Apa bahasa query GraphQL? Apa keuntungan yang diberikan teknologi ini dan masalah apa yang akan dihadapi pengembang saat menggunakannya? Bagaimana cara menggunakan GraphQL secara efektif? Tentang semua ini di bawah potongan.

Artikel ini didasarkan pada laporan tingkat pengantar oleh
Vladimir Tsukur (
volodymyrtsukur ) dari konferensi
Joker 2017 .
Nama saya Vladimir, saya memimpin pengembangan salah satu departemen di WIX. Lebih dari seratus juta pengguna WIX membuat situs web dari berbagai arah - dari situs kartu nama dan toko ke aplikasi web yang kompleks di mana Anda dapat menulis kode dan logika sewenang-wenang. Sebagai contoh nyata dari sebuah proyek di WIX, saya ingin menunjukkan kepada Anda toko situs yang sukses
unicornadoptions.com , yang menawarkan kesempatan untuk membeli kit untuk menjinakkan unicorn - hadiah yang bagus untuk seorang anak.

Pengunjung ke situs ini dapat memilih kit yang mereka sukai untuk menjinakkan unicorn, katakan pink, lalu lihat apa sebenarnya yang ada dalam kit ini: mainan, sertifikat, lencana. Selanjutnya, pembeli memiliki kesempatan untuk menambahkan barang ke keranjang, melihat isinya dan memesan. Ini adalah contoh sederhana dari situs toko, dan kami memiliki banyak, ratusan ribu situs semacam itu. Semuanya dibangun pada platform yang sama, dengan satu backend, dengan satu set klien yang kami dukung menggunakan API untuk ini. Ini tentang API yang akan dibahas lebih lanjut.
API sederhana dan masalahnya
Mari kita bayangkan API tujuan umum (yaitu, satu API untuk semua toko di atas platform) yang dapat kita buat untuk menyediakan fungsionalitas toko. Mari kita berkonsentrasi hanya pada memperoleh data.
Untuk halaman produk di situs tersebut, nama produk, harga, gambar, deskripsi, informasi tambahan dan banyak lagi harus dikembalikan. Dalam solusi lengkap untuk toko di WIX, ada lebih dari dua lusin bidang data tersebut. Solusi standar untuk tugas semacam itu di atas API HTTP adalah untuk menggambarkan sumber daya
/products/:id , yang mengembalikan data produk berdasarkan permintaan
GET . Berikut ini adalah contoh data respons:
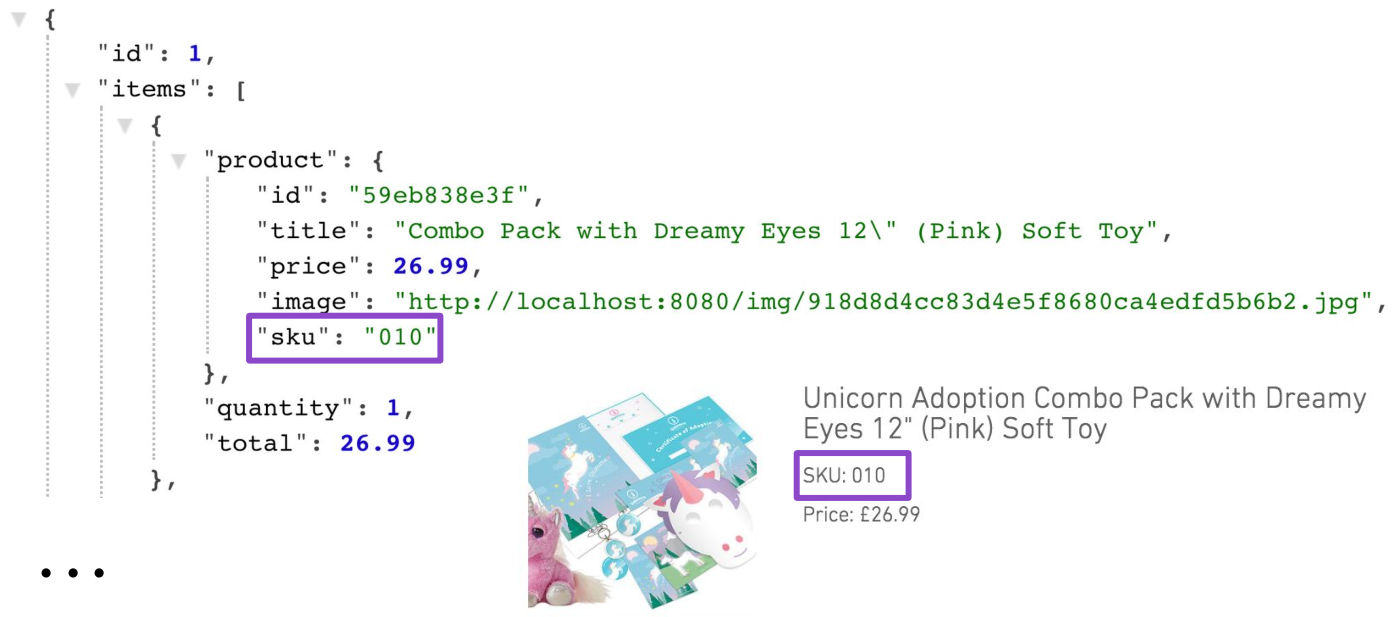
{ "id": "59eb83c0040fa80b29938e3f", "title": "Combo Pack with Dreamy Eyes 12\" (Pink) Soft Toy", "price": 26.99, "description": "Spread Unicorn love amongst your friends and family by purchasing a Unicorn adoption combo pack today. You'll receive your very own fabulous adoption pack and a 12\" Dreamy Eyes (Pink) cuddly toy. It makes the perfect gift for loved ones. Go on, you know you want to, adopt today!", "sku":"010", "images": [ "http://localhost:8080/img/918d8d4cc83d4e5f8680ca4edfd5b6b2.jpg", "http://localhost:8080/img/f343889c0bb94965845e65d3f39f8798.jpg", "http://localhost:8080/img/dd55129473e04f489806db0dc6468dd9.jpg", "http://localhost:8080/img/64eba4524a1f4d5d9f1687a815795643.jpg", "http://localhost:8080/img/5727549e9131440dbb3cd707dce45d0f.jpg", "http://localhost:8080/img/28ae9369ec3c442dbfe6901434ad15af.jpg" ] }

Mari kita lihat halaman katalog produk sekarang. Untuk halaman ini, Anda memerlukan koleksi sumber daya
/ produk . Tetapi hanya dalam menampilkan koleksi produk pada halaman katalog, tidak semua data produk diperlukan, tetapi hanya harga, nama dan gambar utama. Misalnya, deskripsi, informasi tambahan, gambar latar belakang, dll. Tidak menarik bagi kami.

