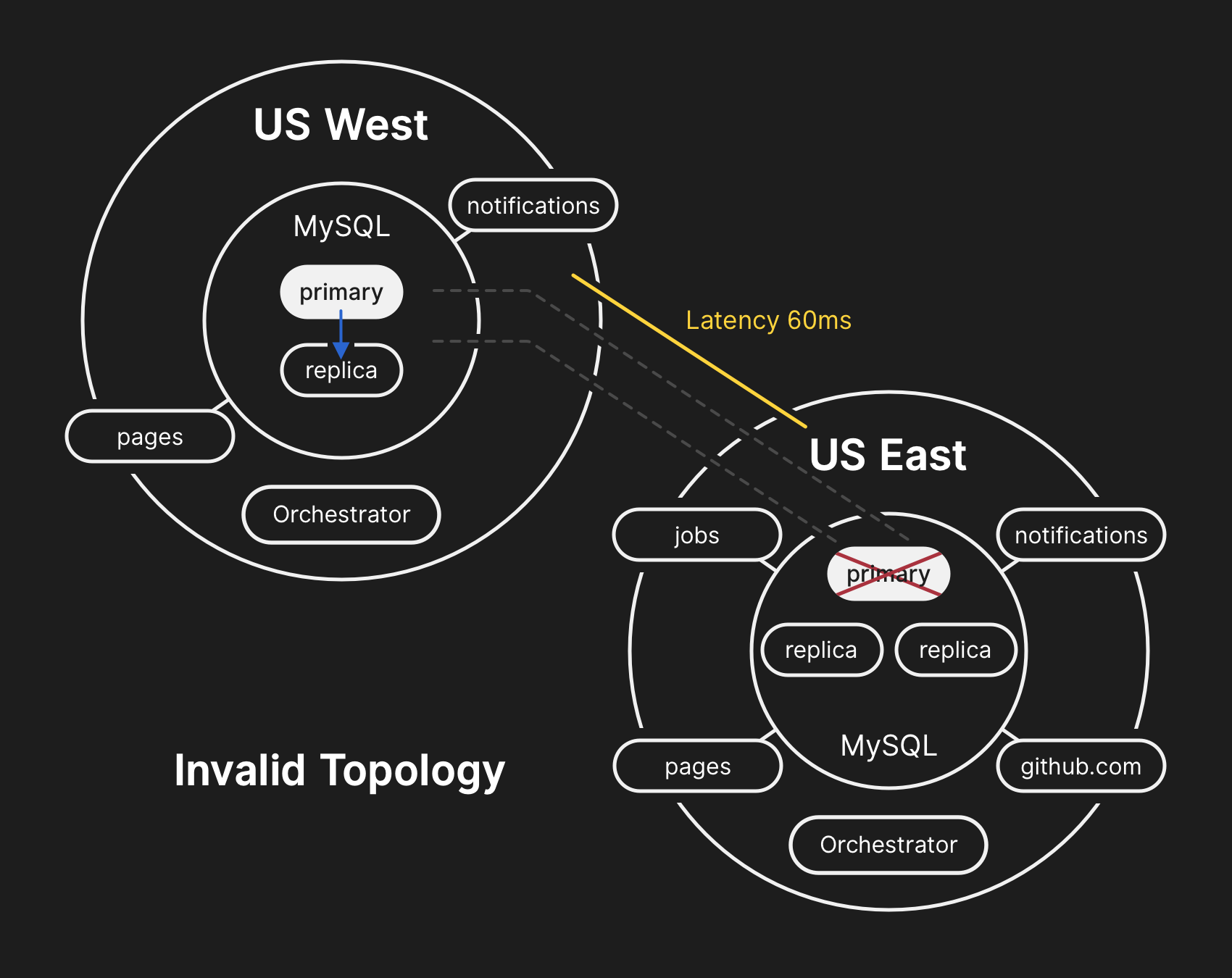 Dalam topologi yang salah, replikasi dari Barat ke Timur dilanggar, dan aplikasi tidak dapat membaca data dari replika saat ini, karena mereka bergantung pada latensi rendah untuk mempertahankan kinerja transaksi
Dalam topologi yang salah, replikasi dari Barat ke Timur dilanggar, dan aplikasi tidak dapat membaca data dari replika saat ini, karena mereka bergantung pada latensi rendah untuk mempertahankan kinerja transaksi10.21.2018, 23:19 UTC
Pertanyaan tentang keadaan cluster database menunjukkan bahwa perlu untuk menghentikan pelaksanaan tugas yang menulis metadata seperti permintaan push. Kami membuat pilihan dan dengan sengaja pergi ke degradasi sebagian layanan, menangguhkan webhooks dan perakitan Halaman GitHub agar tidak membahayakan data yang sudah kami terima dari pengguna. Dengan kata lain, strateginya adalah memprioritaskan: integritas data alih-alih kegunaan situs dan pemulihan cepat.
