Membangun perutean klien / pencarian semantik dan pengelompokan corpus eksternal yang sewenang-wenang di Profi.ru
TLDR
Ini adalah ringkasan eksekutif yang sangat singkat (atau penggoda) tentang apa yang kami berhasil lakukan dalam waktu kurang lebih 2 bulan di departemen Profi.ru DS (saya ada di sana untuk sedikit lebih lama, tetapi memberi diri saya sendiri dan tim saya adalah hal yang terpisah untuk menjadi dilakukan pada awalnya).
Tujuan yang diproyeksikan
- Memahami input / maksud klien dan merutekan klien sesuai (kami memilih untuk pengelompokan agnostik kualitas input pada akhirnya, meskipun kami juga mempertimbangkan model tingkat-depan tipe char dan model bahasa juga. Aturan kesederhanaan);
- Temukan layanan dan sinonim yang sama sekali baru untuk layanan yang ada;
- Sebagai sub-tujuan dari (2) - belajar untuk membangun kelompok yang tepat pada corpus eksternal yang sewenang-wenang;
Mencapai tujuan
Jelas beberapa hasil ini dicapai tidak hanya oleh tim kami, tetapi juga oleh beberapa tim (mis. Kami jelas tidak melakukan bagian pengikisan untuk corpus domain dan anotasi manual, meskipun saya yakin pengikisan juga dapat diselesaikan oleh tim kami - Anda hanya perlu cukup proxy + mungkin beberapa pengalaman dengan selenium).
Tujuan bisnis:
- ~
88+% (vs ~ 60% dengan pencarian elastis) akurasi pada routing klien / klasifikasi maksud (~ kelas 5k ); - Pencarian bersifat agnostik terhadap kualitas input (salah cetak / input parsial);
- Classifier menggeneralisasi, struktur morfologis bahasa dieksploitasi;
- Penggolong sangat efektif dalam berbagai tolok ukur (lihat di bawah);
- Untuk berada di sisi yang aman - setidaknya
1,000 layanan baru ditemukan + setidaknya 15,000 sinonim (vs keadaan saat ini 5,000 + ~ 30,000 ). Saya berharap angka ini menjadi dua kali lipat bahkan tiga kali lipat;
Peluru terakhir adalah perkiraan rata-rata, tetapi yang konservatif.
Juga tes AB akan mengikuti. Tapi saya yakin dengan hasil ini.
Tujuan "Ilmiah":
- Kami benar-benar membandingkan banyak teknik penanaman kalimat modern menggunakan tugas klasifikasi hilir + KNN dengan database sinonim layanan;
- Kami berhasil mengalahkan pencarian yang lemah yang diawasi dengan lemah (pada dasarnya penggolong mereka adalah bag-of-ngrams) pada tolok ukur ini (lihat detail di bawah) menggunakan metode UNSUPERVISED ;
- Kami mengembangkan cara baru untuk membangun model NLP terapan (tas vanilla bi-LSTM + embeddings, pada dasarnya teks cepat bertemu RNN) - ini menjadikan morfologi bahasa Rusia menjadi pertimbangan dan digeneralisasikan dengan baik;
- Kami menunjukkan bahwa teknik penyematan akhir kami (lapisan leher botol dari pengklasifikasi terbaik) dikombinasikan dengan algoritma tanpa pengawasan yang canggih (UMAP + HDBSCAN) dapat menghasilkan gugus bintang;
- Kami menunjukkan dalam praktiknya kemungkinan, kelayakan dan kegunaan dari:
- Distilasi pengetahuan;
- Augmentasi untuk data teks (sic!);
- Pelatihan pengklasifikasi berbasis teks dengan augmentasi dinamis mengurangi waktu konvergensi secara drastis (10x) dibandingkan dengan menghasilkan dataset statis yang lebih besar (mis. CNN belajar untuk menggeneralisasikan kesalahan yang ditunjukkan dengan kalimat yang ditambah secara drastis);
Struktur proyek secara keseluruhan
Ini tidak termasuk penggolong akhir.
