Mempertahankan basis kode yang besar sambil memastikan produktivitas tinggi untuk sejumlah besar pengembang adalah tantangan serius. Selama 5 tahun terakhir, Yandex telah mengembangkan sistem khusus untuk integrasi berkelanjutan. Pada artikel ini, kita akan berbicara tentang skala basis kode Yandex, tentang mentransfer pengembangan ke repositori tunggal dengan pendekatan berbasis trunk untuk pengembangan, tentang tugas-tugas apa yang harus dipecahkan oleh sistem integrasi berkelanjutan untuk bekerja secara efektif dalam kondisi seperti itu.

Bertahun-tahun yang lalu, Yandex tidak memiliki aturan khusus dalam pengembangan layanan: setiap departemen dapat menggunakan bahasa apa pun, teknologi apa pun, sistem penyebaran apa pun. Dan seperti yang telah ditunjukkan oleh praktik, kebebasan seperti itu tidak selalu membantu untuk bergerak maju lebih cepat. Pada saat itu, untuk menyelesaikan masalah yang sama, sering kali ada beberapa pengembangan kepemilikan atau sumber terbuka. Ketika perusahaan tumbuh, ekosistem seperti itu bekerja lebih buruk. Pada saat yang sama, kami ingin tetap menjadi Yandex yang besar, dan tidak terpecah menjadi banyak perusahaan independen, karena memberikan banyak keuntungan: banyak orang melakukan tugas yang sama, hasil pekerjaan mereka dapat digunakan kembali. Mulai dari berbagai struktur data, seperti tabel hash yang didistribusikan dan antrian bebas kunci, dan diakhiri dengan banyak kode khusus berbeda yang telah kami tulis selama 20 tahun.
Banyak tugas yang kami selesaikan tidak selesaikan di dunia open-source. Tidak ada MapReduce yang berfungsi dengan baik pada volume kami (5000+ server) dan tugas kami, tidak ada pelacak tugas yang dapat menangani semua puluhan juta tiket kami. Ini menarik di Yandex - Anda dapat melakukan hal-hal hebat.
Tetapi kami benar-benar kehilangan efisiensi ketika kami memecahkan masalah yang sama lagi, mengulang solusi yang sudah jadi, membuat integrasi antar komponen menjadi sulit. Adalah baik dan nyaman untuk melakukan segalanya hanya untuk diri Anda sendiri di sudut Anda sendiri, Anda tidak dapat memikirkan orang lain untuk saat ini. Tetapi begitu layanan menjadi cukup nyata, ia akan memiliki dependensi. Tampaknya hanya berbagai layanan lemah saling bergantung satu sama lain, pada kenyataannya - ada banyak koneksi antara berbagai bagian perusahaan. Banyak layanan yang tersedia melalui aplikasi Yandex / Browser / dll., Atau saling melekat satu sama lain. Misalnya, Alice muncul di Browser, menggunakan Alice Anda dapat memesan Taksi. Kita semua menggunakan komponen umum: YT , YQL , Nirvana .
Model pembangunan lama memiliki masalah yang signifikan. Karena adanya banyak repositori, sulit bagi pengembang biasa, terutama pemula, untuk mencari tahu:
- dimana komponennya?
- cara kerjanya: tidak ada cara untuk "mengambil dan membaca"
- Siapa yang mengembangkan dan mendukungnya sekarang?
- bagaimana cara menggunakannya?
Akibatnya, masalah saling menggunakan komponen muncul. Komponen hampir tidak dapat menggunakan komponen lain karena mereka mewakili "kotak hitam" satu sama lain. Ini berdampak negatif bagi perusahaan, karena komponen tidak hanya tidak digunakan kembali, tetapi sering juga tidak membaik. Banyak komponen digandakan, jumlah kode yang harus didukung tumbuh secara signifikan. Kami umumnya bergerak lebih lambat dari yang kami bisa.
Repositori dan infrastruktur tunggal
5 tahun yang lalu, kami memulai proyek untuk mentransfer pengembangan ke repositori tunggal, dengan sistem umum untuk perakitan, pengujian, penyebaran, dan pemantauan.
