Halo semuanya! Saya bekerja di Veeam pada proyek Veeam untuk proyek Linux. Dengan produk ini, Anda dapat membuat cadangan mesin Linux. "Agen" dalam namanya berarti bahwa program ini memungkinkan Anda untuk membuat cadangan mesin fisik. Virtualalkans juga cadangan, tetapi terletak di OS tamu.
Inspirasi untuk artikel ini adalah laporan saya di konferensi
Linux Piter , yang saya putuskan untuk diterbitkan sebagai artikel untuk semua habragiteli yang tertarik.
Dalam artikel itu, saya akan mengungkapkan topik membuat snapshot yang memungkinkan Anda untuk membuat cadangan dan berbicara tentang masalah yang kami temui saat membuat mekanisme kami sendiri untuk membuat snapshot dari perangkat blok.
Semua yang berminat silakan meminta potongan!

Sedikit teori di awal
Secara historis, ada dua pendekatan untuk membuat cadangan: File cadangan dan Volume cadangan. Dalam kasus pertama, kami menyalin setiap file sebagai objek yang terpisah, dalam yang kedua, kami menyalin seluruh konten volume sebagai jenis gambar.
Kedua metode memiliki banyak kelebihan dan kekurangan, tetapi kami akan mempertimbangkannya melalui prisma pemulihan dari kegagalan:
- Dalam hal File cadangan, untuk pemulihan penuh seluruh server, kita perlu menginstal OS terlebih dahulu, kemudian layanan yang diperlukan, dan hanya kemudian mengembalikan file dari cadangan.
- Dalam hal cadangan Volume, untuk pemulihan penuh cukup untuk mengembalikan semua volume mesin tanpa upaya yang tidak perlu dari orang tersebut.
Jelas, dalam hal cadangan Volume, Anda dapat memulihkan sistem lebih cepat, dan ini merupakan
karakteristik penting
dari sistem . Karenanya, untuk diri kami sendiri, kami mencatat cadangan volume sebagai opsi yang disukai.
Bagaimana kita mengambil dan menyimpan seluruh volume? Tentu saja, hanya menyalin kita tidak akan mencapai hal yang baik. Selama penyalinan, beberapa aktivitas dengan data akan terjadi pada volume, sebagai akibatnya, data yang tidak konsisten akan muncul di cadangan. Struktur sistem file akan dilanggar, file basis data akan rusak, serta file lain yang dengannya operasi akan dilakukan selama penyalinan.
Untuk menghindari semua masalah ini, umat manusia progresif muncul dengan teknologi snapshot - snapshot. Secara teori, semuanya sederhana: kami membuat salinan yang tidak berubah - potret - dan mencadangkan data darinya. Saat cadangan selesai - kami menghancurkan snapshot. Kedengarannya sederhana, tetapi, seperti biasa, ada nuansa.
Karena mereka, banyak implementasi teknologi ini lahir. Misalnya, solusi berdasarkan pada
mapper perangkat , seperti LVM dan Thin provisioning, memberikan snapshot volume penuh, tetapi memerlukan tata letak disk khusus pada tahap instalasi sistem, yang berarti bahwa secara umum mereka tidak cocok.
BTRFS dan ZFS memungkinkan untuk membuat snapshot dari substruktur sistem file, yang sangat keren, tetapi saat ini bagian mereka pada server kecil, dan kami mencoba membuat solusi universal.
Misalkan ada EXT dangkal pada perangkat blok kami. Dalam hal ini, kita dapat menggunakan
dm-snap (ngomong-ngomong,
dm-bow sedang dikembangkan sekarang), tapi di sini ada nuansa tersendiri. Anda harus memiliki perangkat blok gratis yang siap sehingga Anda dapat membuang data snapshot di mana.