Juga pada akhirnya kami meninggalkan model RNN palsu dan triplet loss demi bottleneck classifier.

Apa yang berfungsi di NLP sekarang?
Pandangan mata burung:

Anda juga mungkin tahu bahwa NLP mungkin mengalami momen Imagenet sekarang .
Retasan UMAP skala besar
Saat membangun cluster, kami menemukan cara / hack untuk menerapkan UMAP ke level 100m + point (atau bahkan 1 miliar) pada dasarnya. Pada dasarnya membangun grafik KNN dengan FAISS dan kemudian hanya menulis ulang loop UMAP utama ke PyTorch menggunakan GPU Anda. Kami tidak membutuhkan itu dan meninggalkan konsep (kami hanya memiliki 10-15m poin setelah semua), tetapi silakan ikuti utas ini untuk detail.
Apa yang terbaik
- Untuk klasifikasi yang diawasi, teks-cepat memenuhi RNN (bi-LSTM) + set n-gram yang dipilih dengan cermat;
- Implementasi - python polos untuk n-gram + PyTorch Embedding layer bag;
- Untuk pengelompokan - lapisan bottleneck dari model ini + UMAP + HDBSCAN;
Tolok ukur classifier terbaik
Set dev beranotasi secara manual
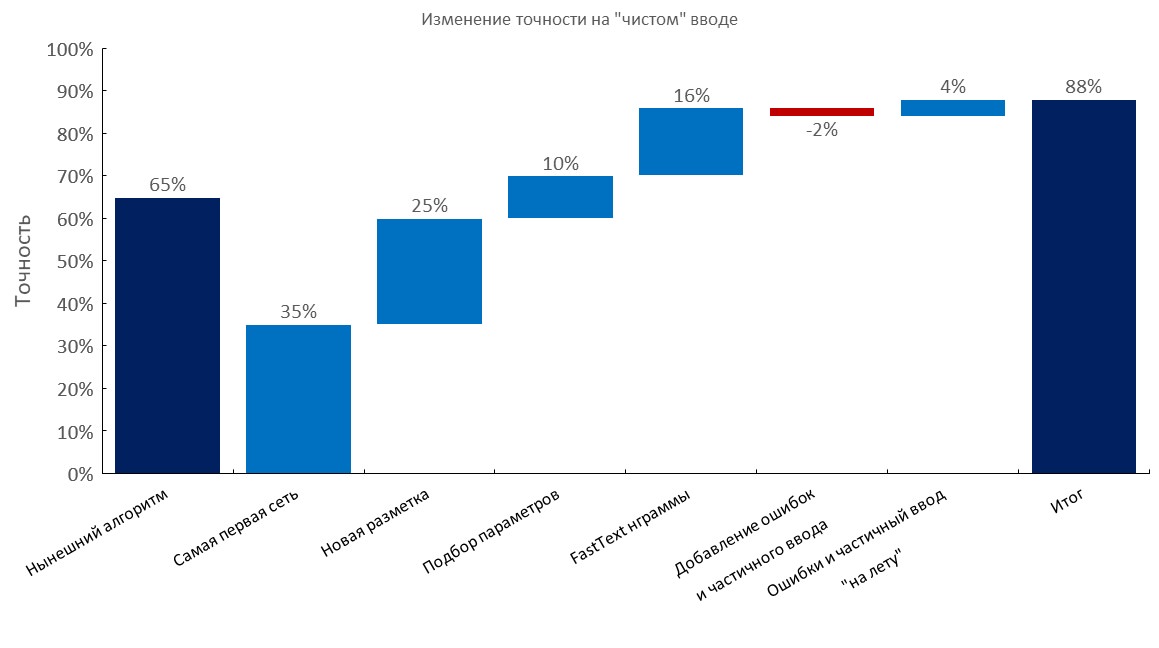
Kiri ke kanan:
(Akurasi Top1)
- Algoritma saat ini (pencarian elastis);
- RNN pertama;
- Anotasi baru;
- Tuning
- Lapisan tas penyisipan teks cepat;
- Menambahkan kesalahan ketik dan input parsial;
- Generasi kesalahan dinamis dan input parsial ( waktu pelatihan berkurang 10x );
- Skor akhir;
Dev beranotasi secara manual menetapkan + 1-3 kesalahan per kueri

Kiri ke kanan:
(Akurasi Top1)
- Algoritma saat ini (pencarian elastis);
- Lapisan tas penyisipan teks cepat;
- Menambahkan kesalahan ketik dan input parsial;
