
Seperti yang Anda ketahui, HTTP 1.1 adalah protokol transfer data berbasis teks. Pesan HTTP dikodekan menggunakan ISO-8859-1 (yang secara kondisional dapat dianggap sebagai versi ASCII yang diperluas yang berisi umlaut, diakritik, dan karakter lain yang digunakan dalam bahasa Eropa Barat). Pada saat yang sama, penyandian lain dapat digunakan di badan pesan, yang harus ditunjukkan di header "Tipe Konten". Tetapi bagaimana jika kita perlu menentukan karakter non-ASCII bukan di badan pesan, tetapi di header itu sendiri? Mungkin kasus yang paling umum adalah meletakkan nama file di header "Content-Disposition". Ini tampaknya menjadi tugas yang cukup umum, tetapi implementasinya tidak begitu jelas.
TL; DR: Gunakan pengkodean yang dijelaskan dalam
RFC 6266 untuk "Content-Disposition" dan ubah teks menjadi Latin (transliterasi) dalam kasus lain.
Intro kecil untuk pengkodean
Artikel tersebut menyebutkan dan menggunakan pengkodean US-ASCII (sering disebut sebagai ASCII), ISO-8859-1, dan UTF-8. Ini adalah pengantar kecil untuk pengkodean ini. Bagian ini ditujukan untuk pengembang yang jarang atau sepenuhnya tidak bekerja dengan penyandian dan berhasil melupakannya. Jika Anda bukan milik mereka, silakan lewati bagian ini.
ASCII adalah penyandian sederhana yang berisi 128 karakter dan termasuk seluruh alfabet, angka, tanda baca dan karakter layanan bahasa Inggris.
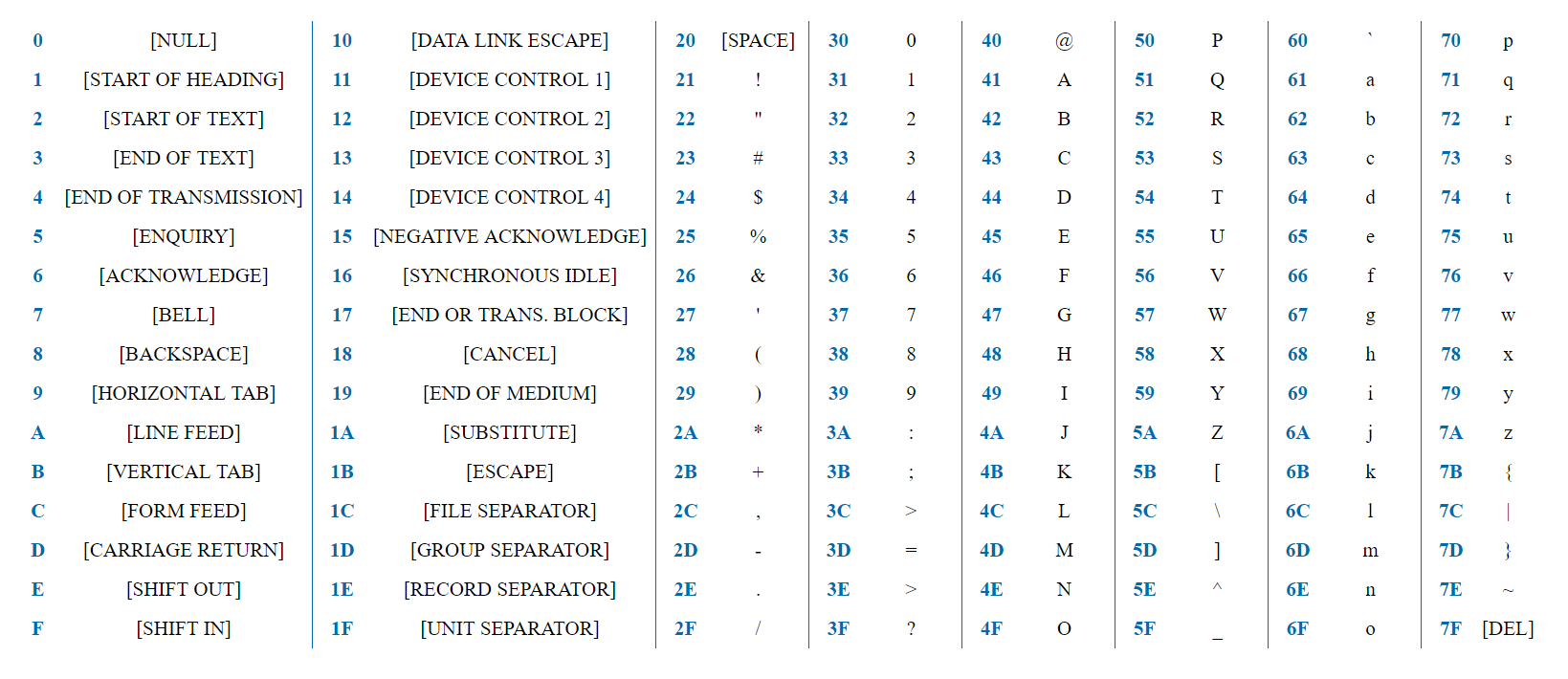
7 bit sudah cukup untuk mewakili karakter ASCII. Kata "test" akan direpresentasikan dalam representasi HEX sebagai 0x74 0x65 0x73 0x74. Bit pertama untuk semua karakter selalu 0, karena karakter dikodekan dalam 128, dan byte menyediakan 2 ^ 8 = 256 opsi.
