Julia adalah salah satu bahasa pemrograman matematika termuda, mengklaim sebagai bahasa pemrograman utama di bidang ini. Sayangnya, saat ini tidak ada cukup literatur dalam bahasa Rusia, dan bahan-bahan yang tersedia dalam bahasa Inggris mengandung informasi yang, karena perkembangan dinamis Julia, tidak selalu sesuai dengan versi saat ini, tetapi ini tidak jelas bagi para programmer pemula Julia. Kami akan mencoba mengisi kekosongan dan menyampaikan ide-ide Julia kepada pembaca dalam bentuk contoh sederhana.
Tujuan artikel ini adalah untuk memberi pembaca ide tentang cara dasar bekerja dengan tabel dalam bahasa pemrograman Julia untuk mendorong mereka mulai menggunakan bahasa pemrograman ini untuk memproses data nyata. Kami berasumsi bahwa pembaca sudah terbiasa dengan bahasa pemrograman lain, jadi kami hanya akan memberikan informasi minimal tentang bagaimana hal ini dilakukan, tetapi kami tidak akan membahas rincian metode pemrosesan data.
Tentu saja, salah satu tahapan terpenting dalam pekerjaan suatu program yang melakukan analisis data adalah impor dan ekspor mereka. Selain itu, format presentasi data yang paling umum adalah tabel. Ada perpustakaan untuk Julia yang menyediakan akses ke DBMS relasional, menggunakan format pertukaran seperti HDF5, MATLAB, JLD. Namun dalam kasus ini, kami hanya akan tertarik pada format teks untuk mewakili tabel, seperti CSV.
Sebelum melihat tabel, Anda perlu membuat pengantar kecil untuk presentasi struktur data ini. Untuk Julia, tabel dapat direpresentasikan sebagai array dua dimensi atau sebagai DataFrame.
Array
Mari kita mulai dengan array di Julia. Penomoran elemen dimulai dengan satu. Ini cukup alami untuk matematikawan, dan di samping itu, skema yang sama digunakan dalam Fortran, Pascal, Matlab. Untuk programmer yang tidak pernah menggunakan bahasa ini, penomoran ini mungkin tampak tidak nyaman dan menyebabkan kesalahan saat menulis kondisi batas, tetapi, pada kenyataannya, ini hanya masalah kebiasaan. Setelah beberapa minggu menggunakan Julia, pertanyaan beralih antar model bahasa tidak lagi muncul.
Poin signifikan kedua dari bahasa ini adalah representasi internal array. Untuk Julia, array linier adalah kolom. Pada saat yang sama, untuk bahasa seperti C, Java, array satu dimensi adalah string.
Kami menggambarkan ini dengan array yang dibuat pada baris perintah (REPL)
julia> a = [1, 2, 3] 3-element Array{Int64,1}: 1 2 3
Perhatikan jenis array - Array {Int64,1}. Array adalah satu dimensi, ketik Int64. Selain itu, jika kita ingin menggabungkan array ini dengan array lain, maka, karena kita berurusan dengan kolom, kita harus menggunakan fungsi vcat (misal: concatenate vertikal). Hasilnya adalah kolom baru.
julia> b = vcat(a, [5, 6, 7]) 7-element Array{Int64,1}: 1 2 3 5 6 7
Jika kita membuat array sebagai string, maka saat menulis literal, kita menggunakan spasi alih-alih koma dan mendapatkan array dua dimensi dari tipe Array {Int64,2}. Argumen kedua dalam deklarasi tipe berarti jumlah koordinat array multidimensi.
julia> c = [1 2 3] 1×3 Array{Int64,2}: 1 2 3
Artinya, kami mendapat matriks dengan satu baris dan tiga kolom.
Presentasi baris dan kolom ini juga merupakan karakteristik Fortran dan Matlab, tetapi, harus diingat bahwa Julia adalah bahasa yang berorientasi khusus pada bidang aplikasi mereka.
Matriks untuk Julia adalah array dua dimensi, di mana semua sel memiliki tipe yang sama. Mari kita perhatikan fakta bahwa jenisnya bisa abstrak Any atau cukup spesifik, seperti Int64, Float64 atau, bahkan, String.
