Pada bagian pertama, kami membiasakan diri dengan metode adaptasi domain melalui pembelajaran yang mendalam. Kami berbicara tentang dataset utama, serta pendekatan non-generatif berbasis perbedaan dan permusuhan. Metode-metode ini bekerja dengan baik untuk beberapa tugas. Dan kali ini kami akan menganalisis metode berbasis permusuhan yang paling kompleks dan menjanjikan: model generatif, serta algoritma yang menunjukkan hasil terbaik pada set data VisDA (adaptasi dari data sintetik ke foto nyata).

Model generatif
Dasar dari pendekatan ini adalah kemampuan GAN untuk menghasilkan data dari distribusi yang diperlukan. Berkat properti ini, Anda bisa mendapatkan jumlah data sintetik yang tepat dan menggunakannya untuk pelatihan. Gagasan utama metode dari keluarga model generatif adalah untuk menghasilkan data menggunakan domain sumber yang semirip mungkin dengan perwakilan dari domain target. Dengan demikian, data sintetis baru akan memiliki label yang sama dengan perwakilan dari domain asli atas dasar mana mereka diperoleh. Kemudian model untuk domain target hanya dilatih tentang data yang dihasilkan ini.
Diperkenalkan di ICML-2018, metode CyCADA: Cycle-Consistent Adversarial Domain Adaptation ( code ) adalah anggota perwakilan dari keluarga model generatif. Ini menggabungkan beberapa pendekatan yang berhasil dari GAN dan adaptasi domain. Bagian penting dari ini adalah penggunaan kehilangan konsistensi siklus, pertama kali diperkenalkan dalam artikel tentang CycleGAN . Gagasan kehilangan siklus-konsistensi adalah bahwa gambar yang diperoleh dengan menghasilkan dari sumber ke domain target, diikuti oleh transformasi terbalik, harus dekat dengan gambar awal. Selain itu, CyCADA mencakup adaptasi pada tingkat piksel dan pada tingkat representasi vektor, serta kehilangan semantik untuk menyimpan struktur dalam gambar yang dihasilkan.
Biarkan fT dan fS - jaringan untuk domain target dan sumber, masing-masing, XT dan XS - domain target dan sumber, YS - markup di domain sumber, GS−>T dan GT−>S - generator dari sumber ke domain target dan sebaliknya, DT dan DS - diskriminator yang menjadi milik domain target dan sumber, masing-masing. Kemudian fungsi kerugian, yang diminimalkan dalam CyCADA, adalah jumlah dari enam fungsi kerugian (skema pelatihan dengan nomor kerugian disajikan di bawah):
- Ltask(fT,GS−>T(XS),YS) - klasifikasi model fT pada data yang dihasilkan dan pseudo-label dari domain sumber.
- LGAN(GS−>T,DT,XT,XS) - Kehilangan permusuhan untuk pelatihan generator GS−>T .
- LGAN(GT−>S,DS,XS,XT) - Kehilangan permusuhan untuk pelatihan generator GT−>S .
- Lcyc(GS−>T,GT−>S,XS,XT) (Kehilangan siklus-konsistensi) - L1 -loss, memastikan bahwa gambar diperoleh dari GS−>T dan GT−>S akan dekat.
- LGAN(fT,Dfeat,fS(GS−>T(XS)),XT) - Kehilangan permusuhan untuk representasi vektor fT dan fS pada data yang dihasilkan (mirip dengan apa yang digunakan dalam ADDA).
- Lsem(GS−>T,GT−>S,XS,XT,fS) (kehilangan konsistensi semantik) - L1 kerugian, bertanggung jawab atas kenyataan itu fS juga akan bekerja seperti pada gambar yang diperoleh dari GS−>T keduanya dari GT−>S .
