
Halo semuanya!
Melanjutkan studi tentang topik
pembelajaran yang mendalam , kami pernah ingin berbicara dengan Anda tentang
mengapa domba tampaknya ada di mana-mana dalam jaringan saraf . Topik ini
dibahas dalam bab ke 9 dari buku Francois Scholl.
Dengan demikian, kami pergi ke studi yang bagus tentang Positive Technologies, yang
dipresentasikan di Habré , serta karya luar biasa dari dua karyawan MIT yang menganggap bahwa "pembelajaran mesin jahat" tidak hanya menjadi penghalang dan masalah, tetapi juga alat diagnostik yang luar biasa.
Berikutnya - di bawah luka.
Selama beberapa tahun terakhir, kasus-kasus gangguan berbahaya telah menarik perhatian serius di komunitas pembelajaran yang mendalam. Dalam artikel ini, kami ingin menguraikan fenomena ini secara umum dan membahas bagaimana hal itu sesuai dengan konteks yang lebih luas dari keandalan pembelajaran mesin.
Intervensi Berbahaya: Sebuah Fenomena MenarikUntuk menguraikan ruang lingkup diskusi kami, kami memberikan beberapa contoh gangguan berbahaya tersebut. Kami berpikir bahwa sebagian besar peneliti yang terlibat di Wilayah Moskow menemukan gambar yang serupa:
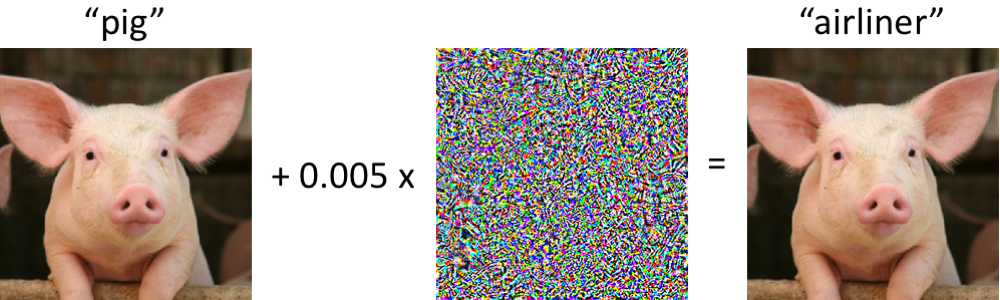
Di sebelah kiri adalah piggy, diklasifikasikan dengan benar sebagai babi oleh jaringan saraf convolutional modern. Segera setelah kami membuat perubahan minimal pada gambar (semua piksel berada dalam kisaran [0, 1], dan setiap perubahan tidak lebih dari 0,005) - dan sekarang jaringan mengembalikan kelas "pesawat" dengan keandalan tinggi. Serangan semacam itu pada pengklasifikasi terlatih telah diketahui sejak setidaknya 2004 (
tautan ), dan yang pertama bekerja pada gangguan berbahaya dengan pengklasifikasi gambar tanggal kembali ke 2006 (
tautan ). Kemudian fenomena ini mulai menarik perhatian lebih signifikan sejak sekitar 2013, ketika ternyata jaringan saraf rentan terhadap serangan semacam ini (lihat di
sini dan di
sini ). Sejak itu, banyak peneliti telah mengusulkan opsi untuk membangun contoh berbahaya, serta cara untuk meningkatkan resistensi pengklasifikasi terhadap gangguan patologis semacam itu.
Namun, penting untuk diingat bahwa tidak perlu menyelidiki jaringan saraf untuk mengamati contoh berbahaya tersebut.
Seberapa kuat contoh malware?Mungkin situasi di mana komputer membingungkan anak babi dengan pesawat mungkin mengkhawatirkan pada awalnya. Namun, harus dicatat bahwa classifier yang digunakan dalam kasus ini (
jaringan Inception-v3 ) tidak rapuh seperti yang terlihat pada pandangan pertama. Meskipun jaringan mungkin salah ketika mencoba untuk mengklasifikasikan babi yang terdistorsi, ini hanya terjadi dalam kasus pelanggaran yang dipilih secara khusus.
Jaringan ini jauh lebih tahan terhadap gangguan acak yang besarnya sebanding. Oleh karena itu, pertanyaan utamanya adalah apakah gangguan berbahaya yang menyebabkan kerapuhan jaringan. Jika kejahatan seperti itu sangat tergantung pada kontrol atas setiap piksel input, maka ketika mengklasifikasikan gambar dalam kondisi realistis, sampel berbahaya semacam itu tampaknya tidak menjadi masalah serius.
