Dalam layanan besar, untuk memecahkan masalah menggunakan pembelajaran mesin berarti hanya melakukan sebagian pekerjaan. Menanamkan model ML tidak begitu mudah, dan membangun proses CI / CD di sekitar mereka bahkan lebih sulit. Pada konferensi Yandex
"Data & Sains: program aplikasi", Adam Eldarov
, kepala ilmu data di YouDo, berbicara tentang bagaimana mengelola siklus hidup model, mengatur proses pelatihan dan pelatihan ulang, mengembangkan layanan mikro yang dapat diskalakan, dan banyak lagi.
- Mari kita mulai dengan pengantar. Ada seorang ilmuwan data, ia menulis beberapa kode di Jupyter Notebook, melakukan fitur-engineering, validasi silang, melatih model model. Kecepatan tumbuh.

Tetapi pada titik tertentu dia mengerti: untuk membawa nilai bisnis kepada perusahaan, dia harus melampirkan solusi di suatu tempat dalam produksi, ke beberapa produksi mitos, yang menyebabkan kita banyak masalah. Laptop yang kami lihat dalam produksi dalam banyak kasus tidak dapat dikirim. Dan muncul pertanyaan: bagaimana cara mengirimkan kode ini di dalam laptop ke layanan tertentu. Dalam kebanyakan kasus, Anda perlu menulis layanan yang memiliki API. Atau mereka berkomunikasi melalui PubSub, melalui antrian.

Ketika kami membuat rekomendasi, kita sering perlu melatih model dan melatihnya. Proses ini harus dipantau. Dalam hal ini, kita harus selalu memeriksa dengan tes baik kode itu sendiri maupun modelnya, sehingga suatu saat model kita tidak menjadi gila dan tidak selalu mulai memprediksi nol. Itu juga perlu diperiksa pada pengguna nyata melalui tes AB - apa yang kami lakukan lebih baik atau setidaknya tidak lebih buruk.
Bagaimana kita mendekati kodenya? Kami memiliki GitLab. Semua kode kami dibagi menjadi banyak perpustakaan kecil yang memecahkan masalah domain tertentu. Pada saat yang sama, ini adalah proyek GitLab yang terpisah, kontrol versi Git dan model percabangan GitFlow. Kami menggunakan hal-hal seperti kait pra-komitmen sehingga Anda tidak dapat melakukan kode yang tidak memenuhi pemeriksaan uji stat kami. Dan tes itu sendiri, tes unit. Kami menggunakan pendekatan pengujian berbasis properti untuk mereka.

Biasanya, ketika Anda menulis tes, berarti Anda memiliki fungsi tes dan argumen yang Anda buat dengan tangan Anda, beberapa contoh, dan nilai apa yang dikembalikan fungsi tes Anda. Ini tidak nyaman. Kode meningkat, banyak yang pada prinsipnya terlalu malas untuk menulisnya. Sebagai hasilnya, kami memiliki banyak kode yang ditemukan oleh tes. Pengujian berbasis properti menyiratkan bahwa semua argumen Anda memiliki distribusi tertentu. Mari kita lakukan pentahapan, dan sering kali sampel semua argumen kami dari distribusi ini, panggil fungsi yang sedang diuji dengan argumen ini, dan periksa properti tertentu hasil dari fungsi ini. Akibatnya, kami memiliki kode jauh lebih sedikit, dan pada saat yang sama, ada banyak tes lagi.
