Terjemahan Arsitektur Jaringan Saraf TiruanAlgoritma jaringan saraf yang dalam telah mendapatkan popularitas besar hari ini, yang sebagian besar dipastikan oleh arsitektur yang dipikirkan dengan matang. Mari kita lihat sejarah perkembangan mereka selama beberapa tahun terakhir. Jika Anda tertarik pada analisis yang lebih dalam, lihat
karya ini .
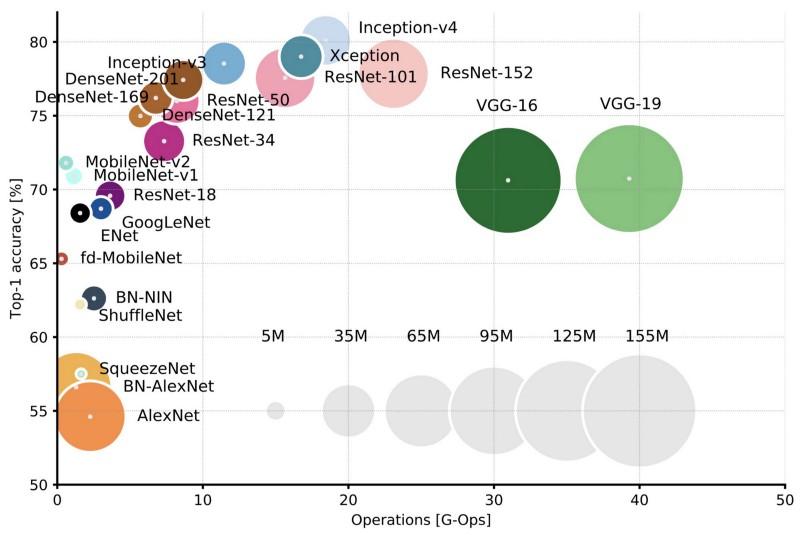 Perbandingan arsitektur populer untuk akurasi satu-potong Top-1 dan jumlah operasi yang diperlukan untuk satu lintasan langsung. Lebih detail di sini .
Perbandingan arsitektur populer untuk akurasi satu-potong Top-1 dan jumlah operasi yang diperlukan untuk satu lintasan langsung. Lebih detail di sini .Lenet5
Pada tahun 1994, salah satu jaringan saraf convolutional pertama dikembangkan, yang meletakkan dasar untuk pembelajaran yang mendalam. Karya perintis oleh Yann LeCun ini, setelah banyak iterasi yang sukses sejak 1988, disebut
LeNet5 !

Arsitektur LeNet5 telah menjadi dasar bagi pembelajaran mendalam, terutama dalam hal distribusi properti gambar di seluruh gambar. Konvolusi dengan parameter pembelajaran diizinkan menggunakan beberapa parameter untuk secara efisien mengekstraksi properti yang sama dari tempat yang berbeda. Pada tahun-tahun itu, tidak ada kartu video yang dapat mempercepat proses pembelajaran, dan bahkan prosesor sentral pun lambat. Oleh karena itu, keuntungan utama dari arsitektur adalah kemampuan untuk menyimpan parameter dan hasil perhitungan, berbeda dengan menggunakan setiap piksel sebagai data input terpisah untuk jaringan saraf multilayer besar. Di LeNet5, piksel tidak digunakan di lapisan pertama, karena gambar sangat berkorelasi spasial, jadi menggunakan piksel individual sebagai properti input tidak akan memungkinkan Anda memanfaatkan korelasi ini.
Fitur LeNet5:
- Jaringan saraf convolutional yang menggunakan urutan tiga lapisan: lapisan konvolusi, lapisan penyatuan, dan lapisan non-linearitas -> sejak publikasi karya Lekun, ini mungkin salah satu fitur utama pembelajaran mendalam dalam kaitannya dengan gambar.
- Menggunakan konvolusi untuk mengambil properti spasial.
- Subsampling menggunakan rata-rata peta spasial.
- Nonlinier dalam bentuk tangen hiperbolik atau sigmoid.
- Pengklasifikasi akhir dalam bentuk jaringan saraf multilayer (MLP).
- Matriks yang jarang dari konektivitas antara lapisan mengurangi jumlah perhitungan.
Jaringan saraf ini membentuk dasar dari banyak arsitektur berikutnya dan menginspirasi banyak peneliti.
