
Halo, Habr! Dua tahun lalu kami
menulis tentang bagaimana kami beralih ke PHP 7.0 dan menghemat satu juta dolar. Pada profil memuat kami, versi baru ternyata dua kali lebih efisien dalam penggunaan CPU: beban yang kami gunakan untuk melayani ~ 600 server, setelah transisi mulai melayani ~ 300. Akibatnya, selama dua tahun kami memiliki cadangan kapasitas.
Tapi Badoo berkembang. Jumlah pengguna aktif terus meningkat. Kami meningkatkan dan mengembangkan fungsionalitas kami, berkat pengguna yang menghabiskan lebih banyak waktu dalam aplikasi. Dan ini, pada gilirannya, tercermin dalam jumlah permintaan, yang selama dua tahun terakhir meningkat 2–2,5 kali.
Kami mendapati diri kami dalam situasi di mana peningkatan kinerja dua kali lipat diratakan oleh lebih dari dua kali lipat permintaan, dan kami mulai mendekati batas-batas cluster kami. Dalam inti PHP,
optimisasi bermanfaat (JIT, preloading) sekali lagi diharapkan, tetapi mereka hanya direncanakan untuk PHP 7.4, dan versi ini akan dirilis tidak lebih awal dari setahun. Oleh karena itu, trik transisi tidak dapat diulangi sekarang - Anda perlu mengoptimalkan kode aplikasi itu sendiri.
Di bawah potongan, saya akan memberi tahu Anda bagaimana kami mendekati tugas-tugas seperti itu, alat apa yang kami gunakan, dan memberikan contoh optimisasi, ide dan pendekatan yang kami terapkan dan yang membantu kami di waktu kami.
Mengapa mengoptimalkan?
Cara termudah dan paling jelas untuk menyelesaikan masalah kinerja adalah menambahkan zat besi. Jika kode Anda berjalan di server yang sama, maka menambahkan satu lagi akan menggandakan kinerja cluster Anda. Mentransfer biaya-biaya ini ke waktu kerja pengembang, kami bertanya pada diri sendiri: apakah ia akan mendapatkan peningkatan dua kali lipat dalam produktivitas selama waktu ini karena optimisasi? Mungkin ya, tapi mungkin tidak: itu tergantung pada seberapa optimal sistem sudah bekerja dan seberapa baik pengembangnya. Di sisi lain, server yang dibeli akan tetap menjadi milik perusahaan, dan waktu yang dihabiskan tidak akan dikembalikan.
Ternyata pada volume kecil solusi yang tepat akan sering berupa penambahan zat besi.
Tetapi ambil situasi kita. Sekarang, setelah keuntungan dari beralih ke PHP 7.0 diimbangi oleh pertumbuhan aktivitas dan jumlah pengguna, kami kembali memiliki 600 server yang melayani permintaan ke aplikasi PHP. Untuk meningkatkan kapasitas sebanyak satu setengah kali, kita perlu menambah 300 server.
Ambil untuk perhitungan biaya rata-rata server - $ 4.000. 300 * 4000 = $ 1.200.000 - biaya peningkatan kapasitas satu setengah kali.
Artinya, dalam kondisi kami, kami dapat menginvestasikan sejumlah besar waktu kerja untuk mengoptimalkan sistem, dan itu masih akan lebih menguntungkan daripada membeli besi.
Perencanaan kapasitas
Sebelum melakukan sesuatu, penting untuk dipahami jika ada masalah. Jika dia tidak ada di sana, maka ada baiknya mencoba memprediksi kapan dia muncul. Proses ini disebut perencanaan kapasitas.
Indikator nyata dari adanya masalah kinerja adalah waktu respons. Memang, tidak masalah jika CPU (atau sumber daya lainnya) dimuat pada 6% atau 146%: jika klien menerima layanan dengan kualitas yang dibutuhkan dalam waktu yang memuaskan, maka semuanya bekerja dengan baik.
Kerugian dari berfokus pada waktu respons adalah bahwa biasanya mulai meningkat hanya ketika masalah sudah muncul. Jika belum, maka sulit untuk memprediksi penampilannya. Selain itu, waktu respons mencerminkan hasil pengaruh semua faktor (layanan pengereman, jaringan, drive, dll.) Dan tidak memberikan pemahaman tentang penyebab masalah.
