
Entah bagaimana, memecahkan masalah analisis linguistik di Power BI dan pada saat yang sama mencari contoh untuk
artikel saya
sebelumnya , saya ingat masalah yang saya coba selesaikan di Excel beberapa tahun yang lalu: perlu untuk mengimplementasikan kamus bahasa Rusia dalam sistem analitik untuk analisis linguistik dari sejumlah besar pertanyaan dalam bahasa alami. Dan diinginkan untuk menggunakan alat kantor standar. Sebagian besar orang akan segera mengambil tugas ini di Excel, dan saya pernah pergi dengan cara yang sama. Saya menggunakan korpus terbuka bahasa Rusia (
http://opencorpora.org/ ) sebagai kamus.
Tapi kekecewaan menunggu saya - kamus terdiri dari 300 ribu bentuk kata, lebih dari 5 juta entri, dan untuk Excel pada prinsipnya adalah jumlah yang mustahil. Bahkan jika Anda mendorong "hanya" 1 juta baris ke dalamnya, maka hanya orang yang sangat sabar yang tidak akan pernah terburu-buru akan dapat melakukan manipulasi dengan mereka atau, Tuhan melarang, perhitungan. Tapi kali ini saya memutuskan untuk menetapkan alat yang lebih cocok untuk tugas tersebut - Power BI.
Apa itu Power BI?
Saya menemukan produk ini sebagian besar diremehkan oleh komunitas profesional. Power BI adalah seperangkat alat analisis bisnis yang dibuat untuk pengguna yang memiliki Excel pada tingkat yang sedikit lebih tinggi daripada "jumlahkan dalam kolom". Jika seseorang dapat menulis rumus kompleksitas sedang di Excel, maka ia akan menguasai Power BI di beberapa malam.
Ini bukan produk tunggal dengan semacam logika pemrograman internal, tetapi sistem tiga komponen:

- Kueri Daya Ini adalah ETL, di mana perlu untuk menulis pertanyaan menggunakan bahasa pemrograman yang berfungsi penuh sendiri - M. Dalam keadilan harus dicatat bahwa, kemungkinan besar, pengguna biasa tidak harus memprogramnya: sebagian besar fungsi tersedia langsung melalui menu atau wizard di antarmuka komponen. Bahasa M benar-benar berbeda dari bahasa permintaan DAX (PowerPivot). Namun, Microsoft menyatukan mereka. Ini masuk akal dari sudut pandang pengembangan: ETL dirancang untuk menerima dan saturasi awal data (tidak cepat), dan DAX - untuk perhitungan yang membantu kami memvisualisasikan data ini (dengan cepat). Yaitu, DAX adalah untuk ujung depan, dan Power Query untuk backend, untuk proses penggalian dan pemformatan data.
- PowerPivot . Modul pemrosesan dalam memori yang didasarkan pada mesin xVelocity. Menggunakan bahasa permintaan DAX, sangat mirip dengan bahasa rumus Excel.
- Komponen visualisasi . Ini sangat berguna untuk aplikasi dalam sistem di mana Anda perlu memvisualisasikan data: di situs web perusahaan, atau di portal dukungan teknis (misalnya, cloud permintaan), atau di sumber daya perusahaan internal. Ada alat yang dapat melakukan ini tanpa Power BI, tetapi banyak dari mereka tidak akan membantu ketika jumlah catatan dalam jutaan dan data perlu dikumpulkan entah bagaimana. Dan dengan alat-alat lain semacam ini, Power BI bersaing karena kesederhanaannya dan biaya pemrosesan memori yang rendah. Jelas bahwa jika kita berbicara tentang data terabyte, maka pendekatan yang berbeda akan diperlukan. Dan untuk kasus-kasus seperti itu, Microsoft sudah memiliki sesuatu untuk ditawarkan, tetapi ini adalah topik untuk artikel terpisah.
Kurva pembelajaran pada tahap pertama meningkat sangat tajam: jika Anda mahir di Excel, maka 80% fitur Power BI akan terbuka untuk Anda setelah studi singkat. Ini adalah alat yang sangat kuat, cukup mudah digunakan, tetapi - sampai titik tertentu. Untuk menggunakannya dengan kapasitas penuh, Anda sudah membutuhkan pengalaman dan pengetahuan mendalam tentang bahasa M dan DAX.
Apa itu Power BI Desktop?
Untuk siapa ini berguna? Pertama-tama, setiap pengguna bisnis yang harus memproses dan menganalisis data dalam jumlah yang cukup besar ketika Excel tidak lagi mampu mengatasi atau mengisap sampai batas. Saya tekankan - Power BI Desktop dirancang
untuk berbagai pengguna yang menyelesaikan beragam tugas . Misalnya, dalam kasus saya, ini tentang menormalkan 5 juta entri teks untuk penentuan frekuensi kata kunci berikutnya.
Ini sangat dibutuhkan ketika memproses kuesioner, permintaan mesin pencari, iklan, dikte / esai, semacam array statistik, dll. Atau untuk memecahkan teka-teki silang ...
Kasus lain dan opsi implementasi dipertimbangkan dalam
artikel tentang "pengenal" Dmitry Tumaikin. Diterapkan pada Excel klasik, tetapi menggunakan makro ...
Skenario populer lainnya untuk aplikasi Power BI ini adalah menghitung rasio indikator untuk periode saat ini dan sebelumnya. Misalnya, kami memiliki data pendapatan pra-agregat, dan Anda perlu membandingkannya berdasarkan hari dengan kuartal sebelumnya, atau tahun, atau periode yang serupa. Dan saya ingin / perlu memasukkan hasil perbandingan di kolom berikutnya dalam bentuk nilai, bukan rumus. Tampaknya bagi Excel tugas paling sederhana adalah menulis rumus perbandingan sederhana dan merentangkannya ke semua sel di kolom. Tetapi tidak jika Anda memiliki beberapa juta baris dalam tabel. Di DAX sendiri tugas ini bahkan lebih mudah daripada di Excel, tetapi juga hanya dengan bantuan post-perhitungan.
Banyak skenario praktis lain untuk menggunakan Power BI dapat diberikan, tetapi Anda, saya pikir, sudah memahami esensinya. Tentu saja, semua tugas ini bukan masalah bagi seorang programmer yang memiliki, misalnya, Python atau R, tetapi spesialis semacam itu adalah apriori yang lebih kecil berdasarkan urutan besarnya daripada para ahli Excel. Excel hanya memiliki kemampuan terbatas, tetapi tidak demikian halnya dengan Power BI, yang menggunakan bahasa rumus DAX, yang sangat mirip dengan bahasa rumus Excel, dan mampu memproses jutaan dan puluhan juta rekaman dengan cepat. Dan kemudian Anda perlu meningkatkan RAM (setidaknya hingga 100, setidaknya hingga 300 GB).
Kami membantu permintaan proses dukungan teknis
Tetapi kembali ke tugas saya. Itu perlu untuk datang dengan bagaimana dukungan teknis garis nol akan secara otomatis mengevaluasi topik permintaan pengguna. Sebagai permulaan, saya memutuskan untuk mengisolasi formulir kata tertentu dan menentukan topik paling penting yang paling sering diangkat pengguna berdasarkan frekuensi kemunculannya dalam pesan.
Kamus sumber adalah file teks sederhana yang memiliki struktur reguler dan terlihat seperti ini:
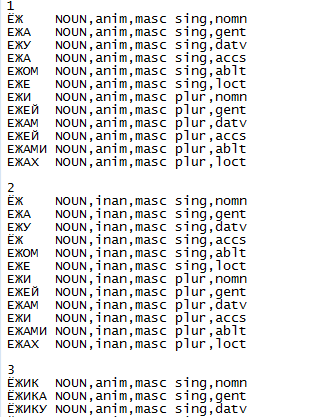
Untuk keperluan statistik, perlu untuk menentukan bentuk awal untuk setiap bentuk kata: untuk kata benda - nomor tunggal dari kasus nominatif, untuk kata kerja - bentuk yang tidak terbatas, dll. Untuk programmer, tugas ini lebih sederhana daripada sederhana: untuk setiap kata di kolom kiri, cari korespondensi dengan formulir yang segera mengikuti jumlah kata ini di kamus.
Itu hanya pengguna bisnis rata-rata yang tidak memiliki Python, alat khusus dan keterampilan pengembangan, tidak akan dapat menyelesaikan masalah ini tanpa menggunakan BI analitik diri atau alat serupa yang ramah pengguna. Selain itu, jika data perlu diproses untuk kebutuhan internal atau tidak ada informasi rahasia yang memerlukan perlindungan, maka Power BI dalam hal ini juga akan bebas *.
Teks tersembunyi*) Ini merujuk pada versi Power BI Desktop dan versi Layanan Power BI untuk penggunaan pribadi dengan tarif Gratis.
Untuk menganalisis data, saya perlu di Power Query, dalam tabel 5 juta catatan, tambahkan kolom baru, digeser oleh satu posisi. Pada awalnya, saya mencoba menerapkan pendekatan klasik menggunakan Power Query, yang
dijelaskan pada portal komunitas Power BI oleh Marcel Beug, penulis panduan referensi online Power Query asli (juga ditulis dalam Power Query). Dua algoritma berbeda diusulkan dalam artikel: satu diilhami oleh ide-ide Matt Elington, seorang guru terkenal dan pelatih Power BI, dan pendekatan kedua adalah ide asli Marcel sendiri, menggunakan fungsi tambahan. Terlepas dari kenyataan bahwa untuk meningkatkan produktivitas, saya benar-benar menyimpan data sumber, kedua pendekatan tersebut membutuhkan waktu yang sangat lama - mereka telah melewati hari kedelapan, dan prosesnya belum selesai. Ukuran file sumber adalah 270 MB, dan ukuran saat ini dari data yang diproses mendekati 17 TB. Saya yakin beberapa pengguna Power BI telah melihat angka seperti itu di jendela untuk memuat data dari sumber file.
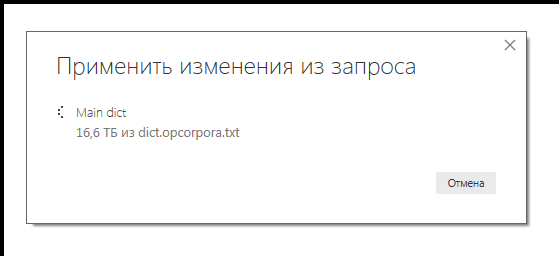
Mengapa volumenya begitu bengkak, tidak jelas; bahkan produk Cartesian dari semua catatan jauh lebih kecil dari 16 Tb. Di sini, pengoptimal internal jelas tidak sesuai standar. Dan, misalnya, DAX-Studio tidak memungkinkan melacak kueri Power Query, hanya DAX. Mungkin seseorang akan berbagi pengalaman mereka dengan PQ Troubleshipping?
Tanpa menunggu selesainya proses pertama, saya memutuskan pada komputer lain untuk mencoba memecahkan masalah menggunakan DAX melalui permintaan yang ditulis sendiri. Permintaan terpenuhi ... dalam sekitar 180 detik, dan konsumsi memori sedikit meningkat.

