Optical Character Recognition (OCR) adalah proses mendapatkan teks yang dicetak dalam format digital. Jika Anda membaca novel klasik pada perangkat digital atau meminta dokter untuk mengambil catatan medis lama melalui sistem komputer rumah sakit, Anda mungkin menggunakan OCR.
OCR membuat konten yang sebelumnya statis dapat diedit, dicari, dan dibagikan. Tetapi banyak dokumen yang perlu didigitalkan mengandung noda kopi, halaman dengan sudut melengkung, dan banyak kerutan yang membuat beberapa dokumen cetak tidak terdigitalkan.
Semua orang sudah lama tahu bahwa ada jutaan buku lama yang disimpan di penyimpanan. Penggunaan buku-buku ini dilarang karena bobrok dan lapuk, dan karenanya digitalisasi buku-buku ini sangat penting.
Makalah ini mempertimbangkan tugas membersihkan teks dari noise, mengenali teks dalam gambar dan mengubahnya menjadi format teks.

Untuk pelatihan, 144 foto digunakan. Ukurannya mungkin berbeda, tetapi sebaiknya harus masuk akal. Gambar harus dalam format PNG. Setelah membaca gambar, binarisasi digunakan - proses mengubah gambar warna menjadi hitam dan putih, yaitu, setiap piksel dinormalisasi ke kisaran 0 hingga 255, di mana 0 berwarna hitam, 255 berwarna putih.
Untuk melatih jaringan convolutional, Anda membutuhkan lebih banyak gambar daripada yang ada. Diputuskan untuk membagi gambar menjadi beberapa bagian. Karena sampel pelatihan terdiri dari gambar dengan ukuran yang berbeda, setiap gambar dikompresi menjadi 448x448 piksel. Hasilnya adalah 144 gambar dalam resolusi 448x448 piksel. Kemudian semuanya dipotong menjadi windows non-overlapping dengan ukuran 112x112 piksel.

Dengan demikian, dari 144 gambar awal, sekitar 2304 gambar dalam set pelatihan diperoleh. Tetapi ini tidak cukup. Dibutuhkan lebih banyak pelatihan untuk pelatihan jaringan konvolusional yang baik. Sebagai akibatnya, pilihan terbaik adalah memutar gambar 90 derajat, kemudian 180 dan 270 derajat. Akibatnya, array dengan ukuran [16.112.112,1] disuplai ke input jaringan. Di mana 16 adalah jumlah gambar, 112 adalah lebar dan tinggi setiap gambar, 1 adalah saluran warna. Ternyata 9216 contoh untuk pelatihan. Ini cukup untuk melatih jaringan konvolusional.
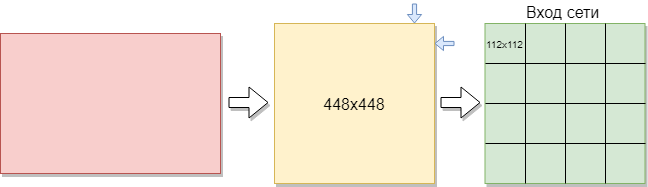
Setiap gambar memiliki ukuran 112x112 piksel. Jika ukurannya terlalu besar, kompleksitas komputasi akan meningkat, karenanya, pembatasan pada kecepatan respons akan dilanggar, penentuan ukuran dalam masalah ini diselesaikan dengan metode pemilihan. Jika Anda memilih ukuran terlalu kecil, jaringan tidak akan dapat mengidentifikasi tanda-tanda utama. Setiap gambar memiliki format hitam dan putih, sehingga dibagi menjadi 1 saluran. Gambar berwarna dibagi menjadi 3 saluran: merah, biru, hijau. Karena kami memiliki gambar hitam dan putih, ukuran setiap gambar adalah 112x122x1 piksel.
Pertama-tama, perlu untuk melatih jaringan saraf convolutional pada gambar yang disiapkan dan diproses. Untuk tugas ini, arsitektur U-Net dipilih.
Versi arsitektur yang direduksi dipilih, hanya terdiri dari dua blok (versi asli empat). Pertimbangan penting adalah fakta bahwa kelas besar algoritma binarisasi terkenal secara eksplisit dinyatakan dalam arsitektur atau arsitektur serupa (sebagai contoh, kita dapat memodifikasi algoritma Niblack dengan mengganti standar deviasi dengan rata-rata deviasi, dalam hal ini jaringan dibangun terutama secara sederhana).
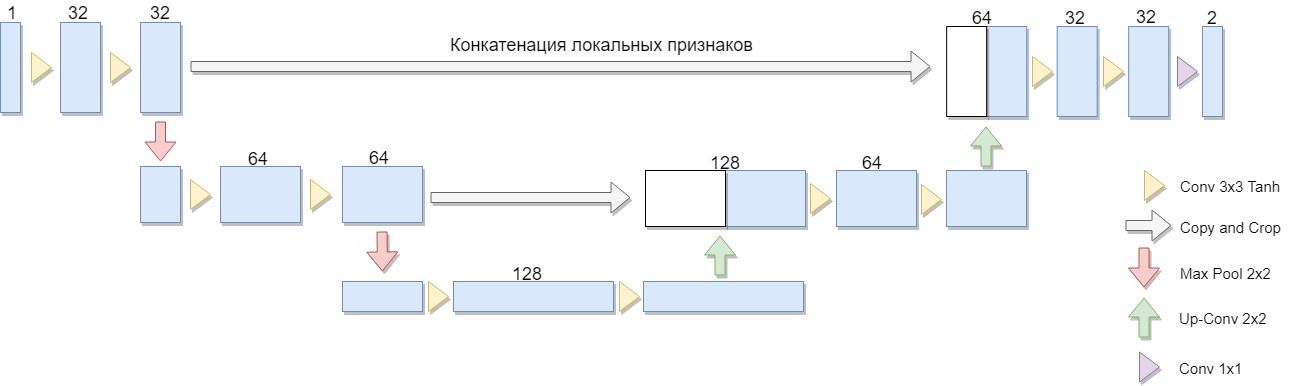
Keuntungan dari arsitektur ini adalah bahwa untuk melatih jaringan, Anda dapat membuat jumlah data pelatihan yang cukup dari sejumlah kecil gambar sumber. Selain itu, jaringan memiliki jumlah bobot yang relatif kecil karena arsitekturnya yang konvolusional. Namun ada beberapa nuansa. Secara khusus, jaringan saraf tiruan yang digunakan, secara tegas, tidak menyelesaikan masalah binarisasi: untuk setiap piksel dari gambar asli, ia mengaitkan angka dari 0 hingga 1, yang mencirikan tingkat di mana piksel ini dimiliki oleh salah satu kelas (pengisian bermakna atau latar belakang) dan yang diperlukan masih dikonversi ke jawaban biner akhir. [1]
U-Net terdiri dari jalur kompresi dan dekompresi dan "maju" di antara mereka. Jalur kompresi, dalam arsitektur ini, terdiri dari dua blok (dalam versi asli empat). Setiap blok memiliki dua konvolusi dengan filter 3x3 (menggunakan fungsi aktivasi Tanh setelah konvolusi) dan pooling dengan ukuran filter 2x2 dalam langkah 2. Jumlah saluran pada setiap langkah turun dua kali lipat.
Jalan meremas juga terdiri dari dua blok. Masing-masing terdiri dari "sapuan" dengan ukuran filter 2x2, membagi dua jumlah saluran, gabungan dengan peta fitur terpotong dari jalur kompresi ("penerusan") dan dua konvolusi dengan filter 3x3 (menggunakan fungsi aktivasi Tanh setelah konvolusi). Selanjutnya, pada lapisan terakhir, konvolusi 1x1 (menggunakan fungsi aktivasi Sigmoid) untuk mendapatkan output, gambar datar. Perhatikan bahwa pemangkasan peta fitur selama penggabungan sangat penting karena hilangnya piksel batas untuk setiap konvolusi. Adam dipilih sebagai metode optimasi stokastik.
Secara umum, arsitektur adalah urutan lapisan penyatuan + konvolusi yang mengurangi resolusi spasial gambar, kemudian meningkatkannya dengan menggabungkannya dengan data gambar terlebih dahulu dan melewati lapisan konvolusi lainnya. Dengan demikian, jaringan bertindak sebagai semacam filter. [2]
Sampel uji terdiri dari gambar yang serupa, perbedaannya hanya pada tekstur noise dan teks. Pengujian jaringan terjadi pada gambar ini.

