Velocity adalah konferensi yang didedikasikan untuk sistem terdistribusi. Ini diselenggarakan oleh O'Reilly, dan berlangsung tiga kali setahun: sekali di California, sekali di New York dan sekali di Eropa (dan kota berubah setiap tahun).
Pada 2018, konferensi diadakan di London dari 30 Oktober hingga 2 November. Kantor utama Badoo terletak di sana, jadi saya dan kolega saya punya dua alasan untuk pergi ke Velocity.
Alatnya ternyata agak lebih rumit daripada yang saya temui di konferensi Rusia. Selain dua hari presentasi yang biasa, ada dua hari lagi pelatihan, yang dapat diambil secara penuh, sebagian atau tidak sama sekali. Bersama-sama, ini berubah menjadi pencarian serius untuk memilih jenis tiket yang Anda butuhkan.
Dalam ulasan ini, saya akan berbicara tentang laporan dan kelas master yang saya ingat. Saya melampirkan tautan ke materi tambahan ke beberapa laporan. Sebagian, ini adalah bahan yang penulis rujuk, dan sebagian bahan untuk studi lebih lanjut, yang saya temukan sendiri.
Kesan umum dari konferensi: penulis tampil dengan sangat baik (dan sesi-sesi utama adalah seluruh pertunjukan dengan para pembicara menghadirkan dan naik panggung ke musik), tetapi pada saat yang sama saya menemukan beberapa laporan yang jauh dari sudut pandang teknis.
Topik terpanas konferensi ini adalah Kubernetes , yang disebutkan di hampir setiap laporan kedua.
Bekerja dengan jejaring sosial dibangun dengan sangat baik: di akun twitter resmi selama konferensi ada banyak retweet operasional dengan laporan. Ini memungkinkan melihat sekilas apa yang terjadi di kamar lain.
Kelas master
31 Oktober adalah hari ketika tidak ada laporan, tetapi ada enam atau delapan kelas master masing-masing dari tiga jam waktu murni, di mana dua harus dipilih.
PS Dalam aslinya, mereka disebut tutorial, tetapi menurut saya benar menerjemahkannya sebagai "kelas master".
Bootcamp rekayasa yang kacau
Presenter: Ana Medina , Insinyur di GREMLIN | Deskripsi
Lokakarya ini didedikasikan untuk memperkenalkan rekayasa kekacauan. Ana dengan lancar mengatakan apa itu, apa manfaatnya, mendemonstrasikan bagaimana itu dapat digunakan, perangkat lunak apa yang dapat membantu dan bagaimana mulai menggunakannya di suatu perusahaan.
Secara umum, ini adalah pengantar yang bagus untuk pemula, tetapi saya tidak terlalu menyukai bagian praktisnya, yang merupakan penyebaran aplikasi web demo di sekelompok mesin yang menggunakan Kubernetes dan mengacaukan pemantauan dari DataDog . Masalah utama adalah bahwa kami menghabiskan hampir setengah waktu dari kelas master dalam hal ini dan itu hanya perlu untuk bermain dengan skrip meniru berbagai masalah di cluster selama 5-10 menit dan melihat perubahan dalam grafik.
Sepertinya bagi saya bahwa untuk efek yang sama itu cukup untuk memberikan akses ke DataDog yang telah dikonfigurasi sebelumnya dan / atau untuk menunjukkan semuanya dari tempat kejadian, dan kali ini harus dihabiskan, misalnya, pada ulasan yang lebih terperinci dan contoh-contoh menggunakan Chaos Monkey yang sama, yang hanya diceritakan secara harfiah beberapa frasa.


Menarik: pada konferensi ini, pembicara sering menyebut istilah "radius ledakan", yang belum pernah saya lihat sebelumnya. Mereka menetapkan bagian dari sistem yang terpengaruh ketika masalah tertentu terjadi.
Bahan tambahan:
Membangun infrastruktur evolusioner
Presenter: Kief Morris , Konsultan Infrastruktur dan penulis Infrastruktur sebagai kode | Deskripsi
Poin utama dari kelas master dapat direduksi menjadi dua hal:
- Sistem berubah sepanjang waktu, jadi itu normal bahwa infrastruktur juga perlu berubah;
- Setelah infrastruktur berubah, maka Anda perlu memastikan bahwa itu sederhana dan aman, dan ini hanya dapat dicapai dengan otomatisasi.
Bagian utama dari ceritanya dikhususkan untuk otomatisasi perubahan infrastruktur, kemungkinan solusi untuk masalah ini dan menguji perubahan. Saya bukan ahli dalam topik ini, tetapi bagi saya sepertinya dia berbicara dengan sangat percaya diri dan detail (dan sangat cepat).
Poin utama yang saya ingat dari kelas master ini adalah rekomendasi untuk memaksimalkan perbedaan antara lingkungan (produksi, pementasan, dll.) Dari kode ke variabel lingkungan. Ini akan mengurangi kemungkinan kesalahan dalam infrastruktur ketika mengubah lingkungan dan membuatnya lebih dapat diuji.



Laporan
1 dan 2 November adalah hari laporan. Mereka dibagi menjadi dua blok utama: serangkaian tiga atau empat laporan utama singkat yang mengalir dalam satu aliran di pagi hari (dan bagi mereka sebuah aula besar berkumpul dari dua yang lebih kecil) dan laporan tematis yang lebih panjang dalam lima aliran yang mengalir sepanjang hari. . Pada siang hari ada beberapa jeda besar di antara laporan, ketika dimungkinkan untuk berjalan di sekitar pameran dengan tribun mitra konferensi.
Evolusi Backend Runtastic
Simon Lasselsberger (Runtastic GmbH) | Deskripsi dan slide
Salah satu dari beberapa laporan di mana penulis tidak hanya mengatakan bagaimana melakukan sesuatu, tetapi menunjukkan rincian proyek tertentu dan apa yang terjadi padanya.
Pada awalnya, Runtastic memiliki basis data Percona Server yang umum dan sebuah monolith dengan kode yang melayani aplikasi seluler dan sebuah situs. Kemudian mereka mulai menulis di Cassandra (saya tidak ingat mengapa itu ada di dalamnya) bagian dari data yang nilai kunci penyimpanannya cukup. Secara bertahap, basis data menjadi bengkak, dan mereka menambahkan MongoDB, di mana mereka mulai menulis data dari sebagian besar layanan. Seiring waktu, mereka membuat tingkat umum yang melayani permintaan dari aplikasi web dan seluler (sesuatu seperti aplikasi kami, seperti yang saya mengerti).
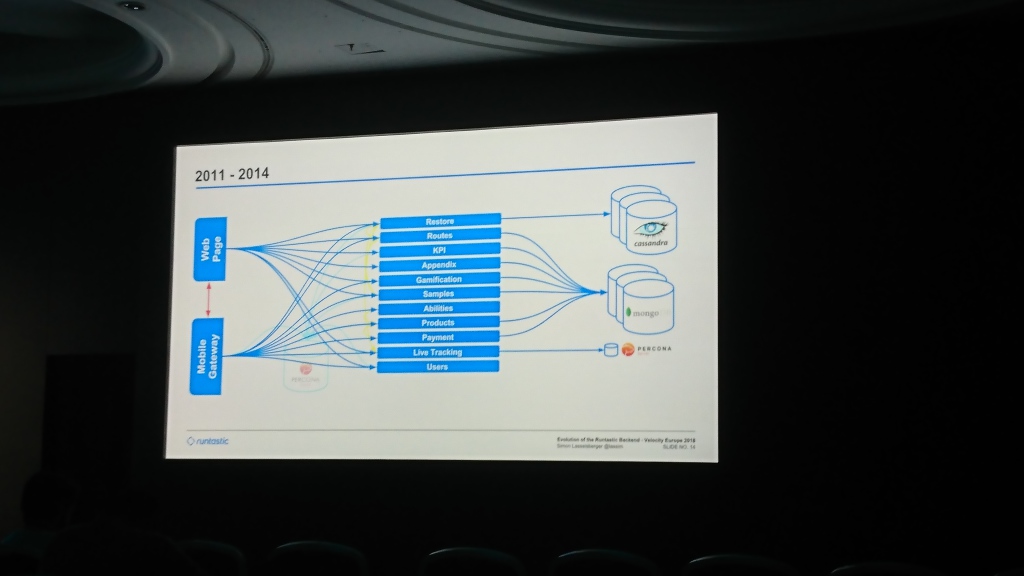
