Saya ingin berbicara tentang pengalaman kami dalam mengembangkan aplikasi berdasarkan platform pencarian teks lengkap Apache Solr.
Tugas kami adalah mengembangkan sistem analisis wicara untuk pusat kontak. Sistem ini didasarkan pada dua teknologi dasar: pengenalan ucapan dan pencarian yang diindeks. Untuk pengakuan, kami menggunakan mesin kami, dan untuk pengindeksan dan pencarian, kami memilih Solr.
Mengapa solr? Kami tidak melakukan penelitian komparatif kami sendiri tentang mesin pencari yang diindeks, tetapi dengan cermat memeriksa
pendapat rekan-rekan kami . Tentu saja, pilihan dapat dibuat untuk mendukung Elasticsearch atau Sphinx, tetapi, tampaknya, bintang-bintang di proyek kami dibentuk untuk Solr, kami “menggergaji” nya. Sudah selama proyek berlangsung, kami menentukan bahwa pengaturan yang tersedia di Solr sudah cukup untuk dikonfigurasikan untuk tugas-tugas kami.
Fitur proyek kami
Sistem ini dikembangkan untuk analitik panggilan pelanggan, yang dicatat di pusat kontak untuk memantau kualitas layanan. Itu tidak menganalisis suara, tetapi teks diperoleh sebagai hasil dari pengakuan otomatis dialog. Teks-teks pidato yang diakui pada dasarnya berbeda dari teks-teks yang kita temui secara teratur di situs web atau email. Bahkan dengan akurasi pengenalan 100%, teks pidato spontan yang dikenali tampaknya tidak memiliki makna.
Ini karena dua faktor utama. Pertama, dalam pidato lisan, ekspresi nonverbal dan wajah sangat sering digunakan, yang tidak dikenali dalam teks, tetapi penting untuk memahami apa yang telah dikatakan. Kedua, dalam pidato, singkatan dan penghilangan struktur bahasa terus digunakan, yang dapat dipulihkan dari konteks situasi komunikatif. Fenomena dalam linguistik ini disebut elipsis.
Untuk melihat dengan mata Anda sendiri teks pidato yang dikenal dengan semua fitur-fiturnya, lihat subtitle otomatis untuk video di youtube dengan suara dimatikan. Itu tentang konten ini, materi masuk ke input dari sistem analitik ucapan.
Pertanyaan yang rumit
Meskipun Solr mendukung
pernyataan dan
pengelompokan bersyarat standar, seringkali kemampuan ini tidak cukup untuk menerapkan semua skenario untuk analis.
Seringkali, analis perlu membangun kueri dengan parameter yang tidak termasuk dalam indeks Solr. Misalnya, temukan semua kata "terima kasih" yang diucapkan dalam 30 detik terakhir percakapan. Kata-kata diindeks oleh Solr, tetapi tidak ada posisi kata sementara. Kami menyebut kueri semacam itu "kompleks" - kueri yang menyertakan parameter indeks Solr dan parameter pemilihan data lainnya yang tidak termasuk dalam indeks Solr.
Bagaimana seorang analis membentuk pertanyaan?
Analis tidak memiliki gagasan tentang komposisi indeks Solr, penting baginya untuk mencari dan memotong semua atribut phonogram panggilan dan transkrip teks mereka. Oleh karena itu, konsep "query kompleks" untuk analis adalah murni pragmatis: kueri di mana ada banyak parameter pemilihan, atau kueri diatur dalam hierarki.
Menggambarkan tindakan analis dalam bahasa teori himpunan, kita dapat mengatakan bahwa dengan bantuan pertanyaan, analis mengeksplorasi hubungan antara himpunan bagian yang berbeda: persimpangan, perbedaan, penambahan. Menggunakan kueri hierarkis, analis mem-parsing array data ke tingkat detail struktur yang diperlukan.