Memperhatikan solusi cadangan alternatif, kami memperhatikan bahwa, sebagai aturan, mereka menggunakan modul kernel untuk membuat snapshot perangkat blok. Kami memutuskan untuk pergi dengan cara ini, menulis modul kami. Diputuskan untuk mendistribusikannya di bawah lisensi GPL, sehingga tersedia untuk umum di
github .
Cara kerjanya - secara teori
Cuplikan mikroskop
Jadi, sekarang kita akan mempertimbangkan prinsip umum operasi modul dan membahas masalah-masalah utama secara lebih rinci.
Sebenarnya, veeamsnap (seperti yang kami sebut modul kernel kami) adalah filter driver perangkat blok.

Tugasnya adalah mencegat permintaan untuk driver perangkat blok.
Setelah mencegat permintaan tulis, modul menyalin data dari perangkat blok asli ke area data foto. Kami menyebut area ini snapstore.
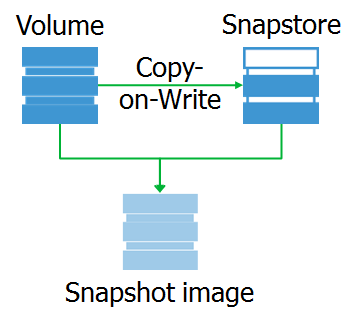
Dan apa snapshot itu sendiri? Ini adalah perangkat blok virtual, salinan perangkat asli pada titik waktu tertentu. Saat mengakses blok data pada perangkat ini, mereka dapat dibaca dari snap-in, atau dari perangkat asli.
Saya ingin mencatat bahwa snapshot itu persis perangkat blok yang sepenuhnya identik dengan aslinya pada saat snapshot dihapus. Berkat ini, kita dapat memasang sistem file pada snapshot dan melakukan pra-pemrosesan yang diperlukan.
Misalnya, kita bisa mendapatkan peta blok yang ditempati dari sistem file. Cara termudah untuk melakukan ini adalah dengan menggunakan ioctl
GETFSMAP .
Data pada blok sibuk memungkinkan Anda untuk hanya membaca data terbaru dari snapshot.
Anda juga dapat mengecualikan beberapa file. Nah, tindakan yang sepenuhnya opsional: indeks file yang masuk ke cadangan, untuk kemungkinan restoran granular di masa depan.
CoW vs RoW
Mari kita memikirkan sedikit tentang memilih algoritma snapshot. Pilihan di sini tidak terlalu luas:
Copy-on-Write atau Redirect-on-Write .
Redirect-on-Write ketika mencegat permintaan tulis akan mengarahkan ulang ke snap, setelah semua permintaan untuk membaca blok ini akan pergi ke sana juga. Algoritme yang bagus untuk sistem penyimpanan yang dibangun berdasarkan pohon B +, seperti BTRFS, ZFS dan Thin Provisioning. Teknologi ini setua dunia, tetapi memanifestasikan dirinya dengan sangat baik di hypervisors, di mana Anda dapat membuat file baru dan menulis blok baru di sana selama durasi snapshot. Kinerja sangat baik dibandingkan dengan Kontrak Karya. Tetapi ada minus lemak - struktur perangkat asli berubah, dan ketika menghapus snapshot, Anda perlu menyalin semua blok dari snap ke lokasi asli.
Copy-on-Write, ketika mencegat permintaan, menyalin data ke snapstore yang harus mengalami perubahan, setelah itu memungkinkan mereka untuk ditimpa di tempat asli. Digunakan untuk membuat snapshot untuk volume LVM dan salinan bayangan VSS. Jelas, itu lebih cocok untuk membuat snapshot perangkat blok, karena tidak mengubah struktur perangkat asli, dan ketika Anda menghapus (atau crash) snapshot hanya dapat dibuang tanpa risiko data. Kelemahan dari pendekatan ini adalah penurunan kinerja, karena beberapa operasi baca / tulis ditambahkan ke setiap operasi penulisan.
Karena keamanan data adalah prioritas utama kami, kami fokus pada Kontrak Karya.