- Generasi kesalahan dinamis dan input parsial;
- Skor akhir;
Set manual beranotasi + input parsial
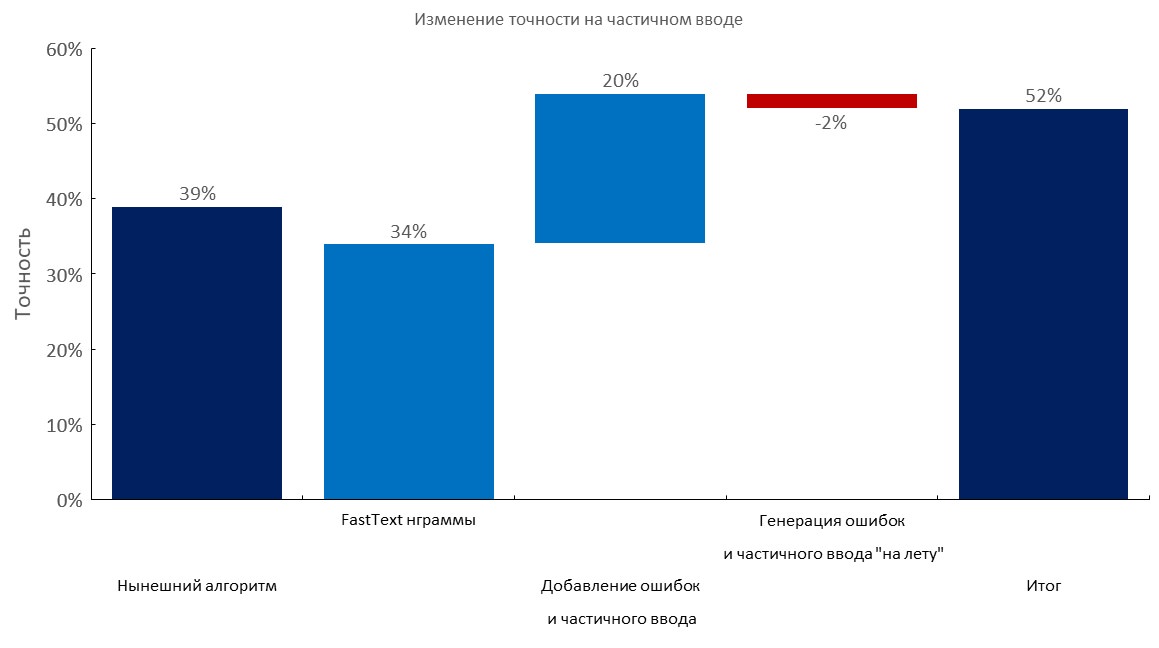
Kiri ke kanan:
(Akurasi Top1)
- Algoritma saat ini (pencarian elastis);
- Lapisan tas penyisipan teks cepat;
- Menambahkan kesalahan ketik dan input parsial;
- Generasi kesalahan dinamis dan input parsial;
- Skor akhir;
Koreksi skala besar / seleksi n-gram
- Kami mengumpulkan korpus terbesar untuk bahasa Rusia:
- Kami mengumpulkan kamus kata
100m menggunakan perayapan 1TB ; - Gunakan juga peretasan ini untuk mengunduh file seperti itu lebih cepat (semalam);
- Kami memilih rangkaian optimal
1m n-gram untuk classifier kami untuk menggeneralisasi terbaik ( 500k n-gram paling populer dari teks cepat yang dilatih di Wikipedia Rusia + 500k n-gram paling populer pada data domain kami);
Tes stres 1M n-gram kami pada kosakata 100M:

Augmentasi teks
Singkatnya:
- Ambil kamus besar dengan kesalahan (mis. 10-100 m kata unik);
- Menghasilkan kesalahan (menjatuhkan surat, menukar surat menggunakan probabilitas yang dihitung, memasukkan huruf acak, mungkin menggunakan tata letak keyboard, dll);
- Periksa apakah kata baru ada dalam kamus;
Kami brute memaksa banyak permintaan ke layanan seperti ini (dalam upaya untuk merekayasa balik dataset mereka), dan mereka memiliki kamus yang sangat kecil di dalamnya (juga layanan ini didukung oleh classifier pohon dengan fitur n-gram). Agak lucu melihat bahwa mereka hanya mencakup 30-50% dari kata-kata yang kami miliki di beberapa corpus .