Kita dapat membuat matriks dalam bentuk literal:
julia> a = [1 2; 3 4] 2×2 Array{Int64,2}: 1 2 3 4
Buat menggunakan konstruktor dan alokasikan memori tanpa inisialisasi (undef):
julia> a = Array{Int64,2}(undef, 2, 3) 2×3 Array{Int64,2}: 4783881648 4783881712 4782818640 4783881680 4783881744 4782818576
Atau dengan inisialisasi jika ada nilai spesifik yang ditentukan alih-alih undef.
Lem dari kolom terpisah:
julia> a = [1, 2, 3] 3-element Array{Int64,1}: 1 2 3 julia> b = hcat(a, a, a, a) 3×4 Array{Int64,2}: 1 1 1 1 2 2 2 2 3 3 3 3
Inisialisasi secara acak:
julia> x = rand(1:10, 2, 3) 2×3 Array{Int64,2}: 1 10 2 9 7 7
Argumen rand - berkisar dari 1 hingga 10 dan dimensi 2 x 3.
Atau gunakan inklusi (Pemahaman)
julia> x = [min(i, j) for i = 0:2, j = 0:2 ] 3×3 Array{Int64,2}: 0 0 0 0 1 1 0 1 2
Perhatikan bahwa fakta bahwa untuk Julia kolom adalah blok memori linear mengarah pada fakta bahwa iterasi elemen-elemen dengan kolom akan secara signifikan lebih cepat daripada memilah-milah baris. Secara khusus, contoh berikut menggunakan matriks 1_000_000 baris dan 100 kolom.
#!/usr/bin/env julia using BenchmarkTools x = rand(1:1000, 1_000_000, 100) #x = rand(1_000_000, 100) function sumbycolumns(x) sum = 0 rows, cols = size(x) for j = 1:cols, i = 1:rows sum += x[i, j] end return sum end @show @btime sumbycolumns(x) function sumbyrows(x) sum = 0 rows, cols = size(x) for i = 1:rows, j = 1:cols sum += x[i, j] end return sum end @show @btime sumbyrows(x)
Hasil:
74.378 ms (1 allocation: 16 bytes) =# @btime(sumbycolumns(x)) = 50053093495 206.346 ms (1 allocation: 16 bytes) =# @btime(sumbyrows(x)) = 50053093495
@waktu dalam contoh adalah beberapa kali fungsi untuk menghitung rata-rata waktu yang diperlukan untuk mengeksekusi. Makro ini disediakan oleh perpustakaan BenchmarkTools.jl. Paket dasar Julia memiliki makro waktu , tetapi mengukur interval tunggal, yang, dalam hal ini, akan tidak akurat. Makro acara hanya menampilkan ekspresi dan nilai yang dihitung di konsol.
Optimalisasi penyimpanan kolom nyaman untuk melakukan operasi statistik dengan sebuah tabel. Karena secara tradisional, tabel dibatasi oleh jumlah kolom, dan jumlah baris dapat berupa apa saja, sebagian besar operasi, seperti menghitung rata-rata, minimum, nilai maksimum, dilakukan secara khusus untuk kolom matriks, dan bukan untuk baris mereka.
Sinonim untuk array dua dimensi adalah tipe Matrix. Namun, ini bukan kenyamanan gaya daripada kebutuhan.
Akses ke elemen matriks dilakukan oleh indeks. Misalnya, untuk matriks yang dibuat sebelumnya
julia> x = rand(1:10, 2, 3) 2×3 Array{Int64,2}: 1 10 2 9 7 7
Kita bisa mendapatkan elemen tertentu sebagai x [1, 2] => 10. Jadi dapatkan seluruh kolom, misalnya, kolom kedua:
julia> x[:, 2] 2-element Array{Int64,1}: 10 7
Atau baris kedua:
julia> x[2, :] 3-element Array{Int64,1}: 9 7 7
Ada juga fungsi selectdim yang berguna, di mana Anda dapat menentukan nomor urut dari dimensi yang ingin Anda pilih, serta indeks elemen-elemen dari dimensi ini. Misalnya, buat sampel pada dimensi 2 (kolom) dengan memilih indeks 1 dan 3. Pendekatan ini nyaman ketika, tergantung pada kondisinya, Anda perlu beralih antara baris dan kolom. Namun, ini berlaku untuk kasus multidimensi, ketika jumlah dimensi lebih dari 2.
julia> selectdim(x, 2, [1, 3]) 2×2 view(::Array{Int64,2}, :, [1, 3]) with eltype Int64: 1 2 9 7
Fungsi untuk pemrosesan statistik array
Lebih lanjut tentang array satu dimensi
Array Multidimensi
Fungsi aljabar linier dan matriks dari bentuk khusus
Membaca tabel dari file dapat dilakukan dengan menggunakan fungsi readdlm diimplementasikan di perpustakaan DelimitedFiles. Merekam - menggunakan writedlm. Fungsi-fungsi ini menyediakan pekerjaan dengan file dengan pembatas, kasus khusus di antaranya adalah format CSV.