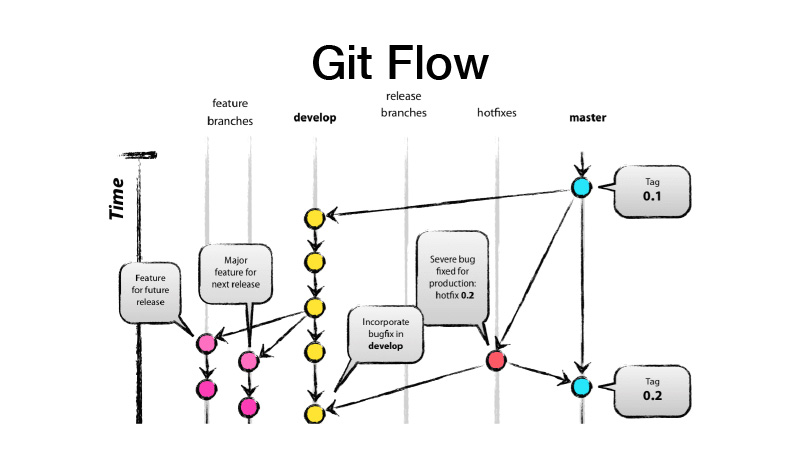
Apa itu GitFlow? Ini adalah model percabangan, yang menyiratkan bahwa Anda memiliki dua cabang utama - mengembangkan dan menguasai, di mana kode siap produksi berada, dan semua pengembangan dilakukan di cabang pengembangan, di mana semua fitur baru diperoleh dari brunch fitur. Artinya, setiap fitur adalah fitur-brunch baru, sedangkan fitur-brunch harus berumur pendek, dan untuk selamanya - juga dibahas melalui fitur toggle. Kami kemudian membuat rilis, dari dev melemparkan perubahan untuk menguasai dan menempatkan tag versi perpustakaan atau layanan kami di atasnya.
Kami sedang melakukan pengembangan, menggergaji beberapa fitur, mendorongnya ke GitLab, membuat permintaan penggabungan dari fitur brunch ke para gadis. Pemicu bekerja, menjalankan tes, jika semuanya OK, kita dapat membekukannya. Tapi bukan kita yang menahannya, tapi seseorang dari tim. Ini merevisi kode, dan dengan demikian meningkatkan faktor bus. Bagian kode ini sudah diketahui oleh dua orang. Akibatnya, jika seseorang ditabrak bus, seseorang sudah tahu apa yang dia lakukan.

Integrasi berkelanjutan untuk perpustakaan biasanya terlihat seperti tes untuk setiap perubahan. Dan jika kami merilisnya, itu juga menerbitkan ke server PyPI pribadi dari paket kami.
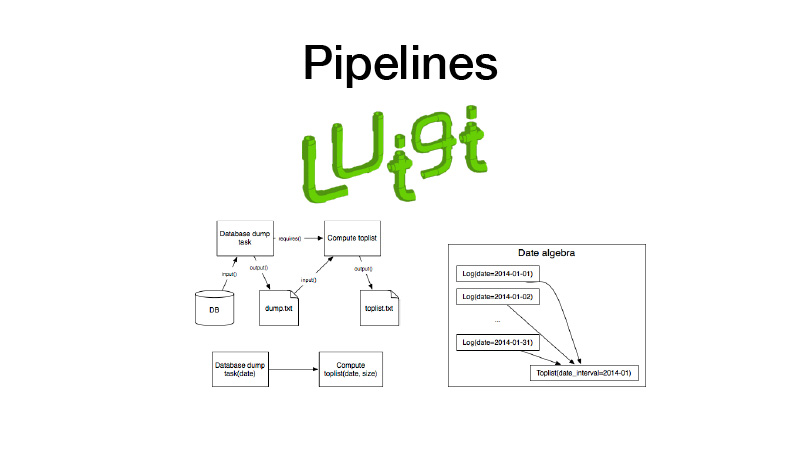
Selanjutnya kita bisa mengumpulkannya di jalur pipa. Untuk ini kami menggunakan perpustakaan Luigi. Ia bekerja dengan entitas seperti tugas, yang memiliki output, di mana artefak yang dibuat selama pelaksanaan tugas disimpan. Ada parameter tugas yang membuat parameter logika bisnis yang dijalankan, mengidentifikasi tugas, dan hasilnya. Pada saat yang sama, tugas selalu memiliki persyaratan yang diajukan tugas lain. Ketika kami menjalankan beberapa jenis tugas, semua dependensinya diperiksa melalui pengecekan outputnya. Jika output ada, ketergantungan kita tidak dimulai. Jika artefak hilang dari penyimpanan, itu dimulai. Ini membentuk pipa, grafik siklik terarah.
