Sebelumnya, di Avito, Anda dapat menemukan produk yang tepat menggunakan pemfilteran kata kunci atau navigasi pohon kategori. Metode ini, meskipun tampaknya akrab, tidak selalu nyaman - untuk menemukan produk atau layanan, perlu dilakukan sejumlah besar klik. Lebih dari setahun yang lalu, kami mendapatkan relevansi, berkat pencarian yang menjadi lebih baik, dan sekarang lebih mudah dan lebih nyaman untuk menemukan produk atau layanan bahkan di halaman utama. Dengan inovasi ini, barang-barang "sampah" yang tidak sesuai, tidak lagi menjadi masalah. Dan ini hanyalah salah satu langkah untuk membuat pencarian Anda lebih baik. Kami secara bertahap mengubah infrastruktur, yang memungkinkan kami untuk mengerjakan kualitas pencarian secara lebih intensif, meningkatkannya lebih cepat, dan meluncurkan fitur-fitur baru yang menguntungkan penjual dan pembeli di Avito.
Dalam artikel ini saya akan memberi tahu Anda bagaimana pencarian di Avito telah berubah: di mana kami memulai dan bagaimana kami sekarang bergerak menuju peningkatan kehidupan pengguna kami, saya akan membagikan inovasi kami baik dalam produk maupun dalam pengisiannya - bagian teknis. Tidak akan ada daging keras di sini, tapi saya harap Anda menikmatinya.

Beberapa catatan pengantar: Avito adalah layanan iklan paling populer di Rusia. Kami memiliki lebih dari 450 ribu iklan setiap hari, dan jumlah pengunjung unik setiap bulan mencapai 35 juta, yang menghasilkan lebih dari 140 juta pencarian setiap hari.
Skenario pencarian khas sebelumnya
Mari kita lihat contoh sederhana tentang bagaimana pencarian bekerja lebih dari setahun yang lalu. Misalkan Anda membutuhkan piano (yah, mengapa tidak?). Kami pergi ke halaman utama, kami mengetik "piano".
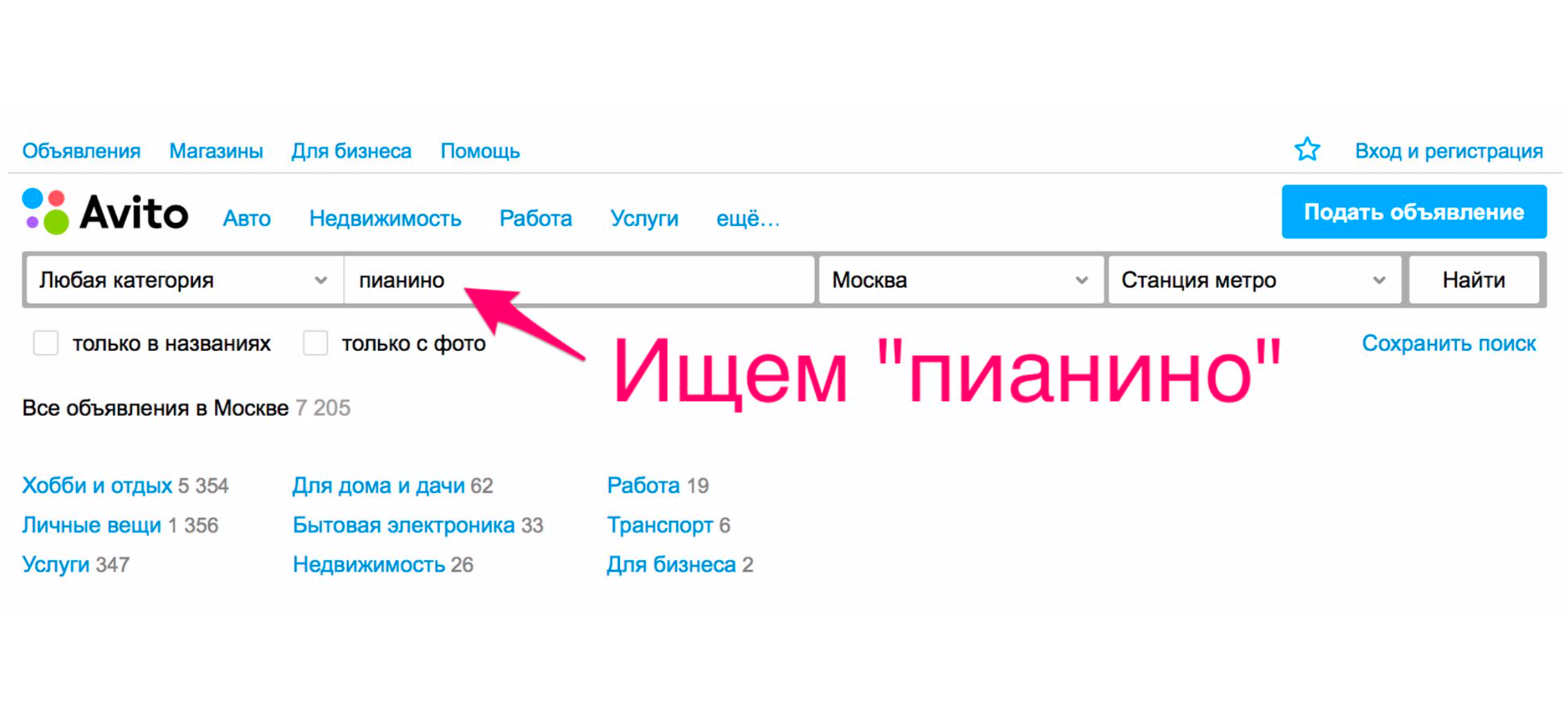
Dalam ekstradisi, Anda kemungkinan besar akan menerima penggerak, layanan transportasi piano atau yang serupa, tetapi bukan alat musik.

Ini terjadi karena kami akan mengurutkan berdasarkan tanggal penempatan - dan layanan ini paling sering ditempatkan.
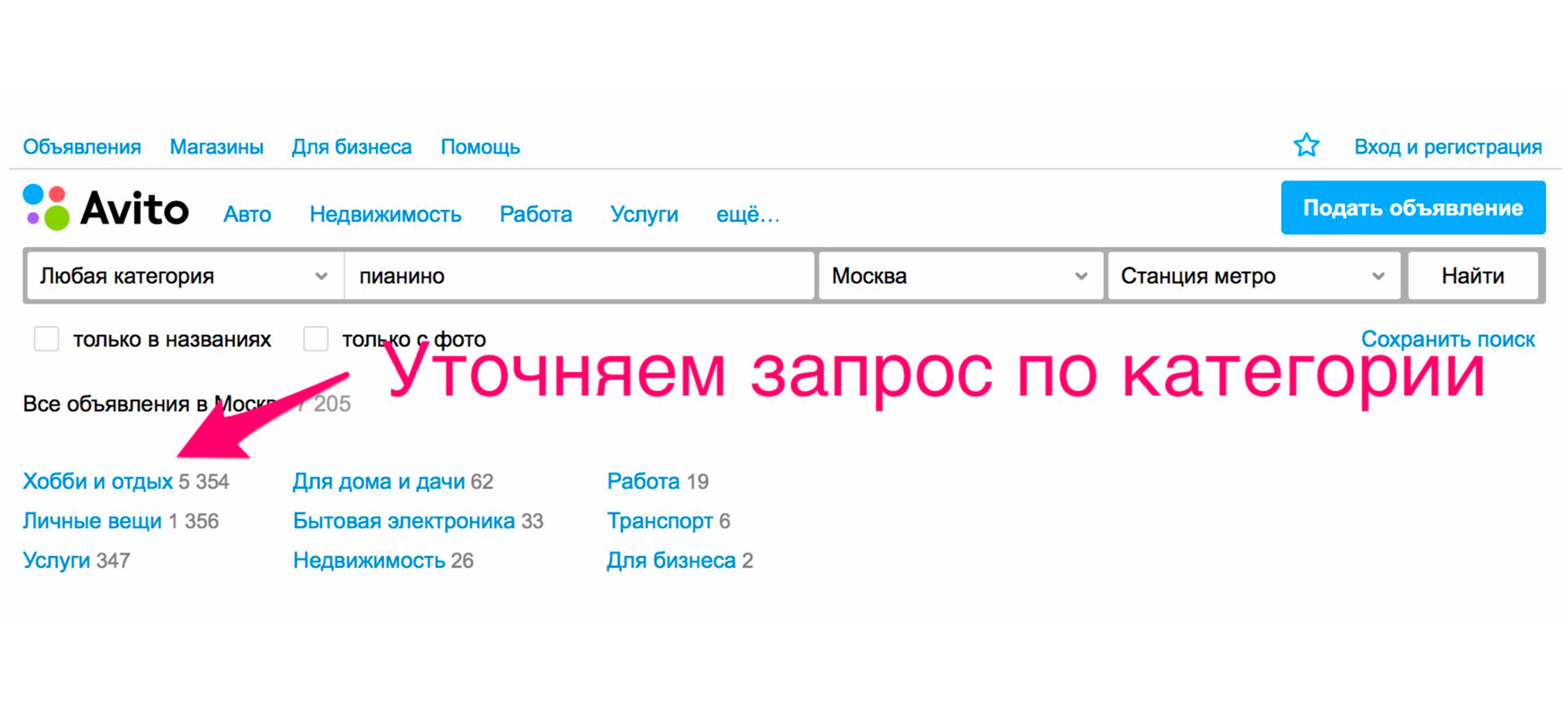
Untuk melihat piano, Anda perlu menentukan kategorinya. Kami klik pada judul "Hobi dan Kenyamanan", turun pohon kategori ke "Alat Musik", lalu "Instrumen Keyboard".
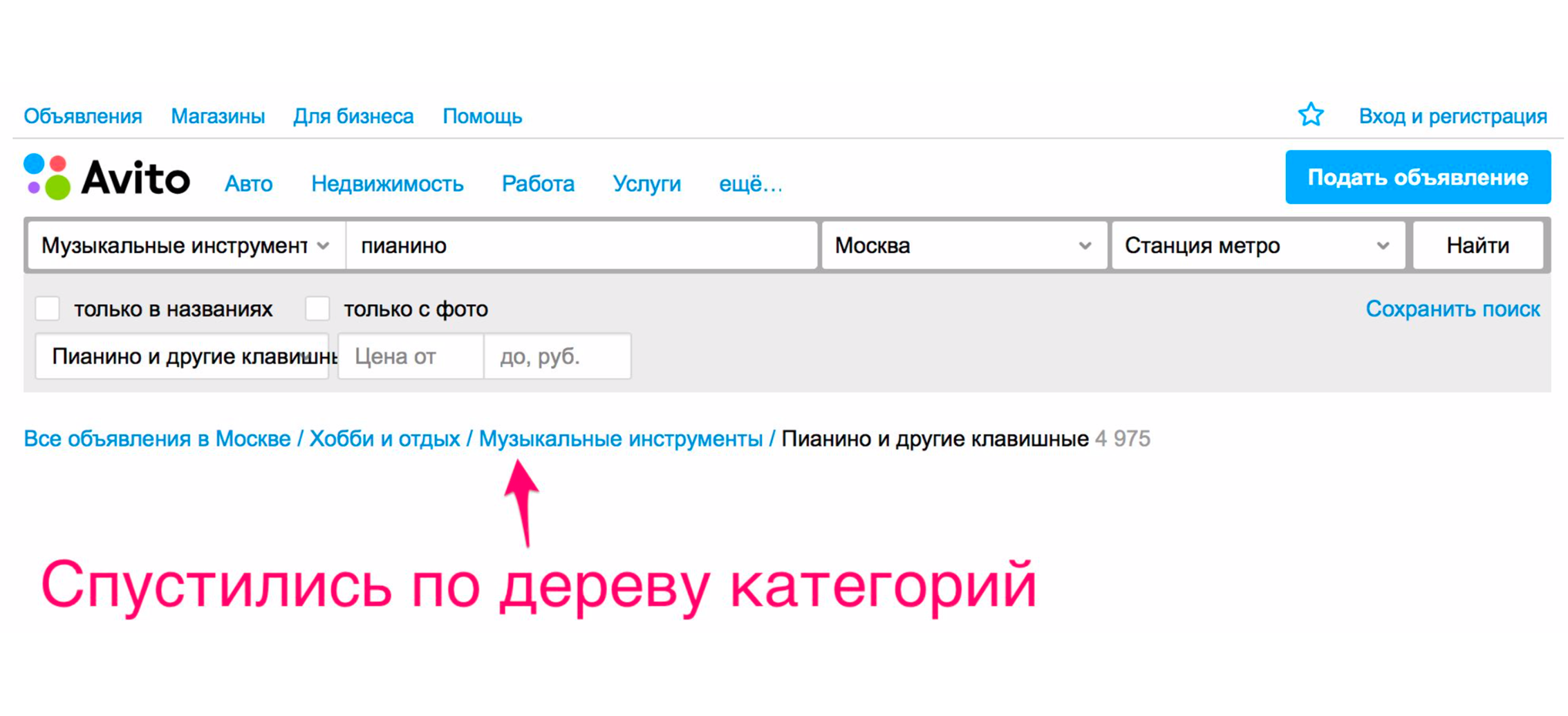
Dan hanya setelah itu kita melihat piano yang kita cari.