Kami menggambarkan dengan contoh dari dokumentasi:
julia> using DelimitedFiles julia> x = [1; 2; 3; 4]; julia> y = ["a"; "b"; "c"; "d"]; julia> open("delim_file.txt", "w") do io writedlm(io, [xy]) # end; julia> readdlm("delim_file.txt") # 4×2 Array{Any,2}: 1 "a" 2 "b" 3 "c" 4 "d"
Dalam hal ini, Anda harus memperhatikan fakta bahwa tabel tersebut berisi data dari berbagai jenis. Oleh karena itu, ketika membaca file, sebuah matriks tipe Array {Any, 2} dibuat.
Contoh lain adalah membaca tabel yang berisi data homogen.
julia> using DelimitedFiles julia> x = [1; 2; 3; 4]; julia> y = [5; 6; 7; 8]; julia> open("delim_file.txt", "w") do io writedlm(io, [xy]) # end; julia> readdlm("delim_file.txt", Int64) # Int64 4×2 Array{Int64,2}: 1 5 2 6 3 7 4 8 julia> readdlm("delim_file.txt", Float64) # Float64 4×2 Array{Float64,2}: 1.0 5.0 2.0 6.0 3.0 7.0 4.0 8.0
Dari sudut pandang efisiensi pemrosesan, opsi ini lebih disukai, karena data akan disajikan secara ringkas. Pada saat yang sama, pembatasan eksplisit pada tabel yang diwakili oleh matriks adalah persyaratan untuk keseragaman data.
Kami sarankan untuk melihat fitur readdlm lengkap dalam dokumentasi. Di antara opsi tambahan ada kemampuan untuk menentukan mode pemrosesan header, melewatkan garis, fungsi pemrosesan sel, dll.
Cara alternatif untuk membaca tabel adalah pustaka CSV.jl. Dibandingkan dengan readdlm dan writedlm, pustaka ini memberikan kontrol yang jauh lebih besar atas opsi untuk menulis dan membaca, serta memeriksa data dalam file yang dibatasi. Namun, perbedaan mendasarnya adalah bahwa hasil dari fungsi CSV.File dapat terwujud menjadi tipe DataFrame.
Kerangka data
Pustaka DataFrames menyediakan dukungan untuk struktur data DataFrame, yang difokuskan pada presentasi tabel. Perbedaan mendasar dari matriks di sini adalah bahwa setiap kolom disimpan secara individual, dan setiap kolom memiliki namanya sendiri. Kami ingat bahwa untuk Julia, mode penyimpanan berdasarkan kolom, secara umum, adalah alami. Dan, meskipun di sini kita memiliki kasus khusus array satu dimensi, solusi optimal diperoleh baik dari segi kecepatan dan fleksibilitas representasi data, karena jenis setiap kolom dapat individual.
Mari kita lihat cara membuat DataFrame.
Matriks apa pun dapat dikonversi ke DataFrame.
julia> using DataFrames julia> a = [1 2; 3 4; 5 6] 3×2 Array{Int64,2}: 1 2 3 4 5 6 julia> b = convert(DataFrame, a) 3×2 DataFrame │ Row │ x1 │ x2 │ │ │ Int64 │ Int64 │ ├─────┼───────┼───────┤ │ 1 │ 1 │ 2 │ │ 2 │ 3 │ 4 │ │ 3 │ 5 │ 6 │
Fungsi konversi mengkonversi data ke tipe yang ditentukan. Dengan demikian, untuk tipe DataFrame, metode fungsi konversi didefinisikan di perpustakaan DataFrames (menurut terminologi Julia, ada fungsi, dan variasi implementasinya dengan argumen yang berbeda disebut metode). Perlu dicatat bahwa kolom matriks secara otomatis diberi nama x1, x2. Artinya, jika sekarang kita meminta nama kolom, kita akan mendapatkannya dalam bentuk array:
julia> names(b) 2-element Array{Symbol,1}: :x1 :x2
Dan nama-nama disajikan dalam format seperti Simbol (terkenal di dunia Ruby).
DataFrame dapat dibuat secara langsung - kosong atau berisi beberapa data pada saat konstruksi. Sebagai contoh:
julia> df = DataFrame([collect(1:3), collect(4:6)], [:A, :B]) 3×2 DataFrame │ Row │ A │ B │ │ │ Int64 │ Int64 │ ├─────┼───────┼───────┤ │ 1 │ 1 │ 4 │ │ 2 │ 2 │ 5 │ │ 3 │ 3 │ 6 │
Di sini kami menunjukkan sebuah array dengan nilai kolom dan sebuah array dengan nama-nama kolom ini. Konstruk dari form collect (1: 3) adalah konversi rentang iterator dari 1 menjadi 3 menjadi array nilai.
Akses ke kolom dimungkinkan dengan nama dan indeks mereka.
Sangat mudah untuk menambahkan kolom baru dengan menulis beberapa nilai di semua baris yang ada. Misalnya, df di atas, kami ingin menambahkan kolom Skor. Untuk melakukan ini, kita perlu menulis:
julia> df[:Score] = 0.0 0.0 julia> df 3×3 DataFrame │ Row │ A │ B │ Score │ │ │ Int64 │ Int64 │ Float64 │ ├─────┼───────┼───────┼─────────┤ │ 1 │ 1 │ 4 │ 0.0 │ │ 2 │ 2 │ 5 │ 0.0 │ │ 3 │ 3 │ 6 │ 0.0 │
Seperti halnya dalam kasus matriks sederhana, kita dapat merekatkan instance DataFrame menggunakan fungsi vcat, hcat. Namun, vcat hanya bisa digunakan dengan kolom yang sama di kedua tabel. Anda dapat menyelaraskan DataFrame, misalnya, menggunakan fungsi berikut:
function merge_df(first::DataFrame, second::DataFrame)::DataFrame if (first == nothing) return second else names_first = names(first) names_second = names(second) sub_names = setdiff(names_first, names_second) second[sub_names] = 0 sub_names = setdiff(names_second, names_first) first[sub_names] = 0 vcat(second, first) end end
Fungsi nama di sini mendapatkan larik nama kolom. Fungsi setdiff (s1, s2) dalam contoh mendeteksi semua elemen s1 yang tidak ada di s2. Selanjutnya, perluas DataFrame ke elemen-elemen ini. vcat menempelkan dua DataFrames dan mengembalikan hasilnya. Tidak perlu menggunakan pengembalian dalam hal ini, karena hasil operasi terakhir jelas.
Kami dapat memeriksa hasilnya:
julia> df1 = DataFrame(:A => collect(1:2)) 2×1 DataFrame │ Row │ A │ │ │ Int64 │ ├─────┼───────┤ │ 1 │ 1 │ │ 2 │ 2 │ julia> df2 = DataFrame(:B => collect(3:4)) 2×1 DataFrame │ Row │ B │ │ │ Int64 │ ├─────┼───────┤ │ 1 │ 3 │ │ 2 │ 4 │ julia> df3 = merge_df(df1, df2) 4×2 DataFrame │ Row │ B │ A │ │ │ Int64 │ Int64 │ ├─────┼───────┼───────┤ │ 1 │ 3 │ 0 │ │ 2 │ 4 │ 0 │ │ 3 │ 0 │ 1 │ │ 4 │ 0 │ 2 │
Perhatikan bahwa dalam hal konvensi penamaan di Julia, bukan kebiasaan untuk menggunakan garis bawah, tetapi kemudian keterbacaan menderita. Juga tidak cukup baik dalam implementasi ini adalah bahwa DataFrame asli dimodifikasi. Namun, contoh ini bagus untuk menggambarkan proses menyelaraskan banyak kolom.
Menggabungkan beberapa DataFrames dengan nilai umum dalam kolom dimungkinkan menggunakan fungsi bergabung (misalnya, menempelkan dua tabel dengan kolom yang berbeda dengan pengidentifikasi pengguna umum).
