Catatan perev. A: Artikel asli ditulis oleh perwakilan BlueData, sebuah perusahaan yang didirikan oleh orang-orang dari VMware. Dia berspesialisasi dalam membuatnya lebih mudah (lebih mudah, lebih cepat, lebih murah) untuk menyebarkan solusi untuk analitik Big Data dan pembelajaran mesin di berbagai lingkungan. Inisiatif baru-baru ini dari perusahaan bernama BlueK8s , di mana penulis ingin merakit galaksi perangkat Open Source "untuk menyebarkan aplikasi stateful dan mengelolanya di Kubernetes," juga diminta untuk berkontribusi dalam hal ini. Artikel ini didedikasikan untuk yang pertama - KubeDirector, yang, menurut penulis, membantu penggemar di bidang Big Data, yang tidak memiliki pelatihan khusus di Kubernetes, menyebarkan aplikasi seperti Spark, Cassandra atau Hadoop di K8s. Instruksi singkat tentang cara melakukan ini disediakan dalam artikel. Namun, perlu diingat bahwa proyek ini memiliki status kesiapan awal - pra-alfa.
KubeDirector adalah proyek Open Source yang dirancang untuk menyederhanakan peluncuran cluster dari aplikasi stateful scalable yang kompleks di Kubernetes. KubeDirector diimplementasikan menggunakan kerangka kerja
Custom Resource Definition (CRD), menggunakan kemampuan ekstensi API Kubernetes asli dan mengandalkan filosofi mereka. Pendekatan ini memberikan integrasi transparan dengan manajemen pengguna dan sumber daya di Kubernetes, serta dengan klien dan utilitas yang ada.
Proyek KubeDirector yang
baru-baru ini diumumkan adalah bagian dari inisiatif Open Source yang lebih besar untuk Kubernet yang disebut BlueK8s. Sekarang saya senang mengumumkan ketersediaan kode
KubeDirector awal (pra-alfa). Posting ini akan menunjukkan cara kerjanya.
KubeDirector menawarkan fitur-fitur berikut:
- Tidak perlu memodifikasi kode untuk menjalankan aplikasi stateful selain cloud asli dari Kubernetes. Dengan kata lain, tidak perlu menguraikan aplikasi yang ada agar sesuai dengan pola arsitektur layanan microser.
- Dukungan asli untuk menyimpan konfigurasi dan status khusus aplikasi.
- Pola penyebaran aplikasi-independen yang meminimalkan waktu startup aplikasi stateful baru di Kubernetes.
KubeDirector memungkinkan para ilmuwan data, terbiasa dengan aplikasi terdistribusi dengan pemrosesan data intensif, seperti Hadoop, Spark, Cassandra, TensorFlow, Caffe2, dll., Untuk menjalankannya di Kubernetes dengan kurva belajar minimal dan tanpa perlu menulis kode saat Go. Ketika aplikasi ini dikendalikan oleh KubeDirector, mereka ditentukan oleh metadata sederhana dan set konfigurasi yang terkait. Metadata aplikasi didefinisikan sebagai sumber daya
KubeDirectorApp .
Untuk memahami komponen KubeDirector, klon repositori di
GitHub dengan perintah seperti berikut:
git clone http://<userid>@github.com/bluek8s/kubedirector.
Definisi
KubeDirectorApp untuk aplikasi Spark 2.2.1 terletak di
kubedirector/deploy/example_catalog/cr-app-spark221e2.json :
~> cat kubedirector/deploy/example_catalog/cr-app-spark221e2.json
{ "apiVersion": "kubedirector.bluedata.io/v1alpha1", "kind": "KubeDirectorApp", "metadata": { "name" : "spark221e2" }, "spec" : { "systemctlMounts": true, "config": { "node_services": [ { "service_ids": [ "ssh", "spark", "spark_master", "spark_worker" ], …
Konfigurasi aplikasi cluster didefinisikan sebagai sumber daya
KubeDirectorCluster .
Definisi
KubeDirectorCluster untuk contoh cluster Spark 2.2.1 tersedia di
kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml :
~> cat kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml
apiVersion: "kubedirector.bluedata.io/v1alpha1" kind: "KubeDirectorCluster" metadata: name: "spark221e2" spec: app: spark221e2 roles: - name: controller replicas: 1 resources: requests: memory: "4Gi" cpu: "2" limits: memory: "4Gi" cpu: "2" - name: worker replicas: 2 resources: requests: memory: "4Gi" cpu: "2" limits: memory: "4Gi" cpu: "2" - name: jupyter …
Luncurkan Spark di Kubernetes dengan KubeDirector
Memulai cluster Spark di Kubernetes dengan KubeDirector mudah.