10/22/2018, 00:05 UTC
Insinyur tim respons mulai mengembangkan rencana untuk menyelesaikan ketidakkonsistenan data dan meluncurkan prosedur failover untuk MySQL. Rencananya adalah mengembalikan file dari cadangan, menyinkronkan replika di kedua situs, kembali ke topologi layanan yang stabil, dan kemudian melanjutkan memproses pekerjaan dalam antrian. Kami memperbarui status untuk memberi tahu pengguna bahwa kami akan melakukan failover terkelola dari sistem penyimpanan internal.
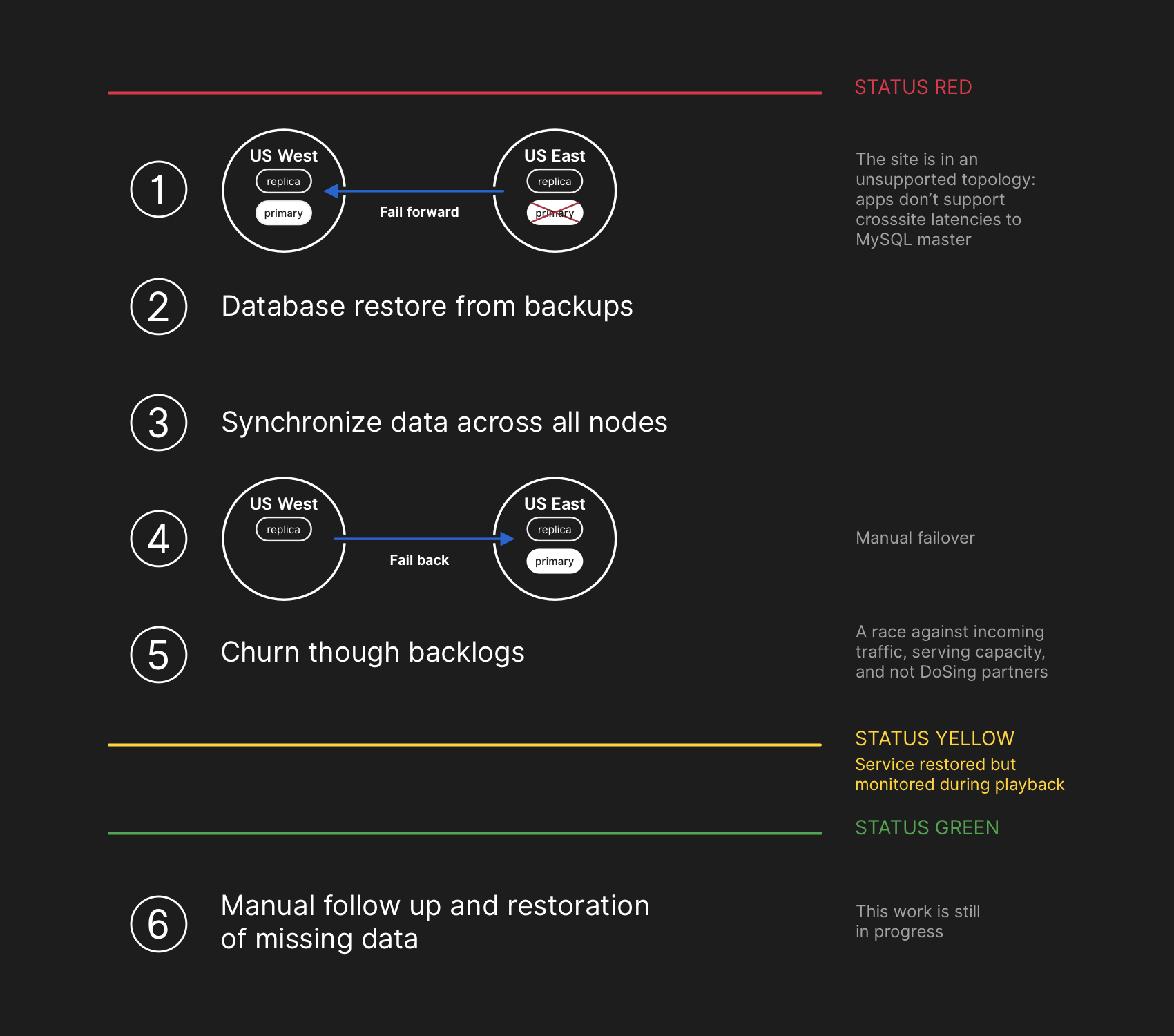 Rencana pemulihan termasuk bergerak maju, memulihkan dari cadangan, menyinkronkan, memutar kembali dan mengatasi penundaan sebelum kembali ke status hijau
Rencana pemulihan termasuk bergerak maju, memulihkan dari cadangan, menyinkronkan, memutar kembali dan mengatasi penundaan sebelum kembali ke status hijauMeskipun cadangan MySQL dibuat setiap empat jam dan disimpan selama bertahun-tahun, mereka berada di penyimpanan awan jauh dari objek gumpalan. Pemulihan beberapa terabyte dari cadangan membutuhkan waktu beberapa jam. Butuh waktu lama untuk mentransfer data dari layanan cadangan jarak jauh. Sebagian besar waktu dihabiskan membongkar, memeriksa checksum, mempersiapkan dan mengunggah file cadangan besar ke server MySQL yang baru disiapkan. Prosedur ini diuji setiap hari, jadi setiap orang punya ide bagus tentang berapa lama pemulihan akan berlangsung. Namun, sebelum kejadian ini, kami tidak pernah harus sepenuhnya membangun kembali seluruh cluster dari cadangan. Strategi lain selalu berhasil, seperti replika ditangguhkan.
