Hal pertama yang kami temui ketika berbicara tentang pengoptimalan proaktif adalah tidak diketahui apa yang perlu dioptimalkan. "Lakukan itu, aku tidak tahu apa."
- Tidak ada algoritma klasik.
- Masalahnya belum muncul (tidak diketahui), dan orang hanya bisa menebak di mana itu mungkin.
- Kita perlu menemukan beberapa titik kelemahan potensial dalam sistem.
- Cobalah untuk mengoptimalkan kinerja permintaan di tempat-tempat ini.
Tujuan utama optimasi proaktif
Tugas utama optimasi proaktif berbeda dari tugas optimasi reaktif dan adalah sebagai berikut:
- menghilangkan hambatan dalam database;
- penurunan konsumsi sumber daya basis data.
Momen terakhir adalah yang paling mendasar. Dalam hal optimasi reaktif, kami tidak memiliki tugas untuk mengurangi konsumsi sumber daya secara keseluruhan, tetapi hanya tugas membawa waktu respon fungsi ke dalam batas yang dapat diterima.
Jika Anda bekerja dengan server pertempuran, Anda memiliki ide bagus tentang apa yang dimaksud insiden kinerja. Anda harus keluar dari segalanya dan dengan cepat menyelesaikan masalah. RNKO Payment Center LLC bekerja dengan banyak agen, dan sangat penting bagi mereka untuk memiliki masalah sesedikit mungkin. Alexander Makarov di HighLoad ++ Siberia mengatakan apa yang dilakukan untuk secara signifikan mengurangi jumlah insiden kinerja. Optimalisasi proaktif datang untuk menyelamatkan. Dan mengapa dan bagaimana itu diproduksi di server tempur, baca di bawah ini.
 Tentang Pembicara:
Tentang Pembicara: Alexander Makarov (
AL_IG_Makarov ), Administrator Terkemuka dari Database Oracle, LLC RNCO Payment Center. Terlepas dari posisinya, hanya ada sedikit administrasi seperti itu, tugas-tugas utama terkait dengan memelihara kompleks dan pengembangannya, khususnya, memecahkan masalah kinerja.
Apakah optimalisasi pada basis data tempur proaktif?
Pertama, kami akan berurusan dengan ketentuan yang disebut oleh laporan ini sebagai "optimalisasi kinerja proaktif." Terkadang Anda dapat memenuhi sudut pandang bahwa optimalisasi proaktif adalah ketika analisis bidang masalah dilakukan sebelum aplikasi diluncurkan. Misalnya, kami mengetahui bahwa beberapa kueri tidak berfungsi optimal, karena tidak ada cukup indeks atau kueri menggunakan algoritma yang tidak efisien, dan pekerjaan ini dilakukan pada server uji.
Namun demikian, kami di RNCO melakukan proyek ini
di server pertempuran . Sering kali saya mendengar: “Bagaimana bisa begitu? Anda melakukannya di server tempur - itu berarti itu bukan optimasi kinerja proaktif! " Di sini kita perlu mengingat pendekatan yang dikembangkan di ITIL. Dari sudut pandang ITIL, kami memiliki:
- insiden kinerja adalah apa yang telah terjadi;
- langkah-langkah yang kami ambil untuk mencegah terjadinya insiden kinerja.
Dalam hal ini, tindakan kami proaktif. Terlepas dari kenyataan bahwa kami sedang memecahkan masalah pada server tempur, masalah itu sendiri belum muncul: insiden itu tidak terjadi, kami tidak lari dan tidak mencoba menyelesaikan masalah ini dalam waktu singkat.
Jadi, dalam laporan ini, proaktif dipahami sebagai
proaktif dalam arti ITIL , kami memecahkan masalah sebelum insiden kinerja terjadi.
Titik referensi
RNKO "Pusat Pembayaran" melayani 2 sistem besar:
Sifat beban pada sistem ini adalah campuran (DSS + OLTP): ada sesuatu yang bekerja sangat cepat, ada laporan, ada beban sedang.
Kita dihadapkan dengan kenyataan yang tidak terlalu sering, tetapi dengan frekuensi tertentu, insiden kinerja terjadi. Mereka yang bekerja dengan server pertempuran membayangkan apa itu. Ini berarti bahwa Anda harus keluar dari segalanya dan dengan cepat menyelesaikan masalah, karena saat ini klien tidak dapat menerima layanan, sesuatu yang tidak berfungsi sama sekali, atau berfungsi sangat lambat.
Karena cukup banyak agen dan klien terikat dengan organisasi kami, ini sangat penting bagi kami. Jika kami tidak dapat dengan cepat menyelesaikan insiden kinerja, maka pelanggan kami akan menderita dengan satu atau lain cara. Misalnya, mereka tidak akan dapat mengisi kembali kartu atau melakukan transfer. Oleh karena itu, kami bertanya-tanya apa yang bisa dilakukan untuk menghilangkan bahkan insiden kinerja yang jarang terjadi ini. Untuk bekerja dalam mode ketika Anda harus meninggalkan semuanya dan menyelesaikan masalah - ini tidak sepenuhnya benar. Kami menggunakan sprint dan menyusun rencana kerja sprint. Kehadiran insiden kinerja juga merupakan penyimpangan dari rencana kerja.
Sesuatu harus dilakukan dengan ini!
Pendekatan Optimasi
Kami berpikir dan memahami teknologi optimasi proaktif. Tetapi sebelum saya berbicara tentang optimasi proaktif, saya harus mengatakan beberapa kata tentang optimasi reaktif klasik.
