
Habr, ini adalah laporan oleh insinyur perangkat lunak Alexei Starkov pada konferensi Moscow Python Conf ++ 2018 di Moskow. Video di akhir pos.
Halo semuanya! Nama saya Alexei Starkov - ini saya, dalam tahun-tahun terbaik saya, saya bekerja di sebuah pabrik.
Sekarang saya bekerja di Qrator Labs. Pada dasarnya, sepanjang hidup saya, saya belajar C dan C ++ - Saya suka Alexandrescu, The Gang of Four, prinsip-prinsip SOLID - itu saja. Yang membuat saya menjadi astronot arsitektur. Saya telah menulis Python selama beberapa tahun terakhir karena saya menyukainya.
Sebenarnya, siapa "kosmonot arsitektur"? Pertama kali saya bertemu dengan Joel Spolsky, Anda mungkin membacanya. Dia menggambarkan "astronot" sebagai orang yang ingin membangun arsitektur yang ideal, yang menggantung abstraksi, atas abstraksi, atas abstraksi, yang menjadi semakin umum. Pada akhirnya, level ini sangat tinggi sehingga menggambarkan semua program yang mungkin, tetapi tidak menyelesaikan masalah praktis. Pada saat ini, "astronot" (ini terakhir kali istilah ini dikelilingi oleh tanda kutip) kehabisan udara dan dia mati.
Saya juga memiliki kecenderungan ke arah eksplorasi ruang arsitektur, tetapi dalam laporan ini saya akan berbicara sedikit tentang bagaimana itu menggigit saya dan tidak memungkinkan saya untuk membangun sebuah sistem dengan kinerja yang diperlukan. Yang utama adalah bagaimana saya mengatasinya.
Ringkasan laporan saya: was / was.

Peningkatan ribuan dan jutaan kali. Ketika saya membuat slide ini, satu-satunya pikiran saya adalah "Bagaimana?"

Di mana saya bisa begitu banyak mengacau? Jika Anda tidak ingin mengacaukan seperti saya - baca terus.

Saya akan berbicara tentang sistem konfigurasi. Sistem konfigurasi adalah alat internal di Qrator Labs yang menyimpan konfigurasi untuk Software Defined Network (SDN) - jaringan penyaringan kami. Ini berkomitmen untuk menyinkronkan konfigurasi antara komponen dan memonitor statusnya.