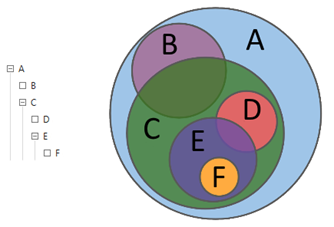 Gambar 1. Permintaan hierarkis
Gambar 1. Permintaan hierarkisGambar 2 menunjukkan contoh klasik dari query kompleks yang mengandung kriteria seleksi tekstual dan numerik.
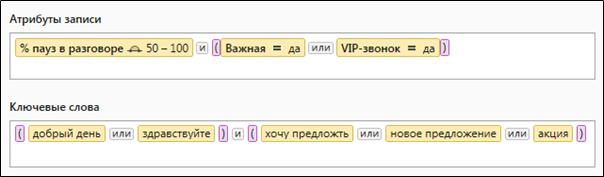 Gambar 2. Permintaan kompleks yang berisi parameter pemilihan data kuantitatif dan leksikal
Gambar 2. Permintaan kompleks yang berisi parameter pemilihan data kuantitatif dan leksikalSeperti apa bentuk query untuk Solr?
Pertimbangkan mekanisme umum untuk mengeksekusi kueri dalam Solr menggunakan contoh kueri
B pada Gambar 1. Seperti yang dapat kita lihat, kueri
B memiliki kueri induk
A , dengan kata lain
B⊆A . Dalam analitik ucapan, permintaan tidak dapat dipenuhi sementara setidaknya satu dari "orang tuanya" tidak terpenuhi. Dengan demikian, kueri
A dieksekusi terlebih dahulu, dan hanya kemudian
B. Jelas,
B harus mengandung kondisi permintaan
A.Hal pertama yang terlintas dalam pikiran adalah menggabungkan kondisi kedua kueri melalui
AND dan menempelkannya ke
query :
q=key:A AND key:BNamun, jika kami hanya menggabungkan semua kueri berturut-turut ke dalam satu
query , itu akan menjadi besar, itu akan berbeda untuk setiap kueri dan itu akan dihitung secara keseluruhan. Juga, kondisi
A akan mempengaruhi relevansi hasil permintaan
B , yang tidak diinginkan.
Mari kita coba menambahkan kueri induk sebagai
FilterQuery . Dalam hal ini, kueri
A tidak akan terpengaruh oleh ketidak relevansi dan kami dapat berharap bahwa itu telah selesai dan hasilnya ada di cache. Dengan demikian, Solr harus menghitung hanya permintaan
B , sementara Solr akan mengurutkan pilihan yang dihasilkan dengan cara yang kita butuhkan:
q=keyword:B &fq=keyword:AJika kami mempertimbangkan format permintaan untuk Solr secara skematis, kami dapat membedakan dua entitas utama:
MainQuery - kueri utama dengan serangkaian parameter yang harus dipenuhi oleh dokumen. Misalnya, permintaan pencarian untuk operator yang sopan akan terlihat seperti ini: text_operator: ” ” .
Ini berarti bidang text_operator pada dokumen pencarian harus mengandung frasa “ ”
FilterQuery - satu set filter tambahan yang membatasi pilihan yang dihasilkan. Format MainQuery cocok dengan MainQuery
Memisahkan permintaan menjadi
Main dan
Filter memungkinkan Anda untuk:
- secara eksplisit menunjukkan parameter kueri mana yang harus memengaruhi peringkat dokumen dalam pemilihan, dan yang hanya berfungsi untuk pemilihan dalam pemilihan yang dihasilkan. Relevansi untuk membangun peringkat dokumen dihitung ketika bagian dari permintaan MainQuery dieksekusi, dan ketika bagian dari permintaan
FilterQuery dokumen yang tidak memenuhi kondisi permintaan - secara signifikan mengurangi beban di mesin pencari, karena sampel yang dihasilkan diperoleh setelah perhitungan
FilterQuery -cache sepenuhnya, sedangkan hasil perhitungan MainQuery disimpan dalam cache hanya untuk yang pertama di peringkat 50 nilai
MainQuery dan
FiletrQuery memiliki efek berbeda pada fungsi Solr. Misalnya, untuk
penyorotan , fungsi yang bertanggung jawab untuk menyoroti fragmen dokumen yang relevan, hanya
MainQuery , dan parameter
FilterQuery tidak memengaruhi
highlighting . Ini logis, karena relevansi dihitung tepat di bagian permintaan
MainQuery . Beginilah hasil yang terlihat seperti pencarian nyata teks dengan kata-kata "halo" dan "layanan".
