Sebagai seorang insinyur infrastruktur di tim pengembangan platform cloud , saya memiliki kesempatan untuk bekerja dengan banyak sistem penyimpanan terdistribusi, termasuk yang ditunjukkan dalam header. Tampaknya ada pemahaman tentang kekuatan dan kelemahan mereka, dan saya akan mencoba berbagi pemikiran saya dengan Anda tentang masalah ini. Jadi untuk berbicara, mari kita lihat siapa yang memiliki fungsi hash lebih lama.

Penafian: Sebelumnya di blog ini Anda bisa melihat artikel di GlusterFS. Saya tidak ada hubungannya dengan artikel ini. Ini adalah blog penulis tim proyek cloud kami dan masing-masing anggotanya dapat menceritakan kisah mereka. Penulis artikel-artikel itu adalah seorang insinyur dari kelompok operasi kami dan ia memiliki tugas dan pengalamannya sendiri, yang ia bagikan. Harap pertimbangkan ini jika Anda tiba-tiba melihat perbedaan pendapat. Saya mengambil kesempatan ini untuk menyampaikan salam saya kepada penulis artikel-artikel itu!
Apa yang akan dibahas
Mari kita bicara tentang sistem file yang dapat dibangun berdasarkan GlusterFS dan CephFS. Kami akan membahas arsitektur kedua sistem ini, melihatnya dari sudut yang berbeda, dan pada akhirnya saya bahkan akan mengambil risiko membuat kesimpulan. Fitur Ceph lainnya, seperti RBD dan RGW, tidak akan terpengaruh.
Terminologi
Untuk membuat artikel lengkap dan dapat dimengerti oleh semua orang, mari kita lihat terminologi dasar kedua sistem:
Terminologi Ceph:
RADOS (Toko Objek Terdistribusi Autonomis Handal) adalah penyimpanan objek mandiri, yang merupakan dasar dari proyek Ceph.
CephFS , RBD (Perangkat Blok RADOS), RGW (RADOS Gateway) - gadget tingkat tinggi untuk RADOS, yang menyediakan berbagai antarmuka bagi pengguna akhir ke RADOS.
Secara khusus, CephFS menyediakan antarmuka sistem file yang sesuai dengan POSIX. Bahkan, data CephFS disimpan dalam RADOS.
OSD (Object Storage Daemon) adalah proses yang melayani disk / penyimpanan objek yang terpisah di cluster RADOS.
RADOS Pool (pool) - beberapa OSD yang disatukan oleh seperangkat aturan umum, seperti, misalnya, kebijakan replikasi. Dari sudut pandang hirarki data, kumpulan adalah direktori atau namespace terpisah (datar, tanpa subdirektori) untuk objek.
AM (Grup Penempatan) - Saya akan memperkenalkan konsep AM sebentar lagi, dalam konteksnya, untuk pemahaman yang lebih baik.
Karena RADOS adalah dasar di mana CephFS dibangun, saya akan sering membicarakannya dan ini akan secara otomatis berlaku untuk CephFS.
Terminologi GlusterFS (selanjutnya disebut gl):
Brick adalah proses melayani disk tunggal, analog OSD dalam terminologi RADOS.
Volume - volume tempat batu bata disatukan. Tom adalah analog kumpulan dalam RADOS, ia juga memiliki topologi replikasi khusus di antara batu bata.
Distribusi data
Untuk membuatnya lebih jelas, pertimbangkan contoh sederhana yang dapat diterapkan oleh kedua sistem.
Pengaturan yang akan digunakan sebagai contoh:
- 2 server (S1, S2) dengan 3 disk dengan volume yang sama (sda, sdb, sdc) di masing-masing;
- volume / kumpulan dengan replikasi 2.
Kedua sistem membutuhkan setidaknya 3 server untuk operasi normal. Tetapi kami menutup mata terhadap hal ini, karena ini hanyalah contoh untuk sebuah artikel.
Dalam kasus gl, ini akan menjadi Volume yang Didistribusikan Terdistribusi yang terdiri dari 3 kelompok replikasi:

Setiap grup replikasi adalah dua batu bata di server yang berbeda.
Bahkan, ternyata volume yang menggabungkan ketiga RAID-1.
Ketika Anda memasangnya, dapatkan sistem file yang diinginkan dan mulai menulis file untuk itu, Anda akan menemukan bahwa setiap file yang Anda tulis termasuk dalam salah satu grup replikasi ini secara keseluruhan.
Distribusi file di antara grup Terdistribusi ini ditangani oleh DHT (Distributed Hash Tables), yang pada dasarnya adalah fungsi hash (kami akan kembali lagi nanti).
