
Di jantung mesin pencarian Meltwater dan
Fairhair.ai adalah Elasticsearch, kumpulan cluster dengan miliaran media dan artikel media sosial.
Pecahan indeks dalam kelompok sangat bervariasi dalam struktur akses, beban kerja, dan ukuran, yang menimbulkan beberapa masalah yang sangat menarik.
Pada artikel ini, kami akan menjelaskan bagaimana kami menggunakan pemrograman linier (optimasi linier) untuk mendistribusikan beban kerja pencarian dan pengindeksan secara merata di semua node dalam cluster. Solusi ini mengurangi kemungkinan satu simpul akan menjadi hambatan dalam sistem. Akibatnya, kami meningkatkan kecepatan pencarian dan menghemat infrastruktur.
Latar belakang
Mesin pencari Fairhair.ai berisi sekitar 40 miliar posting dari media sosial dan editorial, yang memproses jutaan pertanyaan setiap hari. Platform ini menyediakan hasil pencarian, grafik, analitik, ekspor data kepada pelanggan untuk analisis lebih lanjut.
Kumpulan data besar ini berada di beberapa cluster Elasticsearch 750-simpul dengan ribuan indeks di lebih dari 50.000 pecahan.
Untuk informasi lebih lanjut tentang kluster kami, lihat artikel sebelumnya tentang
arsitekturnya dan
penyeimbang beban pembelajaran mesin .
Distribusi beban kerja tidak merata
Data dan kueri pengguna kami biasanya terikat tanggal. Sebagian besar permintaan jatuh ke periode waktu tertentu, misalnya, minggu lalu, bulan lalu, kuartal terakhir atau rentang sewenang-wenang. Untuk menyederhanakan pengindeksan dan kueri, kami menggunakan
pengindeksan waktu , mirip dengan
tumpukan ELK .
Arsitektur indeks ini menawarkan beberapa keuntungan. Misalnya, Anda dapat melakukan pengindeksan massal yang efisien, serta menghapus seluruh indeks saat data usang. Ini juga berarti bahwa beban kerja untuk indeks yang diberikan sangat bervariasi dari waktu ke waktu.
Kueri secara eksponensial lebih banyak masuk ke indeks terbaru, dibandingkan dengan yang lama.
 Fig. 1. Skema akses untuk indeks waktu. Sumbu vertikal mewakili jumlah kueri yang diselesaikan, sumbu horizontal mewakili usia indeks. Dataran tinggi mingguan, bulanan, dan tahunan terlihat jelas, diikuti oleh ekor panjang beban kerja yang lebih rendah pada indeks yang lebih tua
Fig. 1. Skema akses untuk indeks waktu. Sumbu vertikal mewakili jumlah kueri yang diselesaikan, sumbu horizontal mewakili usia indeks. Dataran tinggi mingguan, bulanan, dan tahunan terlihat jelas, diikuti oleh ekor panjang beban kerja yang lebih rendah pada indeks yang lebih tuaPola dalam gambar. 1 cukup dapat diprediksi, karena pelanggan kami lebih tertarik pada informasi segar dan secara teratur membandingkan bulan berjalan dengan masa lalu dan / atau tahun ini dengan tahun lalu. Masalahnya adalah bahwa Elasticsearch tidak tahu tentang pola ini dan tidak secara otomatis mengoptimalkan untuk beban kerja yang diamati!
Algoritma alokasi beling Elasticsearch bawaan hanya memperhitungkan dua faktor:
- Jumlah pecahan pada setiap node. Algoritme mencoba menyeimbangkan jumlah pecahan per node secara merata.
- Label ruang disk kosong. Elasticsearch mempertimbangkan ruang disk yang tersedia pada sebuah node sebelum memutuskan apakah akan mengalokasikan pecahan baru ke node ini atau memindahkan segmen dari node ini ke yang lain. Dengan 80% dari disk yang digunakan, dilarang untuk menempatkan pecahan baru pada sebuah node, 90% dari sistem akan mulai secara aktif mentransfer pecahan dari node ini.
Asumsi mendasar dari algoritma adalah bahwa setiap segmen dalam cluster menerima kira-kira jumlah yang sama dari beban kerja dan bahwa setiap orang memiliki ukuran yang sama. Dalam kasus kami, ini sangat jauh dari kebenaran.
Penyeimbangan beban standar dengan cepat mengarah ke hot spot di cluster. Mereka muncul dan hilang secara acak, saat beban kerja berubah seiring waktu.
Hot spot pada dasarnya adalah sebuah host yang beroperasi di dekat batas satu atau lebih sumber daya sistem, seperti CPU, I / O disk, atau bandwidth jaringan. Ketika ini terjadi, node terlebih dahulu mengantri permintaan untuk sementara, yang meningkatkan waktu respons terhadap permintaan. Tetapi jika kelebihan beban berlangsung lama, maka pada akhirnya permintaan ditolak, dan pengguna mendapatkan kesalahan.