Sebagian besar laporan dikhususkan untuk berpindah antar pusat data. Pada awalnya mereka menyimpan server di Hetzner, yang setelah beberapa waktu dianggap tidak cukup stabil dan data bermigrasi ke T-Systems. Beberapa tahun kemudian, mereka menghadapi kekurangan ruang yang sudah ada di sana dan pindah lagi ke Linz AG. Bagian paling menarik di sini adalah migrasi data. Mereka mulai menyalin data yang berlangsung beberapa bulan. Mereka tidak bisa menunggu terlalu lama karena mereka kehabisan ruang, dan mereka tidak bisa menambahkannya, jadi mereka membuat kesalahan dalam kode, yang mencoba membaca data dari pusat data lama jika itu tidak ada di yang baru.
Di masa depan, mereka berencana untuk membagi data menjadi beberapa pusat data yang terpisah (Simon mengatakan beberapa kali bahwa ini diperlukan untuk Rusia dan China) dan secara kaku membagi basis data dengan layanan terpisah (sekarang kumpulan umum digunakan untuk semua layanan).
Suatu pendekatan yang menarik untuk perancangan modul dalam suatu sistem, yang Simon katakan dengan santai: arsitektur heksagonal .
Mengizinkan aplikasi dikendalikan oleh pengguna, program, tes otomatis atau skrip batch, dan dikembangkan serta diuji secara terpisah dari perangkat run-time dan database yang akhirnya.
Alistair cockburn
Bahan tambahan:
Memantau metrik khusus; atau, Bagaimana saya belajar instrumen dulu dan bertanya nanti
Maxime Petazzoni (SignalFx) | Deskripsi dan presentasi
Kisah ini dikhususkan untuk mengumpulkan metrik yang diperlukan untuk memahami aplikasi. Pesan utama adalah bahwa metrik RED biasa (Nilai, Kesalahan, dan Durasi) sama sekali tidak cukup, dan selain itu, Anda perlu segera mengumpulkan yang lain yang akan membantu untuk memahami apa yang terjadi di dalam aplikasi.
Abstrak, penulis menyarankan untuk mengumpulkan penghitung dan penghitung waktu untuk beberapa tindakan penting dalam sistem (dan tentu saja penghitung kegagalan), membangun grafik dan histogram distribusi dari mereka, menentukan model-meta untuk metrik pengguna (sehingga metrik yang berbeda memiliki serangkaian parameter yang diperlukan sama) dan makna yang sama disebut sama di mana-mana).

Cukup sulit untuk menceritakan kembali detail dalam kata-kata, akan lebih mudah untuk melihat detail dan contoh dalam presentasi, tautan yang ada di halaman laporan di situs web konferensi.
Bahan tambahan:
Bagaimana serverless mengubah departemen TI
Paul Johnston (Bundaran Labs) | Deskripsi dan presentasi
Penulis memperkenalkan dirinya sebagai CTO dan pencinta lingkungan, mengatakan bahwa serverless bukanlah teknologi, tetapi solusi bisnis ("Anda tidak membayar apa-apa jika tidak digunakan"). Kemudian dia menggambarkan praktik terbaik untuk bekerja dengan serverless, kompetensi apa yang diperlukan untuk bekerja dengannya dan bagaimana hal itu memengaruhi pemilihan karyawan baru dan bekerja dengan yang sudah ada.