Pendekatan kami jauh lebih unggul, jika Anda memiliki akses ke kosa kata domain yang besar .
Hasil terbaik tanpa pengawasan / semi-diawasi
KNN digunakan sebagai patokan untuk membandingkan berbagai metode penanaman.
(ukuran vektor) Daftar model yang diuji:
- (512) Pendeteksi kalimat palsu berskala besar dilatih pada 200 GB data perayapan umum;
- (300) Pendeteksi kalimat palsu dilatih untuk memberi tahu kalimat acak dari Wikipedia dari suatu layanan;
- (300) Teks cepat diperoleh dari sini, dilatih sebelumnya tentang araneum corpus;
- (200) Teks cepat dilatih tentang data domain kami;
- (300) Teks cepat dilatih pada 200GB data Perayapan Umum;
- (300) Jaringan Siam dengan kehilangan triplet yang dilatih dengan layanan / sinonim / kalimat acak dari Wikipedia;
- (200) Iterasi pertama dari embedding tas RNN's embedding layer, kalimat dikodekan sebagai seluruh kantong embeddings;
- (200) Sama, tetapi pertama kalimat itu dibagi menjadi kata-kata, lalu setiap kata tertanam, kemudian rata-rata diambil;
- (300) Sama seperti di atas tetapi untuk model akhir;
- (300) Sama seperti di atas tetapi untuk model akhir;
- (250) Lapisan bottleneck dari model akhir (250 neuron);
- Baseline pencarian elastis yang diawasi dengan lemah;
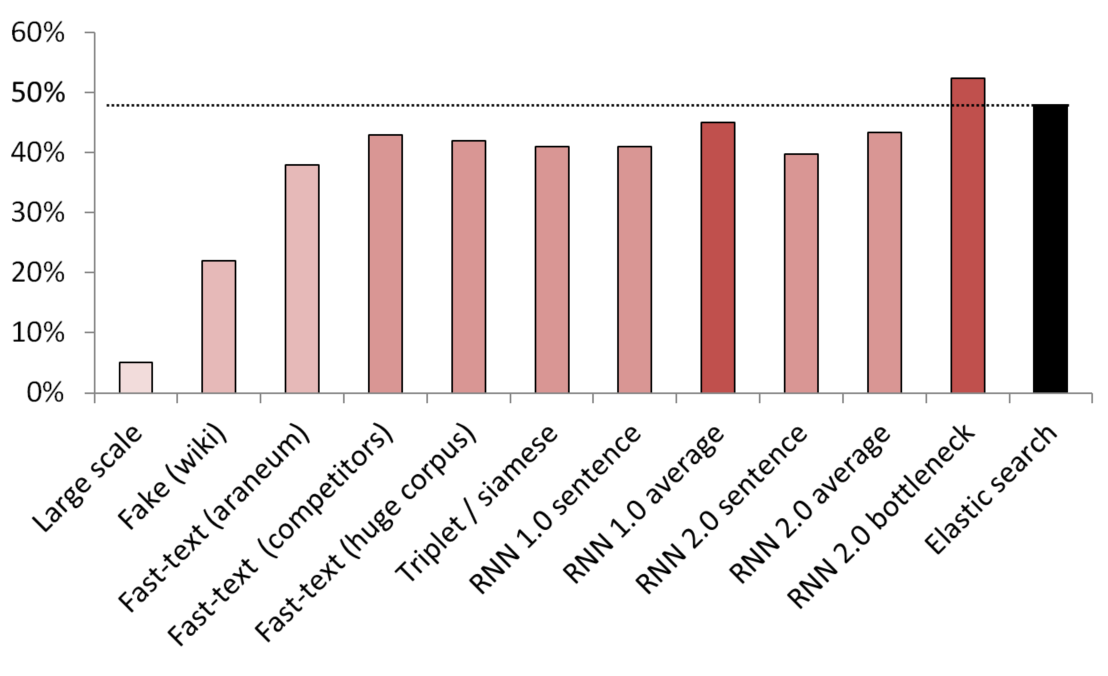
Untuk menghindari kebocoran, semua kalimat acak diambil secara acak. Panjang kata-kata mereka sama dengan panjang layanan / sinonim yang dibandingkan dengan mereka. Juga diambil langkah-langkah untuk memastikan bahwa model tidak hanya belajar dengan memisahkan kosa kata (embeddings dibekukan, Wikipedia undersampled untuk memastikan bahwa setidaknya ada satu kata domain dalam setiap kalimat Wikipedia).
Visualisasi cluster
3D

2D

"Antarmuka" eksplorasi klaster
Hijau - kata / sinonim baru.
