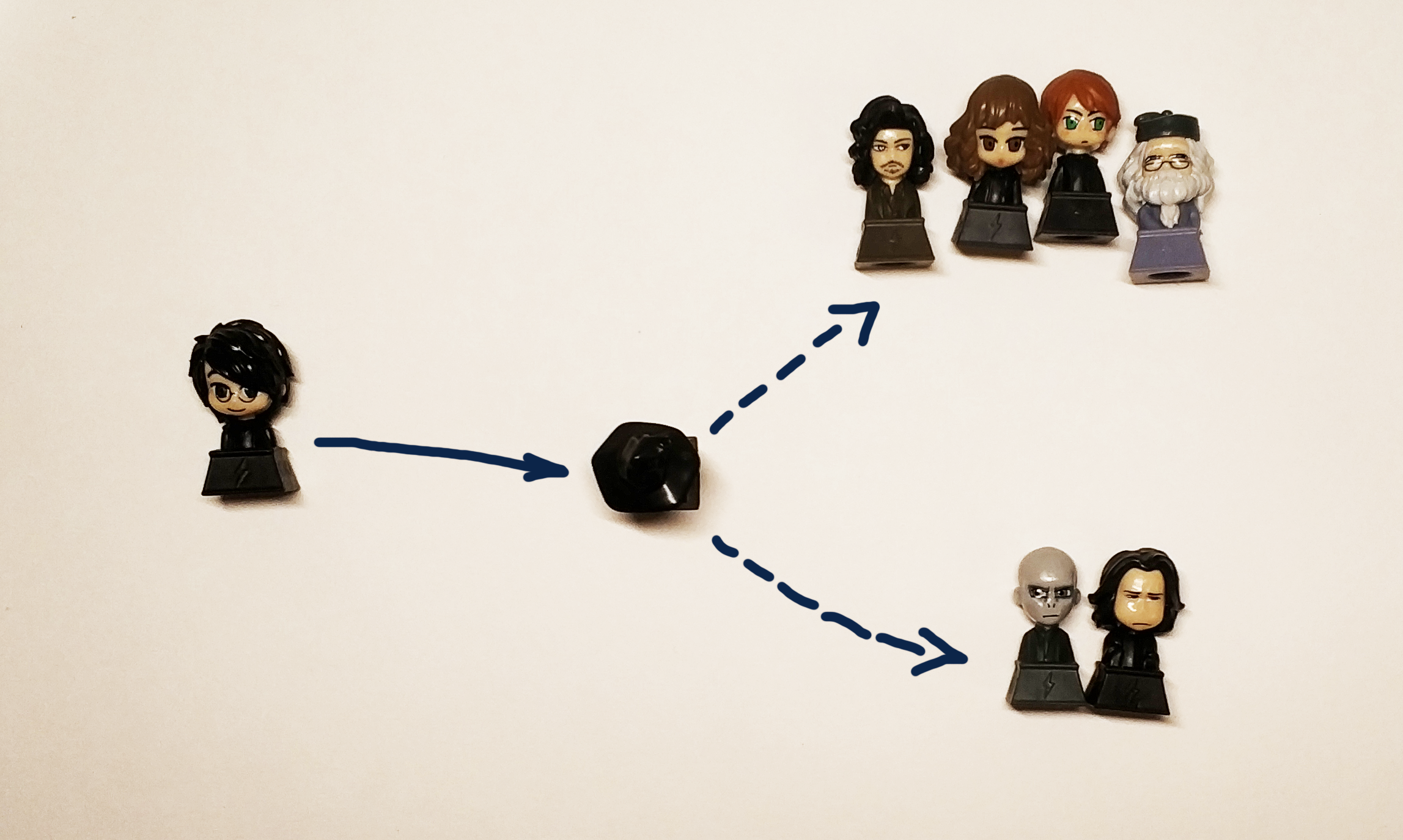
Sebulan yang lalu, Lenta meluncurkan kontes di mana Talking Hat dari Harry Potter mengidentifikasi peserta yang memiliki akses ke jejaring sosial ke salah satu dari empat fakultas. Persaingannya tidak buruk, nama-nama yang terdengar berbeda ditentukan oleh fakultas yang berbeda, dan nama dan nama keluarga Inggris dan Rusia yang sama didistribusikan dengan cara yang sama. Saya tidak tahu apakah distribusinya hanya bergantung pada nama dan nama keluarga, dan apakah jumlah teman atau faktor lain diperhitungkan entah bagaimana, tetapi kompetisi ini menyarankan ide artikel ini: coba latih penggolong dari awal, yang akan memungkinkan pengguna didistribusikan ke fakultas yang berbeda.
Dalam artikel ini, kita akan membuat model ML sederhana yang mendistribusikan orang ke departemen Harry Potter tergantung pada nama dan nama keluarga mereka, setelah melalui proses penelitian kecil mengikuti metodologi CRISP . Yaitu kita:
- Kami merumuskan masalah;
- Kami menyelidiki kemungkinan pendekatan untuk solusinya dan merumuskan persyaratan data (Metode dan data solusi);
- Kami akan mengumpulkan data yang diperlukan (metode solusi dan data);
- Kami akan mempelajari kumpulan data yang dikumpulkan (Penelitian Eksplorasi);
- Ekstrak fitur dari data mentah (Teknik Fitur);
- Mari kita ajarkan model pembelajaran mesin (Evaluasi model);
- Bandingkan hasil yang diperoleh, evaluasi kualitas solusi dan, jika perlu, ulangi paragraf 2-6;
- Kami mengemas solusi menjadi layanan yang dapat digunakan (Produksi).