Pertama, pastikan Kubernetes berjalan (versi 1.9 atau lebih tinggi) menggunakan perintah
kubectl version :
~> kubectl version Client Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T18:02:47Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"} Server Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T17:53:03Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}
Menyebarkan layanan KubeDirector dan sampel
KubeDirectorApp sumber daya
KubeDirectorApp menggunakan perintah berikut:
cd kubedirector make deploy
Akibatnya, ini akan dimulai dengan KubeDirector:
~> kubectl get pods NAME READY STATUS RESTARTS AGE kubedirector-58cf59869-qd9hb 1/1 Running 0 1m
Lihat daftar aplikasi yang diinstal di KubeDirector dengan menjalankan
kubectl get KubeDirectorApp :
~> kubectl get KubeDirectorApp NAME AGE cassandra311 30m spark211up 30m spark221e2 30m
Sekarang Anda bisa memulai cluster Spark 2.2.1 menggunakan file sampel untuk
KubeDirectorCluster dan
kubectl create -f deploy/example_clusters/cr-cluster-spark211up.yaml . Periksa apakah sudah dimulai:
~> kubectl get pods NAME READY STATUS RESTARTS AGE kubedirector-58cf59869-djdwl 1/1 Running 0 19m spark221e2-controller-zbg4d-0 1/1 Running 0 23m spark221e2-jupyter-2km7q-0 1/1 Running 0 23m spark221e2-worker-4gzbz-0 1/1 Running 0 23m spark221e2-worker-4gzbz-1 1/1 Running 0 23m
Spark juga muncul dalam daftar layanan yang berjalan:
~> kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 21s svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 20s svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 20s svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 20s svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 20s
Jika Anda mengakses port 31533 di browser Anda, Anda dapat melihat Spark Master UI:
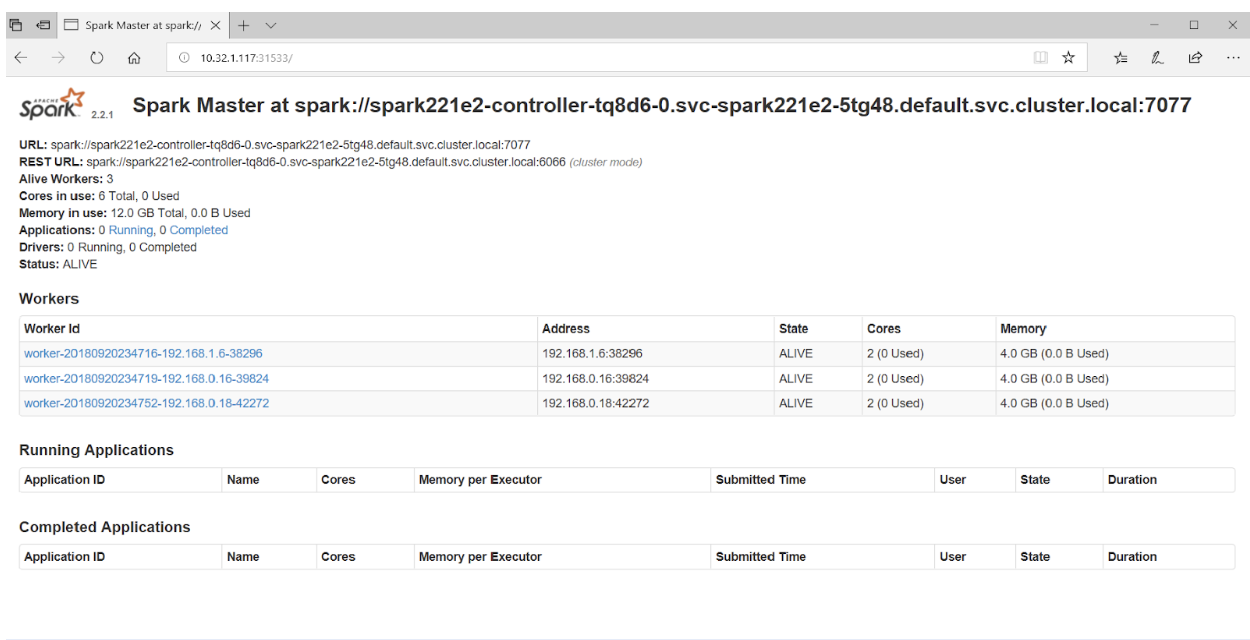
Itu saja! Dalam contoh di atas, selain cluster Spark, kami juga menggunakan
Notebook Jupyter .
Untuk memulai aplikasi lain (misalnya, Cassandra) cukup tentukan file lain dengan
KubeDirectorApp :
kubectl create -f deploy/example_clusters/cr-cluster-cassandra311.yaml
Verifikasi bahwa gugus Cassandra telah dimulai:
~> kubectl get pods NAME READY STATUS RESTARTS AGE cassandra311-seed-v24r6-0 1/1 Running 0 1m cassandra311-seed-v24r6-1 1/1 Running 0 1m cassandra311-worker-rqrhl-0 1/1 Running 0 1m cassandra311-worker-rqrhl-1 1/1 Running 0 1m kubedirector-58cf59869-djdwl 1/1 Running 0 1d spark221e2-controller-tq8d6-0 1/1 Running 0 22m spark221e2-jupyter-6989v-0 1/1 Running 0 22m spark221e2-worker-d9892-0 1/1 Running 0 22m spark221e2-worker-d9892-1 1/1 Running 0 22m
Kubernetes sekarang menjalankan cluster Spark (dengan Jupyter Notebook) dan cluster Cassandra. Daftar layanan dapat dilihat dengan perintah
kubectl get service :
~> kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d svc-cassandra311-seed-v24r6-0 NodePort 10.96.94.204 <none> 22:31131/TCP,9042:30739/TCP 3m svc-cassandra311-seed-v24r6-1 NodePort 10.106.144.52 <none> 22:30373/TCP,9042:32662/TCP 3m svc-cassandra311-vhh29 ClusterIP None <none> 8888/TCP 3m svc-cassandra311-worker-rqrhl-0 NodePort 10.109.61.194 <none> 22:31832/TCP,9042:31962/TCP 3m svc-cassandra311-worker-rqrhl-1 NodePort 10.97.147.131 <none> 22:31454/TCP,9042:31170/TCP 3m svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 24m svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 24m svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 24m svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 24m svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 24m
PS dari penerjemah
Jika Anda tertarik dengan proyek KubeDirector, Anda juga harus memperhatikan
wiki-nya . Sayangnya, tidak mungkin untuk menemukan peta jalan umum, namun,
isu-isu tentang GitHub menjelaskan kemajuan proyek dan pandangan pengembang utama. Selain itu, bagi mereka yang tertarik pada KubeDirector, penulis memberikan tautan ke
Slack chat dan
Twitter .
Baca juga di blog kami: