Vladimir Ivanov vivanov879 , Sr. Deep Learning Engineer NVIDIA terus berbicara tentang penguatan pembelajaran. Artikel ini akan fokus pada pelatihan agen untuk menyelesaikan pencarian dan bagaimana jaringan saraf menggunakan filter untuk mengenali gambar.
Dalam
artikel sebelumnya, pelatihan agen untuk penembak sederhana dibahas.
Vladimir akan berbicara tentang penerapan pembelajaran yang diperkuat dalam praktik di
Konferensi AI pada 22 November.
Terakhir kali kami melihat contoh video game, di mana pelatihan penguatan membantu menyelesaikan masalah. Anehnya, untuk permainan yang sukses dari jaringan saraf, hanya informasi visual yang diperlukan. Setiap jaringan saraf bingkai keempat menganalisis tangkapan layar dan membuat keputusan.
Sepintas, itu terlihat seperti sihir. Struktur kompleks tertentu, yang merupakan jaringan saraf, menerima gambar pada input dan mengeluarkan solusi yang tepat. Mari kita cari tahu apa yang terjadi di dalam: apa yang mengubah satu set piksel menjadi aksi?
Sebelum beralih ke komputer, mari cari tahu apa yang dilihat seseorang.Ketika seseorang melihat sebuah gambar, pandangannya tertuju pada detail kecil (wajah, figur orang, pohon), dan ke gambar secara keseluruhan. Baik itu permainan anak-anak di gang atau pertandingan sepak bola, seseorang dapat memahami konten gambar, suasana hati dan konteks gambar berdasarkan pengalaman hidupnya.

Ketika kami mengagumi karya master di galeri seni, pengalaman hidup kami masih memberi tahu kami bahwa karakter tersembunyi di balik lapisan cat. Anda bisa menebak niat dan gerakan mereka dalam gambar.

Dalam kasus lukisan abstrak, mata menemukan gambar-gambar sederhana dalam gambar: lingkaran, segitiga, kotak. Mereka jauh lebih mudah ditemukan. Terkadang hanya ini yang bisa dilihat.

Item dapat diatur sehingga gambar mengambil rona yang tidak terduga.

Artinya, kita dapat melihat gambar secara keseluruhan, mengabstraksi dari komponen spesifiknya. Tidak seperti kami, komputer pada awalnya tidak memiliki kemampuan ini. Kami memiliki banyak pengalaman hidup yang memberi tahu kami item mana yang penting dan sifat fisik apa yang mereka miliki. Mari kita pikirkan tentang cara memberikan mesin kepada alat agar dapat mempelajari gambar.
Banyak pemilik ponsel yang bahagia dengan kamera berkualitas tinggi sebelum memposting foto dari ponsel ke jejaring sosial memaksakan berbagai filter padanya. Dengan menggunakan filter, Anda dapat mengubah mood foto. Anda dapat menyorot beberapa objek dengan lebih jelas.
Selain itu, filter dapat menyorot tepi objek di foto.
Karena filter memiliki kemampuan ini untuk menyorot objek yang berbeda pada suatu gambar, mari beri komputer kesempatan untuk mengambilnya. Apa itu gambar digital? Ini adalah matriks angka persegi, di setiap titik yang ada nilai intensitas untuk tiga saluran warna: merah, hijau dan biru. Sekarang kita akan memberikan jaringan saraf, misalnya, 32 filter. Setiap filter pada gilirannya ditumpangkan pada gambar. Inti filter diterapkan ke piksel tetangga.
Awalnya, nilai inti dari setiap filter bersifat acak. Tetapi kami akan memberikan jaringan saraf kemampuan untuk mengonfigurasinya tergantung pada tugasnya. Setelah lapisan pertama dengan filter, kita bisa menambahkan beberapa. Karena kami mendapatkan banyak filter, kami membutuhkan banyak data untuk mengaturnya. Untuk ini, beberapa bank besar gambar yang ditandai cocok. Misalnya, dataset MSCoco.