Pengembangan
Dari tahun 1998 hingga 2010, jaringan saraf berada dalam kondisi inkubasi. Kebanyakan orang tidak memperhatikan kemampuan mereka yang terus meningkat, meskipun banyak pengembang secara bertahap mengasah algoritme mereka. Berkat masa kejayaan kamera ponsel dan semakin murahnya kamera digital, semakin banyak data pelatihan yang tersedia bagi kami. Pada saat yang sama, kemampuan komputasi tumbuh, prosesor menjadi lebih kuat, dan kartu video berubah menjadi alat komputasi utama. Semua proses ini memungkinkan pengembangan jaringan saraf, meskipun agak lambat. Ketertarikan pada tugas yang bisa diselesaikan dengan bantuan jaringan saraf tumbuh, dan akhirnya situasinya menjadi jelas ...
Dan ciresan net
Pada tahun 2010, Dan Claudiu Ciresan dan Jurgen Schmidhuber menerbitkan salah satu deskripsi pertama dari implementasi
jaringan saraf GPU . Pekerjaan mereka berisi implementasi langsung dan mundur dari jaringan saraf 9-layer pada
NVIDIA GTX 280 .
Alexnet
Pada 2012, Alexei Krizhevsky menerbitkan
AlexNet , versi LeNet yang mendalam dan diperpanjang, yang dimenangkan dengan margin lebar dalam kompetisi ImageNet.
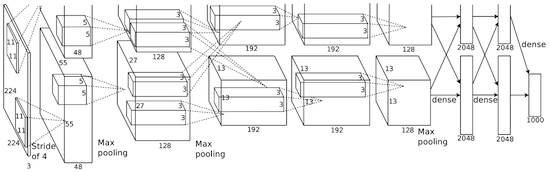
Di AlexNet, hasil perhitungan LeNet diskalakan menjadi jaringan saraf yang jauh lebih besar, yang mampu mempelajari objek yang jauh lebih kompleks dan hierarki mereka. Fitur dari solusi ini:
- Penggunaan linear rectification units (ReLU) sebagai non-linearitas.
- Penggunaan teknik membuang untuk mengabaikan selektif neuron individu selama pelatihan, yang menghindari pelatihan model yang berlebihan.
- Overlap max pooling, yang menghindari efek rata-rata pooling rata-rata.
- Menggunakan NVIDIA GTX 580 untuk mempercepat pembelajaran.
Pada saat itu, jumlah core dalam kartu video telah tumbuh secara signifikan, yang memungkinkan mereka untuk mengurangi waktu pelatihan sekitar 10 kali, dan sebagai hasilnya menjadi mungkin untuk menggunakan dataset dan gambar yang jauh lebih besar.
Keberhasilan AlexNet meluncurkan revolusi kecil, jaringan saraf convolutional telah menjadi pekerja keras pembelajaran mendalam - istilah ini sekarang berarti "jaringan saraf besar yang dapat menyelesaikan tugas-tugas yang bermanfaat."
Makan berlebihan
Pada Desember 2013, laboratorium NYU Jan Lekun menerbitkan deskripsi
Overfeat , varian dari AlexNet. Juga, artikel tersebut menggambarkan kotak pembatas yang terlatih, dan kemudian banyak karya lain tentang topik ini diterbitkan. Kami percaya bahwa lebih baik mempelajari cara membagi objek, daripada menggunakan kotak pembatas buatan.
Vgg
Jaringan
VGG dikembangkan di Oxford di setiap lapisan konvolusional yang digunakan untuk filter 3x3 pertama kali, dan bahkan menggabungkan lapisan ini dalam urutan konvolusi.
Ini bertentangan dengan prinsip-prinsip yang ditetapkan dalam LeNet, yang menurutnya konvolusi besar digunakan untuk mengekstraksi properti gambar yang sama. Alih-alih filter 9x9 dan 11x11 yang digunakan di AlexNet, mereka mulai menggunakan filter yang jauh lebih kecil yang hampir mendekati konvolusi 1x1, yang coba dihindari penulis LeNet, setidaknya di lapisan pertama jaringan. Tetapi keuntungan besar dari VGG adalah menemukan bahwa beberapa konvolusi 3x3 yang digabungkan dalam suatu urutan dapat meniru bidang reseptif yang lebih besar, misalnya, 5x5 atau 7x7. Ide-ide ini nantinya akan digunakan dalam arsitektur Inception dan ResNet.