Tujuan utama yang ingin kami capai adalah untuk menghilangkan hambatan yang mencegah integrasi kode orang lain. Sistem harus menyediakan akses mudah ke kode kerja yang sudah jadi, skema yang jelas untuk koneksi dan penggunaannya, kolektibilitas: proyek selalu dikumpulkan (dan lulus tes).
Sebagai hasil dari proyek, setumpuk teknologi infrastruktur untuk perusahaan muncul: penyimpanan kode sumber, sistem peninjauan kode, sistem pembangunan, sistem integrasi berkelanjutan, penyebaran, pemantauan.
Sekarang sebagian besar kode sumber untuk proyek Yandex disimpan dalam repositori tunggal, atau sedang dalam proses pindah ke sana:
- Lebih dari 2000 pengembang mengerjakan proyek.
- lebih dari 50.000 proyek dan perpustakaan.
- Ukuran repositori melebihi 25 GB.
- Lebih dari 3.000.000 komit telah dikomit ke repositori.
Plus untuk perusahaan:
- proyek apa pun dari repositori menerima infrastruktur siap pakai:
- sistem untuk melihat dan menavigasi kode sumber dan sistem tinjauan kode.
- sistem perakitan dan perakitan terdistribusi. Ini adalah topik besar yang terpisah, dan kami pasti akan membahasnya dalam artikel berikut.
- sistem integrasi berkelanjutan.
- penyebaran, integrasi dengan sistem pemantauan.
- berbagi kode, interaksi tim aktif.
- semua kode adalah umum, Anda dapat datang ke proyek lain dan membuat perubahan yang Anda butuhkan di sana. Ini sangat penting dalam sebuah perusahaan besar, karena tim lain tempat Anda membutuhkan sesuatu mungkin tidak memiliki sumber daya. Dengan kode umum, Anda memiliki kesempatan untuk melakukan bagian dari pekerjaan sendiri dan “membantu terjadi” perubahan yang Anda butuhkan.
- Ada peluang untuk melakukan refactoring global. Anda tidak perlu mendukung versi lama API atau pustaka Anda, Anda dapat mengubahnya dan mengubah tempat di mana mereka digunakan dalam proyek lain.
- kode menjadi kurang "beragam." Anda memiliki serangkaian cara untuk menyelesaikan masalah, dan tidak perlu menambahkan cara lain untuk melakukan hal yang sama, tetapi dengan sedikit perbedaan.
- dalam proyek di sebelah Anda, kemungkinan besar, tidak akan ada bahasa dan perpustakaan yang benar-benar eksotis.
Juga harus dipahami bahwa model pengembangan tersebut memiliki kelemahan yang perlu dipertimbangkan:
- Repositori bersama membutuhkan infrastruktur terpisah dan spesifik.
- perpustakaan yang Anda butuhkan mungkin tidak ada di repositori, tetapi perpustakaan itu dalam open-source. Ada biaya untuk menambah dan memperbaruinya. Sangat tergantung pada bahasa dan perpustakaan, di suatu tempat yang hampir gratis, di suatu tempat yang sangat mahal.
- Anda harus terus bekerja pada "kesehatan" kode. Ini termasuk setidaknya perang melawan dependensi yang tidak perlu dan kode mati.
Pendekatan kami terhadap repositori umum memberlakukan aturan umum yang harus diikuti semua orang. Dalam hal menggunakan repositori tunggal, pembatasan ditempatkan pada bahasa yang digunakan, perpustakaan, dan metode penyebaran. Tetapi dalam proyek tetangga semuanya akan sama atau sangat mirip dengan milik Anda, dan Anda bahkan dapat memperbaiki sesuatu di sana.
Model repositori yang sama berlaku untuk semua perusahaan besar. Repositori monolitik adalah topik yang besar dan telah dipelajari dan dibahas dengan baik, jadi sekarang kita tidak akan membahasnya terlalu banyak. Jika Anda ingin tahu lebih banyak, maka di akhir artikel Anda akan menemukan beberapa tautan bermanfaat yang mengungkapkan topik ini secara lebih rinci.