Optimalisasi reaktif
Skenarionya sederhana, ada server tempur di mana sesuatu terjadi: mereka meluncurkan laporan, klien menerima pernyataan, saat ini ada aktivitas yang sedang berlangsung di database, dan tiba-tiba seseorang memutuskan untuk memperbarui semacam direktori yang bervolume. Sistem mulai melambat. Pada saat ini, klien datang dan berkata: "Saya tidak bisa melakukan ini atau itu" - kita perlu menemukan alasan mengapa dia tidak bisa melakukan ini.
Algoritma tindakan klasik:- Reproduksi masalahnya.
- Temukan lokasi masalah.
- Optimalkan tempat masalah.
Dalam kerangka pendekatan reaktif, tugas utama bukanlah menemukan akar penyebab itu sendiri dan menghilangkannya, tetapi untuk membuat sistem bekerja secara normal. Penghapusan akar penyebabnya bisa ditanggulangi nanti. Yang utama adalah mengembalikan server dengan cepat sehingga klien dapat menerima layanan.
Tujuan utama optimasi reaktif
Dalam optimasi reaktif, dua tujuan utama dapat dibedakan:
1.
Penurunan waktu respons .
Suatu tindakan, misalnya, menerima laporan, pernyataan, transaksi, harus dilakukan untuk beberapa waktu yang dijadwalkan. Penting untuk memastikan bahwa waktu menerima layanan kembali ke batas yang dapat diterima klien. Mungkin layanan bekerja sedikit lebih lambat dari biasanya, tetapi bagi klien ini dapat diterima. Kemudian kami percaya bahwa insiden kinerja telah dihilangkan, dan kami mulai bekerja pada akar penyebabnya.
2.
Peningkatan jumlah objek yang diproses per unit waktu selama pemrosesan batch .
Ketika pemrosesan batch transaksi sedang berlangsung, perlu untuk mengurangi waktu pemrosesan satu objek dari paket.
Kelebihan pendekatan reaktif:●
Berbagai alat dan teknik adalah nilai tambah utama dari pendekatan reaktif.
Kita dapat menggunakan alat pemantauan untuk memahami apa masalahnya secara langsung: tidak ada cukup CPU, utas, memori, atau sistem disk terpeleset, atau log sedang diproses secara lambat. Ada banyak alat dan teknik untuk mempelajari masalah kinerja saat ini di database Oracle.
●
Waktu respons yang diinginkan adalah nilai tambah lainnya.
Dalam proses kerja seperti itu, kami membawa situasi ke waktu respons yang dapat diterima, yaitu, kami tidak mencoba menguranginya ke nilai minimum, tetapi kami mencapai nilai tertentu dan setelah tindakan ini selesai, karena kami yakin telah mencapai batas yang dapat diterima.
Kontra dari pendekatan reaktif:- Insiden kinerja tetap ada - ini adalah minus terbesar dari pendekatan reaktif, karena kita tidak selalu dapat mencapai akar penyebabnya. Dia bisa tinggal di suatu tempat di luar jalan dan berbaring di tempat yang lebih dalam, terlepas dari kenyataan bahwa kami mencapai kinerja yang dapat diterima.
Dan bagaimana menghadapi insiden kinerja jika belum terjadi? Mari kita coba merumuskan bagaimana optimasi proaktif dapat dilakukan untuk mencegah situasi seperti itu.
Optimasi Proaktif
Hal pertama yang kami temui adalah tidak diketahui apa yang perlu dioptimalkan. "Lakukan itu, aku tidak tahu apa."
- Tidak ada algoritma klasik.
- Masalahnya belum muncul (tidak diketahui), dan orang hanya bisa menebak di mana itu mungkin.
- Kita perlu menemukan beberapa titik kelemahan potensial dalam sistem.
- Cobalah untuk mengoptimalkan kinerja permintaan di tempat-tempat ini.
Tujuan utama optimasi proaktif
Tugas utama optimasi proaktif berbeda dari tugas optimasi reaktif dan adalah sebagai berikut:
- menghilangkan hambatan dalam database;
- penurunan konsumsi sumber daya basis data.
Momen terakhir adalah yang paling mendasar. Dalam hal optimasi reaktif, kami tidak memiliki tugas untuk mengurangi konsumsi sumber daya secara keseluruhan, tetapi hanya tugas membawa waktu respons fungsionalitas ke dalam batas yang dapat diterima.
Bagaimana menemukan kemacetan di database?
Ketika kita mulai memikirkan masalah ini, banyak sub-tugas yang muncul segera. Perlu untuk melakukan:
- Pengujian CPU
- uji beban pada baca / catatan;
- stress testing dengan jumlah sesi aktif;
- uji beban pada ... dll.
Jika kami mencoba mensimulasikan masalah ini pada kompleks pengujian, kami mungkin menemukan fakta bahwa masalah yang muncul pada server pengujian tidak ada hubungannya dengan pertempuran. Ada banyak alasan untuk ini, dimulai dengan fakta bahwa server pengujian biasanya lebih lemah. Adalah baik jika memungkinkan untuk membuat server uji salinan yang tepat dari pertempuran, tetapi ini tidak menjamin bahwa beban akan direproduksi dengan cara yang sama, karena Anda perlu mereproduksi aktivitas pengguna secara akurat dan banyak lagi faktor berbeda yang memengaruhi beban akhir. Jika Anda mencoba mensimulasikan situasi ini, maka, pada umumnya, tidak ada yang menjamin bahwa hal yang persis sama akan terjadi yang akan terjadi di server pertempuran.