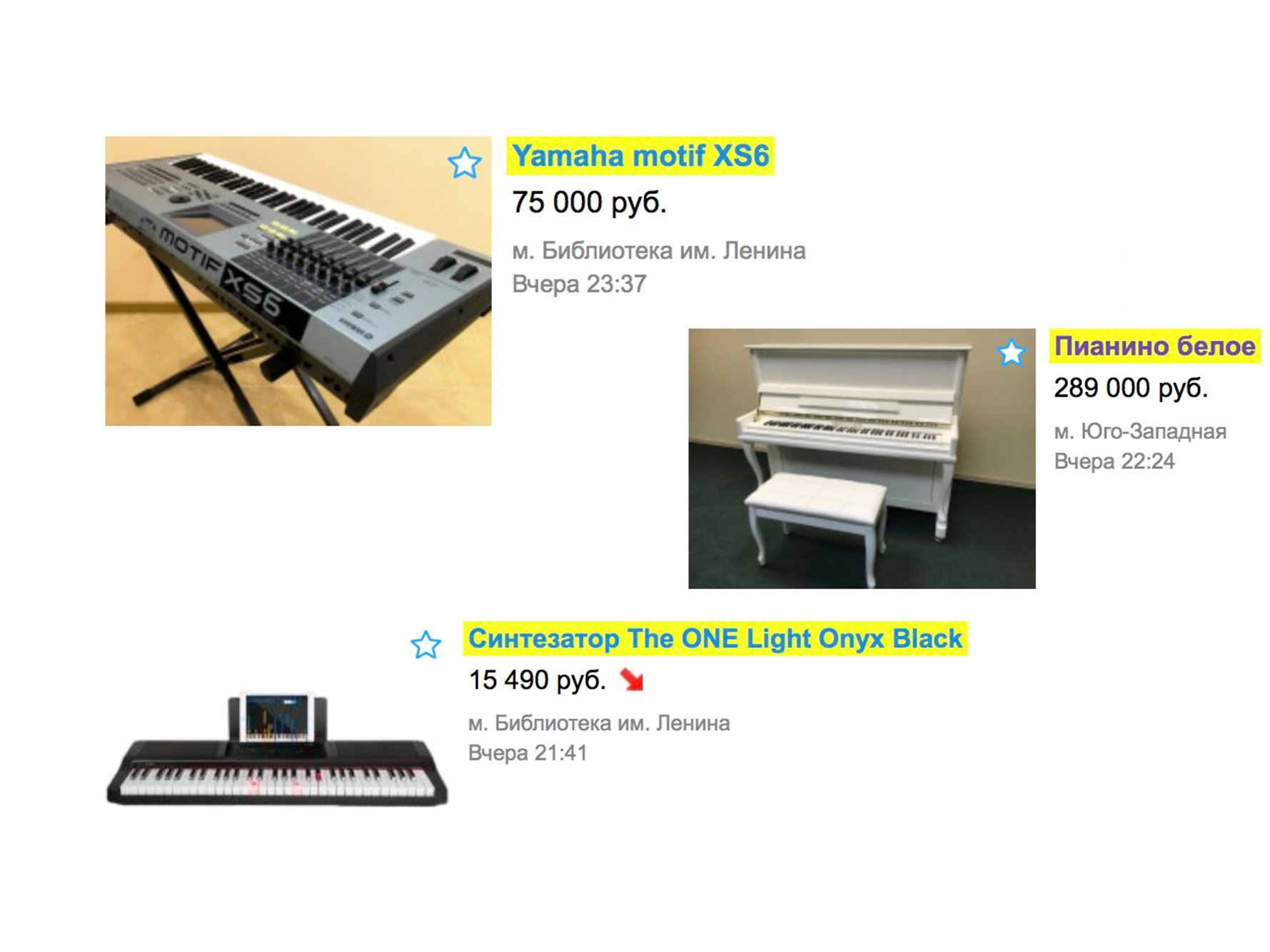
Ternyata, untuk menemukan iklan yang diinginkan, ada opsi berikut:
- penyempurnaan kategori saat mencari dengan kata kunci,
- mengurutkan berdasarkan kesegaran dan harga,
- filter
- cari hanya dengan nama.
Apa yang berubah karena relevansi
Karena relevansi, iklan yang tidak cocok sama sekali tidak lagi dimasukkan dalam penerbitan. Sekarang, jika Anda mencari piano dari halaman utama, kemungkinan besar Anda tidak akan melihat layanan loader yang membantu Anda mengangkutnya, tetapi Anda akan segera melihat alat musik yang Anda inginkan. Pada saat yang sama, penyortiran baru ditambahkan - "Secara default". Ini dibentuk oleh dua indikator: relevansi iklan dengan kueri dan kesegaran teks.

Di atas Anda melihat yang paling segar dari yang relevan.
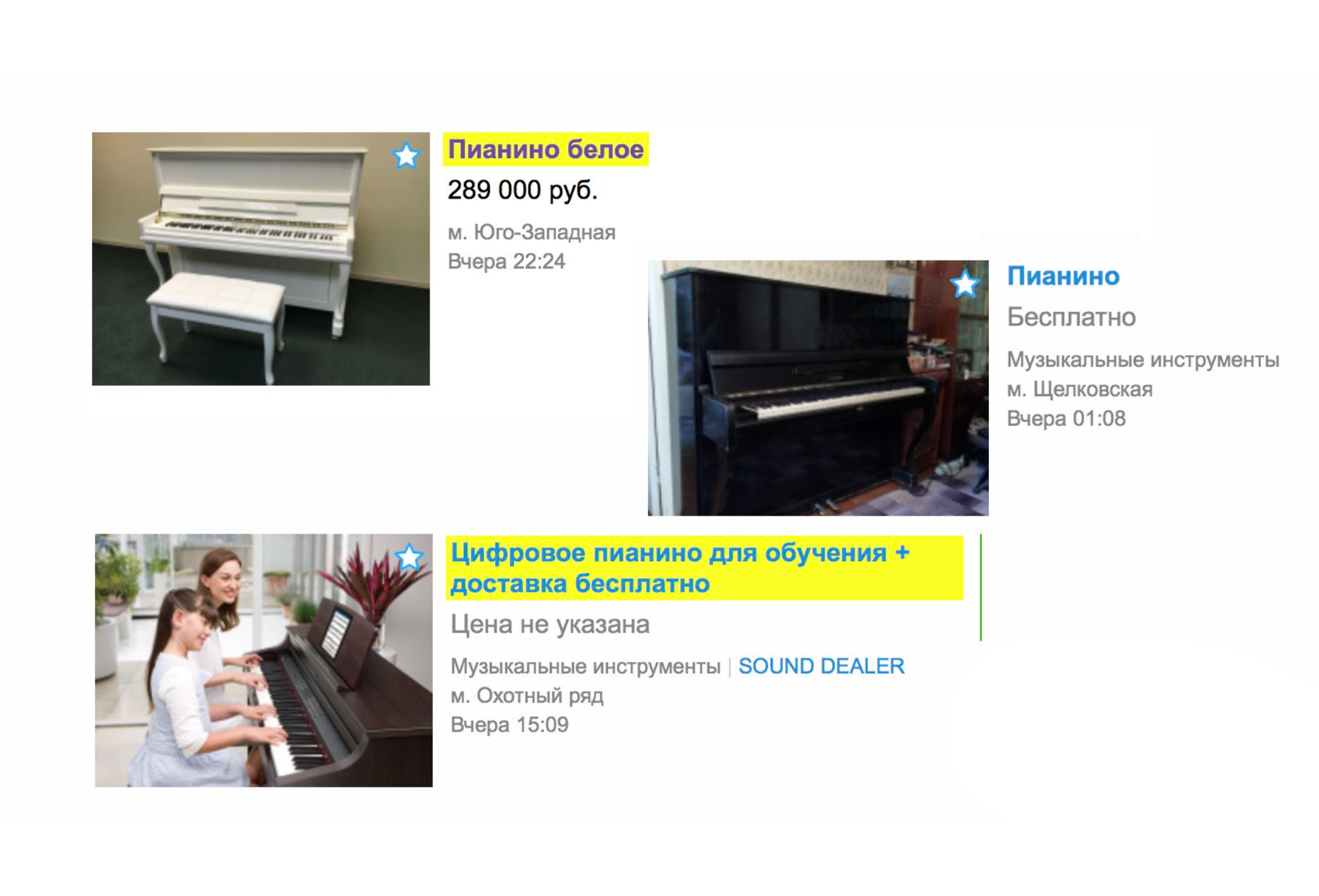
Di Avito, dengan biaya tambahan, Anda dapat menaikkan iklan. Dan dengan diperkenalkannya relevansi, peningkatan gaji bekerja lebih efisien. Mereka akan bekerja, pertama-tama, jika iklan Anda relevan dengan permintaan teks.
Pengenalan relevansi tidak berarti bahwa kami sepenuhnya meninggalkan transisi ke pohon kategori. Hanya untuk sebagian besar kasus, kami mengurangi jumlah klik ke iklan yang diinginkan ketika mencari dari halaman utama. Jika Anda masih membutuhkan layanan transportasi, meskipun Anda baru saja mengetik "piano" dalam pencarian, buka pohon kategori dan Anda akan menemukan iklan ini. Pencarian juga mulai bekerja lebih efisien dan dalam kategori, misalnya, "Barang-barang pribadi" dan "Peralatan rumah tangga".
Cara menemukan produk yang tepat dalam tiga klik
Pencarian menjadi lebih nyaman bagi pengguna tidak hanya karena kualitas hasil pencarian. Ada cara lain untuk memperbaikinya. Salah satunya adalah meneruskan ke kategori. Sebagai contoh, kami mencari Lamborghini Gayardo (ya, Anda suka bermain piano dan ingin mengendarai Lamborghini). Untuk masuk ke kategori mobil model tertentu, Anda perlu membuat dua klik tambahan. Dengan relevansi, kemungkinan besar Anda akan mendapatkan apa yang Anda inginkan.
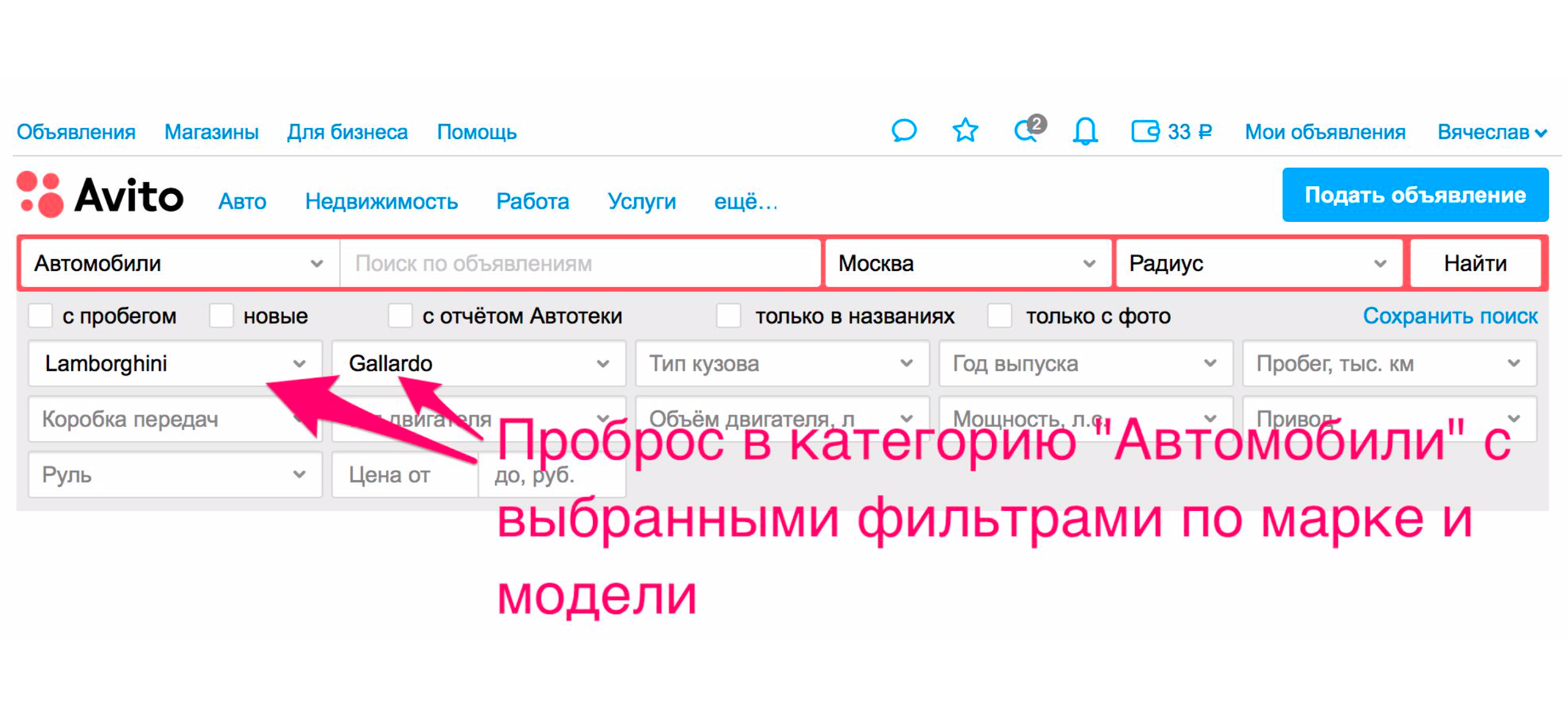
Tetapi ada metode tambahan yang akan segera melemparkan Anda ke dalam mobil. Penerbitan akan dipersempit, mobil yang tepat akan dipilih di filter, dan Anda akan benar-benar menerima mobil dalam penerbitan.