Kondisi di mana sistem integrasi berkelanjutan beroperasi
Pengembangan dilakukan sesuai dengan model pengembangan berbasis batang. Sebagian besar pengguna bekerja dengan HEAD, atau salinan repositori terbaru, yang diperoleh dari cabang utama yang disebut trunk, di mana pengembangan sedang berlangsung. Melakukan perubahan pada repositori dilakukan secara berurutan. Segera setelah komit, kode baru terlihat dan dapat digunakan oleh semua pengembang. Pengembangan di cabang yang terpisah tidak dianjurkan, meskipun cabang dapat digunakan untuk rilis.
Proyek tergantung pada kode sumber. Proyek dan perpustakaan membentuk grafik ketergantungan yang kompleks. Dan ini berarti bahwa perubahan yang dibuat dalam satu proyek berpotensi mempengaruhi sisa repositori.
Aliran besar komit masuk ke repositori:
- lebih dari 2000 komit per hari.
- hingga 10 perubahan per menit selama jam sibuk.
Basis kode berisi lebih dari 500.000 target dan pengujian build.
Tanpa sistem khusus integrasi berkelanjutan dalam kondisi seperti itu, akan sangat sulit untuk bergerak maju dengan cepat.
Sistem integrasi berkelanjutan
Sistem integrasi berkelanjutan meluncurkan rakitan dan pengujian untuk setiap perubahan:
- Pemeriksaan pendahuluan. Mereka mengizinkan memeriksa kode sebelum melakukan dan menghindari tes yang melanggar di bagasi. Sidang dan tes kemudian dijalankan di atas KEPALA. Saat ini, pemeriksaan pra-audit dimulai secara sukarela. Untuk proyek-proyek kritis, diperlukan pemeriksaan sebelum audit.
- Pemeriksaan pasca-komitmen setelah melakukan ke repositori.
Pembuatan dan pengujian berjalan secara paralel pada kelompok besar ratusan server. Pembuatan dan pengujian berjalan pada platform yang berbeda. Di bawah platform utama (linux), semua proyek dirakit dan semua tes dijalankan, di bawah platform lain - sebagian dari yang dapat dikonfigurasi pengguna.
Setelah menerima dan menganalisis hasil rakitan dan menjalankan tes, pengguna menerima umpan balik, misalnya, jika perubahan melanggar tes apa pun.