Studi terbaru menunjukkan sebaliknya: adalah mungkin untuk memastikan stabilitas gangguan pada berbagai efek saluran dalam skenario fisik tertentu. Misalnya, sampel berbahaya dapat dicetak pada printer kantor biasa, sehingga gambar pada mereka yang difoto oleh kamera smartphone
masih belum diklasifikasikan dengan benar . Anda juga dapat membuat stiker, karena jaringan saraf mana yang secara keliru mengklasifikasikan berbagai adegan nyata (lihat, misalnya,
tautan1 ,
tautan2 dan
tautan3 ). Akhirnya, baru-baru ini, para peneliti mencetak kura-kura 3D pada printer 3D, yang oleh jaringan Inception standar
dianggap sebagai senapan di hampir semua sudut pandang.
Persiapan serangan klasifikasi yang salahBagaimana cara membuat gangguan berbahaya seperti itu? Ada banyak pendekatan, tetapi optimasi memungkinkan kita untuk mengurangi semua berbagai metode ini menjadi representasi umum. Seperti yang Anda ketahui, pelatihan classifier sering dirumuskan sebagai menemukan parameter model
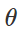
untuk meminimalkan fungsi kerugian empiris untuk serangkaian contoh yang diberikan

:
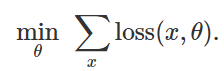
Oleh karena itu, untuk memprovokasi klasifikasi yang salah untuk model tetap
dan input "tidak berbahaya"
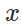
secara alami mencoba untuk menemukan gangguan terbatas

sedemikian rupa sehingga kerugian

ternyata maksimum:
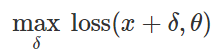
Berdasarkan formulasi ini, banyak metode untuk membuat input berbahaya dapat dianggap berbagai algoritma optimasi (langkah-langkah gradien individu, proyeksi gradien keturunan, dll.) Untuk berbagai set kendala (kecil
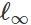
Gangguan -normal, perubahan kecil dalam piksel, dll.). Sejumlah contoh diberikan dalam artikel berikut:
link1 ,
link2 ,
link3 ,
link4 dan
link5 .
Seperti yang dijelaskan di atas, banyak metode yang berhasil untuk menghasilkan sampel berbahaya berfungsi dengan klasifikasi target tetap. Oleh karena itu, pertanyaan penting adalah: tidakkah gangguan-gangguan ini hanya memengaruhi model target tertentu? Menariknya, tidak. Ketika menggunakan banyak metode perturbasi, sampel berbahaya yang dihasilkan dipindahkan dari classifier ke classifier yang dilatih dengan serangkaian nilai acak awal yang berbeda (benih acak) atau arsitektur model yang berbeda. Selain itu, Anda dapat membuat sampel berbahaya yang hanya memiliki akses terbatas ke model target (kadang-kadang dalam kasus ini mereka berbicara tentang "serangan kotak hitam"). Lihat, misalnya, lima artikel berikut:
link1 ,
link2 ,
link3 ,
link4 dan
link5 .
Bukan hanya gambarSampel berbahaya ditemukan tidak hanya dalam klasifikasi gambar. Fenomena serupa diketahui dalam
pengenalan ucapan , dalam
sistem tanya jawab , dalam
pembelajaran yang diperkuat, dan dalam memecahkan masalah lain. Seperti yang telah Anda ketahui, studi tentang sampel berbahaya telah berlangsung selama lebih dari sepuluh tahun:
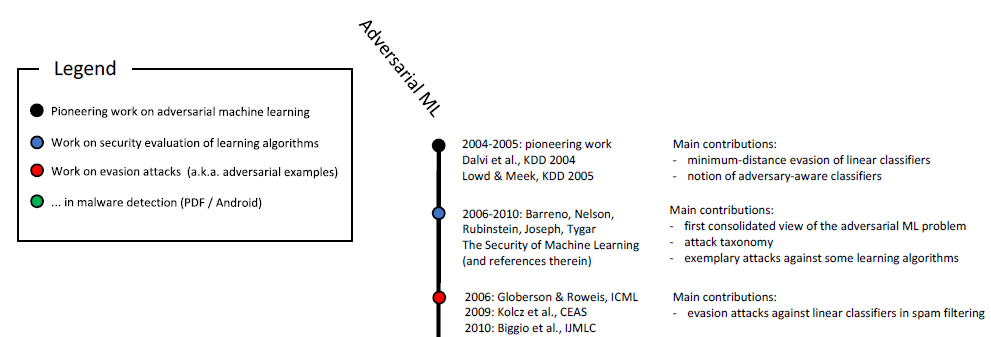
Skala kronologis pembelajaran mesin jahat (awal). Skala penuh ditunjukkan pada gambar. 6 dalam
penelitian ini .