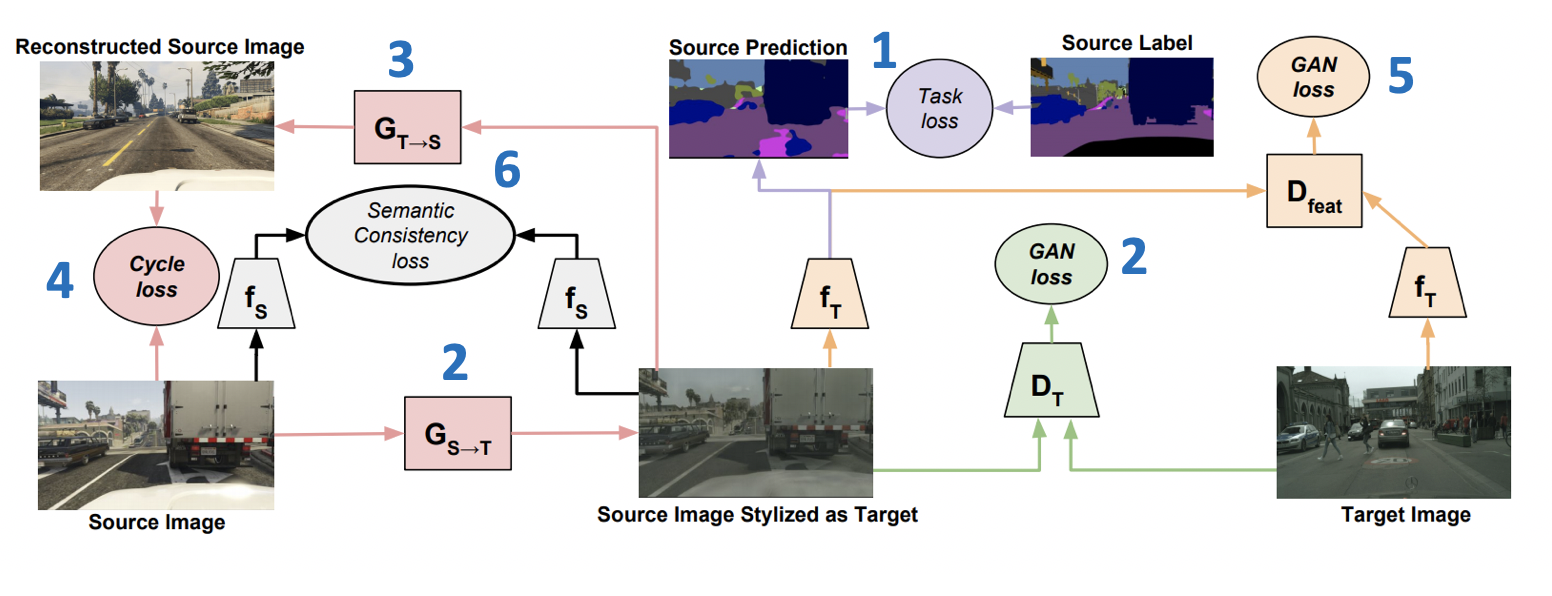
Hasil CyCADA:
- Pada sepasang domain digital USPS -> MNIST: 95,7%.
- Pada tugas segmentasi GTA 5 -> Cityscapes: Mean IoU = 39,5%.
Sebagai bagian dari pendekatan, Generate To Adapt: Aligning Domains menggunakan Generative Adversarial Networks ( kode ) melatih generator tersebut G sehingga pada output itu menghasilkan gambar yang dekat dengan domain asli. Seperti itu G memungkinkan Anda untuk mengonversi data dari domain target dan menerapkan classifier yang terlatih pada data mark-up domain sumber ke mereka.
Untuk melatih generator seperti itu, penulis menggunakan pembeda yang dimodifikasi D dari artikel AC-GAN . Fitur ini D terletak pada fakta bahwa ia tidak hanya menjawab 1 jika input berasal dari domain sumber, dan 0 sebaliknya, tetapi juga dalam kasus jawaban positif ia mengklasifikasikan data input sesuai dengan kelas domain sumber.
Kami menunjukkan F seperti jaringan convolutional yang menghasilkan representasi vektor dari suatu gambar, C - penggolong yang bekerja pada vektor yang berasal dari F . Algoritma pembelajaran dan inferensi:
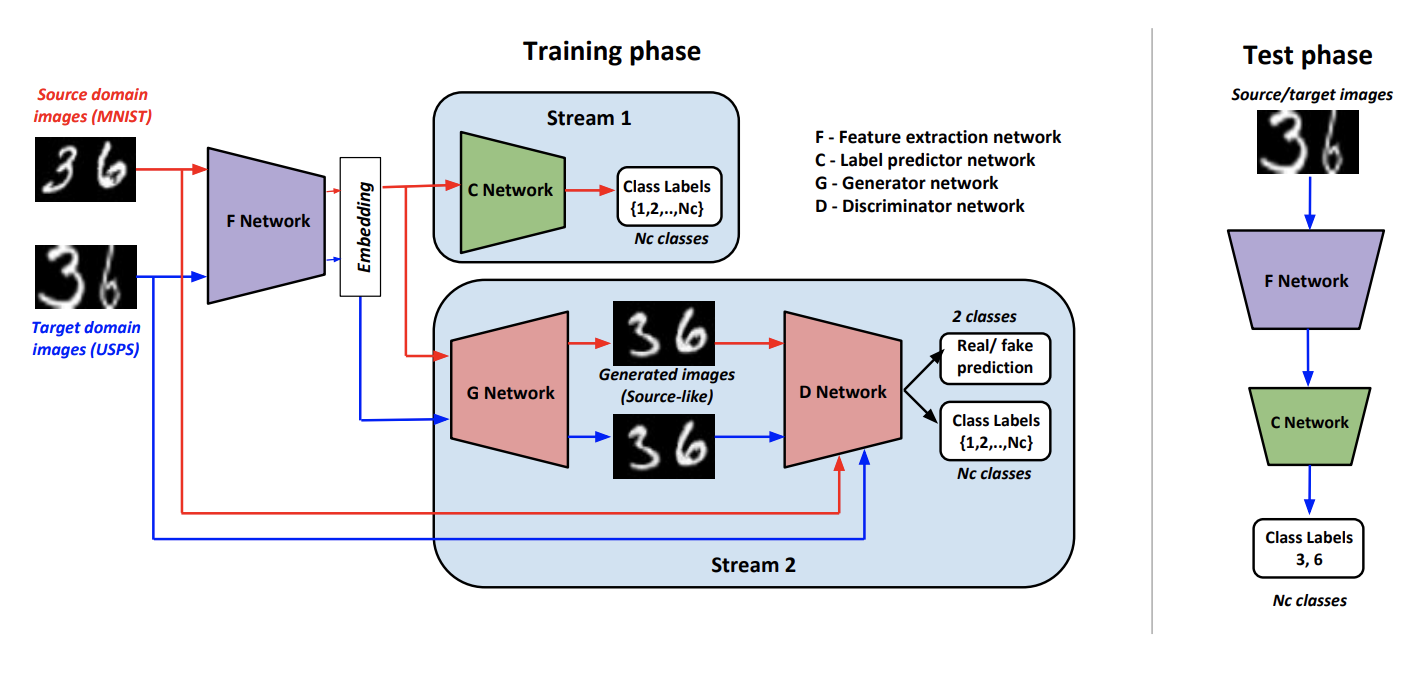
Prosedur pelatihan terdiri dari beberapa komponen:
- Diskriminator D belajar menentukan domain untuk semua yang diterima dari G data, dan untuk domain sumber, kerugian klasifikasi masih ditambahkan, seperti dijelaskan di atas.
- Pada data dari domain sumber G menggunakan kombinasi kerugian kerugian dan kerugian klasifikasi, dilatih untuk menghasilkan hasil yang mirip dengan domain sumber, dan diklasifikasikan dengan benar D .
- F dan C Belajarlah untuk mengklasifikasikan data dari domain sumber. Juga F dengan bantuan kehilangan klasifikasi lain, itu diubah untuk meningkatkan kualitas klasifikasi D .
- Menggunakan kerugian permusuhan F belajar untuk "menipu" D pada data dari domain target.
- Para penulis secara empiris menyimpulkan bahwa sebelum mengirimkan ke G masuk akal untuk menyatukan vektor dari F dengan noise normal dan vektor kelas satu panas ( K+1 untuk data target).
Hasil metode pada tolok ukur:
- Di USPS domain digital -> MNIST: 90,8%.
- Pada dataset Office, kualitas adaptasi rata-rata untuk pasangan domain Amazon dan Webcam adalah 86,5%.
- Pada dataset VisDA, nilai kualitas rata-rata untuk 12 kategori tanpa kelas yang tidak dikenal adalah 76,7%.
Dalam artikel Dari sumber ke target dan kembali: simetris bi-directional adaptif GAN ( kode ), model SBADA-GAN diperkenalkan, yang sangat mirip dengan CyCADA dan yang fungsi sasarannya, seperti CyCADA, terdiri dari 6 komponen. Dalam notasi penulis Gst dan Gts - generator dari domain sumber ke target dan sebaliknya, Ds dan Dt - diskriminator yang membedakan data nyata dari yang dihasilkan di domain sumber dan target, masing-masing, Cs dan Ct - pengklasifikasi yang dilatih tentang data dari domain sumber dan pada versinya diubah menjadi domain target.