DataFrame nyaman untuk dilihat di konsol. Cara apa pun untuk menghasilkan: menggunakan show macro, menggunakan fungsi println, dll., Akan menghasilkan tabel yang dicetak ke konsol dalam bentuk yang mudah dibaca. Jika DataFrame terlalu besar, garis awal dan akhir akan ditampilkan. Namun, Anda dapat secara eksplisit meminta fungsi kepala dan ekor dengan fungsi kepala dan ekor.
Untuk DataFrame, fungsi pengelompokan data dan agregasi untuk fungsi yang ditentukan tersedia. Ada perbedaan dalam apa yang mereka kembalikan. Ini bisa berupa koleksi dengan DataFrame yang memenuhi kriteria pengelompokan, atau satu DataFrame tunggal di mana nama kolom akan dibentuk dari nama asli dan nama fungsi agregasi. Intinya, skema split-apply-menggabungkan diterapkan. Lihat Detail
Kami akan menggunakan contoh dari dokumentasi dengan tabel contoh yang tersedia sebagai bagian dari paket DataFrames.
julia> using DataFrames, CSV, Statistics julia> iris = CSV.read(joinpath(dirname(pathof(DataFrames)), "../test/data/iris.csv"));
Lakukan pengelompokan menggunakan fungsi groupby. Tentukan nama kolom pengelompokan dan dapatkan hasil dari tipe GroupedDataFrame, yang berisi kumpulan DataFrame individu yang dikumpulkan oleh nilai-nilai kolom pengelompokan.
julia> species = groupby(iris, :Species) GroupedDataFrame with 3 groups based on key: :Species First Group: 50 rows │ Row │ SepalLength │ SepalWidth │ PetalLength │ PetalWidth │ Species │ │ │ Float64 │ Float64 │ Float64 │ Float64 │ String │ ├─────┼─────────────┼────────────┼─────────────┼────────────┼─────────┤ │ 1 │ 5.1 │ 3.5 │ 1.4 │ 0.2 │ setosa │ │ 2 │ 4.9 │ 3.0 │ 1.4 │ 0.2 │ setosa │ │ 3 │ 4.7 │ 3.2 │ 1.3 │ 0.2 │ setosa │
Hasilnya dapat dikonversi ke array menggunakan fungsi kumpulkan yang disebutkan sebelumnya:
julia> collect(species) 3-element Array{Any,1}: 50×5 SubDataFrame{Array{Int64,1}} │ Row │ SepalLength │ SepalWidth │ PetalLength │ PetalWidth │ Species │ │ │ Float64 │ Float64 │ Float64 │ Float64 │ String │ ├─────┼─────────────┼────────────┼─────────────┼────────────┼─────────┤ │ 1 │ 5.1 │ 3.5 │ 1.4 │ 0.2 │ setosa │ │ 2 │ 4.9 │ 3.0 │ 1.4 │ 0.2 │ setosa │ │ 3 │ 4.7 │ 3.2 │ 1.3 │ 0.2 │ setosa │ …
Kelompokkan dengan menggunakan fungsi menurut. Tentukan nama kolom dan fungsi pemrosesan dari DataFrame yang diterima. Tahap pertama pekerjaan mirip dengan fungsi groupby - kita mendapatkan koleksi DataFrame. Untuk setiap DataFrame tersebut, hitung jumlah baris dan letakkan di kolom N. Hasilnya akan dilem menjadi DataFrame tunggal dan dikembalikan sebagai hasil dari fungsi by.
julia> by(iris, :Species, df -> DataFrame(N = size(df, 1))) 3×2 DataFrame │ Row │ Species │ N │ │ │ String⍰ │ Int64 │ ├─────┼────────────┼───────┤ │ 1 │ setosa │ 50 │ │ 2 │ versicolor │ 50 │ │ 3 │ virginica │ 50 │
Nah, opsi terakhir adalah fungsi agregat. Kami menentukan kolom untuk pengelompokan dan fungsi agregasi untuk kolom yang tersisa. Hasilnya adalah DataFrame di mana nama kolom akan dibentuk atas nama kolom sumber dan nama fungsi agregasi.
julia> aggregate(iris, :Species, sum) 3×5 DataFrame │Row│Species │SepalLength_sum│SepalWidth_sum│PetalLength_sum│PetalWidth_sum│ │ │ String │ Float64 │ Float64 │ Float64 │ Float64 │ ├───┼──────────┼───────────────┼──────────────┼───────────────┼──────────────┤ │ 1 │setosa │250.3 │ 171.4 │ 73.1 │ 12.3 │ │ 2 │versicolor│296.8 │ 138.5 │ 213.0 │ 66.3 │ │ 3 │virginica │329.4 │ 148.7 │ 277.6 │ 101.3 │
Fungsi colwise menerapkan fungsi yang ditentukan untuk semua atau hanya kolom DataFrame yang ditentukan.