Selain itu, aplikasi terkait keamanan adalah media alami untuk mempelajari aspek berbahaya dari pembelajaran mesin. Jika penyerang dapat menipu classifier dan mengirimkan input berbahaya (katakanlah, spam atau virus) sebagai tidak berbahaya, maka pendeteksi spam atau pemindai anti-virus berdasarkan pembelajaran mesin
tidak akan
efektif . Harus ditekankan bahwa pertimbangan ini tidak sepenuhnya bersifat akademis. Sebagai contoh, tim Google Safebrowsing pada tahun 2011 menerbitkan
penelitian multi-tahun tentang bagaimana penyerang mencoba untuk menghindari sistem deteksi malware mereka. Lihat juga
artikel ini tentang sampel berbahaya dalam konteks pemfilteran spam di email GMail.
Bukan hanya keamananSemua pekerjaan terbaru tentang studi sampel berbahaya sangat jelas dipertahankan dalam kunci untuk memastikan keamanan. Ini adalah sudut pandang yang masuk akal, tetapi kami percaya bahwa sampel semacam itu harus dipertimbangkan dalam konteks yang lebih luas.
KeandalanPertama-tama, sampel berbahaya menimbulkan pertanyaan tentang keandalan seluruh sistem. Sebelum kita dapat membahas secara wajar sifat-sifat penggolong dari sudut pandang keamanan, kita harus memastikan bahwa mekanisme tersebut memberikan akurasi klasifikasi yang tinggi. Pada akhirnya, jika kita akan menggunakan model terlatih kita dalam skenario dunia nyata, maka perlu bahwa mereka menunjukkan tingkat keandalan yang tinggi ketika mengubah distribusi data yang mendasarinya - terlepas dari apakah perubahan ini disebabkan oleh gangguan berbahaya atau hanya fluktuasi alami.
Dalam konteks ini, sampel malware adalah alat diagnostik yang berguna untuk mengevaluasi keandalan sistem pembelajaran mesin. Secara khusus, pendekatan berbasis malware memungkinkan Anda melampaui protokol evaluasi standar, di mana classifier terlatih dijalankan pada set tes yang dipilih dengan cermat (dan biasanya statis).
Jadi, Anda bisa sampai pada kesimpulan yang luar biasa. Sebagai contoh, ternyata seseorang dapat dengan mudah membuat sampel berbahaya tanpa harus menggunakan metode optimasi yang canggih. Dalam
makalah baru -
baru ini, kami menunjukkan bahwa pengklasifikasi gambar mutakhir secara mengejutkan rentan terhadap transisi atau belokan patologis kecil. (Lihat di
sini dan di
sini untuk karya-karya lain tentang topik ini.)

Oleh karena itu, bahkan jika kita tidak mementingkan, katakanlah, gangguan dari pelepasan, masalah dengan keandalan karena rotasi dan transisi sering muncul. Dalam arti yang lebih luas, penting untuk memahami indikator keandalan dari pengklasifikasi kami sebelum dapat diintegrasikan ke dalam sistem yang lebih besar sebagai komponen yang benar-benar andal.
Konsep pengklasifikasiUntuk memahami bagaimana classifier terlatih bekerja, Anda perlu menemukan contoh operasinya yang jelas sukses atau tidak berhasil. Dalam kasus ini, sampel berbahaya menggambarkan bahwa jaringan saraf terlatih sering tidak sesuai dengan pemahaman intuitif kita tentang apa artinya "mempelajari" konsep tertentu. Ini sangat penting dalam pembelajaran mendalam, di mana algoritma dan jaringan yang masuk akal secara biologis yang keberhasilannya tidak kalah dengan keberhasilan manusia sering diklaim (lihat, misalnya, di
sini , di
sini atau di
sini ). Sampel berbahaya jelas membuat orang meragukan hal ini dalam banyak konteks:
- Saat mengklasifikasikan gambar, jika set piksel diubah minimal atau gambar sedikit dirotasi, ini tidak akan menghalangi seseorang untuk menetapkannya ke kategori yang benar. Namun demikian, perubahan tersebut sepenuhnya terputus oleh pengklasifikasi paling modern. Jika Anda menempatkan benda di tempat yang tidak biasa (misalnya, domba di atas pohon ), juga mudah untuk memastikan bahwa jaringan saraf menginterpretasikan pemandangan yang sangat berbeda dari manusia.
