Kami telah memberi tahu Anda tentang
statistik teks yang menarik ,
mengulas artikel tentang penggunaan autocoder dalam analisis teks , dan mengejutkan kami dengan algoritme
pencarian baru kami
untuk pinjaman yang dipindahtangankan dan
parafrase . Saya memutuskan untuk melanjutkan tradisi perusahaan kami dan, pertama, memulai artikel dengan "T", dan kedua, katakan:
- cara cepat menemukan paragraf teks di antara ratusan juta artikel;
- menjadi apa dokumen itu setelah memuat ke dalam sistem Anti-Plagiarisme, dan apa yang harus dilakukan selanjutnya;
- bagaimana sebuah laporan dibentuk yang hampir tidak ada yang melihat, tetapi akan sia-sia;
- cara mengindeks tidak semua, tapi cukup.

Bagaimana semuanya dimulai
Pada tahun 2005, rektor dari salah satu universitas terbesar di Moskow mendatangi kami di
Forecsys untuk menyelesaikan masalah yang sangat serius - di lembaga pendidikan, para siswa lulus ijazah dan surat-surat sekolah yang dihapus seluruhnya. Kami mengambil beberapa ratus karya siswa berprestasi dan mencari mereka di jaringan dengan pertanyaan sederhana. Lebih dari separuh dari
"siswa berprestasi" ternyata adalah penipu yang mengunduh ijazah dari Internet dan hanya mengganti halaman judul. Lebih dari separuh siswa berprestasi, Karl! Apa yang terjadi pada siswa biasa sulit dibayangkan. Cara termudah untuk mencari pekerjaan adalah untuk kueri yang berisi kata-kata dengan "lubang hitam". Kami telah menyadari skala bencana. Sangat mendesak untuk menyelesaikan sesuatu. Pada saat itu, universitas asing berbahasa Inggris sudah menggunakan solusi pencarian pinjaman, tetapi untuk beberapa alasan tidak ada yang memeriksa pekerjaan di Rusia.
Pemain asing tidak ingin menyesuaikan solusi mereka dengan bahasa Rusia saat itu. Akibatnya, pada 17 Maret 2005, pengembangan sistem pencarian pinjaman dalam negeri pertama dimulai. Kata "Anti-plagiarisme" diciptakan sedikit kemudian, dan domain antiplagiat.ru terdaftar pada 28 April 2005. Kami berencana untuk merilis situs pada 1 September 2005, tetapi, seperti yang sering terjadi dengan programmer, tidak punya waktu. Ulang tahun resmi perusahaan kami adalah hari antiplagiat.ru menerima pengguna pertama, yaitu 4 September. Anda tahu, saya bahkan senang dengan ini, karena selama pesta perusahaan pada hari ulang tahun perusahaan, semua orang dapat dengan tenang merayakan, dan tidak khawatir tentang hari sekolah pertama anak-anak mereka.
Tapi sesuatu yang membuat saya terganggu. Pada 2005, kami menciptakan semacam mesin pencari, di mana, tidak seperti Yandex dan Google, kueri itu bukan dua atau tiga kata, tetapi keseluruhan teks yang terdiri dari beberapa kalimat. Karena itu, masuk akal untuk menggunakan "Anti-plagiarisme" jika Anda memiliki teks dari 1000 karakter (ini sekitar setengah halaman).
Selama pengembangan layanan, prototipe dibuat pada php (komponen web) dan Microsoft SQL Server (mesin pencari). Segera menjadi jelas bahwa ini tidak akan lepas landas dan perlahan akan bekerja pada beberapa juta dokumen. Karena itu, saya harus memotong mesin pencari saya. Sekarang sistem ditulis dalam C # dan python, menggunakan PostgreSQL dan MongoDB (pada kenyataannya, lebih banyak, tetapi lebih banyak tentang itu di artikel berikutnya). Mesin pencari masih sepenuhnya dikembangkan oleh kami.
Masukkan suka. Tulis di komentar jika Anda ingin mempelajari tentang sejarah pengembangan sistem, perubahan dalam proses perusahaan dan perangkat keras tempat Antiplagiarisme bekerja pada waktu yang berbeda dalam hidupnya, dan sedang bekerja sekarang.
Kata yang memberi nama perusahaan kini telah menjadi kata rumah tangga. Seringkali di mesin pencari orang dapat menemukan ekspresi seperti "periksa untuk anti-plagiarisme", "meningkatkan anti-plagiarisme". Setiap orang yang entah bagaimana terhubung dengan bidang pencarian pinjaman di Rusia dan negara-negara tetangga mencoba menggunakan kata "anti-plagiarisme" untuk meningkatkannya dalam hasil pencarian. Kita sering ditanya tentang "anti-plagiarisme" lainnya. Jadi, "Anti-plagiarisme" adalah satu, itu adalah merek dagang dan nama perusahaan kami.
Pada awal penerapan layanan pencarian pinjaman, kami memutuskan bahwa kami akan bekerja dengan teks sebagai urutan karakter. Berbagai konstruksi semantik dari teks, pencarian makna, analisis kalimat, dll, langsung ditolak. Solusi yang kami pilih memberikan dua keuntungan besar - kecepatan pencarian tinggi dan volume indeks pencarian yang relatif kecil.
Saat ini ada tiga produk di jajaran kami. Mereka dibedakan berdasarkan fungsinya, tetapi pada dasarnya mengandung prinsip pencarian pinjaman yang sama. Dalam artikel ini, saya akan berbicara tentang bagaimana pencarian klasik kami untuk pinjaman bekerja - fungsionalitas yang telah menjadi dasar layanan sejak awal dan masih belum berubah secara konsep. Skema pencarian pinjaman, seperti yang Anda lihat dalam gambar, sederhana dan mudah, seperti menggambar burung hantu. Pertama, kami mendapatkan dokumen dari pengguna, lalu kami mengekstrak teks dari itu. Kemudian kami mencari pinjaman dalam teks ini, kami mendapatkan "revisi" (seperti yang kita sebut laporan untuk satu modul pencarian) dan, akhirnya, kami mengumpulkan revisi menjadi satu laporan besar, yang kami tampilkan sebagai hasil kepada pengguna.
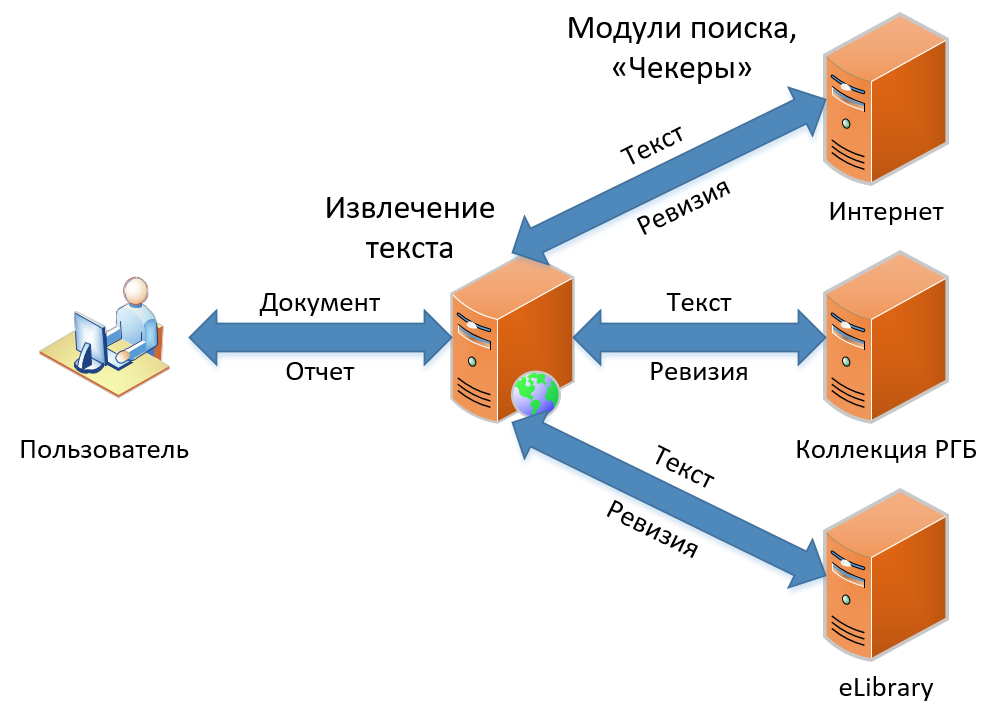
Mari kita lihat bagaimana semua ini terjadi secara rinci.