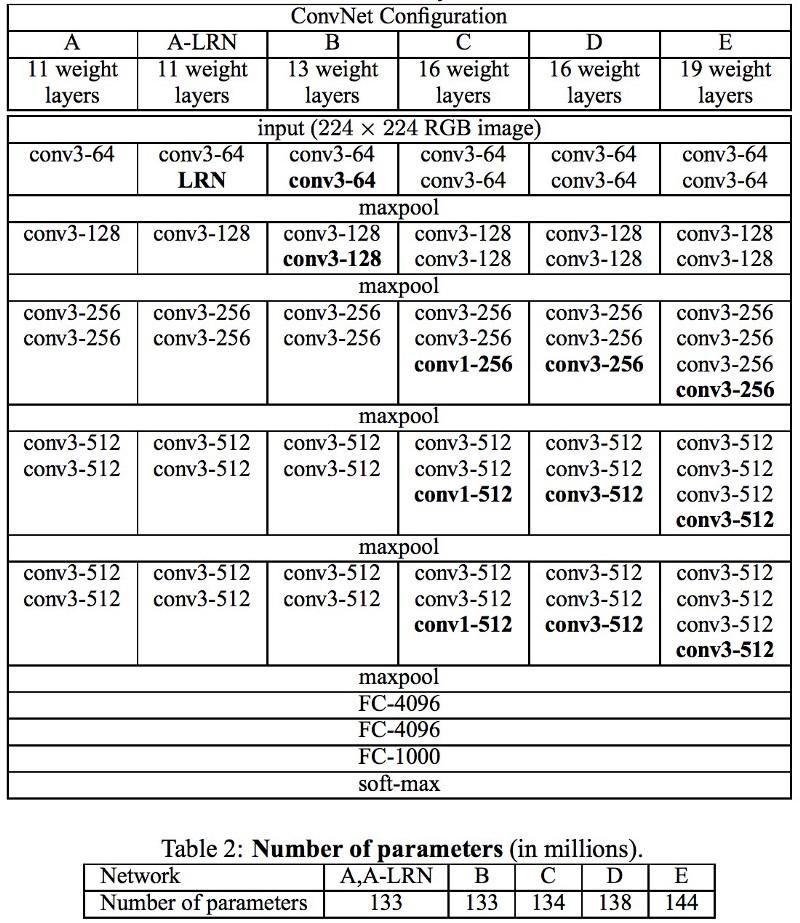
Jaringan VGG menggunakan beberapa lapisan konvolusional 3x3 untuk merepresentasikan properti kompleks. Perhatikan blok 3, 4 dan 5 di VGG-E: untuk mengekstraksi properti yang lebih kompleks dan menggabungkannya, digunakan sekuens filter 256 × 256 dan 512 × 512 3 × 3. Ini setara dengan classifier konvolusional besar 512x512 dengan tiga lapisan! Ini memberi kita sejumlah besar parameter dan kemampuan belajar yang sangat baik. Tetapi sulit untuk mempelajari jaringan seperti itu, saya harus memecahnya menjadi yang lebih kecil, menambahkan lapisan satu per satu. Alasannya adalah kurangnya cara yang efektif untuk mengatur model atau beberapa metode membatasi ruang pencarian yang besar, yang dipromosikan oleh banyak parameter.
VGG di banyak lapisan menggunakan sejumlah besar properti, sehingga pelatihan
mahal secara komputasi . Beban dapat dikurangi dengan mengurangi jumlah properti, seperti yang dilakukan pada lapisan bottleneck dari arsitektur Inception.
Jaringan-dalam-jaringan
Arsitektur
Network-in-network (NiN) didasarkan pada ide sederhana: menggunakan konvolusi 1x1 untuk meningkatkan kombinatorialitas properti di lapisan convolutional.
Di NiN, setelah setiap konvolusi, lapisan MLP spasial digunakan untuk menggabungkan properti lebih baik sebelum diumpankan ke lapisan berikutnya. Tampaknya penggunaan konvolusi 1x1 bertentangan dengan prinsip-prinsip LeNet asli, tetapi dalam kenyataannya memungkinkan menggabungkan properti lebih baik daripada hanya menjejalkan lebih banyak lapisan convolutional. Pendekatan ini berbeda dari menggunakan piksel kosong sebagai input untuk lapisan berikutnya. Dalam hal ini, konvolusi 1x1 digunakan untuk kombinasi spasial properti setelah konvolusi dalam kerangka peta properti, sehingga Anda dapat menggunakan parameter yang jauh lebih sedikit yang umum untuk semua piksel properti ini!