Sejauh ini, semuanya terlihat sederhana, jadi mari kita membahas masalah kehidupan nyata.
Cara kerjanya - dalam praktik
Kondisi yang konsisten
Demi dia, semuanya dikandung.
Misalnya, jika pada saat membuat snapshot (dalam perkiraan pertama, kita dapat mengasumsikan bahwa itu dibuat secara instan), file akan direkam, maka dalam snapshot file tersebut tidak lengkap, yang berarti akan rusak dan tidak berarti. Situasinya mirip dengan file database dan sistem file itu sendiri.
Tapi kita hidup di abad ke-21! Ada mekanisme logging yang melindungi dari masalah seperti itu! Benar, kenyataannya adalah, ada "tetapi" yang penting: perlindungan ini bukan dari kegagalan, tetapi dari konsekuensinya. Ketika mengembalikan ke kondisi yang konsisten menurut log, operasi yang tidak lengkap akan dibuang, yang berarti bahwa mereka akan hilang. Karena itu, penting untuk menggeser prioritas perlindungan dari penyebabnya, daripada mengobati konsekuensinya.
Sistem dapat diperingatkan bahwa snapshot sekarang akan dibuat. Untuk ini, kernel memiliki fungsi
freeze_bdev dan
thaw_bdev . Mereka menarik fungsi filesystem freeze_fs dan unfreeze_fs. Saat Anda memanggil yang pertama, sistem harus mengatur ulang cache, menangguhkan pembuatan permintaan baru ke perangkat blokir dan menunggu penyelesaian semua permintaan yang dihasilkan sebelumnya. Dan ketika unfreeze_fs dipanggil, sistem file mengembalikan fungsi normalnya.
Ternyata kita bisa memperingatkan sistem file. Bagaimana dengan aplikasi? Di sini, sayangnya, semuanya buruk. Sementara di Windows ada mekanisme
VSS yang, dengan bantuan Penulis, menyediakan interaksi dengan produk lain, di Linux masing-masing berjalan dengan caranya sendiri. Saat ini, ini telah menyebabkan situasi yang tugas administrator sistem untuk menulis (menyalin,
mencuri , membeli, dll) pra-membekukan dan skrip post-thaw sendiri, yang akan mempersiapkan aplikasi mereka untuk snapshot. Untuk bagian kami, dalam rilis berikutnya kami akan memperkenalkan dukungan untuk Pemrosesan Aplikasi Oracle, sebagai fitur yang paling sering diminta oleh pelanggan kami. Kemudian, aplikasi lain mungkin didukung, tetapi secara keseluruhan situasinya agak menyedihkan.
Di mana menempatkan snap?
Ini adalah masalah kedua yang menghalangi kita. Sepintas, masalahnya tidak jelas, tetapi setelah sedikit pemahaman, kita melihat bahwa ini masih sempalan.
Tentu saja, solusi termudah adalah menempatkan snap di RAM. Untuk pengembang, opsinya luar biasa! Semuanya cepat, sangat nyaman untuk melakukan debugging, tetapi ada jamb: RAM adalah sumber daya yang berharga, dan tidak ada yang akan memberi kita kesempatan besar di sana.
OK, mari kita jadikan snap-file sebagai file biasa. Tetapi masalah lain muncul - Anda tidak dapat membuat cadangan volume di mana snapstop berada. Alasannya sederhana: kami mencegat permintaan rekaman, yang berarti kami akan mencegat permintaan rekaman kami sendiri di snap-in. Kuda berlarian secara ilmiah - jalan buntu. Lalu ada keinginan akut untuk menggunakan disk terpisah untuk ini, tetapi tidak ada yang akan menambahkan disk ke server kami demi kami. Anda harus bisa mengerjakan apa yang ada.
