Analisis publikasi Lenta.ru selama 18 tahun (dari September 1999 hingga Desember 2017) menggunakan python, sklearn, scipy, XGBoost, pymorphy2, nltk, gensim, MongoDB, Keras dan TensorFlow.

Penelitian ini menggunakan data dari pos " Analisis ini - Lenta.ru " oleh ildarchegg . Penulis dengan ramah menyediakan 3 gigabytes artikel dalam format yang nyaman, dan saya memutuskan bahwa ini adalah kesempatan bagus untuk menguji beberapa metode pemrosesan teks. Pada saat yang sama, jika Anda beruntung, pelajari sesuatu yang baru tentang jurnalisme Rusia, masyarakat, dan secara umum.
Konten:
MongoDB untuk mengimpor json dengan python
Sayangnya, json dengan teks ternyata agak rusak, itu tidak penting bagi saya, tetapi python menolak untuk bekerja dengan file tersebut. Oleh karena itu, saya pertama kali mengimpornya ke MongoDB, dan hanya kemudian, melalui MongoClient dari pymongo library, saya memuat array dan menyimpannya kembali dalam csv dalam bentuk potongan.
Dari komentar: 1. Saya harus memulai database dengan perintah sudo service mongod start - ada pilihan lain, tetapi mereka tidak bekerja; 2. mongoimport - aplikasi terpisah, tidak dimulai dari konsol mongo, hanya dari terminal.
Kesenjangan data merata di seluruh tahun. Saya tidak berencana untuk menggunakan periode kurang dari satu tahun, saya harap itu tidak akan mempengaruhi kebenaran kesimpulan.
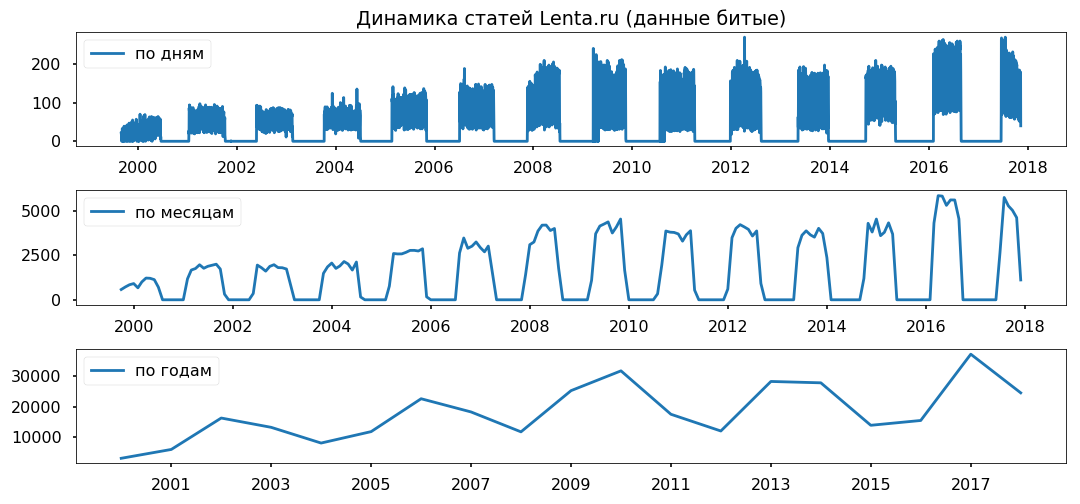
Membersihkan dan menormalkan teks
Sebelum secara langsung menganalisis array, Anda perlu membawanya ke bentuk standar: menghapus karakter khusus, mengonversi teks menjadi huruf kecil (metode string panda melakukan pekerjaan dengan baik), menghapus kata-kata berhenti (stopwords.words ('Rusia') dari nltk.corpus), mengembalikan kata-kata ke bentuk normal mereka menggunakan lemmatization (pymorphy2.MorphAnalyzer).
