
Saya menemukan materi menarik tentang kecerdasan buatan dalam game. Dengan penjelasan tentang hal-hal dasar tentang AI menggunakan contoh-contoh sederhana, dan di dalamnya ada banyak alat dan metode yang berguna untuk pengembangan dan desain yang nyaman. Bagaimana, di mana, dan kapan menggunakannya - juga ada di sana.
Sebagian besar contoh ditulis dalam pseudocode, jadi pengetahuan pemrograman yang mendalam tidak diperlukan. Di bawah potongan 35 lembar teks dengan gambar dan gif, jadi bersiap-siaplah.
UPD Saya
minta maaf , tetapi
PatientZero sudah melakukan terjemahan artikel ini di Habré. Anda dapat membaca versinya di
sini , tetapi karena suatu alasan artikel tersebut melewati saya (saya menggunakan pencarian, tetapi ada yang tidak beres). Dan karena saya sedang menulis blog pengembang game, saya memutuskan untuk meninggalkan opsi terjemahan untuk pelanggan (beberapa saat berbeda untuk saya, beberapa sengaja dilewatkan pada saran pengembang).
Apa itu AI?
Game AI berfokus pada tindakan apa yang harus dilakukan objek berdasarkan kondisi di mana ia berada. Ini biasanya disebut manajemen "agen cerdas," di mana agen adalah karakter permainan, kendaraan, bot, dan kadang-kadang sesuatu yang lebih abstrak: seluruh kelompok entitas atau bahkan peradaban. Dalam setiap kasus, itu adalah sesuatu yang harus melihat sekelilingnya, membuat keputusan atas dasar dan bertindak sesuai dengan mereka. Ini disebut siklus Sense / Think / Act:
- Sense: agen menemukan atau menerima informasi tentang hal-hal di lingkungannya yang dapat memengaruhi perilakunya (ancaman di dekatnya, barang yang akan dikumpulkan, tempat menarik untuk diteliti).
- Pikirkan: agen memutuskan bagaimana bereaksi (mempertimbangkan apakah aman untuk mengumpulkan barang atau apakah dia harus bertarung / bersembunyi terlebih dahulu).
- Act: agen melakukan tindakan untuk mengimplementasikan keputusan sebelumnya (mulai bergerak ke arah lawan atau objek).
- ... sekarang situasinya telah berubah karena aksi karakter, sehingga siklus berulang dengan data baru.
AI cenderung fokus pada bagian indra perulangan. Misalnya, mobil otonom mengambil gambar jalan, menggabungkannya dengan data radar dan lidar, dan menafsirkannya. Biasanya ini dilakukan dengan pembelajaran mesin, yang memproses data yang masuk dan memberi mereka makna, mengekstraksi informasi semantik seperti "ada mobil lain 20 yard di depan Anda." Inilah yang disebut masalah klasifikasi.
Game tidak memerlukan sistem yang kompleks untuk mengekstraksi informasi, karena sebagian besar data sudah merupakan bagian integral darinya. Tidak perlu menjalankan algoritma pengenalan gambar untuk menentukan apakah ada musuh di depan - game sudah tahu dan mentransfer informasi secara langsung dalam proses pengambilan keputusan. Karena itu, bagian dari siklus Sense seringkali jauh lebih sederhana daripada Think and Act.
Keterbatasan game AI
AI memiliki sejumlah batasan yang harus diperhatikan:
- AI tidak perlu dilatih terlebih dahulu, seolah-olah itu adalah algoritma pembelajaran mesin. Tidak ada gunanya menulis jaringan saraf selama pengembangan untuk menonton puluhan ribu pemain dan belajar cara terbaik untuk bermain melawan mereka. Mengapa Karena permainan tidak dirilis, tetapi tidak ada pemain.
- Permainan harus menghibur dan menantang, oleh karena itu agen tidak harus menemukan pendekatan terbaik terhadap orang.
- Agen harus terlihat realistis sehingga pemain merasa seperti mereka bermain melawan orang sungguhan. AlphaGo mengungguli manusia, tetapi langkah-langkah yang diambil jauh dari pemahaman tradisional tentang permainan. Jika permainan meniru lawan manusia, seharusnya tidak ada perasaan seperti itu. Algoritma perlu diubah sehingga membuat keputusan yang masuk akal, bukan yang ideal.
- AI harus bekerja secara real time. Ini berarti bahwa algoritma tidak dapat memonopoli penggunaan prosesor untuk waktu yang lama untuk pengambilan keputusan. Bahkan 10 milidetik untuk ini terlalu lama, karena kebanyakan gim hanya memiliki 16 hingga 33 milidetik untuk menyelesaikan semua pemrosesan dan beralih ke bingkai grafik berikutnya.
- Idealnya, setidaknya bagian dari sistem adalah data-driven sehingga non-coders dapat membuat perubahan dan penyesuaian lebih cepat.
Pertimbangkan pendekatan AI yang menjangkau seluruh siklus Sense / Think / Act.
Pengambilan keputusan dasar
Mari kita mulai dengan game paling sederhana - Pong. Tujuan: memindahkan platform (mendayung) sehingga bola memantul darinya, bukannya terbang melewati. Ini seperti tenis, di mana Anda kalah jika Anda tidak memukul bola. Di sini, AI memiliki tugas yang relatif mudah - untuk memutuskan ke arah mana platform akan dipindahkan.

Pernyataan bersyarat
Untuk AI, Pong memiliki solusi yang paling jelas - selalu mencoba memposisikan platform di bawah bola.
Algoritma sederhana untuk ini, ditulis dalam pseudocode:
setiap frame / pembaruan saat game berjalan:
jika bola ada di sebelah kiri dayung:
pindahkan dayung ke kiri
lain jika bola ada di sebelah kanan dayung:
pindahkan dayung ke kananJika platform bergerak dengan kecepatan bola, maka ini adalah algoritma yang sempurna untuk AI di Pong. Tidak perlu mempersulit apa pun jika tidak ada begitu banyak data dan tindakan yang mungkin untuk agen.
Pendekatan ini sangat sederhana sehingga seluruh siklus Sense / Think / Act hampir tidak terlihat. Tapi dia adalah:
- Bagian Sense terdiri dari dua pernyataan if. Permainan tahu di mana bola berada dan di mana platform berada, jadi AI menoleh ke sana untuk informasi ini.
- Bagian Think juga hadir dalam dua pernyataan if. Mereka mewujudkan dua solusi, yang dalam hal ini saling eksklusif. Akibatnya, salah satu dari tiga tindakan dipilih - pindahkan platform ke kiri, pindah ke kanan, atau tidak melakukan apa-apa jika sudah diposisikan dengan benar.
- Bagian Act ada di pernyataan Move Paddle Left dan Move Paddle Right. Tergantung pada desain gim, mereka dapat memindahkan platform secara instan atau dengan kecepatan tertentu.
Pendekatan semacam itu disebut reaktif - ada seperangkat aturan sederhana (dalam hal ini, jika pernyataan dalam kode) yang merespons keadaan dunia saat ini dan bertindak.
Pohon keputusan
Contoh Pong sebenarnya sama dengan konsep AI formal yang disebut pohon keputusan. Algoritma melewatinya untuk mencapai "daun" - keputusan tentang tindakan apa yang harus diambil.
Mari kita buat diagram blok pohon keputusan untuk algoritme platform kami:
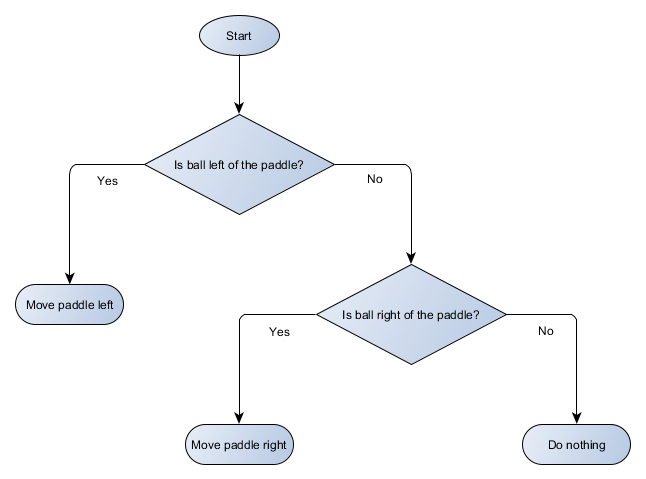
Setiap bagian dari pohon disebut node - AI menggunakan teori grafik untuk menggambarkan struktur tersebut. Ada dua jenis node:
- Node keputusan: memilih antara dua alternatif berdasarkan pengecekan kondisi tertentu di mana setiap alternatif disajikan sebagai simpul yang terpisah.
- Akhir node: Suatu tindakan untuk melakukan yang mewakili keputusan akhir.
Algoritma dimulai dengan simpul pertama ("root" dari pohon). Ia memutuskan simpul anak mana yang akan dituju, atau melakukan tindakan yang disimpan dalam simpul tersebut dan selesai.
Apa keuntungannya jika pohon keputusan melakukan pekerjaan yang sama dengan pernyataan if di bagian sebelumnya? Di sini ada sistem umum di mana setiap solusi hanya memiliki satu kondisi dan dua hasil yang mungkin. Ini memungkinkan pengembang untuk membuat AI dari data yang mewakili keputusan di pohon, menghindari hardcoding-nya. Bayangkan dalam bentuk tabel:
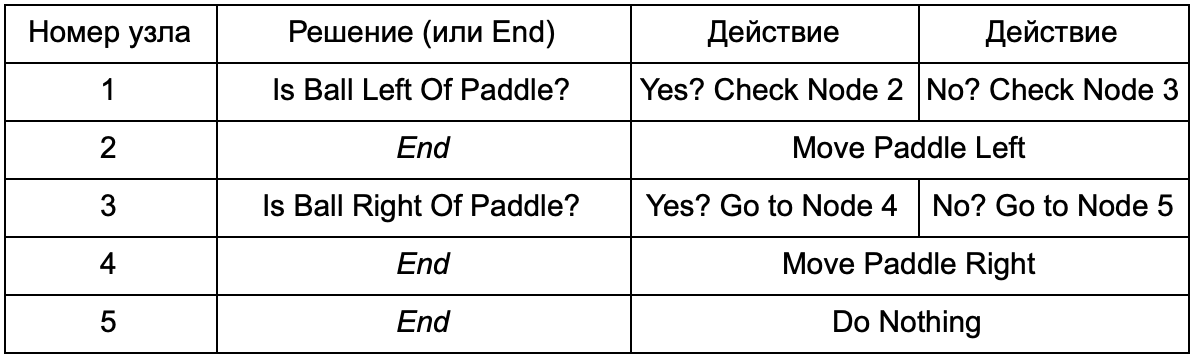
Di sisi kode, Anda mendapatkan sistem untuk membaca string. Buat simpul untuk masing-masing dari mereka, hubungkan logika keputusan berdasarkan kolom kedua dan simpul anak berdasarkan kolom ketiga dan keempat. Anda masih perlu memprogram kondisi dan tindakan, tetapi sekarang struktur permainan akan lebih rumit. Di dalamnya, Anda menambahkan keputusan dan tindakan tambahan, lalu mengonfigurasi seluruh AI dengan hanya mengedit file teks dengan definisi hierarki. Selanjutnya, transfer file ke desainer game yang dapat mengubah perilaku tanpa mengkompilasi ulang game dan mengubah kode.