julia> colwise(mean, iris[1:4]) 4-element Array{Float64,1}: 5.843333333333335 3.057333333333334 3.7580000000000027 1.199333333333334
Fungsi yang sangat nyaman untuk mendapatkan ringkasan tabel dijelaskan. Contoh penggunaan:
julia> describe(iris) 5×8 DataFrame │Row│ variable │mean │min │median│ max │nunique│nmissing│ eltype │ │ │ Symbol │Union… │Any │Union…│ Any │Union… │Int64 │DataType│ ├───┼───────────┼───────┼──────┼──────┼─────────┼───────┼────────┼────────┤ │ 1 │SepalLength│5.84333│ 4.3 │ 5.8 │ 7.9 │ │ 0 │ Float64│ │ 2 │SepalWidth │3.05733│ 2.0 │ 3.0 │ 4.4 │ │ 0 │ Float64│ │ 3 │PetalLength│3.758 │ 1.0 │ 4.35 │ 6.9 │ │ 0 │ Float64│ │ 4 │PetalWidth │1.19933│ 0.1 │ 1.3 │ 2.5 │ │ 0 │ Float64│ │ 5 │Species │ │setosa│ │virginica│ 3 │ 0 │ String │
Daftar lengkap fitur DataFrames .
Seperti halnya kasus Matrix, Anda dapat menggunakan semua fungsi statistik yang tersedia di modul Statistik di DataFrame. Lihat https://docs.julialang.org/en/v1/stdlib/Statistics/index.html
Pustaka StatPlots.jl digunakan untuk menampilkan dataFrame secara grafis. Lihat Lebih Banyak https://github.com/JuliaPlots/StatPlots.jl
Perpustakaan ini mengimplementasikan seperangkat makro untuk menyederhanakan visualisasi.
julia> df = DataFrame(a = 1:10, b = 10 .* rand(10), c = 10 .* rand(10)) 10×3 DataFrame │ Row │ a │ b │ c │ │ │ Int64 │ Float64 │ Float64 │ ├─────┼───────┼─────────┼─────────┤ │ 1 │ 1 │ 0.73614 │ 7.11238 │ │ 2 │ 2 │ 5.5223 │ 1.42414 │ │ 3 │ 3 │ 3.5004 │ 2.11633 │ │ 4 │ 4 │ 1.34176 │ 7.54208 │ │ 5 │ 5 │ 8.52392 │ 2.98558 │ │ 6 │ 6 │ 4.47477 │ 6.36836 │ │ 7 │ 7 │ 8.48093 │ 6.59236 │ │ 8 │ 8 │ 5.3761 │ 2.5127 │ │ 9 │ 9 │ 3.55393 │ 9.2782 │ │ 10 │ 10 │ 3.50925 │ 7.07576 │ julia> @df df plot(:a, [:b :c], colour = [:red :blue])
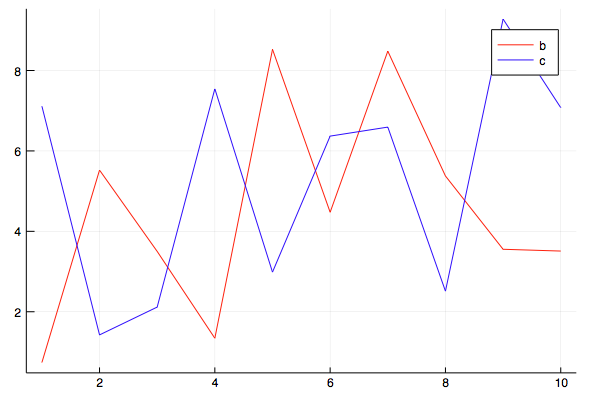
Di baris terakhir, @df adalah makro, df adalah nama variabel dengan DataFrame.