Untuk memosisikan snap-in dari jarak jauh adalah ide yang bagus, tetapi ini dapat diimplementasikan dalam lingkaran jaringan yang sangat sempit dengan bandwidth tinggi dan latensi mikroskopis. Jika tidak, sambil memegang snapshot pada mesin akan ada strategi berbasis giliran.
Jadi, Anda perlu memasang snap pada disk lokal. Tetapi, sebagai aturan, semua ruang pada disk lokal sudah didistribusikan di antara sistem file, dan pada saat yang sama Anda harus berpikir keras bagaimana mengatasi masalah kebuntuan.
Arah untuk refleksi, pada prinsipnya, adalah satu: Anda perlu entah bagaimana mengalokasikan ruang dalam sistem file, tetapi bekerja secara langsung dengan perangkat blok. Solusi untuk masalah ini diimplementasikan dalam kode ruang pengguna, dalam layanan.
Ada panggilan sistem
fallocate yang memungkinkan Anda membuat file kosong dengan ukuran yang diinginkan. Namun, pada kenyataannya, hanya metadata yang dibuat pada sistem file yang menjelaskan lokasi file pada volume. Dan ioctl
FIEMAP memungkinkan kita untuk mendapatkan peta lokasi blok file.
Dan voila: kami membuat file di bawah snap menggunakan fallocate, FIEMAP memberi kami peta lokasi blok file ini, yang dapat kami transfer untuk bekerja di modul veeamsnap kami. Lebih lanjut, ketika mengakses snapstor, modul membuat permintaan langsung ke perangkat blok di blok yang kita kenal, dan tidak ada deadlock.
Namun ada nuansa. Panggilan sistem fallocate hanya didukung oleh XFS, EXT4, dan BTRFS. Untuk sistem file lain seperti EXT3, Anda harus menulisnya sepenuhnya untuk mengalokasikan file. Fungsionalitas dipengaruhi oleh peningkatan waktu untuk menyiapkan snappads, tetapi tidak ada pilihan. Sekali lagi, Anda harus bisa mengerjakan apa yang ada.
Bagaimana jika ioctl FIEMAP juga tidak didukung? Ini adalah realitas NTFS dan FAT32, di mana bahkan tidak ada dukungan untuk FIBMAP kuno. Saya harus mengimplementasikan algoritma generik tertentu, yang operasinya tidak bergantung pada fitur-fitur sistem file. Singkatnya, algoritma ini adalah:
- Layanan membuat file dan mulai menulis pola tertentu.
- Modul memotong permintaan tulis, memeriksa data yang sedang ditulis.
- Jika data blok cocok dengan pola yang diberikan, maka blok ditandai sebagai milik snapstop.
Ya, sulit, ya, lambat, tetapi lebih baik daripada tidak sama sekali. Ini digunakan dalam kasus yang jarang terjadi untuk sistem file tanpa dukungan FIEMAP dan FIBMAP.
Snapshot Overflow
Alih-alih, tempat yang kami sediakan di bawah snapstore berakhir. Inti dari masalahnya adalah tidak ada tempat untuk membuang data baru, yang berarti snapshot menjadi tidak dapat digunakan.
Apa yang harus dilakukan
Jelas, Anda perlu menambah ukuran snappants. Berapa banyak Cara termudah untuk mengatur ukuran snappants adalah dengan menentukan persentase ruang kosong pada volume (seperti yang dilakukan untuk VSS). Untuk volume 20 TB, 10% akan menjadi 2TB - yang merupakan jumlah yang banyak untuk server yang dibongkar. Untuk volume 200 GB, 10% adalah 20GB, yang mungkin terlalu sedikit untuk server yang memperbarui datanya secara intensif. Dan masih ada volume tipis ...
Secara umum, hanya administrator sistem server yang dapat mengetahui ukuran optimal dari snap-in yang diperlukan, yaitu, Anda harus membuat orang tersebut berpikir dan memberikan pendapat ahli. Ini tidak sesuai dengan prinsip "Itu hanya berhasil".