Jika dalam satu kasus masalah muncul karena registri baru tiba, maka di lain itu mungkin timbul karena pengguna meluncurkan laporan besar melakukan semacam besar, karena yang mengisi tablespace sementara, dan, seperti sebagai hasilnya, sistem mulai melambat. Artinya, alasannya bisa berbeda, dan tidak selalu mungkin untuk memprediksi mereka. Karenanya,
kami mengabaikan upaya untuk mencari kemacetan di server uji hampir sejak awal. Kami hanya mengandalkan server tempur dan apa yang terjadi di sana.
Apa yang harus dilakukan dalam kasus ini? Mari kita coba untuk memahami sumber daya apa yang paling mungkin kurang di tempat pertama.
Mengurangi konsumsi sumber daya basis data
Berdasarkan kompleks industri yang kami miliki,
kekurangan sumber daya yang paling sering diamati dalam pembacaan disk dan CPU . Karena itu, pertama-tama, kita akan mencari kelemahan di area ini.
Pertanyaan penting kedua: bagaimana cara mencari sesuatu?
Pertanyaannya sangat tidak sepele. Kami menggunakan Oracle Enterprise Edition dengan opsi Paket Diagnostik dan untuk kami sendiri kami menemukan alat seperti itu -
laporan AWR (dalam edisi lain Oracle Anda dapat menggunakan
laporan STATSPACK ). Di PostgreSQL ada analog - pgstatspack, ada
pg_profile dari Andrey Zubkov. Produk terakhir, seperti yang saya mengerti, muncul dan mulai berkembang hanya tahun lalu. Untuk MySQL, saya tidak dapat menemukan alat serupa, tetapi saya bukan ahli MySQL.
Pendekatan itu sendiri tidak terikat pada jenis database tertentu. Jika mungkin untuk memperoleh informasi tentang beban sistem dari beberapa laporan, maka, dengan menggunakan teknik yang akan saya bicarakan sekarang, Anda dapat melakukan pekerjaan pada optimasi proaktif
atas dasar apa pun .
Optimalisasi 5 operasi teratas
Teknologi optimisasi proaktif yang telah kami kembangkan dan gunakan di Pusat Pembayaran RNCO terdiri dari empat tahap.
Tahap 1. Kami menerima laporan AWR untuk periode sebanyak mungkin.Durasi terbesar yang mungkin diperlukan untuk rata-rata beban pada hari yang berbeda dalam seminggu, karena kadang-kadang sangat berbeda. Sebagai contoh, pendaftar selama seminggu terakhir tiba di RBS-Retail Bank pada hari Selasa, mereka mulai diproses, dan sepanjang hari kami memiliki beban yang di atas rata-rata sekitar 2-3 kali. Di hari lain, bebannya lebih sedikit.
Jika Anda tahu bahwa sistem memiliki beberapa spesifik - pada beberapa hari bebannya lebih besar, pada beberapa hari - kurang, maka Anda perlu menerima laporan untuk periode ini secara terpisah dan bekerja dengannya secara terpisah jika kami ingin mengoptimalkan interval waktu tertentu . Jika Anda perlu mengoptimalkan situasi keseluruhan di server, Anda bisa mendapatkan laporan besar untuk bulan itu, dan melihat apa yang sebenarnya dikonsumsi sumber daya server.
Terkadang situasi yang sangat tidak terduga muncul. Misalnya, dalam kasus CFT Bank, permintaan yang memeriksa antrian server laporan mungkin berada di 10 besar. Selain itu, permintaan ini resmi dan tidak menjalankan logika bisnis, tetapi hanya memeriksa apakah ada laporan tentang eksekusi atau tidak.
Tahap 2. Kami melihat bagian:- SQL dipesan dengan Waktu Berlalu - Kueri SQL diurutkan berdasarkan runtime;
- SQL dipesan berdasarkan Waktu CPU - untuk penggunaan CPU;
- SQL dipesan oleh Gets - oleh bacaan logis;
- SQL dipesan oleh Bacaan - untuk bacaan fisik.
Bagian-bagian lain dari SQL yang dipesan oleh dipelajari sesuai kebutuhan.
Tahap 3. Kami menentukan operasi induk dan permintaan bergantung padanya.Laporan AWR memiliki bagian terpisah di mana, tergantung pada versi Oracle, 15 atau lebih permintaan teratas ditampilkan di masing-masing bagian ini. Tapi pertanyaan ini Oracle dalam laporan AWR menunjukkan kekacauan.
Misalnya, ada operasi induk, di dalamnya bisa ada 3 permintaan teratas. Oracle dalam laporan AWR akan menunjukkan operasi induk dan ketiga kueri ini. Oleh karena itu, Anda perlu melakukan analisis daftar ini dan melihat permintaan spesifik operasi apa yang merujuk, mengelompokkannya.
Tahap 4. Kami mengoptimalkan 5 operasi teratas.Setelah pengelompokan seperti itu, output adalah daftar operasi yang paling sulit Anda pilih. Kami dibatasi hingga 5 operasi (bukan permintaan, yaitu operasi). Jika sistem lebih kompleks, maka Anda dapat mengambil lebih banyak.
Kesalahan desain kueri umum
Selama penerapan teknik ini, kami telah menyusun daftar kecil kesalahan desain yang khas. Beberapa kesalahan sangat sederhana sehingga tampaknya tidak mungkin terjadi.
●
Kurangnya indeks → Pemindaian penuhAda kasus-kasus yang sangat insidental, misalnya, dengan tidak adanya indeks pada skema pertempuran. Kami memiliki contoh konkret di mana kueri untuk waktu yang lama bekerja dengan cepat tanpa indeks. Tapi ada pemindaian penuh, dan ketika ukuran meja berangsur-angsur tumbuh, kueri mulai bekerja lebih lambat, dan dari kuartal ke kuartal butuh waktu lebih lama. Pada akhirnya, kami memperhatikannya dan ternyata indeksnya tidak ada.