Decision tree sangat berguna ketika mereka dibangun secara otomatis berdasarkan sejumlah besar contoh (misalnya, menggunakan algoritma ID3). Ini menjadikannya alat yang efektif dan berkinerja tinggi untuk mengklasifikasikan situasi berdasarkan data yang diterima. Namun, kami melampaui sistem sederhana bagi agen untuk memilih tindakan.
Skenario
Kami membongkar sistem pohon keputusan yang menggunakan kondisi dan tindakan yang telah dibuat sebelumnya. Perancang AI dapat mengatur pohon seperti yang diinginkannya, tetapi ia masih harus bergantung pada pembuat enkode yang memprogram semuanya. Bagaimana jika kita bisa memberikan alat perancang untuk menciptakan kondisi atau tindakan kita sendiri?
Untuk mencegah programmer dari menulis kode untuk Is Ball Left Of Paddle dan Is Ball Right Of Paddle, ia dapat membuat sistem di mana perancang akan mencatat kondisi untuk memeriksa nilai-nilai ini. Maka data dari pohon keputusan akan terlihat seperti ini:
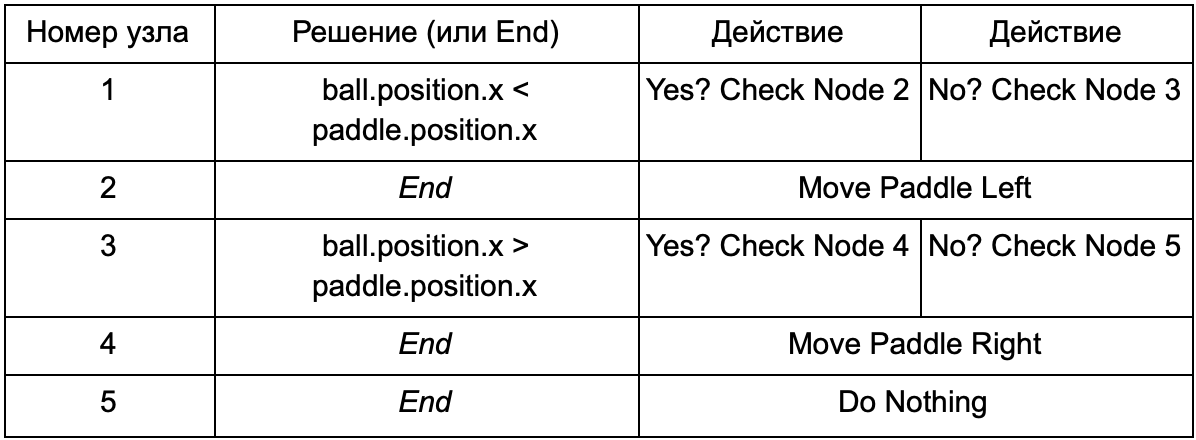
Pada dasarnya, ini sama dengan pada tabel pertama, tetapi solusi di dalam dirinya memiliki kode sendiri, sedikit mirip dengan bagian kondisional dari pernyataan if. Di sisi kode, ini akan dibaca di kolom kedua untuk node keputusan, tetapi alih-alih mencari kondisi tertentu untuk dipenuhi (Apakah Ball Left Of Paddle), itu mengevaluasi ekspresi bersyarat dan mengembalikan benar atau salah, masing-masing. Ini dilakukan dengan menggunakan bahasa skrip Lua atau Angelscript. Dengan menggunakannya, pengembang dapat mengambil objek dalam gimnya (bola dan dayung) dan membuat variabel yang akan tersedia dalam skrip (bola.posisi). Selain itu, bahasa skrip lebih sederhana daripada C ++. Itu tidak memerlukan tahap kompilasi penuh, oleh karena itu sangat cocok untuk penyesuaian cepat logika game dan memungkinkan "non-coders" untuk membuat fungsi yang diperlukan sendiri.
Dalam contoh di atas, bahasa skrip hanya digunakan untuk mengevaluasi ekspresi kondisional, tetapi juga dapat digunakan untuk tindakan. Misalnya, data Move Paddle Right dapat menjadi pernyataan skrip (ball.position.x + = 10). Sehingga aksinya juga didefinisikan dalam skrip, tanpa perlu pemrograman Move Paddle Right.
Anda dapat melangkah lebih jauh dan menulis pohon keputusan lengkap dalam bahasa scripting. Ini akan menjadi kode dalam bentuk pernyataan bersyarat hardcoded, tetapi mereka akan berlokasi di file skrip eksternal, yaitu, mereka dapat diubah tanpa mengkompilasi ulang seluruh program. Seringkali, Anda dapat mengubah file skrip secara langsung selama permainan untuk dengan cepat menguji berbagai reaksi AI.
Respon acara
Contoh di atas sempurna untuk Pong. Mereka terus-menerus menjalankan siklus Sense / Think / Act dan bertindak berdasarkan kondisi terkini dunia. Namun dalam gim yang lebih kompleks, Anda perlu merespons acara individual, dan tidak mengevaluasi semuanya sekaligus. Pong sudah menjadi contoh yang tidak berhasil. Pilih yang lain.
Bayangkan seorang penembak di mana musuh tidak bergerak sampai mereka menemukan pemain, setelah itu mereka bertindak tergantung pada "spesialisasi" mereka: seseorang akan berlari untuk "menghancurkan", seseorang akan menyerang dari jauh. Ini masih merupakan sistem responsif dasar - “jika pemain diperhatikan, maka lakukan sesuatu” - tetapi secara logis dapat dibagi menjadi peristiwa Player Seen (pemain diperhatikan) dan reaksinya (pilih jawaban dan jalankan).
Ini membawa kita kembali ke siklus Sense / Think / Act. Kami dapat menyandikan bagian Sense, yang setiap frame akan memeriksa untuk melihat apakah AI pemain terlihat. Jika tidak, tidak ada yang terjadi, tetapi jika dilihat, maka acara Player Seen dimunculkan. Kode akan memiliki bagian terpisah yang mengatakan: "ketika peristiwa Player Seen terjadi, lakukan itu", di mana jawaban yang Anda butuhkan untuk merujuk ke bagian Think and Act. Dengan demikian, Anda akan mengatur reaksi terhadap peristiwa Player Seen: ChargeAndAttack untuk karakter "berkembang", dan HideAndSnipe untuk sniper. Hubungan ini dapat dibuat dalam file data untuk diedit cepat tanpa harus mengkompilasi ulang. Dan di sini Anda juga bisa menggunakan bahasa scripting.
Membuat keputusan yang sulit
Meskipun sistem reaksi sederhana sangat efektif, ada banyak situasi ketika mereka tidak cukup. Terkadang perlu untuk membuat berbagai keputusan berdasarkan apa yang dilakukan agen saat ini, tetapi sulit untuk membayangkan ini sebagai suatu kondisi. Terkadang ada terlalu banyak kondisi untuk secara efektif mewakilinya dalam pohon keputusan atau naskah. Terkadang Anda perlu melakukan pra-evaluasi bagaimana situasi akan berubah sebelum memutuskan langkah selanjutnya. Memecahkan masalah ini membutuhkan pendekatan yang lebih canggih.
Mesin keadaan terbatas
Mesin keadaan terbatas atau FSM (mesin negara) adalah cara untuk mengatakan bahwa agen kami saat ini berada di salah satu dari beberapa kemungkinan keadaan, dan bahwa ia dapat berpindah dari satu kondisi ke kondisi lainnya. Ada sejumlah negara tertentu - karenanya namanya. Contoh kehidupan terbaik adalah lampu lalu lintas. Di tempat yang berbeda urutan cahaya yang berbeda, tetapi prinsipnya sama - masing-masing negara mewakili sesuatu (berdiri, pergi, dll). Lampu lalu lintas hanya dalam satu keadaan pada waktu tertentu, dan bergerak dari satu ke yang lain berdasarkan aturan sederhana.
Dengan NPC dalam game, cerita serupa. Misalnya, berhati-hatilah dengan kondisi berikut:
- Patroli
- Menyerang
- Melarikan diri
Dan kondisi seperti itu untuk mengubah kondisinya:
- Jika penjaga melihat musuh, dia menyerang.
- Jika penjaga menyerang, tetapi tidak lagi melihat musuh, ia kembali berpatroli.
- Jika penjaga menyerang, tetapi terluka parah, dia melarikan diri.
Anda juga dapat menulis pernyataan if dengan variabel status penjaga dan berbagai pemeriksaan: apakah ada musuh di dekatnya, berapa tingkat kesehatan NPC, dll. Mari kita tambahkan beberapa status lagi:
- Tidak ada tindakan (Pemalasan) - antara patroli.
- Search (Pencarian) - ketika musuh yang terlihat menghilang.
- Minta bantuan (Mencari Bantuan) - ketika musuh terlihat, tetapi terlalu kuat untuk bertarung sendirian dengannya.
Pilihan untuk masing-masing terbatas - misalnya, seorang penjaga tidak akan pergi mencari musuh yang bersembunyi jika kesehatannya buruk.