- Jika Anda mengganti kata-kata yang diperlukan dalam bagian teks, Anda dapat secara serius membingungkan sistem tanya jawab , meskipun, dari sudut pandang seseorang, makna teks tidak akan berubah karena memasukkan seperti itu.
- Sepanjang artikel ini, contoh teks yang dipilih dengan cermat menunjukkan batas Google Terjemahan.
Dalam ketiga kasus tersebut, contoh berbahaya membantu menguji kekuatan model kami saat ini dan menekankan dalam situasi mana model-model ini bertindak sangat berbeda dari apa yang akan dilakukan seseorang.
KeamananAkhirnya, sampel berbahaya memang menghadirkan bahaya di area di mana pembelajaran mesin sudah mencapai akurasi tertentu pada materi "tidak berbahaya". Hanya beberapa tahun yang lalu, tugas-tugas seperti klasifikasi gambar masih dilakukan dengan sangat buruk, sehingga masalah keamanan dalam kasus ini tampak sekunder. Pada akhirnya, tingkat keamanan sistem pembelajaran mesin menjadi signifikan hanya ketika sistem ini mulai memproses input "tidak berbahaya" dengan kualitas yang memadai. Kalau tidak, kita masih tidak bisa mempercayai ramalannya.
Sekarang, di berbagai bidang subjek, keakuratan pengklasifikasi tersebut telah meningkat secara signifikan, dan penempatannya dalam situasi di mana pertimbangan keselamatan sangat penting hanyalah masalah waktu. Jika kita ingin melakukan pendekatan ini secara bertanggung jawab, penting untuk menyelidiki propertinya dengan tepat dalam konteks keamanan. Namun masalah keamanan membutuhkan pendekatan holistik. Menempa beberapa fitur (misalnya, satu set piksel) jauh lebih mudah daripada, misalnya, modalitas sensorik lainnya, atau fitur kategorikal, atau metadata. Pada akhirnya, ketika memastikan keamanan, yang terbaik adalah mengandalkan tanda-tanda yang sulit atau bahkan hampir tidak mungkin untuk diubah.
Hasil (apakah terlalu dini untuk gagal?)Terlepas dari kemajuan yang mengesankan dalam pembelajaran mesin yang telah kita lihat dalam beberapa tahun terakhir, penting untuk memperhitungkan keterbatasan kemampuan alat yang kita miliki. Ada berbagai macam masalah (mis. Yang terkait dengan kejujuran, privasi, atau efek umpan balik), dan keandalan menjadi perhatian utama. Persepsi dan kognisi manusia tahan terhadap berbagai gangguan latar belakang lingkungan. Namun, sampel berbahaya menunjukkan bahwa jaringan saraf masih sangat jauh dari ketahanan yang sebanding.
Jadi, kami yakin akan pentingnya mempelajari contoh berbahaya. Penerapannya dalam pembelajaran mesin jauh dari terbatas pada masalah keamanan, tetapi dapat berfungsi sebagai
standar diagnostik untuk mengevaluasi model yang terlatih. Pendekatan menggunakan sampel berbahaya membandingkan baik dengan prosedur evaluasi standar dan tes statis dalam hal mengidentifikasi potensi kesalahan yang tidak terlihat. Jika kita ingin memahami keandalan pembelajaran mesin modern, maka pencapaian terbaru penting untuk diselidiki dari sudut pandang penyerang (memilih sampel berbahaya dengan benar).
Selama pengklasifikasi kami gagal bahkan dengan perubahan minimal antara pelatihan dan distribusi pengujian, kami tidak dapat mencapai keandalan yang memuaskan. Pada akhirnya, kami berusaha keras untuk menciptakan model yang tidak hanya dapat diandalkan, tetapi akan konsisten dengan ide-ide intuitif kami tentang apa artinya "mempelajari" masalah. Maka mereka akan aman, andal, dan mudah digunakan di berbagai lingkungan.