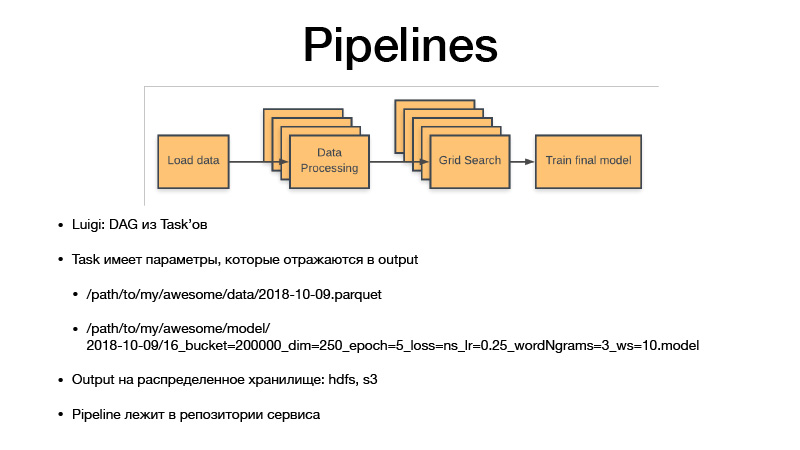
Semua parameter mengidentifikasi logika bisnis. Dengan melakukan itu, mereka mengidentifikasi artefak. Itu selalu kencan dengan rincian, kepekaan, atau satu minggu, hari, jam, tiga jam. Jika kita melatih beberapa model, Luigi taska selalu memiliki hyperparameter dari tugas ini, mereka bocor ke dalam artefak yang kami produksi, hyperparameters tercermin dalam nama artefak. Dengan demikian, kami pada dasarnya versi semua set data menengah dan artefak akhir, dan mereka tidak pernah ditimpa, selalu hanya ditinggikan untuk penyimpanan, dan penyimpanan adalah HDFS dan S3 pribadi, yang melihat artefak akhir dari beberapa acar, model atau sesuatu yang lain . Dan semua kode pipa terletak pada proyek layanan di repositori yang terkait.

Itu perlu diperbaiki entah bagaimana. Tumpukan HashiCorp datang untuk menyelamatkan, kami menggunakan Terraform untuk mendeklarasikan infrastruktur dalam bentuk kode, Vault untuk mengelola rahasia, ada semua kata sandi, penampilan ke database. Konsul adalah layanan penemuan yang didistribusikan oleh penyimpanan nilai kunci yang dapat Anda gunakan untuk mengonfigurasi. Dan juga Konsul melakukan pemeriksaan kesehatan terhadap simpul dan layanan Anda, memeriksa ketersediaannya.
Dan - Pengembara. itu adalah sistem orkestrasi, shedling layanan Anda dan beberapa jenis pekerjaan batch.
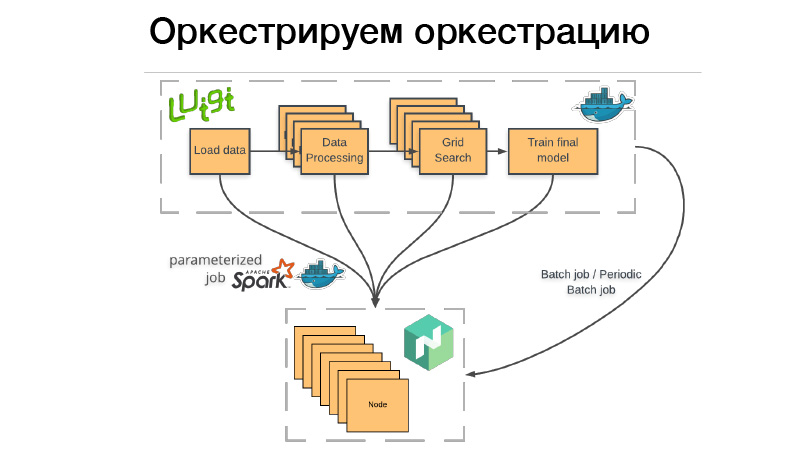
Bagaimana kita menggunakan ini? Ada pipa Luigi, kami akan mengemasnya dalam wadah Docker, menjatuhkan kelelawar atau pekerjaan batch berkala ke Nomad. Pekerjaan batch - ini adalah sesuatu yang selesai, selesai, dan jika semuanya berhasil - semuanya baik-baik saja, kita dapat memulainya secara manual. Tetapi jika ada yang tidak beres, Nomad mencoba lagi sampai menghabiskan upaya, atau tidak berakhir dengan sukses.