Tugas ini mungkin tampak sepele, jadi kami akan memberlakukan batasan tambahan pada seluruh proses (sehingga membutuhkan waktu kurang dari 2 jam) dan pada artikel ini (sehingga waktu membaca kurang dari 15 menit).
Jika Anda sudah tenggelam dalam dunia Data Science yang indah dan indah dan Anda tidak melihat Kagglite terus-menerus, atau (Tuhan melarang) untuk mengukur panjang Hadup Anda selama pertemuan dengan kolega, maka kemungkinan besar artikel itu akan tampak sederhana dan tidak menarik bagi Anda. Selain itu: kualitas model akhir bukanlah nilai utama dari artikel ini. Kami sudah memperingatkan Anda. Ayo pergi.
Repositori github dengan kode yang digunakan dalam artikel ini juga tersedia untuk pembaca yang penasaran. Jika terjadi kesalahan, harap buka PR.
Dimungkinkan untuk menyelesaikan masalah yang tidak memiliki kriteria keputusan yang jelas untuk waktu yang sangat lama, jadi kami akan segera memutuskan bahwa kami ingin mendapatkan solusi yang akan memungkinkan kami untuk mendapatkan jawaban "Gryffindor", "Ravenclaw", "Ravenclaw", "Hufflepuff" atau "Slytherin" sebagai tanggapan terhadap baris yang dimasukkan.
Faktanya, kami ingin mendapatkan kotak hitam:
" " => [?] => Griffindor
Topi hitam asli mendistribusikan penyihir muda ke departemen tergantung pada sifat dan kualitas pribadi mereka. Karena data tentang karakter dan kepribadian berdasarkan kondisi masalah tidak tersedia bagi kami, kami akan menggunakan nama dan nama keluarga peserta, mengingat bahwa dalam hal ini kami harus mendistribusikan karakter buku ke departemen yang sesuai dengan departemen asli mereka dari buku. Dan para potteromanes pasti akan marah jika keputusan kami mendistribusikan Harry ke Hufflepuff atau Ravenclaw (tetapi itu harus mengirim Harry ke Gryffindor dan Slytherin dengan probabilitas yang sama untuk menyampaikan semangat buku itu).
Karena kita berbicara tentang probabilitas, kita meresmikan masalah dalam istilah matematika yang lebih ketat. Dari sudut pandang Ilmu Data, kami memecahkan masalah klasifikasi, yaitu menetapkan ke objek (string, dalam bentuk nama dan nama keluarga) kelas tertentu (sebenarnya itu hanya label, atau label, yang bisa berupa angka atau 4 variabel yang memiliki nilai ya / tidak nilai ) Kami memahami bahwa setidaknya dalam kasus Harry, akan benar untuk memberikan 2 jawaban: Gryffindor dan Slytherin, jadi akan lebih baik untuk tidak memprediksi fakultas spesifik yang didefinisikan topi, tetapi probabilitas bahwa seseorang akan dialokasikan ke fakultas ini, sehingga keputusan kami akan dibuat dalam semacam fungsi
Metrik dan Penilaian Kualitas
Tugas dan tujuan dirumuskan, Sekarang kita akan berpikir bagaimana menyelesaikannya tapi itu belum semuanya. Untuk memulai studi, Anda harus memasukkan metrik kualitas. Dengan kata lain, untuk menentukan bagaimana kami akan membandingkan 2 solusi yang berbeda satu sama lain.
Segala sesuatu dalam hidup ini baik dan sederhana - kami secara intuitif memahami bahwa pendeteksi spam harus memberikan minimum spam ke pesan yang masuk, serta memberikan maksimum surat yang diperlukan dan tentu saja tidak boleh mengirim surat yang diperlukan ke spam.
Pada kenyataannya, semuanya lebih rumit dan konfirmasi ini adalah sejumlah besar artikel yang menjelaskan bagaimana dan metrik apa yang digunakan. Berlatih membantu untuk memahami yang terbaik ini, tetapi ini adalah topik yang sangat banyak sehingga kami berjanji untuk menulis posting terpisah tentang hal itu dan membuat tabel terbuka sehingga semua orang dapat bermain-main dan memahami dalam praktik bagaimana perbedaannya.
Rumah tangga “tetapi mari kita pilih yang terbaik” bagi kita adalah ROC AUC . Inilah yang kita inginkan dari metrik dalam kasus ini: semakin sedikit false positive dan semakin akurat prediksi yang sebenarnya, semakin besar ROC AUC.
Untuk model ROC ideal, AUC adalah 1, untuk model acak ideal yang mendefinisikan kelas benar-benar secara acak - 0,5.
Algoritma
Kotak hitam kami harus memperhitungkan distribusi para pahlawan buku, mengambil nama dan nama keluarga yang berbeda sebagai input, dan memberikan hasilnya. Untuk mengatasi masalah klasifikasi, Anda dapat menggunakan algoritma pembelajaran mesin yang berbeda:
jaringan saraf, mesin faktorisasi, regresi linier, atau, misalnya, SVM.
Berlawanan dengan kepercayaan populer, Ilmu Data tidak terbatas hanya pada jaringan saraf, dan untuk mempopulerkan gagasan ini, dalam artikel ini jaringan saraf dibiarkan sebagai latihan untuk pembaca yang ingin tahu . Mereka yang tidak mengikuti kursus analisis data (terutama yang secara subyektif lebih baik - dari ODS), atau sekadar membaca dan berita tentang pembelajaran mesin atau AI, yang sekarang diterbitkan bahkan di majalah nelayan amatir, mungkin bertemu dengan nama-nama kelompok umum algoritma. : mengantongi, meningkatkan, mendukung metode vektor (SVM), regresi linier. Merekalah yang akan kita gunakan untuk menyelesaikan masalah kita.