Ekstraksi teks
Pertama-tama, "Anti-plagiarisme" adalah layanan untuk mencari hanya pinjaman
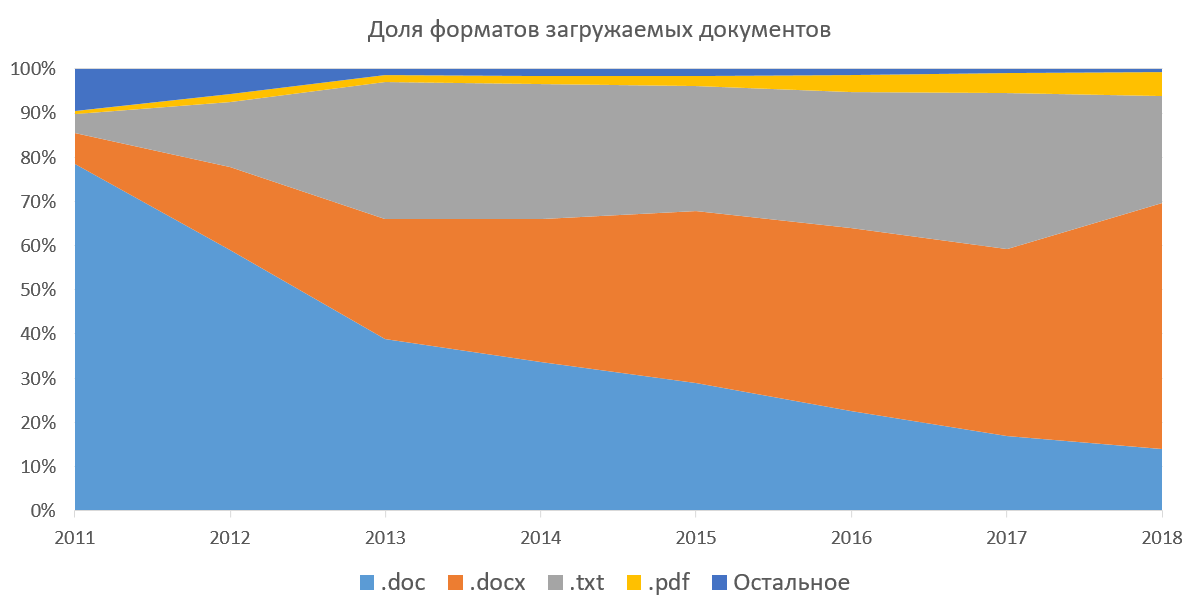
teks , yang berarti bahwa kita perlu mengekstraksi teks dari semua dokumen untuk terus bekerja dengannya. Sistem ini mendukung kemampuan untuk mengunduh dokumen dalam format docx, doc, txt, pdf, rtf, odt, html, pptx dan beberapa format lain (tidak pernah digunakan). Anda juga dapat mengunduh semua dokumen ini di arsip (7z, zip, rar). Metode ini sangat populer ketika kami tidak dapat mengunggah beberapa dokumen sekaligus melalui antarmuka web. Di bawah ini adalah grafik popularitas format dokumen yang dapat diunduh di bagian perusahaan dari sistem kami. Ini menunjukkan bagaimana docx telah digantikan oleh doc selama beberapa tahun, dan proporsi pdf secara bertahap tumbuh. Jika Anda tidak menganggap txt (mengekstraksi teks karena sepele), maka bagi kami yang paling menyenangkan adalah pdf. Di luar negeri pdf adalah standar de facto, menerbitkan artikel, mempersiapkan pekerjaan siswa. Menurut statistik kami, pdf secara bertahap mendapatkan popularitas di Rusia dan negara-negara CIS. Kami sendiri mempromosikan format ini kepada massa, merekomendasikan mengunduh dokumen di dalamnya.
Kami membatasi format unduhan dokumen untuk klien pribadi ke pdf dan txt, dan itulah sebabnya kami mengurangi konsumsi sumber daya dan mengurangi biaya untuk mendukung layanan gratis. Lagi pula, Anda perlu memeriksa teks, dan tidak menguji sistem? Jadi apa bedanya dalam format apa untuk mengunggahnya?
Cara termudah berikutnya untuk mengekstrak teks adalah docx, karena, pada kenyataannya, ini adalah arsip zip dengan xml di dalamnya, cukup sederhana untuk diproses, dan banyak yang bisa dilakukan pada level rendah.