Momen kunci dari "pengaruh pada departemen TI" yang saya ingat adalah pergeseran kompetensi yang diperlukan dari hanya menulis kode ke bekerja dengan infrastruktur dan otomatisasi ("Lebih banyak" rekayasa "daripada" mengembangkan ") .Semua yang lain cukup dangkal (Anda harus terus melakukan tinjauan kode, untuk mendokumentasikan aliran data dan peristiwa yang tersedia untuk digunakan dalam sistem, untuk berkomunikasi lebih banyak dan belajar dengan cepat), tetapi untuk beberapa alasan penulis menghubungkannya dengan fitur tanpa server.

Secara keseluruhan, laporan itu tampak agak campur aduk. Banyak hal yang dibicarakan oleh pembicara dapat dikaitkan dengan sistem kompleks yang tidak pas di kepala sepenuhnya.
Bahan tambahan:
Jangan panik! Bagaimana cara mengatasinya sekarang Anda bertanggung jawab untuk produksi
Euan Finlay (Financial Times) | Deskripsi dan presentasi
Laporan tentang bagaimana menangani insiden produksi jika terjadi kesalahan saat ini. Poin utama dibagi menjadi beberapa bagian berdasarkan waktu.
Sebelum kejadian:
- bedakan peringatan dengan kritikan - mungkin beberapa orang bisa menunggu, dan Anda tidak perlu menghadapinya dengan mendesak;
- Siapkan rencana untuk menganalisis insiden di muka dan perbarui dokumentasi;
- melakukan latihan - memecahkan sesuatu dan melihat apa yang terjadi (alias chaos engineering);
- Tetapkan satu tempat di mana semua informasi tentang perubahan dan masalah berkelompok.
Selama kejadian:
- itu normal bahwa Anda tidak tahu segalanya - menarik orang lain jika perlu;
- membangun satu tempat untuk komunikasi antara orang yang bekerja pada solusi untuk kejadian tersebut;
- Cari solusi paling sederhana yang akan mengembalikan produksi ke kondisi kerja, dan jangan mencoba menyelesaikan masalah sepenuhnya.
Setelah kejadian:
- mencari tahu mengapa masalah muncul dan apa yang diajarkannya kepada Anda;
- penting untuk menulis laporan tentang ini ("laporan insiden");
- mengidentifikasi apa yang dapat ditingkatkan dan merencanakan tindakan spesifik.
Pada akhirnya, Ewan menceritakan sebuah kisah lucu tentang kejadian di Financial Times, yang muncul karena basis produksi (disebut prod ) secara keliru dimodifikasi daripada pra-produksi ( pprod ), dan menyarankan untuk menghindari nama-nama yang serupa.
Belajar dari web kehidupan (Keynote)
Claire Janisch (BiomimicrySA) | Deskripsi
Saya terlambat untuk laporan ini, tetapi di Twitter mereka berbicara dengan sangat baik tentang hal itu. Anda perlu melihat apakah itu menemukan.
Video dengan fragmen pidato dapat dilihat di situs web konferensi
Jane Adams (Investasi Dua Sigma) | Deskripsi
Laporan filosofis tentang topik "bisakah kita mempercayai algoritma pengambilan keputusan." Kesimpulan umum adalah bahwa tidak ada: algoritma dapat mengoptimalkan metrik tertentu, tetapi pada saat yang sama secara serius mempengaruhi apa yang sulit diukur atau terletak di luar metrik ini (sebagai contoh, ada diskriminasi dalam algoritma untuk mempekerjakan karyawan di Amazon, yang secara negatif mempengaruhi budaya di perusahaan dan terpaksa meninggalkan algoritma ini).
The Freedom of Kubernetes (Keynote)
Kris Nova | Deskripsi
Dari sana saya teringat dua pikiran:
- fleksibilitas bukanlah kebebasan, tetapi kekacauan;
- kompleksitas itu sendiri tidak menjadi masalah jika ia membawa nilai apa pun (dalam aslinya itu disebut "kompleksitas yang diperlukan"), yang melebihi biaya kompleksitas ini.
Laporan ini cukup filosofis, oleh karena itu, di satu sisi, saya tidak bisa mendapatkan banyak dari itu, tetapi di sisi lain, apa yang saya dapatkan berlaku tidak hanya untuk Kubernetes.