Misalkan, untuk kesederhanaan, kami memutuskan untuk menggunakan model data produk yang sama untuk sumber daya
/products dan
/products/:id . Dalam hal kumpulan produk-produk semacam itu, kemungkinan akan ada beberapa. Skema respons dapat direpresentasikan sebagai berikut:
GET /products [ { title price images description info ... } ]
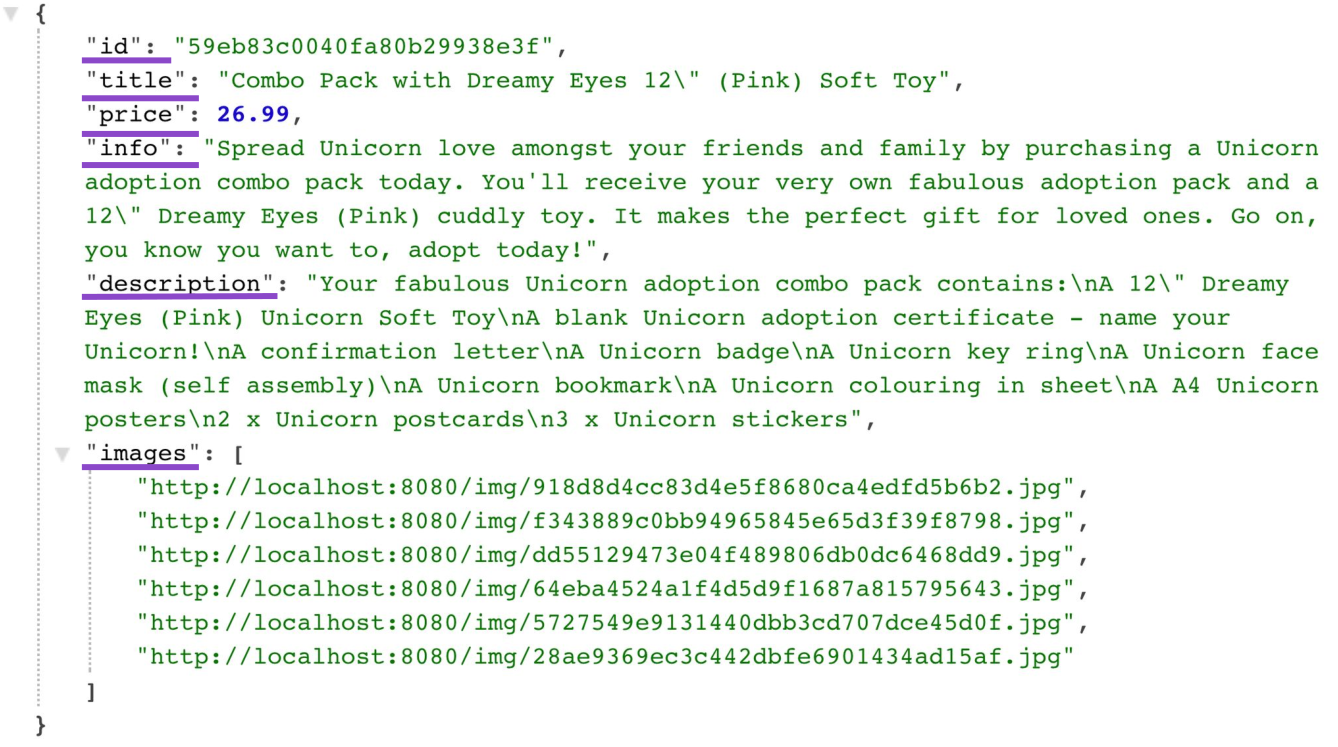
Sekarang mari kita lihat "muatan" dari respons dari server untuk pengumpulan produk. Inilah yang sebenarnya digunakan oleh klien di antara lebih dari dua lusin bidang:
{
"id": "59eb83c0040fa80b29938e3f",
"title": "Combo Pack with Dreamy Eyes 12\" (Pink) Soft Toy",
"price": 26.99,
"info": "Spread Unicorn love amongst your friends and family by purchasing a Unicorn adoption combo pack today. You'll receive your very own fabulous adoption pack and a 12\" Dreamy Eyes (Pink) cuddly toy. It makes the perfect gift for loved ones. Go on, you know you want to, adopt todayl",
" description": "Your fabulous Unicorn adoption combo pack contains:\nA 12\" Dreamy Eyes (Pink) Unicorn Soft Toy\nA blank Unicorn adoption certificate — name your Unicorn!\nA confirmation letter\nA Unicorn badge\nA Unicorn key ring\nA Unicorn face mask (self assembly)\nA Unicorn bookmark\nA Unicorn colouring in sheet\nA A4 Unicorn posters\n2 x Unicorn postcards\n3 x Unicorn stickers",
"images": [
"http://localhost:8080/img/918d8d4cc83d4e5f8680ca4edfd5b6b2.jpg",
"http://localhost:8080/img/f343889c0bb94965845e65d3f39f8798.jpg",
"http://localhost:8080/img/dd55129473604f489806db0dC6468dd9.jpg",
"http://localhost:8080/img/64eba4524a1f4d5d9f1687a815795643.jpg",
"http://localhost:8080/img/5727549e9l3l440dbb3cd707dce45d0f.jpg",
"http://localhost:8080/img/28ae9369ec3c442dbfe6901434ad15af.jpg"
],
...
}Jelas, jika saya ingin menjaga model produk tetap sederhana dengan mengembalikan data yang sama, maka saya berakhir dengan masalah pengambilan berlebihan, dalam beberapa kasus mendapatkan lebih banyak data daripada yang saya butuhkan. Dalam hal ini, ini muncul di halaman katalog produk, tetapi secara umum, layar UI apa pun yang terhubung dengan produk akan memerlukan dari itu berpotensi hanya sebagian (dan tidak semua) data.
Mari kita lihat halaman keranjang sekarang. Dalam keranjang, selain produk itu sendiri, ada juga kuantitasnya (dalam keranjang ini), harga, serta total biaya seluruh pesanan:

Jika kami melanjutkan pendekatan pemodelan sederhana dari HTTP API, maka keranjang dapat diwakili melalui sumber daya
/ gerobak /: id , presentasi yang mengacu pada sumber daya produk yang ditambahkan ke keranjang ini:
{ "id": 1, "items": [ { "product": "/products/59eb83c0040fa80b29938e3f", "quantity": 1, "total": 26.99 }, { "product": "/products/59eb83c0040fa80b29938e40", "quantity": 2, "total": 25.98 }, { "product": "/products/59eb88bd040fa8125aa9c400", "quantity": 1, "total": 26.99 } ], "subTotal": 79.96 }
Sekarang, misalnya, untuk menggambar keranjang dengan tiga produk di ujung depan, Anda perlu membuat empat permintaan: satu untuk memuat keranjang itu sendiri, dan tiga permintaan untuk memuat data produk (nama, harga dan nomor SKU).
Masalah kedua yang kami miliki adalah kurang mengambil. Perbedaan tanggung jawab antara keranjang dan sumber daya produk telah menyebabkan kebutuhan untuk membuat permintaan tambahan. Jelas ada sejumlah kelemahan di sini: karena jumlah permintaan yang lebih besar, kami mendaratkan baterai ponsel lebih cepat dan mendapatkan jawaban lengkap lebih lambat. Dan skalabilitas solusi kami juga menimbulkan pertanyaan.
Tentu saja, solusi ini tidak cocok untuk produksi. Salah satu cara untuk menghilangkan masalah adalah dengan menambahkan dukungan proyeksi untuk keranjang. Salah satu proyeksi seperti itu, selain data keranjang itu sendiri, dapat mengembalikan data produk. Selain itu, proyeksi ini akan sangat spesifik, karena pada halaman keranjang Anda memerlukan nomor inventaris (SKU) produk. Tidak ada tempat lain yang diperlukan SKU di tempat lain.
GET /carts/1?projection=with-products
"Kesesuaian" sumber daya untuk UI tertentu biasanya tidak berakhir, dan kami mulai menghasilkan proyeksi lain: informasi singkat tentang keranjang, proyeksi keranjang untuk web seluler, dan setelah itu proyeksi untuk unicorn.

(Secara umum, di WIX Designer, Anda sebagai pengguna dapat mengkonfigurasi data produk mana yang ingin Anda tampilkan pada halaman produk dan data mana yang ditampilkan di keranjang)
Dan di sini kesulitan menunggu kita: kita membingkai taman dan mencari solusi kompleks. Ada beberapa solusi standar dari sudut pandang API untuk tugas seperti itu, dan mereka biasanya sangat bergantung pada kerangka kerja atau pustaka deskripsi sumber daya HTTP.
Apa yang lebih penting, sekarang semakin sulit untuk bekerja, karena ketika persyaratan di sisi klien berubah, backend harus terus-menerus "mengejar" dan memuaskan mereka.
Sebagai "cherry on the cake," mari kita lihat masalah penting lainnya. Dalam kasus HTTP API sederhana, pengembang server tidak tahu jenis data apa yang digunakan klien. Apakah harga digunakan? Deskripsi? Satu atau semua gambar?