Cara lain adalah dengan memperluas tag. Misalnya, ketika Anda memasukkan kata "jaket", Anda akan mendapatkan petunjuk.
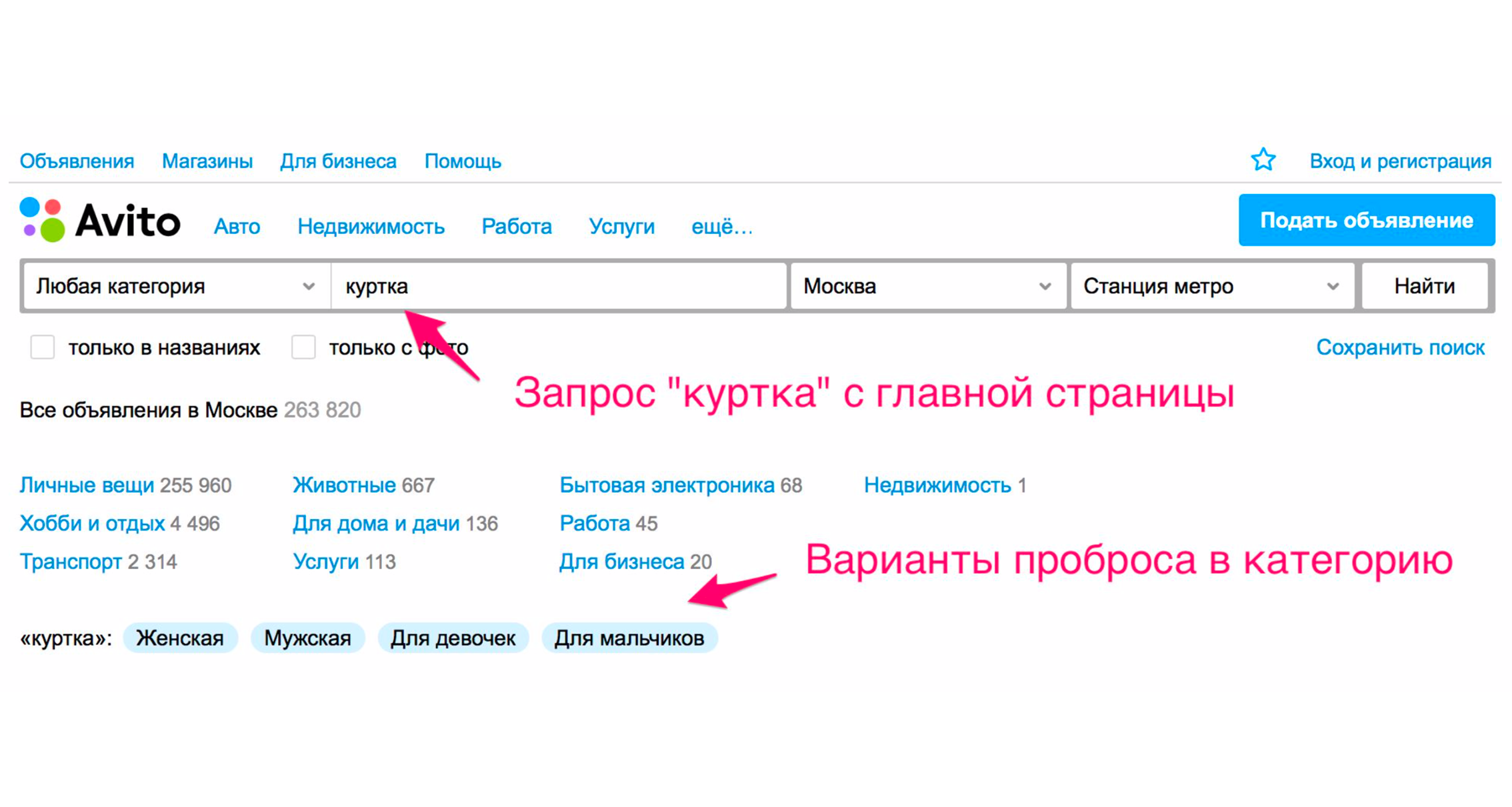
Tangkapan layar di atas menunjukkan tip: jenis jaket - perempuan, laki-laki, perempuan, laki-laki. Jika Anda mengklik "Untuk Anak Perempuan", Anda akan segera jatuh ke dalam kategori di mana filter yang sesuai akan dipilih. Satu set tag tambahan yang diperluas juga akan muncul di sini: jaket musim dingin, kulit, baru dan sebagainya. Jika Anda turun pohon kategori secara manual ke produk yang diinginkan, maka Anda perlu melakukan lebih banyak tindakan.
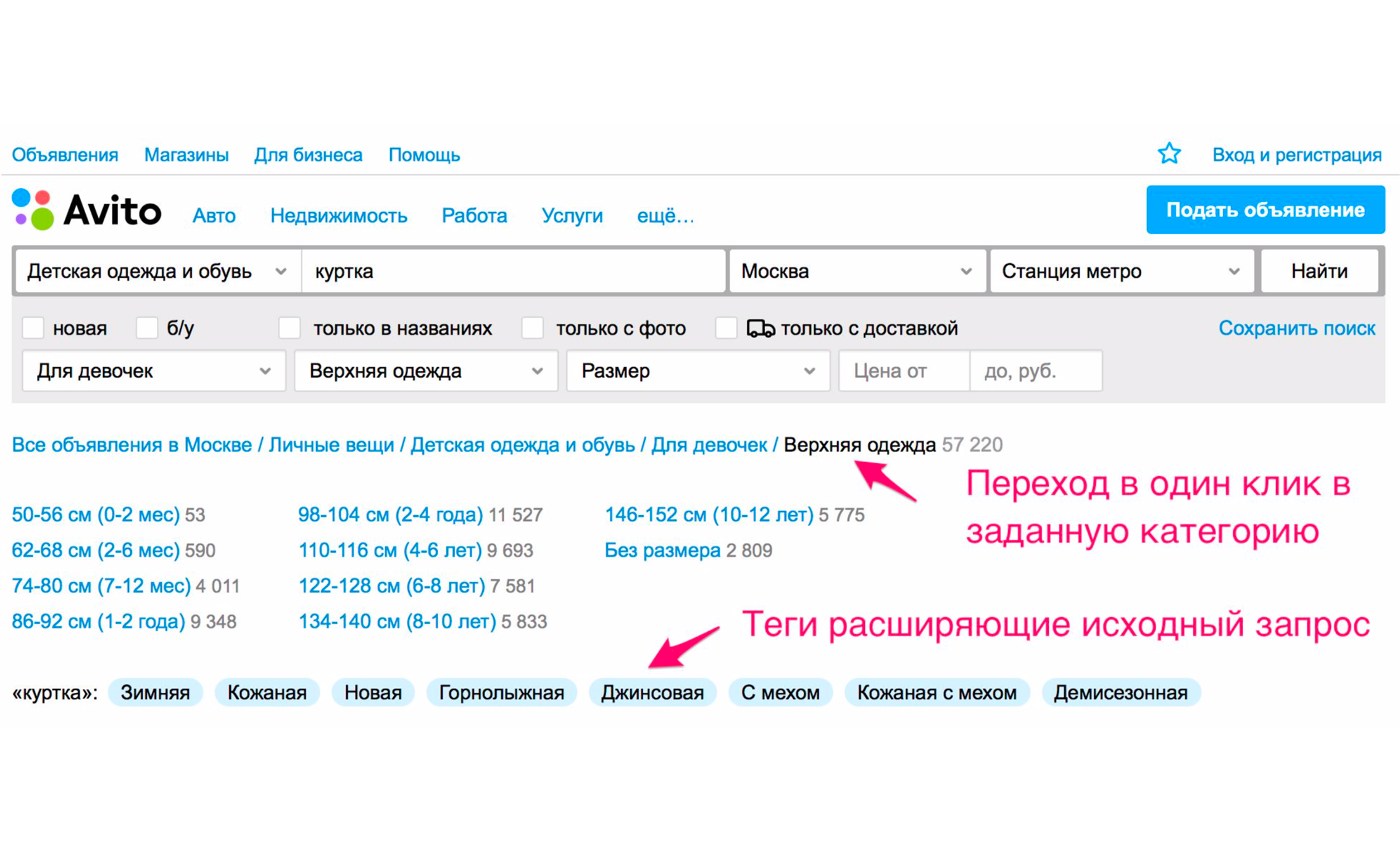
Apa perbedaan antara pencarian dan filter
Ketika saya berbicara di RIT ++ , audiens memiliki pertanyaan: apa perbedaan antara pencarian teks dan filter? Semuanya cukup sederhana. Anda juga dapat menemukan iklan yang diinginkan tanpa permintaan teks dengan turun ke pohon kategori. Dalam hal ini, pencarian masih akan menemukan barang dan jasa, bukan oleh teks yang diberikan, tetapi oleh serangkaian parameter yang dilewatkan dari filter yang sesuai dari kategori yang dipilih.
Setiap kategori memiliki set filternya sendiri. Misalnya, dalam kategori "Mobil" - beberapa filter, dalam kategori "Hal-hal pribadi" - filter lainnya. Yaitu, filter terikat secara kaku ke suatu kategori.
Penempatan pengumuman dalam dua menit
Sebuah inovasi penting telah muncul untuk penjual yang mereka rasakan ketika mengirimkan iklan mereka. Jika iklan Anda tidak mengandung "dilarang" atau bukan duplikat - iklan bagus yang biasa - Anda akan segera melihatnya dalam penerbitan. Sebenarnya penundaan ini berlangsung sekitar dua menit, tetapi dalam kasus yang jarang terjadi, dapat diperpanjang hingga 30 menit. Sebelumnya, sebuah iklan selalu muncul di situs hanya setelah setengah jam.
Asisten Avito
Avito Helper adalah ekstensi untuk Chrome yang menampilkan harga produk serupa di Avito di situs pihak ketiga. Dalam ekstensi, Anda dapat membandingkan harga di banyak toko online dengan harga untuk Avito, atau cukup mencari barang dan layanan yang diperlukan dalam layanan kami, tanpa langsung ke situs web atau aplikasi. Kami dapat menerapkan "Asisten", termasuk berkat perubahan infrastruktur baru.

Arsitektur
Menggergaji monolit
Avito memiliki monolit dalam PHP. Setahun yang lalu, semua fungsi pencarian yang berfungsi di Avito ada di monolith ini. Pencarian di monolith bekerja dengan empat platform: Android, iOS, versi mobile di browser dan desktop. Untuk memberikan output, query SQL yang sesuai dihasilkan dalam Sphinx di dalam kode ini, pemrosesan sedang berlangsung, dan output dikirim dalam format JSON atau HTML. Kemudian pengguna melihat apa yang mereka cari.