Hal yang paling sulit bagi kami adalah dok. Format ini telah ditutup untuk waktu yang lama, dan sekarang ada banyak implementasinya. Microsoft Word terakhir, yang tidak mendukung .docx (walaupun melalui Paket Kompatibilitas Microsoft Office), dirilis 20 tahun yang lalu dan dimasukkan dalam Microsoft Office 97. Formatnya menggunakan OLE, yang kemudian tumbuh menjadi COM dan ActiveX, semuanya biner, kadang tidak kompatibel antar versi. Secara umum, mimpi buruk seorang programmer modern. Adalah baik bahwa format .doc secara bertahap meninggalkan lokasi. Saya pikir waktunya telah tiba bagi kita untuk membantunya pensiun. Kami akan segera memperingatkan pengguna bahwa format ini sudah usang.
Jadi, kembali ke laporan. Kami mendapat file dan mulai mengekstraksi teks. Bersama dengan teks, sistem juga mengekstraksi posisi kata-kata pada halaman sehingga di masa mendatang akan memungkinkan untuk menunjukkan kepada pengguna kami tata letak laporan pinjaman pada dokumen itu sendiri. Selain itu, pada tahap yang sama, kami mencari solusi teknis untuk Anti-Plagiarisme.
Segera setelah "Anti-plagiarisme" muncul, menunjukkan persentase orisinalitas, ada orang yang ingin lulus cek untuk pinjaman dengan usaha minimal, serta orang-orang yang menawarkan layanan seperti itu untuk mendapatkan uang. Masalahnya adalah bahwa parameter numerik meminta untuk menjadi perkiraan. Bagaimanapun, ini sangat sederhana - alih-alih membaca sebuah karya menggunakan sistem sebagai alat, jangan membacanya, tetapi evaluasilah dengan persentase orisinalitas! Kemalangan inilah yang memunculkan arah seperti penyetelan karya (perubahan teks untuk meningkatkan persentase orisinalitas karya). Baca lebih lanjut tentang masalah dalam proses universitas di artikel
"Tentang praktik mendeteksi pinjaman di universitas Rusia .
"Dalam sistem pencarian asing, masalah mendeteksi solusi teknis dan melawannya secara praktis tidak sepadan. Faktanya adalah bahwa "tipuan dengan telinga" yang ditemukan akan diikuti oleh hukuman yang sangat keras - pengusiran, dan noda yang tak terhapuskan pada reputasi ilmiah, tidak sesuai dengan karir selanjutnya. Dalam kasus kami, situasinya sangat sederhana: "Oh, sistem ini mengacaukan sesuatu!", "Oh, ini bukan aku, itu sendiri!" Siswa kemungkinan akan dikirim untuk mengulang. Faktanya adalah bahwa penghapusan, sayangnya, bukanlah sesuatu yang memalukan.
Tapi sekali lagi terganggu. Cara lain untuk mengekstrak teks adalah OCR. Kami mencetak dokumen pada printer virtual, dan kemudian mengenalinya. Baca lebih lanjut tentang ini di artikel
"Pengenalan Gambar dalam Layanan Anti-Plagiarisme" .
Sekarang sedikit kisah kita tentang mengekstraksi teks. Pertama, kami mengekstraksi teks menggunakan IFilters. Mereka lambat, hanya di bawah Windows, dan tidak mengembalikan informasi pemformatan (tidak jelas di mana teks putih berada di latar belakang putih, maka Anda tidak dapat menandai blok pinjaman langsung di dokumen pengguna). Kami berpikir bahwa masalah ini akan diselesaikan jika kami mulai menggunakan perpustakaan berbayar, tetapi kami juga menemukan keterbatasan: seperti sebelumnya di Windows, mereka tidak melihat rumus, kadang-kadang jatuh pada dokumen yang disiapkan khusus (perpustakaan berbeda pada yang berbeda!). Gagasan berikutnya adalah untuk OCR semua dokumen yang masuk, tetapi pendekatan ini sangat intensif sumber daya (hanya memproses 10 halaman per menit pada satu inti), dan di beberapa tempat teks tidak diekstraksi secara akurat.