Dengan demikian, beberapa pertanyaan muncul. Bagaimana cara bekerja dengan data yang sudah usang / usang? Bagaimana saya tahu data mana yang tidak lagi digunakan? Bagaimana relatif aman untuk menghapus data dari respons tanpa merusak sebagian besar klien? Tidak ada jawaban untuk pertanyaan ini dengan HTTP API biasa. Terlepas dari kenyataan bahwa kami optimis dan API tampaknya sederhana, situasinya tidak terlihat begitu panas. Rentang masalah API ini tidak unik untuk WIX. Sejumlah besar perusahaan harus berurusan dengan mereka. Sekarang menarik untuk melihat solusi potensial.
GraphQL. Mulai
Pada 2012, dalam proses mengembangkan aplikasi seluler, Facebook menghadapi masalah serupa. Insinyur ingin mencapai jumlah minimum panggilan aplikasi seluler ke server, sementara pada setiap langkah mereka hanya menerima data yang diperlukan dan tidak ada yang lain selain mereka. Hasil dari upaya mereka adalah GraphQL, dipresentasikan pada konferensi React Conf 2015. GraphQL adalah bahasa deskripsi kueri, serta lingkungan runtime untuk kueri ini.

Pertimbangkan pendekatan khas untuk bekerja dengan server GraphQL.
Kami menggambarkan skema
Skema data dalam GraphQL mendefinisikan jenis dan hubungan di antara mereka dan melakukannya dengan cara yang sangat diketik. Misalnya, bayangkan model sederhana jejaring sosial.
User tahu tentang teman
friends . Pengguna tinggal di City, dan kota tahu tentang penghuninya melalui bidang
citizens . Berikut adalah grafik dari model seperti itu di GraphQL:
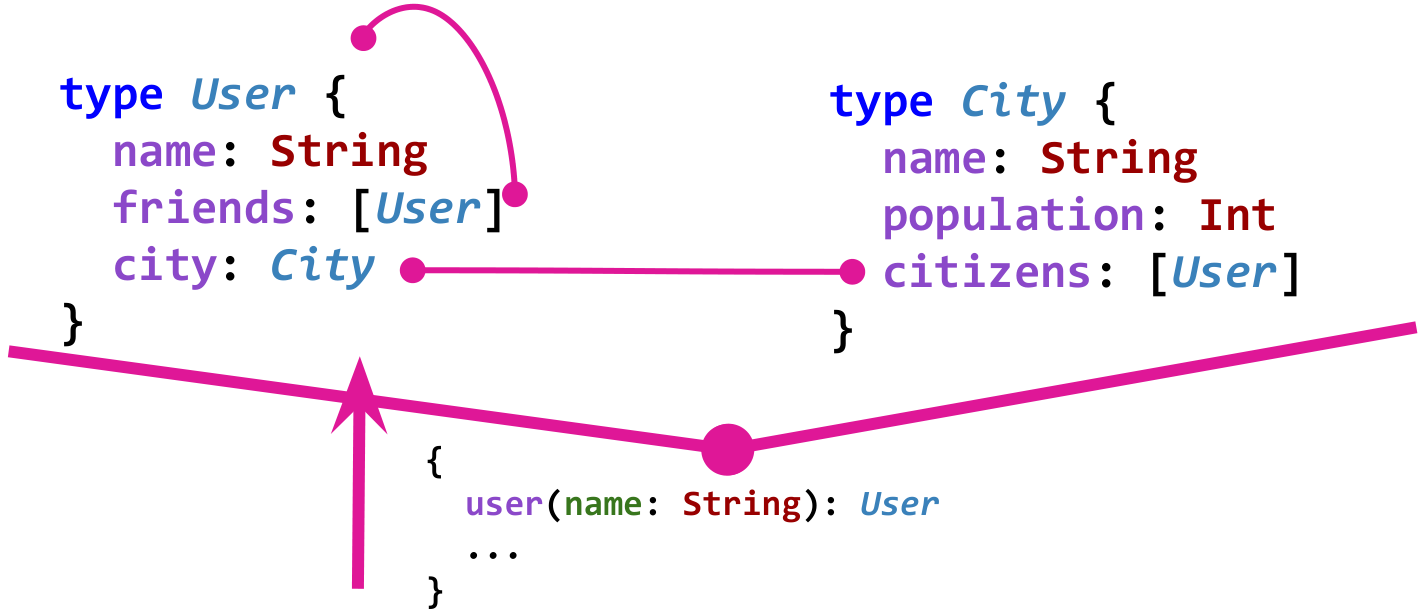
Tentu saja, agar grafik bermanfaat, yang disebut "titik masuk" juga diperlukan. Misalnya, titik masuk seperti itu bisa mendapatkan pengguna dengan nama.
Meminta data
Mari kita lihat apa inti dari bahasa query GraphQL. Mari terjemahkan pertanyaan ini ke dalam bahasa ini:
"Untuk pengguna bernama Vanya Unicorn, saya ingin tahu nama teman-temannya, serta nama dan populasi kota tempat Vanya tinggal" :
{ user(name: "Vanya Unicorn") { friends { name } city { name population } } }
Dan inilah jawabannya dari server GraphQL:
{ "data": { "user": { "friends": [ { "name": "Lena" }, { "name": "Stas" } ] "city": { "name": "Kyiv", "population": 2928087 } } } }
Perhatikan bagaimana formulir permintaan "konsonan" dengan formulir respons. Ada perasaan bahwa bahasa permintaan ini dibuat untuk JSON. Dengan ketikan yang kuat. Dan semua ini dilakukan dalam satu permintaan HTTP POST - tidak perlu melakukan beberapa panggilan ke server.
Mari kita lihat tampilannya dalam praktik. Mari kita buka konsol standar untuk server GraphQL, yang disebut Graph
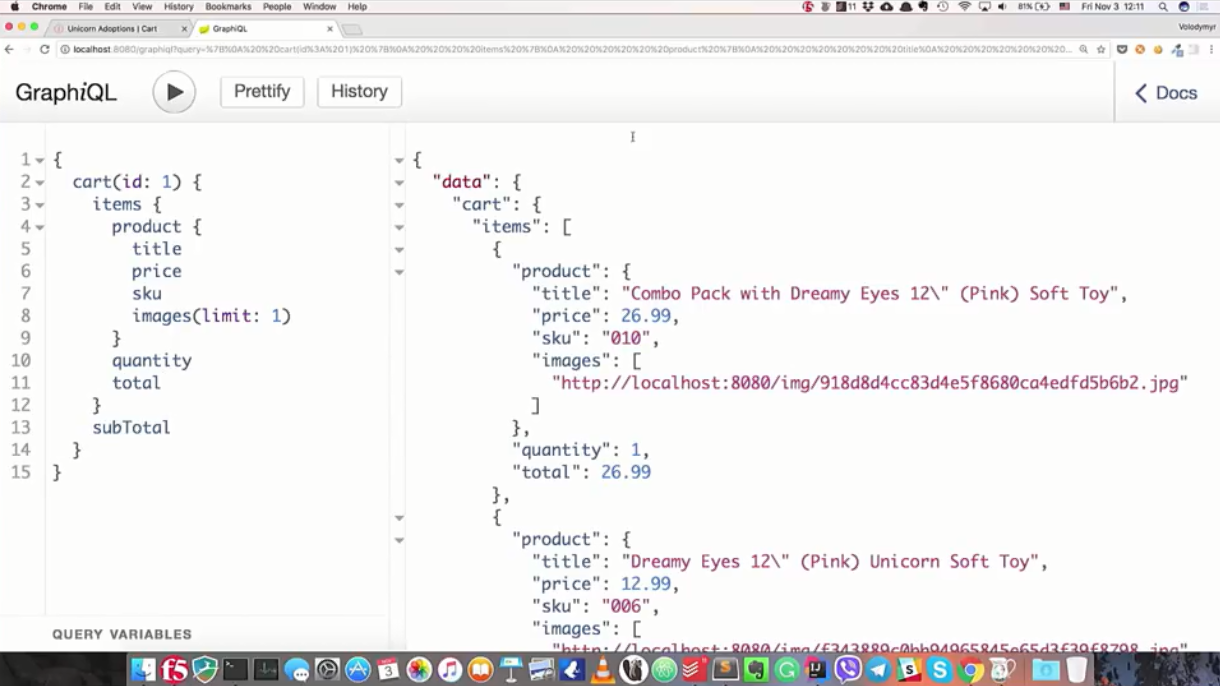
i QL ("graph"). Untuk meminta keranjang, saya akan memenuhi permintaan berikut:
"Saya ingin mendapatkan keranjang dengan pengidentifikasi 1, saya tertarik dengan semua posisi keranjang ini dan informasi produk. Dari informasi, nama, harga, nomor inventaris, dan gambar adalah penting (dan hanya yang pertama). Saya juga tertarik dengan jumlah produk ini, berapa harganya dan total biaya dalam keranjang .