●
Pilihan besar → Pemindaian penuhKesalahan umum kedua adalah sampel data besar - kasus klasik pemindaian penuh. Semua orang tahu bahwa pemindaian penuh harus digunakan hanya ketika benar-benar dibenarkan. Kadang-kadang ada kasus ketika pemindaian penuh ditemukan di mana dimungkinkan untuk dilakukan tanpanya, misalnya, jika Anda mentransfer kondisi pemfilteran dari kode pl / sql ke kueri.
●
Indeks tidak efektif → SCAN RANGE INDEX PanjangMungkin ini bahkan kesalahan yang paling umum, yang untuk beberapa alasan mereka mengatakan sangat sedikit - yang disebut indeks tidak efisien (pemindaian indeks panjang, lama INDEX RANGE SCAN). Misalnya, kami memiliki tabel untuk pendaftar. Dalam permintaan, kami mencoba menemukan semua pendaftar dari agen ini, dan pada akhirnya menambahkan semacam kondisi penyaringan, misalnya, untuk periode tertentu, atau dengan nomor tertentu, atau klien tertentu. Dalam situasi seperti itu, indeks biasanya dibangun hanya pada bidang "agen" untuk alasan universalitas penggunaan. Hasilnya adalah gambar berikut: pada tahun pertama kerja, misalnya, agen memiliki 100 entri dalam tabel ini, tahun depan sudah 1.000, pada tahun lain mungkin ada 10.000 entri. Beberapa waktu berlalu, catatan ini menjadi 100.000. Jelas, permintaan mulai bekerja lambat, karena dalam permintaan Anda perlu menambahkan tidak hanya agen pengenal itu sendiri, tetapi juga beberapa filter tambahan, dalam hal ini berdasarkan tanggal. Jika tidak, akan muncul bahwa ukuran sampel akan meningkat dari tahun ke tahun, karena jumlah pendaftar untuk agen ini bertambah. Masalah ini harus diatasi di tingkat indeks. Jika ada terlalu banyak data, maka kita harus sudah berpikir ke arah partisi.
●
cabang kode distribusi yang tidak perluIni juga merupakan kasus yang aneh, tetapi, bagaimanapun, itu terjadi. Kami melihat kueri teratas, dan kami melihat beberapa kueri aneh di sana. Kami datang ke pengembang dan berkata: "Kami menemukan beberapa permintaan, mari kita mencari tahu dan melihat apa yang bisa dilakukan tentang itu." Pengembang berpikir, kemudian muncul setelah beberapa saat dan berkata: “Cabang kode ini seharusnya tidak ada di sistem Anda. Anda tidak menggunakan fungsi ini. " Kemudian pengembang menyarankan agar Anda mengaktifkan beberapa pengaturan khusus untuk mengatasi bagian kode ini.
Studi kasus
Sekarang saya ingin mempertimbangkan dua contoh dari praktik nyata kami. Ketika kita berurusan dengan kueri teratas, tentu saja kita pertama-tama memikirkan fakta bahwa harus ada sesuatu yang sangat berat, non-sepele, dengan operasi yang kompleks. Sebenarnya, ini tidak selalu terjadi. Kadang-kadang ada kasus ketika pertanyaan yang sangat sederhana masuk dalam operasi teratas.
Contoh 1
select * from (select o.* from rnko_dep_reestr_in_oper o where o.type_oper = 'proc' and o.ean_rnko in (select l.ean_rnko from rnko_dep_link l where l.s_rnko = :1) order by o.date_oper_bnk desc, o.date_reg desc) where ROWNUM = 1
Dalam contoh ini, kueri hanya terdiri dari dua tabel, dan ini bukan tabel berat - hanya beberapa juta rekaman. Akan terlihat lebih mudah? Namun, permintaan mencapai puncak.
Mari kita coba mencari tahu apa yang salah dengannya.
Di bawah ini adalah gambar dari Enterprise Manager Cloud Control - data statistik dari permintaan ini (Oracle memiliki alat seperti itu). Dapat dilihat bahwa ada beban reguler pada permintaan ini (grafik atas). Angka 1 di samping menunjukkan bahwa rata-rata tidak lebih dari satu sesi berjalan. Diagram hijau menunjukkan bahwa
permintaan hanya menggunakan CPU , yang sangat menarik.

Mari kita coba mencari tahu apa yang sedang terjadi di sini?

