Dalam posting terakhir , saya berbicara tentang Kubernetes, bagaimana ThoughtSpot menggunakannya untuk kebutuhan dukungan pengembangannya sendiri. Hari ini saya ingin melanjutkan percakapan tentang yang singkat, tetapi dari itu sejarah debugging yang tidak kalah menarik, yang terjadi baru-baru ini. Artikel ini didasarkan pada kenyataan bahwa containerization! = Virtualisasi. Selain itu, ditunjukkan bagaimana proses kemas bersaing untuk sumber daya bahkan dengan pembatasan optimal pada cgroup dan kinerja alat berat yang tinggi.
Sebelumnya, kami meluncurkan serangkaian operasi terkait pengembangan b CI / CD di kluster internal Kubernetes. Semuanya akan baik-baik saja, tetapi ketika Anda meluncurkan aplikasi "buruh pelabuhan", kinerja tiba-tiba turun secara dramatis. Kami tidak pelit: di masing-masing wadah ada keterbatasan daya komputasi dan memori (5 CPU / 30 GB RAM) yang ditetapkan melalui konfigurasi Pod. Pada mesin virtual dengan parameter seperti itu, semua permintaan kami dari kumpulan data kecil (10 Kb) untuk pengujian akan terbang. Namun, di Docker & Kubernetes dengan 72 CPU / 512 GB RAM, kami berhasil meluncurkan 3-4 salinan produk, dan kemudian rem dimulai. Permintaan yang digunakan untuk menyelesaikan dalam beberapa milidetik sekarang digantung selama 1-2 detik, dan ini menyebabkan semua jenis kegagalan dalam pipa tugas CI. Saya harus berurusan dengan debugging.
Sebagai aturan, semua jenis kesalahan konfigurasi saat mengemas aplikasi di Docker diduga. Namun, kami tidak menemukan apa pun yang dapat menyebabkan setidaknya beberapa jenis perlambatan (bila dibandingkan dengan pemasangan pada perangkat keras atau mesin virtual). Segalanya tampak benar. Selanjutnya, kami mencoba semua jenis tes dari paket Sysbench . Kami memeriksa kinerja CPU, disk, memori - semuanya sama seperti pada bare metal. Beberapa layanan dari toko produk kami memberikan informasi terperinci tentang semua tindakan: kemudian dapat digunakan untuk profil kinerja. Sebagai aturan, ketika ada kekurangan sumber daya (CPU, RAM, disk, jaringan) dalam beberapa panggilan, kegagalan waktu yang signifikan dicatat - jadi kami mencari tahu apa yang memperlambat dan di mana. Namun, tidak ada yang terjadi dalam kasus ini. Proporsi temporal tidak berbeda dari konfigurasi yang berfungsi - dengan satu-satunya perbedaan adalah bahwa setiap panggilan jauh lebih lambat daripada pada bare metal. Tidak ada yang menunjukkan sumber masalah sebenarnya. Kami sudah siap untuk menyerah ketika kami tiba-tiba menemukan ini .
Dalam artikel ini, penulis menganalisis kasus misterius yang serupa ketika dua, pada prinsipnya, proses ringan saling membunuh ketika berjalan di dalam Docker pada mesin yang sama, dan batas sumber daya ditetapkan ke nilai yang sangat sederhana. Kami membuat dua kesimpulan penting:
- Alasan utama terletak pada kernel Linux itu sendiri. Karena struktur objek cache dentry di kernel, perilaku satu proses sangat menghambat panggilan ke kernel
__d_lookup_loop , yang secara langsung mempengaruhi kinerja yang lain. - Penulis menggunakan
perf untuk mendeteksi bug di kernel. Alat debugging luar biasa yang belum pernah kami gunakan sebelumnya (sayang sekali!).
perf (kadang-kadang disebut perf_events atau alat perf; sebelumnya dikenal sebagai Penghitung Kinerja untuk Linux, PCL) adalah alat analisis kinerja Linux yang tersedia dari kernel versi 2.6.31. Utilitas manajemen ruang pengguna, perf, tersedia dari baris perintah dan merupakan kumpulan sub-perintah.