" { cart(id: 1) { items { product { title price sku images(limit: 1) } quantity total } subTotal } }
Setelah berhasil menyelesaikan permintaan, kami mendapatkan apa yang diminta:
Manfaat Utama
- Pengambilan sampel yang fleksibel. Klien dapat mengajukan permintaan sesuai dengan persyaratan spesifiknya.
- Pengambilan sampel yang efektif. Respons hanya mengembalikan data yang diminta.
- Pengembangan lebih cepat. Banyak perubahan pada klien dapat terjadi tanpa perlu mengubah apa pun di sisi server. Misalnya, berdasarkan contoh kami, Anda dapat dengan mudah menampilkan tampilan keranjang yang berbeda untuk web seluler.
- Analitik yang berguna. Karena klien harus menunjukkan bidang secara eksplisit dalam permintaan, server tahu persis bidang mana yang benar-benar diperlukan. Dan ini adalah informasi penting untuk kebijakan depresiasi.
- Bekerja di atas semua sumber data dan transportasi. Adalah penting bahwa GraphQL memungkinkan Anda untuk bekerja di atas semua sumber data dan transportasi apa pun. Dalam hal ini, HTTP bukan obat mujarab, GraphQL juga dapat bekerja melalui WebSocket, dan kami akan menyentuh pada titik ini sedikit kemudian.
Saat ini, server GraphQL dapat dibuat dalam hampir semua bahasa. Versi paling lengkap dari server
GraphQL adalah
GraphQL.js untuk platform Node. Di komunitas Java, implementasi referensi adalah
GraphQL Java .
Buat API GraphQL
Mari kita lihat cara membuat server GraphQL pada contoh kehidupan nyata.
Pertimbangkan versi sederhana dari toko online yang didasarkan pada arsitektur layanan-mikro dengan dua komponen:
- Layanan kereta menyediakan pekerjaan dengan keranjang khusus. Menyimpan data dalam database relasional dan menggunakan SQL untuk mengakses data. Layanan sangat sederhana, tanpa terlalu banyak sihir :)
- Layanan-produk menyediakan akses ke katalog produk, yang darinya, keranjang diisi. Menyediakan API HTTP untuk mengakses data produk.
Kedua layanan diimplementasikan di atas Spring Boot klasik dan sudah mengandung semua logika dasar.
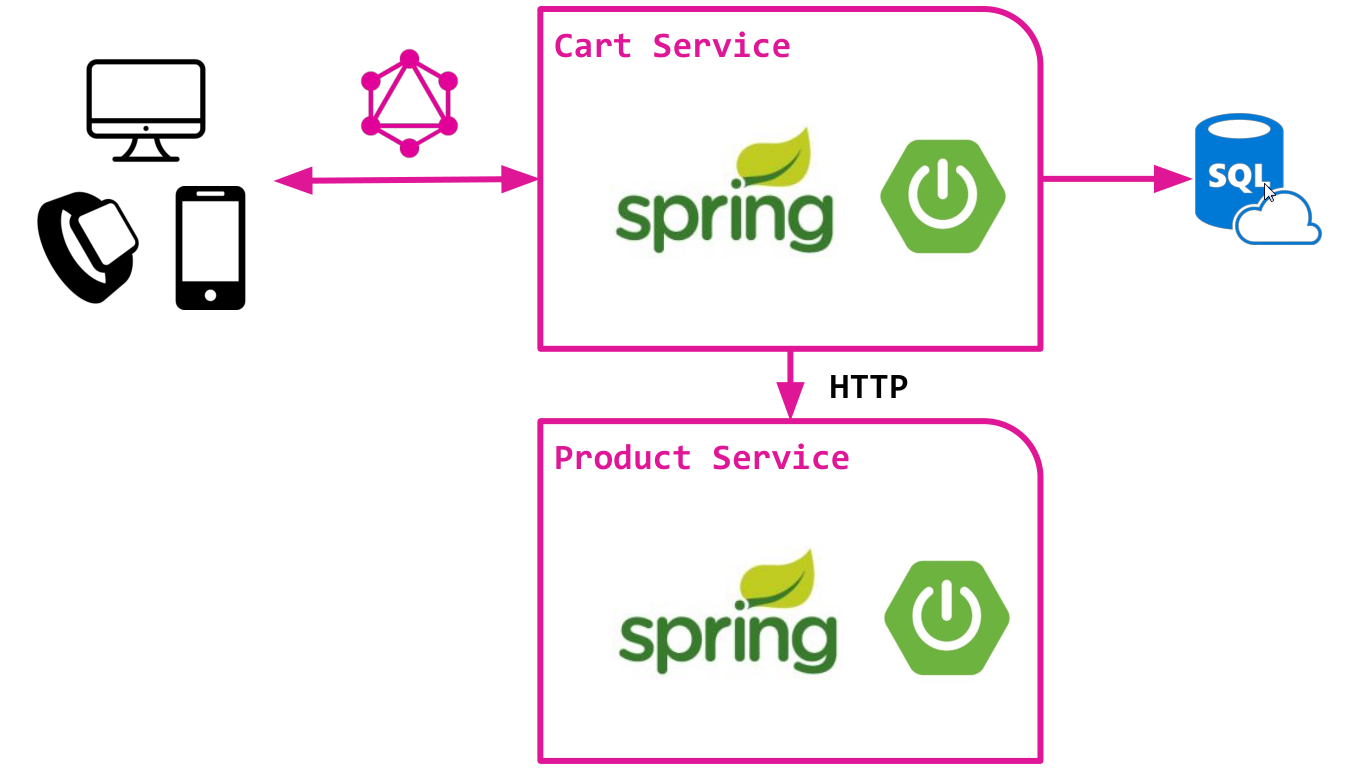
Kami bermaksud membuat GraphQL API di atas layanan Cart. API ini dirancang untuk memberikan akses ke data keranjang dan produk yang ditambahkan padanya.
Versi pertama
Implementasi referensi GraphQL untuk ekosistem Java, yang kami sebutkan sebelumnya - GraphQL Java, akan membantu kami.
Tambahkan beberapa dependensi ke
pom.xml: <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-java</artifactId> <version>9.3</version> </dependency> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-java-tools</artifactId> <version>5.2.4</version> </dependency> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-spring-boot-starter</artifactId> <version>5.0.2</version> </dependency> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphiql-spring-boot-starter</artifactId> <version>5.0.2</version> </dependency>
Selain
graphql-java disebutkan sebelumnya
graphql-java kita akan membutuhkan
graphql-java-tools, alat
graphql-java-tools, serta "permulaan" Boot Spring untuk GraphQL, yang akan sangat menyederhanakan langkah-langkah pertama untuk membuat server GraphQL:
- graphql-spring-boot-starter menyediakan mekanisme untuk menghubungkan GraphQL Java dengan cepat ke Spring Boot;
- graphiql-spring-boot-starter menambahkan konsol web Graph i QL interaktif untuk menjalankan permintaan GraphQL.