Dan lebih tepatnya, kami membandingkan:
- Regresi linier
- Peningkatan (XGboost, LightGBM)
- Memutuskan pohon (sebenarnya, ini adalah dorongan yang sama, tetapi kami akan mengeluarkannya secara terpisah: Pohon Ekstra)
- Bagging (Hutan Acak)
- SVM
Kita dapat memecahkan masalah pendistribusian setiap siswa Hogwarts ke salah satu fakultas dengan mendefinisikan fakultas yang sesuai dengannya, tetapi secara tegas tugas ini bermuara pada penyelesaian masalah menentukan apakah setiap kelas milik secara individual. Oleh karena itu, dalam kerangka artikel ini kami menetapkan tujuan memperoleh 4 model, satu untuk setiap fakultas.
Data
Menemukan dataset yang tepat untuk pelatihan, dan yang lebih penting, legal untuk menggunakannya untuk tujuan yang benar, adalah salah satu tugas yang paling kompleks dan memakan waktu dalam Ilmu Data. Untuk tugas kami, kami akan mengambil data dari wikia di seluruh dunia Harry Potter. Misalnya, pada tautan ini Anda dapat menemukan semua karakter yang belajar di fakultas Gryffindor. Penting bahwa dalam hal ini kami menggunakan data untuk tujuan non-komersial, oleh karena itu kami tidak melanggar lisensi situs ini.

Bagi mereka yang berpikir bahwa Data Scientists adalah orang yang sangat keren, saya akan pergi ke Data Scientists dan biarkan saya mengajar Anda, kami akan mengingatkan Anda bahwa ada langkah seperti membersihkan dan menyiapkan data. Data yang diunduh harus dimoderasi secara manual untuk menghapus, misalnya, "Prefek Ketujuh Gryffindor" dan menghapus "Gadis Tidak Dikenal dari Gryffindor" secara semi-otomatis. Dalam pekerjaan nyata, sebagian besar tugas secara proporsional selalu dikaitkan dengan persiapan, pembersihan, dan pemulihan nilai yang hilang dalam dataset.
Sedikit ctrl + c & ctrl + v dan pada output kita mendapatkan 4 file teks, yang berisi nama-nama karakter dalam 2 bahasa: Inggris dan Rusia.
Kami mempelajari data yang dikumpulkan (EDA, Analisis Data Eksplorasi)
Untuk tahap ini, kami memiliki 4 file yang berisi nama-nama mahasiswa fakultas, kami akan melihat lebih detail:
$ ls ../input griffindor.txt hufflpuff.txt ravenclaw.txt slitherin.txt
Setiap file berisi 1 nama dan nama keluarga (jika ada) dari siswa per baris:
$ wc -l ../input/*.txt 250 ../input/griffindor.txt 167 ../input/hufflpuff.txt 180 ../input/ravenclaw.txt 254 ../input/slitherin.txt 851 total
Data yang dikumpulkan berupa:
$ cat ../input/griffindor.txt | head -3 && cat ../input/griffindor.txt | tail -3 Charlie Stainforth Melanie Stanmore Stewart
Seluruh ide kami didasarkan pada asumsi bahwa ada sesuatu yang serupa dalam nama dan nama keluarga yang dapat dipelajari kotak hitam kami (atau topi hitam).
Algoritme dapat memberi makan garis sebagaimana adanya, tetapi hasilnya tidak akan baik, karena model dasar tidak akan dapat memahami secara independen bagaimana "Draco" berbeda dari "Harry", jadi kita perlu mengekstrak tanda-tanda dari nama dan nama keluarga kita.
Persiapan Data (Teknik Fitur)
Tanda (atau fitur, dari fitur Bahasa Inggris - properti) adalah properti yang membedakan suatu objek. Berapa kali seseorang berganti pekerjaan selama setahun terakhir, jumlah jari di tangan kirinya, kapasitas mesin mesin, apakah jarak tempuh mobil melebihi 100.000 km atau tidak. Segala macam klasifikasi tanda ditemukan oleh jumlah yang sangat besar, tidak ada dan tidak mungkin ada satu sistem dalam hal ini, jadi kami akan memberikan contoh tanda apa yang bisa:
- Bilangan rasional
- Kategori (hingga 12, 12-18 atau 18+)
- Nilai biner (Mengembalikan pinjaman pertama atau tidak)
- Tanggal, warna, pembagian, dll.
Pencarian (atau pembentukan) fitur (dalam Rekayasa Fitur Bahasa Inggris ) sangat sering menonjol sebagai tahap penelitian yang terpisah atau pekerjaan spesialis analisis data. Faktanya, akal sehat, pengalaman dan pengujian hipotesis membantu dalam proses itu sendiri. Menebak tanda-tanda yang tepat segera adalah pertanyaan kombinasi tangan penuh, pengetahuan mendasar dan keberuntungan. Terkadang ada perdukunan di dalamnya, tetapi pendekatan umum sangat sederhana: Anda perlu melakukan apa yang ada dalam pikiran, dan kemudian memeriksa apakah mungkin untuk meningkatkan solusi dengan menambahkan atribut baru. Misalnya, sebagai tanda untuk tugas kita, kita dapat mengambil jumlah desis dalam nama.