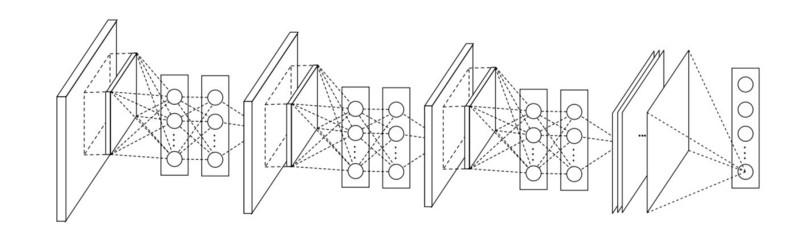
MLP dapat sangat meningkatkan efektivitas lapisan konvolusional individu dengan menggabungkan mereka ke dalam kelompok yang lebih kompleks. Gagasan ini kemudian digunakan dalam arsitektur lain, seperti ResNet, Inception, dan variannya.
GoogLeNet dan Inception
Google Christian Szegedy khawatir tentang menurunkan perhitungan dalam jaringan saraf yang dalam, dan sebagai hasilnya menciptakan
GoogLeNet, arsitektur Inception pertama .
Pada musim gugur 2014, model pembelajaran dalam menjadi sangat berguna dalam mengkategorikan konten gambar dan bingkai dari video. Banyak skeptis telah mengakui manfaat dari pembelajaran yang dalam dan jaringan saraf, dan raksasa internet, termasuk Google, telah menjadi sangat tertarik dalam menyebarkan jaringan yang efisien dan besar pada kapasitas server mereka.
Christian sedang mencari cara untuk mengurangi beban komputasi dalam jaringan saraf, mencapai kinerja tertinggi (misalnya, di ImageNet). Atau mempertahankan jumlah perhitungan, tetapi tetap meningkatkan produktivitas.
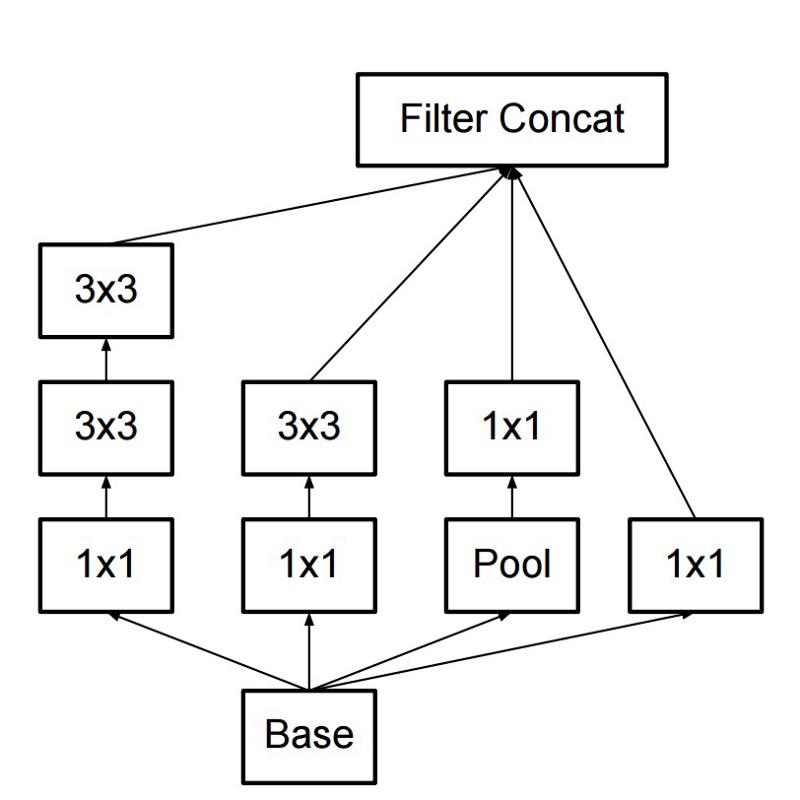
Akibatnya, perintah itu membuat modul Inception:

Sepintas, ini adalah kombinasi paralel dari filter konvolusional 1x1, 3x3 dan 5x5. Tetapi yang paling penting adalah penggunaan blok konvolusi 1x1 (NiN) untuk mengurangi jumlah properti sebelum melayani di blok paralel "mahal". Biasanya bagian ini disebut bottleneck, itu dijelaskan lebih rinci dalam bab berikutnya.
GoogLeNet menggunakan batang tanpa modul Inception sebagai lapisan awal, dan juga menggunakan penyatuan rata-rata dan pengklasifikasi softmax mirip dengan NiN. Klasifikasi ini melakukan sangat sedikit operasi dibandingkan dengan AlexNet dan VGG. Ini juga membantu menciptakan
arsitektur jaringan saraf yang sangat efisien .