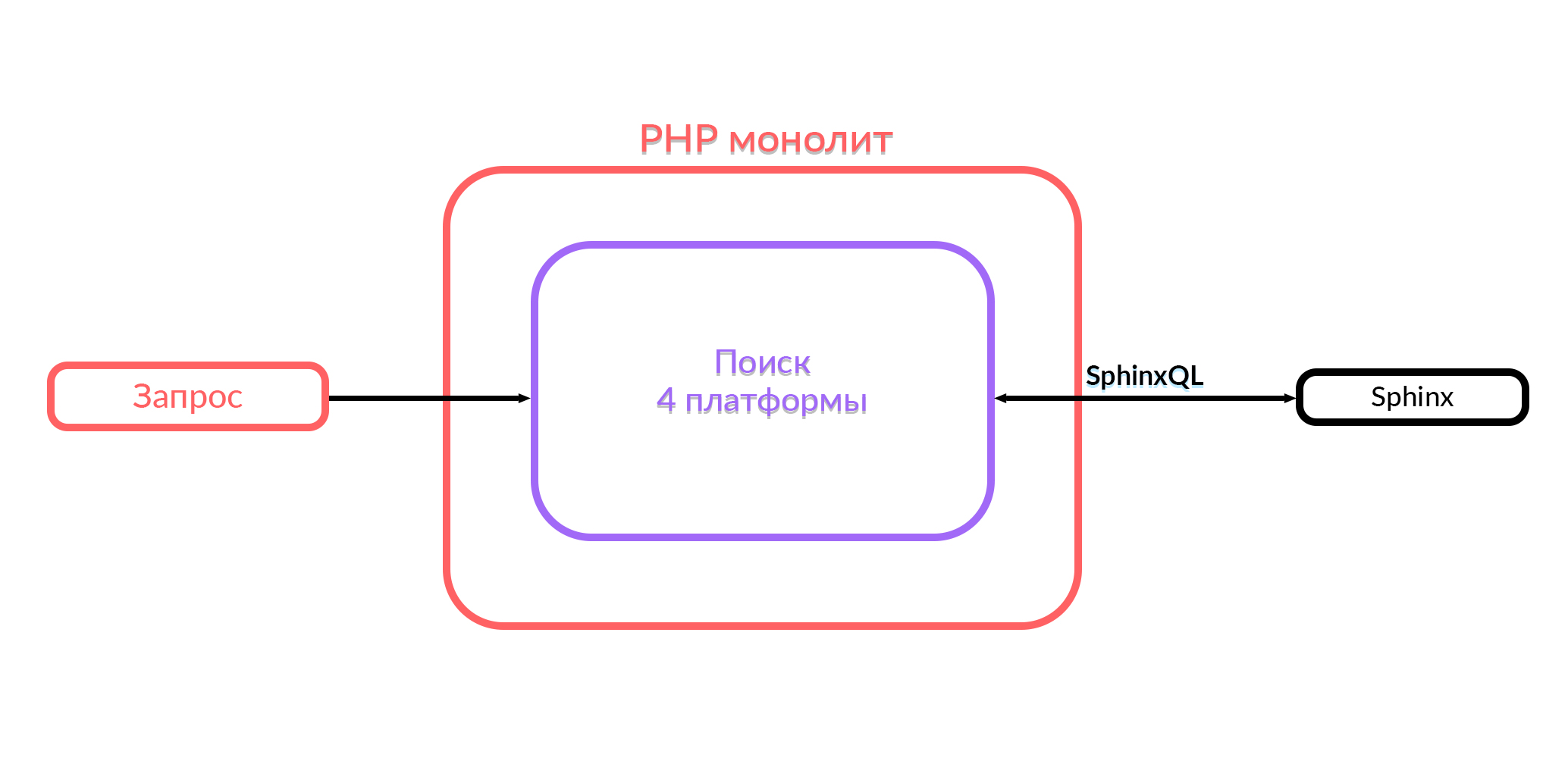
Apa yang kita miliki sekarang
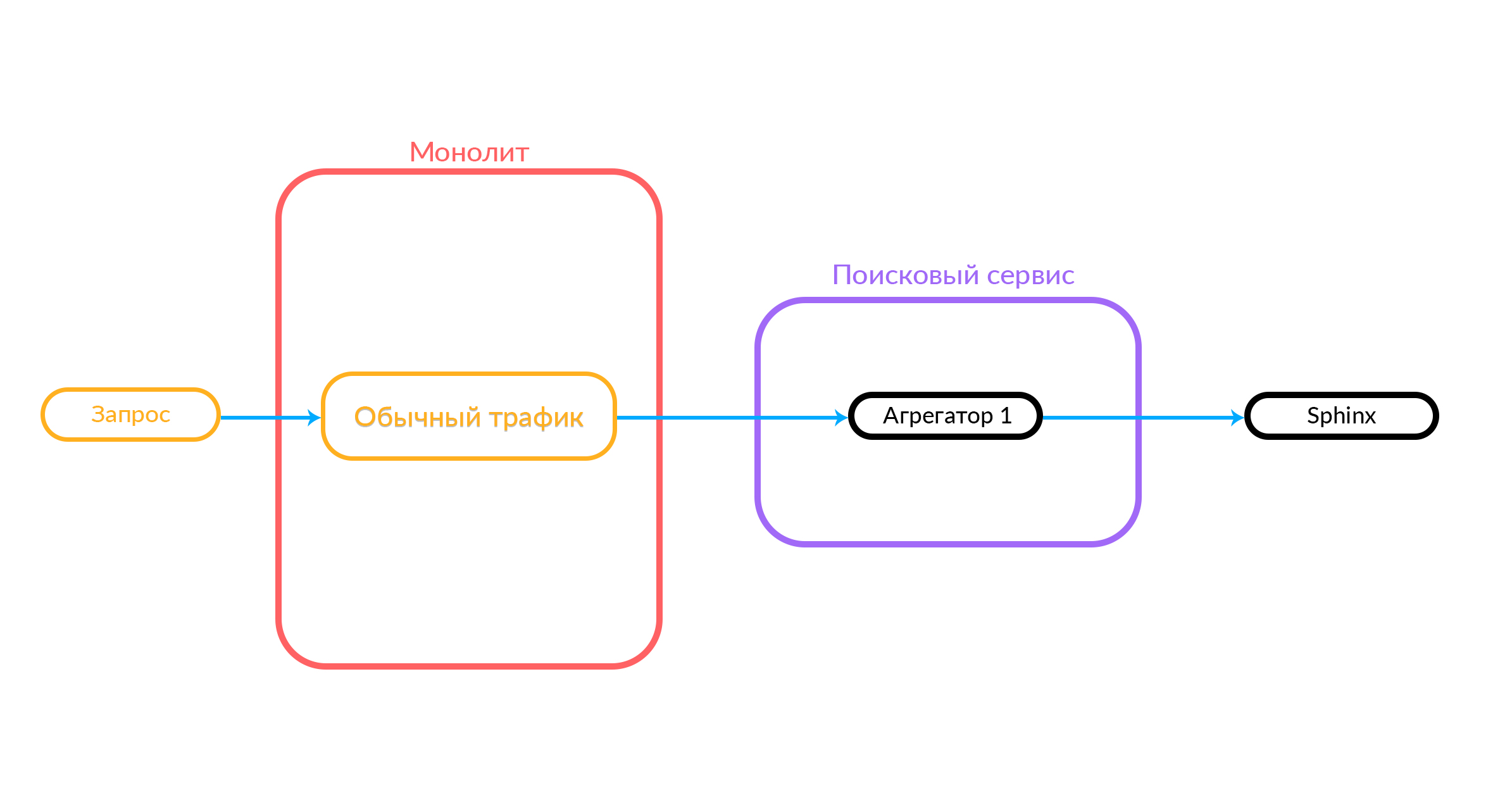
Jika Anda menerapkan fitur baru, sangat sulit untuk diintegrasikan dengan monolith ini. Karena itu, kami memutuskan untuk mengembangkan layanan pencarian, yang kami sebut "Dicari." Sekarang monolit menuju ke layanan pencarian ini, dan layanan tersebut menuju ke Sphinx.

Alasan untuk membuat layanan pencarian
Saat mengembangkan layanan, Anda selalu perlu memahami mengapa Anda melakukan ini. Plus jelas pertama adalah penghapusan logika tingkat rendah. Dalam kasus kami, ini menyembunyikan dapur untuk memproses permintaan SphinxQL. Selain itu, kami dapat lebih mudah menyediakan fungsionalitas pencarian ke sistem pihak ketiga.
Eksekusi query tidak sinkron. Keuntungan ini cukup jelas dan tergantung pada implementasinya, satu atau lain keberhasilan dapat dicapai. Layanan kami diimplementasikan pada Golang, dan ada fungsi yang dapat diparalelkan - tiga permintaan di Sphinx, yang memberikan hasil yang baik.
Penyebaran cepat. Kami telah mengidentifikasi fungsional terpisah dengan kode lebih sedikit, tes tambahan (monolith memiliki banyak tes, tidak hanya fungsi pencarian), dan lebih mudah untuk diluncurkan. Yang paling penting, karena pendekatan yang berhasil dalam implementasi layanan ini, kami dapat mengurangi hal-hal menarik dan menerapkan algoritma peringkat lanjutan - untuk melakukan pemrosesan yang agak rumit yang tidak dapat kami lakukan dalam monolit. Ini memberi kami dasar yang sangat baik untuk bereksperimen dengan kualitas pencarian.
Sebagai bonus, kami memiliki kesempatan untuk beralih dari Sphinx ke Elastic, karena logika level rendah sekarang disembunyikan.
Diagram ini sudah menunjukkan kasus ketika ada monolit, layanan "Dicari" dan layanan pihak ketiga "Avito Assistant".
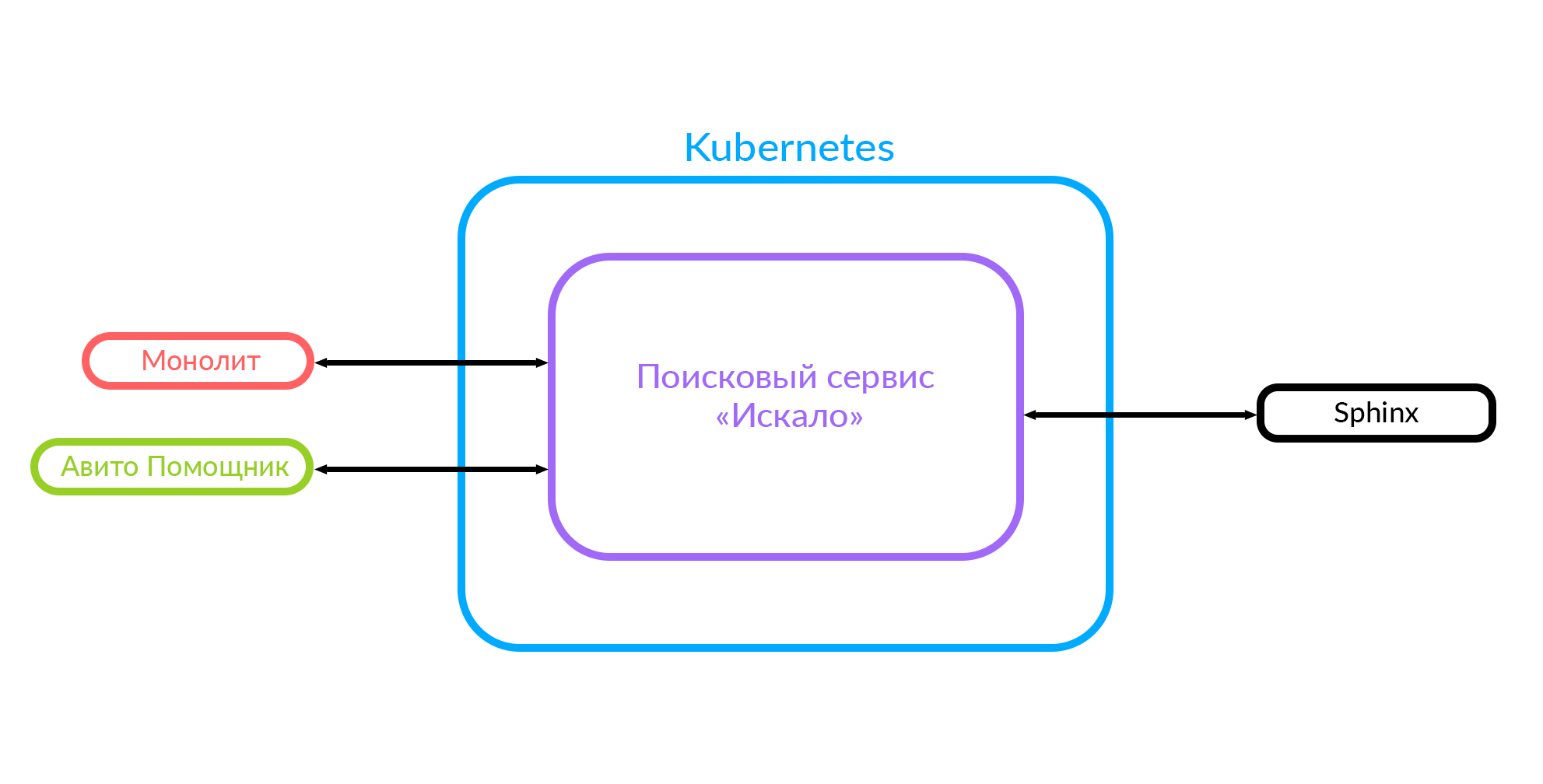
Bagaimana cara kerja layanan pencarian?
