Bagi mereka yang menyukai
artikel saya
sebelumnya , saya terus membagikan kesan saya tentang alat pengujian stres Locust.
Saya akan mencoba untuk menunjukkan dengan jelas keuntungan menulis python uji beban dengan kode di mana Anda dapat dengan mudah menyiapkan data apa pun untuk pengujian dan memproses hasilnya.
Pemrosesan respons server
Terkadang dalam pengujian beban, tidak cukup hanya mendapatkan 200 OK dari server HTTP. Terjadi, perlu untuk memeriksa isi dari respons untuk memastikan bahwa di bawah memuat server mengeluarkan data yang benar atau melakukan perhitungan yang akurat. Hanya untuk kasus-kasus seperti itu, Locust menambahkan kemampuan untuk menimpa parameter keberhasilan respons server. Perhatikan contoh berikut:
from locust import HttpLocust, TaskSet, task import random as rnd class UserBehavior(TaskSet): @task(1) def check_albums(self): photo_id = rnd.randint(1, 5000) with self.client.get(f'/photos/{photo_id}', catch_response=True, name='/photos/[id]') as response: if response.status_code == 200: album_id = response.json().get('albumId') if album_id % 10 != 0: response.success() else: response.failure(f'album id cannot be {album_id}') else: response.failure(f'status code is {response.status_code}') class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000
Itu hanya memiliki satu permintaan, yang akan membuat beban dalam skenario berikut:
Dari server, kami meminta objek foto dengan id acak dalam kisaran 1 hingga 5.000 dan memeriksa id album di objek ini, dengan asumsi bahwa itu tidak boleh kelipatan 10
Di sini Anda dapat langsung memberikan beberapa penjelasan:
- konstruksi mengagumkan dengan request () sebagai respons: Anda berhasil menggantinya dengan response = request () dan bekerja secara diam-diam dengan objek respons
- URL dibentuk menggunakan sintaks format string yang ditambahkan dengan python 3.6, jika saya tidak salah - f '/ photos / {photo_id}' . Di versi sebelumnya, desain ini tidak akan berfungsi!
- argumen baru yang belum pernah kami gunakan sebelumnya, catch_response = Benar , memberi tahu Locust bahwa kami sendiri yang akan menentukan keberhasilan respons server. Jika Anda tidak menentukannya, maka kami akan menerima objek respons dengan cara yang sama dan dapat memproses datanya, tetapi tidak mendefinisikan ulang hasilnya. Di bawah ini adalah contoh terperinci.
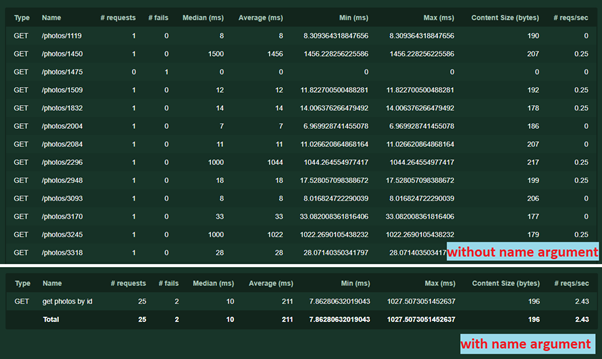
- Nama argumen lain = '/ foto / [id]' . Diperlukan untuk mengelompokkan permintaan dalam statistik. Nama dapat berupa teks apa pun, url berulang tidak diperlukan. Tanpa itu, setiap permintaan dengan alamat atau parameter unik akan direkam secara terpisah. Begini cara kerjanya:
Menggunakan argumen yang sama, Anda dapat melakukan trik lain - kadang-kadang terjadi bahwa satu layanan dengan parameter yang berbeda (misalnya, konten permintaan POST yang berbeda) melakukan logika yang berbeda. Agar hasil pengujian tidak campur aduk, Anda dapat menulis beberapa tugas terpisah, menentukan untuk masing-masing
nama argumennya sendiri.