Kode sumber untuk permintaan DAX:
KeyWord =
CALCULATE(
TOPN(1;
CALCULATETABLE(
VALUES(ShiftedList[Word])
;ALLEXCEPT(ShiftedList;ShiftedList[Word Nr])
)
)//TOPN
)//CALCULATE
Yaitu, untuk setiap baris dalam kolom [Kata Kunci] baru, nilai pertama kolom [Kata] dicari, yang berisi semua varian bentuk kata yang memiliki nomor bentuk kata dasar yang sama (kolom [Kata-kata]). Selama format file sumber tidak berubah, permintaan harus memenuhi tanpa kesalahan pada semua rilis berikutnya dari kamus.
Kode kueri di Power Query, yang membentuk tabel sumber dalam format yang diperlukan, dihasilkan "secara otomatis" dan diselesaikan dalam waktu kurang dari satu menit:

Setelah kolom kata kunci telah dibentuk di antarmuka PowerPivot dalam tiga menit, mencari bentuk kata apa pun di antarmuka Power BI tidak lebih dari 4 detik. Selain itu, pencarian kontrol untuk data yang sama di Notepad ++ x64 favorit Anda dapat memakan waktu 20 detik atau lebih. Tapi ini bukan batu di kebun NPP - lebih sulit (dan lebih lama) untuk mencari seluruh array data daripada menurut data yang sudah ditandai.
Omong-omong, permintaan DAX di atas tidak lahir pertama kali, dan opsi perantara menghabiskan semua memori yang tersedia, bekerja untuk waktu yang lama dan berakhir dengan kesalahan data atau hasil yang tidak relevan.

Akibatnya, ukuran file PBIX yang disimpan menjadi 60% (112 MB) lebih kecil dari kamus teks asli, tetapi lebih dari 4 kali ukuran arsip ZIP dengan kamus yang sama.
Kembali ke pertempuran antara Power Query dan DAX: perbedaan dalam durasi operasi yang sama di komponen yang berbeda menunjukkan bahwa Power BI bukan linggis yang tidak ada penerimaan. Ia memiliki karakter dan fitur aplikasi sendiri, yang harus diperhitungkan dalam karyanya. Sebenarnya, seperti alat apa pun. Dan rekomendasi guru yang bahkan diakui harus diperlakukan dengan hati-hati.
Tampaknya peraih Nobel Richard Smalley biasa berkata, mengutip hukum pertama Clark: “Ketika para ahli mengatakan bahwa sesuatu itu layak, maka mereka mungkin benar (mereka hanya tidak tahu kapan). Ketika mereka mengatakan bahwa ini tidak mungkin, maka kemungkinan besar mereka keliru. "
Karakteristik dari mesin uji:
Prosesor: Intel Core i7 4770 @ 3.4 GHz (4 core)
RAM: 16 GB
OS: Windows 7 Enterprise SP1 x64Kamus siap pakai dalam format Power BI dapat diunduh
dari sini .
Dan di
sini tersedia versi kamus online yang dimodifikasi. Anda dapat memecahkan teka-teki silang dengan santai :)

... Ngomong-ngomong, kemudian, beberapa tahun yang lalu, tugas itu diselesaikan di Excel, meskipun tidak 100%. Hanya untuk analisis teks, tidak seluruh korpus bahasa Rusia digunakan, tetapi kamus frekuensi. Untuk pembersihan teks dasar, salah satu dari
daftar frekuensi top100 yang tersedia di
sini untuk beberapa puluh kilobyte cukup cocok.
Yuri Kolmakov, Pakar, Departemen Konsolidasi dan Sistem Visualisasi Data, Jet Infosystems ( McCow )