Dalam kasus kami, CPU biasanya merupakan hambatan, jadi ketika merencanakan ukuran dan kinerja cluster, kami terutama memperhatikan metrik yang terkait dengan penggunaannya. Kami mengumpulkan penggunaan CPU dari semua mesin kami dan membuat grafik dengan nilai rata-rata, median, persentil ke-75 dan ke-95:
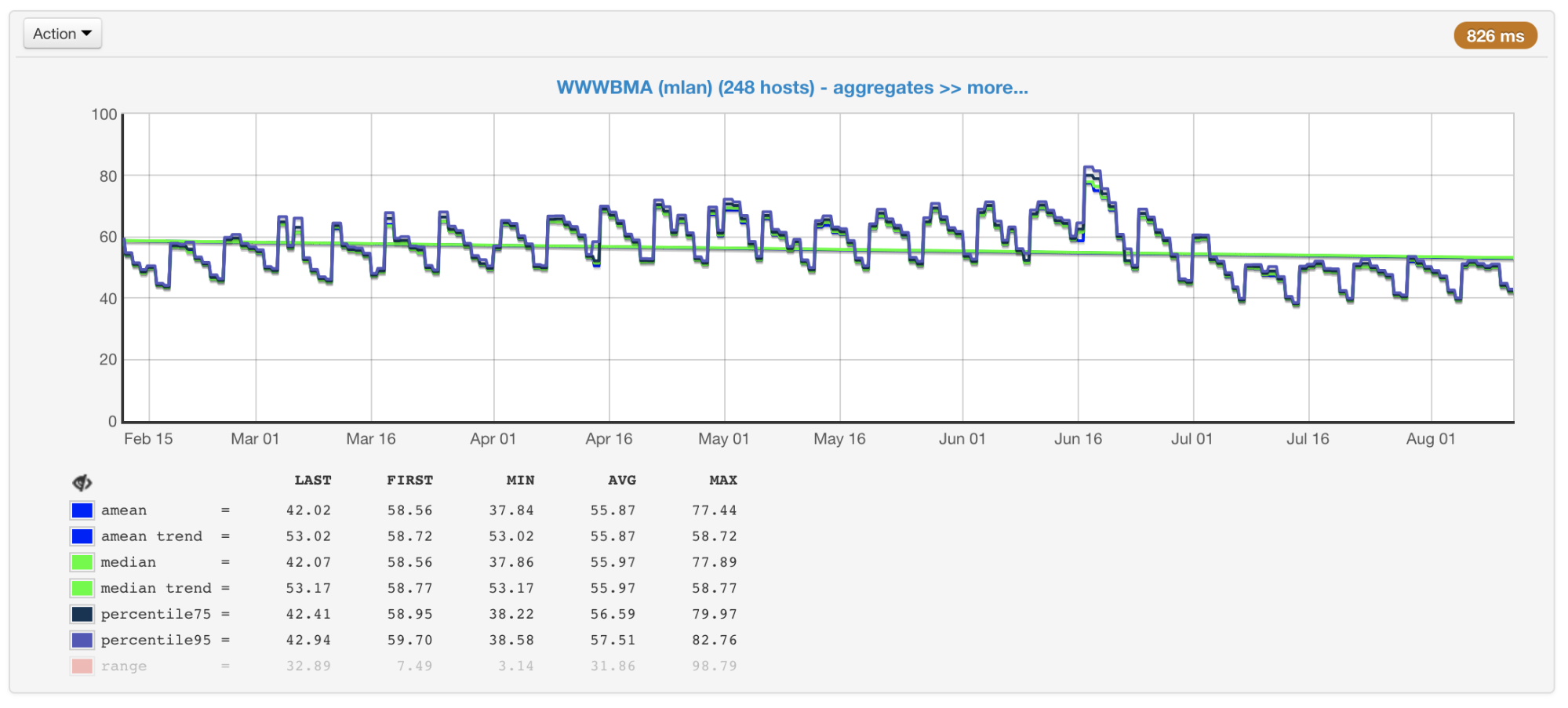 Pemanfaatan CPU dari mesin cluster dalam persen: rata-rata, median, persentil
Pemanfaatan CPU dari mesin cluster dalam persen: rata-rata, median, persentilAda ratusan mesin di cluster kami yang telah ditambahkan di sana selama bertahun-tahun. Mereka berbeda dalam konfigurasi dan kinerja (cluster tidak homogen). Penyeimbang kami memperhitungkan ini (
artikel dan
video ) dan memuat mesin sesuai dengan kemampuan mereka. Untuk mengendalikan proses ini, kami juga memiliki jadwal mesin bermuatan maksimum dan minimum.
 Mesin cluster paling banyak dan paling sedikit dimuat
Mesin cluster paling banyak dan paling sedikit dimuatJika Anda melihat grafik ini (atau hanya pada output dari perintah atas) dan melihat beban CPU 50%, Anda mungkin berpikir bahwa kami masih memiliki margin untuk peningkatan beban dua kali lipat. Tetapi sebenarnya ini biasanya tidak demikian. Dan inilah alasannya.
Threading hiper
Bayangkan satu inti tanpa hipertensi. Kami memuatnya dengan satu utas terikat-CPU. Kita akan melihat 100% memuat di atas.
Sekarang nyalakan hyperreading pada kernel ini dan muat dengan cara yang persis sama. Di atas, kita akan melihat dua core logis, dan total beban akan menjadi 50% (biasanya pada satu 0%, dan yang lain - 100%).
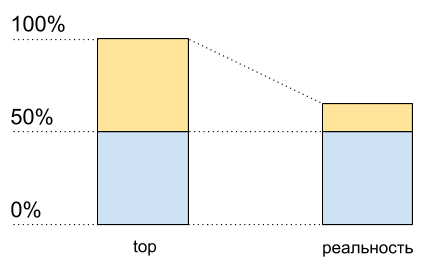 Pemanfaatan CPU: data teratas dan apa yang sebenarnya terjadi
Pemanfaatan CPU: data teratas dan apa yang sebenarnya terjadiSeolah prosesor hanya dimuat 50%. Tetapi secara fisik tidak ada inti gratis tambahan yang muncul. Hypertreading memungkinkan
dalam beberapa kasus untuk mengeksekusi pada satu inti fisik lebih dari satu proses pada satu waktu. Tapi ini jauh dari menggandakan kinerja dalam situasi khusus, meskipun pada grafik penggunaan CPU sepertinya setengah sumber daya: dari 50% menjadi 100%.
Ini berarti bahwa setelah 50% penggunaan CPU ketika hipertensi diaktifkan, itu tidak akan tumbuh sama seperti sebelumnya.
Saya menulis kode ini untuk menunjukkan (ini adalah semacam kasus sintetis, dalam kenyataannya hasilnya akan berbeda):
Kode skrip<?php $concurrency = $_SERVER['argv'][1] ?? 1; $hashes = 100000000; $chunkSize = intval($hashes / $concurrency); $t1 = microtime(true); $children = array(); for ($i = 0; $i < $concurrency; $i++) { $pid = pcntl_fork(); if (0 === $pid) { $first = $i * $chunkSize; $last = ($i + 1) * $chunkSize - 1; for ($j = $first; $j < $last; $j++) { $dummy = md5($j); } printf("[%d]: %d hashes in %0.4f sec\n", $i, $last - $first, microtime(true) - $t1); exit; } else { $children[$pid] = 1; } } while (count($children) > 0) { $pid = pcntl_waitpid(-1, $status); if ($pid > 0) { unset($children[$pid]); } else { exit("Got a error pid=$pid"); } }
Saya memiliki dua inti fisik di laptop saya. Jalankan kode ini dengan data input yang berbeda untuk mengukur kinerjanya dengan sejumlah proses C paralel yang berbeda.
