Ada kelas tugas yang begitu populer di mana perlu untuk melakukan analisis yang cukup mendalam tentang seluruh volume rantai pekerjaan yang direkam oleh sistem informasi (IS). Sebagai IP, bisa ada aliran dokumen, meja layanan, pelacak bug, jurnal elektronik, akuntansi gudang, dll. Nuansa tersebut dimanifestasikan dalam model data, API, volume data, dan aspek lainnya, tetapi prinsip-prinsip untuk menyelesaikan masalah tersebut kira-kira sama. Dan garu yang bisa Anda injak juga sangat mirip.
Untuk mengatasi kelas masalah ini, R sangat cocok. Tetapi, agar tidak mengangkat bahu secara mengecewakan, bahwa R mungkin baik, tetapi oh, sangat lambat, penting untuk memperhatikan kinerja metode pemrosesan data yang dipilih.
Ini adalah kelanjutan dari publikasi sebelumnya .
Biasanya, pendekatan "dahi" yang dangkal bukanlah yang paling efektif. 99% tugas yang terkait dengan analisis dan pemrosesan data dimulai dengan impornya. Dalam esai singkat ini, kami akan mempertimbangkan masalah yang muncul pada tahap dasar mengimpor data dengan data dalam format json , menggunakan contoh tugas khas analisis "dalam" data instalasi Jira. json mendukung model objek yang kompleks, tidak seperti csv , jadi menguraikannya dalam kasus struktur yang kompleks bisa menjadi sangat sulit dan panjang.
Pernyataan masalah
Diberikan:
- jira diimplementasikan dan digunakan dalam proses pengembangan perangkat lunak sebagai sistem manajemen tugas dan pelacak bug.
- Tidak ada akses langsung ke database jira, interaksi adalah melalui API REST (isolasi galvanik).
- File json yang akan diambil memiliki struktur pohon yang sangat kompleks dengan tuple bersarang yang diperlukan untuk mengunggah seluruh riwayat tindakan. Perhitungan metrik membutuhkan sejumlah kecil parameter yang tersebar di berbagai tingkatan hierarki.
Contoh jira json biasa pada gambar.
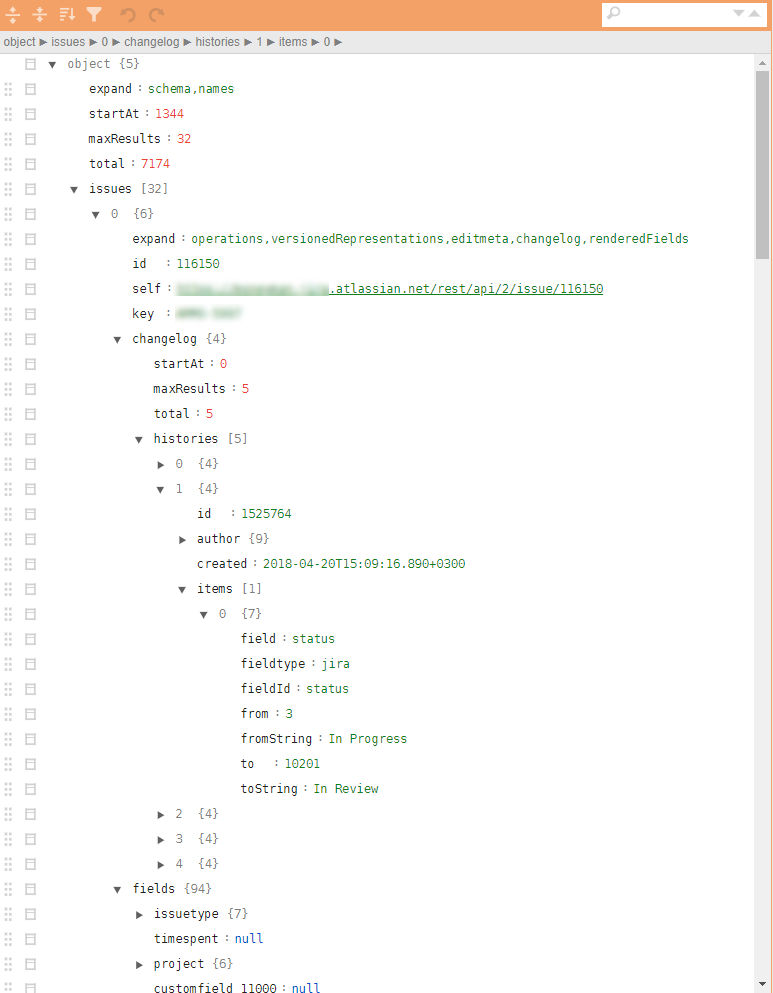
Diperlukan:
- Berdasarkan data jira, perlu untuk menemukan hambatan dan poin dari kemungkinan peningkatan efisiensi proses pengembangan dan meningkatkan kualitas produk yang dihasilkan berdasarkan analisis dari semua tindakan yang terdaftar.
Solusi
Secara teoritis, ada beberapa paket berbeda di R untuk memuat json dan mengubahnya menjadi data.frame . Paket paling mudah adalah jsonlite . Namun, konversi langsung dari hierarki json ke data.frame sulit karena bersarang multi-level dan parameterisasi yang kuat dari struktur rekaman. Mencengkeram parameter tertentu yang terkait, misalnya, dengan riwayat tindakan, mungkin memerlukan berbagai ekstensi. cek dan loop. Yaitu masalah dapat diselesaikan, tetapi untuk file json dari 32 tugas (termasuk semua artefak dan seluruh sejarah tugas) analisis non-linear seperti menggunakan jsonlite dan tidyverse membutuhkan ~ 10 detik pada laptop kinerja rata-rata.