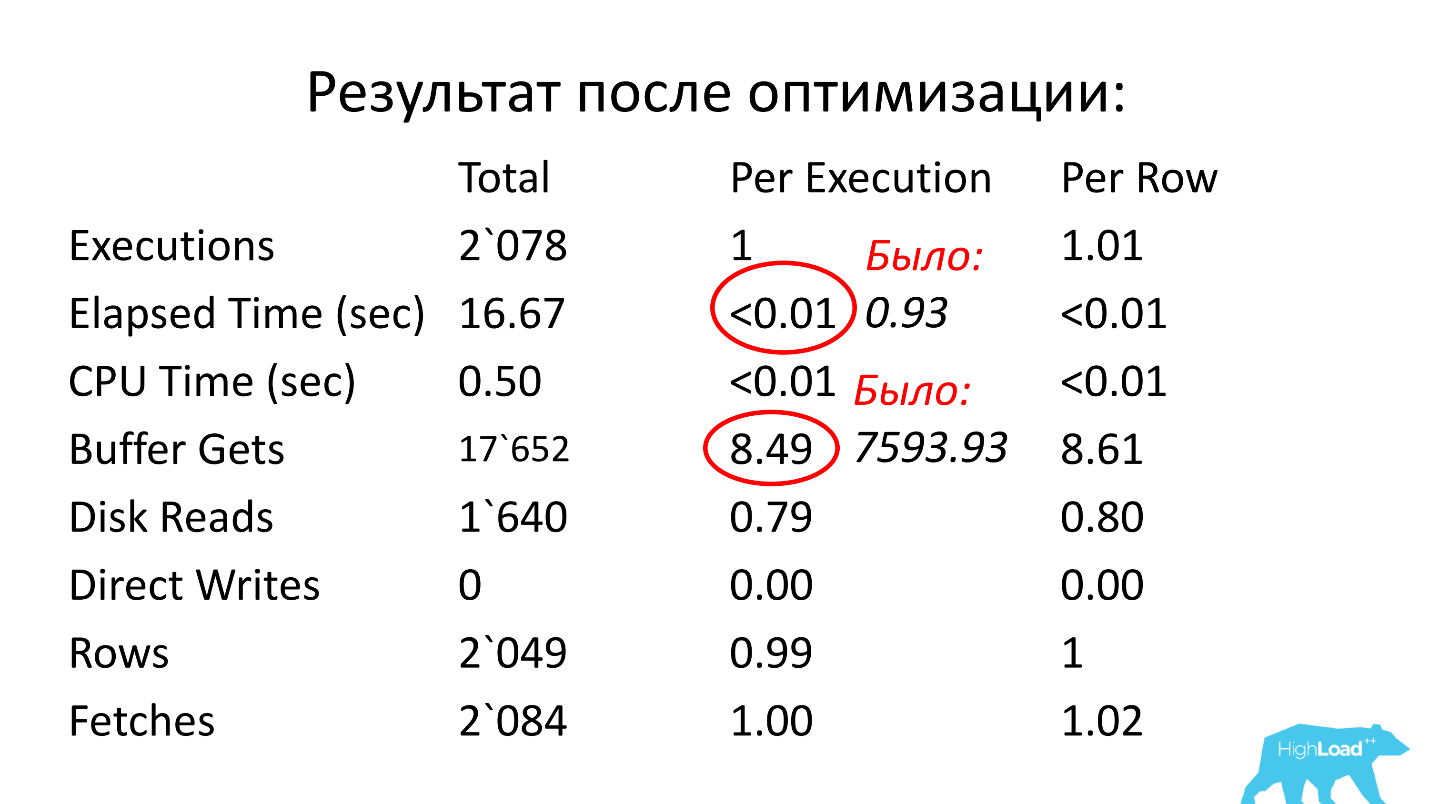
Di atas adalah tabel dengan statistik berdasarkan permintaan. Hampir 700 ribu peluncuran - ini tidak akan mengejutkan siapa pun. Tetapi interval waktu dari Waktu Muatan Pertama pada 15 Desember hingga Waktu Muatan Terakhir pada 22 Desember (lihat gambar sebelumnya) adalah satu minggu. Jika Anda menghitung jumlah awal per detik, ternyata
kueri dieksekusi rata-rata setiap detik .
Kami melihat lebih jauh. Waktu eksekusi permintaan adalah 0,93 detik, mis. kurang dari sedetik, itu bagus. Kami bisa bersukacita - permintaannya tidak berat. Namun demikian, ia mencapai puncak, yang berarti ia menghabiskan banyak sumber daya. Di mana ia menghabiskan banyak sumber daya?
Tabel memiliki garis untuk bacaan logis. Kami melihat bahwa untuk satu peluncuran diperlukan hampir 8 ribu blok (biasanya 1 blok adalah 8 KB). Ternyata permintaan itu, yang bekerja satu detik sekali, memuat sekitar 64 MB data dari memori. Ada yang salah di sini, kita perlu mengerti.
Mari kita lihat rencananya: ada pemindaian penuh. Baiklah, mari kita lanjutkan.
Plan hash value: 634977963
Dalam tabel rnko_dep_reestr_in_oper, hanya ada 5 juta baris dan panjang baris rata-rata adalah 150 byte. Tapi ternyata tidak ada cukup indeks untuk bidang yang terhubung - subquery terhubung ke permintaan melalui bidang ean_rnko, yang tidak ada indeks!
Apalagi, meski dia muncul, nyatanya situasinya tidak akan terlalu bagus. Pemindaian indeks yang panjang (panjang INDEX RANGE SCAN) akan terjadi. ean_rnko adalah pengidentifikasi internal agen. Registrasi agen akan terakumulasi, dan setiap tahun jumlah data yang akan dipilih akan meningkat, dan permintaan akan melambat.
Solusi: buat indeks untuk bidang ean_rnko dan date_reg, minta pengembang membatasi kedalaman pemindaian berdasarkan tanggal dalam permintaan ini. Maka Anda setidaknya dapat sampai batas tertentu menjamin bahwa kinerja permintaan akan tetap kira-kira pada batas yang sama, karena ukuran sampel akan terbatas pada interval waktu yang tetap, dan seluruh tabel tidak perlu dibaca. Ini adalah poin yang sangat penting, lihat apa yang terjadi.
Setelah optimasi, waktu operasi menjadi kurang dari seperseratus detik (itu adalah 0,93), jumlah blok menjadi rata-rata 8,5 - 1000 kali lebih sedikit dari sebelumnya.
Contoh 2
select count(1) from loy$barcodes t where t.id_processing = :b1 and t.id_rec_out is null and not t.barcode is null and t.status = 'u' and not t.id_card is null
Saya memulai ceritanya dengan mengatakan bahwa biasanya sesuatu yang rumit diharapkan di bagian atas permintaan. Di atas adalah contoh kueri "kompleks" yang masuk ke satu tabel (!), Dan itu juga masuk ke kueri teratas :) Ada indeks di bidang ID_PROCESSING!