Pada output dari jaringan saraf convolutional, sebuah array angka dengan ukuran [16.112.112,1] diperoleh. Setiap angka adalah piksel terpisah yang diproses oleh jaringan. Gambar memiliki format 112x112 piksel, seperti sebelumnya, gambar dipotong-potong. Dia harus mengkhianati penampilan aslinya. Kami menggabungkan gambar yang diperoleh dalam satu bagian, akibatnya gambar memiliki format 448x448. Selanjutnya, kita mengalikan setiap angka dalam array dengan 255 untuk mendapatkan rentang 0 hingga 255, di mana 0 berwarna hitam, 255 berwarna putih. Kami mengembalikan gambar ke ukuran aslinya, seperti sebelumnya, itu dikompresi. Hasilnya adalah gambar di bawah ini pada gambar.

Dalam contoh ini, terlihat bahwa jaringan convolutional mengatasi sebagian besar kebisingan dan terbukti efisien. Tetapi jelas terlihat bahwa gambar menjadi lebih gelap dan suara yang terlewat terlihat. Di masa depan, ini dapat mempengaruhi keakuratan pengenalan teks.
Berdasarkan fakta ini, diputuskan untuk menggunakan jaringan saraf lain - perceptron multilayer. Dalam hasil yang diharapkan, jaringan harus membuat teks dalam gambar lebih jelas dan menghilangkan noise yang hilang dari jaringan saraf convolutional.
Gambar yang sudah diproses oleh jaringan konvolusi dikirim ke input perceptron multilayer. Dalam hal ini, sampel pelatihan untuk jaringan ini akan berbeda dari sampel untuk jaringan convolutional, karena jaringan memproses gambar secara berbeda. Jaringan konvolusional dianggap sebagai jaringan utama dan menghilangkan sebagian besar noise dalam gambar, sementara multilayer perceptron memproses kegagalan konvolusional.
Berikut adalah beberapa contoh dari set pelatihan untuk perceptron multilayer.

Data gambar diperoleh dengan memproses sampel pelatihan untuk jaringan convolutional dengan perceptron multilayer. Pada saat yang sama, perceptron dilatih pada sampel yang sama, tetapi pada sejumlah kecil contoh dan sejumlah kecil era.
Untuk pelatihan perceptron, 36 gambar diproses. Jaringan dilatih piksel demi piksel, yaitu, satu piksel dari gambar dikirim ke input jaringan. Pada keluaran jaringan, kami juga mendapatkan satu neuron keluaran - satu piksel, yaitu respons jaringan. Untuk meningkatkan akurasi pemrosesan, 29 neuron input dibuat. Dan pada gambar yang diperoleh setelah diproses oleh jaringan konvolusi, 28 filter ditumpangkan. Hasilnya adalah 29 gambar dengan filter yang berbeda. Kami mengirim satu piksel dari setiap 29 gambar ke input jaringan dan hanya satu piksel yang diterima pada output jaringan, yaitu respons jaringan.
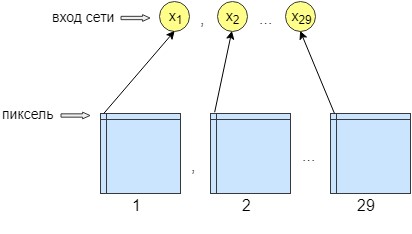
Ini dilakukan untuk pelatihan dan jaringan yang lebih baik. Setelah itu, jaringan mulai meningkatkan keakuratan dan kontras gambar. Ini juga membersihkan kesalahan kecil yang tidak dapat menghapus jaringan konvolusional.
Akibatnya, jaringan saraf memiliki 29 neuron input, satu piksel dari setiap gambar. Setelah percobaan, ditemukan bahwa hanya satu lapisan tersembunyi yang diperlukan, di mana 500 neuron. Hanya ada satu jalan keluar dari jaringan. Karena pelatihan berlangsung pixel demi pixel, jaringan diakses n * m kali, di mana n adalah lebar gambar dan m adalah tinggi, masing-masing.

Setelah memproses gambar secara berurutan oleh dua jaringan saraf, hal utama yang tersisa adalah mengenali teks. Untuk ini, solusi siap pakai diambil, yaitu pustaka Python Pytesseract. Pytesseract tidak menyediakan binding Python yang sebenarnya. Sebaliknya, ini adalah pembungkus sederhana untuk biner tesseract. Dalam hal ini, tesseract diinstal secara terpisah pada komputer. Pytesseract menyimpan gambar ke file sementara pada disk, dan kemudian memanggil file biner tesseract dan menulis hasilnya ke file.