Untuk mengatasi masalah ini, kami mengembangkan algoritma stretch snapshot. Idenya adalah untuk memecah snap menjadi beberapa bagian. Pada saat yang sama, bagian-bagian baru dibuat setelah pembuatan foto yang diperlukan.

Sekali lagi, singkat algoritme:
- Sebelum membuat snapshot, bagian pertama dari snapshot dibuat dan diberikan ke modul.
- Ketika snapshot dibuat, porsi akan mulai terisi.
- Segera setelah setengah dari porsi penuh, permintaan dikirim ke layanan untuk membuat yang baru.
- Layanan menciptakannya, memberikan data ke modul.
- Modul mulai mengisi kumpulan berikutnya.
- Algoritme diulang sampai cadangan selesai, atau sampai kita mencapai batas pada penggunaan ruang disk kosong.
Penting untuk dicatat bahwa modul harus memiliki waktu untuk membuat bagian-bagian baru dari snapposts sesuai kebutuhan, jika tidak - meluap, mengatur ulang snapshot dan tanpa cadangan. Oleh karena itu, pengoperasian algoritma semacam itu hanya dimungkinkan pada sistem file dengan dukungan fallocate, di mana Anda dapat dengan cepat membuat file kosong.
Apa yang harus dilakukan dalam kasus lain? Kami mencoba menebak ukuran yang diperlukan dan membuat keseluruhan snappast sepenuhnya. Tetapi menurut statistik kami, sebagian besar server Linux sekarang menggunakan EXT4 dan XFS. EXT3 ditemukan pada mesin yang lebih tua. Tetapi dalam SLES / openSUSE Anda dapat menemukan BTRFS.
Ubah Pelacakan Blok (CBT)
Cadangan tambahan atau diferensial (omong-omong, lobak lobak lebih manis atau tidak, saya sarankan baca di
sini ) - tanpa itu, Anda tidak dapat membayangkan produk cadangan dewasa. Dan agar ini berfungsi, Anda membutuhkan CBT. Jika seseorang tidak terjawab: CBT memungkinkan Anda melacak perubahan dan menulis ke cadangan, hanya data yang berubah dari cadangan terakhir.

Banyak yang memiliki pengalaman sendiri di bidang ini. Misalnya, dalam VMware vSphere, fitur ini telah tersedia sejak versi 4 pada 2009. Di Hyper-V, dukungan diperkenalkan dengan Windows Server 2016, dan untuk mendukung rilis sebelumnya, driver VeeamFCT-nya dikembangkan kembali pada tahun 2012. Karenanya, untuk modul kami, kami tidak menjadi yang asli dan menggunakan algoritme yang sudah berfungsi.
Tentang cara kerjanya.
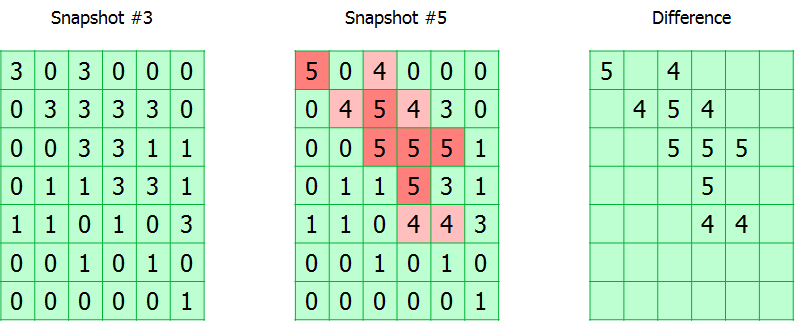
Seluruh volume yang dilacak dipecah menjadi blok-blok. Modul hanya melacak semua permintaan tulis, menandai blok yang diubah di tabel. Faktanya, tabel CBT adalah array byte, di mana setiap byte berhubungan dengan blok dan berisi jumlah snapshot yang diubah.