Langkah penting berikutnya adalah menentukan skema layanan graphQL, grafik kami. Node dari grafik ini dijelaskan menggunakan
tipe , dan ujungnya menggunakan
bidang . Definisi grafik kosong terlihat seperti ini:
schema { }
Dalam skema ini, seperti yang Anda ingat, ada "titik masuk" atau kueri tingkat atas. Mereka didefinisikan melalui bidang
permintaan dalam skema. Panggil jenis kami untuk
titik masuk
EntryPoints :
schema { query: EntryPoints }
Kami mendefinisikan di dalamnya pencarian keranjang dengan pengidentifikasi sebagai titik masuk pertama:
type EntryPoints { cart(id: Long!): Cart }
Cart tidak lebih dari
bidang dalam istilah GraphQL.
id adalah parameter bidang ini dengan tipe skalar
Long . Tanda seru
! setelah menentukan jenisnya berarti parameter tersebut diperlukan.
Saatnya mengidentifikasi dan mengetik
Cart :
type Cart { id: Long! items: [CartItem!]! subTotal: BigDecimal! }
Selain
id standar, keranjang mencakup elemen item dan jumlah untuk semua produk
subTotal . Perhatikan bahwa
item didefinisikan sebagai daftar, seperti yang ditunjukkan oleh tanda kurung siku
[] . Elemen daftar ini adalah tipe
CartItem . Kehadiran tanda seru setelah nama tipe bidang
! menunjukkan bahwa bidang tersebut wajib diisi. Ini berarti bahwa server setuju untuk mengembalikan nilai yang tidak kosong untuk bidang ini, jika diminta.
Tetap melihat definisi tipe
CartItem , yang mencakup tautan ke produk (
productId ), berapa kali ditambahkan ke keranjang (
quantity ) dan jumlah produk, dihitung pada jumlah (
total ):
type CartItem { productId: String! quantity: Int! total: BigDecimal! }
Semuanya sederhana di sini - semua bidang jenis skalar adalah wajib.
Skema ini tidak dipilih secara kebetulan. Layanan Cart telah mendefinisikan keranjang Cart dan elemen
CartItem dengan nama dan tipe bidang yang persis sama seperti dalam skema GraphQL. Model kereta menggunakan perpustakaan Lombok untuk mendapatkan getter / setter, konstruktor, dan metode lainnya. JPA digunakan untuk ketekunan dalam database.
Kelas
Cart :
import lombok.Data; import javax.persistence.*; import java.math.BigDecimal; import java.util.ArrayList; import java.util.List; @Entity @Data public class Cart { @Id @GeneratedValue private Long id; @ElementCollection(fetch = FetchType.EAGER) private List<CartItem> items = new ArrayList<>(); public BigDecimal getSubTotal() { return getItems().stream() .map(Item::getTotal) .reduce(BigDecimal.ZERO, BigDecimal::add); } }
Kelas
CartItem :
import lombok.AllArgsConstructor; import lombok.Data; import javax.persistence.Column; import javax.persistence.Embeddable; import java.math.BigDecimal; @Embeddable @Data @AllArgsConstructor public class CartItem { @Column(nullable = false) private String productId; @Column(nullable = false) private int quantity; @Column(nullable = false) private BigDecimal total; }
Jadi, elemen keranjang (
Cart ) dan elemen keranjang (
CartItem ) dijelaskan baik dalam diagram GraphQL dan dalam kode, dan “kompatibel” satu sama lain sesuai dengan set bidang dan jenisnya. Tetapi ini masih belum cukup untuk layanan kami untuk bekerja.
Kita perlu mengklarifikasi dengan tepat bagaimana titik masuk "
cart(id: Long!): Cart " akan berfungsi. Untuk melakukan ini, buat konfigurasi Java yang sangat sederhana untuk Spring dengan kacang tipe GraphQLQueryResolver. GraphQLQueryResolver hanya menjelaskan "titik masuk" dalam skema. Kami mendefinisikan metode dengan nama yang identik dengan bidang di titik entri (
cart ), membuatnya kompatibel dengan jenis parameter, dan menggunakan
cartService untuk menemukan keranjang yang sama dengan pengidentifikasi:
@Bean public GraphQLQueryResolver queryResolver() { return new GraphQLQueryResolver () { public Cart cart(Long id) { return cartService.findCart(id); } } }
Perubahan ini cukup bagi kita untuk mendapatkan aplikasi yang berfungsi. Setelah memulai ulang layanan Cart di konsol GraphiQL, kueri berikut akan mulai dijalankan dengan sukses:
{ cart(id: 1) { items { productId quantity total } subTotal } }
Catatan
- Kami menggunakan jenis skalar
Long dan String sebagai pengidentifikasi unik untuk keranjang dan produk. GraphQL memiliki tipe khusus untuk tujuan tersebut - ID . Semantik, ini adalah pilihan yang lebih baik untuk API nyata. Nilai ID tipe dapat digunakan sebagai kunci untuk caching.
- Pada tahap ini dalam pengembangan aplikasi kami, model domain internal dan eksternal benar-benar identik. Kita berbicara tentang kelas
Cart dan CartItem dan penggunaan langsungnya dalam resolvers GraphQL. Dalam aplikasi tempur, model ini direkomendasikan untuk dipisahkan. Untuk resolvers GraphQL, model yang terpisah dari area subjek internal harus ada.
Membuat API bermanfaat
Jadi kami mendapat hasil pertama, dan ini luar biasa. Tapi sekarang API kami terlalu primitif. Misalnya, sejauh ini tidak ada cara untuk meminta data yang berguna pada suatu produk, seperti nama, harga, artikel, gambar, dan sebagainya. Sebaliknya, hanya ada
productId . Mari kita buat API sangat berguna dan menambahkan dukungan penuh untuk konsep produk. Berikut ini definisi dari diagram tersebut:
type Product { id: String! title: String! price: BigDecimal! description: String sku: String! images: [String!]! }
Tambahkan bidang yang diperlukan ke
CartItem , dan
productId bidang productId sudah usang:
type Item { quantity: Int! product: Product! productId: String! @deprecated(reason: "don't use it!") total: BigDecimal! }
Kami menemukan skema. Dan sekarang saatnya untuk menggambarkan bagaimana pemilihan bidang
product akan bekerja. Kami sebelumnya mengandalkan getter di kelas
Cart dan
CartItem , yang memungkinkan GraphQL Java untuk secara otomatis mengikat nilai. Tetapi di sini harus diingat bahwa hanya properti
product di kelas
CartItem tidak:
@Embeddable @Data @AllArgsConstructor public class CartItem { @Column(nullable = false) private String productId; @Column(nullable = false) private int quantity; @Column(nullable = false) private BigDecimal total; }
Kami punya pilihan:
- Tambahkan properti produk ke CartItem dan “ajarkan” bagaimana cara menerima data produk;
- Tentukan cara mendapatkan produk tanpa mengubah kelas CartItem .
Cara kedua lebih disukai, karena model deskripsi domain internal (kelas
CartItem ) dalam kasus ini tidak akan dibahas dengan rincian implementasi API Grafik
i QL.
Untuk mencapai tujuan ini, antarmuka marker GraphQLResolver akan membantu. Dengan menerapkannya, Anda bisa menentukan (atau menimpa) cara mendapatkan nilai bidang untuk tipe
T Ini adalah tampilan kacang yang sesuai di konfigurasi Spring:
@Bean public GraphQLResolver<CartItem> cartItemResolver() { return new GraphQLResolver<CartItem>() { public Product product(CartItem item) { return http.getForObject("http://localhost:9090/products/{id}", Product.class, item.getProductId()); } }; }
Nama metode
product tidak dipilih secara kebetulan. GraphQL Java sedang mencari metode pengunduh data berdasarkan nama bidang, dan kami hanya perlu mendefinisikan loader untuk bidang
product ! Objek bertipe
CartItem dilewatkan sebagai parameter menentukan konteks di mana produk dipilih. Berikutnya adalah masalah teknologi. Menggunakan klien
http seperti
RestTemplate kami membuat permintaan GET ke layanan Produk dan mengonversi hasilnya menjadi
Product , yang terlihat seperti ini:
@Data public class Product { private String id; private String title; private BigDecimal price; private String description; private String sku; private List<String> images; }
Perubahan ini harus cukup untuk menerapkan sampel yang lebih menarik, yang mencakup hubungan sebenarnya antara keranjang dan produk yang ditambahkan padanya.