Ada 3 kondisi IS NULL dalam kueri ini, dan, seperti yang kita ketahui, kondisi tersebut tidak diindeks (Anda tidak dapat menggunakan indeks dalam kasus ini). Plus, hanya ada dua kondisi dari jenis kesetaraan (oleh ID_PROCESSING dan STATUS).
Mungkin, pengembang yang akan melihat permintaan ini, pertama-tama akan menyarankan untuk membuat indeks pada ID_PROCESSING dan STATUS. Tetapi mengingat jumlah data yang akan dipilih (akan ada banyak dari mereka), solusi ini tidak berfungsi.
Namun, permintaan tersebut menghabiskan banyak sumber daya, yang berarti bahwa sesuatu harus dilakukan untuk membuatnya bekerja lebih cepat. Mari kita coba mencari tahu alasannya.

Statistik di atas adalah untuk 1 hari, yang menunjukkan bahwa permintaan diluncurkan setiap 5 menit. Konsumsi sumber daya utama adalah CPU dan pembacaan disk. Di bawah ini pada grafik dengan statistik jumlah permintaan dimulai, dapat dilihat bahwa semuanya teratur - jumlah awal hampir tidak berubah dari waktu ke waktu - situasi yang cukup stabil.

Dan jika Anda melihat lebih jauh, Anda dapat melihat bahwa waktu permintaan terkadang berubah cukup kuat - beberapa kali, yang sudah signifikan.
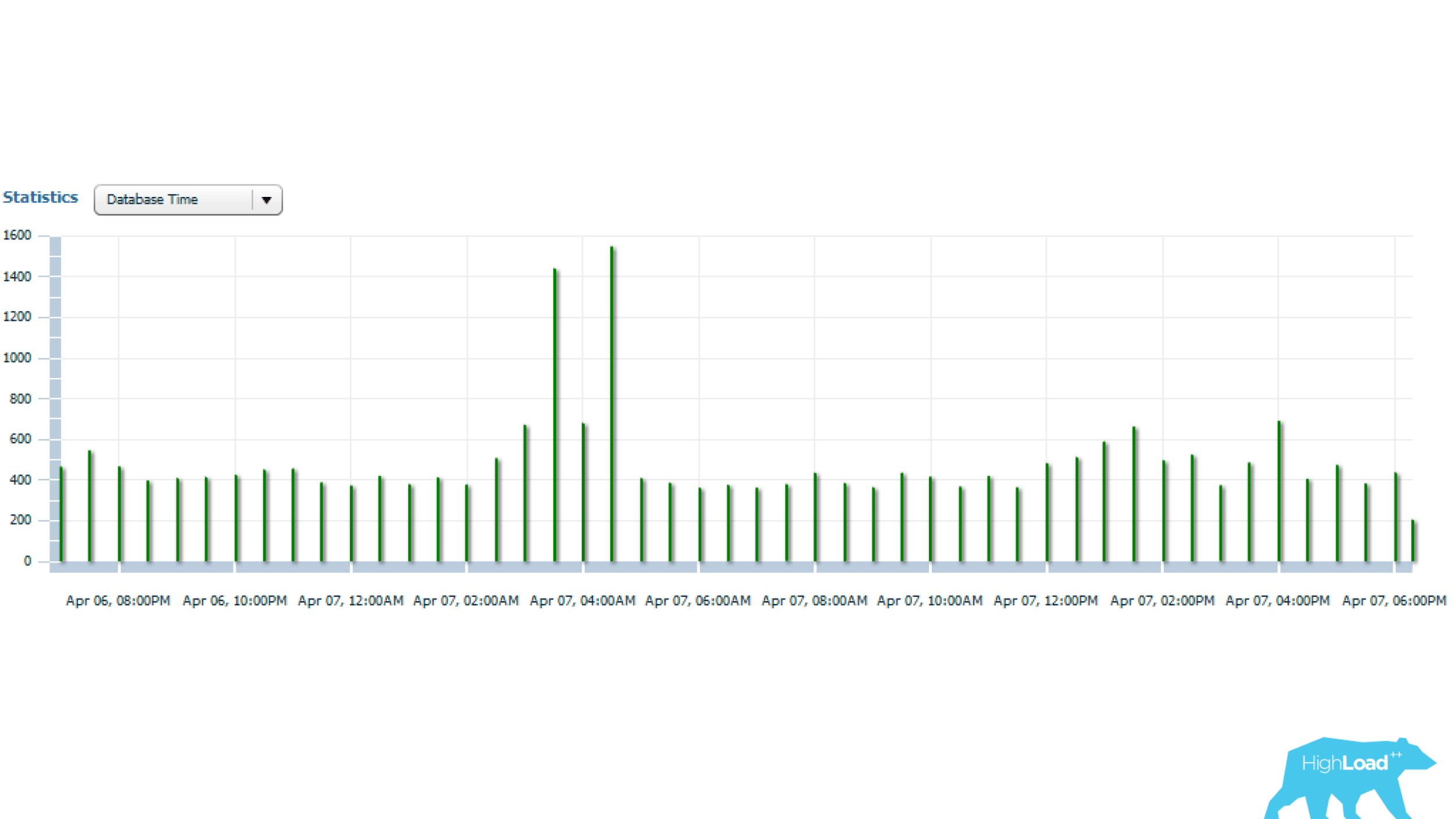
Mari kita cari tahu selanjutnya.
Oracle Enterprise Manager memiliki utilitas Pemantauan SQL. Dengan utilitas ini Anda dapat melihat secara real time konsumsi sumber daya berdasarkan permintaan.