Selama pencadangan, nomor foto direkam dalam metadata cadangan. Dengan demikian, mengetahui jumlah snapshot saat ini dan yang dari mana backup sebelumnya berhasil dibuat, Anda dapat menghitung peta lokasi blok yang diubah.
Ada dua nuansa.
Seperti yang saya katakan, satu byte dialokasikan untuk nomor snapshot dalam tabel CBT, yang berarti bahwa panjang maksimum rantai tambahan tidak boleh lebih dari 255. Ketika ambang ini tercapai, tabel diatur ulang dan terjadi pencadangan penuh. Ini mungkin tampak tidak nyaman, tetapi pada kenyataannya, rantai kenaikan 255 jauh dari solusi terbaik saat membuat rencana cadangan.
Fitur kedua adalah penyimpanan tabel CBT hanya dalam RAM. Jadi, ketika Anda me-reboot mesin target atau membongkar modul, itu akan diatur ulang, dan sekali lagi, Anda harus membuat cadangan penuh. Solusi semacam itu memungkinkan untuk tidak memecahkan masalah start-up modul saat startup sistem. Selain itu, tidak perlu menyimpan tabel CBT saat Anda mematikan sistem.
Masalah kinerja
Cadangan selalu menjadi beban yang baik pada IO peralatan Anda. Jika sudah ada cukup tugas aktif di dalamnya, maka proses pencadangan dapat mengubah sistem Anda menjadi semacam
kemalasan .
Mari kita lihat mengapa.
Bayangkan server secara linear menulis beberapa data. Kecepatan perekaman dalam hal ini adalah maksimum, semua penundaan diminimalkan, kinerja cenderung ke maksimum. Sekarang kami menambahkan proses pencadangan di sini, yang pada setiap penulisan masih perlu menyelesaikan algoritme Copy-on-Write, dan ini merupakan operasi baca tambahan dengan penulisan selanjutnya. Dan jangan lupa bahwa untuk cadangan Anda masih perlu membaca data dari volume yang sama. Singkatnya, akses linear Anda yang indah berubah menjadi akses acak tanpa ampun dengan semua konsekuensinya.
Kami jelas perlu melakukan sesuatu dengan ini, dan kami menerapkan saluran pipa untuk memproses permintaan tidak satu per satu, tetapi di seluruh bundel. Ini berfungsi seperti ini.
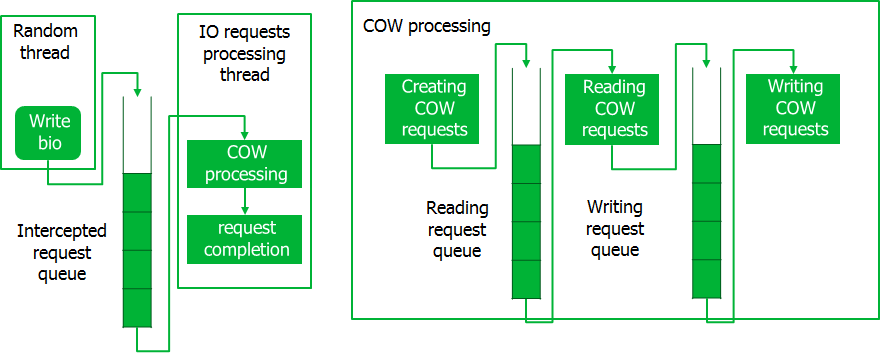
Saat mencegat permintaan, mereka ditempatkan dalam antrian, di mana aliran khusus membawanya dalam porsi. Saat ini, permintaan Kontrak Karya dibuat, yang juga diproses dalam batch. Saat memproses permintaan Kontrak Karya, pertama semua operasi baca dilakukan untuk seluruh bagian, setelah itu operasi tulis dilakukan. Hanya setelah pemrosesan seluruh bagian dari permintaan KK diselesaikan, permintaan yang dicegat dieksekusi. Konveyor semacam itu menyediakan akses ke disk dalam potongan besar data, yang meminimalkan kehilangan waktu.