Kami memplot hasil peluncuran:
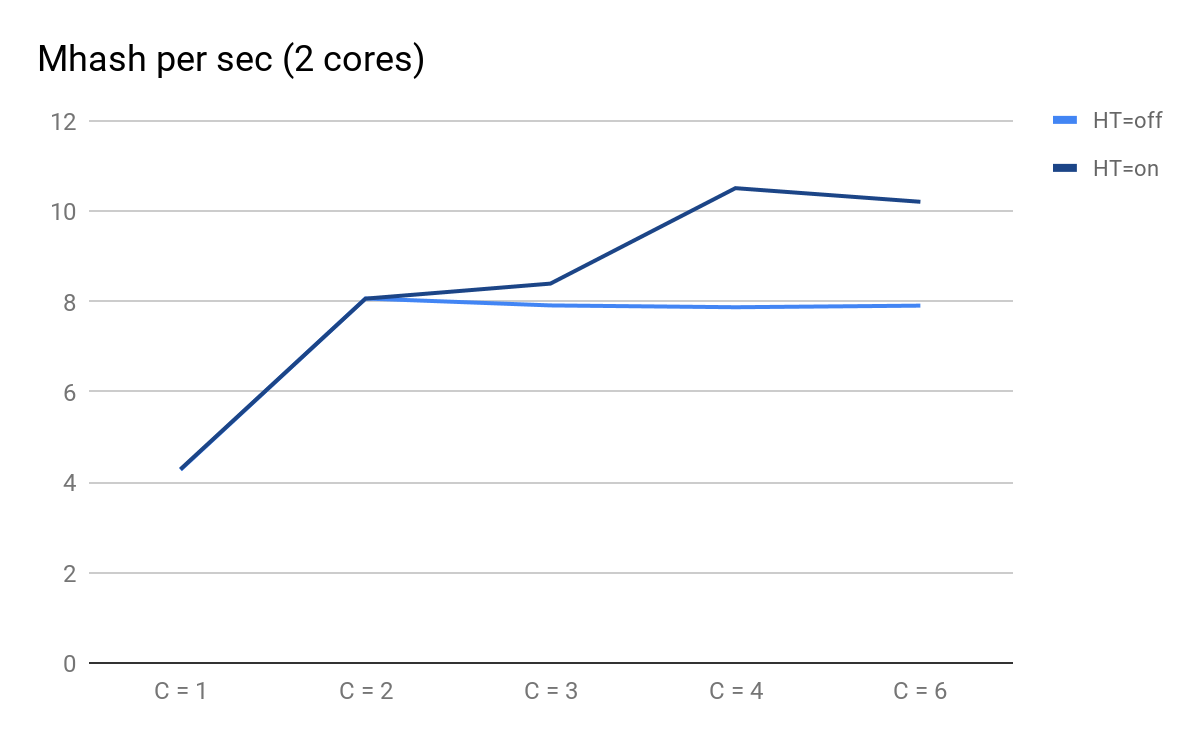 Kinerja skrip tergantung pada jumlah proses paralel
Kinerja skrip tergantung pada jumlah proses paralelApa yang dapat Anda perhatikan:
- C = 1 dan C = 2 diperkirakan sama untuk HT = on dan HT = off, kinerja berlipat ganda ketika inti fisik ditambahkan;
- pada C = 3, keuntungan HT menjadi nyata: untuk HT = aktif, kami bisa mendapatkan kinerja tambahan, sedangkan untuk HT = mati dengan C = 3 dan seterusnya mulai menurun dengan dapat diprediksi secara perlahan;
- pada C = 4 kita melihat semua manfaat HT; kami dapat memeras tambahan 30% produktivitas, tetapi dibandingkan dengan C = 2 saat ini, penggunaan CPU meningkat dari 50% menjadi 100%.
Total, melihat di atas 50% dari beban CPU, ketika menjalankan skrip ini, kami mendapatkan 8.065 Mhash / detik, dan pada 100% - 10.511 Mhash / detik. Ini berarti bahwa sekitar 50% dari yang teratas, kita mendapatkan 8.065 / 10.511 ~ 77% dari kinerja sistem maksimum dan pada kenyataannya kita memiliki sekitar 100% yang tersisa di cadangan - 77% = 23%, dan bukan 50%, seperti yang terlihat.
Fakta ini harus dipertimbangkan ketika merencanakan.
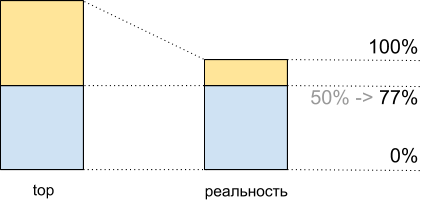 Pemanfaatan CPU untuk demoscript: data teratas dan apa yang sebenarnya terjadi
Pemanfaatan CPU untuk demoscript: data teratas dan apa yang sebenarnya terjadiKetidakkonsistenan lalu lintas
Selain hipertensi, perencanaan juga memperumit ketimpangan lalu lintas tergantung pada waktu, hari dalam seminggu, musim dan frekuensi lainnya. Bagi kami, misalnya, puncaknya adalah Minggu malam.
 Jumlah permintaan per detik, puncak Minggu malam
Jumlah permintaan per detik, puncak Minggu malamTidak selalu jumlah permintaan berubah dengan cara yang jelas. Sebagai contoh, pengguna entah bagaimana dapat berinteraksi dengan pengguna lain: aktivitas beberapa dapat menghasilkan push / email ke orang lain dan dengan demikian melibatkan mereka dalam proses. Untuk ini ditambahkan kampanye promosi yang meningkatkan lalu lintas dan untuk itu Anda juga harus siap.
Semua ini juga penting untuk dipertimbangkan ketika merencanakan: misalnya, untuk membangun tren pada hari-hari puncak dan mengingat kemungkinan non-linearitas pertumbuhan puncak.