Jika terjadi kegagalan atau pengujian rakitan baru, kami mengirim pemberitahuan kepada pemilik tes dan pembuat perubahan. Sistem juga menyimpan dan menampilkan hasil pemeriksaan dalam antarmuka khusus. Antarmuka web sistem integrasi menampilkan progres dan hasil pengujian, dikelompokkan berdasarkan jenis pengujian. Layar dengan hasil pemindaian sekarang dapat terlihat seperti ini:
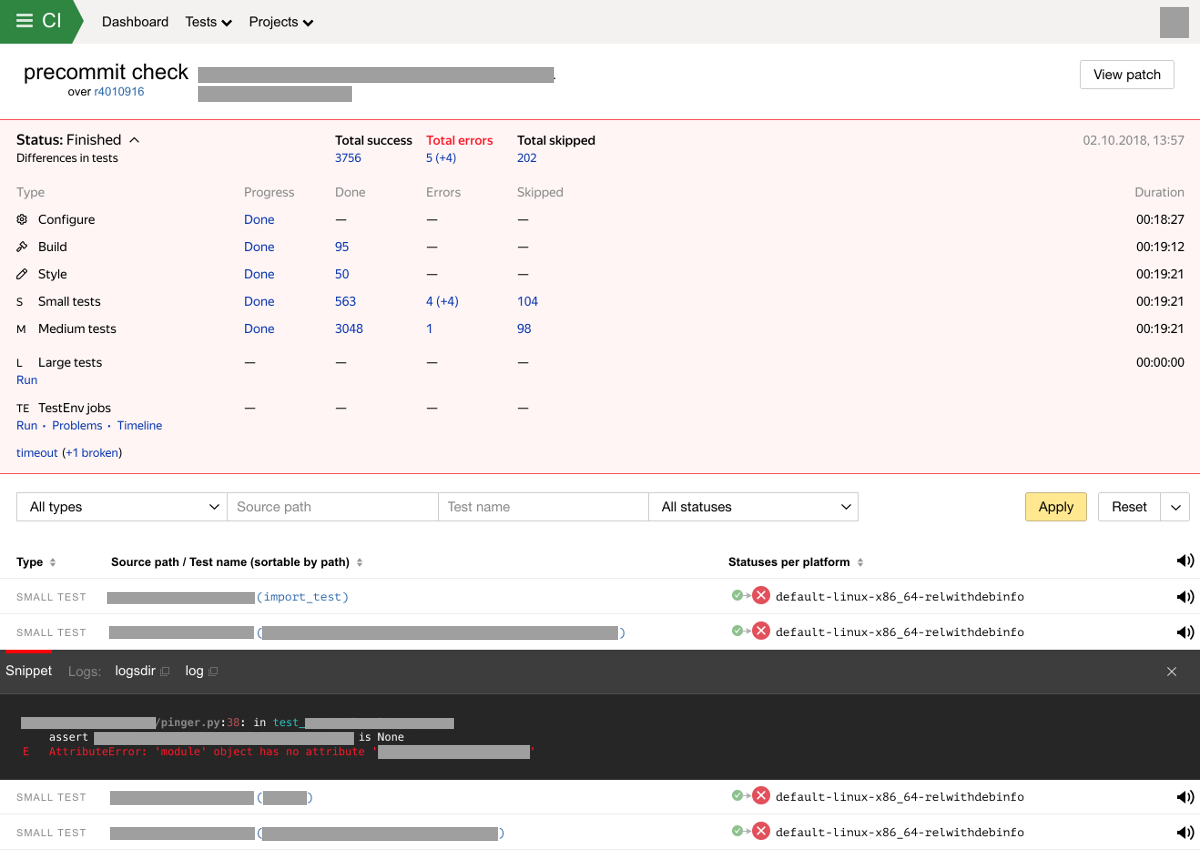
Fitur dan kemampuan sistem integrasi berkelanjutan
Memecahkan berbagai masalah yang dihadapi pengembang dan penguji, kami mengembangkan sistem integrasi berkelanjutan kami. Sistem sudah menyelesaikan banyak masalah, tetapi masih banyak yang harus diperbaiki.
Jenis dan ukuran tes
Ada beberapa jenis tujuan yang dapat dipicu oleh sistem integrasi berkelanjutan:
- konfigurasikan. Fase konfigurasi dilakukan oleh sistem build. Konfigurasi mencakup analisis file konfigurasi sistem perakitan, menentukan dependensi antara proyek dan parameter perakitan dan menjalankan tes.
- membangun. Majelis perpustakaan dan proyek.
- gaya. Pada tahap ini, gaya kode cocok dengan persyaratan yang ditentukan.
- tes. Tes dibagi menjadi beberapa tahap sesuai dengan batas waktu mereka untuk waktu kerja dan persyaratan untuk sumber daya komputasi.
- kecil. <1 mnt
- sedang. <10 mnt
- besar > 10 mnt Selain itu, mungkin ada persyaratan khusus untuk sumber daya komputasi.
- ekstra besar. Ini adalah jenis tes khusus. Pengujian tersebut dikarakteristikkan dengan serangkaian karakteristik berikut: waktu operasi yang lama, konsumsi sumber daya yang besar, sejumlah besar data input, mereka mungkin memerlukan akses khusus, dan yang paling penting, dukungan untuk skenario uji kompleks yang dijelaskan di bawah ini. Ada lebih sedikit tes semacam itu daripada jenis tes lainnya, tetapi mereka sangat penting.
Uji frekuensi peluncuran dan deteksi kesalahan biner
Sumber daya besar dialokasikan untuk pengujian di Yandex - ratusan server yang kuat. Tetapi bahkan dengan sejumlah besar sumber daya, kami tidak dapat menjalankan semua tes untuk setiap perubahan yang memengaruhi mereka. Tetapi pada saat yang sama, sangat penting bagi kami untuk selalu membantu pengembang untuk melokalkan tempat di mana tes rusak, terutama di repositori besar.