Pada "diagram" itu akan terlihat seperti ini:
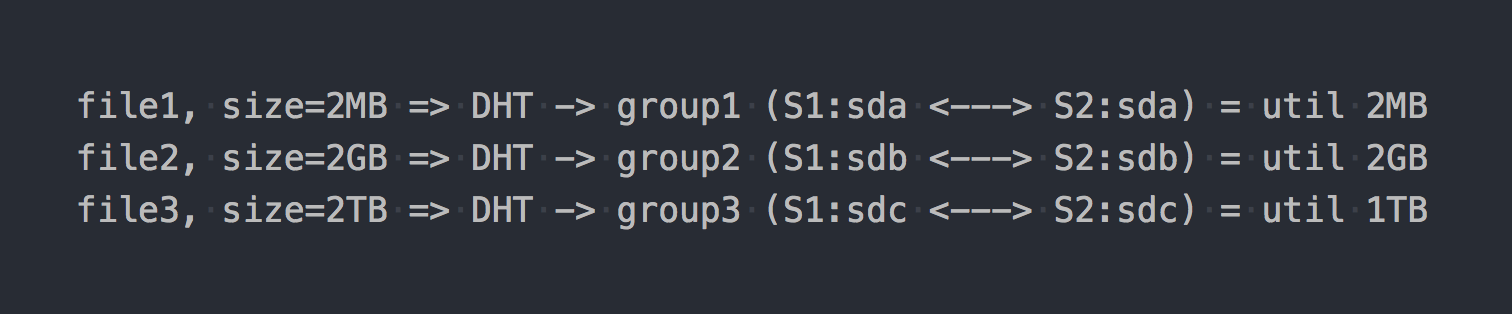
Seolah-olah fitur arsitektur pertama sudah terwujud:
- tempat dalam kelompok dibuang secara tidak rata, itu tergantung pada ukuran file;
- ketika menulis satu file, IO hanya pergi ke satu grup, sisanya idle;
- Anda tidak bisa mendapatkan IO seluruh volume saat menulis satu file;
- jika tidak ada cukup ruang dalam grup untuk menulis file, Anda akan mendapatkan kesalahan, file tidak akan ditulis dan tidak akan didistribusikan kembali ke grup lain.
Jika Anda menggunakan volume jenis lain, misalnya, Terdistribusi-Bergaris-Digandakan atau bahkan Dispersi (Penghapusan Kode), maka hanya mekanisme pendistribusian data dalam satu kelompok yang secara fundamental akan berubah. DHT juga akan menguraikan file sepenuhnya ke dalam kelompok-kelompok ini, dan pada akhirnya kita akan mendapatkan semua masalah yang sama. Ya, jika volume hanya terdiri dari satu grup, atau jika Anda memiliki semua file dengan ukuran yang sama, maka tidak akan ada masalah. Tetapi kita berbicara tentang sistem normal, di bawah ratusan terabyte data, termasuk file dengan ukuran berbeda, jadi kami percaya bahwa ada masalah.
Sekarang mari kita lihat CephFS. RADOS yang disebutkan di atas memasuki lokasi. Dalam RADOS, setiap disk dilayani oleh proses terpisah - OSD. Berdasarkan pengaturan kami, kami hanya mendapatkan 6 di antaranya, 3 di setiap server. Selanjutnya, kita perlu membuat kumpulan untuk data dan mengatur jumlah PG dan faktor replikasi data dalam kumpulan ini - dalam kasus kami 2.
Katakanlah kita membuat kolam dengan 8 PG. PG ini akan didistribusikan secara merata di seluruh OSD:
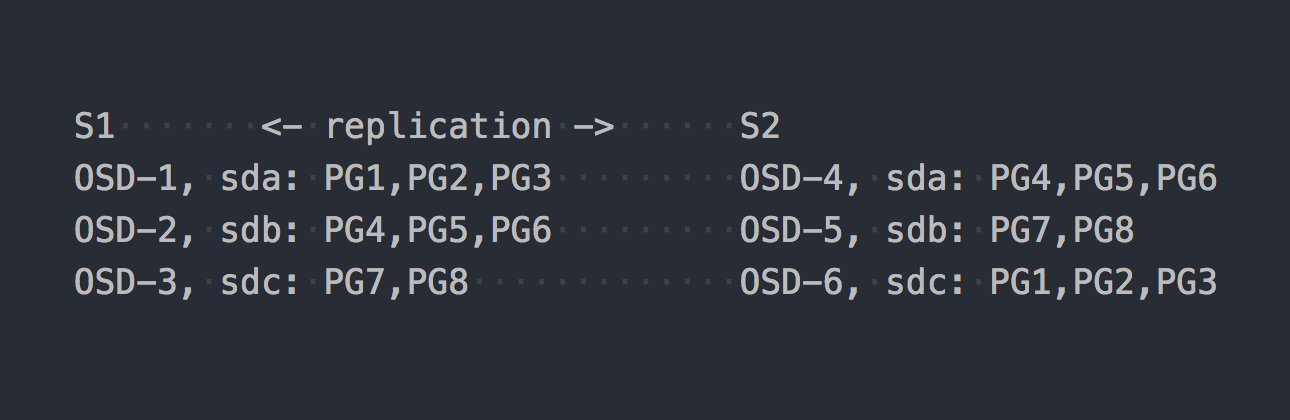
Sudah waktunya untuk menjelaskan bahwa PG adalah grup logis yang menggabungkan sejumlah objek. Karena kita menetapkan fakta replikasi 2, setiap PG memiliki replika pada beberapa OSD lain di server lain (secara default). Misalnya, PG1, yang ada di OSD-1 di server S1, memiliki kembaran pada S2 di OSD-6. Dalam setiap pasangan PG (atau rangkap tiga, jika replikasi 3) adalah PG UTAMA, yang sedang direkam. Misalnya, PRIMARY untuk PG4 ada di S1, tetapi PRIMARY untuk PG4 ada di S2.
Sekarang setelah Anda tahu cara kerja RADOS, kami dapat beralih ke menulis file ke kumpulan baru kami. Meskipun RADOS adalah penyimpanan penuh, tidak mungkin untuk memasangnya sebagai sistem file atau menggunakannya sebagai perangkat blok. Untuk menulis data secara langsung, Anda perlu menggunakan utilitas atau pustaka khusus.