ISO-8859-1 adalah penyandian yang ditujukan untuk bahasa Eropa Barat. Berisi diakritik Prancis, umlaut Jerman, dll.
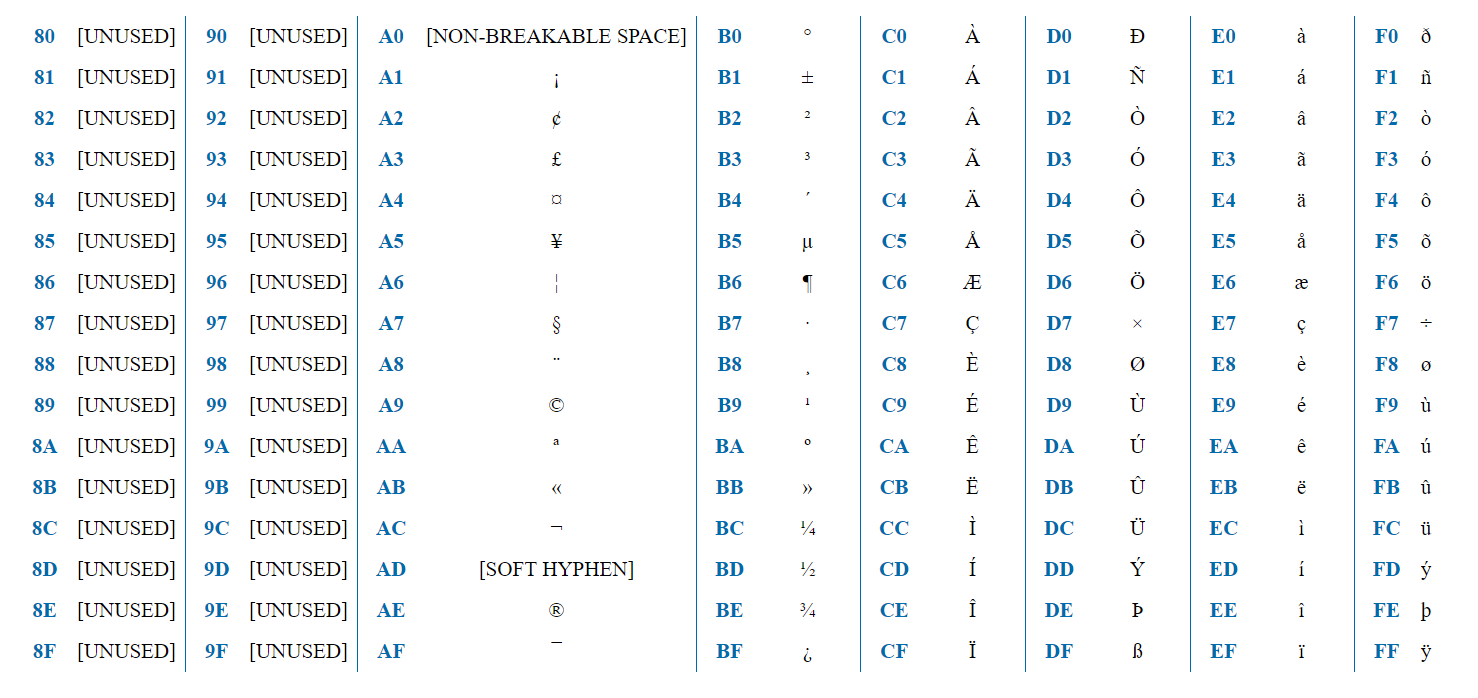
Pengkodean berisi 256 karakter dan, dengan demikian, dapat diwakili oleh satu byte. Paruh pertama (128 karakter) persis sama dengan ASCII. Jadi, jika bit pertama = 0, maka ini adalah karakter ASCII biasa. Jika 1, maka ini adalah karakter khusus untuk ISO-8859-1.
UTF-8 adalah salah satu pengkodean paling terkenal bersama dengan ASCII. Mampu meng-encode 1.112.064 karakter.