Ini memiliki seperangkat agregator. Setiap agregator melakukan logika bisnis tertentu terkait dengan pemrosesan penerbitan. Ia dapat membentuk masalah ini dengan cara tertentu.
Permintaan tiba di penjadwal. Penjadwal memilih agregator sesuai dengan kriteria kueri dalam hal parameternya (atau jika agregator yang diinginkan ditentukan dalam permintaan itu sendiri). Agregator pergi ke Sphinx. Setelah menerima respons dari Sphinx, itu menghasilkan output dan memberikan jawaban kepada klien.

Dalam hal ini, permintaan berada di luar, bukan dari cloud tempat layanan pencarian kami bekerja. Tetapi opsi lain juga dimungkinkan: beberapa layanan kami yang lain, di dalam cloud, misalnya, Avito Assistant, beralih ke layanan pencarian. Permintaan ini sudah masuk ke agregator lain - ada logika bisnis lain. Begini cara kerjanya:
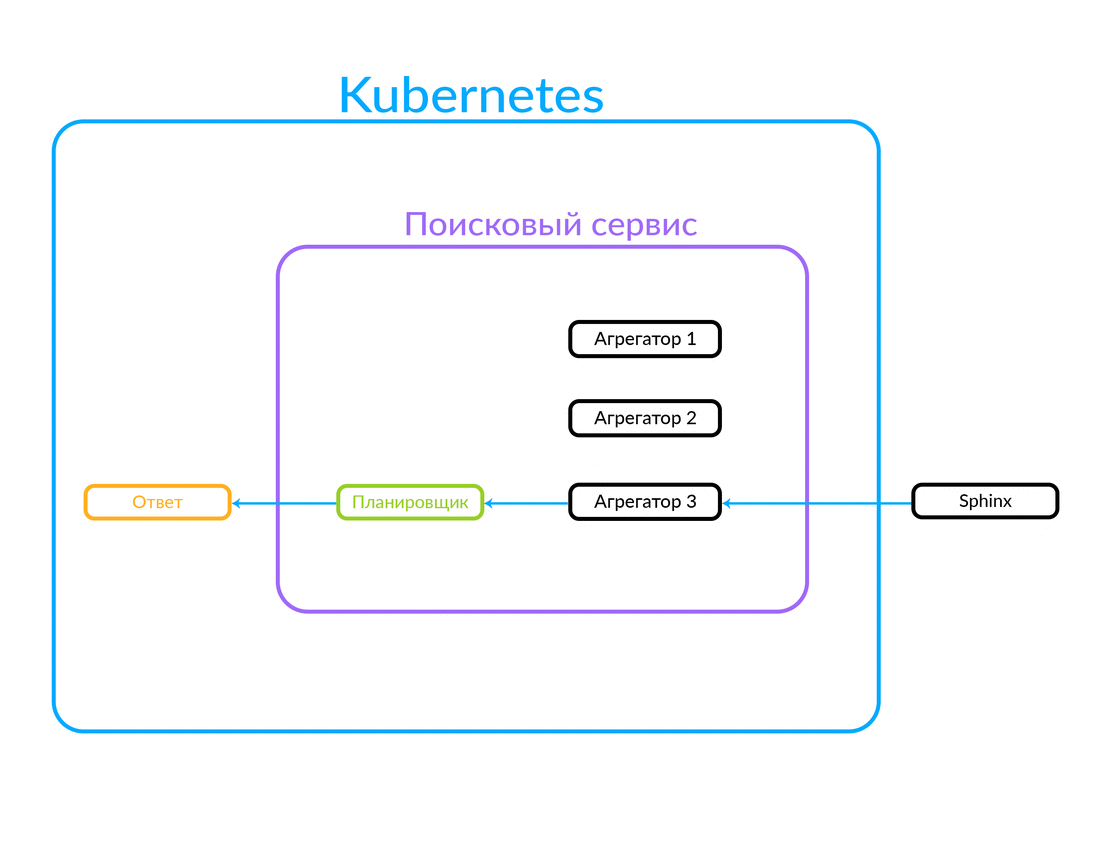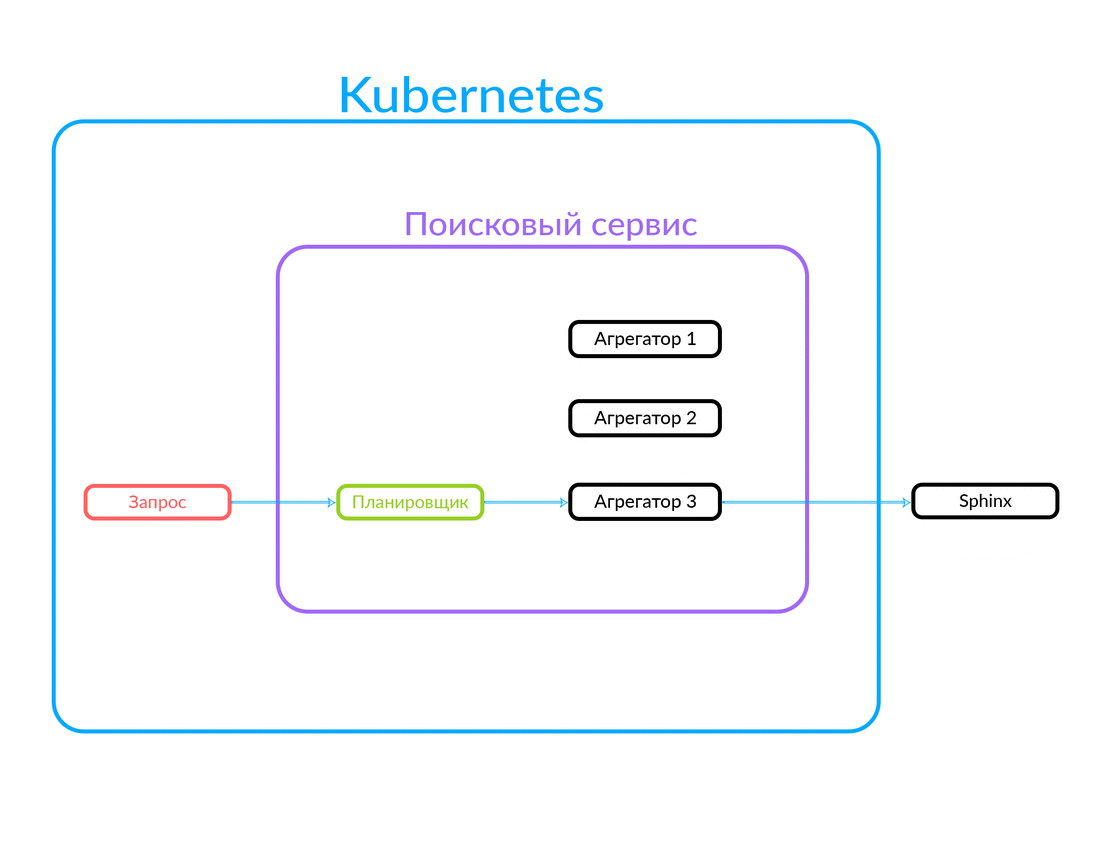
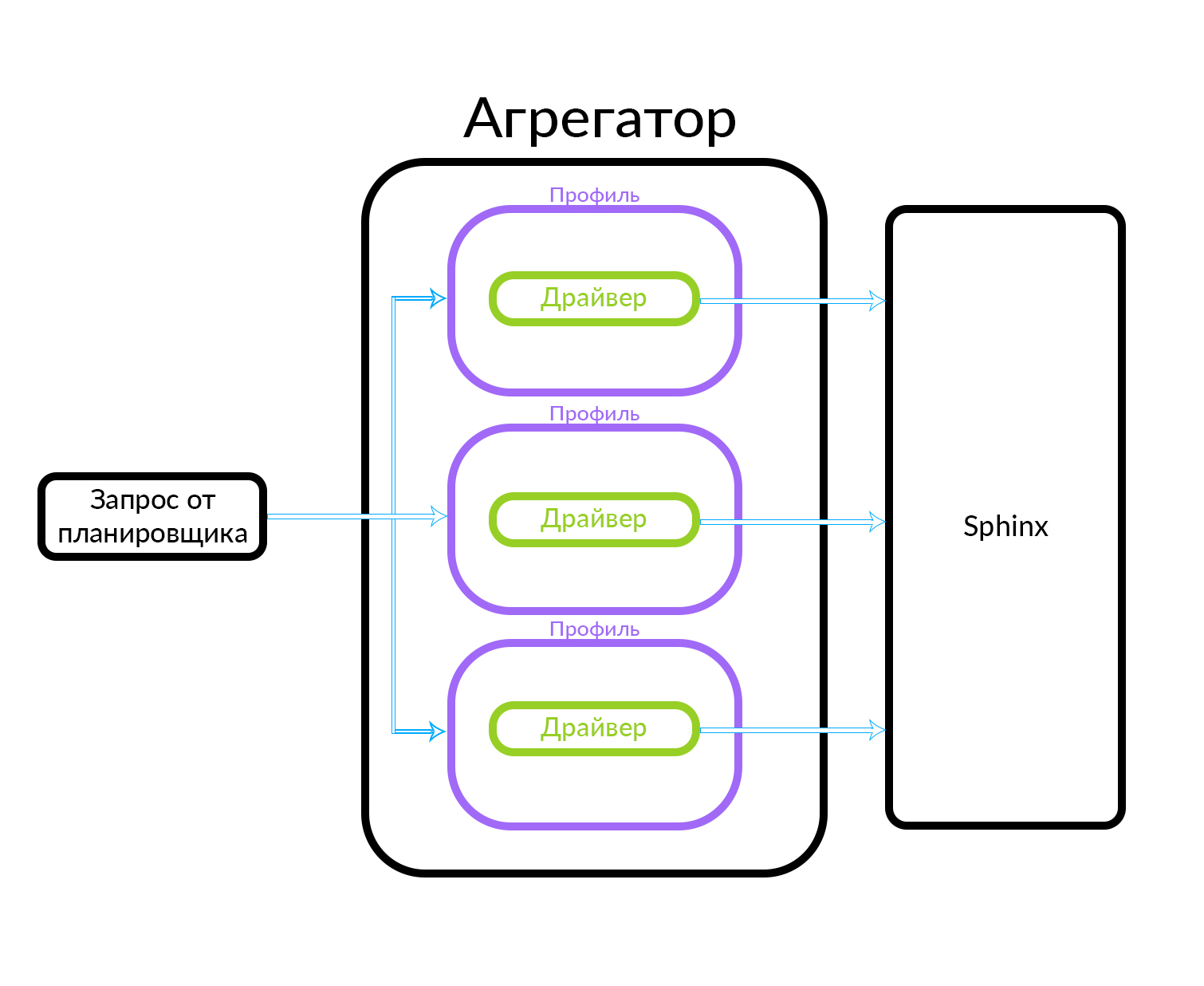
Bagaimana eksekusi query tidak sinkron pada agregator bekerja
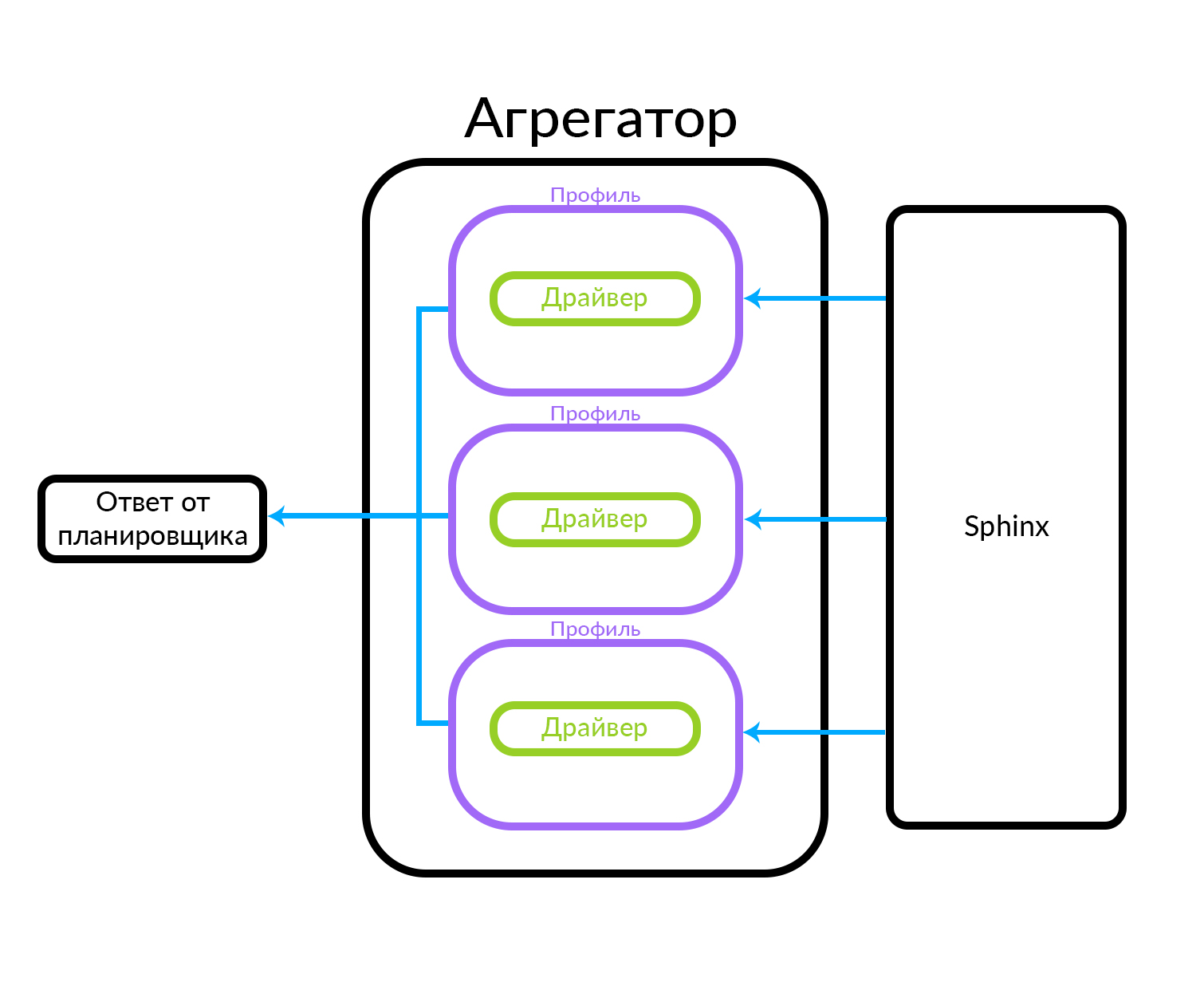
Agregator terdiri dari beberapa profil. Sebuah profil, secara kasar, adalah entitas di mana Anda bisa mendapatkan pengumuman dari beberapa jenis atau dengan cara tertentu. Misalnya, ini dapat dijelaskan melalui analogi: ada "Premium", "VIP" dan iklan reguler di Avito. Agregator menerima permintaan dari penjadwal, sementara permintaan paralel dijalankan untuk sekumpulan profil yang dikenal dalam agregator. Profil memiliki driver di dalamnya yang secara fisik mengakses level yang mendasarinya, dalam hal ini di Sphinx, tetapi dapat berupa sumber data lainnya
Agregator dapat dengan mudah memberikan scheduler hasil query ke profil, dan itu juga dapat melakukan tindakan yang lebih kompleks, misalnya, mencampur hasil ini menggunakan satu atau algoritma lain.