Setelah memulai ulang aplikasi, Anda dapat mencoba kueri baru di konsol Graph
i QL.
{ cart(id: 1) { items { product { title price sku images } quantity total } subTotal } }
Dan inilah hasil dari eksekusi query:

Meskipun
productId ditandai sebagai
@deprecated , kueri yang mengindikasikan bidang ini akan terus berfungsi. Tetapi konsol Graph
i QL tidak akan menawarkan pelengkapan otomatis untuk bidang tersebut dan akan menyoroti penggunaannya dengan cara khusus:

Saatnya untuk menunjukkan Document Explorer, bagian dari konsol Graph
i QL, yang dibangun berdasarkan skema GraphQL dan menampilkan informasi pada semua jenis yang ditentukan. Inilah yang tampak seperti Document Explorer untuk tipe
CartItem :

Namun kembali ke contoh. Untuk mencapai fungsi yang sama seperti pada demo pertama, masih belum ada batasan yang cukup untuk jumlah gambar yang dikembalikan. Memang, untuk keranjang, misalnya, Anda hanya perlu satu gambar untuk setiap produk:
images(limit: 1)
Untuk melakukan ini, ubah skema dan tambahkan parameter baru untuk bidang
gambar ke tipe
Produk :
type Product { id: ID! title: String! price: BigDecimal! description: String sku: String! images(limit: Int = 0): [String!]! }
Dan dalam kode aplikasi kita akan menggunakannya lagi GraphQLResolver, hanya kali ini dengan mengetik Product: @Bean public GraphQLResolver<Product> productResolver() { return new GraphQLResolver<Product>() { public List<String> images(Product product, int limit) { List<String> images = product.getImages(); int normalizedLimit = limit > 0 ? limit : images.size(); return images.subList(0, Math.min(normalizedLimit, images.size())); } }; }
Sekali lagi saya menarik perhatian Anda bahwa nama metode ini tidak disengaja: itu bertepatan dengan nama bidang images. Objek konteks Productmemberikan akses ke gambar, dan limitmerupakan parameter dari bidang itu sendiri.Jika klien tidak menentukan apa pun sebagai nilai untuk limit, maka layanan kami akan mengembalikan semua gambar produk. Jika klien menentukan nilai tertentu, maka layanan akan mengembalikan persis sama (tetapi tidak lebih dari yang ada dalam produk).Kami mengkompilasi proyek dan menunggu hingga server dimulai ulang. Mulai ulang sirkuit di konsol dan menjalankan permintaan, kami melihat bahwa permintaan lengkap benar-benar berfungsi. { cart(id: 1) { items { product { title price sku images(limit: 1) } quantity total } subTotal } }
Setuju, semua ini sangat keren. Dalam waktu singkat, kami tidak hanya mengetahui apa itu GraphQL, tetapi juga mentransfer sistem layanan mikro sederhana untuk mendukung API semacam itu. Dan tidak masalah bagi kami dari mana data berasal: SQL dan HTTP API cocok di bawah satu atap.Pendekatan Code-First dan GraphQL SPQR
Anda mungkin telah memperhatikan bahwa selama proses pengembangan ada beberapa ketidaknyamanan, yaitu kebutuhan untuk terus menjaga skema GraphQL dan kode dalam sinkronisasi. Jenis perubahan selalu harus dilakukan di dua tempat. Dalam banyak kasus, lebih mudah menggunakan pendekatan kode-pertama. Esensinya adalah bahwa skema untuk GraphQL secara otomatis dihasilkan dari kode. Dalam hal ini, Anda tidak perlu merawat sirkuit secara terpisah. Sekarang saya akan menunjukkan tampilannya.Hanya fitur dasar GraphQL Java yang tidak cukup bagi kami, kami juga akan membutuhkan pustaka GraphQL SPQR. Kabar baiknya adalah bahwa GraphQL SPQR adalah add-on untuk GraphQL Java, dan bukan alternatif implementasi server GraphQL di Jawa.Tambahkan ketergantungan yang diinginkan ke pom.xml: <dependency> <groupId>io.leangen.graphql</groupId> <artifactId>spqr</artifactId> <version>0.9.8</version> </dependency>
Berikut adalah kode yang mengimplementasikan fungsi berbasis GraphQL SPQR yang sama untuk keranjang: @Component public class CartGraph { private final CartService cartService; @Autowired public CartGraph(CartService cartService) { this.cartService = cartService; } @GraphQLQuery(name = "cart") public Cart cart(@GraphQLArgument(name = "id") Long id) { return cartService.findCart(id); } }
Dan untuk produk: @Component public class ProductGraph { private final RestTemplate http; @Autowired public ProductGraph(RestTemplate http) { this.http = http; } @GraphQLQuery(name = "product") public Product product(@GraphQLContext CartItem cartItem) { return http.getForObject( "http://localhost:9090/products/{id}", Product.class, cartItem.getProductId() ); } @GraphQLQuery(name = "images") public List<String> images(@GraphQLContext Product product, @GraphQLArgument(name = "limit", defaultValue = "0") int limit) { List<String> images = product.getImages(); int normalizedLimit = limit > 0 ? limit : images.size(); return images.subList(0, Math.min(normalizedLimit, images.size())); } }
Anotasi @GraphQLQuery digunakan untuk menandai metode pemuat bidang. Anotasi @GraphQLContextmenentukan jenis seleksi untuk bidang tersebut. Dan anotasi @GraphQLArgumentdengan jelas menandai parameter argumen. Semua ini adalah bagian dari satu mekanisme yang membantu GraphQL SPQR untuk menghasilkan skema secara otomatis. Sekarang, jika Anda menghapus skema dan konfigurasi Java yang lama, restart layanan Cart menggunakan chip baru dari GraphQL SPQR, Anda dapat memastikan bahwa semuanya berfungsi secara fungsional dengan cara yang sama seperti sebelumnya.Kami memecahkan masalah N +1
Ini adalah waktu untuk melihat b pada lshih rinci bagaimana pelaksanaan seluruh permintaan "di bawah tenda". Kami dengan cepat membuat GraphQL API, tetapi apakah ini bekerja secara efisien?Pertimbangkan contoh berikut: Mendapatkan keranjang
Mendapatkan keranjang cartterjadi dalam satu query SQL ke database. Data aktif itemsdan subtotaldikembalikan ke sana, karena elemen keranjang dimuat dengan seluruh koleksi, berdasarkan strategi JPA yang ingin diambil: @Data public class Cart { @ElementCollection(fetch = FetchType.EAGER) private List<Item> items = new ArrayList<>(); ... }
 Ketika datang untuk mengunduh data pada produk, maka permintaan untuk layanan Produk akan dieksekusi persis seperti dalam keranjang produk ini. Jika ada tiga produk berbeda dalam keranjang, maka kami akan menerima tiga permintaan ke HTTP API dari layanan produk, dan jika ada sepuluh dari mereka, maka layanan yang sama harus menjawab sepuluh permintaan tersebut.