Ada beberapa kelemahan, misalnya, Dmitry Peskov berubah menjadi "Dmitry" dan "pasir", tetapi secara keseluruhan saya senang dengan hasilnya.
Tag cloud
Sebagai benih, mari kita lihat publikasi apa yang berada dalam bentuk paling umum. Kami akan menampilkan 50 kata yang paling sering digunakan oleh jurnalis Lenta dari tahun 1999 hingga 2017 dalam bentuk tag cloud.

Ria Novosti (sumber paling populer), miliar dolar dan jutaan dolar (topik keuangan), hadir (sirkulasi bicara umum ke semua situs berita), lembaga penegak hukum dan kasus kriminal (berita kriminal) ), "Perdana Menteri" dan "Vladimir Putin" (politik) - gaya dan tema yang diharapkan untuk portal berita.
Pemodelan Bertema LDA
Kami menghitung topik paling populer untuk setiap tahun menggunakan LDA dari gensim. LDA (pemodelan tematik menggunakan metode penempatan laten Dirichlet) secara otomatis mengungkapkan topik tersembunyi (satu set kata yang muncul bersamaan dan paling sering) dengan frekuensi kata yang diamati dalam artikel.
Landasan jurnalisme domestik adalah Rusia, Putin, Amerika Serikat.
Dalam beberapa tahun, topik ini diencerkan dengan perang Chechnya (dari tahun 1999 hingga 2000), 11 September - pada tahun 2001, dan Irak (dari tahun 2002 hingga 2004). Dari 2008 hingga 2009, ekonomi menempati urutan pertama: bunga, perusahaan, dolar, rubel, miliar, juta. Pada 2011, mereka sering menulis tentang Gaddafi.