Apa yang berubah ketika kita offline dulu? (Keynote)
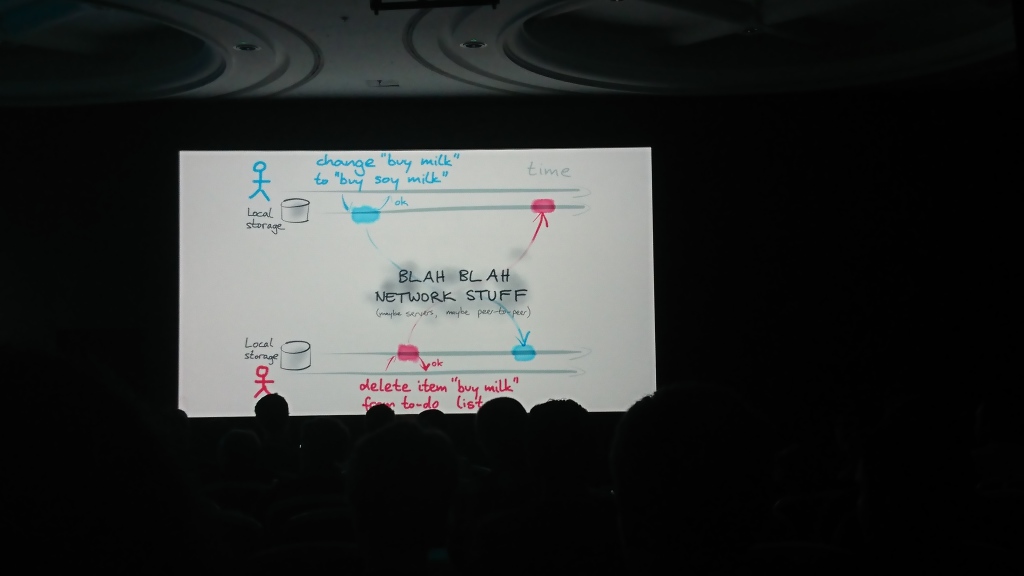
Martin Kleppmann (Universitas Cambridge), penulis Merancang Aplikasi Data-Intensif | Deskripsi
Laporan tersebut terdiri dari dua bagian logis: yang pertama, Martin berbicara tentang masalah sinkronisasi data di antara mereka sendiri, yang dapat bervariasi dalam beberapa sumber secara independen satu sama lain, dan yang kedua, ia berbicara tentang kemungkinan solusi dan algoritma yang dapat digunakan untuk ini ( transformasi operasional , OT , dan tipe data yang direplikasi bebas konflik , CRDT)) dan mengusulkan solusinya - pustaka automerge untuk menyelesaikan masalah tersebut.


Bahan tambahan:
Panduan programmer untuk mengamankan koneksi
Pembicara: Liz Rice | Deskripsi dan slide
Laporan tersebut diadakan dalam bentuk sesi pengkodean langsung, dan di dalamnya Liz menunjukkan cara kerja HTTPS, kesalahan apa yang dapat terjadi ketika bekerja dengan koneksi yang aman dan bagaimana menyelesaikannya. Tidak ada kedalaman yang besar, tetapi demonstrasi itu sendiri sangat bagus.
Paling berguna: slide dengan kesalahan utama ( alias dari laporan Liz di konferensi lain ):

Bahan tambahan:
Semua yang ingin Anda ketahui tentang monorepos tetapi takut untuk bertanya
Simon Stewart (Proyek Selenium) | Deskripsi
Tesis utama dari laporan ini adalah bahwa dalam monorepo jauh lebih mudah untuk mengelola dependensi dalam kode, dan ini mencakup semua keuntungan dari repositori individu. Dia mengimbau fakta bahwa Google dan Microsoft menyimpan data dalam satu repositori (masing-masing berukuran 86 Tb dan 300 Gb), dan repositori Facebook (54 file Gb) menggunakan "off the shell mercurial".
Ruangan itu "meledak" setelah pertanyaan "Siapa yang memiliki lebih banyak repositori di perusahaan daripada karyawan?"