Pada akhirnya, daftar besar "jika <x dan y, tetapi tidak z>, maka <p>" mungkin menjadi terlalu rumit, jadi kita harus memformalkan sebuah metode yang akan memungkinkan kita untuk mengingat keadaan dan transisi antar negara. Untuk melakukan ini, kami memperhitungkan semua negara bagian, dan di bawah setiap negara bagian, kami mencantumkan semua transisi ke negara-negara lain, bersama dengan kondisi yang diperlukan untuk mereka.
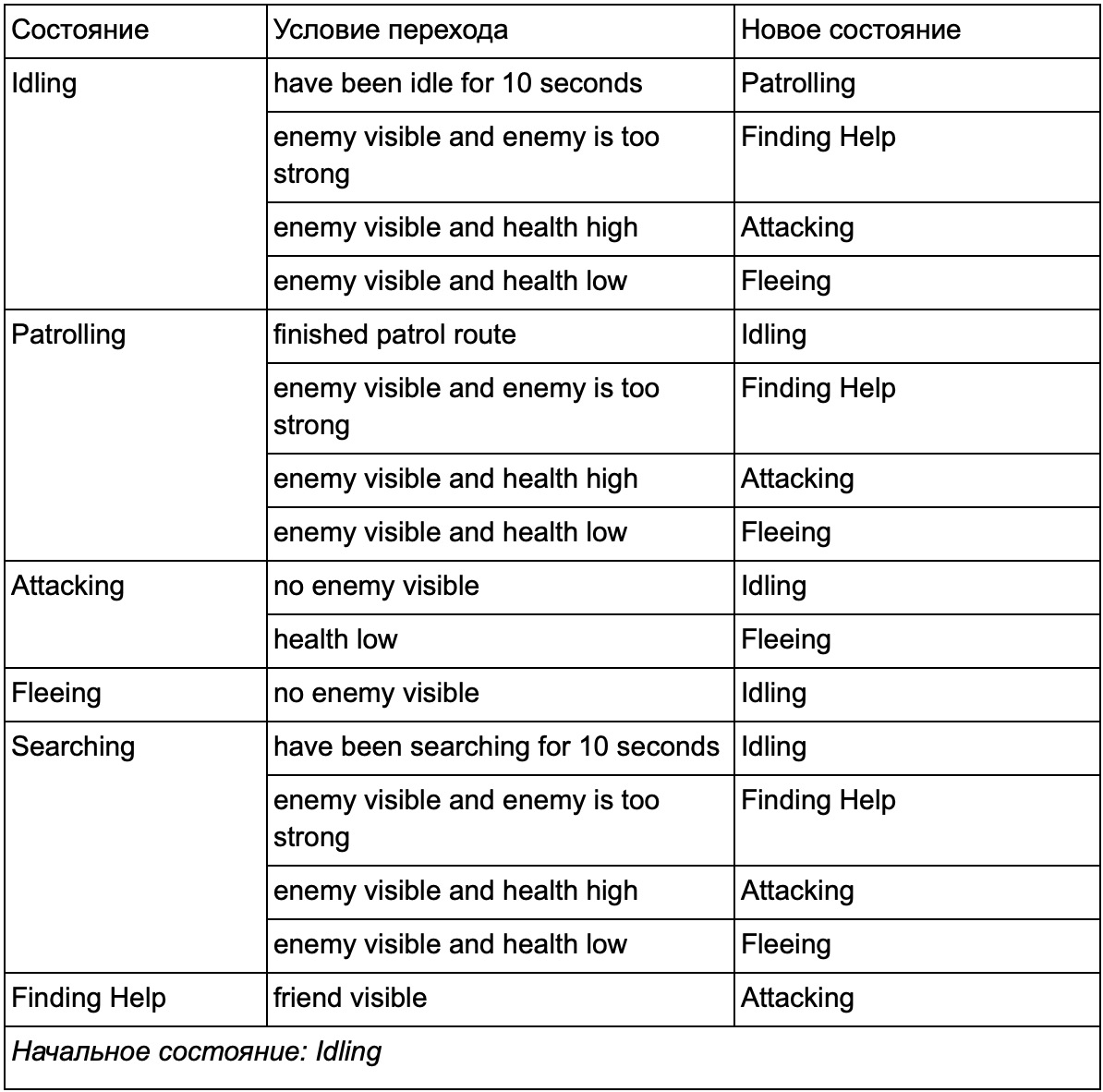
Tabel transisi negara ini adalah cara komprehensif untuk mewakili FSM. Mari menggambar diagram dan mendapatkan gambaran lengkap tentang bagaimana perilaku NPC berubah.
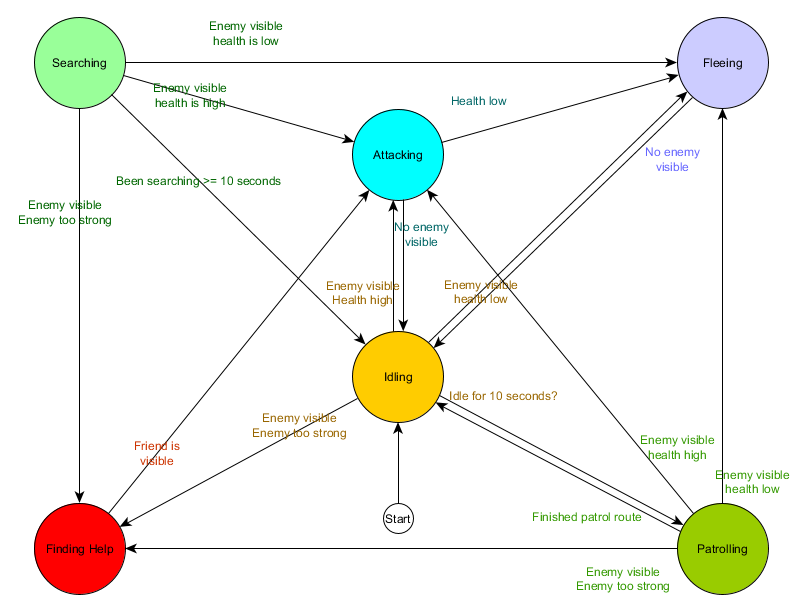
Bagan mencerminkan esensi pengambilan keputusan untuk agen ini berdasarkan situasi saat ini. Selain itu, setiap panah menunjukkan transisi antar negara jika kondisi di sebelahnya benar.
Setiap pembaruan, kami memeriksa keadaan agen saat ini, melihat daftar transisi, dan jika kondisi untuk transisi terpenuhi, dibutuhkan keadaan baru. Sebagai contoh, setiap frame memeriksa untuk melihat apakah timer 10 detik telah kedaluwarsa, dan jika demikian, penjaga beralih dari Pemalaan ke Patroli. Dengan cara yang sama, status Menyerang memeriksa kesehatan agen - jika rendah, maka status Fleeing akan hilang.
Ini menangani transisi negara, tetapi bagaimana dengan perilaku yang terkait dengan negara itu sendiri? Mengenai implementasi perilaku aktual untuk keadaan tertentu, biasanya ada dua jenis "kait" di mana kami memberikan tindakan kepada FSM:
- Tindakan kami lakukan secara berkala untuk kondisi saat ini.
- Tindakan yang kami ambil saat berpindah dari satu negara ke negara lain.
Contoh untuk tipe pertama. Keadaan patroli Setiap kerangka akan memindahkan agen di sepanjang rute patroli. Status serangan setiap frame akan mencoba memulai serangan atau masuk ke kondisi jika memungkinkan.
Untuk tipe kedua, pertimbangkan transisi "jika musuh terlihat dan musuh terlalu kuat, kemudian pergi ke negara Mencari Bantuan. Agen harus memilih ke mana harus mencari bantuan dan menyimpan informasi ini sehingga status Menemukan Bantuan tahu ke mana harus pergi. Segera setelah bantuan ditemukan, agen kembali ke status Menyerang. Pada titik ini, ia ingin memberi tahu sekutu tentang ancaman itu, sehingga tindakan NotifyFriendOfThreat dapat terjadi.
Dan lagi, kita dapat melihat sistem ini melalui prisma siklus Sense / Think / Act. Sense diterjemahkan menjadi data yang digunakan oleh logika transisi. Pikirkan - transisi tersedia di setiap negara. Dan UU dilakukan oleh tindakan yang dilakukan secara berkala di dalam negara atau pada transisi antar negara.
Kadang-kadang pemungutan suara yang berkesinambungan dari kondisi transisi bisa mahal. Misalnya, jika setiap agen melakukan perhitungan kompleks pada setiap frame untuk menentukan apakah ia melihat musuh dan memahami apakah mungkin untuk beralih dari status Patroli ke Menyerang, ini akan membutuhkan banyak waktu prosesor.
Perubahan penting dalam keadaan dunia dapat dianggap sebagai peristiwa yang akan diproses saat terjadi. Alih-alih FSM memeriksa kondisi transisi "dapatkah agen saya melihat pemain?" Setiap frame, Anda dapat mengonfigurasi sistem terpisah untuk melakukan pemeriksaan lebih jarang (misalnya, 5 kali per detik). Dan hasilnya adalah memberikan Player Seen ketika cek berlalu.
Ini diteruskan ke FSM, yang sekarang harus masuk ke kondisi Player Seen menerima kondisi dan bereaksi sesuai. Perilaku yang dihasilkan adalah sama kecuali untuk penundaan yang hampir tak terlihat sebelum menjawab. Tetapi kinerjanya menjadi lebih baik sebagai hasil dari pemisahan bagian dari Sense di bagian yang terpisah dari program.
Mesin negara hingga hirarkis
Namun, bekerja dengan FSM besar tidak selalu nyaman. Jika kita ingin memperluas status serangan dengan menggantinya dengan MeleeAttacking (melee) yang terpisah dan RangedAttacking (rentang), kita harus mengubah transisi dari semua negara lain yang mengarah ke status Menyerang (saat ini dan masa depan).