Ukuran setiap karakter bervariasi dari 1 hingga 4 byte (
sebelumnya diizinkan hingga 6 byte).

Program yang bekerja dengan pengkodean ini ditentukan oleh bit pertama berapa banyak byte yang termasuk dalam karakter. Jika oktet dimulai pada 0, maka karakter diwakili oleh satu byte. 110 - dua byte, 1110 - tiga byte, 11110 - 4 byte.
Seperti dengan ISO-8859-1, 128 karakter pertama sepenuhnya sesuai ASCII. Oleh karena itu, teks yang hanya menggunakan karakter ASCII akan benar-benar identik dalam representasi biner, terlepas dari apakah US-ASCII, ISO-8859-1 atau UTF-8 digunakan untuk penyandian.
Menggunakan UTF-8 di isi pesan
Sebelum beralih ke tajuk, mari kita lihat sekilas bagaimana menggunakan UTF-8 dalam isi pesan. Untuk melakukan ini, gunakan tajuk
"Tipe Konten" .

Jika "Tipe Konten" tidak ditentukan, maka browser harus memproses pesan seolah-olah ditulis dalam ISO-8859-1.
Peramban seharusnya tidak mencoba menebak penyandian dan, terlebih lagi, abaikan "Jenis Konten". Tetapi apa yang sebenarnya muncul dalam situasi di mana "Tipe-Konten" tidak dikirim tergantung pada implementasi browser. Sebagai contoh, Firefox akan melakukan sesuai spesifikasi dan membaca pesan seolah-olah itu dikodekan dalam ISO-8859-1. Google Chrome, sebaliknya, akan menggunakan penyandian sistem operasi, yang bagi banyak pengguna Rusia sama dengan Windows-1251. Bagaimanapun, jika pesan itu di UTF-8, maka itu tidak akan ditampilkan dengan benar.

Kami menempatkan pesan UTF-8 dalam nilai header
Dengan isi pesan, semuanya cukup sederhana. Isi pesan selalu mengikuti tajuk, sehingga tidak ada masalah teknis. Tapi bagaimana dengan tajuk berita utama? Spesifikasi
secara eksplisit menyatakan bahwa urutan header dalam pesan tidak masalah. Yaitu tidak mungkin untuk menentukan pengkodean dalam satu header melalui header lainnya.
Apa yang terjadi jika Anda hanya mengambil dan menulis nilai UTF-8 ke nilai header? Kita telah melihat bahwa tipuan dengan isi pesan akan menghasilkan nilai yang cukup dibaca di ISO-8859-1. Adalah logis untuk berasumsi bahwa hal yang sama akan terjadi dengan tajuk utama. Tapi ini tidak benar. Bahkan, dalam banyak kasus, jika tidak sebagian besar, solusi ini akan berhasil. Ini termasuk iPhone lama, IE11, Firefox, Google Chrome. Satu-satunya browser di ujung jari saya ketika saya menulis artikel ini yang tidak ingin bekerja dengan judul itu adalah Edge.

Perilaku ini tidak dicatat dalam spesifikasi. Mungkin pengembang browser memutuskan untuk membuat hidup lebih mudah bagi para pengembang dan secara otomatis mendeteksi bahwa header pesan dikodekan dalam UTF-8. Secara umum, ini bukan tugas yang sulit. Kita melihat bit pertama: jika 0, lalu ASCII, jika 1 - lalu, mungkin, UTF-8.
Apakah ada persimpangan dengan ISO-8859-1 dalam kasus ini? Bahkan hampir tidak ada. Ambil contoh UTF-8 karakter 2 oktet (huruf Rusia diwakili oleh dua oktet). Simbol dalam biner yang disajikan akan terlihat seperti:
110xxxxx 10xxxxxx . Dalam representasi HEX:
[0xC0-0x6F] [0x80-0xBF] . Dalam ISO-8859-1, karakter-karakter ini hampir tidak dapat menyandikan sesuatu yang membawa beban semantik. Oleh karena itu, risiko yang salah peramban mendekripsi pesan adalah sangat kecil.
Namun, ketika Anda mencoba menggunakan metode ini, Anda mungkin mengalami masalah teknis: server web atau kerangka kerja Anda mungkin tidak mengizinkan penulisan karakter UTF-8 ke nilai header. Misalnya, Apache Tomcat menempatkan 0x3F (tanda tanya) alih-alih semua karakter UTF-8. Tentu saja, pembatasan ini dapat dielakkan, tetapi jika aplikasi itu sendiri berjabat tangan dan tidak memungkinkan sesuatu dilakukan, maka mungkin Anda tidak perlu melakukan ini.
Tapi, terlepas dari apakah kerangka kerja atau server Anda memungkinkan Anda untuk menulis pesan UTF-8 ke header atau tidak, saya tidak merekomendasikan melakukan ini. Ini bukan solusi yang terdokumentasi yang mungkin berhenti bekerja di browser pada waktu tertentu.