Argumen "dengan repositori besar untuk bekerja lambat" pecah sebagai berikut:
- Anda tidak harus membawa seluruh riwayat perubahan ke mesin lokal: gunakan shadow clone dan checkout jarang ;
- Anda tidak perlu menggunakan semua file dari repositori: mengatur hierarki file dan hanya bekerja dengan direktori yang diperlukan, dan mengecualikan yang lainnya.
Bahan tambahan:
Membangun sistem pemrosesan aliran real-time yang didistribusikan
Amy Boyle (Relik Baru) | Deskripsi dan presentasi
Sebuah cerita bagus tentang bekerja dengan streaming data dari seorang insinyur dari NewRelic (di mana mereka jelas memiliki banyak pengalaman bekerja dengan data tersebut). Amy mengatakan bahwa ini bekerja dengan streaming data, bagaimana data tersebut dapat digabungkan, apa yang dapat dilakukan dengan data yang tertinggal, bagaimana cara membuang stream peristiwa dan bagaimana menyeimbangkannya kembali jika terjadi kegagalan prosesor, apa yang harus dipantau, dll.
Laporan itu banyak materi, saya tidak akan mencoba menceritakannya kembali, tetapi hanya merekomendasikan untuk melihat presentasi itu sendiri (sudah ada di situs konferensi).


Arsitek untuk tv
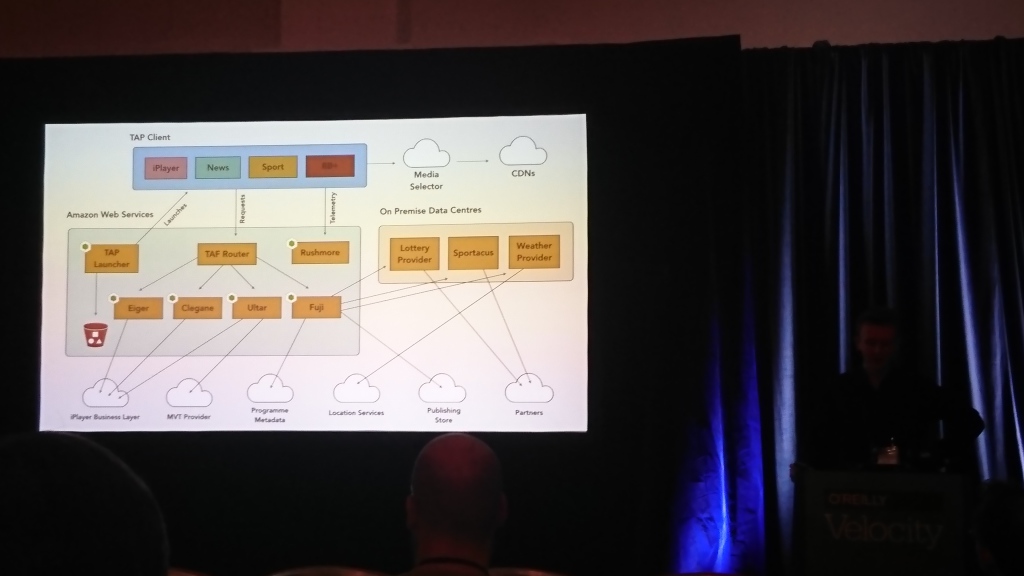
David Buckhurst (BBC), Ross Wilson (BBC) | Deskripsi
Sebagian besar pembicaraan tentang frontend BBC. Orang-orang memiliki televisi interaktif dan banyak televisi dan perangkat lain (komputer, ponsel, tablet) di mana ini harus bekerja Anda perlu bekerja dengan perangkat yang berbeda dengan cara yang sangat berbeda, sehingga mereka datang dengan bahasa berbasis JSON mereka sendiri untuk menggambarkan antarmuka dan menerjemahkannya ke dalam apa yang dapat dipahami oleh perangkat tertentu.
Kesimpulan utama bagi saya adalah bahwa dibandingkan dengan orang-orang TV, aplikasi seluler tidak memiliki masalah dengan pelanggan lama.