Alat profil dan pengukuran
Misalkan kita mengetahui bahwa ada masalah kinerja, pahamilah bahwa ini bukan database / layanan / barang, namun kami memutuskan untuk mengoptimalkan kode. Untuk melakukan ini, pertama-tama, kita memerlukan profiler atau beberapa alat untuk menemukan kemacetan dan kemudian melihat hasil optimasi kami.
Sayangnya, untuk PHP saat ini tidak ada alat universal yang bagus.
perf
perf adalah alat pembuatan profil yang dibangun di dalam kernel Linux. Ini adalah profiler
pengambilan sampel yang diluncurkan oleh proses yang terpisah, oleh karena itu ia tidak secara langsung menambahkan overhead ke program yang sedang diprofilkan. Secara tidak langsung menambahkan overhead secara seragam "diolesi", sehingga tidak merusak pengukuran.
Untuk semua kelebihannya, perf hanya dapat bekerja dengan kode yang dikompilasi dan dengan JIT dan tidak dapat bekerja dengan kode yang menjalankan "di bawah mesin virtual". Oleh karena itu, kode PHP itu sendiri tidak dapat diprofilkan di dalamnya, tetapi Anda dapat dengan jelas melihat bagaimana PHP bekerja di dalamnya, termasuk berbagai ekstensi PHP, dan berapa banyak sumber daya yang dihabiskan untuk itu.
Misalnya, dengan perf, kami menemukan beberapa kemacetan, termasuk tempat kompresi, yang akan saya bahas di bawah.
Contoh:
perf record --call-graph dwarf,65528 -F 99 -p $(pgrep php-cgi | paste -sd "," -) -- sleep 20
perf report(jika proses dan perf dieksekusi di bawah pengguna yang berbeda, maka perf perlu dijalankan dari bawah sudo).
 Contoh output laporan Perf untuk PHP-FPM
Contoh output laporan Perf untuk PHP-FPMAgregator XHProf dan XHProf
XHProf adalah ekstensi untuk PHP yang menempatkan penghitung waktu di sekitar semua panggilan ke fungsi / metode, dan juga berisi alat untuk memvisualisasikan hasil yang diperoleh. Tidak seperti perf, ini memungkinkan Anda untuk beroperasi dengan ketentuan kode PHP (pada saat yang sama, apa yang terjadi dalam ekstensi tidak terlihat).
Kerugiannya meliputi dua hal:
- semua pengukuran dikumpulkan dalam kerangka permintaan tunggal, oleh karena itu mereka tidak memberikan informasi tentang gambar secara keseluruhan;
- overhead, meskipun tidak sebesar , misalnya, ketika menggunakan Xdebug, tetapi itu, dan dalam beberapa kasus hasilnya sangat terdistorsi (semakin sering suatu fungsi dipanggil dan semakin sederhana, semakin besar distorsi).
Berikut adalah contoh yang menggambarkan poin terakhir:
function child1() { return 1; } function child2() { return 2; } function parent1() { child1(); child2(); return; } for ($i = 0; $i < 1000000; $i++) { parent1(); }
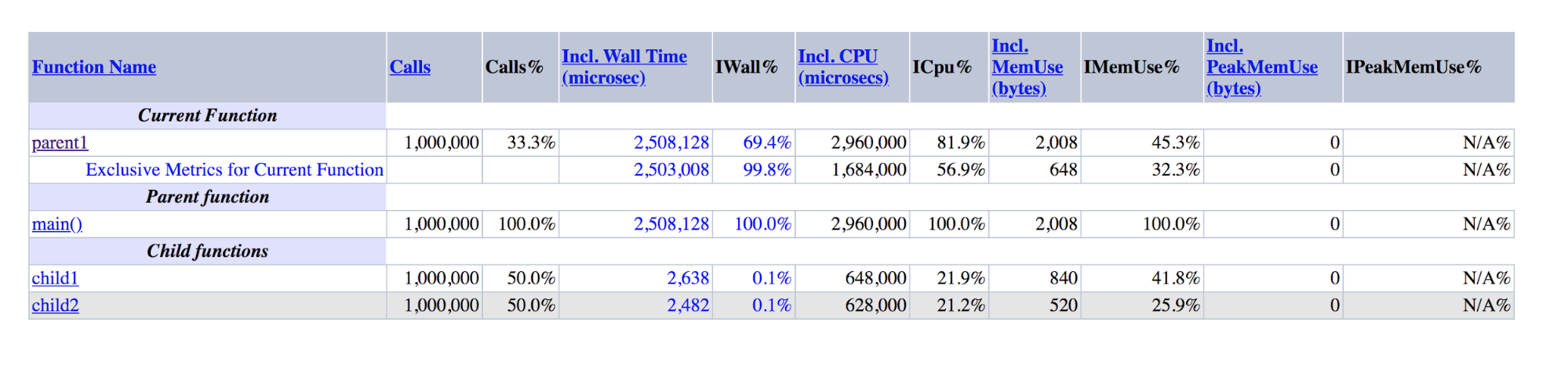 Output XHProf untuk demo: parent1 adalah urutan besarnya lebih besar dari jumlah child1 dan child2
Output XHProf untuk demo: parent1 adalah urutan besarnya lebih besar dari jumlah child1 dan child2Dapat dilihat bahwa parent1 () dieksekusi ~ 500 kali lebih lama dari child1 () + child2 (), meskipun dalam kenyataannya angka-angka ini harus kira-kira sama, seperti sama dengan main () dan parent1 ().
Jika kelemahan terakhir sulit untuk diperjuangkan, maka untuk melawan yang pertama kami membuat add-on lebih dari XHProf, yang mengagregasi profil permintaan yang berbeda dan memvisualisasikan data agregat.
Selain XHProf, ada banyak profiler lain yang kurang dikenal bekerja pada prinsip yang sama. Mereka memiliki kelebihan dan kekurangan yang serupa.