Lapisan bottleneck
Lapisan ini mengurangi jumlah properti (dan karena itu operasi) di setiap lapisan, sehingga kecepatan memperoleh hasil dapat dipertahankan pada tingkat tinggi. Sebelum mentransfer data ke modul konvolusional “mahal”, jumlah properti dikurangi, katakanlah, 4 kali. Ini sangat mengurangi jumlah perhitungan, yang telah membuat arsitektur populer.
Mari kita cari tahu. Misalkan kita memiliki 256 properti pada input dan 256 pada output, dan biarkan layer Inception hanya melakukan konvolusi 3x3. Kami mendapatkan konvolusi 256x256x3x3 (589.000 operasi multiplikasi akumulasi, yaitu operasi MAC). Ini mungkin melampaui persyaratan kecepatan komputasi kami, misalkan sebuah layer diproses dalam 0,5 milidetik di Google Server. Kemudian kurangi jumlah properti untuk dilipat menjadi 64 (256/4). Dalam hal ini, pertama-tama lakukan konvolusi 1x1 256 -> 64, lalu konvolusi 64 lainnya di semua cabang Inception, dan kemudian terapkan konvolusi 1x1 dengan 64 -> 256 properti. Jumlah operasi:
- 256 × 64 × 1 × 1 = 16.000
- 64 × 64 × 3 × 3 = 36.000
- 64 × 256 × 1 × 1 = 16.000
Hanya sekitar 70.000, jumlah operasi berkurang hampir 10 kali lipat! Tetapi pada saat yang sama, kami tidak kehilangan generalisasi di lapisan ini. Lapisan bottleneck telah menunjukkan kinerja yang sangat baik pada dataset ImageNet, dan telah digunakan dalam arsitektur selanjutnya seperti ResNet. Alasan kesuksesan mereka adalah bahwa properti input berkorelasi, yang berarti bahwa Anda dapat menghilangkan redundansi dengan menggabungkan properti dengan benar dengan konvolusi 1x1. Dan setelah melipat dengan properti lebih sedikit, Anda dapat kembali menyebarkannya ke dalam kombinasi yang signifikan pada lapisan berikutnya.
Inception V3 (dan V2)
Christian dan timnya telah terbukti menjadi peneliti yang sangat efektif. Pada bulan Februari 2015, arsitektur
Inception yang dinormalisasi Batch diperkenalkan sebagai versi kedua
Inception . Batch-normalisasi menghitung rata-rata dan standar deviasi dari semua peta distribusi properti di lapisan output, dan menormalkan tanggapan mereka dengan nilai-nilai ini. Ini sesuai dengan "pemutihan" data, yaitu, respons dari semua peta saraf terletak pada kisaran yang sama dan dengan rata-rata nol. Pendekatan ini membuat pembelajaran lebih mudah, karena lapisan berikutnya tidak diperlukan untuk mengingat offset data input dan hanya dapat mencari kombinasi properti terbaik.
Pada Desember 2015,
versi baru modul Inception dan arsitektur yang sesuai dirilis . Artikel penulis lebih baik menjelaskan arsitektur GoogLeNet asli, yang menceritakan lebih banyak tentang keputusan yang dibuat. Ide-ide kunci:
- Memaksimalkan aliran informasi dalam jaringan karena keseimbangan antara kedalaman dan lebarnya. Sebelum setiap penyatuan, peta properti bertambah.
- Dengan meningkatnya kedalaman, jumlah properti atau lebar lapisan juga meningkat secara sistematis.
- Lebar setiap lapisan meningkat untuk meningkatkan kombinasi properti sebelum lapisan berikutnya.
- Sedapat mungkin, hanya 3x3 konvolusi yang digunakan. Mengingat bahwa filter 5x5 dan 7x7 dapat didekomposisi menggunakan beberapa 3x3
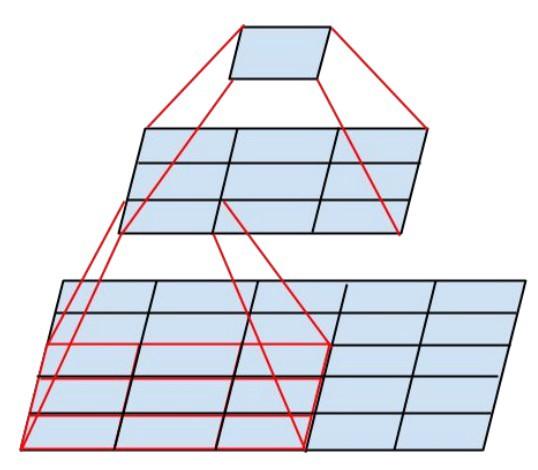
Modul Inception baru terlihat seperti ini:
- Filter juga dapat didekomposisi menggunakan konvolusi yang dihaluskan menjadi modul yang lebih kompleks:

- Modul Inception dapat mengurangi ukuran data menggunakan pooling selama perhitungan Inception. Ini mirip dengan melakukan konvolusi dengan langkah secara paralel dengan lapisan penyatuan sederhana:

Inception menggunakan lapisan penyatuan dengan softmax sebagai penggolong akhir.