10/22/2018, 00:41 UTC
Pada saat ini, proses pencadangan telah dimulai untuk semua kluster MySQL yang terpengaruh, dan para insinyur melacak perkembangannya. Pada saat yang sama, beberapa kelompok insinyur mempelajari cara-cara untuk mempercepat transfer dan pemulihan tanpa degradasi lebih lanjut dari situs atau risiko korupsi data.
10/22/2018, 06:51 UTC
Beberapa cluster di pusat data timur menyelesaikan pemulihan dari cadangan dan mulai mereplikasi data baru dari Pantai Barat. Hal ini menyebabkan perlambatan pemuatan halaman yang melakukan operasi penulisan di seluruh negeri, tetapi membaca halaman dari kelompok basis data ini mengembalikan hasil aktual jika permintaan baca jatuh pada replika yang baru dipulihkan. Cluster database yang lebih besar lainnya terus pulih.
Tim kami telah mengidentifikasi metode pemulihan langsung dari Pantai Barat untuk mengatasi keterbatasan bandwidth yang disebabkan oleh boot dari penyimpanan eksternal. Menjadi hampir 100% jelas bahwa pemulihan akan selesai dengan sukses, dan waktu untuk membuat topologi replikasi yang sehat tergantung pada berapa banyak replikasi mengejar ketinggalan. Perkiraan ini diinterpolasi secara linear berdasarkan replikasi telemetri yang tersedia, dan halaman status
diperbarui untuk menetapkan waktu tunggu dua jam sebagai perkiraan waktu pemulihan.