SBADA-GAN, seperti CyCADA, menggunakan gagasan CycleGAN, kehilangan konsistensi dan pseudo-label untuk data yang dihasilkan dalam domain target, menyusun fungsi target dari istilah yang sesuai. Fitur SBADA-GAN meliputi:
- Gambar + noise diumpankan ke input ke generator.
- Tes ini menggunakan kombinasi linear prediksi model target dan model sumber berdasarkan transformasi Gst .
Skema Pelatihan SBADA-GAN:
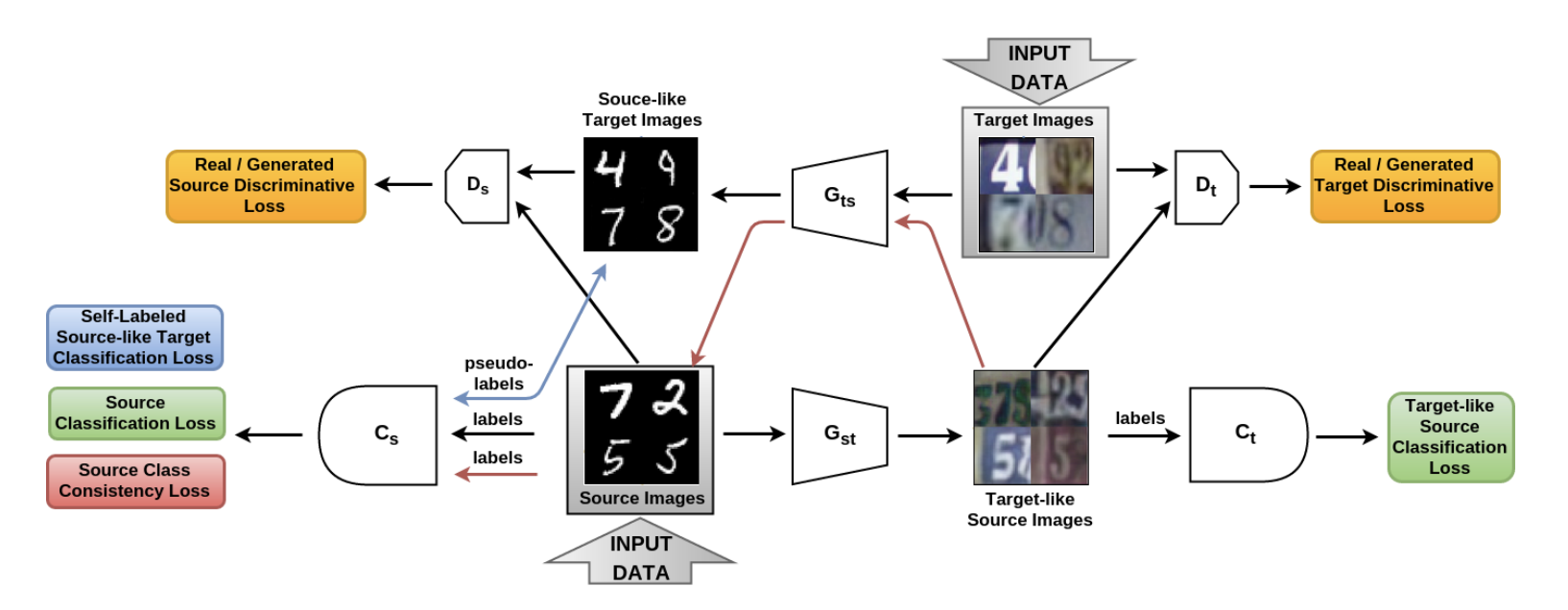
Penulis SBADA-GAN melakukan lebih banyak percobaan daripada penulis CyCADA, dan memperoleh hasil sebagai berikut:
- Pada USPS -> domain MNIST: 95,0%.
- Di MNIST -> domain SVHN: 61.1%.
- Pada rambu-rambu jalan Synth Signs -> GTSRB: 97,7%.
Dari keluarga model generatif, masuk akal untuk mempertimbangkan artikel signifikan berikut:
Tantangan Adaptasi Domain Visual
Sebagai bagian dari lokakarya, konferensi ECCV dan ICCV menjadi tuan rumah kontes adaptasi domain Visual Domain Adaptation Challenge . Di dalamnya, peserta diundang untuk melatih classifier pada data sintetis dan mengadaptasinya ke data yang tidak terisi dari ImageNet.