Pekerjaan batch berkala - ini persis sama, hanya bekerja sesuai jadwal.
Ada masalah. Ketika kami menggunakan wadah untuk sistem orkestrasi apa pun, kami perlu menunjukkan berapa banyak memori yang dibutuhkan oleh wadah ini, CPU atau memori. Jika kami memiliki saluran pipa yang beroperasi selama tiga jam, dua jam dari ini menghabiskan 10 GB RAM, 1 jam - 70 GB. Jika kita melebihi batas yang kita berikan padanya, daemon Docker datang dan membunuh Dockers dan (nrzb.) [02:26:13] Kami tidak ingin kehabisan memori terus-menerus, jadi kami harus menentukan semua 70 GB, beban memori puncak. Tapi di sini masalahnya, semua 70 GB selama tiga jam akan dialokasikan dan tidak dapat diakses untuk pekerjaan lain.
Karena itu, kami pergi ke arah lain. Seluruh saluran pipa Luigi kami tidak memulai segala macam logika bisnis, ia hanya meluncurkan serangkaian dadu di Nomad, yang disebut pekerjaan parameterisasi. Sebenarnya, ini adalah analog dari fungsi Server (NRZB.) [02:26:39], AVS Lambda, siapa tahu. Ketika kita membuat pustaka, kita menyebarkan melalui CI semua kode kita dalam bentuk pekerjaan parameter, yaitu wadah dengan beberapa parameter. Misalkan, Lite JBM Classifier, ia memiliki parameter ke jalur ke data input untuk pelatihan, hyperparameter model dan jalur ke artefak output. Semua ini terdaftar di Nomad, dan kemudian dari pipa Luigi kita bisa menarik semua Pekerjaan Nomad ini melalui API, dan pada saat yang sama Luigi memastikan untuk tidak menjalankan tugas yang sama berkali-kali.
Misalkan kita memiliki pemrosesan teks yang sama. Ada 10 model bersyarat, dan kami tidak ingin memulai kembali pemrosesan teks setiap saat. Ini akan mulai hanya sekali, dan pada saat yang sama akan ada hasil selesai setiap kali digunakan kembali. Dan pada saat yang sama, semua ini bekerja secara terdistribusi, kita dapat menjalankan pencarian grid raksasa pada sekelompok besar, hanya punya waktu untuk membuang besi.
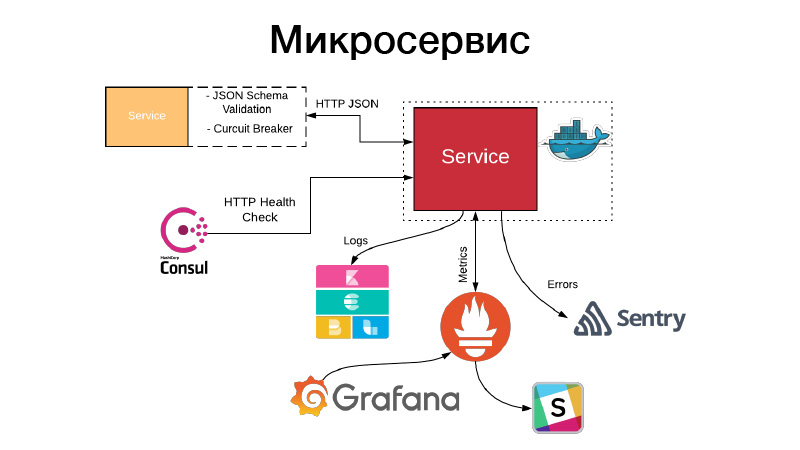
Kami memiliki artefak, kami perlu mengaturnya dalam bentuk layanan. Layanan memperlihatkan API HTTP atau berkomunikasi melalui antrian. Dalam contoh ini, ini adalah API HTTP, contoh paling sederhana. Pada saat yang sama, komunikasi dengan layanan, atau layanan kami berkomunikasi dengan layanan lain melalui HTTP JSON API, memvalidasi skema JSON. Layanan itu sendiri selalu menggambarkan objek JSON dalam dokumentasi untuk API dan skema objek ini. Tetapi tidak semua bidang objek JSON selalu dibutuhkan, oleh karena itu kontrak yang digerakkan konsumen divalidasi, skema ini divalidasi, komunikasi dilakukan melalui pemutus sirkuit pola untuk mencegah kegagalan sistem terdistribusi kami karena kegagalan cascading.