Wrapper ini dikembangkan oleh Google dan gratis dan gratis untuk digunakan. Ini dapat digunakan untuk keperluan sendiri dan untuk tujuan komersial. Perpustakaan berfungsi tanpa koneksi internet, mendukung banyak bahasa untuk pengenalan dan mengesankan dengan kecepatannya. Aplikasinya dapat ditemukan di berbagai aplikasi populer.
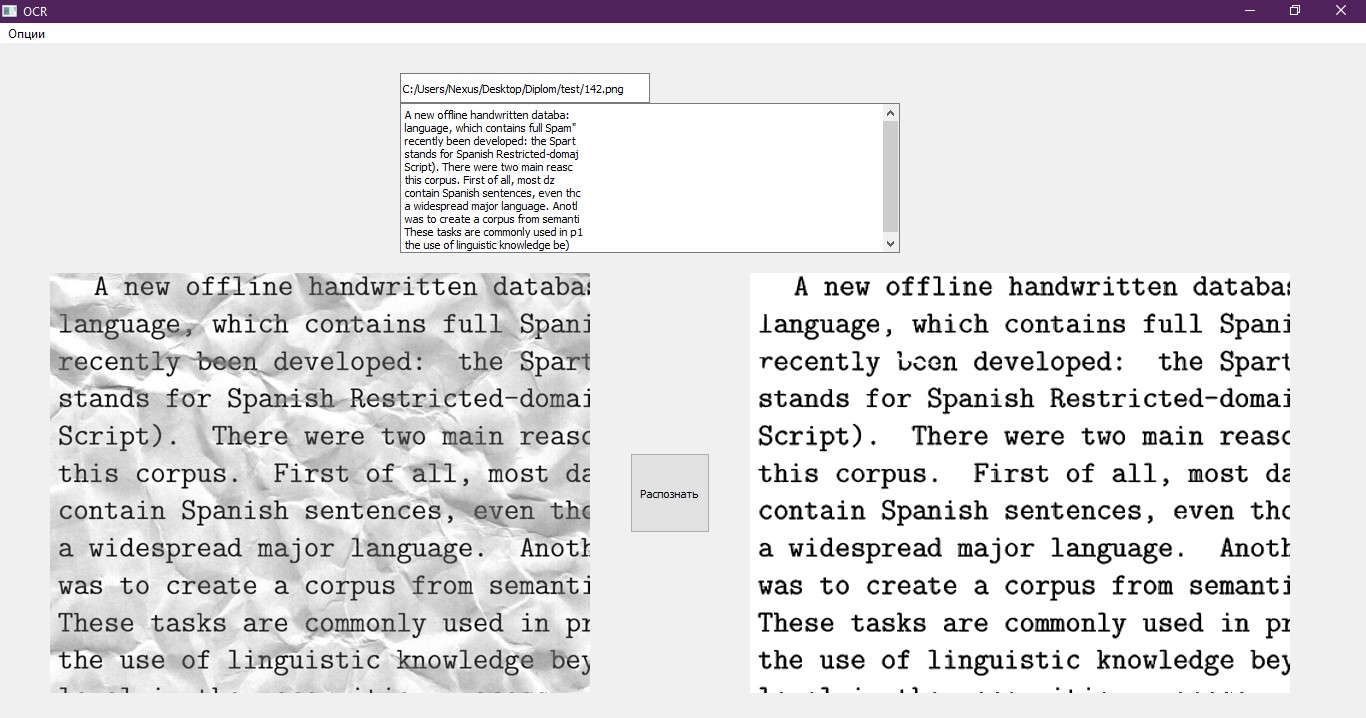
Item terakhir yang tersisa adalah untuk menulis teks yang dikenali ke file dalam format yang sesuai untuk memprosesnya. Kami menggunakan ini untuk notebook biasa, yang terbuka setelah program selesai. Juga, teks ditampilkan pada antarmuka uji. Contoh antarmuka yang bagus.
Referensi:
- Kisah kemenangan di kompetisi pengakuan dokumen internasional dari tim SmartEngines [Sumber daya elektronik]. Mode Akses: https://habr.com/company/smartengines/blog/344550/
- Segmentasi gambar menggunakan jaringan saraf: U-Net [Sumber daya elektronik]. Mode Akses: http://robocraft.ru/blog/machinelearning/3671.html
> Gudang Github