Kami tidak menemukan peluru perak, meskipun beberapa kali kami berpikir bahwa itu adalah Kebahagiaan. Namun, kemudian, setelah hidup sedikit dengan ini, mereka menyadari bahwa itu lagi-lagi sebuah Pengalaman. Ekstraksi teks menyeimbangkan garis tipis antara kinerja (Anda perlu mengekstrak teks dari ratusan dokumen per menit), keandalan (Anda perlu mengekstraksi teks dari segalanya), fungsionalitas (memformat, menyelesaikan masalah, itu saja). Sekarang semua hal di atas dan sedikit lebih banyak pekerjaan untuk kita. Kami terus bereksperimen dengan bidang ini dan terus mencari Kebahagiaan kami.
Teks diekstraksi, putaran ditemukan dan dihilangkan sebagian, kami berangkat untuk mencari pinjaman!
Pencarian Pinjaman
Idenya, diimplementasikan dalam prosedur pencarian, diusulkan oleh Ilya Segalovich dan Yuri Zelenkov (Anda dapat membaca, misalnya, dalam artikel:
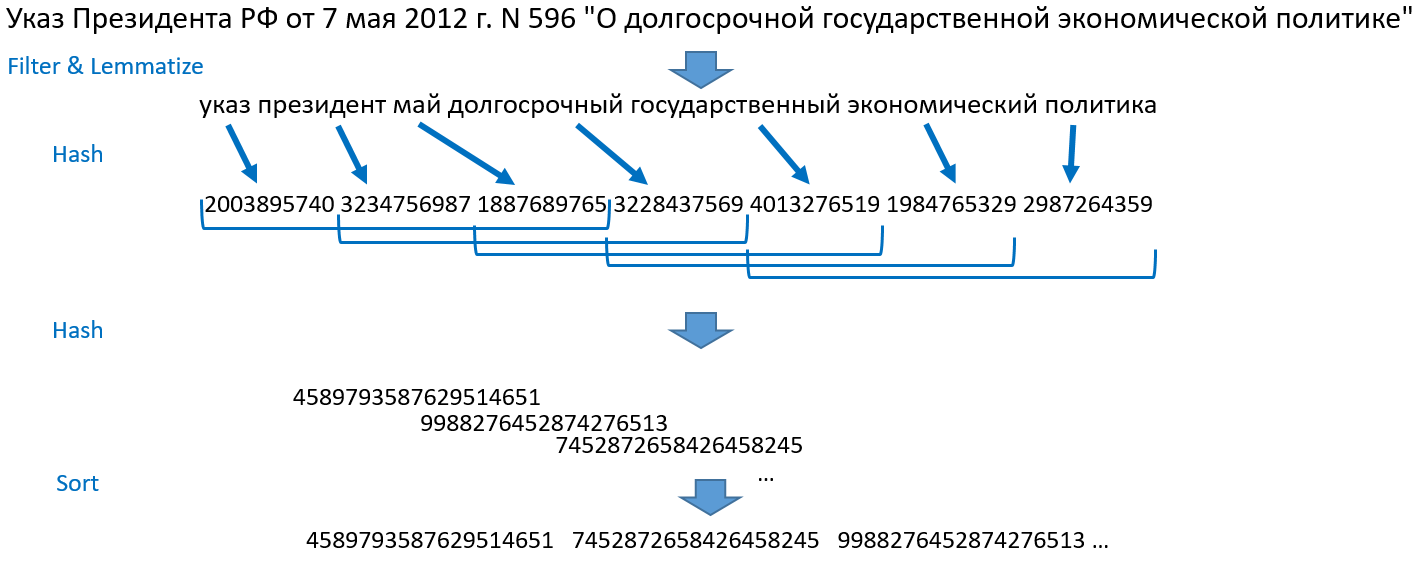
Analisis komparatif metode untuk menentukan duplikat fuzzy untuk dokumen Web ). Saya akan memberi tahu Anda cara kerjanya untuk kami. Ambil, misalnya, kalimat: "Keputusan Presiden Federasi Rusia 7 Mei 2012 N 596" Tentang Kebijakan Ekonomi Negara Jangka Panjang "."
- Kami memecah kalimat menjadi kata-kata, kami membuang angka, tanda baca, menghentikan kata-kata. Lemmatize (bentuk normal) semua kata.
- Kami mengubah kata menjadi bilangan bulat dengan hashing, kami mendapatkan array angka.