Pada saat yang sama, layanan harus menetapkan pemeriksaan kesehatan HTTP sehingga Konsul dapat datang dan memeriksa ketersediaan layanan ini. Pada saat yang sama, Nomad dapat membuatnya sehingga ada layanan untuk tiga halo cek berturut-turut, ia dapat memulai kembali layanan untuk membantunya. Layanan menulis semua lognya dalam format JSON. Kami menggunakan driver logging JSON dan tumpukan Elastik, di setiap titik FileBit hanya mengambil semua log JSON, melemparkannya ke cache log, dari sana mereka sampai ke Elastis, kita dapat menganalisis KBan. Pada saat yang sama, kami tidak menggunakan log untuk kumpulan metrik dan dasbor bangunan, itu tidak efisien, kami menggunakan sistem penarik Prometheus untuk ini, kami memiliki proses untuk membuat templat untuk setiap layanan dasbor, dan kami dapat menganalisis metrik teknis yang dihasilkan oleh layanan.
Selain itu, jika terjadi kesalahan, peringatan akan masuk, tetapi dalam kebanyakan kasus ini tidak cukup. Sentry datang membantu kami, ini untuk analisis insiden. Faktanya, kami menangkap semua log tingkat kesalahan oleh Sentry handler dan mendorongnya ke Sentry. Dan kemudian ada traceback terperinci, ada semua informasi tentang lingkungan apa layanan itu berada, versi mana, yang fungsinya disebut dengan argumen mana, dan variabel mana dalam lingkup ini dengan nilai apa. Semua konfigurasi, semua ini terlihat, dan sangat membantu untuk dengan cepat memahami apa yang terjadi dan memperbaiki kesalahan.
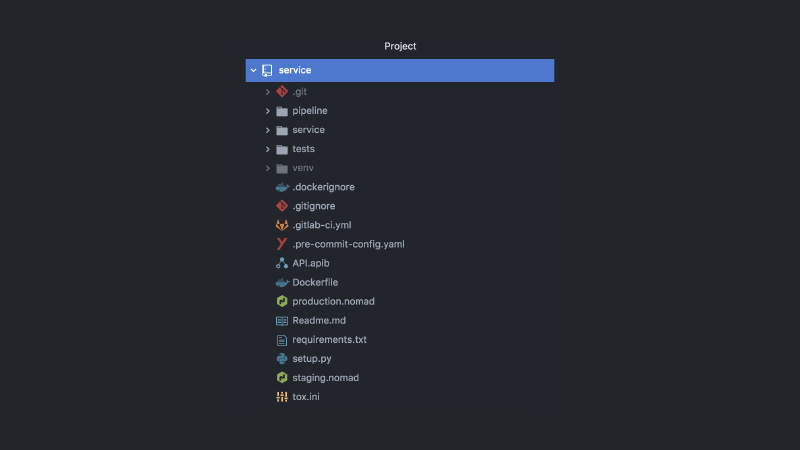
Akibatnya, layanannya terlihat seperti ini. Pisahkan proyek GitLab, kode pipa, kode uji, kode layanan itu sendiri, sekelompok konfigurasi yang berbeda, Pengembara, konfigurasi CI, dokumentasi API, kait komit dan banyak lagi.