Dari 2014 hingga 2017 tahun-tahun Ukraina dimulai dan berlanjut di Rusia. Puncaknya terjadi pada 2015, maka tren mulai menurun, tetapi masih terus tetap pada level tinggi.
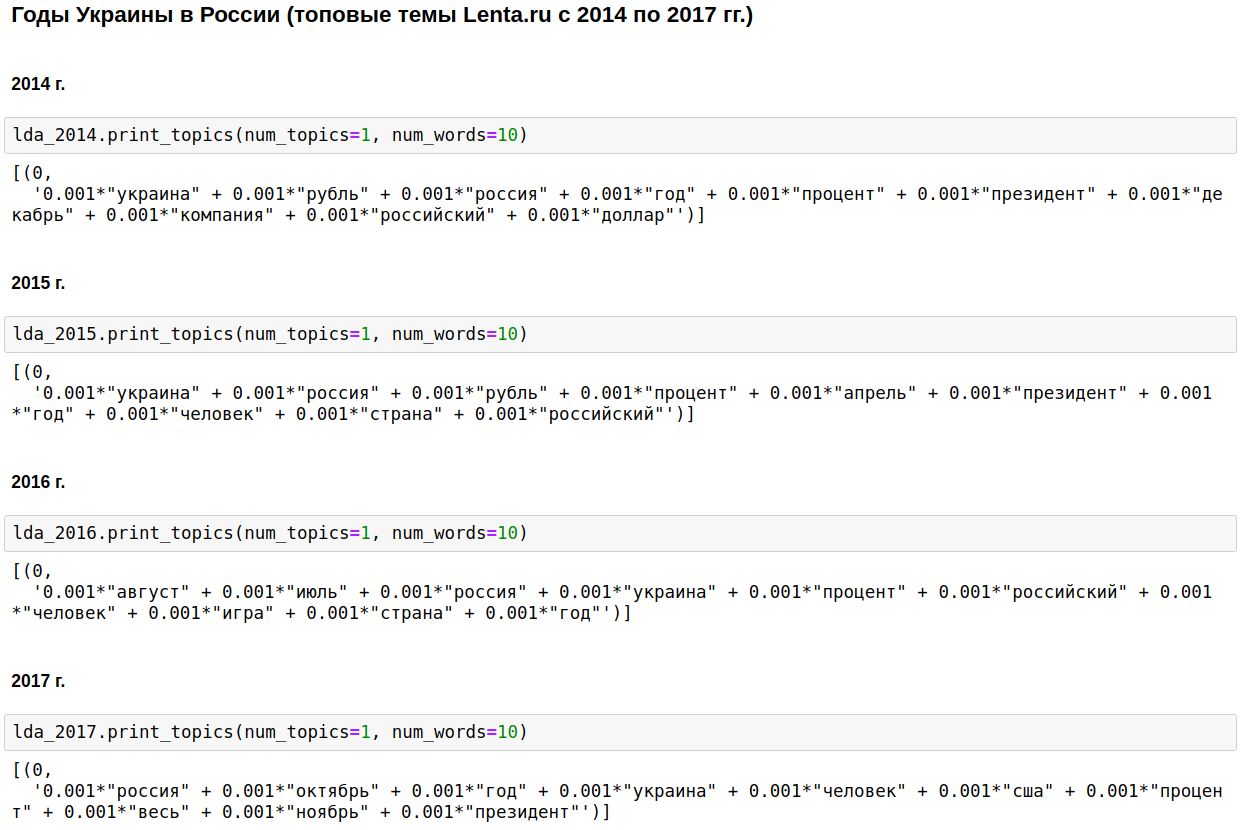
Memang menarik, tentu saja, tetapi tidak ada yang tidak akan saya ketahui atau tebak.
Mari kita ubah pendekatan sedikit - pilih topik teratas sepanjang waktu dan lihat bagaimana rasio mereka telah berubah dari tahun ke tahun, yaitu, kita akan mempelajari evolusi topik.
Opsi yang paling ditafsirkan adalah Top 5:
- Kejahatan (pria, polisi, terjadi, ditahan, polisi);
- Politik (Rusia, Ukraina, Presiden, AS, Kepala);
- Budaya (pemintal, purulen, instagram, bertele-tele - ya, ini adalah budaya kita, meskipun secara khusus topik ini ternyata agak campuran);
- Olahraga (pertandingan, tim, permainan, klub, atlet, kejuaraan);
- Ilmu pengetahuan (ilmuwan, ruang angkasa, satelit, planet, sel).
Selanjutnya, kami mengambil setiap artikel dan melihat bagaimana hubungannya dengan topik tertentu, sebagai akibatnya, semua materi akan dibagi menjadi lima kelompok.
Kebijakan itu ternyata menjadi yang paling populer - di bawah 80% dari semua publikasi. Namun, puncak popularitas materi politik disahkan pada tahun 2014, sekarang bagian mereka menurun, dan kontribusi pada agenda informasi Kejahatan dan Olahraga semakin meningkat.
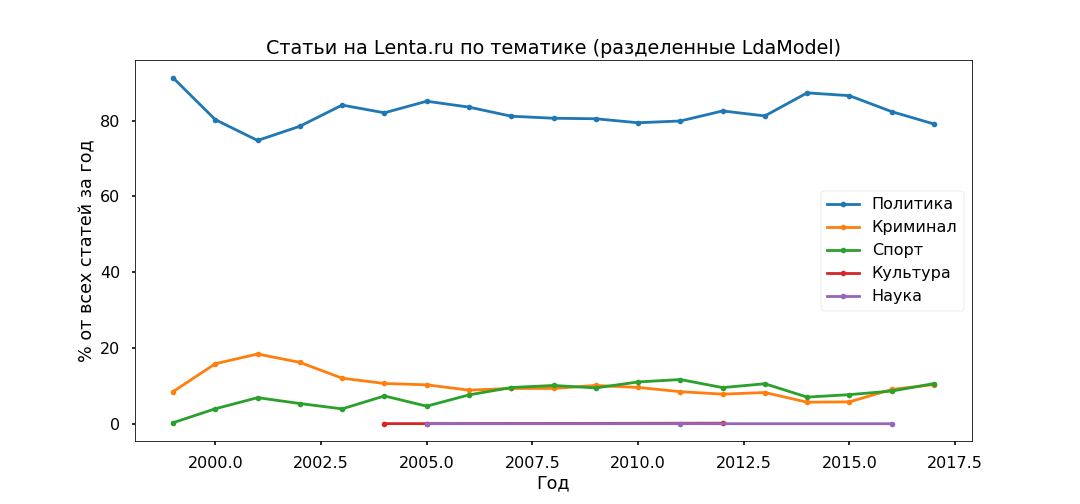
Kami akan memeriksa kecukupan model tematik menggunakan subpos yang ditunjukkan oleh editor. Subkategori teratas telah diidentifikasi dengan tepat sejak 2013.