Selanjutnya kita lakukan pengecekan. Saya memiliki 2 di antaranya. Pertama, kami memverifikasi bahwa server mengembalikan jawaban jika
response.status_code == 200 :
Jika ya, maka periksa apakah id album adalah kelipatan 10. Jika tidak kelipatan, maka tandai jawaban ini sebagai
respons yang berhasil.success
()Dalam kasus lain, kami menunjukkan mengapa respons gagal
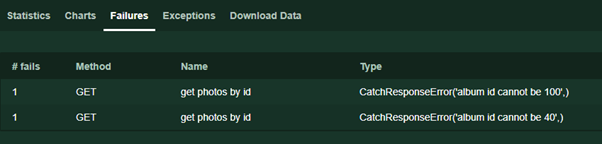
response.failure ('teks kesalahan') . Teks ini akan ditampilkan pada halaman Kegagalan selama pengujian.
Juga, pembaca yang penuh perhatian dapat memperhatikan tidak adanya Pengecualian yang merupakan karakteristik dari kode yang bekerja dengan antarmuka jaringan. Memang, dalam kasus batas waktu, kesalahan koneksi dan insiden tak terduga lainnya, Locust akan menangani kesalahan dan masih mengembalikan respons, menunjukkan, bagaimanapun, status kode respons adalah 0.
Jika kode masih melempar Pengecualian, kode itu akan ditulis ke tab Pengecualian saat runtime sehingga kami dapat menanganinya. Situasi yang paling khas adalah bahwa json'e dari jawaban tidak mengembalikan nilai yang kita cari, tetapi kita sudah melakukan operasi berikut di atasnya.
Sebelum menutup topik - dalam contoh saya menggunakan server json untuk kejelasan, karena lebih mudah untuk memproses tanggapan. Tetapi dengan kesuksesan yang sama Anda dapat bekerja dengan HTML, XML, FormData, lampiran file, dan data lain yang digunakan oleh protokol berbasis HTTP.
Bekerja dengan skenario yang kompleks
Hampir setiap kali tugasnya adalah untuk melakukan pengujian beban aplikasi web, dengan cepat menjadi jelas bahwa tidak mungkin untuk menyediakan cakupan yang layak dengan layanan GET saja - yang hanya mengembalikan data.
Contoh klasik: untuk menguji toko online, diharapkan bahwa pengguna
- Membuka toko utama
- Saya mencari barang
- Rincian item yang dibuka
- Menambahkan item ke troli
- Dibayar
Dari contoh, kita dapat mengasumsikan bahwa layanan panggilan dalam urutan acak tidak akan berfungsi, hanya secara berurutan. Selain itu, barang, keranjang, dan bentuk pembayaran mungkin memiliki pengidentifikasi unik untuk setiap pengguna.
Menggunakan contoh sebelumnya, dengan modifikasi kecil, Anda dapat dengan mudah menerapkan pengujian skenario seperti itu. Kami mengadaptasi contoh untuk server pengujian kami:
- Pengguna sedang menulis posting baru.
- Pengguna menulis komentar pada posting baru
- Pengguna membaca komentar
from locust import HttpLocust, TaskSet, task class FlowException(Exception): pass class UserBehavior(TaskSet): @task(1) def check_flow(self):
Dalam contoh ini, saya menambahkan kelas
FlowException baru. Setelah setiap langkah, jika tidak berjalan seperti yang diharapkan, saya melempar kelas pengecualian ini untuk mengganggu skrip - jika posting tidak berfungsi, maka tidak akan ada komentar, dll. Jika diinginkan, konstruksi dapat diganti dengan pengembalian yang biasa, tetapi dalam kasus ini, saat runtime dan ketika menganalisis hasilnya, tidak akan begitu jelas di mana skrip yang dijalankan jatuh pada tab Pengecualian. Untuk alasan yang sama, saya tidak menggunakan
coba ... kecuali membangun.