Ketika datang untuk mengunduh data pada produk, maka permintaan untuk layanan Produk akan dieksekusi persis seperti dalam keranjang produk ini. Jika ada tiga produk berbeda dalam keranjang, maka kami akan menerima tiga permintaan ke HTTP API dari layanan produk, dan jika ada sepuluh dari mereka, maka layanan yang sama harus menjawab sepuluh permintaan tersebut. Berikut adalah komunikasi antara layanan Cart dan layanan Produk di Charles Proxy:
Berikut adalah komunikasi antara layanan Cart dan layanan Produk di Charles Proxy: Karenanya, kami kembali ke masalah klasik N +1. Persisnya mereka berusaha keras untuk melarikan diri di awal laporan. Tidak diragukan lagi, kami memiliki kemajuan, karena tepat satu permintaan dijalankan antara klien akhir dan sistem kami. Namun dalam ekosistem server, kinerja jelas perlu ditingkatkan.Saya ingin menyelesaikan masalah ini dengan mendapatkan semua produk yang tepat dalam satu permintaan. Untungnya, layanan Produk sudah mendukung fitur ini melalui parameter
Karenanya, kami kembali ke masalah klasik N +1. Persisnya mereka berusaha keras untuk melarikan diri di awal laporan. Tidak diragukan lagi, kami memiliki kemajuan, karena tepat satu permintaan dijalankan antara klien akhir dan sistem kami. Namun dalam ekosistem server, kinerja jelas perlu ditingkatkan.Saya ingin menyelesaikan masalah ini dengan mendapatkan semua produk yang tepat dalam satu permintaan. Untungnya, layanan Produk sudah mendukung fitur ini melalui parameter idsdi sumber pengumpulan: GET /products?ids=:id1,:id2,...,:idn
Mari kita lihat bagaimana Anda dapat mengubah kode metode sampel untuk bidang produk . Versi Sebelumnya: @GraphQLQuery(name = "product") public Product product(@GraphQLContext CartItem cartItem) { return http.getForObject( "http://localhost:9090/products/{id}", Product.class, cartItem.getProductId() ); }
Ganti dengan yang lebih efektif: @GraphQLQuery(name = "product") @Batched public List<Product> products(@GraphQLContext List<Item> items) { String productIds = items.stream() .map(Item::getProductId) .collect(Collectors.joining(",")); return http.getForObject( "http://localhost:9090/products?ids={ids}", Products.class, productIds ).getProducts(); }
Kami melakukan tiga hal:- menandai metode bootloader dengan anotasi @Batched , menjelaskan kepada GraphQL SPQR bahwa pemuatan harus terjadi dengan batch;
- mengubah tipe dan parameter konteks kembali ke daftar, karena bekerja dengan bets mengasumsikan bahwa beberapa objek diterima dan dikembalikan;
- mengubah tubuh metode, menerapkan pemilihan semua produk yang diperlukan pada suatu waktu.
Perubahan ini cukup untuk menyelesaikan masalah N + 1 kami. Jendela aplikasi Proxy Charles sekarang menunjukkan satu permintaan ke layanan Produk, yang mengembalikan tiga produk sekaligus:
Sampel Lapangan yang Efektif
Kami memecahkan masalah utama, tetapi Anda dapat memilih lebih cepat! Sekarang layanan Produk mengembalikan semua data, terlepas dari apa yang dibutuhkan pelanggan akhir. Kami dapat meningkatkan kueri dan hanya mengembalikan bidang yang diminta. Misalnya, jika pelanggan akhir tidak meminta gambar, mengapa kita perlu mentransfernya ke layanan Keranjang?Sangat bagus bahwa API HTTP dari layanan Produk sudah mendukung fitur ini melalui parameter sertakan untuk sumber daya pengumpulan yang sama: GET /products?ids=...?include=:field1,:field2,...,:fieldN
Untuk metode bootloader, tambahkan parameter tipe Set dengan anotasi @GraphQLEnvironment. GraphQL SPQR memahami bahwa kode dalam hal ini "meminta" daftar nama bidang yang diminta untuk produk, dan secara otomatis mengisinya: @GraphQLQuery(name = "product") @Batched public List<Product> products(@GraphQLContext List<Item> items, @GraphQLEnvironment Set<String> fields) { String productIds = items.stream() .map(Item::getProductId) .collect(Collectors.joining(",")); return http.getForObject( "http://localhost:9090/products?ids={ids}&include={fields}", Products.class, productIds, String.join(",", fields) ).getProducts(); }
Sekarang sampel kami benar-benar efektif, tanpa masalah N + 1 dan hanya menggunakan data yang diperlukan:
Pertanyaan "Berat"
Bayangkan bekerja dengan grafik pengguna di jejaring sosial klasik seperti Facebook. Jika sistem seperti itu menyediakan GraphQL API, maka tidak ada yang mencegah klien mengirim permintaan dengan sifat berikut: { user(name: "Vova Unicorn") { friends { name friends { name friends { name friends { name ... } } } } } }
Pada tingkat bersarang 5-6, implementasi penuh dari permintaan semacam itu akan mengarah pada pemilihan semua pengguna di dunia. Server tentu tidak akan mampu mengatasi tugas seperti itu dalam sekali duduk dan kemungkinan besar itu hanya "jatuh".Ada sejumlah langkah yang harus diambil untuk melindungi diri Anda dari situasi seperti itu:- Batasi kedalaman permintaan. Dengan kata lain, pelanggan seharusnya tidak diizinkan untuk meminta data penyarangan sewenang-wenang.
- Batasi kompleksitas permintaan. Dengan menetapkan bobot untuk setiap bidang dan menghitung jumlah bobot semua bidang dalam permintaan, Anda dapat menerima atau menolak permintaan tersebut di server.
Misalnya, pertimbangkan permintaan berikut: { cart(id: 1) { items { product { title } quantity } subTotal } }
Jelas, kedalaman permintaan seperti itu adalah 4, karena jalur terpanjang ada di dalamnya cart -> items -> product -> title.Jika kita menganggap bahwa bobot masing-masing bidang adalah 1, maka dengan memperhitungkan 7 bidang dalam kueri, kompleksitasnya juga 7.Dalam GraphQL Java, superposisi cek dicapai dengan menunjukkan instrumentasi tambahan saat membuat objek GraphQL: GraphQL.newGraphQL(schema) .instrumentation(new ChainedInstrumentation(Arrays.asList( new MaxQueryComplexityInstrumentation(20), new MaxQueryDepthInstrumentation(3) ))) .build();
Instrumentasi MaxQueryDepthInstrumentationmemeriksa kedalaman permintaan dan tidak memungkinkan permintaan terlalu "dalam" untuk diluncurkan (dalam hal ini, dengan kedalaman lebih dari 3).Instrumentasi MaxQueryComplexityInstrumentationsebelum mengeksekusi kueri menghitung dan memeriksa kerumitannya. Jika nomor ini melebihi nilai yang ditentukan (20), maka permintaan seperti itu ditolak. Anda dapat mendefinisikan ulang bobot untuk setiap bidang, karena beberapa di antaranya jelas "lebih keras" daripada yang lain. Misalnya, bidang produk dapat diberikan kompleksitas 10 melalui anotasi yang @GraphQLComplexity,didukung di GraphQL SPQR: @GraphQLQuery(name = "product") @GraphQLComplexity("10") public List<Product> products(...)
Berikut ini adalah contoh pemeriksaan kedalaman ketika jelas melebihi nilai yang ditentukan: Omong-omong, mekanisme instrumentasi tidak terbatas pada memaksakan pembatasan. Itu juga dapat digunakan untuk tujuan lain, seperti logging atau tracing.Kami memeriksa langkah-langkah "perlindungan" khusus untuk GraphQL. Namun, ada sejumlah trik yang perlu diperhatikan terlepas dari jenis API:
Omong-omong, mekanisme instrumentasi tidak terbatas pada memaksakan pembatasan. Itu juga dapat digunakan untuk tujuan lain, seperti logging atau tracing.Kami memeriksa langkah-langkah "perlindungan" khusus untuk GraphQL. Namun, ada sejumlah trik yang perlu diperhatikan terlepas dari jenis API:- pembatasan / pembatasan tingkat - batasi jumlah permintaan per unit waktu
- batas waktu - batas waktu untuk operasi dengan layanan lain, basis data, dll.
- pagination - dukungan pagination.