10/22/2018, 07:46 UTC
GitHub memposting
posting blog informatif . Kami sendiri menggunakan Halaman GitHub, dan semua majelis dijeda beberapa jam yang lalu, sehingga publikasi membutuhkan upaya tambahan. Kami mohon maaf atas keterlambatan ini. Kami bermaksud mengirimkan pesan ini jauh lebih awal dan di masa depan kami akan menyediakan publikasi pembaruan dalam kondisi pembatasan tersebut.
10/22/2018, 11:12 UTC
Semua basis data primer ditransfer kembali ke Timur. Hal ini menyebabkan situs menjadi jauh lebih responsif, karena catatan sekarang dialihkan ke server basis data yang terletak di pusat data fisik yang sama dengan lapisan aplikasi kami. Meskipun ini secara signifikan meningkatkan kinerja, masih ada puluhan replika membaca database yang beberapa jam di belakang salinan utama. Replika yang tertunda ini telah menyebabkan pengguna melihat data yang tidak konsisten saat berinteraksi dengan layanan kami. Kami mendistribusikan beban baca di kumpulan besar replika baca, dan setiap permintaan ke layanan kami memiliki peluang bagus untuk masuk ke replika baca dengan penundaan selama beberapa jam.
Bahkan, waktu mengejar replika lagging berkurang secara eksponensial, tidak linear. Ketika pengguna di AS dan Eropa terbangun, karena peningkatan beban pada catatan dalam kelompok basis data, proses pemulihan memakan waktu lebih lama dari yang diperkirakan.
10/22/2018, 13:15 UTC
Kami sedang mendekati beban puncak di GitHub.com. Tim respon mendiskusikan langkah selanjutnya. Jelas bahwa replikasi lag ke keadaan konsisten meningkat, tidak menurun. Sebelumnya, kami mulai menyiapkan replika bacaan MySQL tambahan di cloud publik East Coast. Setelah tersedia, menjadi lebih mudah untuk mendistribusikan aliran permintaan baca di antara beberapa server. Mengurangi beban rata-rata pada replika baca yang mempercepat replikasi catch-up.
10/22/2018, 16:24 UTC
Setelah menyinkronkan replika, kami kembali ke topologi asli, menghilangkan masalah keterlambatan dan ketersediaan. Sebagai bagian dari keputusan sadar tentang prioritas integritas data atas koreksi situasi yang cepat, kami
mempertahankan status merah situs ketika kami mulai memproses akumulasi data.
10/22/2018, 16:45 UTC
Pada tahap pemulihan, perlu menyeimbangkan peningkatan beban yang terkait dengan jeda, berpotensi membebani mitra ekosistem kita dengan pemberitahuan dan kembali ke efisiensi seratus persen secepat mungkin. Lebih dari lima juta acara kait dan 80 ribu permintaan untuk membangun halaman web tetap dalam antrian.
Ketika kami mengaktifkan kembali pemrosesan data ini, kami memproses sekitar 200.000 tugas yang bermanfaat dengan webhook yang melebihi TTL internal dan dibatalkan. Setelah mengetahui hal ini, kami berhenti memproses dan mulai meningkatkan TTL.
Untuk menghindari penurunan lebih lanjut dalam keandalan pembaruan status kami, kami meninggalkan status degradasi hingga kami selesai memproses seluruh jumlah data yang terakumulasi dan memastikan bahwa layanan telah jelas kembali ke tingkat kinerja normal.
10/22/2018, 11:03 malam UTC
Semua acara webhook yang tidak lengkap dan rakitan Halaman diproses, dan integritas serta operasi yang benar dari semua sistem dikonfirmasi. Status situs telah
diperbarui menjadi hijau .
Tindakan selanjutnya
Menyelesaikan Ketidakcocokan Data
Selama pemulihan, kami memperbaiki log MySQL biner dengan entri terutama dari pusat data, yang tidak direplikasi ke yang barat. Jumlah total entri semacam itu relatif kecil. Misalnya, di salah satu cluster tersibuk, hanya ada 954 catatan dalam detik ini. Kami sedang menganalisis log-log ini dan menentukan entri mana yang dapat direkonsiliasi secara otomatis dan yang membutuhkan bantuan pengguna. Beberapa tim berpartisipasi dalam pekerjaan ini, dan analisis kami telah menentukan kategori catatan yang kemudian diulangi pengguna - dan mereka berhasil disimpan. Seperti yang dinyatakan dalam analisis ini, tujuan utama kami adalah untuk menjaga integritas dan keakuratan data yang Anda simpan di GitHub.