Jaringan saraf akan menyesuaikan bobot untuk menyelesaikan masalah ini. Dalam kasus kami, untuk segmentasi gambar, yaitu definisi kelas setiap piksel gambar. Sekarang mari kita lihat bagaimana gambar akan terlihat setelah setiap lapisan filter.
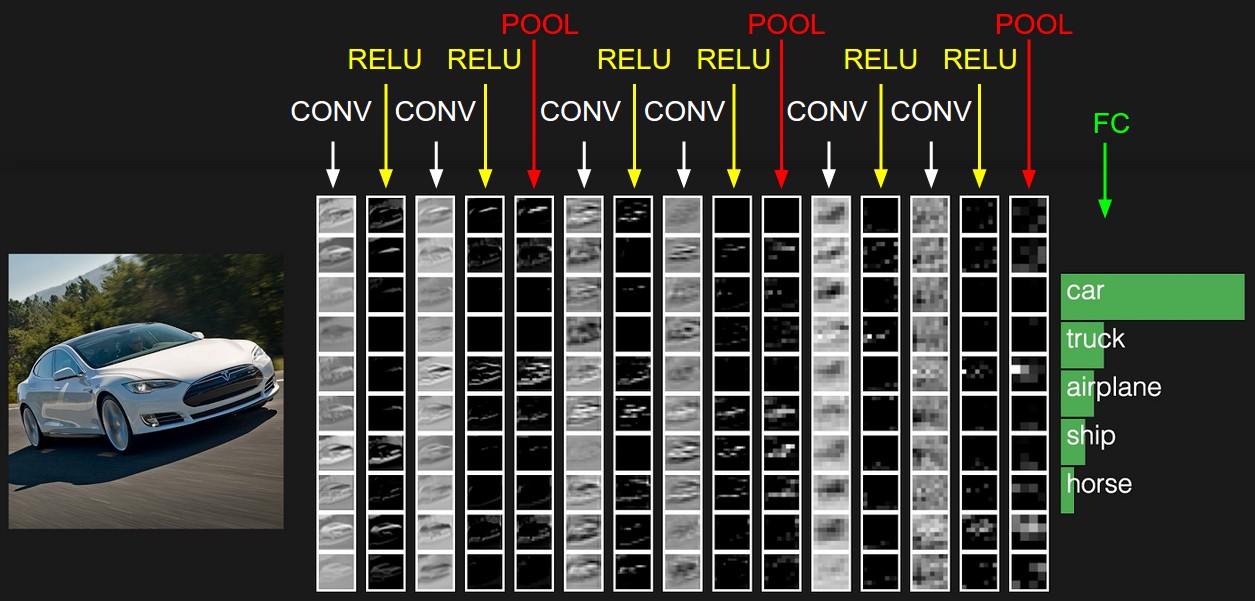
Jika Anda melihat lebih dekat, Anda akan melihat bahwa filter pada satu atau lain tingkat meninggalkan mobil, dan membersihkan area di sekitarnya - jalan, pohon dan langit.
Kembali ke agen yang belajar bermain game. Misalnya, ambil game balap Mario Kart.
Kami memberinya alat analisis gambar yang kuat - jaringan saraf. Mari kita lihat filter apa yang dia pilih untuk belajar mengendarai. Mari kita ambil area terbuka sebagai permulaan.
Mari kita lihat seperti apa gambarnya setelah 24 film pertama. Di sini mereka berada dalam bentuk tabel 8x3.
Ini sepenuhnya opsional bahwa masing-masing dari 24 output memiliki makna yang jelas, karena gambar pergi lebih jauh ke pintu masuk dengan filter berikut. Ketergantungan bisa sangat berbeda. Namun, dalam hal ini, Anda dapat menemukan beberapa logika di output. Misalnya, filter kedua di baris pertama menyoroti jalan berwarna hitam. Filter pertama dari baris ketujuh menggandakan fungsinya. Dan pada sebagian besar filter lainnya, kartu yang kita kontrol terlihat jelas.
Dalam game ini, area di sekitarnya berubah dan sebuah terowongan bertemu. Apa yang diperhatikan jaringan saraf balap ketika bertemu dengan pintu masuk ke terowongan?
Output dari filter lapisan pertama:
Di baris keenam, filter pertama menyoroti pintu masuk ke terowongan. Jadi, selama perjalanan, jaringan belajar mengidentifikasi mereka.
Dan apa yang terjadi ketika mesin memasuki terowongan?
Hasil dari 24 filter pertama:
Terlepas dari kenyataan bahwa iluminasi pemandangan telah berubah, dan juga lingkungannya, jaringan saraf menangkap hal yang paling penting - jalan dan peta. Sekali lagi, filter kedua di baris pertama, yang bertanggung jawab untuk menemukan jalan di tempat terbuka, di terowongan mempertahankan fungsinya. Dan dengan cara yang sama, filter pertama dari garis ketujuh, seperti sebelumnya, menemukan jalannya.
Sekarang kita telah mengetahui apa yang dilihat jaringan saraf, mari kita coba menggunakannya untuk memecahkan masalah yang lebih kompleks. Sebelum ini, kami mempertimbangkan tugas-tugas di mana Anda secara praktis tidak perlu berpikir ke depan, tetapi Anda harus menyelesaikan masalah yang sedang kami hadapi sekarang. Dalam permainan menembak dan balapan Anda harus bertindak "refleksif", dengan cepat merespons perubahan tiba-tiba dalam permainan. Bagaimana dengan menyelesaikan game pencarian? Misalnya, game Montezuma Revenge, di mana Anda perlu menemukan kunci dan membuka pintu yang terkunci untuk keluar dari piramida.