Kami menulis tiga file yang sama seperti pada contoh di atas:
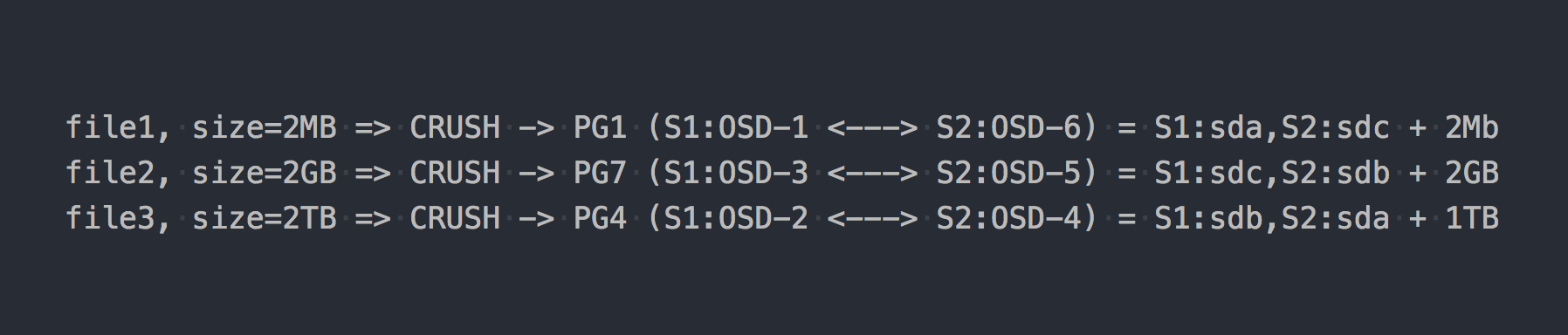
Dalam kasus RADOS, semuanya menjadi lebih rumit, setuju.
Kemudian CRUSH (Replikasi Terkendali Di Bawah Scashing Hashing) muncul di rantai. CRUSH adalah algoritma yang digunakan RADOS (kami akan kembali lagi nanti). Dalam kasus khusus ini, menggunakan algoritma ini, ditentukan di mana file harus ditulis ke PG mana. Di sini CRUSH melakukan fungsi yang sama dengan DHT di gl. Sebagai hasil dari distribusi file pseudo-acak pada PG, kami mendapatkan semua masalah yang sama seperti gl, hanya pada skema yang lebih kompleks.
Tapi saya sengaja diam tentang satu hal penting. Hampir tidak ada yang menggunakan RADOS dalam bentuk murni. Untuk pekerjaan mudah dengan RADOS, lapisan berikut dikembangkan: RBD, CephFS, RGW, yang sudah saya sebutkan.
Semua penerjemah ini (klien RADOS) menyediakan antarmuka klien yang berbeda, tetapi mereka serupa dalam pekerjaan mereka dengan RADOS. Kesamaan yang paling penting adalah bahwa semua data yang melewati mereka dipotong-potong dan dimasukkan ke dalam RADOS sebagai objek RADOS yang terpisah. Secara default, klien resmi memotong arus input menjadi 4MB. Untuk RBD, ukuran garis dapat diatur saat membuat volume. Dalam kasus CephFS, ini adalah atribut (xattr) dari file dan dapat dikelola pada tingkat file individual atau untuk semua file katalog. Nah, RGW juga memiliki parameter yang sesuai.
Sekarang anggaplah kita menumpuk CephFS di atas kumpulan RADOS yang ditampilkan dalam contoh sebelumnya. Sekarang sistem yang dipermasalahkan sepenuhnya sejajar dan menyediakan antarmuka akses file yang identik.
Jika kita menulis file pengujian kita kembali ke CephFS baru, kita akan menemukan distribusi data yang sangat seragam dan hampir seragam pada OSD. Sebagai contoh, file2 ukuran 2GB akan dibagi menjadi 512 buah, yang akan didistribusikan di berbagai Pg berbeda dan, sebagai hasilnya, di berbagai OSD hampir seragam, dan ini praktis memecahkan masalah dengan distribusi data yang dijelaskan di atas.
Dalam contoh kami, hanya 8 PG yang digunakan, walaupun direkomendasikan untuk memiliki ~ 100 PG pada satu OSD. Dan Anda membutuhkan 2 kumpulan agar CephFS bekerja. Anda juga memerlukan beberapa daemon layanan agar RADOS bekerja pada prinsipnya. Jangan berpikir bahwa semuanya begitu sederhana, saya secara khusus menghilangkan banyak, agar tidak menyimpang dari esensi.
Jadi sekarang CephFS tampaknya lebih menarik, bukan? Tetapi saya tidak menyebutkan poin penting lain, kali ini tentang gl. Gl juga memiliki mekanisme untuk memotong file menjadi potongan dan menjalankan potongan itu melalui DHT. Yang disebut dengan sharding ( Sharding ).
Lima menit sejarah
Pada 21 April 2016, tim pengembang Ceph merilis "Jewel", rilis Ceph pertama di mana CephFS dianggap stabil.
Ini sekarang semua kiri dan kanan berteriak tentang CephFS! Dan 3-4 tahun yang lalu untuk menggunakannya setidaknya akan menjadi keputusan yang meragukan. Kami mencari solusi lain, dan gl dengan arsitektur yang dijelaskan di atas tidak baik. Tapi kami lebih mempercayainya daripada CephFS, dan menunggu pecahannya, yang sedang bersiap untuk rilis.
Dan ini dia hari X:
4 Juni 2015 - Komunitas Gluster hari ini mengumumkan ketersediaan umum perangkat lunak penyimpanan terbuka yang ditentukan oleh GlusterFS 3.7.
3,7 - versi pertama gl, di mana sharding diumumkan sebagai peluang percobaan. Mereka memiliki hampir setahun sebelum rilis stabil CephFS untuk mendapatkan pijakan di podium ...