Komunikasi
Mencoba menyampaikan informasi penting kepada Anda selama kejadian, kami membuat beberapa perkiraan publik tentang waktu pemulihan berdasarkan kecepatan pemrosesan dari data yang terakumulasi. Melihat ke belakang, perkiraan kami tidak memperhitungkan semua variabel. Kami mohon maaf atas kebingungan ini dan akan berusaha untuk memberikan informasi yang lebih akurat di masa mendatang.
Langkah-langkah teknis
Dalam perjalanan analisis ini, sejumlah langkah teknis diidentifikasi. Analisis berlanjut, daftar dapat ditambahkan.
- Sesuaikan konfigurasi Orchestrator untuk mencegah basis data primer bergerak ke luar wilayah. Orchestrator bekerja sesuai dengan pengaturan, meskipun lapisan aplikasi tidak mendukung perubahan topologi seperti itu. Memilih pemimpin dalam suatu wilayah biasanya aman, tetapi kemunculan tiba-tiba karena arus lalu lintas lintas benua telah menjadi penyebab utama insiden ini. Ini adalah perilaku baru yang muncul dari sistem, karena sebelumnya kita tidak menemukan bagian internal dari jaringan sebesar ini.
- Kami telah mempercepat migrasi ke sistem pelaporan status baru, yang akan menyediakan platform yang lebih cocok untuk membahas insiden aktif dengan formulasi yang lebih tepat dan jelas. Meskipun banyak bagian GitHub tersedia sepanjang insiden, kami hanya dapat memilih status hijau, kuning, dan merah untuk seluruh situs. Kami mengakui bahwa ini tidak memberikan gambaran yang akurat: apa yang berhasil dan apa yang tidak. Sistem baru akan menampilkan berbagai komponen platform sehingga Anda mengetahui status setiap layanan.
- Beberapa minggu sebelum kejadian ini, kami meluncurkan inisiatif rekayasa di seluruh perusahaan untuk mendukung melayani lalu lintas GitHub dari beberapa pusat data menggunakan arsitektur aktif / aktif / aktif. Tujuan dari proyek ini adalah untuk mendukung redundansi N + 1 di tingkat pusat data untuk menahan kegagalan satu pusat data tanpa campur tangan pihak luar. Ini banyak pekerjaan dan akan memakan waktu, tetapi kami percaya bahwa beberapa pusat data yang terhubung dengan baik di berbagai daerah akan memberikan kompromi yang baik. Insiden terbaru mendorong inisiatif ini lebih jauh.
- Kami akan mengambil sikap yang lebih aktif dalam memeriksa asumsi kami. GitHub tumbuh dengan pesat dan telah mengumpulkan cukup banyak kompleksitas selama dekade terakhir. Semakin sulit untuk menangkap dan meneruskan kepada generasi baru karyawan konteks historis kompromi dan keputusan yang dibuat.
Langkah-langkah organisasi
Kejadian ini sangat memengaruhi pemahaman kami tentang keandalan situs. Kami belajar bahwa memperketat kontrol operasional atau meningkatkan waktu respons bukan jaminan yang cukup untuk keandalan dalam sistem layanan yang kompleks seperti milik kami. Untuk mendukung upaya ini, kami juga akan memulai praktik sistematis pengujian skenario kesalahan sebelum benar-benar terjadi. Pekerjaan ini mencakup pemecahan masalah yang disengaja dan penggunaan alat rekayasa kekacauan.
Kesimpulan
Kami tahu bagaimana Anda mengandalkan GitHub dalam proyek dan bisnis Anda. Kami peduli lebih dari siapa pun tentang ketersediaan layanan kami dan keamanan data Anda.
Analisis kejadian ini akan terus menemukan peluang untuk melayani Anda lebih baik dan membenarkan kepercayaan Anda.