Latar belakang abu-abu - kemungkinan kata baru.
Teks abu-abu - sinonim yang ada.

Tes ablasi dan apa yang berhasil, apa yang kami coba dan apa yang tidak
- Lihat grafik di atas;
- Rata-rata polos / tf-idf rata-rata pernikahan teks cepat - garis dasar SANGAT tangguh ;
- Teks-cepat> Word2Vec untuk Bahasa Rusia;
- Penyisipan kalimat dengan jenis deteksi kalimat palsu, tetapi artinya jika dibandingkan dengan metode lain;
- BPE (sentencepiece) tidak menunjukkan peningkatan pada domain kami;
- Model tingkat Char berjuang untuk menggeneralisasi, meskipun ada kertas dari google;
- Kami mencoba multi-head transformer (dengan classifier dan kepala pemodelan bahasa), tetapi pada penjelasan yang tersedia, kinerjanya kira-kira sama dengan model berbasis vanilla LSTM biasa. Ketika kami bermigrasi untuk menyematkan pendekatan yang buruk, kami meninggalkan jalur penelitian ini karena kepraktisan transformer yang lebih rendah dan ketidakpraktisan memiliki kepala LM bersama dengan lapisan kantong penyematan;
- BERT - tampaknya berlebihan, juga beberapa orang mengklaim bahwa transformer berlatih secara harfiah selama berminggu-minggu;
- ELMO - menggunakan perpustakaan seperti AllenNLP tampaknya tidak produktif menurut pendapat saya baik di lingkungan penelitian / produksi dan pendidikan untuk alasan yang saya tidak akan berikan di sini;
Sebarkan
Selesai menggunakan:
- Wadah Docker dengan layanan web sederhana;
- Hanya CPU untuk inferensi sudah cukup;
- ~
2.5 ms per query pada CPU, tidak perlu batching; - ~ Jejak memori RAM
1GB ; - Hampir tidak ada dependensi, selain dari
PyTorch , numpy dan pandas (dan server web ofc). - Meniru generasi n-gram teks cepat seperti ini ;
- Menanamkan lapisan tas + indeks karena baru saja disimpan dalam kamus;