Tentunya Anda memperhatikan bahwa dalam contoh kita ada banyak duplikat transisi. Sebagian besar transisi dalam status idling identik dengan transisi dalam status patroli. Akan menyenangkan untuk tidak mengulangi, terutama jika kita menambahkan lebih banyak negara serupa. Masuk akal untuk mengelompokkan Pemalasan dan Patroli di bawah label umum "non-tempur", di mana hanya ada satu set transisi yang umum ke negara-negara tempur. Jika kami menampilkan label ini sebagai keadaan, maka Pemalasan dan Patroli akan menjadi substate. Contoh menggunakan tabel konversi terpisah untuk substrat non-tempur baru:
Kondisi utama: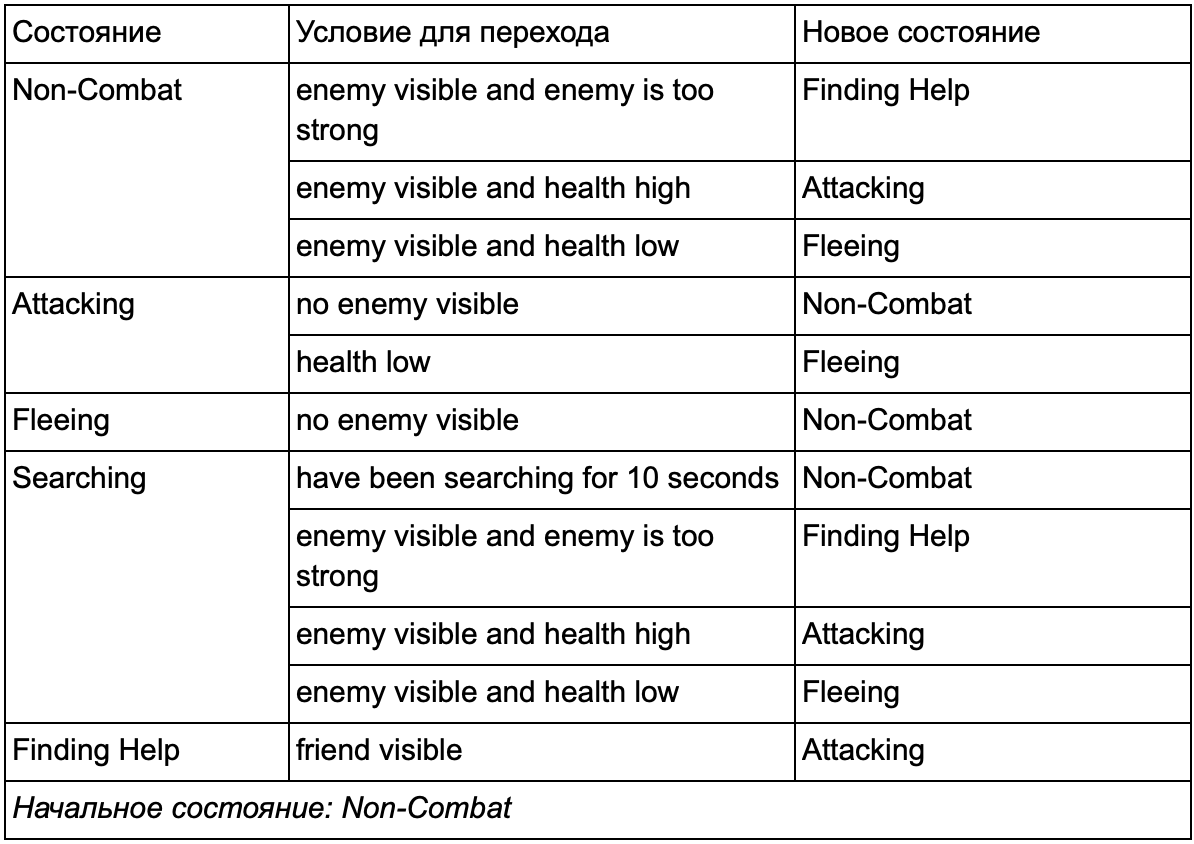 Status di luar pertempuran:
Status di luar pertempuran:
Dan dalam bentuk grafik:
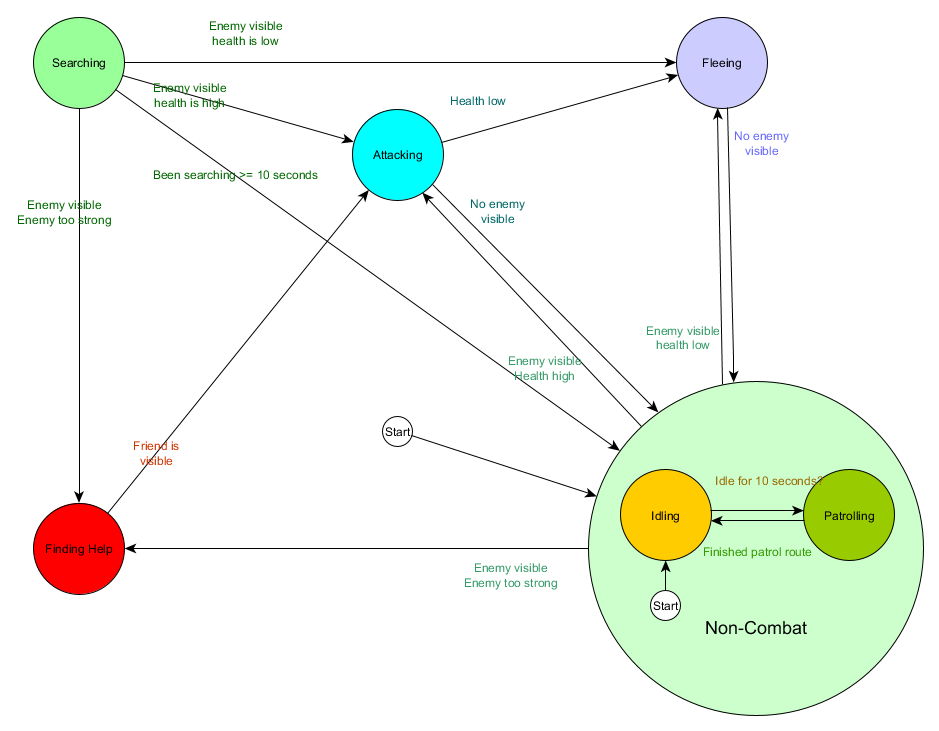
Ini adalah sistem yang sama, tetapi dengan keadaan non-tempur baru, yang mencakup Pemalasan dan Patroli. Dengan masing-masing negara bagian yang berisi FSM dengan media (dan media ini, pada gilirannya, berisi FSM mereka sendiri - dan seterusnya sebanyak yang Anda butuhkan), kami mendapatkan Mesin Status Hingga Hirarki atau HFSM (mesin status hierarkis). Setelah mengelompokkan negara non-tempur, kami memotong banyak transisi yang berlebihan. Kita dapat melakukan hal yang sama untuk setiap negara baru dengan transisi umum. Misalnya, jika di masa depan kita memperpanjang status Menyerang ke status MeleeAttacking dan MissileAttacking, mereka akan menjadi substrat yang saling bersilangan berdasarkan jarak ke musuh dan keberadaan amunisi. Sebagai hasilnya, model perilaku yang kompleks dan sub-model perilaku dapat direpresentasikan dengan minimum transisi yang digandakan.
HFSM . , , . , . . , , . , 25%, , , , — . 25% 10%, .
, « », , . .
, : «» , , , . :
- : Succeeded ( ), Failed ( ) Running ( ).
- . Decorator, . Succeed, .
- , , Running .
. HFSM :
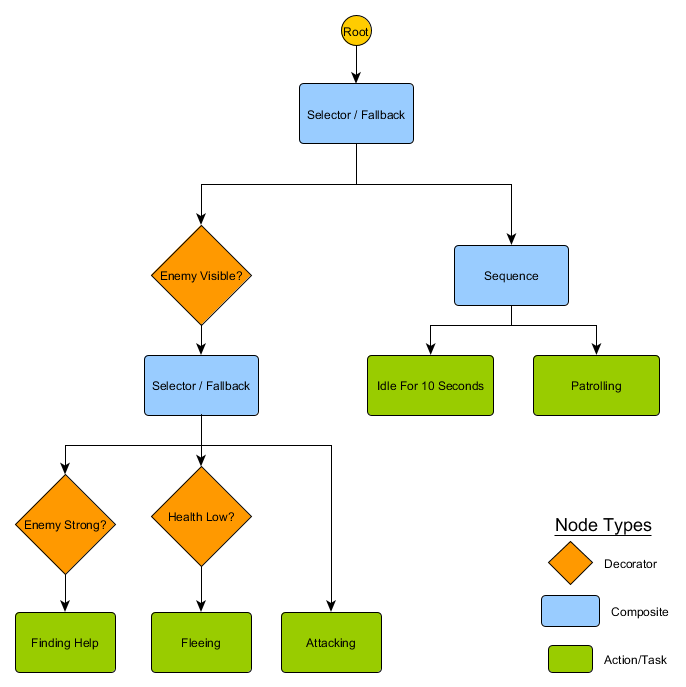
Idling/Patrolling Attacking . , , Fleeing, , — Patrolling, Idling, Attacking .
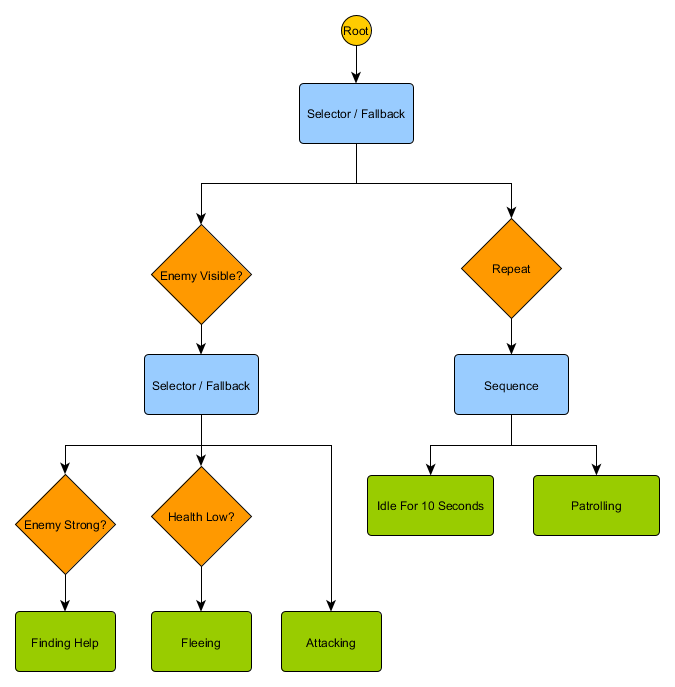
— , . , — , ? , — , Idling 10 , , ?
