Posting sebelumnya di blog perusahaan tidak mengandung tim konsol tunggal, dan kami memutuskan untuk mengejar ketinggalan.
Perusahaan kami memiliki metrik yang dirancang untuk mencegah fakaps besar di hosting bersama. Di setiap server hosting bersama ada situs pengujian di WordPress, yang diakses secara berkala.
Ini adalah bagaimana situs pengujian terlihat pada setiap server hosting bersama
Kecepatan dan keberhasilan respons situs diukur. Setiap karyawan perusahaan dapat melihat statistik umum dan melihat seberapa baik kinerja perusahaan. Dapat melihat persentase respons yang berhasil dari situs uji untuk keseluruhan hosting atau untuk server tertentu. Tidak perlu menjadi karyawan perusahaan - di panel kontrol, pelanggan juga melihat statistik di server tempat akun mereka berada.
Kami menyebut metrik waktu aktif ini (persentase respons yang berhasil dari situs uji untuk semua permintaan ke situs uji). Bukan nama yang sangat bagus, mudah untuk membingungkan dengan uptime-yang-total-waktu-setelah-reboot-server terakhir .
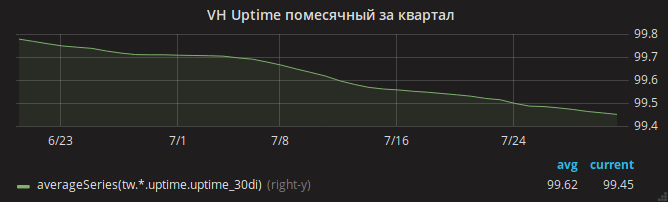
Musim panas berlalu, dan jadwal uptime perlahan turun.
Administrator segera mengidentifikasi alasan - kurangnya RAM. Mudah untuk melihat kasus OOM di log ketika server kehabisan memori dan kernel membunuh nginx.
Kepala departemen, Andrey, membagi satu tugas menjadi beberapa dengan tangan seorang penyihir dan memparalelkannya dengan administrator yang berbeda. Satu akan menganalisis pengaturan Apache - mungkin pengaturan tidak optimal dan dengan banyak lalu lintas Apache menggunakan semua memori? Analisis lain konsumsi memori mysqld - tiba-tiba ada pengaturan yang ketinggalan zaman sejak shared hosting menggunakan Gentoo OS? Yang ketiga melihat perubahan terbaru ke pengaturan nginx.
Satu per satu, administrator kembali dengan hasil. Masing-masing berhasil mengurangi konsumsi memori di area yang dialokasikan kepadanya. Dalam kasus nginx, misalnya, mod_security yang disertakan tetapi tidak digunakan terdeteksi. Sementara itu, OOM juga sering terjadi.
Akhirnya, dimungkinkan untuk memperhatikan bahwa konsumsi memori inti (khususnya, SUnreclaim) sangat besar pada beberapa server. Baik dalam output ps maupun di htop adalah parameter ini tidak terlihat, jadi kami tidak langsung menyadarinya! Contoh server dengan infern SUnreclaim:
root@vh28.timeweb.ru:~
RAM 24 gigabytes diberikan ke kernel, dan kernel menghabiskannya tanpa ada yang tahu!
Administrator (sebut saja dia Gabriel) bergegas ke pertempuran. Merakit kembali kernel dengan opsi KMEMLEAK untuk deteksi kebocoran.
Opsi untuk membangun kembaliUntuk mengaktifkan KMEMLEAK, cukup tentukan opsi yang tercantum di bawah ini dan muat kernel dengan kmemleak = pada parameter.