10 detik saja tidak banyak. Namun tepatnya hingga saat ketika tidak ada terlalu banyak file-file ini. Evaluasi sampel parsing dan pemuatan menggunakan metode "langsung" yang sama ~ 4000 file (~ 4 GB) memberi 8-9 jam kerja.
Sejumlah besar file muncul karena suatu alasan. Pertama, jira memiliki batas waktu untuk sesi REST, tidak mungkin untuk menarik semuanya dengan balok. Kedua, sedang dibangun ke dalam sirkuit produktif, pengunggahan harian data tentang tugas-tugas yang diperbarui diharapkan. Ketiga, dan ini akan disebutkan di bawah, tugas ini sangat baik untuk penskalaan linier dan Anda perlu memikirkan paralelisasi dari langkah pertama.
Bahkan 10-15 iterasi pada tahap analisis data, mengidentifikasi set minimum parameter yang diperlukan, mendeteksi situasi yang luar biasa atau salah, dan mengembangkan algoritma postprocessing memberikan biaya dalam jumlah 2-3 minggu (hanya menghitung waktu).
Secara alami, "kinerja" seperti itu tidak cocok untuk analitik operasional, yang dibangun ke dalam sirkuit produktif, dan sangat tidak efektif pada tahap analisis data awal dan pengembangan prototipe.
Melewati semua detail perantara, saya segera beralih ke jawabannya. Kami mengingat Donald Knuth, menyingsingkan lengan baju kami dan mulai microbenching semua operasi utama, tanpa ampun memotong segala sesuatu yang mungkin.
Solusi yang dihasilkan dikurangi menjadi 10 baris berikut (ini adalah kerangka palsu, tanpa body kit non-fungsional berikutnya):
library(tidyverse) library(jsonlite) library(readtext) fnames <- fs::dir_ls(here::here("input_data"), glob = "*.txt") ff <- function(fname){ json_vec <- readtext(fname, text_field = "texts", encoding = "UTF-8") %>% .$text %>% jqr::jq('[. | {issues: .issues}[] | .[]', '{id: .id, key: .key, created: .fields.created, type: .fields.issuetype.name, summary: .fields.summary, descr: .fields.description}]') jsonlite::fromJSON(json_vec, flatten = TRUE) } tictoc::tic("Loading with jqr-jsonlite single-threaded technique") issues_df <- fnames %>% purrr::map(ff) %>% data.table::rbindlist(use.names = FALSE) tictoc::toc() system.time({fst::write_fst(issues_df, here::here("data", "issues.fst"))})
Apa yang menarik di sini?
- Untuk mempercepat proses pemuatan, sebaiknya gunakan paket khusus yang diprofilkan, seperti
readtext . - Menggunakan parser streaming
jq memungkinkan jq untuk menerjemahkan semua pengait atribut yang diperlukan ke dalam bahasa fungsional, menurunkannya ke level CPP dan meminimalkan manipulasi manual daftar bersarang atau daftar dalam data.frame . - Paket
bench sangat menjanjikan untuk microbenchmarks telah muncul. Ini memungkinkan Anda untuk mempelajari tidak hanya waktu pelaksanaan operasi, tetapi juga manipulasi memori. Bukan rahasia lagi bahwa Anda bisa kehilangan banyak dalam menyalin data dalam memori. - Untuk sejumlah besar data dan pemrosesan sederhana, sering kali perlu dalam keputusan akhir untuk meninggalkan
tidyverse dan mentransfer komponen yang menghabiskan waktu ke data.table . data.table , khususnya, tabel digabung di sini menggunakan data.table . Dan juga semua transformasi pada tahap postprocessing (yang termasuk dalam siklus melalui fungsi ff juga dibuat menggunakan data.table alat dengan pendekatan mengubah data dengan referensi, atau paket yang dibangun menggunakan Rcpp , misalnya, paket anytime untuk bekerja dengan tanggal dan waktu. - Paket pertama sangat baik untuk membuang data ke file dan kemudian membacanya. Secara khusus, hanya perlu sepersekian detik untuk menyimpan semua analisis riwayat jira selama 4 tahun, dan data disimpan persis seperti tipe data R, yang baik untuk digunakan kembali berikutnya.
Selama solusi, pendekatan menggunakan paket rjson . Opsi jsonlite::fromJSON sekitar 2 kali lebih lambat daripada rjson = rjson::fromJSON(json_vec) , tetapi itu perlu untuk meninggalkannya, karena ada nilai NULL dalam data, dan pada tahap konversi NULL ke NA dalam daftar yang rjson oleh rjson kita kehilangan keuntungan, dan kode semakin berat.
Kesimpulan
- Refactoring tersebut menyebabkan perubahan dalam waktu pemrosesan semua file json dalam mode single-threaded pada laptop yang sama dari 8-9 jam menjadi 10 menit.
- Menambahkan paralelisasi tugas menggunakan
foreach praktis tidak membebani kode (+ 5 baris) tetapi mengurangi waktu eksekusi menjadi 5 menit. - Mentransfer solusi ke server linux yang lemah (hanya 4 core), tetapi berjalan pada SSD dalam mode multi-threaded mengurangi waktu eksekusi menjadi 40 detik.
- Publikasi pada sirkuit yang produktif (20 core, 3 GHz, SSD) telah mengurangi waktu eksekusi menjadi 6-8 detik, yang lebih dari cukup untuk tugas analitik operasional.
Secara total, tetap dalam kerangka platform R, refactoring kode sederhana berhasil mengurangi waktu eksekusi dari ~ 9 jam menjadi ~ 9 detik.
Keputusan tentang R bisa sangat cepat. Jika sesuatu tidak berhasil untuk Anda, coba lihat dari sudut yang berbeda dan gunakan teknik baru.
Publikasi sebelumnya - “Parasut Analitik untuk Manajer” .