Waktu sebelumnya kita membahas bahwa agen tidak akan belajar cara mencari kunci dan pintu baru, karena tindakan ini membutuhkan banyak waktu permainan, dan karena itu sinyal dalam bentuk poin yang diterima akan sangat jarang. Jika Anda menggunakan poin untuk musuh yang dipukuli sebagai hadiah kepada agen, ia akan terus-menerus merobohkan tengkorak bergulir dan tidak akan mencari langkah baru.
Mari kita beri penghargaan kepada agen untuk kamar baru yang terbuka. Kami akan menggunakan fakta yang diketahui apriori bahwa ini adalah sebuah pencarian, dan semua kamar di dalamnya berbeda.

Karena itu, jika gambar di layar secara fundamental berbeda dari yang kita lihat sebelumnya, agen akan menerima hadiah.
Sebelum ini, kami mempertimbangkan agen game yang hanya mengandalkan data visual selama pelatihan. Tetapi jika kita memiliki akses ke data lain dari game, kita akan menggunakannya juga. Pertimbangkan, misalnya, permainan Dot. Di sini, jaringan menerima dua puluh ribu angka di pintu masuk, yang sepenuhnya menggambarkan keadaan permainan. Misalnya, posisi sekutu, kesehatan menara.

Pemain dibagi menjadi dua tim, masing-masing lima orang. Gim berlangsung rata-rata 40 menit. Setiap pemain memilih pahlawan dengan kemampuan unik. Dan setiap pemain dapat membeli item yang mengubah parameter kerusakan, kecepatan, dan bidang tampilan.
Terlepas dari kenyataan bahwa permainan pada pandangan pertama sangat berbeda dari Doom, proses pembelajaran tetap sama. Kecuali beberapa poin. Karena horizon perencanaan dalam game ini lebih tinggi daripada di Doom, kami akan memproses 16 frame terakhir untuk membuat keputusan. Dan sinyal penghargaan yang diterima agen akan sedikit lebih rumit. Ini termasuk jumlah musuh yang dikalahkan, kerusakan yang ditimbulkan, serta uang yang diperoleh dalam permainan. Agar jaringan saraf dapat bermain bersama, kami akan memasukkan kesejahteraan anggota tim agen sebagai hadiah.
Akibatnya, tim bot
mengalahkan tim orang yang cukup kuat, tetapi kalah dari juara. Alasan kekalahan adalah bahwa bot jarang memainkan pertandingan selama satu jam. Dan permainan dengan orang sungguhan berlangsung lebih lama daripada yang dimainkan dengan simulator. Yaitu, jika seorang agen menemukan dirinya dalam situasi yang tidak dia latih, kesulitan mulai muncul dalam dirinya.