. , . , .
Utility-based system
. , , . , , .
Utility-based system (, ) . , , , . — , .
, . FSM, , , . , ( , ). , .
— , 0 ( ) 100 ( ). , . :

— . . , , , Fleeing, FindingHelp . FindingHelp . , 50, . .
, . . , Fleeing , , Attacking , . - Fleeing Attacking , , . , , FSM.
. . The Sims, , — «», . , , EatFood , , , EatFood .
, Utility-based system , . . , Utility , , .
, , , . ? , , , , ? .
Manajemen
, , , . , , . . Sense/Think/Act, , Think , Act . , , . — , . , , . :
desired_travel = destination_position – agent_position2D-. (-2,-2), - - (30, 20), , — (32, 22). , — 5 , (4.12, 2.83). 8 .
. , , 5 / ( ), . , .
— , , , . . steering behaviours, : Seek (), Flee (), Arrival () . . , , , .
. Seek Arrival — . Obstacle Avoidance ( ) Separation () , . Alignment () Cohesion () . steering behaviours . , Arrival, Separation Obstacle Avoidance, . .
, — , - Arrival Obstacle Avoidance. , , . : , .
, , - .
Steering behaviours ( ), — . pathfinding ( ), .
— . - , , . . , ( , ). , Breadth-First Search BFS ( ). ( breadth, «»). , , — , , .
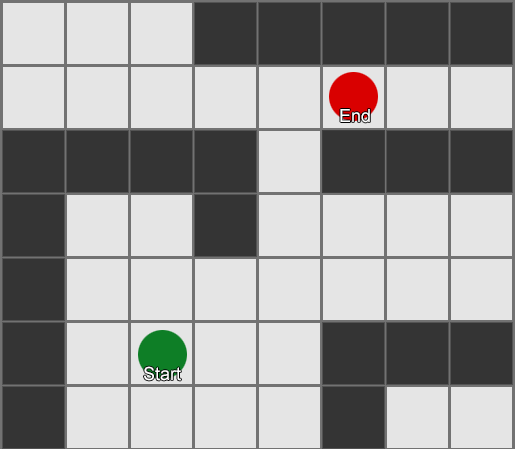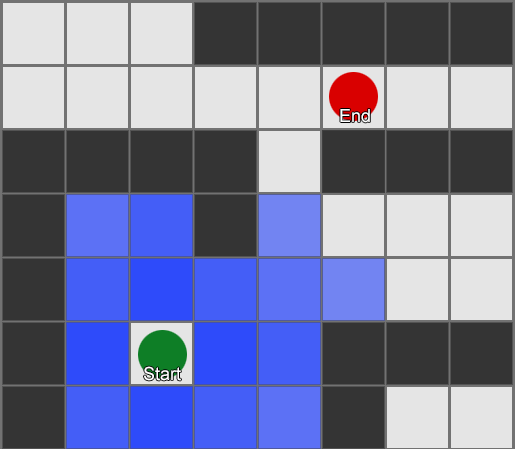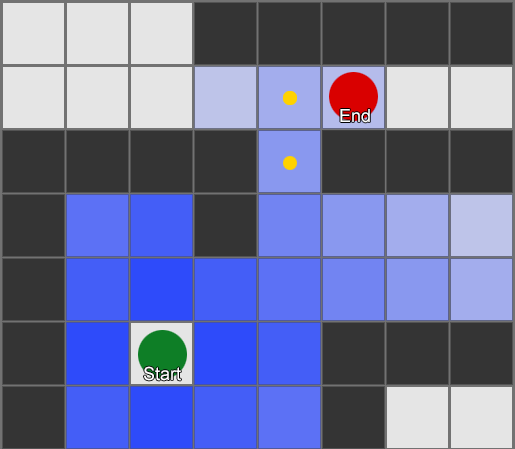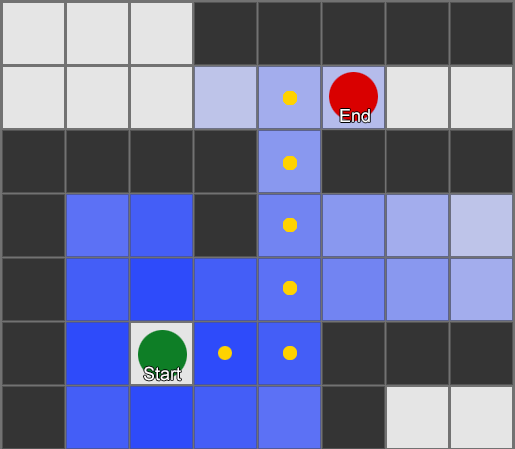
, . (, pathfinding) — , , .
, , steering behaviours, — 1 2, 2 3 . — , — . - .
BFS — «» , «». A* (A star). , - ( , ), , , . , — «» ( ) , ( ).
, , , . , BFS, — .
Tetapi sebagian besar permainan tidak diletakkan di grid, dan seringkali itu tidak dapat dilakukan tanpa mengorbankan realisme. Dibutuhkan kompromi. Berapa ukuran kotak seharusnya? Terlalu besar - dan mereka tidak akan dapat membayangkan koridor atau belokan kecil dengan benar, terlalu kecil - akan ada terlalu banyak kotak untuk dicari, yang pada akhirnya akan memakan banyak waktu.
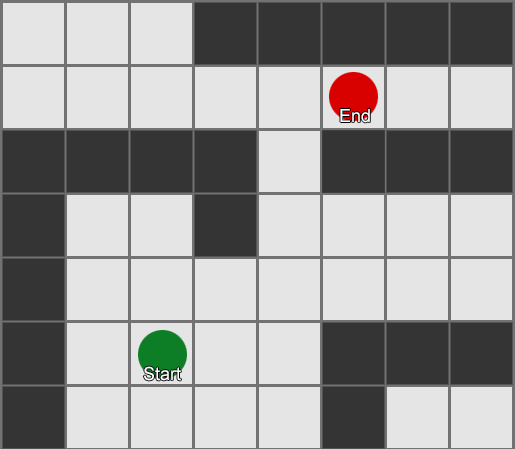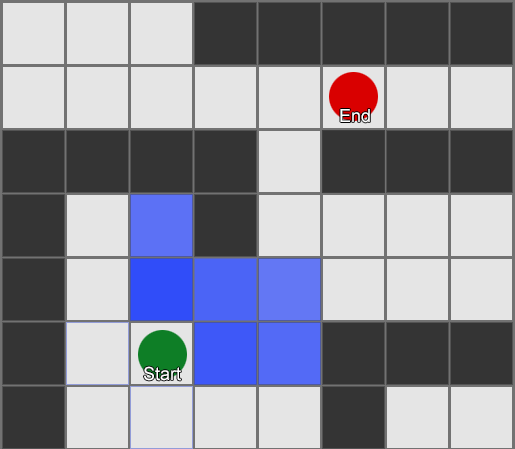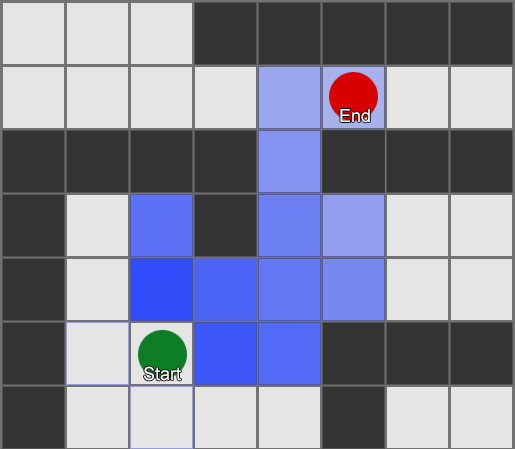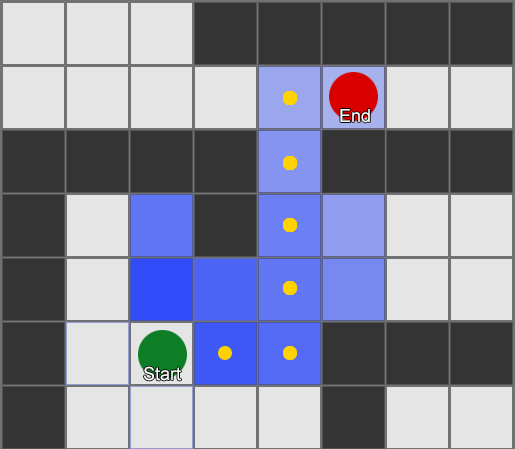
Hal pertama yang harus dipahami adalah bahwa grid memberi kita grafik dari node yang terhubung. Algoritma A * dan BFS sebenarnya bekerja pada grafik dan sama sekali tidak peduli dengan grid kami. Kita bisa meletakkan node di mana saja di dunia game: jika ada koneksi antara dua node yang terhubung, serta antara titik awal dan akhir dan setidaknya satu dari node, algoritma akan bekerja sama baiknya dengan sebelumnya. Ini sering disebut sistem waypoint, karena setiap node mewakili posisi signifikan di dunia, yang dapat menjadi bagian dari sejumlah jalur hipotetis.
 Contoh 1: simpul di setiap kotak. Pencarian dimulai dari simpul di mana agen berada, dan berakhir di simpul kuadrat yang diinginkan.
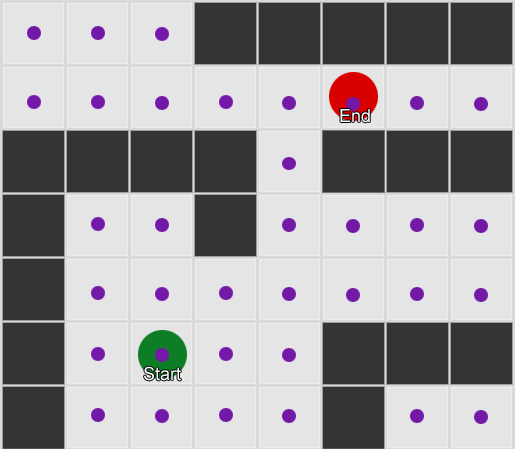
Contoh 1: simpul di setiap kotak. Pencarian dimulai dari simpul di mana agen berada, dan berakhir di simpul kuadrat yang diinginkan. Contoh 2: satu set node (waypoint) yang lebih kecil. Pencarian dimulai kuadrat dengan agen, melewati jumlah node yang diperlukan, dan kemudian melanjutkan ke tujuan.