Penyimpanan indeks pencarian
Karena kami menggunakan Kubernetes di arsitektur, di RIT ++ saya ditanya pertanyaan tentang menyimpan indeks pencarian - apakah disimpan di Kubernetes? Tidak, kami memiliki Sphinx yang hidup di mesin fisik. Di Kubernetes, kami menggunakan layanan pencarian yang memproses logika pencarian. Cloud juga berisi indeks pencarian sampel untuk lingkungan pengembangan tempat pengujian dijalankan, tetapi tidak diinginkan untuk menempatkan indeks pertempuran di sana, karena layanan yang bekerja di Kubernetes, pertama-tama, layanan tanpa kewarganegaraan.
Cari Beban Layanan
Sekarang layanan ini dalam pertempuran, melayani 100% dari beban dengan beberapa pengecualian. Beban yang dipegangnya sekitar 200 krpm. Keterlambatan: median - hingga 17 ms, 95 persentil - hingga 120 ms, 99 persentil - hingga 320 ms.
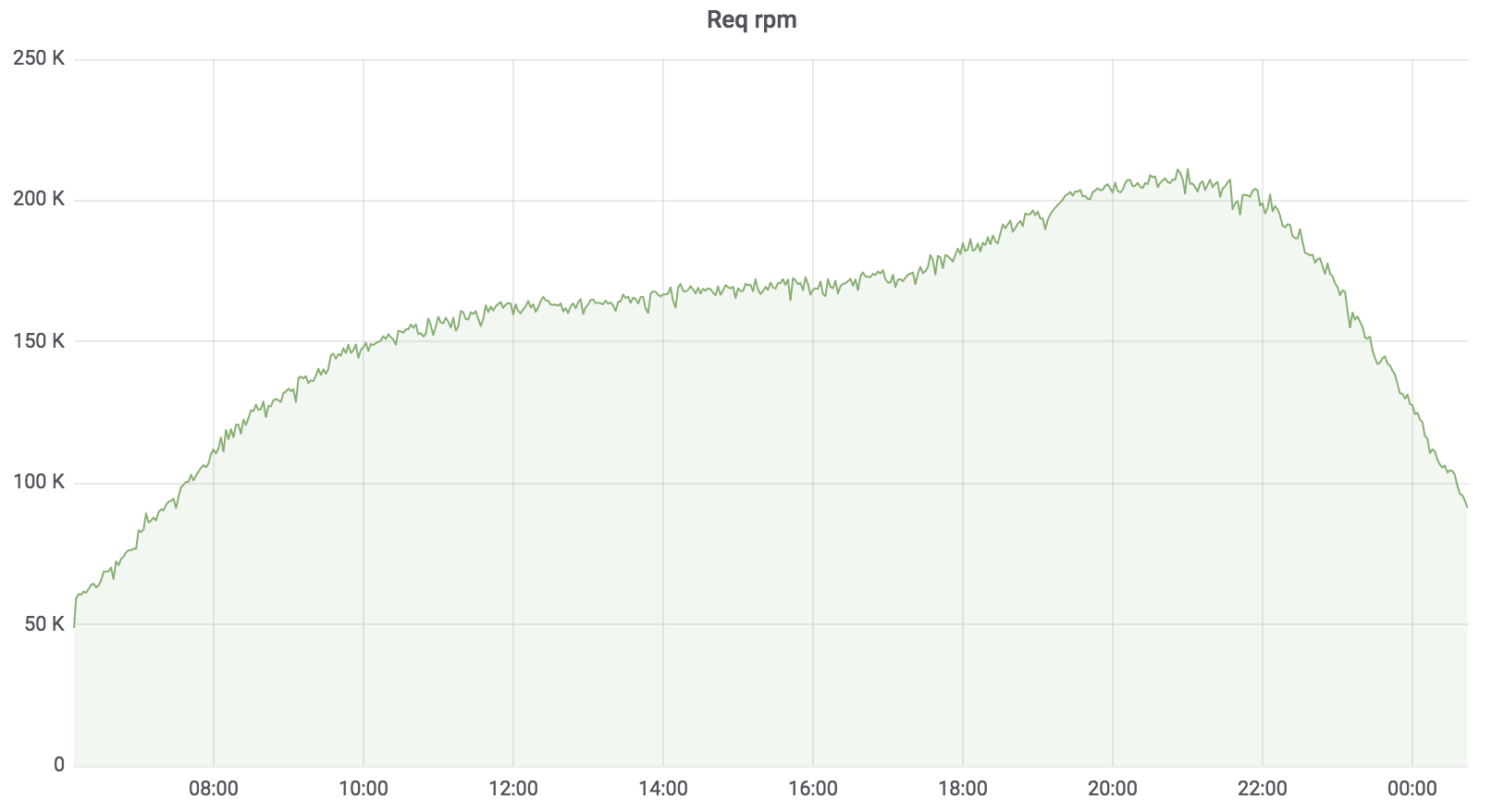
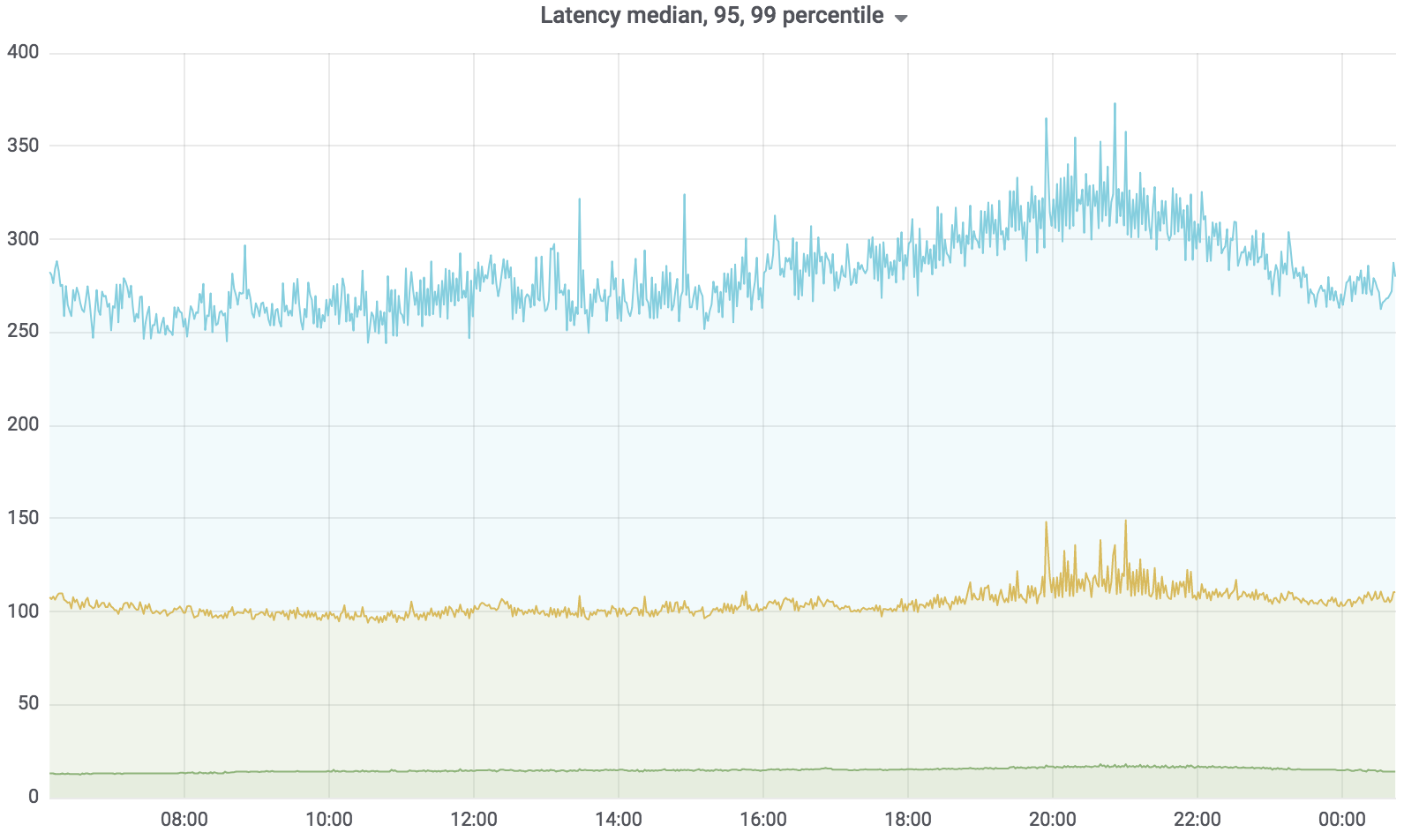
Layanan Pencarian Total
Layanan pencarian ditulis dalam Golang, digunakan untuk Kubernetes, agregator secara asinkron bekerja dengan beberapa profil. Profil berfungsi dengan driver yang ditentukan, driver mengakses sumber data yang ditentukan, misalnya, Sphinx. Jumlah permintaan yang dilayani oleh layanan kami hingga 200 krpm saat ini. Keterlambatan: median - hingga 17 ms, 95 persentil - hingga 120 ms, 99 persentil - hingga 320 ms.
Implementasi layanan dalam sistem kerja
Masalah fungsi ganda cukup jelas, kita harus mendukung dua basis kode yang harus melakukan tugas yang sama. Kita perlu mundur. Kami menyebutnya "Sedotan" - kami ingat tentang "sedotan". Selain itu, kita perlu kontrol lalu lintas, itu diharapkan cepat, melalui dashboard.
Bagaimana "sedotan"
Permintaan pencarian datang ke "Straw", yang bekerja di dalam monolith dan dapat membuat panggilan lebih lanjut baik untuk pencarian baru atau lama. Dia membuat panggilan ke pencarian baru, dia memenuhinya, dan jika berhasil, kita hanya mendapatkan hasil dari pencarian baru.