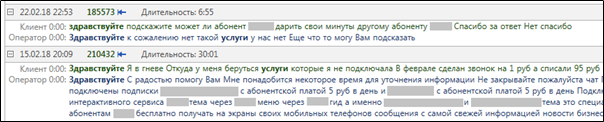 Gambar 3. Menyorot kata-kata yang relevan setelah menyelesaikan permintaan
Gambar 3. Menyorot kata-kata yang relevan setelah menyelesaikan permintaan MainQuery .
Kueri yang rumit di Solr
Mari kita kembali ke contoh operator yang sopan. Dalam contoh ini, kami menentukan panggilan yang sesuai dengan kehadiran frasa "selamat siang" dalam pidato operator, tetapi tidak menunjukkan interval waktu untuk mencari kata kunci relatif terhadap awal atau akhir percakapan.
Tampaknya ada semua yang diperlukan untuk ini - transkrip teks percakapan telepon berisi stempel waktu untuk setiap kata, serta informasi tentang siapa dari peserta dalam dialog yang dimilikinya. Data ini juga dapat digunakan dalam pencarian.
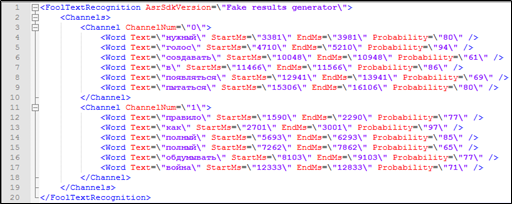 Gambar 4. Sebuah fragmen dekripsi tekstual dengan markup yang tidak termasuk dalam indeks Solr: afiliasi pembicara, cap waktu.
Gambar 4. Sebuah fragmen dekripsi tekstual dengan markup yang tidak termasuk dalam indeks Solr: afiliasi pembicara, cap waktu.Tetapi bagaimana cara memproses permintaan pencarian untuk Solr, jika parameter yang tidak dapat diindeks terlibat dalam permintaan - waktu kata diucapkan?
Dua cara yang jelas untuk mengatasi masalah ini muncul:
- tambahkan parameter yang tidak diindeks ke indeks Solr. Pada saat yang sama, konsumsi memori akan sedikit meningkat, tetapi indeks akan secara signifikan lebih berat
- pemilihan data berdasarkan parameter yang tidak dapat diindekskan harus dilakukan dengan menggunakan layanannya, dan dalam pengumpulan dokumen yang diperoleh setelah pemilihan tersebut, cari menggunakan indeks Solr. Pada saat yang sama, konsumsi memori akan secara signifikan lebih besar daripada dalam kasus pertama, tetapi kinerjanya akan dapat diprediksi
Kami telah memilih opsi kedua. Untuk melakukan ini, kami telah mengembangkan layanan yang menghitung koleksi berdasarkan permintaan yang berisi parameter logis dan numerik apa pun yang tidak termasuk dalam indeks Solr. Sebagai hasil karya layanan ini, bagian dari koleksi yang tidak memenuhi permintaan ditandai dengan tag khusus ("lolos") dan kemudian tidak berpartisipasi dalam perhitungan hasil permintaan.