Pinba
Pinba memungkinkan Anda untuk
memantau kinerja dengan skrip (tindakan) dan oleh pengatur waktu yang telah ditentukan. Semua pengukuran dalam konteks skrip dibuat di luar kotak, untuk ini, tidak ada langkah tambahan yang diperlukan. Untuk setiap skrip dan penghitung waktu,
getrusage dieksekusi , jadi kami tahu persis berapa banyak waktu prosesor dihabiskan untuk sepotong kode tertentu (tidak seperti sampling profiler, di mana kali ini berubah menjadi jaringan, disk, dll.). Pinba sangat bagus untuk menyimpan data historis dan mendapatkan gambar baik secara umum maupun dalam jenis pertanyaan tertentu.
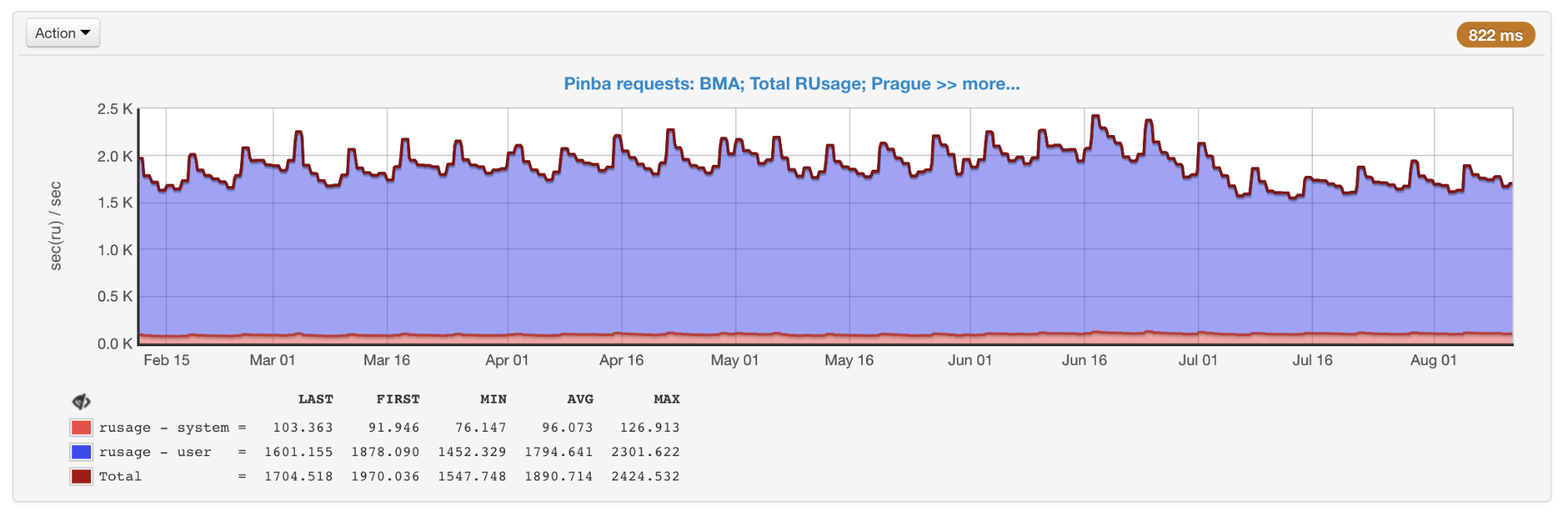 Rusage umum semua skrip yang diperoleh dari Pinba
Rusage umum semua skrip yang diperoleh dari PinbaKerugiannya termasuk fakta bahwa pengatur waktu yang membuat profil bagian tertentu dari kode, dan bukan seluruh skrip, harus diatur terlebih dahulu dalam kode, serta keberadaan overhead yang (seperti dalam XHProf) dapat mengubah data.
phpspy
phpspy adalah proyek yang relatif baru (komit pertama pada GitHub adalah setengah tahun yang lalu), yang terlihat menjanjikan, jadi kami sedang memonitornya.
Dari sudut pandang pengguna, phpspy mirip dengan perf: proses paralel diluncurkan, yang secara berkala menyalin bagian memori dari proses PHP, mem-parsing mereka dan menerima jejak stack dan data lainnya dari sana. Ini dilakukan dengan cara yang agak spesifik. Untuk meminimalkan overhead, phpspy tidak menghentikan proses PHP dan menyalin memori secara langsung saat sedang berjalan. Ini mengarah pada fakta bahwa profiler bisa mendapatkan keadaan yang tidak konsisten, jejak tumpukan dapat dipecahkan. Tetapi phpspy dapat mendeteksi ini dan membuang data tersebut.
Di masa depan, dengan menggunakan alat ini akan dimungkinkan untuk mengumpulkan data pada gambar secara keseluruhan dan profil dari jenis pertanyaan tertentu.
Tabel perbandingan
Untuk menyusun perbedaan antara alat, mari kita buat tabel pivot:
 Perbandingan fitur utama profilerGrafik nyala
Perbandingan fitur utama profilerGrafik nyalaOptimalisasi dan pendekatan
Dengan alat ini, kami terus memantau kinerja dan penggunaan sumber daya kami. Ketika mereka digunakan secara tidak adil atau kita mendekati ambang (untuk CPU kita secara empiris memilih nilai 55% untuk memiliki margin waktu jika terjadi pertumbuhan), seperti yang saya tulis di atas, salah satu solusi untuk masalah ini adalah optimasi.
Nah, jika optimasi sudah dilakukan oleh orang lain, seperti halnya dengan PHP 7.0, ketika versi ini ternyata jauh lebih produktif daripada yang sebelumnya. Kami biasanya mencoba menggunakan teknologi dan alat modern, termasuk pembaruan tepat waktu untuk versi terbaru PHP. Menurut
tolok ukur publik , PHP 7.2 lebih cepat 5-12% dari PHP 7.1. Tetapi transisi ini, sayangnya, memberi kami jauh lebih sedikit.
Selama ini kami telah menerapkan sejumlah besar optimisasi. Sayangnya, kebanyakan dari mereka sangat terkait dengan logika bisnis kami. Saya akan berbicara tentang hal-hal yang mungkin relevan tidak hanya untuk kita, atau gagasan dan pendekatan yang dapat digunakan di luar kode kita.
