bab sebelumnya
Kurva belajar
28 Mendiagnosis Bias dan Menyebarkan: Kurva Belajar
Kami memeriksa beberapa pendekatan untuk pemisahan kesalahan menjadi bias dan pencar yang dapat dihindari. Kami melakukan ini dengan mengevaluasi proporsi kesalahan optimal, menghitung kesalahan pada sampel pelatihan dari algoritma dan pada sampel validasi. Mari kita bahas pendekatan yang lebih informatif: belajar grafik kurva.
Grafik dari kurva pembelajaran adalah ketergantungan dari bagian kesalahan pada jumlah contoh sampel pelatihan.
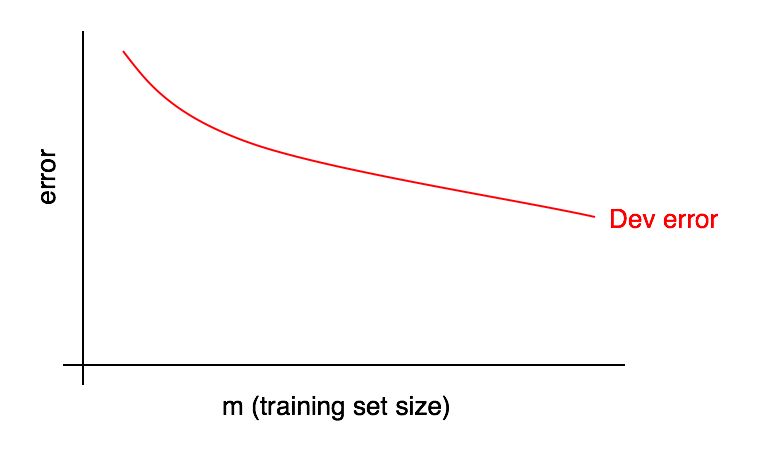
Ketika ukuran sampel pelatihan meningkat, kesalahan dalam sampel validasi akan berkurang.
Kami akan sering fokus pada beberapa "bagian kesalahan yang diinginkan" yang kami harap pada akhirnya akan mencapai algoritma kami. Sebagai contoh:
- Jika kita berharap untuk mencapai tingkat kualitas yang dapat diakses manusia, maka bagian kesalahan manusia harus menjadi "bagian kesalahan yang diinginkan"
- Jika algoritme pembelajaran digunakan dalam beberapa produk (seperti penyedia gambar-kucing), kami mungkin memiliki pemahaman tentang tingkat kualitas apa yang perlu Anda capai sehingga pengguna mendapatkan manfaat maksimal
- Jika Anda telah mengerjakan aplikasi penting untuk waktu yang lama, Anda mungkin memiliki pemahaman yang masuk akal tentang kemajuan apa yang dapat Anda buat pada kuartal / tahun berikutnya.
Tambahkan tingkat kualitas yang diinginkan ke kurva pembelajaran kami:

Anda dapat memperkirakan secara visual kurva kesalahan merah dalam sampel validasi dan mengasumsikan seberapa dekat Anda dengan tingkat kualitas yang diinginkan dengan menambahkan lebih banyak data. Pada contoh yang ditunjukkan pada gambar, sepertinya menggandakan ukuran sampel pelatihan akan mencapai tingkat kualitas yang diinginkan.
Namun, jika kurva fraksi kesalahan sampel validasi telah mencapai dataran tinggi (mis., Telah berubah menjadi garis lurus sejajar dengan sumbu absis), segera mengindikasikan bahwa menambahkan data tambahan tidak akan membantu mencapai tujuan:
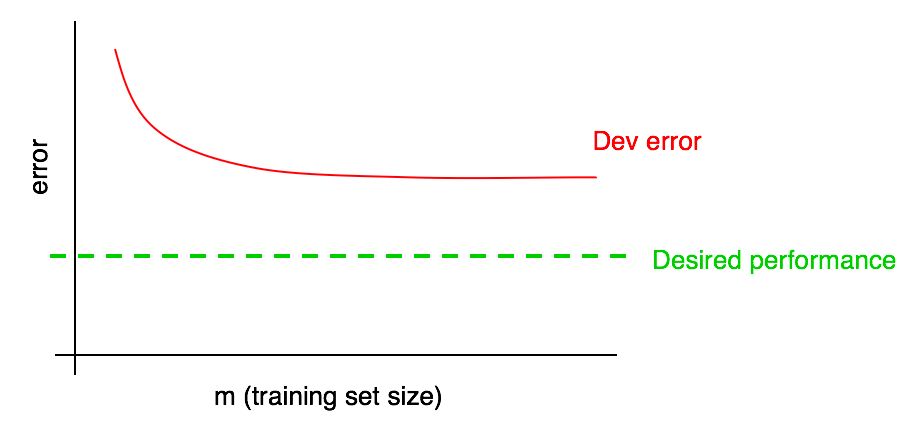
Melihat kurva pembelajaran dengan demikian dapat membantu Anda menghindari menghabiskan waktu berbulan-bulan mengumpulkan data pelatihan dua kali lebih banyak hanya untuk menyadari bahwa menambahkannya tidak membantu.