Resnet
Pada bulan Desember 2015, pada waktu yang hampir bersamaan ketika arsitektur Inception v3 diperkenalkan, sebuah revolusi terjadi - mereka menerbitkan
ResNet . Ini berisi ide-ide sederhana: serahkan output dari dua lapisan konvolusional yang sukses dan memotong input untuk lapisan berikutnya!

Ide-ide semacam itu telah diajukan, misalnya, di
sini . Tetapi dalam kasus ini, penulis memotong DUA lapisan dan menerapkan pendekatan dalam skala besar. Memotong satu layer tidak memberi banyak manfaat, dan mem-bypass dua adalah kunci. Ini dapat dilihat sebagai penggolong kecil, sebagai jaringan-dalam-jaringan!
Itu juga contoh pertama dari pelatihan jaringan beberapa ratus, bahkan ribuan lapisan.
Multilayer ResNet menggunakan lapisan bottleneck mirip dengan yang digunakan dalam Inception:

Lapisan ini mengurangi jumlah properti di setiap lapisan, pertama menggunakan konvolusi 1x1 dengan output yang lebih rendah (biasanya seperempat dari input), kemudian lapisan 3x3, dan kemudian kembali melilitkan 1x1 ke dalam sejumlah besar properti. Seperti dalam kasus modul Inception, ini menghemat sumber daya komputasi sambil mempertahankan banyak kombinasi properti. Bandingkan dengan batang yang lebih kompleks dan kurang jelas dalam Inception V3 dan V4.
ResNet menggunakan lapisan penyatuan dengan softmax sebagai penggolong akhir.
Setiap hari, informasi tambahan tentang arsitektur ResNet muncul:
- Hal ini dapat dianggap sebagai sistem modul paralel dan serial secara simultan: dalam banyak modul sinyal keluar datang paralel, dan sinyal output dari masing-masing modul dihubungkan secara seri.
- ResNet dapat dianggap sebagai beberapa ansambel modul paralel atau serial .
- Ternyata ResNet biasanya beroperasi dengan blok kedalaman 20-30 yang relatif kecil yang bekerja secara paralel, daripada berjalan secara berurutan di sepanjang seluruh jaringan.
- Karena sinyal output kembali dan dimasukkan sebagai input, seperti yang dilakukan dalam RNN, ResNet dapat dianggap sebagai model yang lebih baik dari korteks serebral .
Inception V4
Christian dan timnya unggul lagi dengan
Inception versi baru .
Modul awal batang berikut sama dengan dalam Inception V3:

Dalam hal ini, modul Inception dikombinasikan dengan modul ResNet:

Arsitektur ini, menurut selera saya, lebih rumit, kurang elegan, dan juga diisi dengan solusi heuristik yang buram. Sulit untuk memahami mengapa penulis membuat keputusan ini atau itu, dan sama sulitnya untuk memberi mereka penilaian apa pun.
Oleh karena itu, hadiah untuk jaringan saraf yang bersih dan sederhana, mudah dipahami dan dimodifikasi, diberikan kepada ResNet.
Pemerasan
SqueezeNet diterbitkan baru-baru ini. Ini adalah pembuatan ulang dengan cara baru dari banyak konsep dari ResNet dan Inception. Para penulis menunjukkan bahwa meningkatkan arsitektur mengurangi ukuran jaringan dan jumlah parameter tanpa algoritma kompresi yang kompleks.
ENET
Semua fitur arsitektur terbaru digabungkan menjadi jaringan yang sangat efisien dan kompak, menggunakan sangat sedikit parameter dan daya komputasi, tetapi pada saat yang sama memberikan hasil yang sangat baik. Arsitekturnya disebut
ENet , dikembangkan oleh Adam Paszke (
Adam Paszke ). Sebagai contoh, kami menggunakannya untuk menandai objek yang sangat akurat di layar dan mem-parsing adegan.
Beberapa contoh Enet . Video-video ini tidak terkait dengan
dataset pelatihan .