- Kita ambil tiga hash pertama, lalu hash ke-2, ke-3, ke-4, kemudian ke-3, ke-4, ke-5 dan seterusnya ke akhir array hash. Ini adalah sirap. Metode ini mendapatkan namanya karena set ubin yang tumpang tindih tersebut. Kami menggabungkan setiap ubin menjadi satu objek dan hash lagi.
- Kami mengurutkan angka yang dihasilkan, kami mendapatkan array bilangan bulat yang dipesan. Ini adalah dasar untuk pencarian.
Sekarang untuk pencarian, kita membutuhkan fungsi ajaib yang, menurut daftar hash, mengubah dokumen, diurutkan dalam urutan menurun dari jumlah hash yang cocok, menjadi dokumen sumber. Fungsi ini seharusnya bekerja dengan cepat karena kami ingin mencari miliaran dokumen. Untuk menemukan set tersebut dengan cepat, kita memerlukan indeks balik, yang oleh hash mengembalikan daftar dokumen yang berisi hash ini. Kami telah mengimplementasikan tabel hash raksasa tersebut. Tidak seperti saudara pencarian kami yang lebih tua, kami menyimpan tabel ini di SSD, bukan di memori. Kami cukup kekurangan kinerja seperti itu. Pencarian indeks mengambil sebagian kecil dari seluruh siklus pemrosesan dokumen. Lihat bagaimana pencarian berjalan:
Tahap 1. Pencarian Indeks
Untuk setiap hash dari teks permintaan, kami mendapatkan daftar pengidentifikasi dari dokumen sumber di mana itu terjadi. Selanjutnya, kami memberi peringkat daftar pengidentifikasi dokumen sumber dengan jumlah hash yang ditemui dari teks permintaan. Kami mendapatkan daftar peringkat dokumen kandidat untuk sumber pinjaman.
Tahap 2. Konstruksi audit
Untuk permintaan teks besar kandidat, mungkin ada sekitar 10 ribu. Ini masih banyak untuk membandingkan setiap dokumen dengan teks permintaan. Kami bertindak rakus, tetapi tegas. Kami mengambil dokumen sumber pertama, membuat perbandingan dengan teks permintaan dan mengecualikan dari semua kandidat hash lain yang sudah ada dalam dokumen pertama ini. Kami menghapus dari daftar kandidat yang memiliki hash nol, mengurutkan kembali kandidat sesuai dengan jumlah hash yang baru. Kami mengambil dokumen pertama dari daftar baru, membandingkannya dengan teks sumber, menghapus hash, menghapus kandidat nol, mengurutkan ulang kandidat. Kami melakukannya 10-20 kali, biasanya ini cukup untuk membuat daftar habis atau hanya dokumen yang cocok dengan beberapa hash yang tersisa di dalamnya.
Menggunakan hash kata memungkinkan kita untuk melakukan operasi perbandingan lebih cepat, menghemat memori, dan tidak menyimpan teks dokumen sumber, tetapi gips digitalnya (TextSpirit, demikian kami menyebutnya) yang diperoleh selama pengindeksan, sehingga melanggar hak cipta. Pemilihan fragmen pinjaman tertentu dilakukan dengan menggunakan pohon suffix.
Sebagai hasil dari pengecekan dengan satu modul pencarian, kami mendapatkan revisi, yang berisi daftar sumber, metadata mereka dan koordinat unit pinjaman relatif terhadap teks permintaan.
Perakitan laporan
Omong-omong, bagaimana jika salah satu dari 10-15 modul tidak merespons tepat waktu? Kami mencari koleksi RSL, eLibrary, dan Penjamin. Modul pencarian ini terletak di wilayah organisasi pihak ketiga, dan tidak dapat ditransfer ke situs kami karena alasan hak cipta. Titik kegagalan di sini selalu bisa menjadi saluran komunikasi dan berbagai force majeure di pusat data yang tidak dikendalikan oleh kami. Di satu sisi, pinjaman dapat ditemukan di modul pencarian apa pun, di sisi lain, jika salah satu komponen sistem tidak tersedia, Anda dapat menurunkan kualitas pencarian, tetapi memberikan sebagian besar hasilnya, sambil memperingatkan pengguna bahwa hasil untuk beberapa modul pencarian belum siap. Opsi mana yang akan Anda terapkan? Kami menerapkan kedua opsi ini sebagaimana mestinya.