Kompresi Zlib => zstd
Kami menggunakan kompresi untuk tombol memkey besar. Ini memungkinkan kami untuk menghabiskan memori tiga hingga empat kali lebih sedikit untuk penyimpanan karena biaya CPU tambahan untuk kompresi / dekompresi. Kami menggunakan zlib untuk ini (ekstensi kami untuk bekerja dengan memek berbeda dari yang datang dengan PHP, tetapi yang resmi
juga menggunakan zlib).
Pada dasarnya, produksi adalah seperti ini:
+ 4.03% 0.22% php-cgi libz.so.1.2.11 [.] inflate
+ 3.38% 0.00% php-cgi libz.so.1.2.11 [.] deflate7-8% dari waktu dihabiskan untuk kompresi / dekompresi.
Kami memutuskan untuk menguji berbagai level dan algoritma kompresi. Ternyata zstd berjalan pada data kami hampir sepuluh kali lebih cepat, kalah di tempat ~ 1,1 kali. Perubahan algoritma yang cukup sederhana menyelamatkan kami ~ 7.5% CPU (ini, saya ingat, pada volume kami setara dengan ~ 45 server).
Penting untuk dipahami bahwa rasio kinerja berbagai algoritma kompresi dapat sangat bervariasi tergantung pada data input. Ada berbagai
perbandingan , tetapi yang paling akurat ini hanya dapat diperkirakan dengan menggunakan contoh dunia nyata.
IS_ARRAY_IMMUTABLE sebagai repositori data yang jarang dimodifikasi
Ketika bekerja dengan tugas nyata, Anda harus berurusan dengan data yang sering Anda butuhkan dan pada saat yang sama jarang berubah dan memiliki ukuran terbatas. Kami memiliki banyak data yang serupa, contoh yang baik adalah konfigurasi
tes split . Kami memeriksa apakah pengguna berada dalam kondisi pengujian tertentu, dan tergantung pada ini, kami menunjukkan kepadanya fungsionalitas eksperimental atau normal (ini terjadi hampir selama setiap permintaan). Dalam proyek lain, konfigurasi dan berbagai direktori dapat menjadi contoh: negara, kota, bahasa, kategori, merek, dll.
Karena data tersebut sering diminta, tanda terima mereka dapat membuat beban tambahan yang nyata baik pada aplikasi itu sendiri maupun pada layanan di mana data ini disimpan. Masalah terakhir dapat dipecahkan, misalnya, menggunakan APCu, yang menggunakan memori mesin yang sama yang menjalankan PHP-FPM sebagai penyimpanan. Namun demikian:
- akan ada biaya serialisasi / deserialisasi;
- Anda perlu entah bagaimana membatalkan data saat mengubah;
- Ada beberapa overhead dibandingkan dengan mengakses hanya variabel di PHP.
PHP 7.0 memperkenalkan optimasi
IS_ARRAY_IMMUTABLE . Jika Anda mendeklarasikan sebuah array, yang semua elemennya diketahui pada saat kompilasi, maka elemen itu akan diproses dan ditempatkan ke dalam memori OPCache satu kali, pekerja PHP-FPM akan merujuk ke memori bersama ini tanpa menghabiskan waktu mereka sebelum mencoba mengubah. Ini juga mengikuti bahwa memasukkan array seperti itu akan memakan waktu yang konstan terlepas dari ukuran (biasanya ~ 1 mikrodetik).
Sebagai perbandingan: contoh waktu untuk mendapatkan array 10.000 elemen melalui include dan apcu_fetch:
$t0 = microtime(true); $a = include 'test-incl-1.php'; $t1 = microtime(true); printf("include (%d): %d microsec\n", count($a), ($t1-$t0) * 1e6); $t0 = microtime(true); $a = apcu_fetch('a'); $t1 = microtime(true); printf("apcu_fetch (%d): %d microsec\n", count($a), ($t1-$t0) * 1e6);
Memeriksa apakah optimasi ini telah diterapkan bisa sangat sederhana jika Anda melihat opcodes yang dihasilkan:
$ cat immutable.php <?php return [ 'key1' => 'val1', 'key2' => 'val2', 'key3' => 'val3', ]; $ cat mutable.php <?php return [ 'key1' => \SomeClass::CONST_1, 'key2' => 'val2', 'key3' => 'val3', ]; $ php -d opcache.enable=1 -d opcache.enable_cli=1 -d opcache.opt_debug_level=0x20000 immutable.php $_main: ; (lines=1, args=0, vars=0, tmps=0) ; (after optimizer) ; /home/ubuntu/immutable.php:1-8 L0 (4): RETURN array(...) $ php -d opcache.enable_cli=1 -d opcache.opt_debug_level=0x20000 mutable.php $_main: ; (lines=5, args=0, vars=0, tmps=2) ; (after optimizer) ; /home/ubuntu/mutable.php:1-8 L0 (4): T1 = FETCH_CLASS_CONSTANT string("SomeClass") string("CONST_1") L1 (4): T0 = INIT_ARRAY 3 T1 string("key1") L2 (5): T0 = ADD_ARRAY_ELEMENT string("val2") string("key2") L3 (6): T0 = ADD_ARRAY_ELEMENT string("val3") string("key3") L4 (6): RETURN T0
Dalam kasus pertama, jelas bahwa hanya ada satu opcode dalam file - kembalinya array yang sudah jadi. Dalam kasus kedua, pembentukan elemen-demi-elemennya terjadi setiap kali file ini dieksekusi.
Dengan demikian, dimungkinkan untuk menghasilkan struktur dalam bentuk yang tidak memerlukan transformasi lebih lanjut dalam runtime. Misalnya, alih-alih membongkar nama kelas dengan tanda “_” dan “\” setiap kali untuk autoload, Anda dapat membuat sebelumnya peta korespondensi “Class => Path”. Dalam hal ini, fungsi konversi akan direduksi menjadi panggilan tabel hash tunggal. Komposer melakukan optimasi semacam ini jika Anda mengaktifkan
opsi optim-autoloader .