Pelambatan
Sudah pada tahap debugging, nuansa lain muncul. Selama pencadangan, sistem menjadi tidak responsif, mis. permintaan I / O sistem mulai berjalan dengan penundaan yang lama. Tetapi, permintaan untuk membaca data dari snapshot dilakukan dengan kecepatan mendekati maksimum.
Saya harus mencekik proses pencadangan sedikit dengan menerapkan mekanisme pelambatan. Untuk melakukan ini, proses membaca dari gambar snapshot dimasukkan ke dalam keadaan menunggu jika antrian permintaan dicegat tidak kosong. Diharapkan, sistem menjadi hidup.
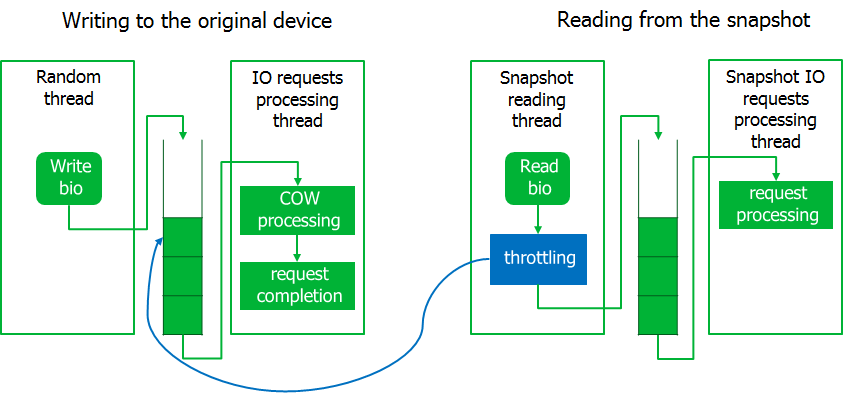
Akibatnya, jika beban pada sistem I / O meningkat tajam, maka proses pembacaan dari foto akan menunggu. Di sini kami memutuskan untuk dipandu oleh prinsip bahwa lebih baik kita mengakhiri cadangan dengan kesalahan daripada mengganggu server.
Jalan buntu
Saya pikir kita perlu menjelaskan secara lebih rinci apa itu.
Sudah pada tahap pengujian, kami mulai menghadapi situasi-situasi sistem yang lengkap dengan diagnosis tujuh masalah - satu reset.
Mereka mulai mengerti. Ternyata situasi ini dapat diamati jika, misalnya, Anda membuat snapshot dari perangkat blok di mana volume LVM berada, dan menempatkan snap-shot pada volume LVM yang sama. Biarkan saya mengingatkan Anda bahwa LVM menggunakan modul kernel mapper perangkat.

Dalam situasi ini, ketika mencegat permintaan tulis, modul, menyalin data ke snap-in, akan mengirim permintaan menulis ke volume LVM. Device mapper akan mengarahkan permintaan ini ke perangkat blokir. Permintaan dari device mapper akan kembali dicegat oleh modul. Tetapi permintaan baru tidak dapat diproses sampai yang sebelumnya telah diproses. Akibatnya, pemrosesan permintaan diblokir, Anda disambut oleh jalan buntu.
Untuk mencegah situasi ini, modul kernel itu sendiri memberikan batas waktu untuk operasi menyalin data ke snap-in. Ini memungkinkan Anda untuk mendeteksi cadangan macet dan macet. Logikanya di sini sama: lebih baik tidak membuat cadangan daripada menangguhkan server.
Database round robin
Ini sudah merupakan masalah yang dilemparkan oleh pengguna setelah rilis versi pertama.
Ternyata ada layanan seperti itu yang hanya terlibat dalam terus-menerus menimpa blok yang sama.