Jadi sharding artinya. Seperti semua yang ada di gl, ini diimplementasikan dalam penerjemah terpisah, yang berdiri di atas DHT (juga penerjemah) pada tumpukan. Karena lebih tinggi dari DHT, DHT menerima serpihan siap pakai pada input dan mendistribusikannya di antara kelompok replikasi sebagai file biasa. Sharding diaktifkan pada level volume individu. Ukuran beling dapat diatur, secara default - 4MB, seperti lotion Ceph.
Ketika saya melakukan tes pertama saya sangat senang! Saya mengatakan kepada semua orang bahwa gl sekarang adalah hal utama dan sekarang kita akan hidup! Dengan diaktifkannya sharding, merekam satu file berjalan secara paralel ke grup replikasi yang berbeda. Dekompresi setelah kompresi “On-Write” dapat menjadi tambahan ke level shard. Di hadapan penembakan cache di sini juga, semuanya menjadi baik dan pecahan yang terpisah dipindahkan ke cache, dan bukan seluruh file. Secara umum, saya bersukacita, karena sepertinya dia mendapatkan alat yang sangat keren di tangannya.
Tetap menunggu perbaikan bug pertama dan status "siap untuk produksi". Tapi semuanya ternyata tidak begitu cerah ... Agar tidak meregangkan artikel dengan daftar bug kritis yang terkait dengan sharding, sekarang dan kemudian muncul di versi berikutnya, saya hanya bisa mengatakan bahwa "masalah utama" terakhir dengan deskripsi berikut:
Memperluas volume kilau yang terbuang dapat menyebabkan file rusak. Volume yang diiris biasanya digunakan untuk gambar VM, jika volume tersebut diperluas atau mungkin dikontrak (yaitu menambah / menghapus batu bata dan menyeimbangkan kembali) ada laporan bahwa gambar VM menjadi rusak.
ditutup pada rilis 3.13.2, 20 Januari 2018 ... mungkin ini bukan yang terakhir?
Mengomentari salah satu artikel kami tentang ini, bisa dikatakan, secara langsung.
RedHat dalam dokumentasinya untuk RedHat Gluster Storage 3.4 saat ini mencatat bahwa satu-satunya kasing yang mereka dukung adalah penyimpanan untuk disk VM.
Sharding memiliki satu use case yang didukung: dalam konteks penyediaan Red Hat Gluster Storage sebagai domain penyimpanan untuk Red Hat Enterprise Virtualization, untuk menyediakan penyimpanan untuk gambar mesin virtual langsung. Perhatikan bahwa sharding juga merupakan persyaratan untuk kasus penggunaan ini, karena memberikan peningkatan kinerja yang signifikan dibandingkan implementasi sebelumnya.
Saya tidak tahu mengapa pembatasan seperti itu, tetapi Anda harus mengakui, itu mengkhawatirkan.
Sekarang saya memiliki segalanya untuk Anda
Kedua sistem menggunakan fungsi hash untuk mendistribusikan data secara acak ke seluruh disk.
Untuk RADOS, tampilannya seperti ini:
PG = pool_id + "." + jenkins_hash(object_name) % pg_coun # eg pool id=5 => pg = 5.1f OSD = crush_hash_based_on_jenkins(PG) # eg pg=5.1f => OSD = 12
Gl menggunakan apa yang disebut hashing konsisten . Setiap bata mendapatkan "rentang dalam ruang hash 32-bit". Artinya, semua batu bata berbagi seluruh ruang hash alamat linear tanpa memotong rentang atau lubang. Klien menjalankan nama file melalui fungsi hash, dan kemudian menentukan rentang hash mana yang diterima oleh hash. Dengan demikian batu bata dipilih. Jika ada beberapa batu bata di grup replikasi, maka mereka semua memiliki rentang hash yang sama. Sesuatu seperti ini:
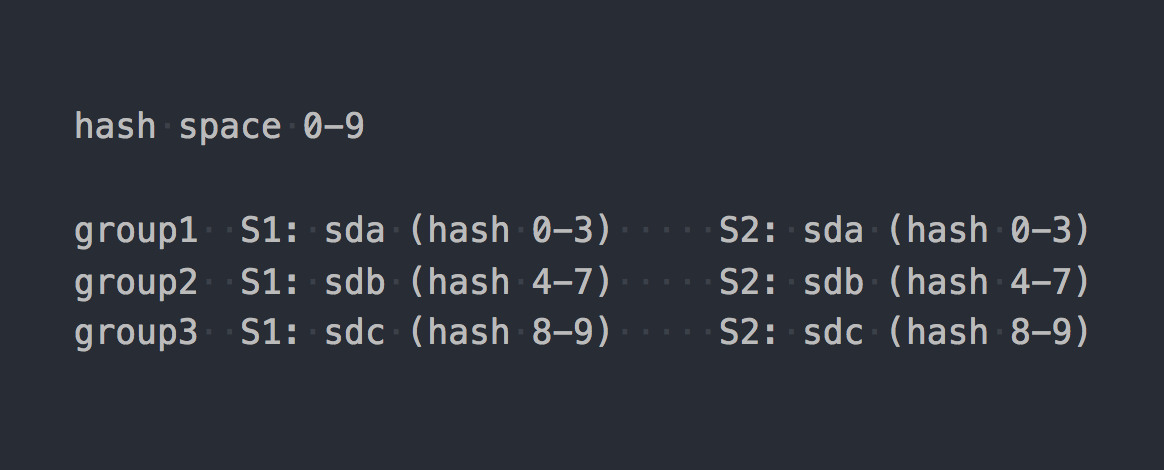
Jika kita membawa karya dua sistem ke bentuk logis tertentu, itu akan menghasilkan sesuatu seperti ini:
file -> HASH -> placement_unit
di mana penempatan_unit dalam kasus RADOS adalah PG, dan dalam kasus gl itu adalah grup replikasi dari beberapa batu bata.