Bayangkan kita ingin memaksakan pembatasan pencarian pada query
B yang sudah kita ketahui, hanya dalam 30 detik pertama dialog. Pada tahap pertama, kita mengeksekusi
B sebagai kueri sederhana, lalu "menyaring" kata-kata yang melampaui rentang yang dipilih sehingga mereka tidak jatuh ke dalam indeks Solr, tetapi pada saat yang sama, kita dapat mengembalikan dokumen asli dari mereka. Dokumen yang dihasilkan ditempatkan dalam koleksi Solr terpisah dan pencarian untuk permintaan
B dimulai kembali di atasnya.
Di sini saya harus mengatakan bahwa pembatasan pada awal atau akhir percakapan adalah bunga, beri adalah pembatasan pada hasil permintaan orang tua. Pertimbangkan eksekusi permintaan seperti itu.
Bayangkan dokumen kita terdiri dari bola-bola dengan angka. Mari kita coba menemukan semua bola "6" yang terletak tidak lebih dari dua bola di sebelah kanan "5".
Anda sudah menyadari bahwa nomor bola termasuk dalam indeks Solr, dan tidak ada jarak antara bola.
|  |
Temukan semua dokumen dengan bola "6" dan "5". Sebagai MainQuery menggunakan kueri untuk bola "5", dan kueri untuk "6" kami akan kirim ke FilterQuery . Sebagai hasilnya, Solr akan menyoroti bola "5" di hasil pencarian, yang akan sangat menyederhanakan hidup kita di langkah selanjutnya. | 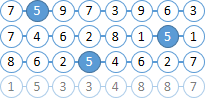 |
| Kami menyaring semua bola kecuali yang berada pada jarak yang diinginkan dari "5". Dokumen yang diterima (dokumen dengan bola yang diinginkan) akan ditempatkan dalam koleksi terpisah. |  |
Mari kita jalankan FilterQuery pada bola "6" di koleksi yang dihasilkan, hasilnya adalah dokumen yang kita FilterQuery . |  |
Dalam praktiknya, bola 5 dan 6 biasanya menyembunyikan kueri yang menempati beberapa layar dalam representasi tekstualnya. Saya senang kami menerapkan pencarian ini tidak sia-sia - analis sering menggunakan pertanyaan dengan batasan dari orang tua.
Kesimpulan
Apa yang kami pelajari, apa yang kami pelajari dan apa yang kami capai sebagai hasil dari proyek ini?
Kami tahu cara menggunakan Solr secara efektif untuk bekerja dengan data dari berbagai jenis, kami dapat "mengajarkan" Solr untuk memproses permintaan dengan parameter yang tidak termasuk dalam indeks pencariannya.
Kami telah mengembangkan sistem analisis suara industri yang beroperasi di bawah beban tinggi: permintaan pencarian yang kompleks dari para analis dihitung untuk sampel hingga lima juta dokumen teks. Itu mungkin dan lebih, tetapi tidak ada kebutuhan praktis. Sampel analis yang biasa digunakan adalah hingga sekitar 500 ribu teks panggilan telepon yang dikenali, dan jumlah total panggilan dapat mencapai 15 juta.
Untuk pelanggan kami di pusat kontak, sistem memberikan peluang yang belum pernah terjadi sebelumnya untuk analisis yang sangat berbeda: analisis topik dan alasan permintaan, analisis kepuasan pelanggan, dan banyak lainnya.
Sekarang kami menghubungkan sumber baru ke analitik kami - obrolan teks pelanggan dengan operator. Kami menerapkan satu aplikasi untuk analitik panggilan klien di semua saluran pusat kontak: telepon, obrolan, formulir di situs, dll.
Kami akan dengan senang hati menjawab pertanyaan Anda.
Terima kasih
PS Solr adalah hal yang sangat sulit dan membutuhkan penyetelan yang baik untuk mendapatkan hasil yang baik. Kami akan menceritakan tentang pengalaman kami di bidang ini dalam artikel berikut.