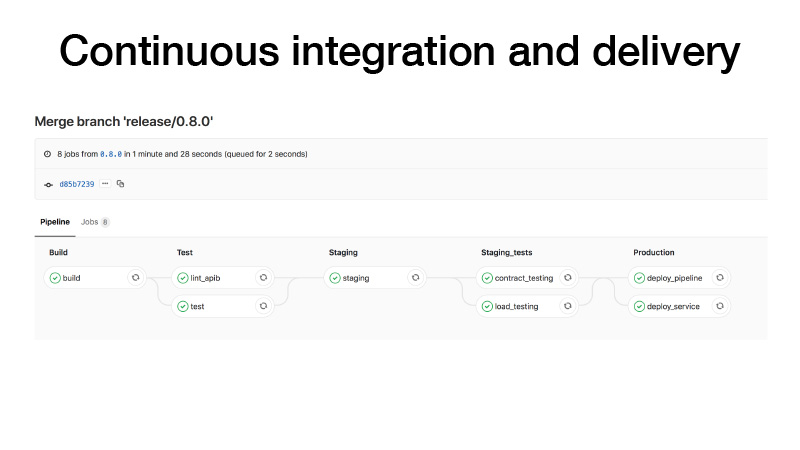
CI, ketika kami melakukan rilis, kami melakukannya dengan cara ini: membangun sebuah wadah, menjalankan tes, melemparkan sebuah cluster di atas panggung, menjalankan kontrak uji untuk layanan kami di sana, melakukan pengujian stres untuk memastikan bahwa prediksi kami tidak terlalu lambat dan menjaga beban yang kami pikir . Jika semuanya baik-baik saja, kami akan menggunakan layanan ini untuk produksi. Dan ada dua cara: kita dapat menggunakan pipa, jika pekerjaan batch berkala, itu bekerja di suatu tempat di latar belakang dan menghasilkan artefak, atau dengan pena kita memicu beberapa pipa, itu melatih beberapa model, setelah itu kita mengerti bahwa semuanya baik-baik saja dan menyebarkan layanan.

Apa lagi yang terjadi dalam kasus ini? Saya mengatakan bahwa dalam pengembangan fitur brunch ada paradigma seperti fitur toggle. Dengan cara yang baik, Anda perlu menutup fitur dengan beberapa toggle, hanya untuk mengurangi fitur dalam pertempuran jika terjadi kesalahan. Kami kemudian dapat mengumpulkan semua fitur di kereta rilis, dan bahkan jika fitur tersebut belum selesai, kami dapat menyebarkannya. Fitur-toggle saja akan dimatikan. Karena kita semua Ilmuwan Data, kami juga ingin melakukan tes AV. Katakanlah kita mengganti LightGBM dengan CatBoost. Kami ingin memeriksa ini, tetapi pada saat yang sama, tes AV dikelola dengan mengacu pada beberapa ID pengguna. Fitur toggle terikat ke userID, dan dengan demikian lulus tes AV. Kami perlu memeriksa metrik ini di sini.
Semua layanan dikerahkan ke Nomad. Kami memiliki dua kluster produksi Nomad - satu untuk pekerjaan batch dan satu untuk layanan.
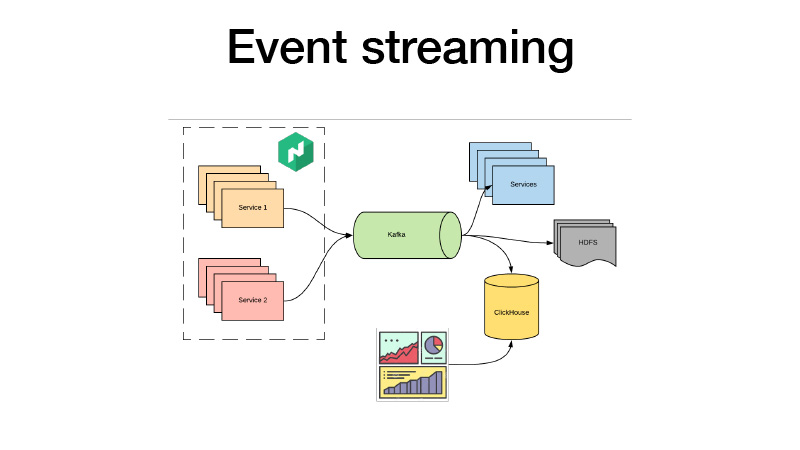
Mereka mendorong semua acara bisnis mereka ke Kafka. Dari sana kita bisa mengambilnya. Intinya, ini adalah arsitektur domba. Kami dapat berlangganan HDFS dengan beberapa layanan, melakukan beberapa analitik waktu nyata, dan pada saat yang sama, kami semua membuka ClickHouse dan membangun dasbor untuk menganalisis semua acara bisnis untuk layanan kami. Kami dapat menganalisis tes AV, apa pun.