Contoh 2: satu set node (waypoint) yang lebih kecil. Pencarian dimulai kuadrat dengan agen, melewati jumlah node yang diperlukan, dan kemudian melanjutkan ke tujuan.Ini adalah sistem yang sepenuhnya fleksibel dan kuat. Tetapi Anda perlu hati-hati dalam memutuskan di mana dan bagaimana menempatkan titik jalan, jika tidak agen mungkin tidak melihat titik terdekat dan tidak akan dapat memulai jalan. Akan lebih mudah jika kita dapat secara otomatis menetapkan titik arah berdasarkan geometri dunia.
Kemudian jala navigasi atau navmesh muncul. Biasanya ini adalah jala segitiga 2D yang menutupi geometri dunia - di mana pun agen diizinkan berjalan. Setiap segitiga dalam kisi menjadi simpul dalam grafik dan memiliki hingga tiga segitiga berdekatan yang menjadi simpul yang berdekatan dalam grafik.
Gambar ini adalah contoh dari mesin Unity - ia menganalisis geometri di dunia dan menciptakan navmesh (biru muda di tangkapan layar). Setiap poligon di navmesh adalah area di mana agen dapat berdiri atau bergerak dari satu poligon ke poligon lain. Dalam contoh ini, poligon lebih kecil dari lantai di mana mereka berada - dibuat untuk memperhitungkan dimensi agen, yang akan melampaui posisi nominalnya.

Kami dapat mencari rute melalui kisi ini, lagi-lagi menggunakan algoritma A *. Ini akan memberi kita rute yang hampir sempurna di dunia yang memperhitungkan semua geometri dan tidak memerlukan node dan titik jalan tambahan.
Pathfinding adalah topik yang terlalu luas tentang yang satu bagian dari artikel tidak cukup. Jika Anda ingin mempelajarinya secara lebih rinci, maka
situs Amit Patel akan membantu dalam hal ini.
Perencanaan
Kami memastikan dengan merintis jalan bahwa kadang-kadang tidak cukup hanya dengan memilih arah dan bergerak - kita harus memilih rute dan membuat beberapa belokan untuk mencapai tujuan yang diinginkan. Kita dapat meringkas ide ini: mencapai tujuan bukan hanya langkah berikutnya, tetapi keseluruhan urutan, di mana kadang-kadang Anda perlu melihat ke depan beberapa langkah untuk mencari tahu apa yang seharusnya. Ini disebut perencanaan. Pathfinding dapat dianggap sebagai salah satu dari beberapa penambahan perencanaan. Dari perspektif siklus Sense / Think / Act kami, di sinilah bagian Think merencanakan beberapa bagian Act untuk masa depan.
Mari kita lihat contoh permainan papan Magic: The Gathering. Kami pergi dulu dengan set kartu seperti di tangan:
- Rawa - memberikan 1 mana hitam (peta bumi).
- Hutan - memberikan 1 mana hijau (peta bumi).
- Fugitive Wizard - Membutuhkan 1 blue mana untuk memanggil.
- Elvish Mystic - Membutuhkan 1 green mana untuk memanggil.
Kami mengabaikan tiga kartu yang tersisa untuk membuatnya lebih mudah. Menurut aturan, seorang pemain diperbolehkan memainkan 1 kartu tanah per giliran, dia dapat "mengetuk" kartu ini untuk mengekstrak mana darinya, dan kemudian menggunakan mantra (termasuk makhluk pemanggilan) sesuai dengan jumlah mana. Dalam situasi ini, pemain manusia tahu bahwa Anda harus bermain Forest, "ketuk" 1 mana hijau, dan kemudian panggil Elvish Mystic. Tapi bagaimana menurut Anda game AI?
Perencanaan mudah
Pendekatan sepele adalah mencoba setiap tindakan secara bergantian sampai ada yang sesuai. Melihat kartunya, AI melihat apa yang bisa dimainkan oleh Swamp. Dan memainkannya. Apakah ada tindakan lain yang tersisa dari giliran ini? Dia tidak bisa memanggil Elvish Mystic atau Fugitive Wizard, karena panggilan mereka masing-masing membutuhkan mana hijau dan biru, dan Swamp hanya memberikan mana hitam. Dan dia tidak akan bisa bermain Forest, karena dia sudah bermain Swamp. Dengan demikian, game AI berjalan sesuai aturan, tetapi melakukannya dengan buruk. Itu bisa diperbaiki.
Perencanaan dapat menemukan daftar tindakan yang membawa game ke kondisi yang diinginkan. Sama seperti setiap kotak di jalan memiliki tetangga (dalam pencarian jalan), setiap tindakan dalam rencana juga memiliki tetangga atau penerus. Kami dapat mencari tindakan ini dan tindakan selanjutnya hingga mencapai kondisi yang diinginkan.
Dalam contoh kita, hasil yang diinginkan adalah "memanggil makhluk, jika memungkinkan." Di awal langkah, kami hanya melihat dua tindakan yang dimungkinkan oleh aturan permainan:
1. Mainkan Swamp (hasil: Swamp dalam game)
2. Mainkan Hutan (hasil: Hutan dalam game)Setiap tindakan yang diambil dapat mengarah pada tindakan lebih lanjut dan menutup tindakan lainnya, sekali lagi, tergantung pada aturan permainan. Bayangkan kita memainkan Rawa - ini akan menghapus Rawa sebagai langkah selanjutnya (kita sudah memainkannya), itu juga akan menghapus Hutan (karena menurut aturan kamu dapat memainkan satu peta tanah per giliran). Setelah itu, AI menambahkan sebagai langkah selanjutnya - mendapatkan 1 MP mana, karena tidak ada opsi lain. Jika dia melangkah lebih jauh dan memilih Ketuk Rawa, dia akan menerima 1 unit mana hitam dan tidak dapat melakukan apa-apa dengannya.
1. Mainkan Swamp (hasil: Swamp dalam game)
1.1 Rawa "Ketuk" (hasil: Rawa "ketuk", +1 unit mana hitam)
Tidak Ada Tindakan yang Tersedia - AKHIR
2. Mainkan Hutan (hasil: Hutan dalam game)Daftar tindakannya singkat, kita menemui jalan buntu. Ulangi proses untuk langkah selanjutnya. Kami bermain Forest, buka aksi "dapatkan 1 mana hijau", yang pada gilirannya akan membuka aksi ketiga - panggilan Elvish Mystic.
1. Mainkan Swamp (hasil: Swamp dalam game)
1.1 Rawa "Ketuk" (hasil: Rawa "ketuk", +1 unit mana hitam)
Tidak Ada Tindakan yang Tersedia - AKHIR
2. Mainkan Hutan (hasil: Hutan dalam game)
2.1 Hutan "Ketuk" (hasil: Hutan "ketuk", +1 unit mana hijau)
2.1.1 Memanggil Mystic Elvish (hasil: Mystic Elvish dalam game, -1 unit mana hijau)
Tidak Ada Tindakan yang Tersedia - AKHIRAkhirnya, kami memeriksa semua tindakan yang mungkin dan menemukan rencana memanggil makhluk itu.
Ini adalah contoh yang sangat sederhana. Dianjurkan untuk memilih rencana terbaik, dan tidak ada yang memenuhi beberapa kriteria. Sebagai aturan, Anda dapat mengevaluasi rencana potensial berdasarkan hasil akhir atau total manfaat dari implementasinya. Anda dapat menambahkan diri sendiri 1 poin untuk memainkan peta bumi dan 3 poin untuk menantang makhluk. Untuk memainkan Swamp akan menjadi rencana yang memberikan 1 poin. Dan untuk memainkan Forest → Ketuk Forest → memanggil Elvish Mystic - dia akan segera memberikan 4 poin.
Begitulah cara perencanaan bekerja di Magic: The Gathering, tetapi dengan logika yang sama itu berlaku dalam situasi lain. Misalnya, memindahkan pion untuk memberi ruang bagi uskup untuk bergerak dalam catur. Atau berlindung di balik dinding untuk menembak XCOM dengan aman seperti itu. Secara umum, Anda mendapatkan intinya.
Perencanaan yang lebih baik
Terkadang ada terlalu banyak tindakan potensial untuk mempertimbangkan setiap opsi yang memungkinkan. Kembali ke contoh dengan Magic: The Gathering: katakanlah dalam permainan dan di tangan Anda ada beberapa kartu tanah dan makhluk - jumlah kombinasi gerakan yang mungkin ada dalam puluhan. Ada beberapa solusi untuk masalah ini.
Cara pertama adalah chaining mundur. Daripada memilah-milah semua kombinasi, lebih baik memulai dengan hasil akhir dan mencoba menemukan rute langsung. Alih-alih jalur dari akar pohon ke daun tertentu, kami bergerak ke arah yang berlawanan - dari daun ke akar. Metode ini lebih sederhana dan lebih cepat.
Jika lawan memiliki 1 unit kesehatan, Anda dapat menemukan rencana untuk "menimbulkan 1 atau lebih unit kerusakan." Untuk mencapai ini, sejumlah persyaratan harus dipenuhi:
1. Kerusakan dapat disebabkan oleh mantra - itu harus di tangan.
2. Untuk mengucapkan mantra, Anda membutuhkan mana.
3. Untuk mendapatkan mana, Anda perlu memainkan kartu darat.
4. Untuk memainkan kartu bumi - Anda harus memilikinya di tangan Anda.
Cara lain adalah pencarian best-first. Alih-alih melewati semua jalur, kami memilih yang paling cocok. Paling sering, metode ini memberikan rencana optimal tanpa biaya pencarian yang tidak perlu. A * adalah bentuk pencarian pertama yang terbaik - menjelajahi rute yang paling menjanjikan dari awal, dia sudah dapat menemukan cara terbaik tanpa harus memeriksa opsi lain.