Dalam versi pertama (karena studi Ilmu Data nyata - sebagai mahakarya, tidak pernah dapat diselesaikan) dari model kami, kami akan menggunakan fitur berikut untuk nama dan nama keluarga:
- 1 dan huruf terakhir dari kata - vokal atau konsonan
- Vokal dan konsonan ganda
- Jumlah vokal, konsonan, tuli, disuarakan
- Panjang nama, panjang nama belakang
- ...
Untuk melakukan ini, kita akan mengambil repositori ini sebagai dasar dan menambahkan kelas sehingga dapat digunakan untuk huruf Latin. Ini akan memberi kita kesempatan untuk menentukan bagaimana setiap huruf terdengar.
>> from Phonetic import RussianLetter, EnglishLetter >> RussianLetter('').classify() {'consonant': True, 'deaf': False, 'hard': False, 'mark': False, 'paired': False, 'shock': False, 'soft': False, 'sonorus': True, 'vowel': False} >> EnglishLetter('d').classify() {'consonant': True, 'deaf': False, 'hard': True, 'mark': False, 'paired': False, 'shock': False, 'soft': False, 'sonorus': True, 'vowel': False}
Sekarang kita dapat mendefinisikan fungsi sederhana untuk menghitung statistik, misalnya:
def starts_with_letter(word, letter_type='vowel'): """ , . :param word: :param letter_type: 'vowel' 'consonant'. . :return: Boolean """ if len(word) == 0: return False return Letter(word[0]).classify()[letter_type] def count_letter_type(word): """ . :param word: :param debug: :return: :obj:`dict` of :obj:`str` => :int:count """ count = { 'consonant': 0, 'deaf': 0, 'hard': 0, 'mark': 0, 'paired': 0, 'shock': 0, 'soft': 0, 'sonorus': 0, 'vowel': 0 } for letter in word: classes = Letter(letter).classify() for key in count.keys(): if classes[key]: count[key] += 1 return count
Dengan menggunakan fungsi-fungsi ini, kita sudah bisa mendapatkan tanda-tanda pertama:
from feature_engineering import * >> print(" («»): ", len("")) («»): 5 >> print(" («») : ", starts_with_letter('', 'vowel')) («») : False >> print(" («») : ", starts_with_letter('', 'consonant')) («») : True >> count_Harry = count_letter_type("") >> print (" («»): ", count_Harry['paired']) («»): 1
Sebenarnya, dengan bantuan fungsi-fungsi ini kita bisa mendapatkan representasi vektor dari string, yaitu, kita mendapatkan pemetaan:
Sekarang kita dapat mempresentasikan data kita dalam bentuk dataset yang dapat dimasukkan ke algoritma pembelajaran mesin:
>> from data_loaders import load_processed_data >> hogwarts_df = load_processed_data() >> hogwarts_df.head()

Selain itu, sebagai hasilnya, kami mendapatkan gejala berikut untuk setiap siswa:
>> hogwarts_df[hogwarts_df.columns].dtypes
Tanda-tanda Diterima name object surname object is_english bool name_starts_with_vowel bool name_starts_with_consonant bool name_ends_with_vowel bool name_ends_with_consonant bool name_length int64 name_vowels_count int64 name_double_vowels_count int64 name_consonant_count int64 name_double_consonant_count int64 name_paired_count int64 name_deaf_count int64 name_sonorus_count int64 surname_starts_with_vowel bool surname_starts_with_consonant bool surname_ends_with_vowel bool surname_ends_with_consonant bool surname_length int64 surname_vowels_count int64 surname_double_vowels_count int64 surname_consonant_count int64 surname_double_consonant_count int64 surname_paired_count int64 surname_deaf_count int64 surname_sonorus_count int64 is_griffindor int64 is_hufflpuff int64 is_ravenclaw int64 is_slitherin int64 dtype: object
4 kolom terakhir ditargetkan - berisi informasi tentang fakultas tempat siswa terdaftar.
Pelatihan Algoritma
Singkatnya, algoritma dilatih sama seperti orang: mereka membuat kesalahan dan belajar dari mereka. Untuk memahami seberapa banyak mereka melakukan kesalahan, algoritma menggunakan fungsi kesalahan (fungsi kerugian, fungsi kerugian bahasa Inggris ).
Biasanya, proses pembelajarannya sangat sederhana dan terdiri dari beberapa langkah:
- Buat prediksi.
- Nilai kesalahan.
- Perbaiki parameter model.
- Ulangi 1-3 hingga tujuan tercapai, proses berhenti atau data berakhir.
Nilai kualitas model yang dihasilkan.
Dalam praktiknya, tentu saja, semuanya sedikit lebih rumit. Misalnya, ada fenomena overfitting - algoritme dapat benar-benar mengingat atribut apa yang sesuai dengan jawaban dan dengan demikian memperburuk hasil untuk objek yang tidak mirip dengan yang dilatih. Untuk menghindarinya, ada berbagai teknik dan retasan.