Jadi, fungsi hash, maka yang ini mendistribusikan, mendistribusikan file, dan tiba-tiba ternyata satu penempatan_unit digunakan lebih dari yang lain. Itulah fitur dasar dari sistem distribusi hash. Dan kami menghadapi tugas yang sangat umum - untuk ketidakseimbangan data.
Gl mampu membangun kembali, tetapi karena arsitektur dengan rentang hash yang dijelaskan di atas, Anda dapat menjalankan pembangunan kembali sebanyak yang Anda suka, tetapi tidak ada rentang hash (dan, sebagai hasilnya, data) tidak akan bergerak. Satu-satunya kriteria untuk mendistribusikan ulang rentang hash adalah perubahan kapasitas volume. Dan Anda memiliki satu opsi tersisa - untuk menambahkan batu bata. Dan jika kita berbicara tentang volume dengan replikasi, maka kita harus menambahkan grup replikasi keseluruhan, yaitu, dua batu bata baru di pengaturan kita. Setelah memperluas volume, Anda dapat mulai membangun kembali - rentang hash akan didistribusikan kembali dengan mempertimbangkan grup baru dan data akan didistribusikan. Ketika grup replikasi dihapus, rentang hash dialokasikan secara otomatis.
RADOS memiliki seluruh kemungkinan mobil. Dalam artikel Ceph, saya banyak mengeluh tentang konsep PG, tetapi di sini, dibandingkan dengan gl, tentu saja, RADOS tentang menunggang kuda. Setiap OSD memiliki bobotnya sendiri, biasanya diatur berdasarkan ukuran disk. Pada gilirannya, PG didistribusikan oleh OSD tergantung pada berat yang terakhir. Semuanya, lalu kita hanya mengubah berat OSD naik atau turun dan PG (beserta data) mulai pindah ke OSD lain. Juga, setiap OSD memiliki bobot penyesuaian tambahan, yang memungkinkan Anda untuk menyeimbangkan data antara disk satu server. Semua ini melekat dalam CRUSH. Keuntungan utama adalah bahwa tidak perlu memperluas kapasitas kumpulan untuk ketidakseimbangan data dengan lebih baik. Dan tidak perlu menambahkan disk dalam grup, Anda hanya dapat menambahkan satu OSD dan sebagian PG akan ditransfer ke dalamnya.
Ya, ada kemungkinan bahwa ketika membuat kumpulan mereka tidak membuat cukup PG dan ternyata masing-masing PG cukup besar volumenya, dan ke mana pun mereka bergerak, ketidakseimbangan akan tetap ada. Dalam hal ini, Anda dapat meningkatkan jumlah PG, dan mereka dibagi menjadi yang lebih kecil. Ya, jika cluster penuh dengan data, maka itu menyakitkan, tetapi hal utama dalam perbandingan kami adalah bahwa ada peluang seperti itu. Sekarang hanya peningkatan jumlah PG yang diizinkan dan dengan ini Anda harus lebih berhati-hati, tetapi dalam versi Ceph - Nautilus berikutnya akan ada dukungan untuk mengurangi jumlah PG (penggabungan pg).
Replikasi data
Kumpulan dan volume pengujian kami memiliki faktor replikasi 2. Yang menarik, sistem yang dimaksud menggunakan pendekatan berbeda untuk mencapai jumlah replika ini.
Dalam kasus RADOS, skema perekaman terlihat seperti ini:
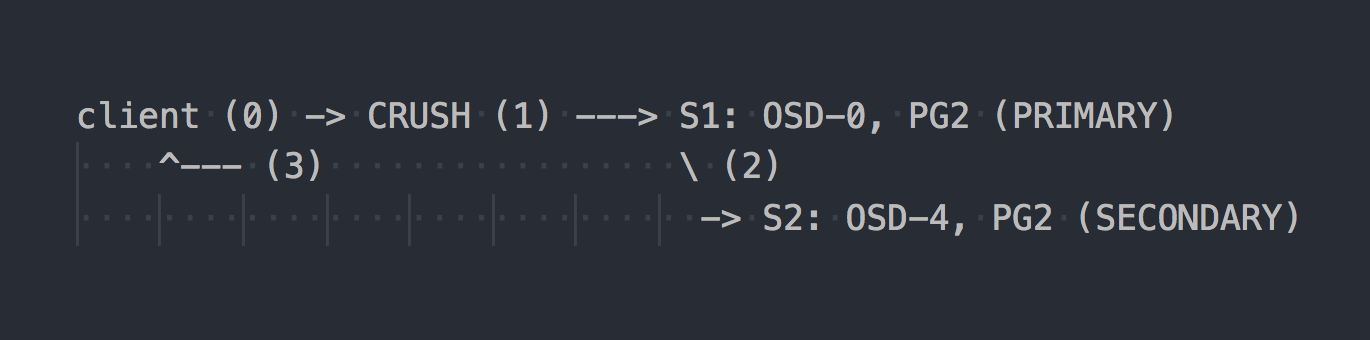
Klien mengetahui topologi seluruh kluster, menggunakan CRUSH (langkah 0) untuk memilih PG tertentu untuk ditulis, menulis ke PRIMARY PG pada OSD-0 (langkah 1), kemudian OSD-0 secara sinkron mereplikasi data ke SECONDARY PG (langkah 2), dan hanya setelah berhasil / tidak berhasil langkah 2, OSD mengkonfirmasi / tidak mengkonfirmasi operasi ke klien (langkah 3). Replikasi data antara dua OSD transparan untuk klien. OSD umumnya dapat menggunakan "cluster" terpisah, jaringan yang lebih cepat untuk replikasi data.