Tidak ada kontradiksi khusus yang diperhatikan: Politik mandek pada 2017, Sepak Bola dan Insiden terus berkembang, Ukraina masih dalam tren, dengan puncak pada 2015.
Prediksi popularitas: XGBClassifier, LogisticRegression, Embedding & LSTM
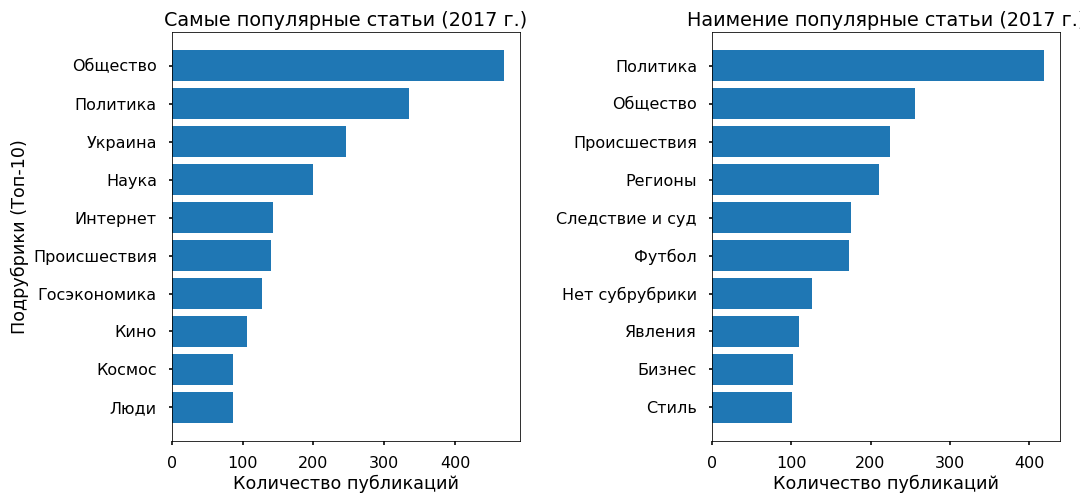
Mari kita coba memahami apakah mungkin untuk memprediksi popularitas sebuah artikel di Tape dari teks, dan pada apa popularitas ini umumnya bergantung. Sebagai variabel target, saya mengambil jumlah repost Facebook untuk 2017.
3 ribu artikel untuk 2017 tidak memiliki posting ulang di Fb - mereka diberi kelas "tidak populer", 3 ribu artikel dengan jumlah posting terbanyak menerima label "paling populer".
Teks (6 ribu publikasi untuk 2017) dibagi menjadi unograms dan bigrams (kata-kata token, baik frase tunggal dan dua kata) dan matriks dibangun di mana kolom adalah token, baris adalah artikel, dan di persimpangan relatif frekuensi kemunculan kata dalam artikel. Fungsi yang digunakan dari sklearn - CountVectorizer dan TfidfTransformer.
Data yang disiapkan diumpankan ke input XGBClassifier (classifier berdasarkan peningkatan gradien dari perpustakaan xgboost), yang setelah 13 menit penghitungan hyperparameters (GridSearchCV dengan cv = 3) memberikan akurasi 76% pada tes.