Algoritme yang disajikan dalam Ensembel mandiri untuk adaptasi domain visual ( kode ) dimenangkan di VisDA-2017. Metode ini didasarkan pada ide self-ensembling: ada jaringan guru (model guru) dan jaringan siswa. Pada setiap iterasi, gambar input dijalankan melalui kedua jaringan ini. Siswa dilatih menggunakan jumlah kehilangan klasifikasi dan kehilangan konsistensi, di mana kehilangan klasifikasi adalah cross-entropy yang biasa dengan label kelas yang terkenal, dan kehilangan konsistensi adalah perbedaan kuadrat rata-rata antara prediksi guru dan siswa (kuadrat perbedaan). Bobot jaringan guru dihitung sebagai rata-rata bergerak eksponensial dari bobot jaringan siswa. Prosedur pelatihan ini diilustrasikan di bawah ini.
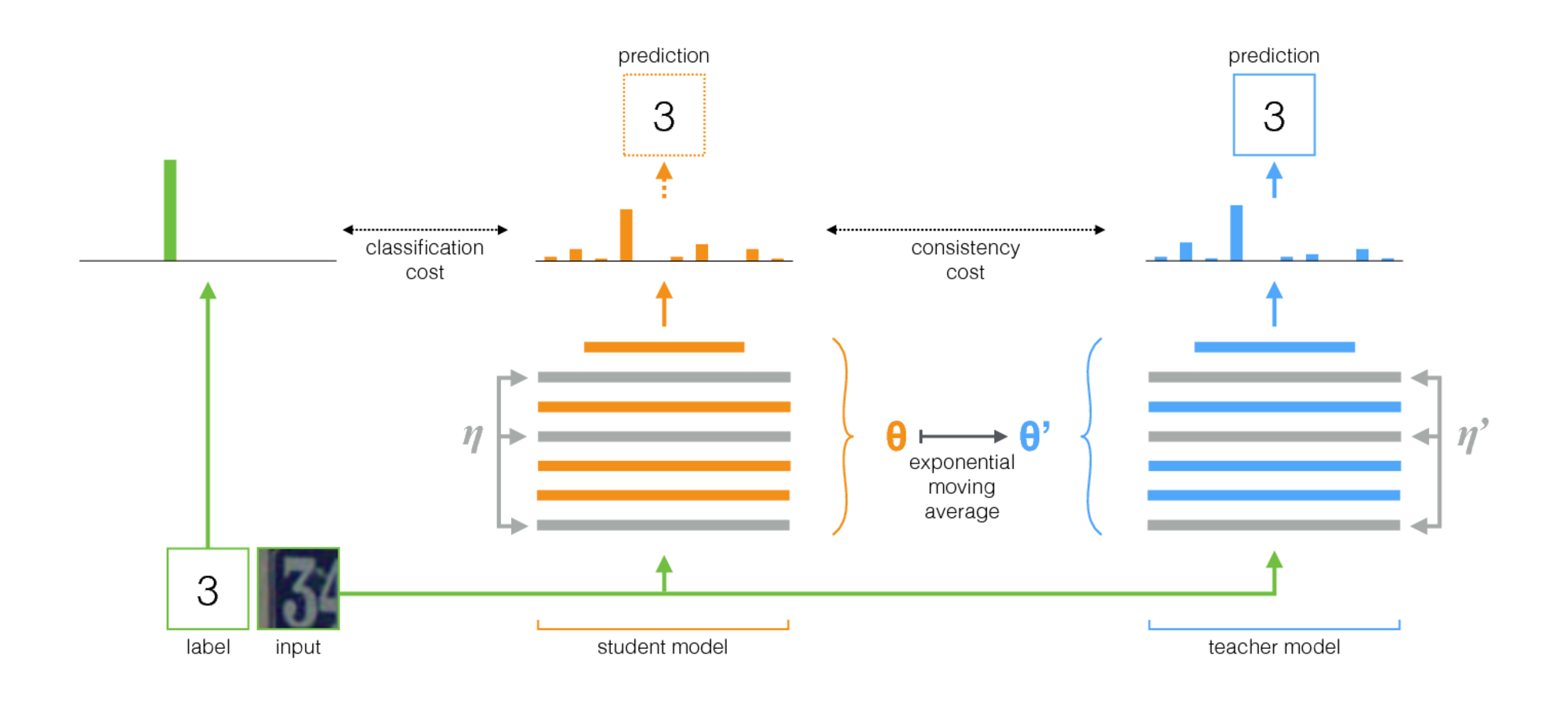
Fitur penting dari penerapan metode ini untuk adaptasi domain adalah:
- Dalam kumpulan pelatihan, data dari domain sumber dicampur xSi dengan label kelas ySi dan data dari domain target xTi tanpa tag.