Untuk pembatalan data seperti itu, Anda tidak perlu melakukan apa pun secara khusus - PHP sendiri akan mengkompilasi ulang file ketika berubah, sama seperti dengan penyebaran kode normal. Satu-satunya kelemahan yang tidak boleh Anda lupakan: jika file tersebut sangat besar, maka permintaan pertama setelah mengubahnya akan menyebabkan kompilasi ulang, yang bisa memakan waktu nyata.
Kinerja meliputi / mengharuskan
Berbeda dengan contoh array statis, melampirkan file dengan deklarasi kelas dan fungsi tidak begitu cepat. Meskipun ada OPCache, mesin PHP harus menyalinnya ke memori proses, menghubungkan dependensi secara rekursif, yang pada akhirnya dapat mengambil ratusan mikrodetik atau bahkan milidetik per file.
Jika Anda membuat proyek kosong baru di
Symfony 4.1 dan menempatkan
get_included_files () sebagai baris pertama dalam tindakan, Anda dapat melihat bahwa 310 file sudah terhubung. Dalam proyek nyata, jumlah ini dapat mencapai ribuan per permintaan. Perlu memperhatikan hal-hal berikut.
Kurangnya fitur lading otomatisAda
Fungsi Autoloading RFC , tetapi tidak ada pengembangan yang terlihat selama beberapa tahun. Oleh karena itu, jika ketergantungan dalam Komposer mendefinisikan fungsi di luar kelas dan fungsi-fungsi ini harus dapat diakses oleh pengguna, maka ini dilakukan dengan
kewajiban menghubungkan file dengan fungsi-fungsi ini ke setiap inisialisasi autoloader.
Misalnya, menghapus salah satu dependensi dari composer.json, yang menyatakan banyak fungsi dan mudah diganti dengan seratus baris kode, kami memenangkan beberapa persen dari CPU.
Loader otomatis lebih sering dipanggil daripada yang terlihat.Untuk mendemonstrasikan ide tersebut, buat file seperti itu dengan kelas:
<?php class A extends B implements C { use D; const AC1 = \E::E1; const AC2 = \F::F1; private static $as3 = \G::G1; private static $as4 = \H::H1; private $a5 = \I::I1; private $a6 = \J::J1; public function __construct(\K $k = null) {} public static function asf1(\L $l = null) :? LR { return null; } public static function asf2(\M $m = null) :? MR { return null; } public function af3(\N $n = null) :? NR { return null; } public function af4(\P $p = null) :? PR { return null; } }
Daftarkan pemuat otomatis: spl_autoload_register(function ($name) { echo "Including $name...\n"; include "$name.php"; });
Dan kami akan membuat beberapa kasus penggunaan untuk kelas ini: include 'A.php' Including B... Including D... Including C... \A::AC1 Including A... Including B... Including D... Including C... Including E... new A() Including A... Including B... Including D... Including C... Including E... Including F... Including G... Including H... Including I... Including J...
Anda mungkin memperhatikan bahwa ketika kita entah bagaimana hanya menghubungkan kelas, tetapi tidak membuat turunannya, induk, antarmuka dan sifat akan terhubung. Ini dilakukan secara rekursif untuk semua file yang terhubung sebagai resolusi.
Saat membuat contoh, resolusi semua konstanta dan bidang ditambahkan ke ini, yang mengarah ke koneksi semua file yang diperlukan untuk ini, yang, pada gilirannya, juga akan menyebabkan koneksi berulang sifat, orang tua dan antarmuka kelas yang baru terhubung.
 Menghubungkan kelas terkait untuk proses pembuatan instance dan kasus lainnya
Menghubungkan kelas terkait untuk proses pembuatan instance dan kasus lainnyaTidak ada solusi universal untuk masalah ini, Anda hanya perlu mengingatnya dan memantau koneksi antar kelas: satu baris dapat menarik koneksi ratusan file.
Pengaturan OPCacheJika Anda menggunakan metode
penyebaran atom dengan mengubah symlink yang diusulkan oleh Rasmus Lerdorf, pencipta PHP, maka untuk
menyelesaikan masalah "menempelkan" symlink pada versi lama Anda harus menyertakan opcache.revalidate_path, seperti yang disarankan, misalnya, dalam
artikel ini tentang OPCache yang diterjemahkan oleh Mail .Ru Group.
Masalahnya adalah bahwa opsi ini secara signifikan (rata-rata, satu setengah hingga dua kali) meningkatkan waktu untuk memasukkan setiap file. Secara total, ini dapat mengkonsumsi sejumlah besar sumber daya (dalam kasus kami, menonaktifkan opsi ini memberi keuntungan 7-9%).
Untuk menonaktifkannya, Anda perlu melakukan dua hal:
- membuat server web menyelesaikan symlink;
- berhenti menghubungkan file di dalam skrip PHP di sepanjang jalur yang berisi symlinks, atau paksa mereka melalui readlink () atau realpath ().
Jika semua file terhubung dengan autoloader Composer, maka item kedua akan dieksekusi secara otomatis setelah yang pertama selesai: omposer menggunakan konstanta __DIR__, yang akan diselesaikan dengan benar.
OPCache memiliki beberapa opsi lagi yang dapat memberikan peningkatan kinerja dengan imbalan fleksibilitas. Anda dapat membaca lebih lanjut tentang ini di
artikel yang saya sebutkan di atas.
Terlepas dari semua optimasi ini, termasuk masih tidak akan gratis. Untuk mengatasi ini, PHP 7.4 berencana untuk menambahkan
preload .
Kunci APCu
Meskipun kita tidak berbicara tentang basis data dan layanan di sini, berbagai jenis kunci juga dapat terjadi dalam kode, yang meningkatkan waktu eksekusi skrip.
Seiring meningkatnya permintaan, kami melihat adanya penurunan tajam dalam respons di masa puncaknya. Setelah menemukan alasannya, ternyata meskipun APCu adalah cara tercepat untuk mendapatkan data (dibandingkan dengan Memcache, Redis dan penyimpanan eksternal lainnya), APCu juga dapat bekerja secara lambat dengan seringnya menimpa kunci yang sama.