Membuat beban menjadi realistis
Sekarang saya dapat dicela - dalam kasus toko semuanya benar-benar linier, tetapi contoh dengan posting dan komentar terlalu dibuat-buat - mereka membaca posting 10 kali lebih sering daripada yang mereka buat. Secara masuk akal, mari kita membuat contoh lebih layak. Dan setidaknya ada 2 pendekatan:
- Anda dapat “meng-hardcode” daftar posting yang dibaca pengguna dan menyederhanakan kode pengujian jika ada kemungkinan dan fungsionalitas backend tidak bergantung pada posting tertentu
- Simpan posting yang dibuat dan baca jika tidak mungkin untuk mengatur daftar posting atau beban realistis tergantung pada posting mana yang dibaca (Saya menghapus pembuatan komentar dari contoh untuk membuat kodenya lebih kecil dan lebih visual)
from locust import HttpLocust, TaskSet, task import random as r class UserBehavior(TaskSet): created_posts = [] @task(1) def create_post(self): new_post = {'userId': 1, 'title': 'my shiny new post', 'body': 'hello everybody'} post_response = self.client.post('/posts', json=new_post) if post_response.status_code != 201: return post_id = post_response.json().get('id') self.created_posts.append(post_id) @task(10) def read_post(self): if len(self.created_posts) == 0: return post_id = r.choice(self.created_posts) self.client.get(f'/posts/{post_id}', name='read post') class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000
Di kelas
UserBehavior, saya membuat daftar
Created_posts . Berikan perhatian khusus - ini adalah objek dan itu tidak dibuat dalam konstruktor dari kelas
__init __ (), oleh karena itu, tidak seperti sesi klien, daftar ini umum untuk semua pengguna. Tugas pertama membuat posting dan menulis id ke daftar. Yang kedua - 10 kali lebih sering, membaca satu posting yang dipilih secara acak dari daftar. Kondisi tambahan dari tugas kedua adalah untuk memeriksa apakah ada tulisan yang dibuat.
Jika kami ingin setiap pengguna hanya mengoperasikan dengan data mereka sendiri, kami dapat mendeklarasikannya dalam konstruktor sebagai berikut:
class UserBehavior(TaskSet): def __init__(self, parent): super(UserBehavior, self).__init__(parent) self.created_posts = list()
Beberapa fitur lainnya
Untuk peluncuran tugas berurutan, dokumentasi resmi menyarankan bahwa kami juga menggunakan anotasi tugas @seq_task (1), menentukan nomor seri tugas dalam argumen
class MyTaskSequence(TaskSequence): @seq_task(1) def first_task(self): pass @seq_task(2) def second_task(self): pass @seq_task(3) @task(10) def third_task(self): pass
Dalam contoh ini, setiap pengguna pertama-tama akan menjalankan
first_task , lalu
second_task , lalu 10 kali
third_task .
Terus terang, ketersediaan kesempatan seperti itu menggembirakan, tetapi, tidak seperti contoh sebelumnya, tidak jelas bagaimana mentransfer hasil dari tugas pertama ke yang kedua jika perlu.
Juga, untuk skenario yang sangat kompleks, dimungkinkan untuk membuat set tugas bersarang, pada kenyataannya, membuat beberapa kelas TaskSet dan menghubungkan satu sama lain.
from locust import HttpLocust, TaskSet, task class Todo(TaskSet): @task(3) def index(self): self.client.get("/todos") @task(1) def stop(self): self.interrupt() class UserBehavior(TaskSet): tasks = {Todo: 1} @task(3) def index(self): self.client.get("/") @task(2) def posts(self): self.client.get("/posts") class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000
Dalam contoh di atas, dengan probabilitas 1 hingga 6, skrip
Todo akan diluncurkan, dan akan dieksekusi hingga, dengan probabilitas 1 hingga 4, skrip tersebut akan kembali ke skrip
UserBehavior . Sangat penting bahwa Anda memiliki panggilan ke
self.interrupt () - tanpanya, pengujian akan fokus pada subtugas.
Terima kasih sudah membaca. Pada artikel terakhir saya akan menulis tentang pengujian terdistribusi dan pengujian tanpa UI, serta tentang kesulitan yang saya temui selama pengujian dengan Locust dan bagaimana cara mengatasinya.