Seperti disebutkan di atas, kami akan menyelesaikan 4 masalah: satu untuk setiap fakultas. Karena itu, kami akan menyiapkan data untuk Slytherin:
Saat belajar, algoritme terus-menerus membandingkan hasilnya dengan data nyata, untuk bagian dataset ini dialokasikan untuk validasi. Aturan nada yang baik juga dianggap untuk mengevaluasi hasil algoritma pada data individual yang tidak terlihat oleh algoritma sama sekali. Oleh karena itu, sekarang kami membagi sampel dalam proporsi 70/30 dan melatih algoritma pertama:
from sklearn.cross_validation import train_test_split from sklearn.ensemble import RandomForestClassifier
Selesai Sekarang, jika Anda mengirimkan data ke input model ini, itu akan menghasilkan hasil. Ini menyenangkan, jadi pertama-tama kita akan memeriksa untuk melihat apakah model di Harry mengenali Slytherin. Untuk melakukan ini, pertama-tama siapkan fungsi untuk mendapatkan prediksi algoritma:
Lihat kode from data_loaders import parse_line_to_hogwarts_df import pandas as pd def get_single_student_features (name): """ :param name: string :return: pd.DataFrame """ featurized_person_df = parse_line_to_hogwarts_df(name) person_df = pd.DataFrame(featurized_person_df, columns=[ 'name', 'surname', 'is_english', 'name_starts_with_vowel', 'name_starts_with_consonant', 'name_ends_with_vowel', 'name_ends_with_consonant', 'name_length', 'name_vowels_count', 'name_double_vowels_count', 'name_consonant_count', 'name_double_consonant_count', 'name_paired_count', 'name_deaf_count', 'name_sonorus_count', 'surname_starts_with_vowel', 'surname_starts_with_consonant', 'surname_ends_with_vowel', 'surname_ends_with_consonant', 'surname_length', 'surname_vowels_count', 'surname_double_vowels_count', 'surname_consonant_count', 'surname_double_consonant_count', 'surname_paired_count', 'surname_deaf_count', 'surname_sonorus_count', ], index=[0] ) featurized_person = person_df.drop( ['name', 'surname'], axis = 1 ) return featurized_person def get_predictions_vector (model, person): """ :param model: :param person: string :return: list """ encoded_person = get_single_student_features(person) return model.predict_proba(encoded_person)[0]
Sekarang mari kita atur set data uji kecil untuk mempertimbangkan hasil dari algoritma.
def score_testing_dataset (model): """ . :param model: """ testing_dataset = [ " ", "Kirill Malev", " ", "Harry Potter", " ", " ","Severus Snape", " ", "Tom Riddle", " ", "Salazar Slytherin"] for name in testing_dataset: print ("{} — {}".format(name, get_predictions_vector(model, name)[1])) score_testing_dataset(rfc_model)
— 0.5 Kirill Malev — 0.5 — 0.0 Harry Potter — 0.0 — 0.75 — 0.9 Severus Snape — 0.5 — 0.2 Tom Riddle — 0.5 — 0.2 Salazar Slytherin — 0.3
Hasilnya meragukan. Bahkan pendiri fakultas tidak akan berada di fakultasnya, menurut model ini. Karenanya, Anda perlu mengevaluasi kualitas yang ketat: lihat metrik yang kami tanyakan di awal:
from sklearn.metrics import accuracy_score, roc_auc_score, classification_report predictions = rfc_model.predict(X_test) print("Classification report: ") print(classification_report(y_test, predictions)) print("Accuracy for Random Forest Model: %.2f" % (accuracy_score(y_test, predictions) * 100)) print("ROC AUC from first Random Forest Model: %.2f" % (roc_auc_score(y_test, predictions)))
Classification report: precision recall f1-score support 0 0.66 0.88 0.75 168 1 0.38 0.15 0.21 89 avg / total 0.56 0.62 0.56 257 Accuracy for Random Forest Model: 62.26 ROC AUC from first Random Forest Model: 0.51
Tidak mengherankan bahwa hasilnya sangat meragukan - ROC AUC sekitar 0,51 menunjukkan bahwa model tersebut memprediksi sedikit lebih baik daripada lemparan koin.
Menguji hasilnya. Metrik kualitas
Dengan menggunakan satu contoh di atas, kami melihat bagaimana 1 algoritma dilatih yang mendukung antarmuka sklearn. Sisanya dilatih dengan cara yang persis sama, jadi kami hanya bisa melatih semua algoritma dan memilih yang terbaik di setiap kasus.

Ini tidak rumit, untuk setiap algoritma kami latih 1 dengan pengaturan standar, dan juga latih seluruh rangkaian, memilah-milah berbagai pilihan yang mempengaruhi kualitas algoritma. Tahap ini disebut Model Tuning atau Hyperparameter Optimization dan esensinya sangat sederhana: set pengaturan yang memberikan hasil terbaik dipilih.
from model_training import train_classifiers from data_loaders import load_processed_data import warnings warnings.filterwarnings('ignore')
— 0.09437856871661066 Kirill Malev — 0.20820536334902712 — 0.07550095601699099 Harry Potter — 0.07683794773639624 — 0.9414529336862744 — 0.9293671807790949 Severus Snape — 0.6576783576162999 — 0.18577792617672767 Tom Riddle — 0.8351835484058869 — 0.25930925139546795 Salazar Slytherin — 0.24008788903854789
Angka-angka dalam versi ini terlihat lebih baik secara subyektif daripada di masa lalu, tetapi masih belum cukup baik untuk perfeksionis internal. Oleh karena itu, kita akan turun ke tingkat yang lebih dalam dan kembali ke pengertian produk dari tugas kita: kita perlu memprediksi fakultas yang paling mungkin, yang pahlawan akan ditentukan oleh topi distribusi. Ini berarti bahwa Anda perlu melatih model untuk masing-masing fakultas.