Akhirnya, semua revisi diterima, kami memulai perakitan laporan. Ini menggunakan pendekatan yang mirip dengan menyiapkan satu revisi. Sepertinya tidak ada yang rumit, tetapi ada juga tugas yang menarik. Kami memiliki dua jenis pinjaman. "Kutipan" diindikasikan dalam tanda kutip berwarna hijau - dikutip dengan benar (menurut GOST) dari modul "Kutipan", ungkapan dari "apa yang harus dibuktikan" dari modul "Ekspresi Umum", dokumen hukum dari database Penjamin dan Lexpro. Semua pinjaman lainnya ditandai dengan warna oranye. Hijau didahulukan dari jeruk, kecuali mereka memasuki seluruh blok jeruk.
Sebagai hasilnya, laporan tersebut dapat dibandingkan dengan teks yang dicetak di atas kertas yang tergeletak di atas meja, di mana garis-garis berwarna (blok pinjaman dan kutipan) ditulis, saling tumpang tindih. Apa yang kita lihat di atas adalah laporan. Kami memiliki dua indikator untuk setiap sumber:
Bagian dalam laporan adalah rasio volume pinjaman, yang diperhitungkan dari sumber ini, dengan total volume dokumen. Jika teks yang sama ditemukan di beberapa sumber, maka itu hanya diperhitungkan di salah satu dari mereka. Saat Anda mengubah konfigurasi laporan (aktifkan atau nonaktifkan sumber), indikator sumber ini dapat berubah. Secara total, ini memberikan persentase pinjaman dan kutipan (tergantung pada warna sumbernya).
Bagikan dalam teks - rasio volume yang dipinjam dari sumber teks yang diberikan ke total volume dokumen. Tidak masuk akal untuk meringkas saham dalam teks dengan sumber, itu akan dengan mudah berubah 146% atau bahkan lebih. Indikator ini tidak berubah ketika laporan berubah.
Secara alami, laporan dapat diedit. Ini adalah fungsi khusus untuk ahli yang memeriksa pekerjaan untuk menonaktifkan peminjaman karya penulis sendiri (mungkin tampak bahwa fragmen ini tidak hanya dalam pekerjaan penulis sendiri, tetapi juga di tempat lain) dan memisahkan blok pinjaman, mengubah jenis sumber dari meminjam untuk kutipan. Sebagai hasil dari pengeditan laporan, ahli menerima nilai pinjaman sesungguhnya. Pekerjaan apa pun untuk verifikasi harus dibaca. Lebih mudah untuk melakukan ini dengan melihat bentuk asli dokumen, di mana blok pinjaman ditandai, dan segera, saat Anda membaca, edit laporan. Sayangnya, ini bukan tindakan logis oleh semua orang, banyak yang puas dengan persentase orisinalitas, bahkan tanpa melihat laporan.
Namun, mari kita mundur dan mencari tahu apa yang sebenarnya termasuk dalam indeks modul pencarian Internet yang dibuat oleh Anti-Plagiarisme.
Pengindeksan internet
Anti-plagiarisme sebagian besar difokuskan pada karya siswa, publikasi ilmiah, karya kualifikasi akhir, disertasi, dll. Kami mengindeks Internet dalam arah terarah - kami mencari kelompok besar teks ilmiah, abstrak, artikel, disertasi, jurnal ilmiah, dll. Pengindeksan terjadi seperti ini:
- Robot kami datang, memperkenalkan dirinya sendiri dan, dipandu oleh robots.txt (kami memiliki robot yang bagus), mengunduh dokumen dengan muatan yang masuk akal pada setiap host (ratusan situs berjalan pada saat yang sama, sehingga kami dapat menunggu beberapa saat di antara pemuatan halaman);
- Robot melewati dokumen dan metadata ke antrian pemrosesan, teks diekstraksi dari dokumen;
- Teks dianalisis untuk "kualitas" - seperti yang Anda ingat dari artikel tentang TPA, kita dapat menentukan genre dokumen, menambahkan heuristik sederhana ke volume di sini dan memahami apakah teks yang cocok datang kepada kami atau sampah;
- Teks kualitatif melangkah lebih jauh dan berubah menjadi hash. Hash dan metadata dikirim ke indeks Internet utama;
- Kami membandingkan teks yang diterima dengan teks yang sebelumnya diindeks oleh kami. Seorang pemula ditambahkan hanya jika itu benar-benar baru , yaitu 90% - . , url .