Konsekuensi umum lain dari kemacetan adalah tekanan tidak stabil dari sampah JVM karena permintaan dan operasi pengindeksan, yang mengarah ke fenomena "neraka menakutkan" dari pengumpul sampah JVM. Dalam situasi seperti itu, JVM tidak bisa mendapatkan memori dengan cukup cepat dan keluar dari memori, atau terjebak dalam siklus pengumpulan sampah yang tak berujung, membeku dan berhenti merespons permintaan dan ping cluster.
Masalahnya memburuk ketika kami
refactored arsitektur kami di bawah AWS . Sebelumnya, kami “diselamatkan” oleh fakta bahwa kami menjalankan hingga empat node Elasticsearch di server kami yang sangat kuat (24 core) di pusat data kami. Ini menutupi pengaruh distribusi asimetris pecahan: beban sebagian besar dihaluskan oleh sejumlah besar inti pada mesin.
Setelah refactoring, kami hanya menempatkan satu node pada satu waktu pada mesin yang kurang kuat (8 core) - dan tes pertama segera mengungkapkan masalah besar dengan "hot spot".
Elasticsearch menetapkan pecahan dalam urutan acak, dan dengan lebih dari 500 node dalam satu cluster, kemungkinan terlalu banyak pecahan "panas" pada satu node telah meningkat pesat - dan node tersebut dengan cepat meluap.
Untuk pengguna, ini berarti kemunduran yang serius dalam pekerjaan, karena node yang padat merespons secara lambat, dan terkadang benar-benar menolak permintaan atau kerusakan. Jika Anda membawa sistem seperti itu ke dalam produksi, maka pengguna akan sering melihat, sepertinya, UI acak melambat dan waktu habis acak.
Pada saat yang sama, masih ada sejumlah besar node dengan pecahan tanpa banyak beban, yang sebenarnya tidak aktif. Ini mengarah pada penggunaan sumber daya cluster kami yang tidak efisien.
Kedua masalah dapat dihindari jika Elasticsearch mendistribusikan pecahan lebih cerdas, karena rata-rata penggunaan sumber daya sistem di semua node berada pada tingkat yang sehat sebesar 40%.
Perubahan Berkelanjutan Cluster
Ketika bekerja lebih dari 500 node, kami mengamati satu hal lagi: perubahan konstan dalam status node. Pecahan terus bergerak bolak-balik dalam node di bawah pengaruh faktor-faktor berikut:
- Indeks baru dibuat, dan yang lama dibuang.
- Label disk dipicu karena pengindeksan dan perubahan pecahan lainnya.
- Elasticsearch secara acak memutuskan bahwa ada terlalu sedikit atau terlalu banyak pecahan pada node dibandingkan dengan nilai rata-rata cluster.
- Perangkat keras crash dan crash di tingkat OS menyebabkan instance AWS baru untuk memulai dan bergabung dengan mereka ke cluster. Dengan 500 node, ini terjadi rata-rata beberapa kali seminggu.
- Situs baru ditambahkan hampir setiap minggu karena pertumbuhan data normal.
Dengan semua ini diperhitungkan, kami sampai pada kesimpulan bahwa solusi yang kompleks dan berkelanjutan dari semua masalah memerlukan algoritma optimisasi ulang yang berkelanjutan dan dinamis.
Solusi: Shardonnay
Setelah mempelajari panjang opsi yang tersedia, kami sampai pada kesimpulan bahwa kami ingin:
- Bangun solusi Anda sendiri. Kami tidak menemukan artikel, kode, atau ide lain yang ada yang akan bekerja dengan baik pada skala kami dan untuk tugas kami.
- Luncurkan proses penyeimbangan ulang di luar Elasticsearch dan gunakan API pengalihan yang berkerumun daripada mencoba membuat plugin . Kami ingin loop umpan balik cepat, dan menggunakan plugin pada sekelompok skala ini dapat memakan waktu beberapa minggu.
- Gunakan pemrograman linier untuk menghitung gerakan serpihan optimal pada waktu tertentu.
- Lakukan optimasi terus menerus sehingga keadaan klaster secara bertahap mencapai yang optimal.
- Jangan memindahkan terlalu banyak pecahan sekaligus.
Kami memperhatikan hal yang menarik: jika Anda memindahkan terlalu banyak pecahan sekaligus, sangat mudah untuk memicu
badai gerakan pecahan yang mengalir . Setelah terjadinya badai seperti itu, ia dapat berlanjut selama berjam-jam, ketika pecahan bergerak tak terkendali bolak-balik, menyebabkan munculnya tanda tentang tingkat kritis ruang disk di berbagai tempat. Pada gilirannya, ini mengarah pada gerakan pecahan baru dan seterusnya.