Pilihan yang menarik dan semakin populer untuk pencarian pertama-terbaik adalah Pencarian Pohon Monte Carlo. Alih-alih menebak rencana mana yang lebih baik daripada yang lain ketika memilih setiap tindakan berikutnya, algoritme memilih penerus acak pada setiap langkah hingga mencapai akhir (ketika rencana mengarah pada kemenangan atau kekalahan). Kemudian hasil akhir digunakan untuk menambah atau mengurangi peringkat berat dari opsi sebelumnya. Mengulangi proses ini beberapa kali berturut-turut, algoritma memberikan perkiraan yang baik tentang langkah selanjutnya yang lebih baik, bahkan jika situasinya berubah (jika lawan mengambil tindakan untuk mencegah pemain).
Kisah tentang perencanaan dalam permainan tidak akan dilakukan tanpa Goal-Oriented Action Planning atau GOAP (perencanaan tindakan berorientasi tujuan). Ini adalah metode yang banyak digunakan dan dibahas, tetapi selain beberapa detail yang berbeda, ini pada dasarnya adalah metode rantai mundur yang kita bicarakan sebelumnya. Jika tugasnya adalah "menghancurkan pemain", dan pemain berada di balik penutup, rencananya mungkin ini: hancurkan dengan granat → dapatkan → jatuhkan.
Biasanya ada beberapa tujuan, masing-masing dengan prioritasnya sendiri. Jika tujuan dengan prioritas tertinggi tidak dapat diselesaikan (tidak ada kombinasi tindakan membuat rencana untuk "menghancurkan pemain" karena pemain tidak terlihat), AI akan kembali ke target dengan prioritas yang lebih rendah.
Pelatihan dan adaptasi
Kami sudah mengatakan bahwa game AI biasanya tidak menggunakan pembelajaran mesin karena tidak cocok untuk mengelola agen secara real time. Tetapi ini tidak berarti bahwa Anda tidak dapat meminjam apa pun dari area ini. Kami ingin musuh seperti itu dalam penembak yang darinya kami bisa belajar sesuatu. Misalnya, cari tahu tentang posisi terbaik di peta. Atau musuh dalam permainan pertempuran yang akan memblokir trik kombo yang sering digunakan oleh pemain, memotivasi orang lain untuk menggunakannya. Jadi pembelajaran mesin dalam situasi seperti itu bisa sangat berguna.
Statistik dan Peluang
Sebelum kita beralih ke contoh kompleks, kami akan memperkirakan seberapa jauh kita bisa melangkah dengan mengambil beberapa pengukuran sederhana dan menggunakannya untuk membuat keputusan. Misalnya, strategi waktu-nyata - bagaimana kita dapat menentukan apakah seorang pemain dapat meluncurkan serangan dalam beberapa menit pertama pertandingan dan pertahanan apa yang harus dipersiapkan untuk melawan hal ini? Kami dapat mempelajari pengalaman masa lalu pemain untuk memahami apa reaksi di masa depan. Untuk memulainya, kami tidak memiliki data awal seperti itu, tetapi kami dapat mengumpulkannya - setiap kali ketika AI bermain melawan seseorang, ia dapat merekam waktu serangan pertama. Setelah beberapa sesi, kami akan mendapatkan waktu rata-rata dimana pemain akan menyerang di masa depan.
Nilai rata-rata memiliki masalah: jika seorang pemain "memutuskan" 20 kali dan bermain perlahan 20 kali, maka nilai yang diperlukan akan berada di suatu tempat di tengah, dan ini tidak akan memberi kita apa pun yang berguna. Salah satu solusinya adalah membatasi input - Anda dapat mempertimbangkan 20 buah terakhir.
Pendekatan serupa digunakan untuk menilai kemungkinan tindakan tertentu, dengan asumsi bahwa preferensi masa lalu pemain akan sama di masa depan. Jika seorang pemain menyerang kami lima kali dengan bola api, dua kali dengan petir dan satu kali dengan pertarungan tangan kosong, jelas bahwa ia lebih suka bola api. Kami memperkirakan dan melihat kemungkinan menggunakan berbagai senjata: bola api = 62,5%, petir = 25% dan jarak dekat = 12,5%. Game AI kami perlu bersiap untuk proteksi kebakaran.
Metode lain yang menarik adalah dengan menggunakan Naive Bayes Classifier (naive Bayesian classifier) untuk mempelajari volume besar data input dan mengklasifikasikan situasi sehingga AI merespons dengan cara yang benar. Pengklasifikasi Bayesian terkenal karena menggunakan filter spam email. Di sana, mereka meneliti kata-kata, membandingkannya dengan tempat kata-kata ini muncul sebelumnya (dalam spam atau tidak), dan menarik kesimpulan tentang surat yang masuk. Kita dapat melakukan hal yang sama bahkan dengan input yang lebih sedikit. Atas dasar semua informasi berguna yang AI lihat (misalnya, unit musuh mana yang dibuat, atau mantra apa yang mereka gunakan, atau teknologi apa yang mereka jelajahi), dan hasil akhirnya (perang atau perdamaian, "hancurkan" atau pertahankan, dll.) - kami akan memilih perilaku AI yang diinginkan.
Semua metode pelatihan ini sudah cukup, tetapi disarankan untuk menggunakannya berdasarkan data dari pengujian. AI akan belajar bagaimana beradaptasi dengan berbagai strategi yang telah digunakan penguji permainan Anda. AI yang beradaptasi dengan pemain setelah rilis dapat menjadi terlalu mudah ditebak, atau sebaliknya, terlalu rumit untuk dimenangkan.
Adaptasi Berbasis Nilai
Mengingat konten dunia permainan kami dan aturannya, kami dapat mengubah serangkaian nilai yang memengaruhi pengambilan keputusan, dan tidak hanya menggunakan data input. Kami melakukan ini:
- Biarkan AI mengumpulkan data tentang keadaan dunia dan kejadian-kejadian penting selama pertandingan (seperti yang ditunjukkan di atas).
- Mari kita ubah beberapa nilai penting berdasarkan data ini.
- Kami menyadari keputusan kami berdasarkan pada pemrosesan atau evaluasi nilai-nilai ini.
Misalnya, agen memiliki beberapa ruang untuk memilih penembak orang pertama di peta. Setiap kamar memiliki nilai tersendiri, yang menentukan seberapa diinginkannya untuk dikunjungi. AI secara acak memilih ruang mana yang akan pergi berdasarkan nilai nilai. Kemudian agen itu ingat di kamar mana dia terbunuh, dan mengurangi nilainya (probabilitas bahwa dia akan kembali ke sana). Demikian pula untuk situasi sebaliknya - jika agen menghancurkan banyak lawan, maka nilai ruangan meningkat.
Model Markov
Bagaimana jika kita menggunakan data yang dikumpulkan untuk perkiraan? Jika kita mengingat setiap ruangan tempat kita melihat pemain untuk jangka waktu tertentu, kita akan memprediksi ruang mana yang bisa digunakan pemain. Dengan melacak dan merekam pergerakan pemain di kamar (nilai), kami dapat memperkirakannya.
Mari kita ambil tiga kamar: merah, hijau dan biru. Serta pengamatan yang kami rekam saat menonton sesi permainan:
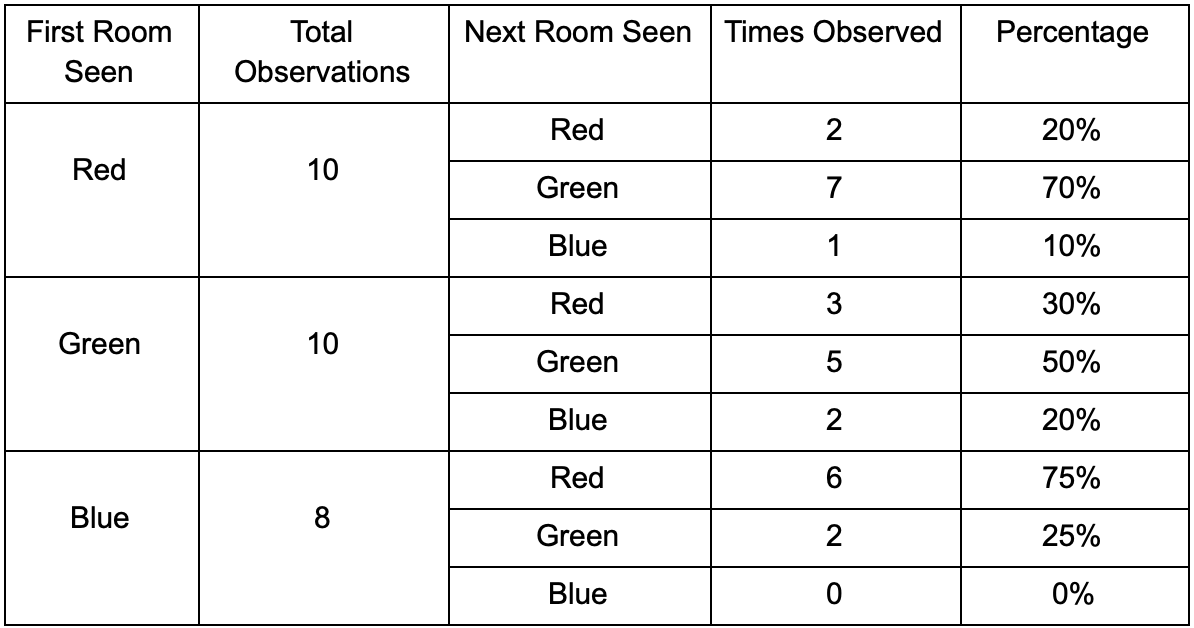
Jumlah pengamatan untuk setiap kamar hampir sama - kita masih tidak tahu di mana membuat tempat yang bagus untuk penyergapan. Pengumpulan statistik juga diperumit dengan respawn pemain yang tampil merata di seluruh peta. Tetapi data di kamar sebelah, yang mereka masukkan setelah muncul di peta, sudah berguna.
Dapat dilihat bahwa ruang hijau cocok untuk para pemain - kebanyakan orang dari merah pergi ke sana, 50% di antaranya tetap ada dan lebih jauh. Ruang biru, sebaliknya, tidak populer, hampir tidak pernah dikunjungi, dan jika ya, tidak akan bertahan lama.