Jika replikasi tiga dikonfigurasi, maka itu juga berjalan secara sinkron dengan PRIMARY OSD pada dua SECONDARY, transparan untuk klien ... well, hanya saja yang diperbolehkan lebih tinggi.
Gl bekerja secara berbeda:
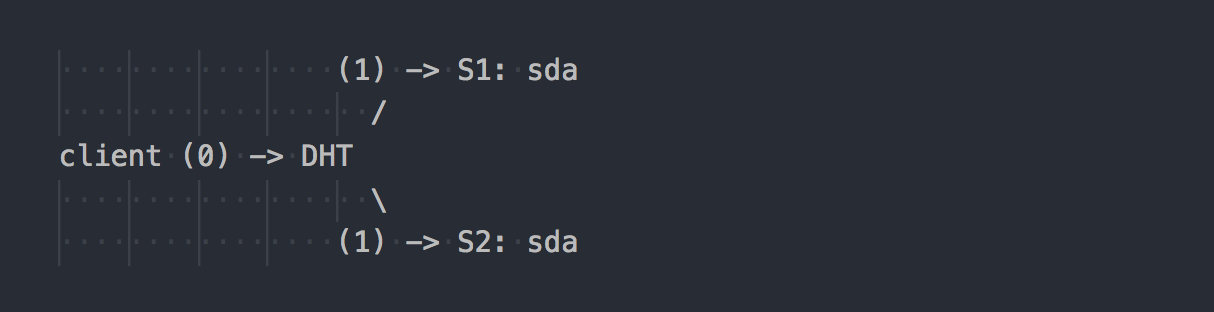
Klien tahu topologi volume, menggunakan DHT (langkah 0) untuk menentukan bata yang diinginkan, kemudian menulis ke sana (langkah 1). Semuanya sederhana dan jelas. Tapi di sini kita ingat bahwa semua batu bata dalam kelompok replikasi memiliki kisaran hash yang sama. Dan fitur minor ini membuat seluruh hari libur. Klien menulis secara paralel ke semua batu bata yang memiliki rentang hash yang cocok.
Dalam kasus kami, dengan replikasi ganda, klien melakukan perekaman ganda secara paralel pada dua batu bata yang berbeda. Selama replikasi tiga kali lipat, perekaman rangkap tiga akan dilakukan, masing-masing, dan 1MB data akan berubah secara kasar menjadi 3MB lalu lintas jaringan dari klien ke sisi gl-server. Setuju, konsep sistem tegak lurus.
Dalam skema seperti itu, lebih banyak pekerjaan yang ditugaskan untuk klien gl, dan, sebagai akibatnya, ia membutuhkan lebih banyak CPU, well, saya sudah katakan tentang jaringan.
Replikasi dilakukan oleh penerjemah AFP (Automatic File Replication) - Sebuah xlator sisi klien yang melakukan replikasi sinkron. Replika menulis ke semua bata replika → Menggunakan model transaksi.
Jika perlu, sinkronkan replika dalam kelompok (penyembuhan), misalnya, setelah tidak tersedianya sementara satu batu bata, para daemon glagon melakukan ini sendiri menggunakan AFP bawaan, transparan untuk klien dan tanpa partisipasi mereka.
Sangat menarik bahwa jika Anda bekerja bukan melalui klien gl asli, tetapi menulis melalui server NFS built-in di gl, maka kita akan mendapatkan perilaku yang sama seperti RADOS. Dalam hal ini, AFP akan digunakan dalam dasmon untuk mereplikasi data tanpa intervensi klien. Tetapi NFS bawaan diamankan dalam gl v4, dan jika Anda menginginkan perilaku ini, disarankan untuk menggunakan NFS-Ganesha.
Omong-omong, karena perilaku yang sangat berbeda saat menggunakan NFS dan klien asli, Anda dapat melihat indikator kinerja yang sangat berbeda.
Apakah Anda memiliki kluster yang sama, hanya "di lutut"?
Saya sering melihat pada diskusi Internet tentang semua jenis pengaturan tempurung lutut, di mana sekelompok data dibangun dari apa yang ada. Dalam hal ini, solusi berbasis RADOS dapat memberi Anda lebih banyak kebebasan saat memilih drive. Di RADOS, Anda dapat menambahkan drive dengan hampir semua ukuran. Setiap disk akan memiliki bobot yang sesuai dengan ukurannya (biasanya), dan data akan didistribusikan di seluruh disk hampir secara proporsional dengan bobotnya. Dalam kasus gl, tidak ada konsep "disk terpisah" dalam volume replikasi. Disk ditambahkan berpasangan pada replikasi ganda atau tiga kali lipat pada triple. Jika ada disk dengan ukuran berbeda dalam satu grup replikasi, maka Anda akan menemukan tempat di disk terkecil dalam grup dan tidak menggunakan kapasitas disk besar. Dalam skema seperti itu, gl akan menganggap bahwa kapasitas satu grup replikasi sama dengan kapasitas disk terkecil dalam grup, yang logis. Pada saat yang sama, diperbolehkan untuk memiliki grup replikasi yang terdiri dari disk dengan ukuran berbeda - grup dengan ukuran berbeda. Grup yang lebih besar dapat menerima rentang hash yang lebih besar relatif terhadap grup lain dan, sebagai hasilnya, menerima lebih banyak data.