>> from model_training import train_all_models
Kesimpulan panjang hasil dan hasil regresi multinomial SVM Default Report Accuracy for SVM Default: 73.93 ROC AUC for SVM Default: 0.53 Tuned SVM Report Accuracy for Tuned SVM: 72.37 ROC AUC for Tuned SVM: 0.50 KNN Default Report Accuracy for KNN Default: 70.04 ROC AUC for KNN Default: 0.58 Tuned KNN Report Accuracy for Tuned KNN: 69.65 ROC AUC for Tuned KNN: 0.58 XGBoost Default Report Accuracy for XGBoost Default: 70.43 ROC AUC for XGBoost Default: 0.54 Tuned XGBoost Report Accuracy for Tuned XGBoost: 68.09 ROC AUC for Tuned XGBoost: 0.56 Random Forest Default Report Accuracy for Random Forest Default: 73.93 ROC AUC for Random Forest Default: 0.62 Tuned Random Forest Report Accuracy for Tuned Random Forest: 74.32 ROC AUC for Tuned Random Forest: 0.54 Extra Trees Default Report Accuracy for Extra Trees Default: 69.26 ROC AUC for Extra Trees Default: 0.57 Tuned Extra Trees Report Accuracy for Tuned Extra Trees: 73.54 ROC AUC for Tuned Extra Trees: 0.55 LGBM Default Report Accuracy for LGBM Default: 70.82 ROC AUC for LGBM Default: 0.62 Tuned LGBM Report Accuracy for Tuned LGBM: 74.71 ROC AUC for Tuned LGBM: 0.53 RGF Default Report Accuracy for RGF Default: 70.43 ROC AUC for RGF Default: 0.58 Tuned RGF Report Accuracy for Tuned RGF: 71.60 ROC AUC for Tuned RGF: 0.60 FRGF Default Report Accuracy for FRGF Default: 68.87 ROC AUC for FRGF Default: 0.59 Tuned FRGF Report Accuracy for Tuned FRGF: 69.26 ROC AUC for Tuned FRGF: 0.59 SVM Default Report Accuracy for SVM Default: 70.43 ROC AUC for SVM Default: 0.50 Tuned SVM Report Accuracy for Tuned SVM: 71.60 ROC AUC for Tuned SVM: 0.50 KNN Default Report Accuracy for KNN Default: 63.04 ROC AUC for KNN Default: 0.49 Tuned KNN Report Accuracy for Tuned KNN: 65.76 ROC AUC for Tuned KNN: 0.50 XGBoost Default Report Accuracy for XGBoost Default: 69.65 ROC AUC for XGBoost Default: 0.54 Tuned XGBoost Report Accuracy for Tuned XGBoost: 68.09 ROC AUC for Tuned XGBoost: 0.50 Random Forest Default Report Accuracy for Random Forest Default: 66.15 ROC AUC for Random Forest Default: 0.51 Tuned Random Forest Report Accuracy for Tuned Random Forest: 70.43 ROC AUC for Tuned Random Forest: 0.50 Extra Trees Default Report Accuracy for Extra Trees Default: 64.20 ROC AUC for Extra Trees Default: 0.49 Tuned Extra Trees Report Accuracy for Tuned Extra Trees: 70.82 ROC AUC for Tuned Extra Trees: 0.51 LGBM Default Report Accuracy for LGBM Default: 67.70 ROC AUC for LGBM Default: 0.56 Tuned LGBM Report Accuracy for Tuned LGBM: 70.82 ROC AUC for Tuned LGBM: 0.50 RGF Default Report Accuracy for RGF Default: 66.54 ROC AUC for RGF Default: 0.52 Tuned RGF Report Accuracy for Tuned RGF: 65.76 ROC AUC for Tuned RGF: 0.53 FRGF Default Report Accuracy for FRGF Default: 65.76 ROC AUC for FRGF Default: 0.53 Tuned FRGF Report Accuracy for Tuned FRGF: 69.65 ROC AUC for Tuned FRGF: 0.52 SVM Default Report Accuracy for SVM Default: 74.32 ROC AUC for SVM Default: 0.50 Tuned SVM Report Accuracy for Tuned SVM: 74.71 ROC AUC for Tuned SVM: 0.51 KNN Default Report Accuracy for KNN Default: 69.26 ROC AUC for KNN Default: 0.48 Tuned KNN Report Accuracy for Tuned KNN: 73.15 ROC AUC for Tuned KNN: 0.49 XGBoost Default Report Accuracy for XGBoost Default: 72.76 ROC AUC for XGBoost Default: 0.49 Tuned XGBoost Report Accuracy for Tuned XGBoost: 74.32 ROC AUC for Tuned XGBoost: 0.50 Random Forest Default Report Accuracy for Random Forest Default: 73.93 ROC AUC for Random Forest Default: 0.52 Tuned Random Forest Report Accuracy for Tuned Random Forest: 74.32 ROC AUC for Tuned Random Forest: 0.50 Extra Trees Default Report Accuracy for Extra Trees Default: 73.93 ROC AUC for Extra Trees Default: 0.52 Tuned Extra Trees Report Accuracy for Tuned Extra Trees: 73.93 ROC AUC for Tuned Extra Trees: 0.50 LGBM Default Report Accuracy for LGBM Default: 73.54 ROC AUC for LGBM Default: 0.52 Tuned LGBM Report Accuracy for Tuned LGBM: 74.32 ROC AUC for Tuned LGBM: 0.50 RGF Default Report Accuracy for RGF Default: 73.54 ROC AUC for RGF Default: 0.51 Tuned RGF Report Accuracy for Tuned RGF: 73.93 ROC AUC for Tuned RGF: 0.50 FRGF Default Report Accuracy for FRGF Default: 73.93 ROC AUC for FRGF Default: 0.53 Tuned FRGF Report Accuracy for Tuned FRGF: 73.93 ROC AUC for Tuned FRGF: 0.50 SVM Default Report Accuracy for SVM Default: 80.54 ROC AUC for SVM Default: 0.50 Tuned SVM Report Accuracy for Tuned SVM: 80.93 ROC AUC for Tuned SVM: 0.52 KNN Default Report Accuracy for KNN Default: 78.60 ROC AUC for KNN Default: 