Tetapi data memberi tahu kita sesuatu yang lebih penting - ketika pemain berada di ruang biru, ruang berikutnya di mana kita kemungkinan besar akan melihatnya akan berwarna merah, bukan hijau. Terlepas dari kenyataan bahwa ruang hijau lebih populer daripada yang merah, situasinya berubah jika pemain berwarna biru. Keadaan berikutnya (mis. Ruang pemain akan masuk) tergantung pada keadaan sebelumnya (mis. Kamar pemain di sekarang). Karena studi dependensi, kami akan membuat perkiraan lebih akurat daripada jika kami hanya menghitung pengamatan secara independen satu sama lain.
Memprediksi keadaan masa depan berdasarkan data keadaan masa lalu disebut model Markov, dan contoh seperti itu (dengan kamar) disebut rantai Markov. Karena model mewakili probabilitas perubahan antara negara-negara berturut-turut, mereka ditampilkan secara visual sebagai FSM dengan probabilitas di dekat setiap transisi. Sebelumnya, kami menggunakan FSM untuk mewakili keadaan perilaku di mana agen itu berada, tetapi konsep ini berlaku untuk keadaan apa pun, terlepas dari apakah itu terkait dengan agen atau tidak. Dalam hal ini, negara bagian mewakili ruangan yang ditempati oleh agen:
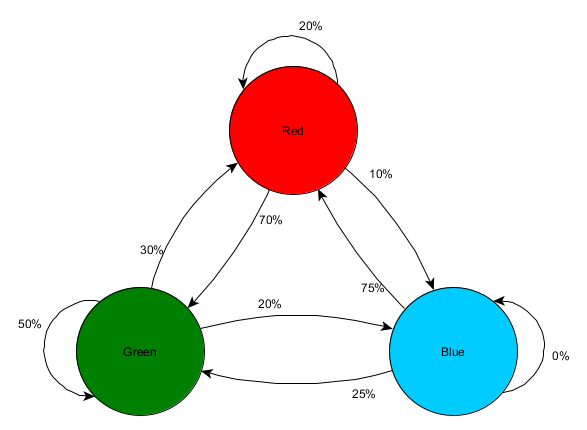
Ini adalah versi sederhana dari representasi probabilitas relatif dari perubahan di negara, memberikan AI beberapa peluang untuk memprediksi negara berikutnya. Anda dapat memprediksi beberapa langkah ke depan.
Jika pemain berada di ruang hijau, maka ada kemungkinan 50% bahwa ia akan tetap di sana selama pengamatan berikutnya. Tapi apa kemungkinan dia masih akan ada di sana bahkan setelahnya? Tidak hanya ada kemungkinan bahwa pemain tetap di ruang hijau setelah dua pengamatan, tetapi juga kesempatan bahwa dia pergi dan kembali. Ini adalah tabel baru dengan data baru:
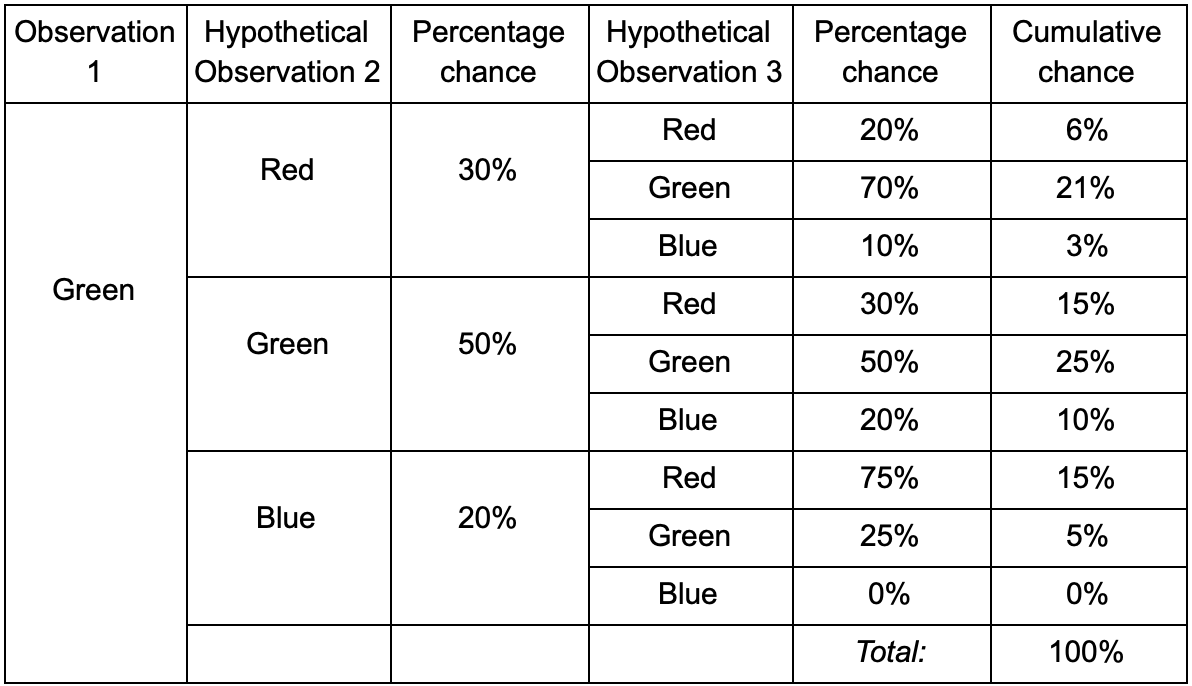
Ini menunjukkan bahwa peluang untuk melihat pemain di ruang hijau setelah dua pengamatan adalah 51% - 21%, bahwa ia akan datang dari ruang merah, 5% dari mereka, bahwa pemain akan mengunjungi ruang biru di antara mereka, dan 25%, bahwa pemain tidak akan meninggalkan ruang hijau.
Tabel hanyalah alat visual - prosedur hanya membutuhkan penggandaan probabilitas di setiap langkah. Ini berarti bahwa Anda dapat melihat jauh ke masa depan dengan satu perubahan: kami berasumsi bahwa kesempatan untuk memasuki ruangan sepenuhnya tergantung pada ruang saat ini. Ini disebut Properti Markov - negara di masa depan hanya bergantung pada saat ini. Tetapi ini tidak sepenuhnya akurat. Pemain dapat membuat keputusan tergantung pada faktor-faktor lain: tingkat kesehatan atau jumlah amunisi. Karena kami tidak memperbaiki nilai-nilai ini, perkiraan kami akan kurang akurat.
N-gram
- ? ! , , -.
— (, Kick, Punch Block) . , Kick, Kick, Punch, SuperDeathFist, , .
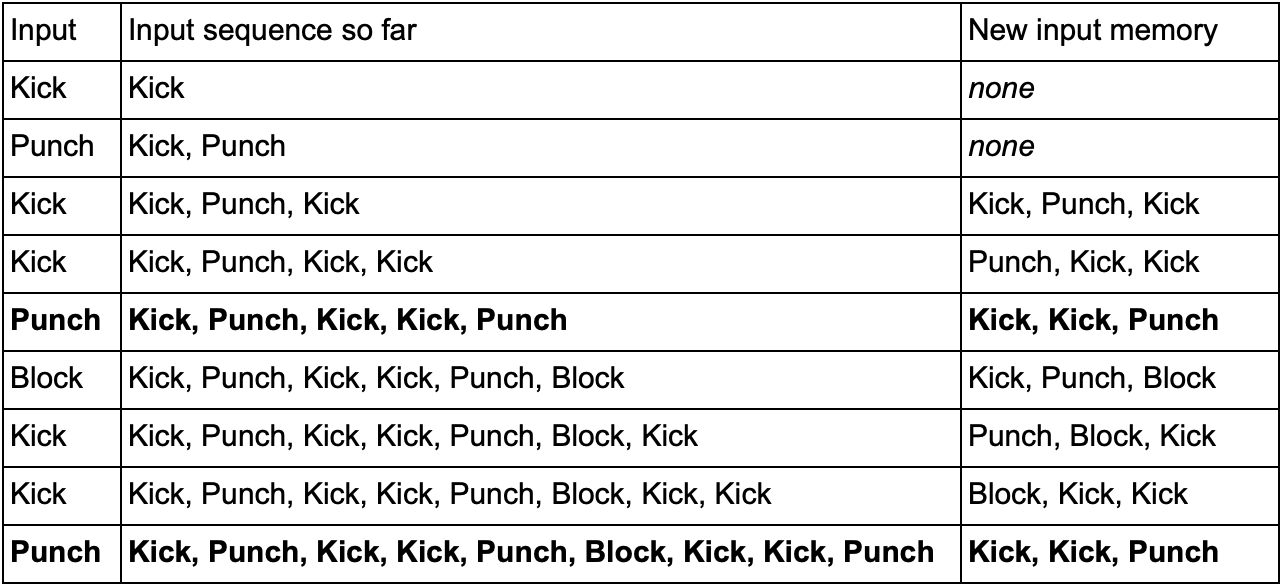
( , SuperDeathFist.)
, Kick, Kick, , Punch. - SuperDeathFist , .
N- (N-grams), N — . 3- (), : . 5- .
N-. N , . , 2- () Kick, Kick Kick, Punch, Kick, Kick, Punch, SuperDeathFist.
, , . Kick, Punch Block, 10-, 60 .
— « / » , . 3- N- , ( N-) , — . Kick Kick Kick Punch. , , , . , , - .
Kesimpulan
. , .
. , , . , :
- , ,
- / (minimax alpha-beta pruning)
- (, )
- ( , )
- ( )
- ( , anytime, timeslicing)
- :
1. GameDev.net
,
.
2.
AiGameDev.com .
3.
The GDC Vault GDC AI, .
4.
AI Game Programmers Guild .
5. , , YouTube-
AI and Games .
:
1. Game AI Pro , , .
Game AI Pro: Collected Wisdom of Game AI ProfessionalsGame AI Pro 2: Collected Wisdom of Game AI ProfessionalsGame AI Pro 3: Collected Wisdom of Game AI Professionals2. AI Game Programming Wisdom — Game AI Pro. , .
AI Game Programming Wisdom 1AI Game Programming Wisdom 2AI Game Programming Wisdom 3AI Game Programming Wisdom 43.
Artificial Intelligence: A Modern Approach — . — .