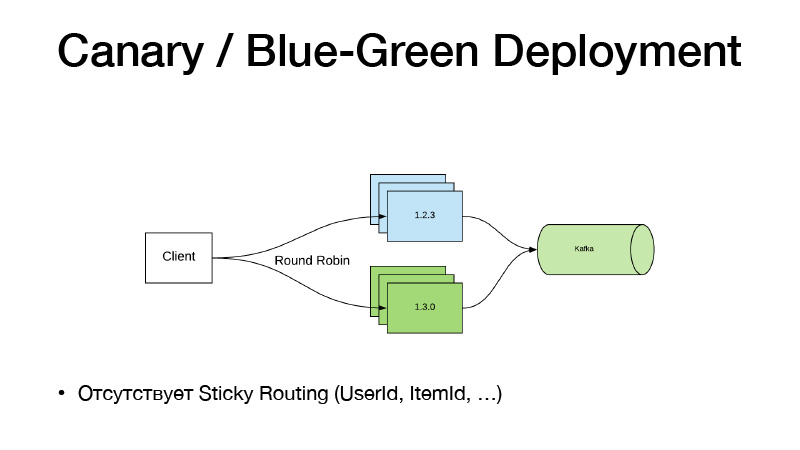
Dan jika kami tidak mengubah kode, jangan gunakan fitur toggle. Kami baru saja mulai bekerja dengan beberapa pena pada pipa, dia mengajari kami model baru. Kami memiliki jalan baru untuk itu. Kami hanya mengubah jalur Nomad ke model di konfigurasi, membuat rilis layanan baru, dan di sini paradigma Canary Deployment datang ke bantuan kami, tersedia di Nomad dari kotak.
Kami memiliki versi layanan saat ini dalam tiga contoh. Kami mengatakan bahwa kami menginginkan tiga burung kenari - tiga replika versi baru dikerahkan tanpa memotong yang lama. Akibatnya, lalu lintas mulai dibagi menjadi dua bagian. Sebagian lalu lintas jatuh pada versi layanan baru. Semua layanan mendorong semua acara bisnis mereka ke Kafka. Hasilnya, kami dapat menganalisis metrik secara waktu nyata.
Jika semuanya baik-baik saja, maka kita dapat mengatakan bahwa semuanya baik-baik saja. Menyebarkan, Nomad akan melalui, matikan semua versi lama dan skala yang baru.
Model ini buruk karena jika kita perlu mengikat perutean versi oleh beberapa entitas, Item Pengguna. Skema seperti itu tidak berhasil, karena lalu lintas seimbang melalui round-robin. Karena itu, kami pergi dengan cara berikut dan menggergaji layanan menjadi dua bagian.
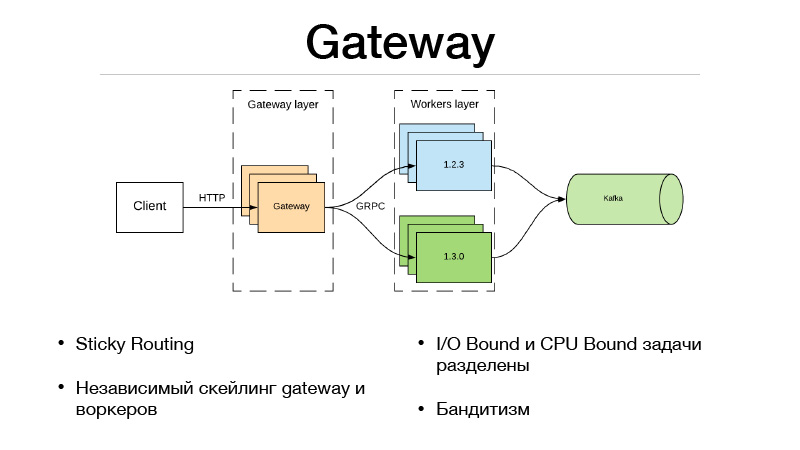
Ini adalah lapisan Gateway dan lapisan pekerja. Klien berkomunikasi melalui HTTP dengan lapisan Gateway, semua logika pemilihan versi dan perimbangan lalu lintas ada di Gateway. Pada saat yang sama, semua tugas I / O Bound yang diperlukan untuk menyelesaikan predikat juga terletak di Gateway. Misalkan kita mendapatkan userID dalam predikat dalam permintaan, yang perlu kita perkaya dengan beberapa informasi. Kami harus menarik layanan microser lainnya dan mengambil semua info, fitur atau pangkalan. Akibatnya, semua ini terjadi di Gateway. Dia berkomunikasi dengan pekerja yang hanya dalam model, dan melakukan satu hal - prediksi. Input dan output.