0.50 Tuned KNN Report Accuracy for Tuned KNN: 80.16 ROC AUC for Tuned KNN: 0.51 XGBoost Default Report Accuracy for XGBoost Default: 80.54 ROC AUC for XGBoost Default: 0.50 Tuned XGBoost Report Accuracy for Tuned XGBoost: 77.04 ROC AUC for Tuned XGBoost: 0.52 Random Forest Default Report Accuracy for Random Forest Default: 77.43 ROC AUC for Random Forest Default: 0.49 Tuned Random Forest Report Accuracy for Tuned Random Forest: 80.54 ROC AUC for Tuned Random Forest: 0.50 Extra Trees Default Report Accuracy for Extra Trees Default: 76.26 ROC AUC for Extra Trees Default: 0.48 Tuned Extra Trees Report Accuracy for Tuned Extra Trees: 78.60 ROC AUC for Tuned Extra Trees: 0.50 LGBM Default Report Accuracy for LGBM Default: 75.49 ROC AUC for LGBM Default: 0.51 Tuned LGBM Report Accuracy for Tuned LGBM: 80.54 ROC AUC for Tuned LGBM: 0.50 RGF Default Report Accuracy for RGF Default: 78.99 ROC AUC for RGF Default: 0.52 Tuned RGF Report Accuracy for Tuned RGF: 75.88 ROC AUC for Tuned RGF: 0.55 FRGF Default Report Accuracy for FRGF Default: 76.65 ROC AUC for FRGF Default: 0.50 # ,
from sklearn.linear_model import LogisticRegression clf = LogisticRegression(random_state=0, solver='lbfgs', multi_class='multinomial') hogwarts_df = load_processed_data_multi()
— [0.3602361 0.16166944 0.16771712 0.31037733] Kirill Malev — [0.47473072 0.16051924 0.13511385 0.22963619] — [0.38697926 0.19330242 0.17451052 0.2452078 ] Harry Potter — [0.40245098 0.16410043 0.16023278 0.27321581] — [0.13197025 0.16438855 0.17739254 0.52624866] — [0.17170203 0.1205678 0.14341742 0.56431275] Severus Snape — [0.15558044 0.21589378 0.17370406 0.45482172] — [0.39301231 0.07397324 0.1212741 0.41174035] Tom Riddle — [0.26623969 0.14194379 0.1728505 0.41896601] — [0.24843037 0.21632736 0.21532696 0.3199153 ] Salazar Slytherin — [0.09359144 0.26735897 0.2742305 0.36481909]
Dan confusion_matrix:
confusion_matrix(clf.predict(X_data), y)
array([[144, 68, 64, 78], [ 8, 9, 8, 6], [ 22, 18, 31, 20], [ 77, 73, 78, 151]])
def get_predctions_vector (models, person): predictions = [get_predictions_vector (model, person)[1] for model in models] return { 'slitherin': predictions[0], 'griffindor': predictions[1], 'ravenclaw': predictions[2], 'hufflpuff': predictions[3] } def score_testing_dataset (models): testing_dataset = [ " ", "Kirill Malev", " ", "Harry Potter", " ", " ","Severus Snape", " ", "Tom Riddle", " ", "Salazar Slytherin"] data = [] for name in testing_dataset: predictions = get_predctions_vector(models, name) predictions['name'] = name data.append(predictions) scoring_df = pd.DataFrame(data, columns=['name', 'slitherin', 'griffindor', 'hufflpuff', 'ravenclaw']) return scoring_df
name slitherin griffindor hufflpuff ravenclaw 0 0.349084 0.266909 0.110311 0.091045 1 Kirill Malev 0.289914 0.376122 0.384986 0.103056 2 0.338258 0.400841 0.016668 0.124825 3 Harry Potter 0.245377 0.357934 0.026287 0.154592 4 0.917423 0.126997 0.176640 0.096570 5 0.969693 0.106384 0.150146 0.082195 6 Severus Snape 0.663732 0.259189 0.290252 0.074148 7 0.268466 0.579401 0.007900 0.083195 8 Tom Riddle 0.639731 0.541184 0.084395 0.156245 9 0.653595 0.147506 0.172940 0.137134 10 Salazar Slytherin 0.647399 0.169964 0.095450 0.26126

,
, , , , XGBoost CV , .
! , 70% . , 4 .
from model_training import train_production_models from xgboost import XGBClassifier best_models = [] for i in range (0,4): best_models.append(XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1, colsample_bytree=0.7, gamma=0, learning_rate=0.05, max_delta_step=0, max_depth=6, min_child_weight=11, missing=-999, n_estimators=1000, n_jobs=1, nthread=4, objective='binary:logistic', random_state=0, reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=1337, silent=1, subsample=0.8)) slitherin_model, griffindor_model, ravenclaw_model, hufflpuff_model = \ train_production_models(best_models) top_models = slitherin_model, griffindor_model, ravenclaw_model, hufflpuff_model score_testing_dataset(top_models)
name slitherin griffindor hufflpuff ravenclaw 0 0.273713 0.372337 0.065923 0.279577 1 Kirill Malev 0.401603 0.761467 0.111068 0.023902 2 0.031540 0.616535 0.196342 0.217829 3 Harry Potter 0.183760 0.422733 0.119393 0.173184 4 0.945895 0.021788 0.209820 0.019449 5 0.950932 0.088979 0.084131 0.012575 6 Severus Snape 0.634035 0.088230 0.249871 0.036682 7 0.426440 0.431351 0.028444 0.083636 8 Tom Riddle 0.816804 0.136530 0.069564 0.035500 9 0.409634 0.213925 0.028631 0.252723 10 Salazar Slytherin 0.824590 0.067910 0.111147 0.085710
, , .