CONFIG_HAVE_DEBUG_KMEMLEAK=y CONFIG_DEBUG_KMEMLEAK=y CONFIG_DEBUG_KMEMLEAK_DEFAULT_OFF=y CONFIG_DEBUG_KMEMLEAK_EARLY_LOG_SIZE=10000
KMEMLEAK menulis (dalam /sys/kernel/debug/kmemleak ) baris-baris ini:
unreferenced object 0xffff88013a028228 (size 8): comm "apache2", pid 23254, jiffies 4346187846 (age 1436.284s) hex dump (first 8 bytes): 00 00 00 00 00 00 00 00 ........ backtrace: [<ffffffff818570c8>] kmemleak_alloc+0x28/0x50 [<ffffffff811d450a>] kmem_cache_alloc_trace+0xca/0x1d0 [<ffffffff8136dcc3>] apparmor_file_alloc_security+0x23/0x40 [<ffffffff81332d63>] security_file_alloc+0x33/0x50 [<ffffffff811f8013>] get_empty_filp+0x93/0x1c0 [<ffffffff811f815b>] alloc_file+0x1b/0xa0 [<ffffffff81728361>] sock_alloc_file+0x91/0x120 [<ffffffff8172b52e>] SyS_socket+0x7e/0xc0 [<ffffffff81003854>] do_syscall_64+0x54/0xc0 [<ffffffff818618ab>] return_from_SYSCALL_64+0x0/0x6a [<ffffffffffffffff>] 0xffffffffffffffff unreferenced object 0xffff880d67030280 (size 624): comm "hrrb", pid 23713, jiffies 4346190262 (age 1426.620s) hex dump (first 32 bytes): 01 00 00 00 03 00 ff ff 00 00 00 00 00 00 00 00 ................ 00 e7 1a 06 10 88 ff ff 00 81 76 6e 00 88 ff ff ..........vn.... backtrace: [<ffffffff818570c8>] kmemleak_alloc+0x28/0x50 [<ffffffff811d4337>] kmem_cache_alloc+0xc7/0x1d0 [<ffffffff8172a25d>] sock_alloc_inode+0x1d/0xc0 [<ffffffff8121082d>] alloc_inode+0x1d/0x90 [<ffffffff81212b01>] new_inode_pseudo+0x11/0x60 [<ffffffff8172952a>] sock_alloc+0x1a/0x80 [<ffffffff81729aef>] __sock_create+0x7f/0x220 [<ffffffff8172b502>] SyS_socket+0x52/0xc0 [<ffffffff81003854>] do_syscall_64+0x54/0xc0 [<ffffffff818618ab>] return_from_SYSCALL_64+0x0/0x6a [<ffffffffffffffff>] 0xffffffffffffffff
Gabriel tidak mengungkapkan semua rahasianya kepada kami dan tidak memberi tahu bagaimana ia dari baris di atas mengetahui penyebab pasti dari kebocoran memori. Kemungkinan besar, ia menggunakan perintah addr2line /usr/lib/debug/lib/modules/`uname -r`/vmlinux ffffffff81722361 untuk menemukan baris yang tepat. Atau hanya membuka file net/socket.c dan melihatnya sampai file menjadi tidak nyaman.
Masalahnya ternyata adalah tambalan pada file net/socket.c , yang telah ditambahkan ke repositori kami beberapa tahun yang lalu. Tujuannya adalah untuk melarang klien menggunakan panggilan sistem bind (), ini adalah perlindungan sederhana terhadap server proxy yang dimulai oleh klien. Patch memenuhi tujuannya, tetapi tidak menghapus memori setelahnya.
Mungkin ada malware modis baru di PHP yang mencoba menjalankan server proxy dalam satu lingkaran - yang menyebabkan ratusan ribu panggilan bind () yang diblokir dan kehilangan RAM gigabytes.
Maka itu sederhana - Gabriel memperbaiki patch dan membangun kembali kernel. Penambahan pemantauan nilai SUnreclaim pada semua server yang menjalankan Linux. Insinyur memperingatkan pelanggan dan memulai kembali hosting di inti baru.
OOM menghilang.
Tetapi masalah dengan ketersediaan situs tetap
Di semua server, situs pengujian berhenti merespons beberapa kali sehari.
Di sini, penulis akan mulai merobek rambut di berbagai bagian tubuh. Tetapi Gabriel tetap tenang dan menyalakan rekaman lalu lintas ke bagian-bagian dari server hosting.
Dalam dump lalu lintas, terlihat bahwa paling sering permintaan ke situs uji jatuh setelah penerimaan tiba-tiba paket TCP RST . Dengan kata lain, permintaan mencapai server, tetapi koneksi akhirnya terputus oleh nginx.
Lebih jauh lebih menarik! Utilitas strace yang diluncurkan oleh Gabriel menunjukkan bahwa daemon nginx tidak mengirim paket ini. Bagaimana ini bisa terjadi, karena hanya nginx yang mendengarkan pada port 80?
Alasannya adalah kombinasi dari beberapa faktor:
- dalam pengaturan nginx, opsi
reuseport (termasuk SO_REUSEPORT soket SO_REUSEPORT ), yang memungkinkan berbagai proses menerima koneksi pada alamat dan port yang sama - di (pada saat itu, versi terbaru) dari nginx 1.13.0 terdapat bug yang ketika memulai tes konfigurasi
nginx -t melalui nginx -t dan menggunakan SO_REUSEPORT proses pengujian nginx ini benar-benar mulai mendengarkan port 80 dan mencegat permintaan dari klien nyata . Dan pada akhir proses pengujian konfigurasi, klien menerima Connection reset by peer - akhirnya, dalam memantau zabbix, pemantauan kebenaran konfigurasi nginx dikonfigurasikan pada semua server dengan nginx terinstal: perintah
nginx -t dipanggil pada mereka sekali dalam satu menit.
Hanya setelah memperbarui nginx Anda dapat bernapas dengan tenang. Grafik uptime situs telah naik.
Apa moral dari keseluruhan cerita ini? Jadilah optimis dan hindari menggunakan kernel rakitan.