Itu melakukan profil statistik dari seluruh sistem (kernel dan ruang pengguna). Alat ini mendukung penghitung kinerja perangkat keras dan perangkat lunak (misalnya, hrtimer) platform, titik jejak, dan sampel dinamis (katakanlah, kprobes atau jubah). Pada 2012, dua insinyur IBM mengakui perf (bersama dengan OProfile) sebagai salah satu dari dua alat penghitung kinerja yang paling banyak digunakan di Linux.
Jadi kami berpikir: mungkin kita memiliki hal yang sama? Kami memulai ratusan proses berbeda dalam wadah, dan semuanya memiliki inti yang sama. Kami merasakan bahwa kami telah menyerang jejak! Berbekal perf , kami mengulangi debugging, dan pada akhirnya kami menunggu penemuan yang paling menarik.
Di bawah ini adalah entri perf dari 10 detik pertama ThoughtSpot yang berjalan pada mesin sehat (cepat) (kiri) dan di dalam wadah (kanan).
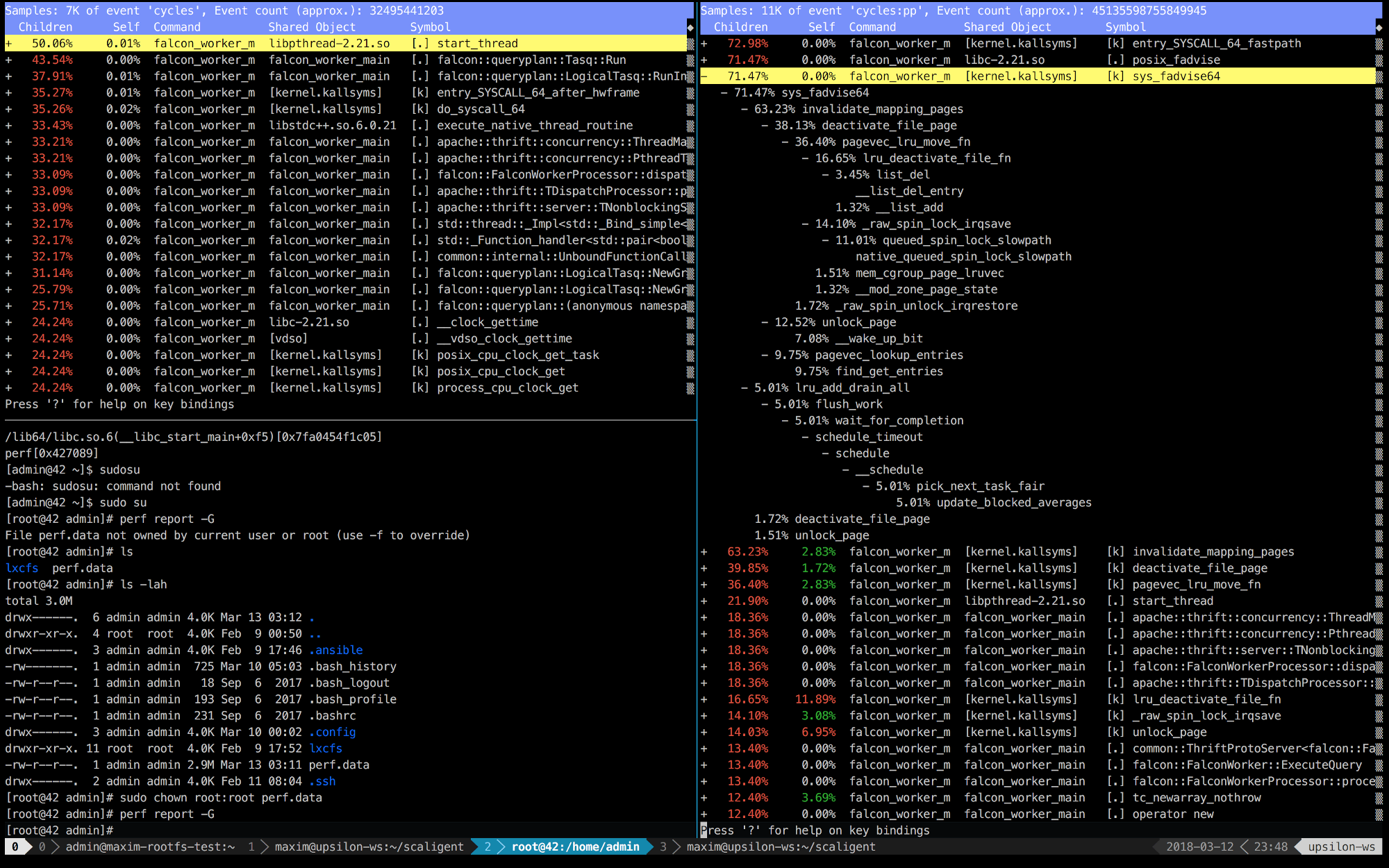
Segera jelas bahwa di sebelah kanan 5 panggilan pertama terhubung dengan kernel. Waktu sebagian besar dihabiskan pada ruang kernel, sementara di sebelah kiri - sebagian besar waktu dihabiskan untuk proses kita sendiri yang berjalan di ruang pengguna. Tetapi hal yang paling menarik adalah bahwa panggilan posix_fadvise membutuhkan waktu.
Program menggunakan posix_fadvise (), menyatakan niatnya untuk mengakses data file sesuai dengan pola tertentu di masa depan. Ini memberi kernel kesempatan untuk melakukan optimasi yang diperlukan.
Panggilan digunakan untuk situasi apa pun, oleh karena itu, tidak menunjukkan sumber masalah secara eksplisit. Namun, dengan menggali ke dalam kode, saya hanya menemukan satu tempat yang, secara teoritis, memengaruhi setiap proses dalam sistem:
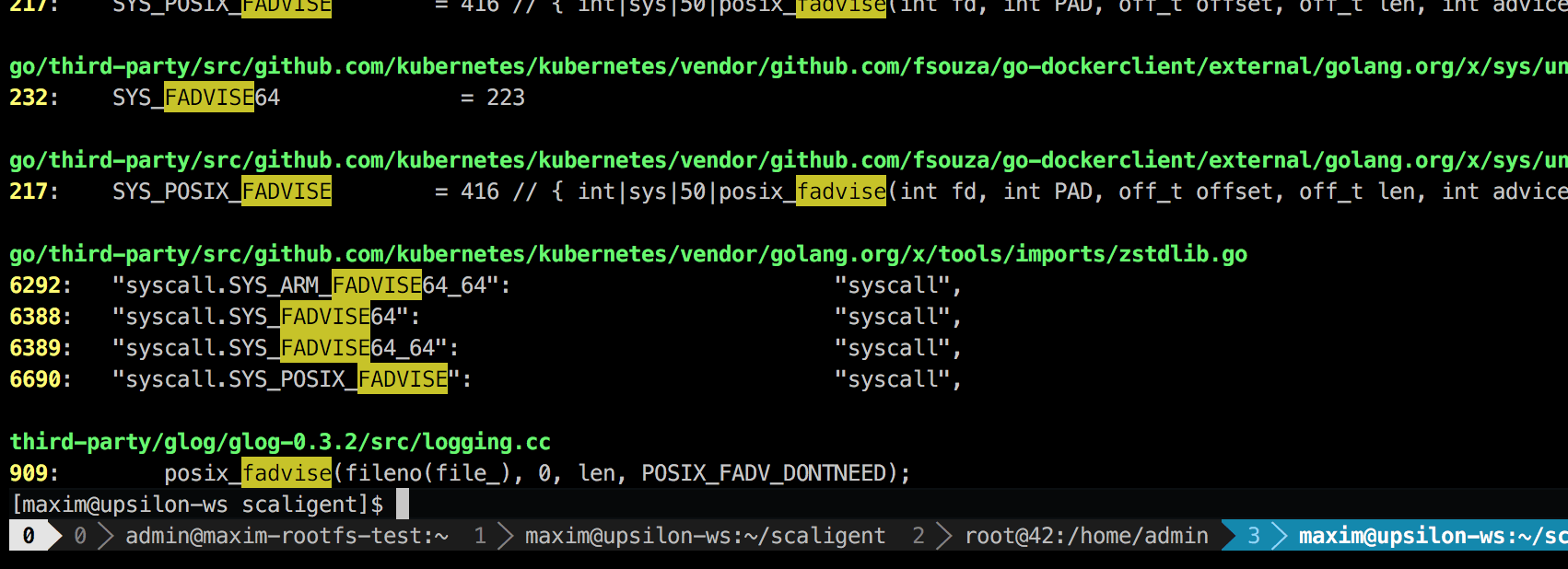
Ini adalah perpustakaan logging pihak ketiga yang disebut glog . Kami menggunakannya untuk proyek. Secara khusus, baris ini (dalam LogFileObject::Write ) mungkin merupakan jalur paling kritis dari seluruh pustaka. Disebut untuk semua peristiwa "log to file" (log ke file), dan banyak contoh log produk kami cukup sering. Melihat sekilas pada kode sumber menunjukkan bahwa bagian fadvise dapat dinonaktifkan dengan mengatur --drop_log_memory=false parameter --drop_log_memory=false :