Laporan di atas untuk permintaan yang bermasalah. Pertama-tama, kita harus tertarik pada fakta bahwa INDEX RANGE SCAN (bottom line) di kolom Actual Rows menunjukkan 17 juta baris. Mungkin layak dipertimbangkan.
Jika kita melihat lebih jauh pada rencana implementasi, ternyata setelah item berikutnya dalam rencana, dari 17 juta baris ini, hanya tersisa 1705. Pertanyaannya adalah, mengapa 17 juta dipilih? Sekitar 0,01% tetap dalam sampel akhir, yaitu
, jelas tidak efisien, pekerjaan yang tidak perlu dilakukan . Apalagi pekerjaan ini dilakukan setiap 5 menit. Inilah masalahnya! Oleh karena itu, permintaan ini mengenai kueri teratas.
Mari kita coba selesaikan masalah non-sepele ini. Indeks yang memohon sendiri pada awalnya tidak efisien, jadi Anda harus membuat sesuatu yang rumit dan mengalahkan kondisi IS NULL.
Indeks baru
Kami berkonsultasi dengan pengembang, berpikir, dan sampai pada keputusan ini: kami membuat indeks fungsional di mana ada kolom ID_PROCESSING, yang dengan kondisi kesetaraan dalam permintaan, dan kami memasukkan semua bidang lain sebagai argumen fungsi ini:
create index gc.loy$barcod_unload_i on gc.loy$barcodes (gc.loy_barcodes_ic_unload(id_rec_out, barcode, id_card, status), id_processing); function loy_barcodes_ic_unload( pIdRecOut in loy$barcodes.id_rec_out%type, pBarcode in loy$barcodes.barcode%type, pIdCard in loy$barcodes.id_card%type, pStatus in loy$barcodes.status%type) return varchar2 deterministic is vRes varchar2(1) := ''; begin if pIdRecOut is null and pBarcode is not null and pIdCard is not null and pStatus = 'U' then vRes := pStatus; end if; return vRes; end loy_barcodes_ic_unload;
Fungsi ini adalah tipe deterministik, yaitu, pada set parameter yang sama ia selalu memberikan jawaban yang sama. Kami memastikan bahwa fungsi ini selalu selalu mengembalikan satu nilai - dalam hal ini "U". Ketika semua persyaratan ini terpenuhi, "U" dikeluarkan, saat tidak terpenuhi - NULL. Indeks fungsional semacam itu memungkinkan untuk memfilter data secara efektif.
Penerapan indeks ini menghasilkan hasil sebagai berikut:
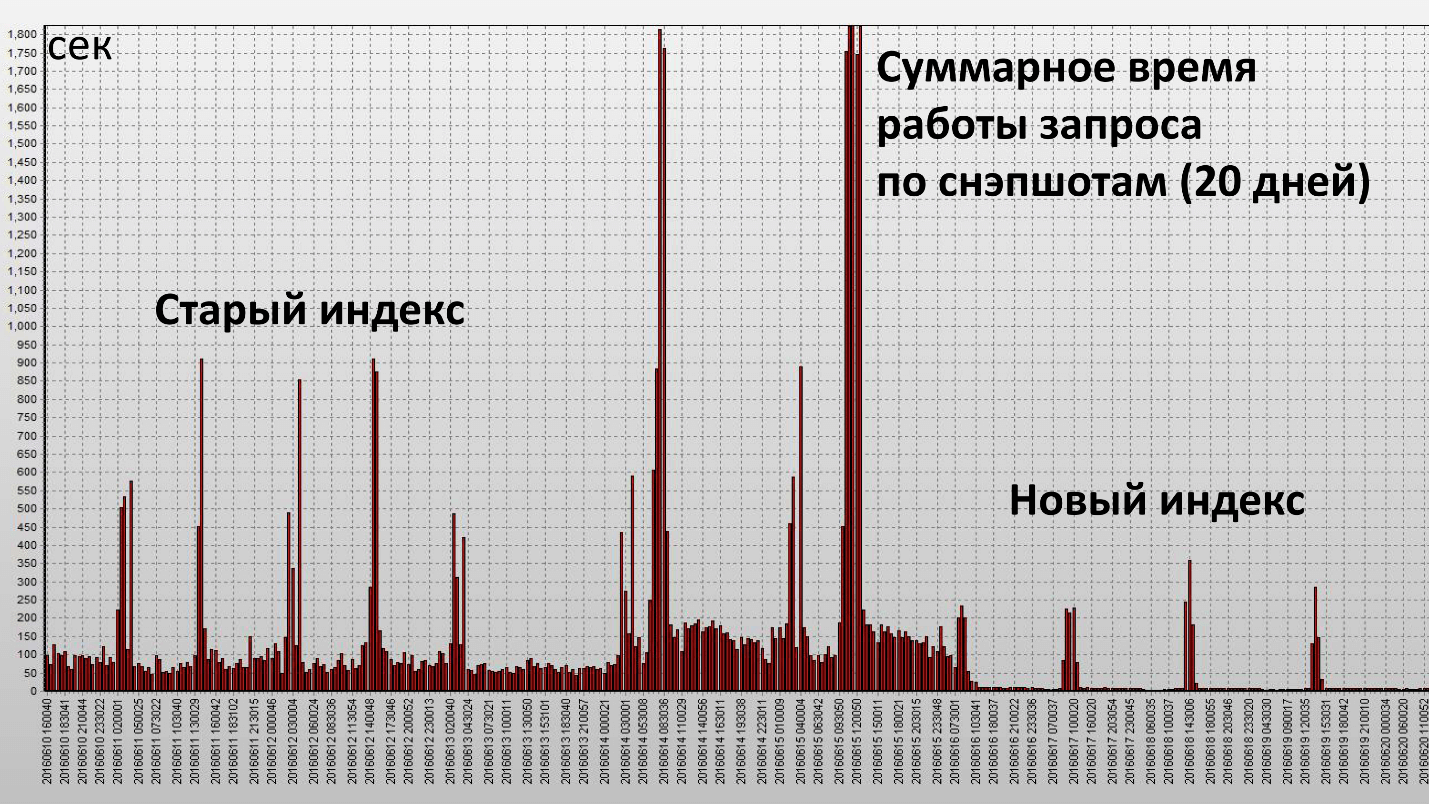
Di sini, satu kolom adalah satu snapshot, mereka dilakukan setiap setengah jam dari database. Kami telah mencapai tujuan kami dan indeks ini sangat efektif. Mari kita lihat karakteristik kuantitatif:
Statistik permintaan rata-rata
|
| Sebelumnya
| SETELAH
|
Waktu yang Berlalu, dtk
| 143.21
| 60.7
|
Waktu CPU, dtk
| 33.23
| 45.38
|
Buffer Mendapat Blok
| 6`288`237.67
| 1`589`836
|
Disk Membaca Blok
| 266`600.33
| 2`680
|
Waktu operasi berkurang 2,5 kali, dan konsumsi sumber daya (Buffer Gets) - sekitar 4. Jumlah blok data yang dibaca dari disk menurun sangat signifikan.