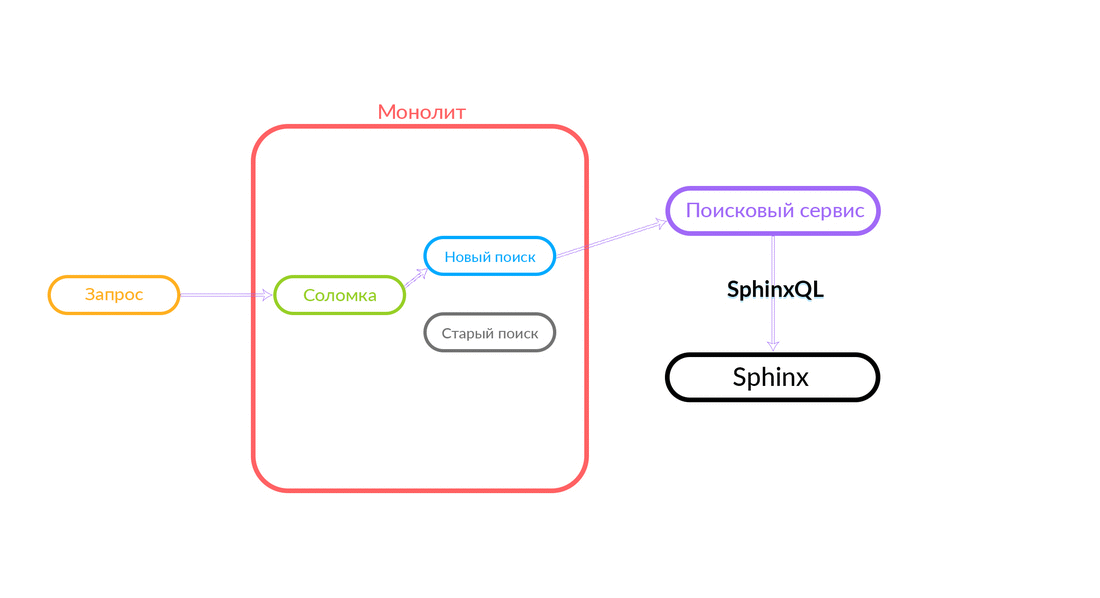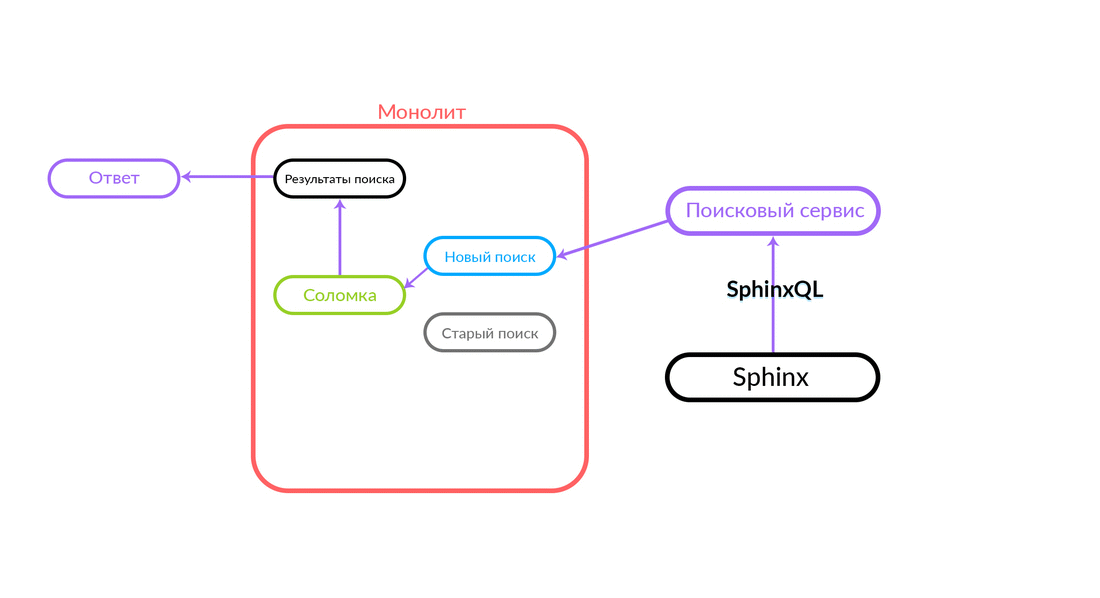
Ada situasi ketika beberapa permintaan untuk layanan pencarian gagal: misalnya, dan sampai beberapa jenis fungsi diimplementasikan di dalam layanan pencarian. Maka kita harus berjanji permintaan semacam itu - "The Straw" akan menjalankannya dalam pencarian lama. Pencarian lama dari monolith akan beralih ke Sphinx, dan jawabannya akan jatuh ke klien. Klien tidak akan merasakan apa pun.
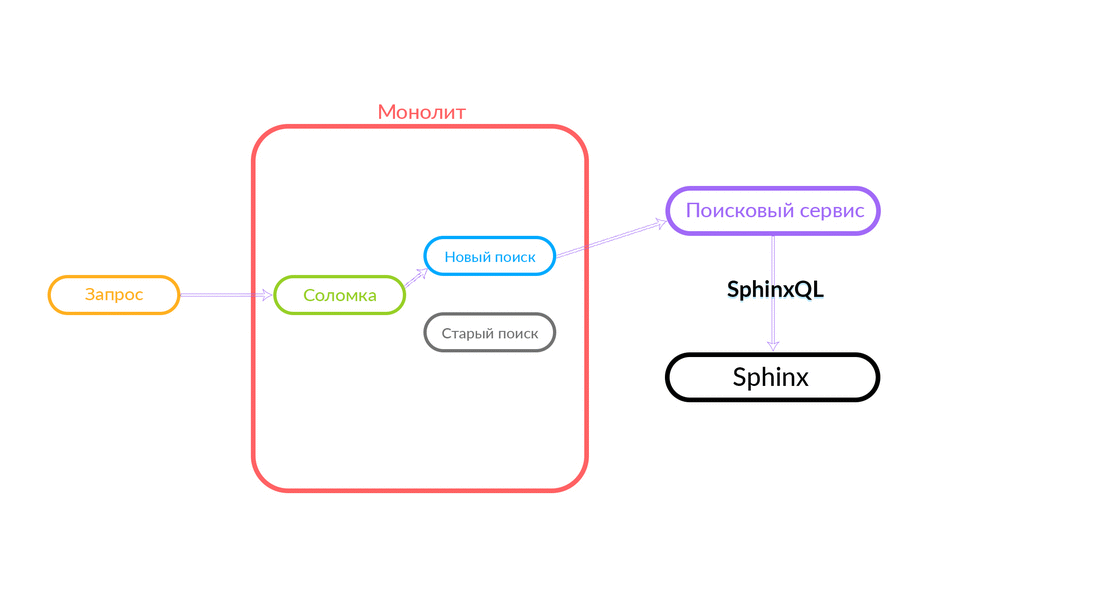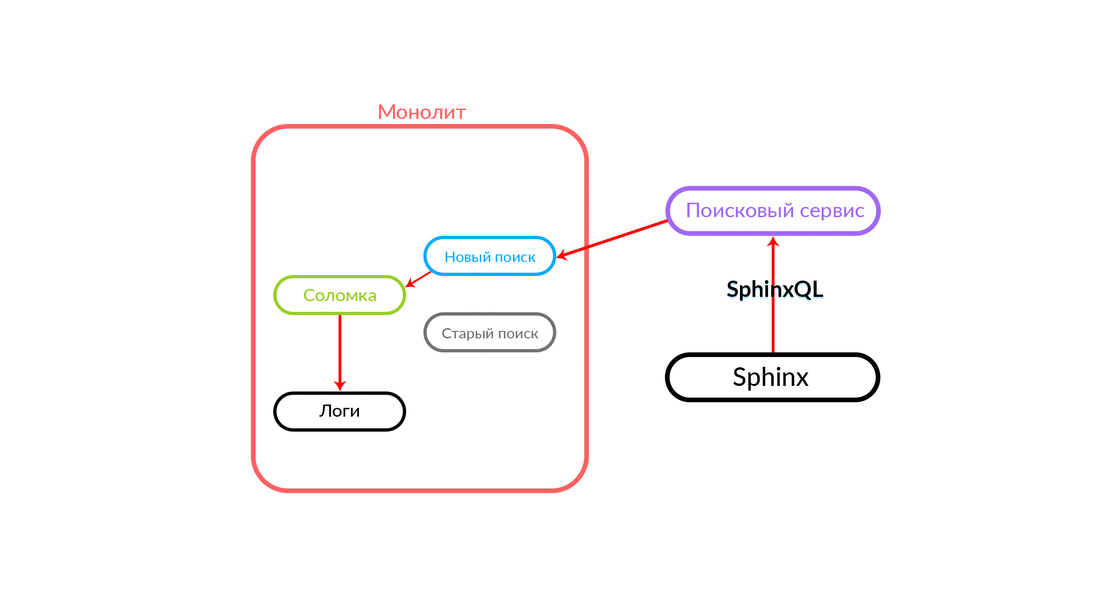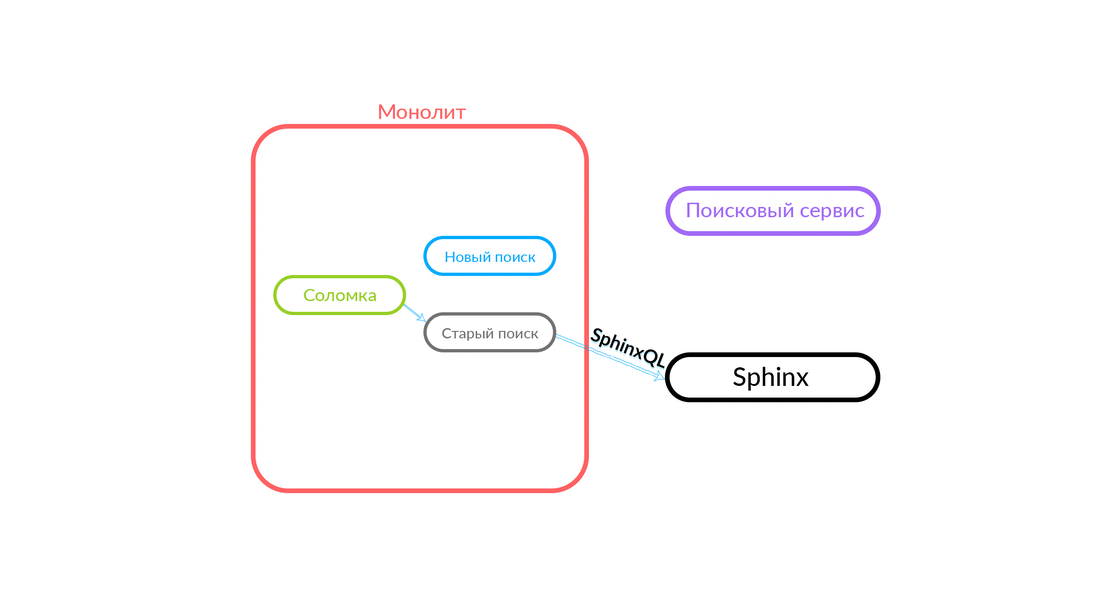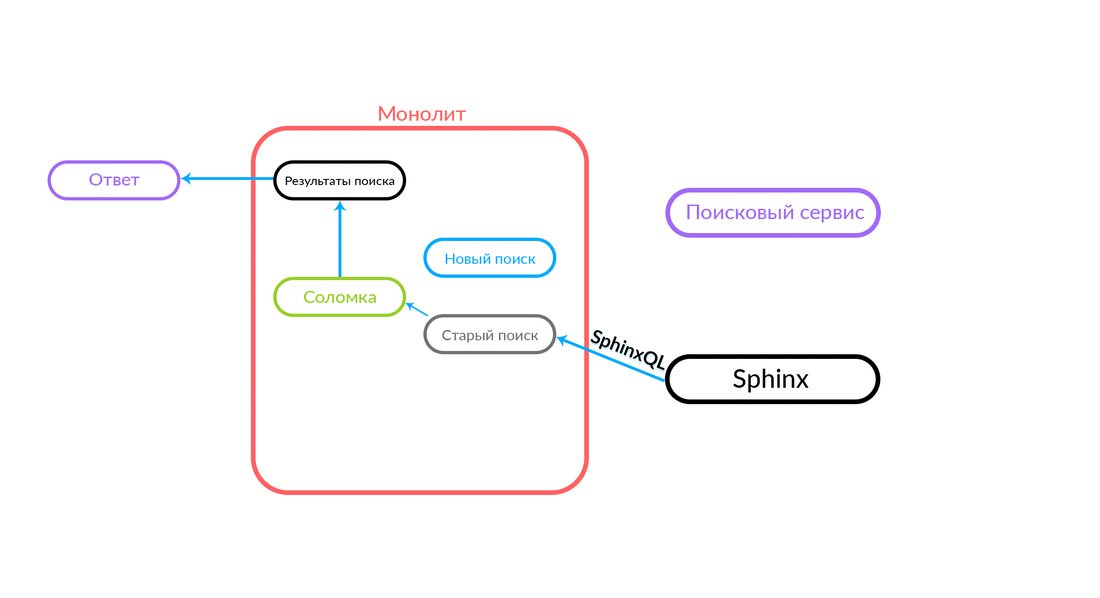
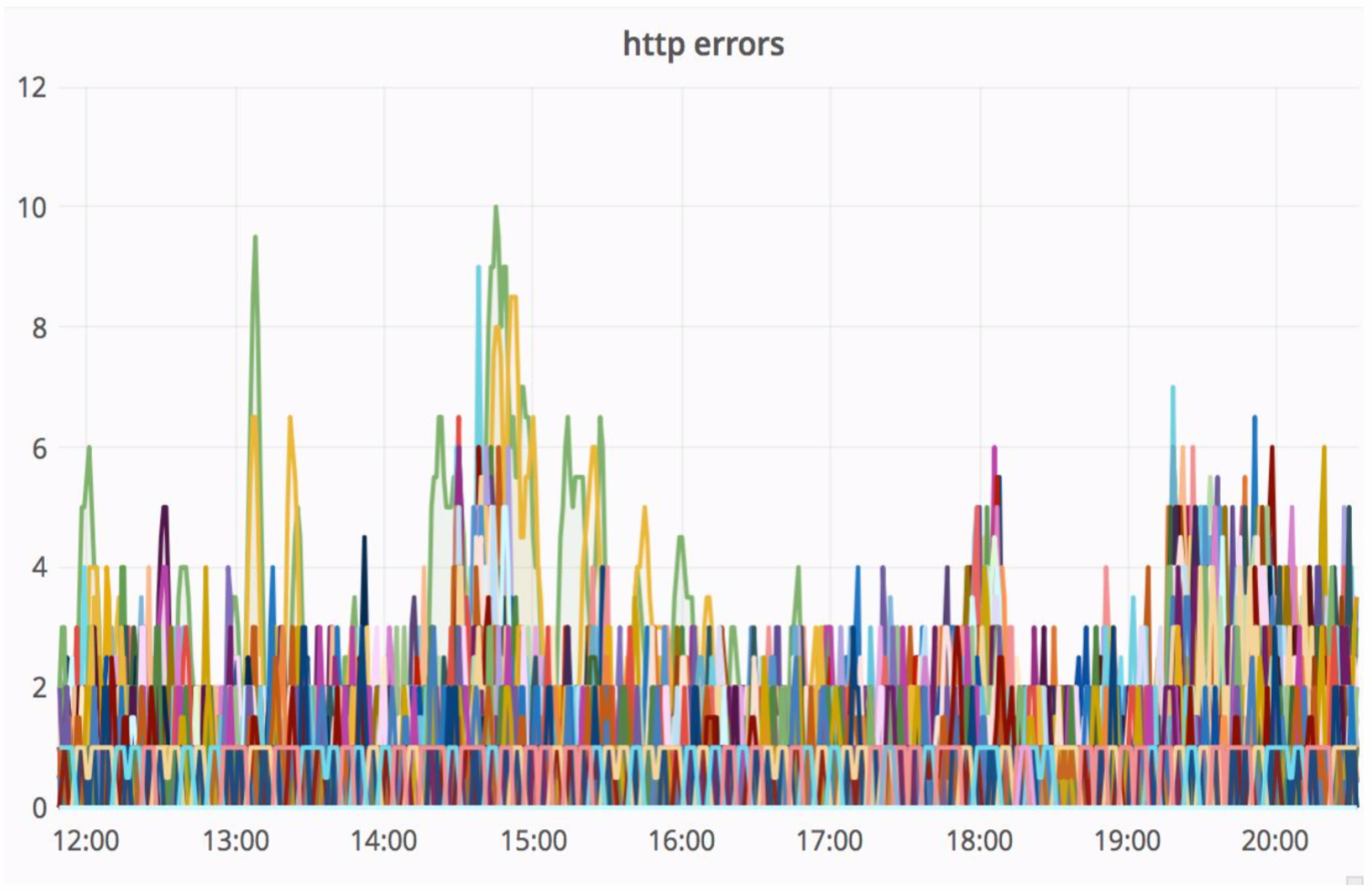
Skema yang cukup andal, dan selalu menarik untuk melihat apa yang terjadi dalam praktik. Departemen Arsitektur Avito terus meningkatkan cloud kami, menyetel, menjadikannya lebih andal dan produktif. Pada tahap tertentu, ada masalah ketika melayani salah satu node dengan intensitas yang cukup tinggi, kesalahan berasal dari monolith (100 kesalahan per detik).

Pada saat yang sama, penundaan layanan meningkat tajam - pada gambar di bawah ini Anda dapat melihat puncak.
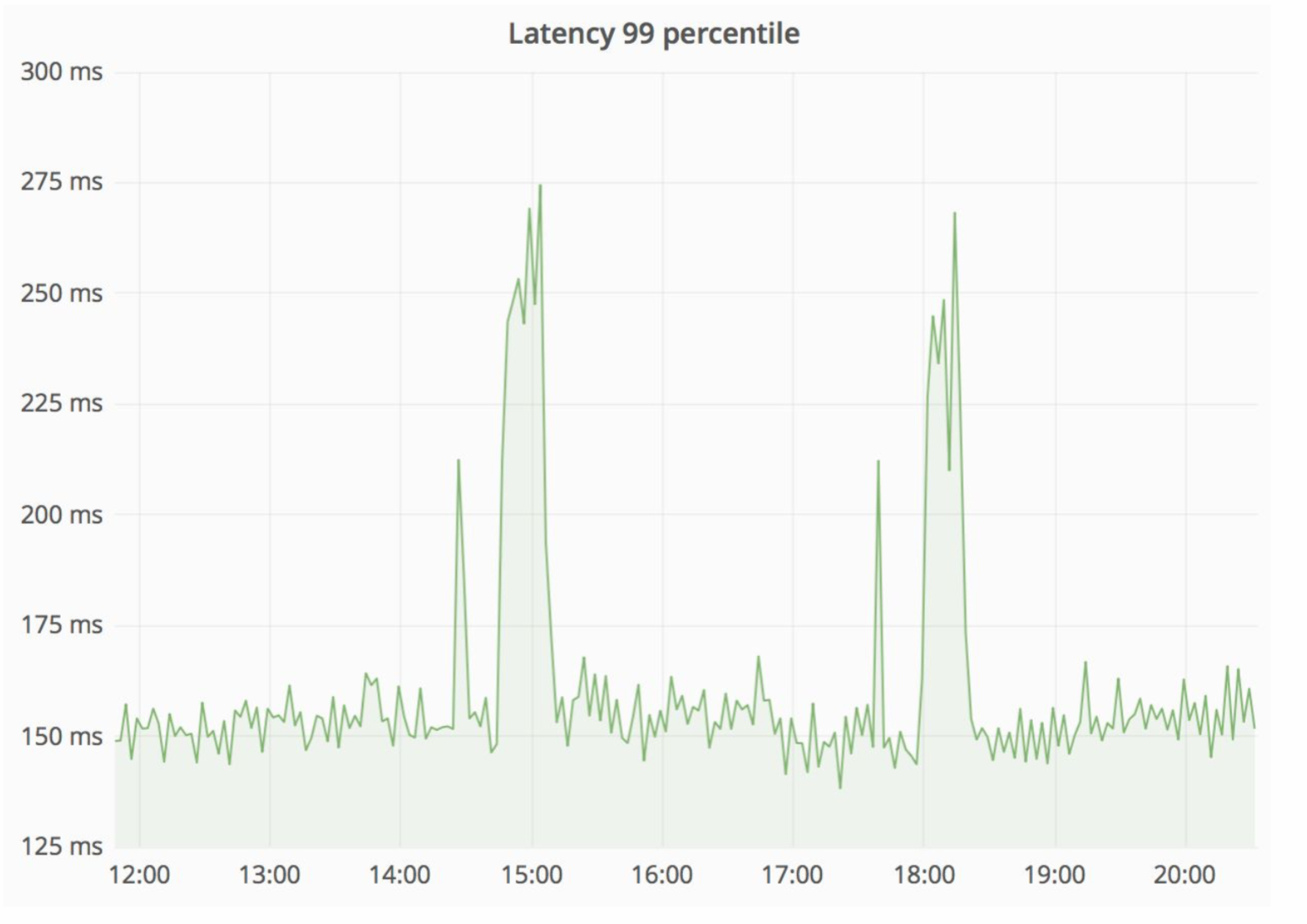
"Jerami" berhasil situasi ini sangat, dan kesalahan HTTP yang dihasilkan berada pada tingkat yang sama - unit kesalahan untuk seluruh Avito. Pengunjung kami tidak melihat apa pun.
Otomasi Eksperimen
Kami ingin pencarian berkembang dengan cepat, dan meluncurkan fitur baru ke dalamnya lebih mudah. Untuk ini, infrastruktur yang tepat diperlukan. Kami telah mengonfigurasi otomatisasi pengujian A / B. Dengan menggunakan dasbor, kita dapat memulai eksperimen baru, mengonfigurasinya berdasarkan inovasi yang ditambahkan, dan, karenanya, menjalankan eksperimen tanpa menggulirkan monolith.
Pada kondisi awal, saat tidak ada satu percobaan pun yang diluncurkan, semua pengunjung melihat fungsi pencarian yang biasa.
Dalam eksperimen yang khas, pengguna dibagi menjadi beberapa kelompok. Grup kontrol - dengan fungsi yang biasa untuk pengunjung kami. Ada beberapa kelompok uji - dengan inovasi. Saat kami perlu membuat eksperimen baru, di layanan pencarian kami menerapkan fungsi pencarian baru (menambahkan agregator baru) dan melalui dasbor kami mengatur percobaan dengan grup yang diperlukan, menghubungkannya dengan agregator baru.