if (file_length_ >= logging::kPageSize) {
yang kami, tentu saja, lakukan dan ... di bullseye!
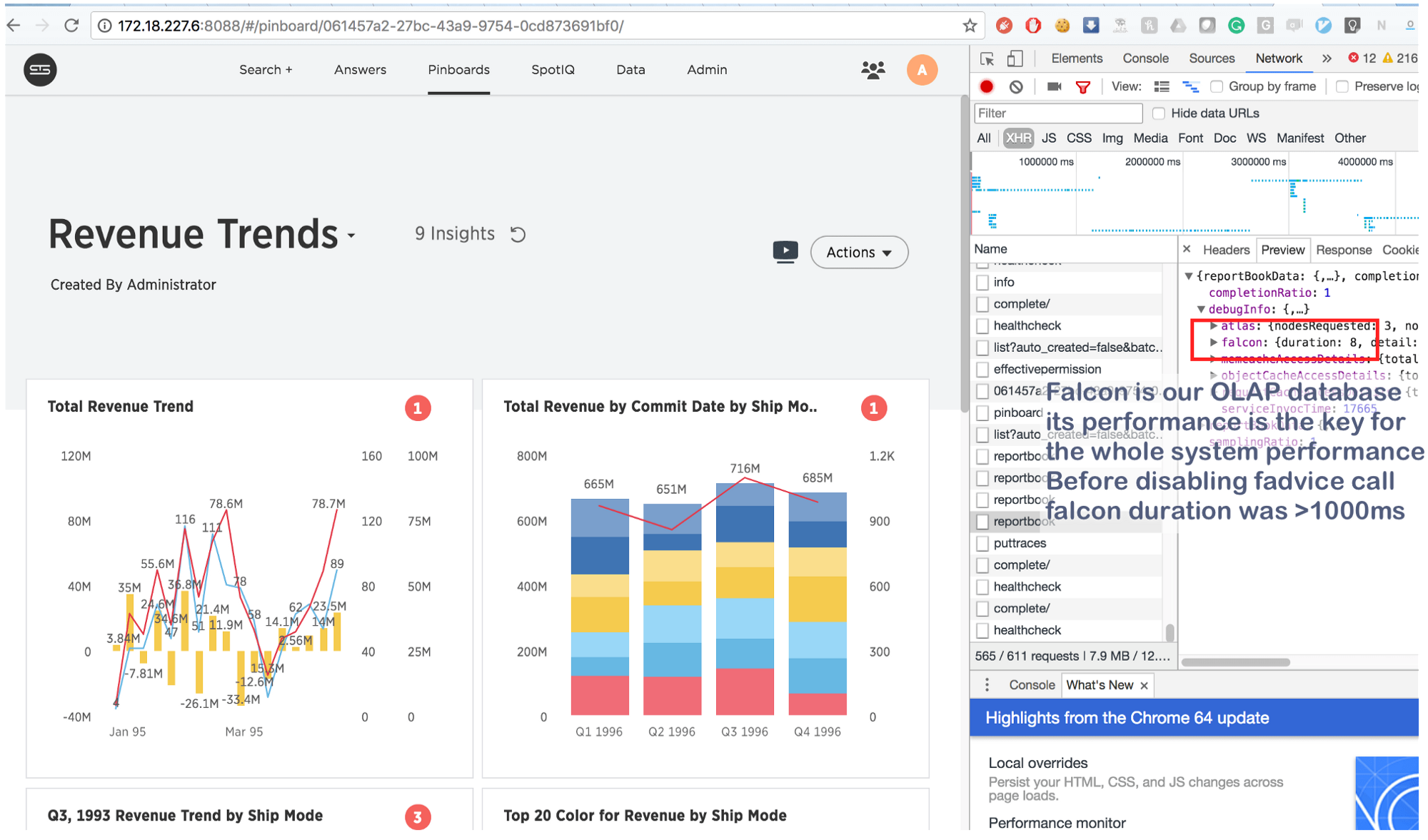
Apa yang digunakan untuk mengambil beberapa detik sekarang dilakukan dalam 8 (delapan!) Milidetik. Sedikit googling, kami menemukan ini: https://issues.apache.org/jira/browse/MESOS-920 dan juga ini: https://github.com/google/glog/pull/145 , yang sekali lagi dikonfirmasi firasat kami tentang penyebab sebenarnya dari penghambatan. Kemungkinan besar, hal yang sama terjadi pada mesin virtual / bare metal, tetapi karena kami memiliki 1 salinan proses untuk setiap mesin / inti, intensitas panggilan mode secara signifikan lebih rendah, yang menjelaskan kurangnya konsumsi sumber daya tambahan. Meningkatkan proses logging sebanyak 3-4 kali dan menyoroti satu inti umum untuk mereka, kami melihat bahwa itu benar-benar macet.
Dan sebagai kesimpulan:
Informasi ini bukan hal baru, tetapi untuk beberapa alasan banyak orang lupa hal utama: dalam kasus dengan wadah, proses "terisolasi" bersaing untuk semua sumber daya inti , dan tidak hanya untuk CPU , RAM , ruang disk dan jaringan . Dan karena kernel adalah struktur yang sangat kompleks, crash dapat terjadi di mana saja (seperti, misalnya, dalam __d_lookup_loop dari artikel Sysdig ). Namun, ini tidak berarti bahwa kontainer lebih buruk atau lebih baik daripada virtualisasi tradisional. Mereka adalah alat yang luar biasa yang menyelesaikan tugas mereka. Ingat saja: kernel adalah sumber daya bersama, dan bersiaplah untuk men-debug konflik yang tidak terduga dalam ruang kernel. Selain itu, konflik semacam itu merupakan peluang besar bagi penyerang untuk menembus isolasi "menipis" dan membuat saluran tersembunyi di antara kontainer. Dan akhirnya, ada perf - alat yang sangat baik yang akan menunjukkan apa yang terjadi dalam sistem dan membantu men-debug setiap masalah kinerja. Jika Anda berencana untuk menjalankan aplikasi yang sangat dimuat di Docker, pastikan untuk meluangkan waktu untuk mempelajari perf .