Kemudian saya menggunakan regresi logistik biasa (sklearn.linear_model.LogisticRegression) dan setelah 17 detik saya mendapat akurasi 81%.
Sekali lagi saya yakin bahwa metode linear paling cocok untuk klasifikasi teks, asalkan datanya disiapkan dengan cermat.
Sebagai penghargaan untuk fashion, saya sedikit menguji jaringan saraf. Dia menerjemahkan kata-kata menjadi angka menggunakan one_hot dari keras, membawa semua artikel ke panjang yang sama (fungsi pad_afterences dari keras) dan menerapkan LSTM (jaringan saraf convolutional, menggunakan backend TensorFlow) melalui lapisan Embedding (untuk mengurangi dimensi dan mempercepat waktu pemrosesan).
Jaringan bekerja dalam 2 menit dan menunjukkan akurasi pada pengujian 70%. Sama sekali tidak membatasi, tetapi dalam hal ini tidak masuk akal untuk banyak repot.
Secara umum, semua metode menghasilkan akurasi yang relatif rendah. Seperti yang ditunjukkan oleh pengalaman, algoritma klasifikasi bekerja dengan baik dengan berbagai gaya - pada materi hak cipta, dengan kata lain. Ada materi seperti itu di Lenta.ru, tetapi ada sangat sedikit dari mereka - kurang dari 2%.

Array utama ditulis menggunakan kosakata berita netral. Dan popularitas berita ditentukan bukan oleh teks itu sendiri dan bahkan bukan topik seperti itu, tetapi milik mereka dalam tren informasi ke atas.
Sebagai contoh, beberapa artikel populer meliput acara di Ukraina, yang paling tidak populer hampir tidak membahas topik ini.
Menjelajahi Objek Menggunakan Word2Vec
Sebagai kesimpulan, saya ingin melakukan analisis sentimental - untuk memahami bagaimana jurnalis berhubungan dengan objek paling populer yang mereka sebutkan dalam artikel mereka, apakah sikap mereka berubah seiring waktu.
Tetapi saya tidak memiliki data yang ditandai, dan pencarian thesauri semantik tidak akan berfungsi dengan benar, karena kosa kata berita sangat netral, pelit dengan emosi. Oleh karena itu, saya memutuskan untuk fokus pada konteks di mana objek disebutkan.
Saya mengambil Ukraina (2015 vs 2017) dan Putin (2000 vs 2017) sebagai ujian. Saya memilih artikel di mana mereka disebutkan, menerjemahkan teks ke dalam ruang vektor multidimensi (Word2Vec dari gensim.models) dan memproyeksikannya menjadi dua dimensi menggunakan metode Komponen Utama.
Setelah merender foto-foto itu, mereka ternyata epik, tidak kurang dari ukuran permadani dari Bayeux. Saya memotong kluster yang diperlukan untuk menyederhanakan persepsi, yang saya bisa, maaf untuk "serigala".


Apa yang saya perhatikan.
Putin dari model 2000 selalu muncul dalam konteks Rusia dan telah ditangani secara pribadi. Pada tahun 2017, presiden Federasi Rusia berubah menjadi pemimpin (apa pun artinya) dan menjauhkan diri dari negara itu, sekarang, dilihat dari konteksnya, ia adalah perwakilan Kremlin yang berkomunikasi dengan dunia melalui sekretaris persnya.
Ukraina-2015 di media Rusia - perang, pertempuran, ledakan; disebutkan depersonalized (Kiev menyatakan, Kiev dimulai). Ukraina-2017 muncul terutama dalam konteks negosiasi antara pejabat, dan orang-orang ini memiliki nama tertentu.
...
Anda dapat menginterpretasikan informasi yang diterima untuk beberapa waktu, tetapi, seperti yang saya pikirkan, ini adalah sumber daya offtopic pada sumber daya ini. Mereka yang berharap dapat melihat sendiri. Saya lampirkan kode dan data.
Tautan Skrip
Tautan Data