- Sebelum memasukkan gambar ke jaringan saraf, berbagai penambahan kuat diterapkan: Gaussian noise, transformasi affine, dll.
- Kedua jaringan menggunakan metode regularisasi yang kuat (seperti putus sekolah).
- zTi - output jaringan siswa, widetildezTi - guru jaringan. Jika input berasal dari domain target, maka hanya konsistensi kehilangan antara zTi dan widetildezTi , kehilangan lintas-entropi = 0.
- Untuk keberlanjutan pembelajaran, ambang kepercayaan digunakan: jika prediksi guru kurang dari ambang batas (0,9), maka kehilangan konsistensi hilang = 0.
Skema prosedur yang dijelaskan:

Pada dataset utama, algoritma mencapai kinerja tinggi. Benar, penulis secara terpisah memilih satu set augmentasi untuk setiap tugas.
- USPS -> MNIST: 99,54%.
- MNIST -> SVHN: 97.0%.
- Nomor Synth -> SVHN: 97,11%.
- Pada rambu-rambu jalan Synth Signs -> GTSRB: 99,37%.
- Pada dataset VisDA, nilai kualitas rata-rata untuk 12 kategori tanpa kelas Tidak Diketahui adalah 92,8%. Penting untuk dicatat bahwa hasil ini diperoleh dengan menggunakan ansambel 5 model dan menggunakan augmentasi waktu uji.
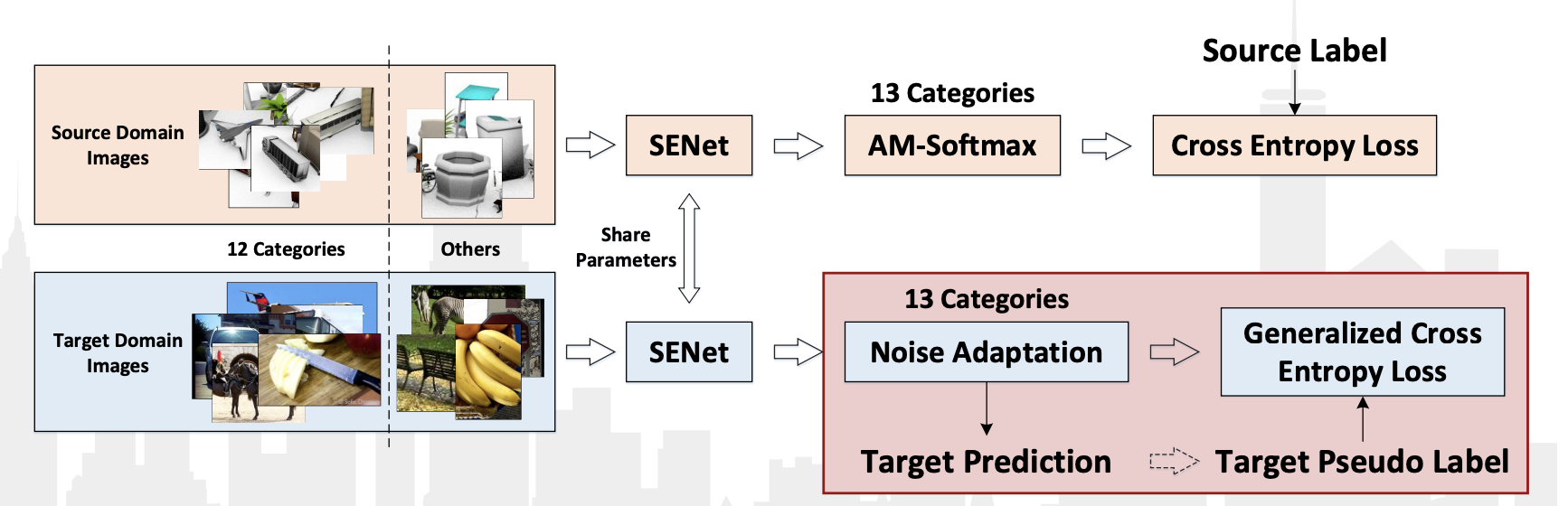
Kompetisi VisDA-2018 diadakan tahun ini sebagai bagian dari konferensi ECCV-2018. Kali ini mereka menambahkan kelas 13: Tidak Diketahui, yang mendapatkan semua yang tidak termasuk dalam 12 kelas. Selain itu, kompetisi terpisah diadakan untuk mendeteksi objek milik 12 kelas ini. Di kedua kategori, tim Cina JD AI Research menang. Pada kontes klasifikasi, mereka mencapai hasil 92,3% (nilai rata-rata kualitas dalam 13 kategori). Tidak ada publikasi dengan deskripsi terperinci tentang metode mereka, hanya ada presentasi dari lokakarya .