Tetapi karena kami membagi layanan kami menjadi dua bagian, overhead muncul karena panggilan jaringan jarak jauh. Bagaimana cara menaikkannya? Kerangka kerja JRPC dari Google, RPC dari Google, yang berjalan di atas HTTP2 hadir untuk menyelamatkan. Anda dapat menggunakan multiplexing dan kompresi. JPRC menggunakan protobuff. Ini adalah protokol biner yang sangat diketik yang memiliki serialisasi dan deserialisasi yang cepat.
Sebagai hasilnya, kami juga memiliki kemampuan untuk mengukur Gateway dan pekerja secara mandiri. Katakanlah kita tidak dapat menyimpan sejumlah koneksi HTTP terbuka. Oke, skala Gateway. Prediksi kami terlalu lambat, kami tidak punya waktu untuk menyimpannya - ok, kami mengukur pekerja. Pendekatan ini sangat cocok dengan bandit multi-bersenjata. Di Gateway, karena seluruh logika penyeimbangan lalu lintas diimplementasikan, ia dapat pergi ke layanan microser eksternal dan mengambil semua statistik untuk setiap versi dari mereka, serta membuat keputusan tentang bagaimana menyeimbangkan lalu lintas. Katakanlah menggunakan Thompson Sampling.
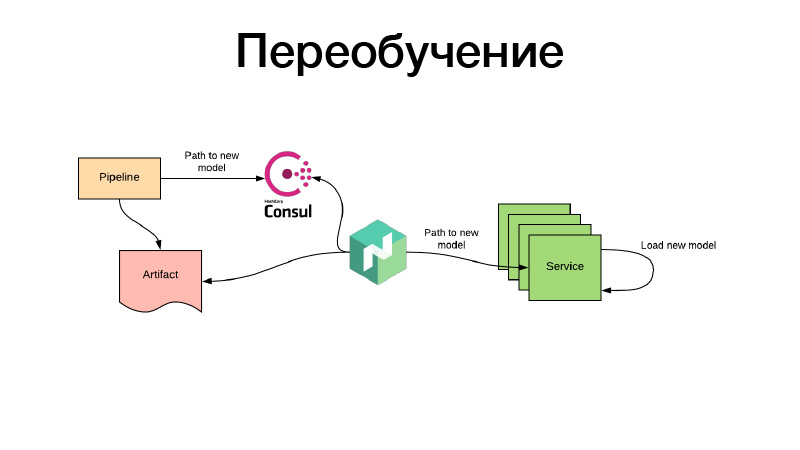
Semua baik-baik saja, modelnya entah bagaimana dilatih, kami mendaftarkannya di konfigurasi Nomad. Tetapi bagaimana jika ada model rekomendasi yang sudah memiliki waktu untuk menjadi usang selama pelatihan, dan kita perlu terus melatihnya? Semuanya dilakukan dengan cara yang sama: melalui pekerjaan batch berkala beberapa artefak diproduksi - katakanlah, setiap tiga jam. Pada saat yang sama, pada akhir pekerjaannya, pipeline menetapkan jalur untuk model baru di Konsul. Ini adalah penyimpanan nilai kunci, yang digunakan untuk konfigurasi. Nomad dapat mengkonfigurasi konfigurasi. Biarkan ada variabel lingkungan berdasarkan nilai-nilai Konsul penyimpanan nilai kunci. Dia memantau perubahan dan, segera setelah jalur baru muncul, memutuskan bahwa dua jalur dapat diambil. Dia mengunduh artefak itu sendiri melalui tautan baru, menempatkan wadah layanan di Docker menggunakan volume dan reboot - dan melakukan semua ini sehingga tidak ada downtime, yaitu, secara perlahan, secara individu. Atau dia membuat konfigurasi baru dan melaporkan layanan kepadanya. Atau layanan itu sendiri mendeteksi itu - dan di dalam dirinya dapat secara mandiri, tinggal perbarui modelka-nya. Itu saja, terima kasih.