Translit
Saya pikir translit digunakan - eto bolee horoshee reshenie. Banyak sumber daya Rusia besar yang populer tidak menghina untuk menggunakan transliterasi dalam nama file. Ini adalah solusi yang dijamin yang tidak akan putus dengan rilis browser baru dan yang tidak perlu diuji secara terpisah pada setiap platform. Meskipun, tentu saja, Anda perlu memikirkan cara mengubah seluruh spektrum karakter yang mungkin, yang mungkin tidak sepenuhnya sepele. Misalnya, jika aplikasi dirancang untuk audiens Rusia, maka huruf Tatar ә dan ң dapat muncul dalam nama file, yang harus diproses entah bagaimana, dan tidak hanya diganti dengan "?".
RFC 2047
Seperti yang sudah saya sebutkan, tomkat tidak mengizinkan saya untuk memasukkan UTF-8 di header pesan. Apakah fitur perilaku ini tercermin dalam Java docs for servlets? Ya, tercermin:
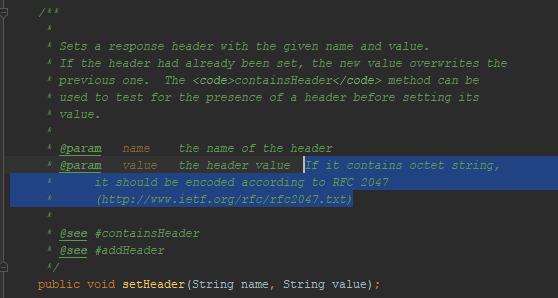
Disebutkan
RFC 2047 . Saya mencoba menyandikan pesan menggunakan format ini - browser tidak mengerti saya. Metode pengkodean ini tidak berfungsi dalam HTTP. Meskipun dia bekerja sebelumnya. Misalnya,
tiket untuk menghapus dukungan untuk pengodean ini dari Firefox.
RFC 6266
Dalam tiket, tautan yang ada di bagian sebelumnya,
ada referensi bahwa bahkan setelah penghentian dukungan untuk RFC 2047, masih ada cara untuk mentransfer nilai UTF-8 atas nama file yang diunduh:
RFC 6266 . Menurut pendapat saya, ini adalah keputusan yang paling tepat saat ini. Banyak sumber daya online populer menggunakannya. Kami di
Platform CUBA juga menggunakan RFC khusus ini untuk menghasilkan "Content-Disposition".
RFC 6266 adalah spesifikasi yang menjelaskan penggunaan header "Content-Disposition". Metode pengkodean itu sendiri dijelaskan secara rinci dalam spesifikasi lain,
RFC 8187 .

Parameter "nama file" berisi nama file di ASCII, "nama file *" - dalam setiap pengkodean yang diperlukan. Dengan kedua atribut, "nama file" diabaikan di semua browser modern (termasuk IE11 dan versi Safari yang lebih lama). Sebaliknya, sebagian besar browser lama mengabaikan "nama file *".
Saat menggunakan metode pengkodean ini, parameter pertama menunjukkan pengkodean, diikuti oleh nilai yang dikodekan. Karakter yang terlihat dari pengkodean ASCII tidak perlu. Karakter yang tersisa hanya ditulis dalam representasi hex, dengan "%" sebelum setiap oktet.
Apa yang harus dilakukan dengan header lain?
Pengkodean yang dijelaskan dalam RFC 8187 tidak universal. Ya, Anda bisa meletakkan parameter dengan awalan * di header, dan ini bahkan bisa berfungsi untuk beberapa browser, tetapi
spesifikasinya memberitahu Anda untuk tidak melakukannya.
Dalam setiap kasus di mana UTF-8 didukung dalam tajuk, saat ini ada penyebutan eksplisit dalam RFC yang relevan. Selain Disposisi Konten, pengkodean ini digunakan, misalnya, dalam
Web Linking dan
Digest Access Authentication .
Perlu dicatat bahwa standar di bidang ini terus berubah. Menggunakan pengkodean yang dijelaskan di atas dalam HTTP
diusulkan hanya pada tahun 2010 . Penggunaan pengkodean ini di "Content-Disposition" telah
diperbaiki dalam standar pada 2011 . Terlepas dari kenyataan bahwa standar-standar ini hanya
pada tahap "Usulan Standar" , mereka didukung di mana-mana. Pilihan bahwa di masa depan kami mengharapkan standar baru yang akan memungkinkan lebih banyak pekerjaan seragam dengan pengkodean berbeda di header tidak dikesampingkan. Oleh karena itu, tetap mengikuti berita di dunia standar HTTP dan tingkat dukungannya di sisi browser.