Saat menganalisis eksperimen, kami membandingkan perilaku pengunjung dalam kelompok kontrol dengan yang diuji dan, berdasarkan ini, menarik kesimpulan tentang keberhasilan percobaan.

Misalkan kita telah mengembangkan formula peringkat baru. Apa yang perlu kita lakukan untuk bereksperimen dengannya?
- Di layanan pencarian, gulir agregator yang sesuai (biarlah "Aggregator 2").
- Buat percobaan melalui dasbor dan hubungkan salah satu grup dalam percobaan ini dengan agregator ini.
- Sekarang, jika sebuah pertanyaan datang dalam pencarian yang termasuk dalam kelompok uji, ia pergi ke layanan pencarian di "Aggregator 2".
Kami dapat terus membuat eksperimen baru dan mengaitkan grup uji mereka dengan agregator baru.
Infrastruktur Pencarian Total
Ada sekelompok server Sphinx 3. Ia menampung 13 krps kueri SphinxQL, dan memiliki lebih dari 45 juta iklan aktif.
Sphinx 3.0 stabil dan menyenangkan dengan kinerjanya. Omong-omong, binari berada dalam domain publik . Selain itu, berkat Avito, fitur-fitur baru difilmkan dalam Sphinx 3, misalnya, pengoperasian produk skalar vektor, dan bug yang ditemukan diperbaiki.
Kami menggunakan arsitektur layanan. Kami memiliki layanan pencarian "Iskalo" dan layanan "Avito Assistant". Sebagian dari fungsi tetap ada di monolith, tetapi kami terus berupaya memotongnya.
Kesimpulan
Selama setahun terakhir, sistem pengembangan fungsionalitas pencarian lanjutan telah diterima. Kami mendapat kesempatan untuk melakukan eksperimen cepat dan fleksibel. Dan sekarang pencarian untuk pengguna menjadi lebih mudah, lebih cepat dan lebih baik membantu menyelesaikan masalah mereka.
Apa selanjutnya
Selanjutnya, kami akan terus menghapus dari monolith apa yang tersisa: rendering, filter. Kami akan bekerja untuk meningkatkan kualitas pencarian, terus menyenangkan pengunjung kami. Semoga kamu juga.
Jika Anda memiliki pertanyaan tentang pekerjaan pencarian kami, kami ingin mengetahui lebih banyak detail teknis, tulis di komentar. Saya akan menjawab dengan senang hati. Ngomong-ngomong, baru-baru ini, Andrey Drozdov berbicara di Highload ++ 2018 dengan laporan tentang optimasi multi-kriteria dari hasil pencarian , inilah presentasinya .