Query.jl bisa menjadi perpustakaan yang sangat berguna. Menggunakan mekanisme makro dan saluran pemrosesan, Query.jl menyediakan bahasa permintaan khusus. Contohnya adalah untuk mendapatkan daftar orang di atas 50 dan jumlah anak yang mereka miliki:
julia> using Query, DataFrames julia> df = DataFrame(name=["John", "Sally", "Kirk"], age=[23., 42., 59.], children=[3,5,2]) 3×3 DataFrame │ Row │ name │ age │ children │ │ │ String │ Float64 │ Int64 │ ├─────┼────────┼─────────┼──────────┤ │ 1 │ John │ 23.0 │ 3 │ │ 2 │ Sally │ 42.0 │ 5 │ │ 3 │ Kirk │ 59.0 │ 2 │ julia> x = @from i in df begin @where i.age>50 @select {i.name, i.children} @collect DataFrame end 1×2 DataFrame │ Row │ name │ children │ │ │ String │ Int64 │ ├─────┼────────┼──────────┤ │ 1 │ Kirk │ 2 │
Atau formulir dengan saluran:
julia> using Query, DataFrames julia> df = DataFrame(name=["John", "Sally", "Kirk"], age=[23., 42., 59.], children=[3,5,2]); julia> x = df |> @query(i, begin @where i.age>50 @select {i.name, i.children} end) |> DataFrame 1×2 DataFrame │ Row │ name │ children │ │ │ String │ Int64 │ ├─────┼────────┼──────────┤ │ 1 │ Kirk │ 2 │
Lihat lebih detail
Kedua contoh di atas menunjukkan penggunaan bahasa permintaan yang secara fungsional mirip dengan dplyr atau LINQ. Selain itu, bahasa-bahasa ini tidak terbatas pada Query.jl. Pelajari lebih lanjut tentang menggunakan bahasa ini dengan DataFrames di sini .
Contoh terakhir menggunakan operator | |. Lihat lebih lanjut
Operator ini mengganti argumen menjadi fungsi yang ditunjukkan di sebelah kanannya. Dengan kata lain:
julia> [1:5;] |> x->x.^2 |> sum |> inv 0.01818181818181818
Setara dengan:
julia> inv(sum( [1:5;] .^ 2 )) 0.01818181818181818
Dan hal terakhir yang ingin saya perhatikan adalah kemampuan untuk menulis DataFrame ke format output dengan pemisah menggunakan perpustakaan CSV.jl yang disebutkan sebelumnya
julia> df = DataFrame(name=["John", "Sally", "Kirk"], age=[23., 42., 59.], children=[3,5,2]) 3×3 DataFrame │ Row │ name │ age │ children │ │ │ String │ Float64 │ Int64 │ ├─────┼────────┼─────────┼──────────┤ │ 1 │ John │ 23.0 │ 3 │ │ 2 │ Sally │ 42.0 │ 5 │ │ 3 │ Kirk │ 59.0 │ 2 │ julia> CSV.write("out.csv", df) "out.csv"
Kami dapat memeriksa hasil yang direkam:
> cat out.csv name,age,children John,23.0,3 Sally,42.0,5 Kirk,59.0,2
Kesimpulan
Sulit untuk memprediksi apakah Julia akan menjadi bahasa pemrograman yang umum seperti R, misalnya, tetapi tahun ini telah menjadi bahasa pemrograman yang paling cepat berkembang. Jika hanya sedikit yang tahu tentang hal itu tahun lalu, tahun ini, setelah rilis versi 1.0 dan stabilisasi fungsi perpustakaan, mereka mulai menulis tentang hal itu, hampir pasti, tahun depan itu akan menjadi bahasa, akan tidak senonoh untuk tidak tahu di bidang Ilmu Data. Dan perusahaan yang tidak mulai menggunakan Julia untuk menganalisis data akan menjadi dinosaurus langsung untuk digantikan oleh keturunan yang lebih gesit.
Julia adalah bahasa pemrograman muda. Sebenarnya, setelah kemunculan proyek percontohan, akan menjadi jelas seberapa banyak infrastruktur Julia siap untuk penggunaan industri nyata. Pengembang Julia sangat ambisius dan siap sekarang. Bagaimanapun, sintaksis Julia yang sederhana namun ketat menjadikannya bahasa pemrograman yang sangat menarik untuk dipelajari saat ini. Kinerja tinggi memungkinkan Anda untuk mengimplementasikan algoritma yang cocok tidak hanya untuk tujuan pendidikan, tetapi juga untuk penggunaan nyata dalam analisis data. Kami akan mulai mencoba Julia secara konsisten di berbagai proyek sekarang.