Dari fitur-fitur algoritma mereka dapat dicatat:
- Menggunakan pseudo-label untuk data dari domain target dan melatih ulang classifier pada mereka bersama dengan data dari domain sumber.
- Menggunakan jaringan konvolusi SE-ResNeXt-101, lapisan adaptasi AM-Softmax dan Noise, Generalized cross entropy loss untuk data dari domain target.
Diagram algoritma dari presentasi:
Kesimpulan
Sebagian besar, kami telah membahas metode adaptasi berdasarkan pendekatan berbasis permusuhan. Namun, dalam dua kontes VisDA terakhir, algoritma yang tidak terkait dengannya dan menggunakan pelatihan label-pseudo dan modifikasi metode pembelajaran mendalam yang lebih klasik dimenangkan. Menurut pendapat saya, ini karena fakta bahwa metode berdasarkan GAN masih hanya pada awal pengembangan mereka dan sangat tidak stabil. Tetapi setiap tahun kami mendapatkan semakin banyak hasil baru yang meningkatkan kinerja GAN. Selain itu, fokus minat komunitas ilmiah di bidang adaptasi domain terutama difokuskan pada metode berbasis permusuhan, dan artikel baru terutama mempelajari pendekatan ini. Oleh karena itu, ada kemungkinan bahwa algoritma yang terkait dengan GAN secara bertahap akan menjadi yang terdepan dalam masalah adaptasi.
Tetapi penelitian terhadap pendekatan-pendekatan non-permusuhan juga sedang berlangsung. Berikut beberapa artikel menarik dari area ini:
Metode berbasis perbedaan dapat diklasifikasikan sebagai "historis", tetapi banyak ide yang digunakan dalam metode terbaru: MMD, pseudo-label, pembelajaran metrik, dll. Selain itu, kadang-kadang dalam masalah adaptasi sederhana masuk akal untuk menerapkan metode ini karena relatif mudahnya pelatihan dan interpretasi hasil yang lebih baik.
Sebagai kesimpulan, saya ingin mencatat bahwa metode adaptasi domain masih mencari aplikasi mereka di bidang terapan, tetapi tugas prospektif yang membutuhkan penggunaan adaptasi secara bertahap menjadi semakin banyak. Misalnya, adaptasi domain secara aktif digunakan dalam pelatihan modul mobil otonom : karena mahal dan memakan waktu untuk mengumpulkan data nyata di jalan-jalan kota untuk melatih pilot otomatis, mobil otonom menggunakan data sintetik (database SYNTHIA dan GTA 5 menjadi contohnya), khususnya. untuk memecahkan masalah segmentasi dari apa yang "dilihat" kamera dari mobil.
Mendapatkan model berkualitas tinggi berdasarkan pelatihan mendalam di Computer Vision sangat tergantung pada ketersediaan dataset berlabel besar untuk pelatihan. Markup hampir selalu membutuhkan banyak waktu dan uang, yang secara signifikan meningkatkan siklus pengembangan model dan, sebagai hasilnya, produk berdasarkan pada mereka.
Metode adaptasi domain ditujukan untuk memecahkan masalah ini dan berpotensi berkontribusi pada terobosan dalam banyak masalah yang diterapkan dan kecerdasan buatan pada umumnya. Mentransfer pengetahuan dari satu domain ke domain lain adalah tugas yang sangat sulit dan menarik, yang saat ini sedang dipelajari secara aktif. Jika Anda mengalami kekurangan data dalam tugas Anda, dan dapat meniru data atau menemukan domain yang serupa, maka saya sarankan mencoba metode adaptasi domain!