Kami telah tinggal bersama Ceph untuk tahun kelima. Kami mulai dengan disk dengan volume yang sama, sekarang kami memperkenalkan yang lebih luas. Dengan Ceph, Anda dapat menghapus disk dan menggantinya dengan yang lebih besar atau sedikit lebih kecil tanpa kesulitan arsitektur. Dengan gl, semuanya lebih rumit - mengeluarkan disk 2 TB - tolong masukkan yang sama. Baik, atau menarik seluruh kelompok secara keseluruhan, yang tidak terlalu baik, setuju.
Kegagalan
Kami sudah sedikit berkenalan dengan arsitektur dari dua solusi dan sekarang kita dapat berbicara tentang bagaimana hidup dengannya dan apa saja fitur-fiturnya ketika melakukan servis.
Misalkan kita memiliki sda pada s1 yang ditolak - hal yang umum.
Dalam kasus gl:
- salinan data pada disk langsung yang tersisa dalam grup tidak secara otomatis didistribusikan ke grup lain;
- sampai disk diganti, hanya satu salinan data yang tersisa;
- ketika mengganti disk yang gagal dengan yang baru, replikasi dilakukan dari disk yang bekerja ke yang baru (1 on 1).
Ini seperti melayani rak dengan banyak RAID-1. Ya, dengan replikasi tiga kali lipat, jika satu drive gagal, tidak satu salinan tetap, tetapi dua, tetapi masih pendekatan ini memiliki kelemahan serius, dan saya akan menunjukkan kepada mereka dengan contoh yang baik dengan RADOS.
Misalkan kita memiliki sda pada S1 (OSD-0) gagal - hal yang umum:
- PG yang menggunakan OSD-0 akan secara otomatis dipetakan kembali ke OSD lain setelah 10 menit (default). Dalam contoh kita, pada OSD 1 dan 2. Jika ada lebih banyak server, maka pada jumlah OSD yang lebih besar.
- PG yang menyimpan salinan data kedua yang bertahan akan secara otomatis mereplikasi mereka ke OSD di mana PG yang dipulihkan ditransfer. Ternyata replikasi banyak-ke-banyak, bukan replikasi satu-ke-satu seperti gl.
- Ketika disk baru diperkenalkan, bukan yang rusak, beberapa PG akan diakumulasikan sesuai dengan bobotnya di OSD baru dan data dari OSD lain akan didistribusikan kembali.
Saya pikir tidak masuk akal untuk menjelaskan keunggulan arsitektural RADOS. Anda tidak dapat bergerak ketika menerima surat yang mengatakan bahwa drive gagal. Dan ketika Anda mulai bekerja di pagi hari, temukan bahwa semua salinan yang hilang telah dipulihkan ke lusinan OSD lain atau dalam proses. Pada kelompok besar, di mana ratusan PG tersebar di banyak disk, pemulihan data satu OSD dapat terjadi pada kecepatan yang jauh lebih tinggi daripada kecepatan satu disk karena fakta bahwa puluhan OSD terlibat (baca dan tulis). Nah, Anda juga jangan lupa tentang load balancing.
Scaling
Dalam konteks ini, saya mungkin akan memberikan alas gl. Dalam sebuah artikel di Ceph, saya sudah menulis tentang beberapa kompleksitas penskalaan RADOS yang terkait dengan konsep PG. Jika peningkatan PG dengan pertumbuhan cluster masih bisa dialami, bagaimana dengan Ceph MDS tidak jelas. CephFS berjalan di atas RADOS dan menggunakan kumpulan terpisah untuk metadata dan proses khusus, server meta ceph (MDS), untuk melayani metadata sistem file dan mengoordinasikan semua operasi dengan FS. Saya tidak mengatakan bahwa memiliki MDS mengakhiri skalabilitas CephFS, tidak, terutama karena Anda dapat menjalankan beberapa MDS dalam mode aktif-aktif. Saya hanya ingin mencatat bahwa secara arsitektur tanpa semua ini. Ia tidak memiliki mitra PG, tidak seperti MDS. Gl benar-benar berskala sempurna hanya dengan menambahkan grup replikasi, hampir secara linear.
Kembali pada hari-hari sebelum CephFS, kami merancang solusi untuk petabyte data dan melihat gl. Kemudian kami memiliki keraguan tentang skalabilitas gl dan kami menemukan melalui milis. Inilah salah satu jawabannya (T: pertanyaan saya):
Saya menggunakan 60 server masing-masing memiliki total disk 26x8TB 1560 disk 16 + 4 volume EC dengan 9PB ruang yang dapat digunakan.
T: Apakah Anda menggunakan libgfapi atau FUSE atau NFS di sisi klien?
Saya menggunakan FUSE dan saya memiliki hampir 1000 klien.
T: Berapa banyak file yang Anda miliki dalam volume Anda?
T: File lebih besar atau kecil?
Saya memiliki lebih dari 1 juta file dan% 13 cluster digunakan yang membuat ukuran file rata-rata 1GB.
Ukuran file minimum / maksimum adalah 100MB / 2GB. Setiap hari 10-20TB data baru memasuki volume.
T: Seberapa cepat "ls" bekerja)?
Operasi metadata lambat seperti yang Anda harapkan. Saya mencoba untuk tidak meletakkan lebih dari 2-3 ribu file dalam direktori. Kasing penggunaan saya untuk cadangan / arsip jadi saya jarang melakukan operasi metadata.
Ganti nama File
Kembali ke fungsi hash lagi. Kami telah menemukan cara file-file tertentu diarahkan ke disk tertentu, dan sekarang pertanyaannya menjadi relevan, tetapi apa yang akan terjadi ketika mengganti nama file?