Untuk memahami apa yang terjadi, penting untuk mengetahui bahwa ketika Anda memindahkan segmen yang diindeks secara aktif, itu sebenarnya mulai menggunakan lebih banyak ruang pada disk dari mana ia bergerak. Ini karena cara Elasticsearch menyimpan
log transaksi . Kami telah melihat kasus di mana saat memindahkan node, indeksnya berlipat ganda. Ini berarti bahwa node yang memprakarsai gerakan beling karena penggunaan ruang disk yang tinggi akan menggunakan
lebih banyak ruang disk untuk sementara waktu sampai ia memindahkan cukup pecahan ke node lain.
Untuk mengatasi masalah ini, kami mengembangkan layanan
Shardonnay untuk menghormati varietas anggur Chardonnay yang terkenal.
Optimalisasi linier
Optimalisasi linear (atau
pemrograman linier , LP) adalah metode untuk mencapai hasil terbaik, seperti laba maksimum atau biaya terendah, dalam model matematika yang persyaratannya diwakili oleh hubungan linear.
Metode optimasi didasarkan pada sistem variabel linier, beberapa kendala yang harus dipenuhi, dan fungsi objektif yang menentukan seperti apa solusi yang berhasil. Tujuan dari optimasi linear adalah untuk menemukan nilai-nilai variabel yang meminimalkan fungsi objektif, tunduk pada batasan.
Distribusi pecahan sebagai masalah optimisasi linier
Shardonnay harus bekerja terus menerus, dan pada setiap iterasi ia melakukan algoritma berikut:
- Menggunakan API, Elasticsearch mengambil informasi tentang pecahan, indeks, dan node yang ada di cluster, serta lokasi mereka saat ini.
- Model keadaan cluster sebagai satu set variabel LP biner. Setiap kombinasi (simpul, indeks, beling, replika) mendapat variabelnya sendiri. Dalam model LP, ada sejumlah heuristik yang dirancang dengan hati-hati, pembatasan, dan fungsi tujuan, lebih lanjut tentang ini di bawah ini.
- Mengirim model LP ke pemecah linier, yang memberikan solusi optimal dengan mempertimbangkan kendala dan fungsi tujuan. Solusinya adalah dengan menetapkan kembali pecahan ke node.
- Menafsirkan solusi LP dan mengubahnya menjadi urutan gerakan beling.
- Menginstruksikan Elasticsearch untuk memindahkan pecahan melalui API redirect kluster.
- Menunggu cluster untuk memindahkan pecahan.
- Kembali ke langkah 1.
Hal utama adalah mengembangkan batasan yang benar dan fungsi tujuan. Sisanya akan dilakukan oleh Solver LP dan Elasticsearch.
Tidak mengherankan, tugas itu sangat sulit untuk sekelompok ukuran dan kompleksitas ini!
Keterbatasan
Kami mendasarkan beberapa batasan pada model berdasarkan pada aturan yang ditentukan oleh Elasticsearch sendiri. Misalnya, selalu menempel pada label disk atau melarang menempatkan replika pada simpul yang sama dengan replika lain dari pecahan yang sama.
Yang lain ditambahkan berdasarkan pengalaman yang diperoleh selama bertahun-tahun bekerja dengan kelompok besar. Berikut ini beberapa contoh keterbatasan kita sendiri:
- Jangan pindahkan indeks hari ini, karena ini adalah yang terpanas dan dapatkan beban hampir konstan untuk membaca dan menulis.
- Berikan preferensi untuk memindahkan pecahan yang lebih kecil, karena Elasticsearch menanganinya lebih cepat.
- Dianjurkan untuk membuat dan menempatkan pecahan di masa depan beberapa hari sebelum mereka menjadi aktif, mulai diindeks, dan mengalami beban berat.
Fungsi biaya
Fungsi biaya kami menimbang bersama sejumlah faktor yang berbeda. Sebagai contoh, kami ingin:
- meminimalkan variasi pengindeksan dan permintaan pencarian untuk mengurangi jumlah "hot spot";
- pertahankan varians minimum penggunaan disk untuk operasi sistem yang stabil;
- meminimalkan jumlah gerakan beling sehingga "badai" dengan reaksi berantai tidak dimulai, seperti dijelaskan di atas.
Pengurangan variabel LP
Pada skala kami, ukuran model LP ini menjadi masalah. Kami dengan cepat menyadari bahwa masalah tidak dapat diselesaikan dalam waktu yang wajar dengan lebih dari 60 juta variabel. Oleh karena itu, kami menerapkan banyak trik optimasi dan pemodelan untuk mengurangi jumlah variabel secara drastis. Diantaranya adalah pengambilan sampel yang bias, heuristik, metode membagi dan menaklukkan, relaksasi berulang dan optimalisasi.