Contoh yang mencolok adalah layanan pemantauan, yang terus-menerus menghasilkan data tentang keadaan sistem dan menimpanya dalam lingkaran. Untuk tugas-tugas seperti itu gunakan basis data siklik khusus ( RRD ).Ternyata dengan cadangan basis-basis seperti itu, snapshot dijamin akan meluap. Dalam studi rinci tentang masalah ini, kami menemukan kelemahan dalam implementasi algoritma CoW. Jika blok yang sama ditimpa, maka data disalin ke snap-in setiap waktu. Hasil: duplikasi data dalam sekejap.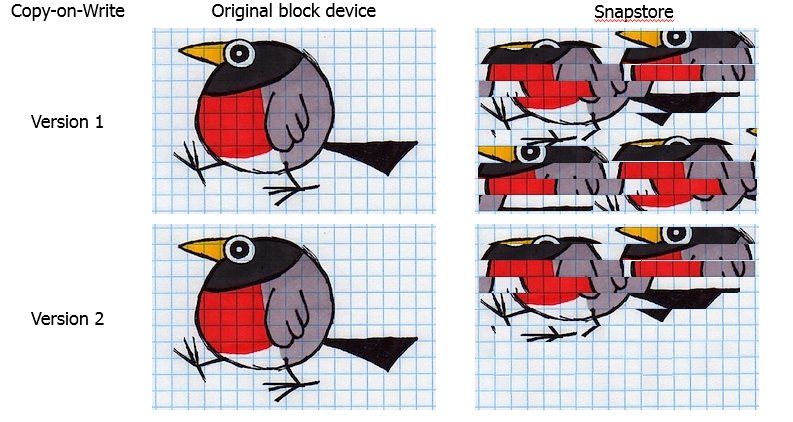 Secara alami, kami mengubah algoritme. Sekarang volume dibagi menjadi blok, dan data disalin ke blok jepret. Jika blok sudah disalin sekali, maka proses ini tidak berulang.
Secara alami, kami mengubah algoritme. Sekarang volume dibagi menjadi blok, dan data disalin ke blok jepret. Jika blok sudah disalin sekali, maka proses ini tidak berulang.Pilihan ukuran blok
Sekarang, ketika snapstrap dipecah menjadi balok, muncul pertanyaan: apa, sebenarnya, ukuran balok yang harus dibuat untuk memecahkan snapplug?Masalahnya ada dua. Jika blok dibuat besar, lebih mudah bagi mereka untuk beroperasi, tetapi jika setidaknya satu sektor berubah, Anda harus mengirim seluruh blok ke rig dan, sebagai akibatnya, kemungkinan kelebihan pengisian rig meningkat. Jelas, semakin kecil ukuran blok, semakin besar persentase data berguna yang dikirim ke snapstore, tetapi bagaimana hal itu akan mencapai kinerja?Mereka mencari kebenaran secara empiris dan menghasilkan 16KiB. Perhatikan juga bahwa Windows VSS juga menggunakan 16 blok KiB.
Jelas, semakin kecil ukuran blok, semakin besar persentase data berguna yang dikirim ke snapstore, tetapi bagaimana hal itu akan mencapai kinerja?Mereka mencari kebenaran secara empiris dan menghasilkan 16KiB. Perhatikan juga bahwa Windows VSS juga menggunakan 16 blok KiB.Alih-alih sebuah kesimpulan
Itu saja untuk saat ini. Saya akan meninggalkan banyak masalah lain, yang tidak kalah menarik, seperti ketergantungan pada versi kernel, pilihan opsi distribusi modul, kompatibilitas kABI, bekerja dalam kondisi backport, dll. Artikel itu ternyata sangat banyak, jadi saya memutuskan untuk memikirkan masalah yang paling menarik.Sekarang kami sedang bersiap untuk rilis versi 3.0, kode modul ada di github , dan siapa pun dapat menggunakannya di bawah lisensi GPL.