Hasil Optimasi Proaktif
Kami telah menerima:
- mengurangi beban pada basis data;
- meningkatkan stabilitas database;
- pengurangan yang signifikan dalam jumlah insiden kinerja perangkat lunak.
Insiden kinerja menurun 10 kali lipat . Ini adalah jumlah subyektif, sebelum insiden terjadi di kompleks RBS-Retail Bank 1-2 kali sebulan, tetapi sekarang kita secara praktis telah melupakannya.
Ini menimbulkan pertanyaan - bagaimana dengan insiden kinerja perangkat lunak? Kami tidak berurusan dengan mereka secara langsung?
Kembali ke jadwal terakhir. Jika Anda ingat, ada pemindaian penuh, itu diperlukan untuk menyimpan sejumlah besar blok dalam memori. Karena permintaan dieksekusi secara teratur, semua blok ini disimpan dalam cache Oracle. Ternyata jika saat ini beban tinggi terjadi di database, misalnya, seseorang mulai menggunakan memori secara aktif, Anda akan memerlukan cache untuk menyimpan blok data. Dengan demikian, bagian dari data untuk permintaan kami akan ramai, yang berarti bahwa kami harus melakukan pembacaan fisik. Jika Anda melakukan pembacaan fisik, waktu menjalankan kueri akan segera meningkat secara luar biasa.
Pembacaan logis bekerja dengan memori, itu terjadi dengan cepat, dan setiap akses ke disk lambat (jika Anda melihat waktu, milidetik). Jika Anda beruntung, dan ada data ini dalam cache sistem operasi atau dalam cache array, maka itu akan tetap puluhan mikrodetik. Membaca dari cache Oracle jauh lebih cepat.
Ketika kami menyingkirkan pemindaian penuh, kebutuhan untuk menyimpan sejumlah besar blok dalam cache (Buffer Cache) menghilang. Ketika ada kekurangan sumber daya ini, permintaan lebih atau kurang stabil. Tidak ada lagi paku besar seperti itu dengan indeks lama.
Ringkasan Optimasi Proaktif:- Optimalisasi permintaan awal harus dilakukan pada server pengujian, untuk melihat bagaimana kueri dan logika bisnis mereka bekerja, agar tidak melakukan apa pun yang berlebihan. Karya-karya ini tetap ada.
- Tetapi secara berkala, setiap beberapa bulan sekali, masuk akal untuk menghapus laporan tentang muatan penuh dari server, melakukan pencarian untuk pertanyaan dan operasi teratas dalam database dan mengoptimalkannya.
Ada banyak alat untuk mendapatkan statistik dalam database Oracle:- Laporan AWR (DBMS_WORKLOAD_REPOSITORY.awr_report_html);
- Enterprise Manager Cloud Control 12c (Detail SQL);
- Laporan Aktif Perincian SQL (DBMS_PERF.report_sql);
- Pemantauan SQL (tab dalam EMCC);
- Laporan Pemantauan SQL (DBMS_SQLTUNE.report_sql_monitor *).
Beberapa alat ini berfungsi di konsol, yaitu, mereka tidak terikat dengan Enterprise Manager.
Contoh alat Oracle untuk mengumpulkan statistik Bonus: spesialis RNCO "Pusat Pembayaran" dan CFT dipersiapkan dengan baik untuk konferensi di Novosibirsk, membuat beberapa laporan yang berguna, dan juga mengorganisir radio keluar yang nyata. Selama dua hari, para ahli, pembicara, dan penyelenggara berhasil mengunjungi radio CFT. Anda dapat kembali ke musim panas Siberia dengan memasukkan entri, berikut adalah tautan ke blok:
Kubernetes: pro dan kontra ;
Ilmu Data & Pembelajaran Mesin ;
DevOps .
Di HighLoad ++ di Moskow, yang sudah 8 dan 9 November, akan ada hal yang lebih menarik. Program ini mencakup laporan tentang semua aspek pekerjaan pada proyek yang sangat banyak dimuat, kelas master, pertemuan dan acara dari mitra yang akan berbagi saran ahli dan menemukan sesuatu yang mengejutkan. Pastikan untuk menulis tentang yang paling menarik dan beri tahu di buletin , terhubung!