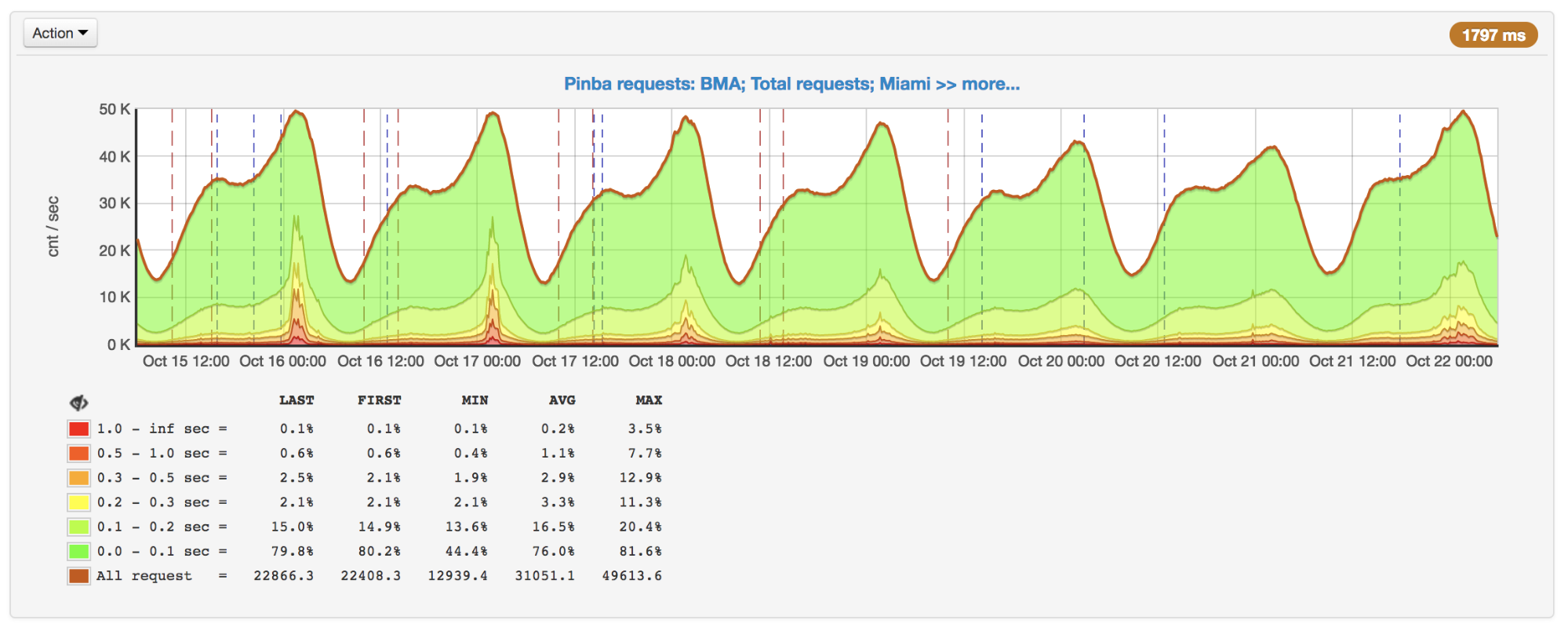 Jumlah permintaan per detik dan runtime: puncak pada 16 dan 17 Oktober
Jumlah permintaan per detik dan runtime: puncak pada 16 dan 17 OktoberSaat menggunakan APCu sebagai cache, masalah ini tidak begitu relevan, karena caching biasanya melibatkan penulisan yang jarang dan sering membaca. Tetapi beberapa tugas dan algoritma (misalnya,
Circuit Breaker (
implementasi dalam PHP )) juga sering melibatkan perekaman, yang menyebabkan kunci.
Tidak ada solusi universal untuk masalah ini, tetapi dalam kasus Circuit Breaker dapat diselesaikan, misalnya, dengan meletakkannya di
layanan terpisah yang diinstal pada mesin dengan PHP.
Pemrosesan batch
Bahkan jika Anda tidak memasukkan akun, biasanya semua bagian penting dari waktu eksekusi query dihabiskan untuk inisialisasi: kerangka kerja (misalnya, membangun wadah DI dan menginisialisasi semua dependensinya, routing, mengeksekusi semua pendengar), meningkatkan sesi, Pengguna, dan sebagainya selanjutnya.
Jika backend Anda adalah API internal untuk sesuatu, maka untuk beberapa permintaan tertentu pada klien dapat digabungkan dan dikirim sebagai satu permintaan. Dalam hal ini, inisialisasi akan dilakukan sekali untuk beberapa permintaan.
Jika ini tidak memungkinkan pada klien, cobalah mencari permintaan yang dapat diproses secara tidak sinkron. Mereka dapat diterima dengan beberapa skrip sederhana yang tidak menginisialisasi apa pun dan hanya menempatkan mereka dalam antrian. Dan sudah bisa diproses dalam batch.Pemanfaatan Sumber Daya Cerdas
Di Badoo, kami memiliki kelompok berbeda yang disesuaikan dengan kebutuhan yang berbeda. Selain cluster dengan PHP-FPM, di mana ratusan server dimuat pada CPU, dan disk tidak digunakan, kami memiliki satu cluster basis data khusus dari beberapa ratus mesin, yang berbanding terbalik dengan yang pertama: dengan disk besar dan banyak dimuat di IO, yang CPU-nya idle.Solusi yang jelas di sini adalah menjalankan PHP-FPM pada cluster kedua - pada kenyataannya, kami mendapat beberapa ratus mesin tambahan di cluster PHP secara gratis.(CPU, IO), . , , , , - , . , . , , .
Kesimpulan
. PHP .
:
- ;
- ;
- - , : , ;
- : (, , );
- : ;
- , OPCache PHP, , , ;
- : (, , PHP 7.2 , );
- : , .
?
Terima kasih atas perhatian anda!