Mutasi data
Sejauh ini, kami telah mempertimbangkan murni pengambilan sampel data. Tapi GraphQL memungkinkan Anda untuk mengatur secara organik tidak hanya penerimaan data, tetapi juga perubahannya. Ada mekanisme untuk ini mutation: schema { query: EntryPoints, mutation: Mutations }
Misalnya, menambahkan produk ke keranjang dapat diatur melalui mutasi berikut: type Mutations { addProductToCart(cartId: Long!, productId: String!, count: Int = 1): Cart }
Ini mirip dengan mendefinisikan bidang, karena mutasi juga memiliki parameter dan nilai balik.Implementasi mutasi dalam kode server menggunakan GraphQL SPQR adalah sebagai berikut: @GraphQLMutation(name = "addProductToCart") public Cart addProductToCart( @GraphQLArgument(name = "cartId") Long cartId, @GraphQLArgument(name = "productId") String productId, @GraphQLArgument(name = "quantity", defaultValue = "1") int quantity) { return cartService.addProductToCart(cartId, productId, quantity); }
Tentu saja, sebagian besar pekerjaan yang bermanfaat dilakukan secara internal cartService. Dan tugas lapisan metode ini adalah untuk mengasosiasikannya dengan API. Seperti dalam kasus pengambilan sampel data, berkat anotasi, @GraphQL*sangat mudah untuk memahami skema GraphQL mana yang dihasilkan dari definisi metode ini.Di konsol GraphQL, Anda sekarang dapat melakukan permintaan mutasi untuk menambahkan produk tertentu ke keranjang kami dalam jumlah 2: mutation { addProductToCart( cartId: 1, productId: "59eb83c0040fa80b29938e3f", quantity: 2) { items { product { title } quantity total } subTotal } }
Karena mutasi memiliki nilai kembali, dimungkinkan untuk meminta bidang dari itu sesuai dengan aturan yang sama seperti yang kami lakukan untuk sampel biasa.Beberapa tim pengembangan WIX secara aktif menggunakan GraphQL dengan Scala dan perpustakaan Sangria, implementasi utama GraphQL dalam bahasa ini.Salah satu teknik berguna yang digunakan dalam WIX adalah dukungan untuk permintaan GraphQL saat merender HTML. Kami melakukan ini untuk menghasilkan JSON langsung di kode halaman. Berikut ini contoh mengisi templat HTML: // Pre-rendered <html> <script data-embedded-graphiql> { product(productId: $productId) title description price ... } } </script> </html>
Dan inilah hasilnya: // Rendered <html> <script> window.DATA = { product: { title: 'GraphQL Sticker', description: 'High quality sticker', price: '$2' ... } } </script> </html>
Kombinasi renderer HTML dan server GraphQL ini memungkinkan kami untuk menggunakan kembali API secara maksimal dan tidak membuat lapisan pengontrol tambahan. Selain itu, teknik ini sering ternyata menguntungkan dalam hal kinerja, karena setelah memuat halaman, aplikasi JavaScript tidak perlu pergi ke backend untuk data yang diperlukan pertama - itu sudah ada di halaman.Kerugian dari GraphQL
Hari ini, GraphQL menggunakan sejumlah besar perusahaan, termasuk raksasa seperti GitHub, Yelp, Facebook dan banyak lainnya. Dan jika Anda memutuskan untuk bergabung dengan nomor mereka, Anda harus tahu tidak hanya kelebihan GraphQL, tetapi juga kelemahannya, dan ada banyak dari mereka:- -, GraphQL . GraphQL , HTTP API. Cache-Control Last-Modified HTTP GraphQL API. , proxy gateways (Varnish, Fastly ). , GraphQL , , .
- GraphQL — . , API, , .
- GraphQL . .
- . GraphQL — . JSON XML, , , GraphQL, .
- GraphQL . , HTTP PUT POST -. , . GraphQL . .
- . , -: «delete» «kill», «annihilate» «terminate», . GraphQL API . HTTP DELETE .
- Joker 2016 . GraphQL . API- , , , HATEOAS, , « REST». , , GraphQL .
Perlu juga diingat bahwa jika Anda tidak berhasil mengembangkan HTTP API dengan baik, kemungkinan besar Anda tidak akan dapat mengembangkan GraphQL API. Lagi pula, apa yang paling penting dalam pengembangan API apa pun? Pisahkan model domain internal dari model API eksternal. Buat API berdasarkan skenario penggunaan, bukan perangkat internal aplikasi. Buka hanya informasi minimum yang diperlukan, dan tidak semuanya dalam satu baris. Pilih nama yang tepat. Jelaskan grafik dengan benar. Ada grafik sumber daya di HTTP API, dan grafik bidang di GraphQL API. Dalam kedua kasus, grafik ini harus dilakukan secara kualitatif.Ada beberapa alternatif di dunia HTTP API, dan Anda tidak harus selalu menggunakan GraphQL saat Anda membutuhkan pilihan yang kompleks. Misalnya, ada standar OData, yang mendukung pilihan parsial dan memperluas, seperti GraphQL, dan berfungsi di atas HTTP. Ada API JSON standar yang berfungsi dengan JSON dan mendukung hypermedia dan kemampuan pengambilan yang kompleks. Ada juga LinkRest, yang dapat Anda pelajari lebih lanjut dari https://youtu.be/EsldBtrb1Qc "> laporan oleh Andrus Adamchik di Joker 2017.Untuk mereka yang ingin mencoba GraphQL, saya sangat merekomendasikan membaca artikel perbandingan dari para insinyur yang sangat berpengalaman dalam REST dan GraphQL dari sudut pandang praktis dan filosofis:Akhirnya tentang Langganan dan tunda
GraphQL memiliki satu kelebihan menarik dibandingkan API standar. Dalam GraphQL, kedua kasus penggunaan sinkron dan asinkron dapat duduk di bawah atap yang sama.Kami mempertimbangkan menerima data melalui Anda query, mengubah status server melalui mutation, tetapi ada satu kebaikan lagi. Misalnya, kemampuan untuk mengatur langganan subscriptions.Bayangkan bahwa klien ingin menerima pemberitahuan tentang menambahkan produk ke keranjang secara tidak sinkron. Melalui GraphQL API, ini dapat dilakukan berdasarkan skema seperti itu: schema { query: Queries, mutation: Mutations, subscription: Subscriptions } type Subscriptions { productAdded(cartId: String!): Cart }
Pelanggan dapat berlangganan melalui permintaan berikut: subscription { productAdded(cart: 1) { items { product ... } subTotal } }
Sekarang, setiap kali suatu produk ditambahkan ke keranjang 1, server akan mengirim setiap klien yang berlangganan pesan di WebSocket dengan data yang diminta pada keranjang. Sekali lagi, melanjutkan kebijakan GraphQL, hanya data yang diminta klien saat berlangganan akan datang: { "data": { "productAdded": { "items": [ { "product": …, "subTotal": … }, { "product": …, "subTotal": … }, { "product": …, "subTotal": … }, { "product": …, "subTotal": … } ], "subTotal": 289.33 } } }
Klien sekarang dapat menggambar ulang keranjang, tidak harus menggambar ulang seluruh halaman.Ini nyaman karena API sinkron (HTTP) dan API asinkron (WebSocket) dapat dijelaskan melalui GraphQL.Contoh lain menggunakan komunikasi asinkron adalah mekanisme penundaan . Gagasan utamanya adalah bahwa klien memilih data apa yang ingin ia terima segera (secara serempak), dan yang siap ia terima nanti (secara tidak serempak). Misalnya, untuk permintaan seperti itu: query { feedStories { author { name } message comments @defer { author { name } message } } }
Server pertama akan mengembalikan penulis dan pesan untuk setiap cerita: { "data": { "feedStories": [ { "author": …, "message": … }, { "author": …, "message": … } ] } }
Setelah itu, server, setelah menerima data tentang komentar, akan mengirimkannya ke klien melalui WebSocket secara tidak serempak, yang menunjukkan di jalur yang mana riwayat riwayat sekarang siap: { "path": [ "feedStories", 0, "comments" ], "data": [ { "author": …, "message": … } ] }
Sumber Sampel
Kode yang digunakan untuk menyiapkan laporan ini dapat ditemukan di GitHub .Baru-baru ini, kami mengumumkan JPoint 2019 , yang akan diadakan 5-6 April 2019. Anda dapat mempelajari lebih lanjut tentang apa yang diharapkan dari konferensi dari pusat kami . Hingga 1 Desember, tiket Early Bird masih tersedia dengan harga terendah.