Apa yang kita lakukan Untuk setiap perubahan untuk semua proyek yang terkena dampak, rakitan, pemeriksaan gaya, dan pengujian dengan ukuran kecil dan menengah dijalankan. Sisa tes dijalankan tidak untuk setiap komit yang mempengaruhi, tetapi dengan periodisitas tertentu, jika ada komitmen yang mempengaruhi tes. Dalam beberapa kasus, pengguna dapat mengontrol frekuensi startup, dalam kasus lain, frekuensi startup diatur oleh sistem. Ketika kegagalan tes terdeteksi, proses mencari komit pemecahan dimulai. Semakin jarang tes berjalan, semakin lama kita akan mencari komit melanggar setelah kegagalan terdeteksi.

Saat memulai pemeriksaan pra-audit, kami juga menjalankan hanya rakitan dan uji ringan. Kemudian pengguna dapat secara manual memulai peluncuran tes berat dengan memilih dari daftar tes yang dipengaruhi oleh perubahan yang disediakan oleh sistem.
Deteksi Tes Berkedip
Tes Flash adalah tes yang menjalankan (Lulus / Gagal) hasil pada kode yang sama mungkin tergantung pada berbagai faktor. Penyebab tes berkedip dapat berbeda: tidur dalam kode uji, kesalahan saat bekerja dengan multithreading, masalah infrastruktur (tidak tersedianya sistem apa pun), dll. Tes berkedip menghadirkan masalah serius:
- Mereka mengarah pada kenyataan bahwa sistem integrasi terus menerus dari peringatan palsu tentang kegagalan pengujian.
- Kontaminasi hasil tes. Semakin sulit untuk memutuskan keberhasilan hasil verifikasi.
- Tunda rilis produk.
- Sulit dideteksi. Tes mungkin berkedip sangat jarang.
Pengembang dapat mengabaikan tes yang berkedip saat menganalisis hasil tes. Terkadang salah.
Tidak mungkin untuk sepenuhnya menghilangkan tes yang berkedip, ini harus diperhitungkan dalam sistem integrasi berkelanjutan.
Saat ini, untuk setiap tes, kami menjalankan semua tes dua kali untuk mendeteksi tes flashing. Kami juga memperhitungkan keluhan akun dari pengguna (penerima notifikasi). Jika kami mendeteksi kedipan, kami menandai tes dengan bendera khusus (dibisukan) dan memberi tahu pemilik tes. Setelah ini, hanya pemilik tes yang akan menerima pemberitahuan tentang kegagalan pengujian. Selanjutnya, kami terus menjalankan tes dalam mode normal, sambil menganalisis riwayat peluncurannya. Jika tes tidak berkedip di jendela waktu tertentu, otomasi dapat memutuskan bahwa tes telah berhenti berkedip dan Anda dapat menghapus benderanya.
Algoritma kami saat ini cukup sederhana dan banyak perbaikan yang direncanakan di tempat ini. Pertama-tama, kami ingin menggunakan sinyal yang jauh lebih bermanfaat.
Pembaruan otomatis input uji
Saat menguji sistem Yandex yang paling kompleks, di samping metode pengujian lainnya, pengujian strategi kotak hitam + pengujian berbasis data sering digunakan. Untuk memastikan cakupan yang baik, pengujian semacam itu membutuhkan sejumlah besar data input. Data dapat dipilih dari kelompok produksi. Tetapi ada masalah dengan fakta bahwa data dengan cepat menjadi usang. Dunia tidak tinggal diam, sistem kami terus berkembang. Data uji yang ketinggalan zaman dari waktu ke waktu tidak akan memberikan cakupan tes yang baik, dan kemudian benar-benar mengarah pada gangguan tes karena fakta bahwa program mulai menggunakan data baru yang tidak tersedia dalam data uji yang ketinggalan zaman.
Agar data tidak menjadi usang, sistem integrasi berkelanjutan dapat memperbaruinya secara otomatis. Bagaimana cara kerjanya?
- Data uji disimpan dalam penyimpanan sumber daya khusus.
- Tes berisi metadata yang menjelaskan input yang diperlukan.
- Korespondensi antara input tes yang diperlukan dan sumber daya disimpan dalam sistem integrasi berkelanjutan.