Dengan demikian, kami mengindeks teks berkualitas tinggi, dan semua teks yang diindeks secara signifikan berbeda untuk kami. Pertumbuhan volume yang diindeks di Internet ditunjukkan pada gambar di bawah ini. Sekarang rata-rata kami menambah indeks 15-20 juta dokumen per bulan.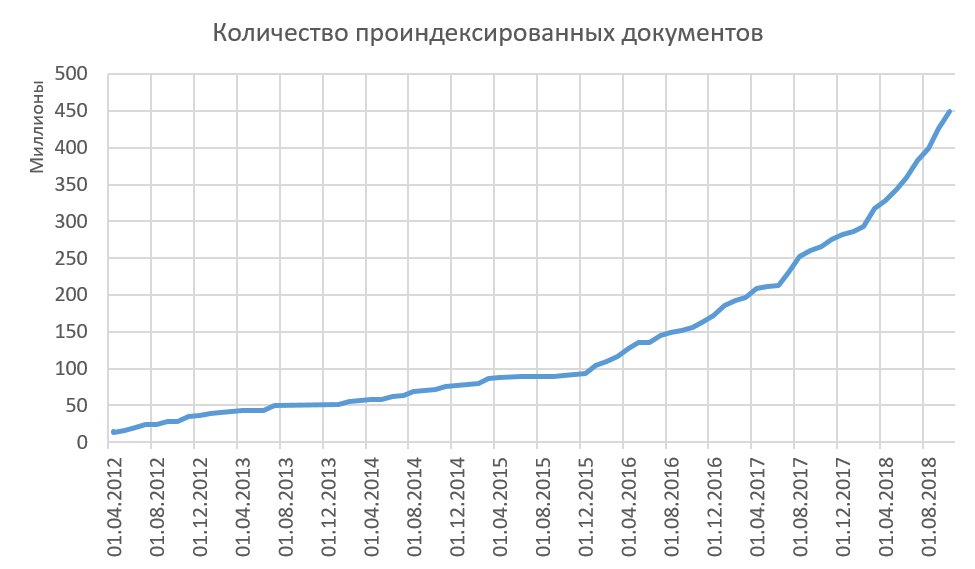 Melihat bahwa prosedur untuk menghapus dari indeks tidak dijelaskan di mana pun? Dan dia tidak! Kami pada dasarnya tidak menghapus dokumen dari indeks. Kami percaya bahwa jika kami dapat melihat sesuatu di Internet, maka orang lain dapat melihat teks ini dan menggunakannya dalam satu atau lain cara. Dalam hal ini, ada statistik yang menarik tentang apa yang dulunya di Internet, dan sekarang tidak ada lagi. Ya, bayangkan ungkapan "Sekali di Internet akan tinggal di sana selamanya" tidak benar! Sesuatu menghilang dari Internet selamanya. Apakah Anda tertarik mempelajari statistik kami tentang ini?
Melihat bahwa prosedur untuk menghapus dari indeks tidak dijelaskan di mana pun? Dan dia tidak! Kami pada dasarnya tidak menghapus dokumen dari indeks. Kami percaya bahwa jika kami dapat melihat sesuatu di Internet, maka orang lain dapat melihat teks ini dan menggunakannya dalam satu atau lain cara. Dalam hal ini, ada statistik yang menarik tentang apa yang dulunya di Internet, dan sekarang tidak ada lagi. Ya, bayangkan ungkapan "Sekali di Internet akan tinggal di sana selamanya" tidak benar! Sesuatu menghilang dari Internet selamanya. Apakah Anda tertarik mempelajari statistik kami tentang ini?Kesimpulan
Sungguh menakjubkan bagaimana solusi teknis yang diadopsi lebih dari 10 tahun yang lalu masih tetap relevan. Kami sekarang bersiap untuk merilis versi 4 dari indeks, lebih cepat, lebih maju secara teknologi dan lebih baik, tetapi didasarkan pada solusi yang sama. Arah pencarian baru telah muncul - pinjaman yang dapat dipindahtangankan, parafrase, tetapi indeks kami juga digunakan di sana, melakukan bahkan bagian kecil tapi penting dari pekerjaan.Pembaca yang budiman, apa yang ingin Anda ketahui tentang layanan kami?