Lagi pula, jika kita mengubah nama file, maka hash atas namanya juga akan berubah, yang berarti tempat file ini pada disk lain (dalam rentang hash yang berbeda) atau pada PG / OSD lain dalam kasus RADOS. Ya, kami berpikir dengan benar, dan di sini di dua sistem, semuanya kembali tegak lurus.
Dalam kasus gl, ketika mengganti nama file, nama baru dijalankan melalui fungsi hash, bata baru didefinisikan dan tautan khusus dibuat di atasnya ke bata lama, di mana file tetap tetap seperti sebelumnya. Topovka, kan? Agar data benar-benar pindah ke tempat baru, dan klien tidak perlu mengklik tautan, Anda perlu melakukan pemberontakan.
Tetapi RADOS umumnya tidak memiliki metode untuk mengganti nama objek hanya karena kebutuhan untuk pergerakan selanjutnya. Diusulkan untuk menggunakan penyalinan yang adil untuk penggantian nama, yang mengarah pada gerakan sinkron objek. Dan CephFS, yang berjalan di atas RADOS, memiliki kartu truf di lengannya dalam bentuk kumpulan dengan metadata dan MDS. Mengubah nama file tidak mempengaruhi isi file di kumpulan data.
Replikasi 2.5
Gl memiliki satu fitur yang sangat keren yang ingin saya sebutkan secara terpisah. Semua orang mengerti bahwa replikasi 2 bukanlah konfigurasi yang andal, namun demikian secara berkala terjadi agar cukup dibenarkan. Untuk melindungi dari otak-terpecah dalam skema semacam itu dan untuk memastikan konsistensi data, gl memungkinkan Anda untuk membangun volume dengan replika 2 dan arbiter tambahan. Arbiter berlaku untuk replikasi 3 atau lebih. Ini adalah bata yang sama dalam grup dengan dua lainnya, hanya saja sebenarnya hanya membuat struktur file dari file dan direktori. File pada bata semacam itu berukuran nol, tetapi atributnya yang diperluas dari sistem file (atribut diperluas) dipertahankan dalam keadaan tersinkronisasi dengan file ukuran penuh dalam replika yang sama. Saya pikir idenya jelas. Saya pikir ini adalah kesempatan keren.
Satu-satunya saat ... ukuran tempat dalam kelompok replikasi ditentukan oleh ukuran bata terkecil, dan ini berarti bahwa penengah perlu menyelipkan disk setidaknya ukuran yang sama dengan sisa dalam kelompok. Untuk melakukan ini, disarankan untuk membuat fiksi tipis (tipis) LV, ukuran besar, agar tidak menggunakan disk nyata.
Dan bagaimana dengan pelanggan?
API asli dari kedua sistem diimplementasikan dalam bentuk perpustakaan libgfapi (gl) dan libcephfs (CephFS). Binding untuk bahasa populer juga tersedia. Secara umum, dengan perpustakaan, semuanya tentang sama baiknya. NFS-Ganesha di mana-mana mendukung kedua perpustakaan sebagai FSAL, yang juga merupakan norma. Qemu juga mendukung API gl asli melalui libgfapi.
Tetapi fio (Flexible I / O Tester) telah lama dan berhasil mendukung libgfapi, tetapi tidak mendukung libcephfs. Ini adalah plus gl, karena menggunakan fio sangat bagus untuk menguji gl secara langsung. Hanya bekerja dari userspace melalui libgfapi yang akan Anda dapatkan semuanya dari gl.
Tetapi jika kita berbicara tentang sistem file POSIX dan cara memasangnya, maka gl hanya dapat menawarkan klien FUSE, dan implementasi CephFS di kernel upstream. Jelas bahwa dalam modul kernel Anda dapat melakukan trik sehingga FUSE akan menunjukkan kinerja yang lebih baik. Namun dalam praktiknya, FUSE selalu merupakan overhead pada pengalihan konteks. Saya pribadi telah melihat lebih dari sekali bagaimana FUSE membengkokkan server dual-socket dengan CSs saja.
Entah bagaimana, Linus berkata:
Filesystem Userspace? Masalahnya ada di sana. Selalu begitu. Orang-orang yang berpikir bahwa filesystem userspace realistis untuk apa pun tetapi mainan hanya sesat.
Pengembang Gl, sebaliknya, berpikir bahwa SEKERING itu keren. Ini dikatakan memberi lebih banyak fleksibilitas dan pelepasan dari versi kernel. Sedangkan bagi saya, mereka menggunakan FUSE karena gl bukan tentang kecepatan. Entah bagaimana itu ditulis - baik, itu normal, dan mengganggu implementasi di kernel benar-benar aneh.
Performa
Tidak akan ada perbandingan).
Ini terlalu rumit. Bahkan pada pengaturan yang identik terlalu sulit untuk melakukan pengujian objektif. Bagaimanapun, akan ada seseorang di komentar yang akan memberikan 100500 parameter yang "mempercepat" salah satu sistem dan mengatakan bahwa tes itu omong kosong. Karena itu, jika tertarik, silakan tes sendiri.
Kesimpulan
RADOS dan CephFS, khususnya, adalah solusi yang lebih kompleks baik dalam pemahaman, pengaturan, dan pemeliharaan.
Tetapi secara pribadi, saya suka arsitektur RADOS dan berjalan di atas CephFS lebih dari GlusterFS. Lebih banyak pegangan (PG, bobot OSD, hierarki CRUSH, dll.), Metadata CephFS meningkatkan kompleksitas, tetapi memberikan lebih banyak fleksibilitas dan membuat solusi ini lebih efektif, menurut pendapat saya.
Ceph jauh lebih cocok dengan kriteria SDS saat ini dan menurut saya lebih menjanjikan. Tapi ini pendapat saya, bagaimana menurut Anda?