Di sini Anda dapat menemukan detail teknis ENet. Ini adalah jaringan berdasarkan encoder dan decoder. Encoder dibangun pada skema kategorisasi CNN biasa, dan decoder adalah netowrk upampling yang dirancang untuk segmentasi dengan menyebarkan kategori kembali ke gambar ukuran asli. Untuk segmentasi gambar, hanya jaringan saraf yang digunakan, tidak ada algoritma lain.
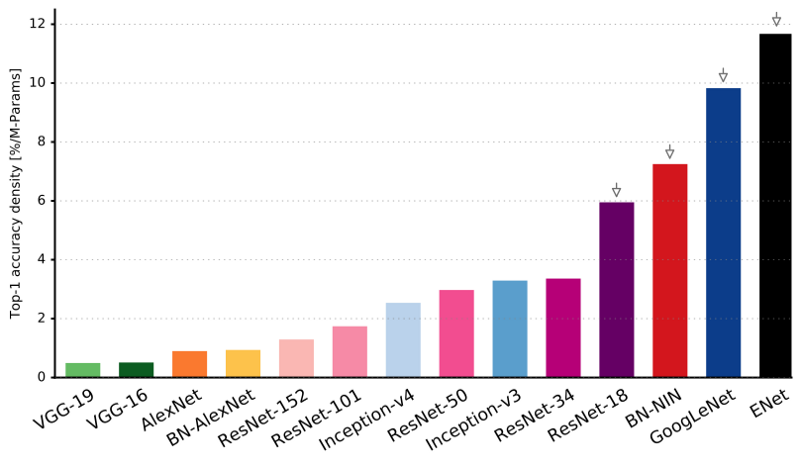
Seperti yang Anda lihat, ENet memiliki akurasi spesifik tertinggi dibandingkan dengan semua jaringan saraf lainnya.
ENet dirancang untuk menggunakan sumber daya sesedikit mungkin dari awal. Akibatnya, encoder dan decoder bersama-sama hanya menempati 0,7 MB dengan presisi fp16. Dan dengan ukuran sekecil itu, ENet tidak kalah dengan akurasi segmentasi atau lebih unggul daripada solusi jaringan saraf murni lainnya.
Analisis modul
Diterbitkan penilaian sistematis modul CNN. Ternyata bermanfaat:
- Gunakan ELU non-linearitas tanpa batch normalisasi (batchnorm) atau ReLU dengan normalisasi.
- Terapkan transformasi ruang warna RGB yang dipelajari.
- Gunakan kebijakan peluruhan tingkat pembelajaran linier.
- Gunakan jumlah layer pooling tengah dan maksimum.
- Gunakan paket mini 128 atau 256. Jika ini terlalu banyak untuk kartu video Anda, kurangi kecepatan belajar sebanding dengan ukuran paket.
- Gunakan lapisan yang sepenuhnya terhubung sebagai lapisan konvolusional dan perkiraan rata-rata untuk memberikan solusi akhir.
- Jika Anda menambah ukuran dataset pelatihan, pastikan Anda belum mencapai dataran tinggi dalam pelatihan. Kebersihan data lebih penting daripada ukuran.
- Jika Anda tidak dapat meningkatkan ukuran gambar input, mengurangi langkah di lapisan berikutnya, efeknya akan kurang lebih sama.
- Jika jaringan Anda memiliki arsitektur yang kompleks dan sangat optimal, seperti di GoogLeNet, ubahlah dengan hati-hati.
Xception
Xception memperkenalkan
arsitektur yang lebih sederhana dan lebih elegan ke dalam modul Inception, yang tidak kalah efisien dari ResNet dan Inception V4.