Salah satu kelemahan dari pendekatan ini adalah bahwa jika Anda hanya melihat kurva kesalahan dalam sampel validasi, mungkin sulit untuk memperkirakan dan memperkirakan secara akurat bagaimana perilaku kurva merah jika Anda menambahkan lebih banyak data. Oleh karena itu, ada grafik tambahan lain yang dapat membantu menilai dampak data pelatihan tambahan pada proporsi kesalahan: kesalahan belajar.
29 Jadwal kesalahan belajar
Kesalahan dalam validasi (dan uji) sampel harus berkurang dengan meningkatnya sampel pelatihan. Namun dalam sampel pelatihan, kesalahan dalam menambahkan data biasanya tumbuh.
Mari kita ilustrasikan efek ini dengan sebuah contoh. Misalkan sampel pelatihan Anda hanya terdiri dari 2 contoh: Satu gambar dengan kucing dan satu tanpa kucing. Dalam hal ini, algoritma pembelajaran dapat dengan mudah mengingat kedua contoh sampel pelatihan dan menunjukkan 0% kesalahan pada sampel pelatihan. Bahkan jika kedua contoh pelatihan diberi label yang salah, algoritme akan dengan mudah mengingat kelas mereka.
Sekarang bayangkan bahwa set pelatihan Anda terdiri dari 100 contoh. Misalkan sejumlah contoh diklasifikasikan secara salah, atau tidak mungkin untuk membuat kelas dalam beberapa contoh, misalnya, dalam gambar buram, ketika bahkan seseorang tidak dapat menentukan apakah kucing hadir dalam gambar atau tidak. Misalkan algoritma pembelajaran masih "mengingat" sebagian besar contoh sampel pelatihan, tetapi sekarang lebih sulit untuk mendapatkan akurasi 100%. Meningkatkan sampel pelatihan dari 2 hingga 100 contoh, Anda akan menemukan bahwa keakuratan algoritma dalam sampel pelatihan akan berkurang secara bertahap.
Pada akhirnya, anggap set pelatihan Anda terdiri dari 10.000 contoh. Dalam hal ini, menjadi semakin sulit bagi algoritma untuk secara ideal mengklasifikasikan semua contoh, terutama jika set pelatihan berisi gambar buram dan kesalahan klasifikasi. Dengan demikian, algoritma Anda akan bekerja lebih buruk pada sampel pelatihan seperti itu.
Mari kita tambahkan grafik kesalahan belajar ke yang sebelumnya.
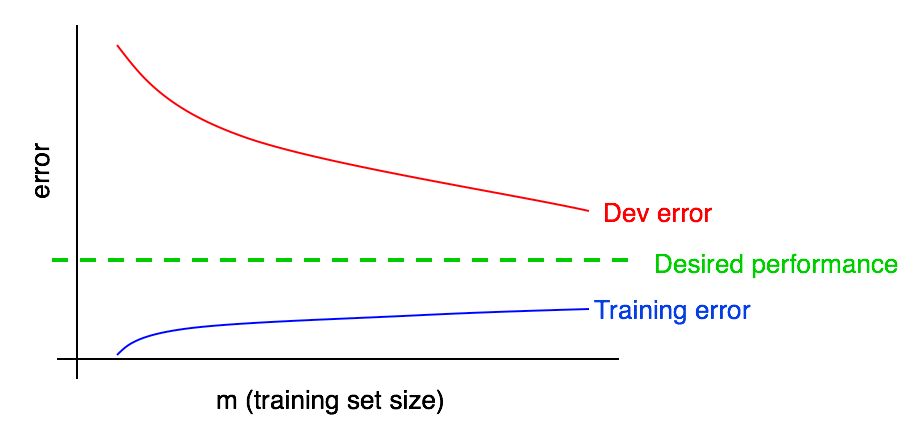
Anda dapat melihat bahwa kurva "Kesalahan Pembelajaran" biru tumbuh dengan peningkatan sampel pelatihan. Selain itu, algoritma pembelajaran biasanya menunjukkan kualitas yang lebih baik dalam sampel pelatihan daripada yang validasi; dengan demikian, kurva kesalahan merah dalam sampel validasi terletak tepat di atas kurva kesalahan biru dalam sampel pelatihan.
Selanjutnya, mari kita bahas bagaimana menafsirkan grafik ini.
kelanjutan