- Pengembang menyediakan pengiriman data segar secara rutin ke toko sumber daya.
- Sistem integrasi berkelanjutan mencari versi baru data uji dalam repositori sumber daya dan mengalihkan data input.
Penting untuk memperbarui data sehingga tes palsu tidak terjadi. Anda tidak bisa hanya mengambil dan, mulai dari komit tertentu, mulai menggunakan data baru, karena dalam hal terjadi gangguan pengujian, tidak akan jelas siapa yang harus disalahkan - melakukan atau data baru. Ini juga akan membuat tes diff (dijelaskan di bawah) tidak beroperasi.

Oleh karena itu, kami membuatnya sehingga ada beberapa interval kecil komit, di mana tes diluncurkan baik dengan yang lama dan dengan versi baru dari data input.

Tes Diff
Diff-tes kami sebut jenis khusus tes yang digerakkan oleh data , yang berbeda dari pendekatan yang diterima secara umum dalam bahwa tes tidak memiliki hasil referensi, tetapi pada saat yang sama kita perlu menemukan dalam melakukan apa tes melakukan perubahan perilakunya.
Pendekatan standar dalam pengujian berbasis data adalah sebagai berikut. Tes memiliki hasil referensi yang diperoleh saat tes pertama kali dijalankan. Hasil referensi dapat disimpan dalam repositori di sebelah tes. Pengujian selanjutnya harus menghasilkan hasil yang sama.

Jika hasilnya berbeda dari referensi, pengembang harus memutuskan apakah perubahan ini diharapkan atau kesalahan. Jika perubahan diharapkan, pengembang harus memperbarui hasil referensi pada saat yang sama dengan melakukan perubahan pada repositori.
Ada kesulitan saat menggunakan pendekatan ini dalam repositori besar dengan aliran komit besar:
- Mungkin ada banyak tes dan tes bisa sangat sulit. Pengembang tidak memiliki kemampuan untuk menjalankan semua tes yang terpengaruh dalam lingkungan kerja.
- Setelah melakukan perubahan, tes dapat rusak jika hasil referensi tidak diperbarui secara bersamaan dengan perubahan pada kode. Kemudian pengembang lain dapat membuat perubahan pada komponen yang sama dan hasil pengujian akan berubah lagi. Kami mendapatkan pengenaan satu kesalahan pada kesalahan lainnya. Sangat sulit untuk menangani masalah seperti itu, butuh waktu dari pengembang.
Apa yang kita lakukan Tes diff terdiri dari 2 bagian:
- Periksa komponen.
- Kami memulai tes dan menyimpan hasilnya dalam penyimpanan sumber daya.
- Jangan bandingkan hasilnya dengan referensi.
- Kami dapat menangkap beberapa kesalahan, misalnya, program tidak memulai / tidak berakhir, macet, program tidak merespons. Validasi hasil juga dapat dilakukan: keberadaan setiap bidang dalam jawaban, dll.
- Komponen diff.
- Bandingkan hasil yang diperoleh pada peluncuran yang berbeda dan beda build. Dalam kasus paling sederhana, ini adalah fungsi yang mengambil 2 parameter dan mengembalikan diff.
- Penampilan diff tergantung pada tes, tetapi itu harus menjadi sesuatu yang dapat dimengerti bagi seseorang yang akan melihat diff. Biasanya diff adalah file html.
Peluncuran komponen check dan diff dikendalikan oleh sistem integrasi berkelanjutan.

Jika sistem integrasi berkelanjutan mendeteksi diff, maka pencarian biner pertama kali dilakukan untuk komit yang menyebabkan perubahan. Setelah menerima pemberitahuan dari pengembang, dimungkinkan untuk mempelajari perbedaan dan memutuskan apa yang harus dilakukan selanjutnya: mengenali perbedaan seperti yang diharapkan (untuk ini Anda perlu melakukan tindakan khusus) atau memperbaiki / "mengembalikan" perubahan Anda.
Untuk dilanjutkan
Pada artikel selanjutnya kita akan berbicara tentang bagaimana sistem integrasi berkelanjutan bekerja.
Referensi
Repositori monolitik, pengembangan berbasis trunk
Pengujian berdasarkan data