Seperti inilah modul Xception:
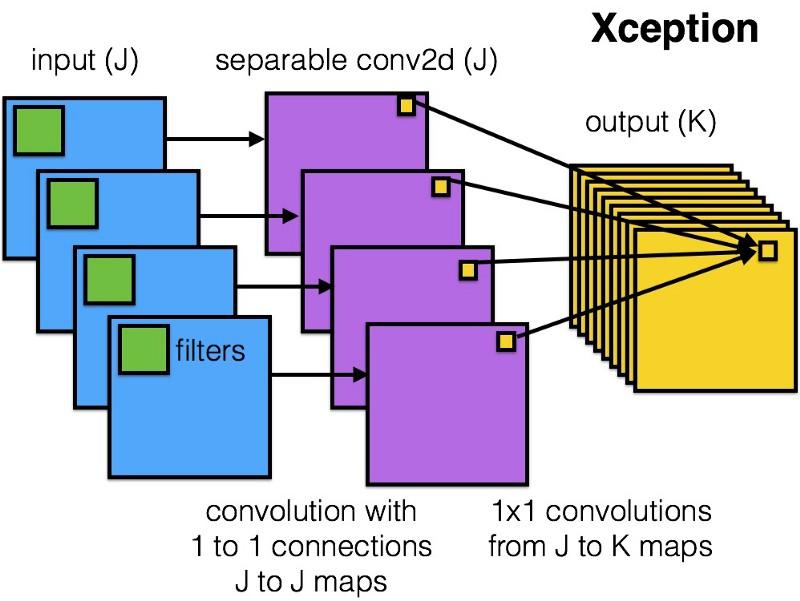
Siapa pun akan menyukai jaringan ini karena kesederhanaan dan keanggunan arsitekturnya:

Ini berisi 36 langkah konvolusi, dan ini mirip dengan ResNet-34. Pada saat yang sama, model dan kode sederhana, seperti di ResNet, dan jauh lebih menyenangkan daripada di Inception V4.
Implementasi torch7 dari jaringan ini tersedia di
sini , sementara implementasi Keras / TF tersedia di sini.
Anehnya, penulis arsitektur Xception baru-baru ini juga terinspirasi oleh
pekerjaan kami pada filter convolutional yang terpisah .
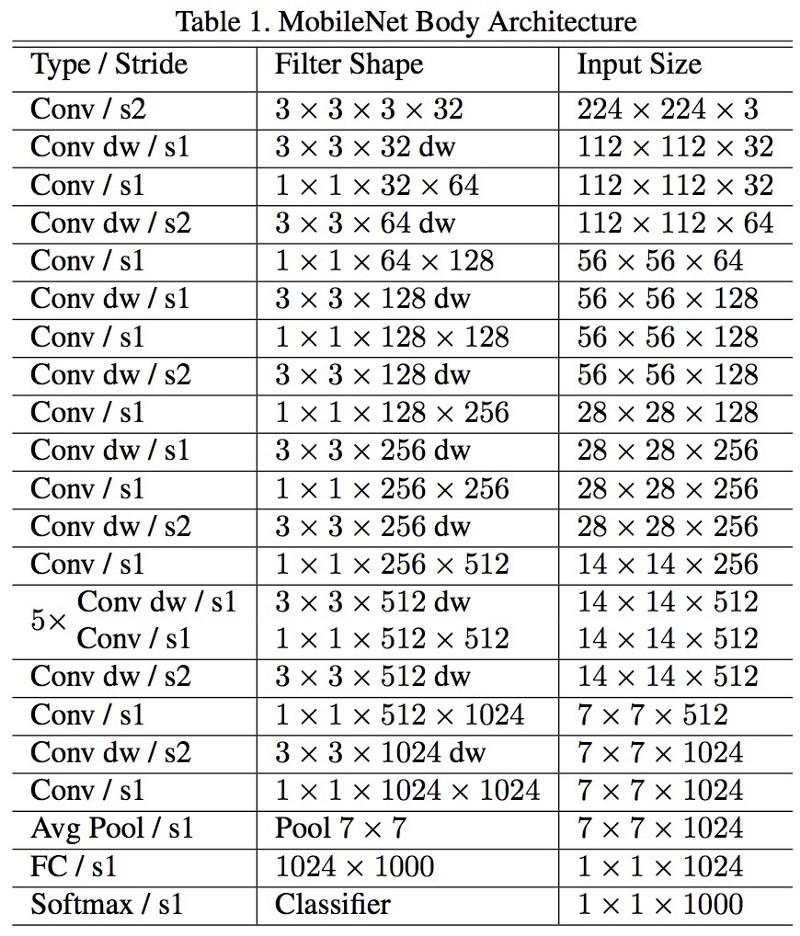
MobileNets
Arsitektur baru M
obileNets dirilis pada April 2017. Untuk mengurangi jumlah parameter, ia menggunakan konvolusi yang dapat dilepas, sama seperti pada Xception. Juga dinyatakan dalam karya ini bahwa penulis dapat sangat mengurangi jumlah parameter: sekitar setengah dalam kasus FaceNet. :
, 1 (batch of 1) Titan Xp. :
- resnet18: 0,002871
- alexnet: 0,001003
- vgg16: 0,001698
- squeezenet: 0,002725
- mobilenet: 0,033251
! , .
FractalNet , ImageNet ResNet.
, . , .
, , , , ? , .
.
, . , .
, .
.