 Fig. 2. Peta panas menunjukkan beban yang tidak seimbang pada cluster Elasticsearch. Ini dimanifestasikan dalam dispersi besar penggunaan sumber daya di sisi kiri grafik. Melalui optimalisasi terus-menerus, situasinya secara bertahap stabil
Fig. 2. Peta panas menunjukkan beban yang tidak seimbang pada cluster Elasticsearch. Ini dimanifestasikan dalam dispersi besar penggunaan sumber daya di sisi kiri grafik. Melalui optimalisasi terus-menerus, situasinya secara bertahap stabil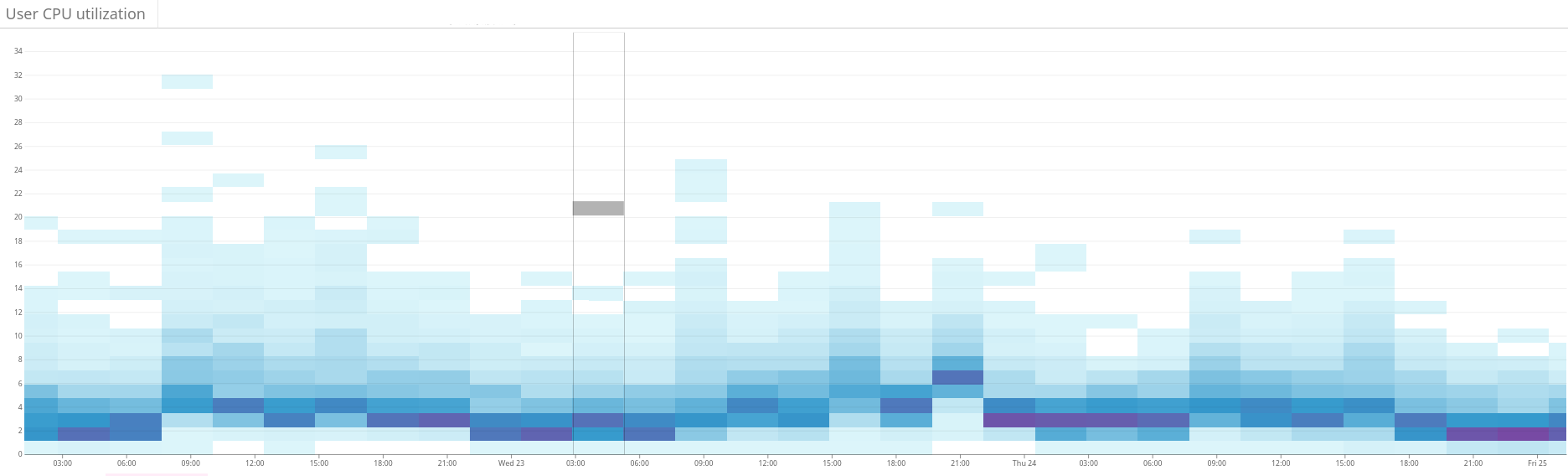 Fig. 3. Peta panas menunjukkan penggunaan CPU pada semua node cluster sebelum dan sesudah mengatur fungsi hotness di Shardonnay. Perubahan signifikan dalam penggunaan CPU terlihat dengan beban kerja yang konstan.
Fig. 3. Peta panas menunjukkan penggunaan CPU pada semua node cluster sebelum dan sesudah mengatur fungsi hotness di Shardonnay. Perubahan signifikan dalam penggunaan CPU terlihat dengan beban kerja yang konstan. Fig. 4. Peta panas menunjukkan throughput baca dari disk selama periode yang sama seperti pada gambar. 3. Operasi baca juga lebih merata di seluruh cluster.
Fig. 4. Peta panas menunjukkan throughput baca dari disk selama periode yang sama seperti pada gambar. 3. Operasi baca juga lebih merata di seluruh cluster.Hasil
Hasilnya, pemecah LP kami menemukan solusi yang baik dalam beberapa menit, bahkan untuk kelompok besar kami. Dengan demikian, sistem iteratif meningkatkan keadaan cluster ke arah optimalitas.
Dan bagian terbaiknya adalah bahwa dispersi dari beban kerja dan penggunaan disk menyatu seperti yang diharapkan - dan kondisi hampir-optimal ini dipertahankan setelah banyak perubahan yang disengaja dan tidak terduga di negara cluster sejak itu!
Kami sekarang mendukung distribusi beban kerja yang sehat di kluster Elasticsearch kami. Semua berkat optimasi linear dan layanan kami, yang kami suka sebut
Chardonnay .