, , . .
import pickle pickle.dump(slitherin_model, open("../output/slitherin.xgbm", "wb")) pickle.dump(griffindor_model, open("../output/griffindor.xgbm", "wb")) pickle.dump(ravenclaw_model, open("../output/ravenclaw.xgbm", "wb")) pickle.dump(hufflpuff_model, open("../output/hufflpuff.xgbm", "wb"))
, . , , , .
, , . , . , Data Scientist — -.
:
, docker-, python-. , flask.
from __future__ import print_function
Dockerfile:
FROM datmo/python-base:cpu-py35
:
docker build -t talking_hat . && docker rm talking_hat && docker run --name talking_hat -p 5000:5000 talking_hat
— . , Apache Benchmark . , . — .
$ ab -p data.json -T application/json -c 50 -n 10000 http://0.0.0.0:5000/predict
ab This is ApacheBench, Version 2.3 <$Revision: 1807734 $> Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/ Benchmarking 0.0.0.0 (be patient) Completed 1000 requests Completed 2000 requests Completed 3000 requests Completed 4000 requests Completed 5000 requests Completed 6000 requests Completed 7000 requests Completed 8000 requests Completed 9000 requests Completed 10000 requests Finished 10000 requests Server Software: Werkzeug/0.14.1 Server Hostname: 0.0.0.0 Server Port: 5000 Document Path: /predict Document Length: 141 bytes Concurrency Level: 50 Time taken for tests: 238.552 seconds Complete requests: 10000 Failed requests: 0 Total transferred: 2880000 bytes Total body sent: 1800000 HTML transferred: 1410000 bytes Requests per second: 41.92 [#/sec] (mean) Time per request: 1192.758 [ms] (mean) Time per request: 23.855 [ms] (mean, across all concurrent requests) Transfer rate: 11.79 [Kbytes/sec] received 7.37 kb/s sent 19.16 kb/s total Connection Times (ms) min mean[+/-sd] median max Connect: 0 0 0.1 0 3 Processing: 199 1191 352.5 1128 3352 Waiting: 198 1190 352.5 1127 3351 Total: 202 1191 352.5 1128 3352 Percentage of the requests served within a certain time (ms) 50% 1128 66% 1277 75% 1378 80% 1451 90% 1668 95% 1860 98% 2096 99% 2260 100% 3352 (longest request)
, :
def prod_predict_classes_for_name (full_name): <...> predictions = get_predctions_vector([ app.slitherin_model, app.griffindor_model, app.ravenclaw_model, app.hufflpuff_model ], person_df.drop(['name', 'surname'], axis=1)) return { 'slitherin': float(predictions[0][1]), 'griffindor': float(predictions[1][1]), 'ravenclaw': float(predictions[2][1]), 'hufflpuff': float(predictions[3][1]) } def create_app(): <...> with app.app_context(): app.slitherin_model = pickle.load(open("models/slitherin.xgbm", "rb")) app.griffindor_model = pickle.load(open("models/griffindor.xgbm", "rb")) app.ravenclaw_model = pickle.load(open("models/ravenclaw.xgbm", "rb")) app.hufflpuff_model = pickle.load(open("models/hufflpuff.xgbm", "rb")) return app
:
$ docker build -t talking_hat . && docker rm talking_hat && docker run --name talking_hat -p 5000:5000 talking_hat $ ab -p data.json -T application/json -c 50 -n 10000 http://0.0.0.0:5000/predict
ab This is ApacheBench, Version 2.3 <$Revision: 1807734 $> Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/ Benchmarking 0.0.0.0 (be patient) Completed 1000 requests Completed 2000 requests Completed 3000 requests Completed 4000 requests Completed 5000 requests Completed 6000 requests Completed 7000 requests Completed 8000 requests Completed 9000 requests Completed 10000 requests Finished 10000 requests Server Software: Werkzeug/0.14.1 Server Hostname: 0.0.0.0 Server Port: 5000 Document Path: /predict Document Length: 141 bytes Concurrency Level: 50 Time taken for tests: 219.812 seconds Complete requests: 10000 Failed requests: 3 (Connect: 0, Receive: 0, Length: 3, Exceptions: 0) Total transferred: 2879997 bytes Total body sent: 1800000 HTML transferred: 1409997 bytes Requests per second: 45.49 [#/sec] (mean) Time per request: 1099.062 [ms] (mean) Time per request: 21.981 [ms] (mean, across all concurrent requests) Transfer rate: 12.79 [Kbytes/sec] received 8.00 kb/s sent 20.79 kb/s total Connection Times (ms) min mean[+/-sd] median max Connect: 0 0 0.1 0 2 Processing: 235 1098 335.2 1035 3464 Waiting: 235 1097 335.2 1034 3462 Total: 238 1098 335.2 1035 3464 Percentage of the requests served within a certain time (ms) 50% 1035 66% 1176 75% 1278 80% 1349 90% 1541 95% 1736 98% 1967 99% 2141 100% 3464 (longest request)
. . , .
Kesimpulan
, . - .
, :
- feature engineering- ( ), , Soundex .
- PyTorch . , , .
- flask Quart , , .
- - -, .
, , . , !
Artikel ini tidak akan dipublikasikan tanpa komunitas Open Data Science, yang menyatukan sejumlah besar spesialis analisis data berbahasa Rusia.