Singkatnya, terdiri dari apa itu? Kami memiliki database yang menyimpan snapshot dari konfigurasi kami untuk seluruh jaringan, dan kami memiliki server yang memproses perintah yang datang kepadanya dan entah bagaimana mengubah konfigurasi.
Administrator teknis dan klien kami datang ke server ini dan menggunakan konsol, melalui API titik akhir, API REST, JSON RPC, dan hal-hal lain, mengeluarkan perintah ke server, sehingga mengubah konfigurasi kami.
Tim bisa sangat sederhana atau lebih rumit. Kemudian, kami memiliki satu set penerima yang membentuk SDN kami dan server mendorong konfigurasi ke penerima ini. Itu terdengar sangat sederhana. Pada dasarnya, saya akan berbicara tentang bagian ini.
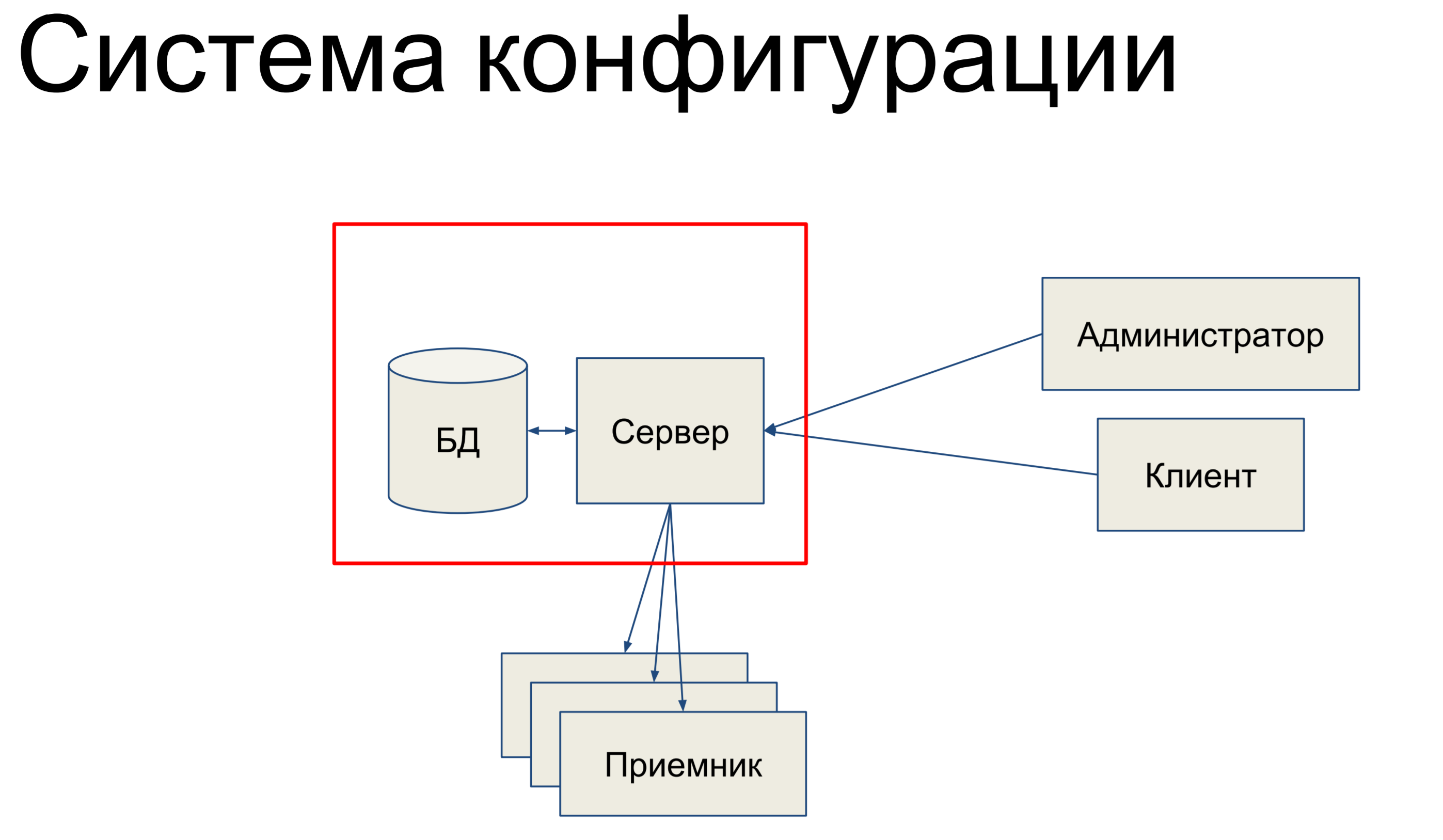
Karena dialah yang terkait dengan database dan alkimia.

Apa kekhasan sistem ini? Cukup kecil - biasa-biasa saja. Ratusan ribu, hingga jutaan, entitas disimpan dalam database ini. Keunikannya adalah grafik hubungan antar entitas cukup kompleks. Ada beberapa hierarki pewarisan antara entitas, ada inklusi, hanya ada dependensi di antara entitas. Semua batasan ini ditentukan oleh logika bisnis dan kita harus mematuhinya.
Rasio permintaan tulis untuk membaca permintaan adalah sekitar 15: 1. Ini jelas: ada banyak perintah untuk mengubah konfigurasi dan sekali dalam jangka waktu tertentu kami memiliki konfigurasi push ke titik akhir.
MySQL digunakan secara internal - juga tersedia di produk-produk lain dari perusahaan kami, kami memiliki keahlian yang cukup serius pada database ini, ada orang yang dapat bekerja dengannya: membangun skema data, permintaan desain, dan yang lainnya. Oleh karena itu, kami menggunakan MySQL sebagai basis data relasional universal.

Apa masalahnya setelah kami merancang sistem ini? Eksekusi satu perintah memakan waktu dari satu hingga tiga puluh detik, tergantung pada kompleksitas tim. Dengan demikian, penundaan eksekusi mencapai lima menit. Satu tim tiba - 30 detik, yang kedua dan seterusnya, setumpuk akumulasi - penundaan 5 menit.
Keterlambatan dalam menerapkan konfigurasi hingga sepuluh menit. Diputuskan bahwa ini tidak cukup bagi kami dan bahwa optimasi diperlukan.

Pertama, sebelum melakukan optimasi apa pun, perlu untuk melakukan penyelidikan dan mencari tahu apa yang sebenarnya terjadi.

Ternyata, kami tidak memiliki komponen yang paling penting untuk penyelidikan - kami tidak memiliki telemetri. Karena itu, jika Anda merancang semacam sistem, pertama, pada tahap desain, masukkan telemetri ke dalamnya. Sekalipun sistem awalnya kecil, lalu sedikit lagi, lalu bahkan lebih lagi - pada akhirnya, semua orang sampai pada situasi di mana Anda perlu menonton trek, tetapi tidak ada telemetri.
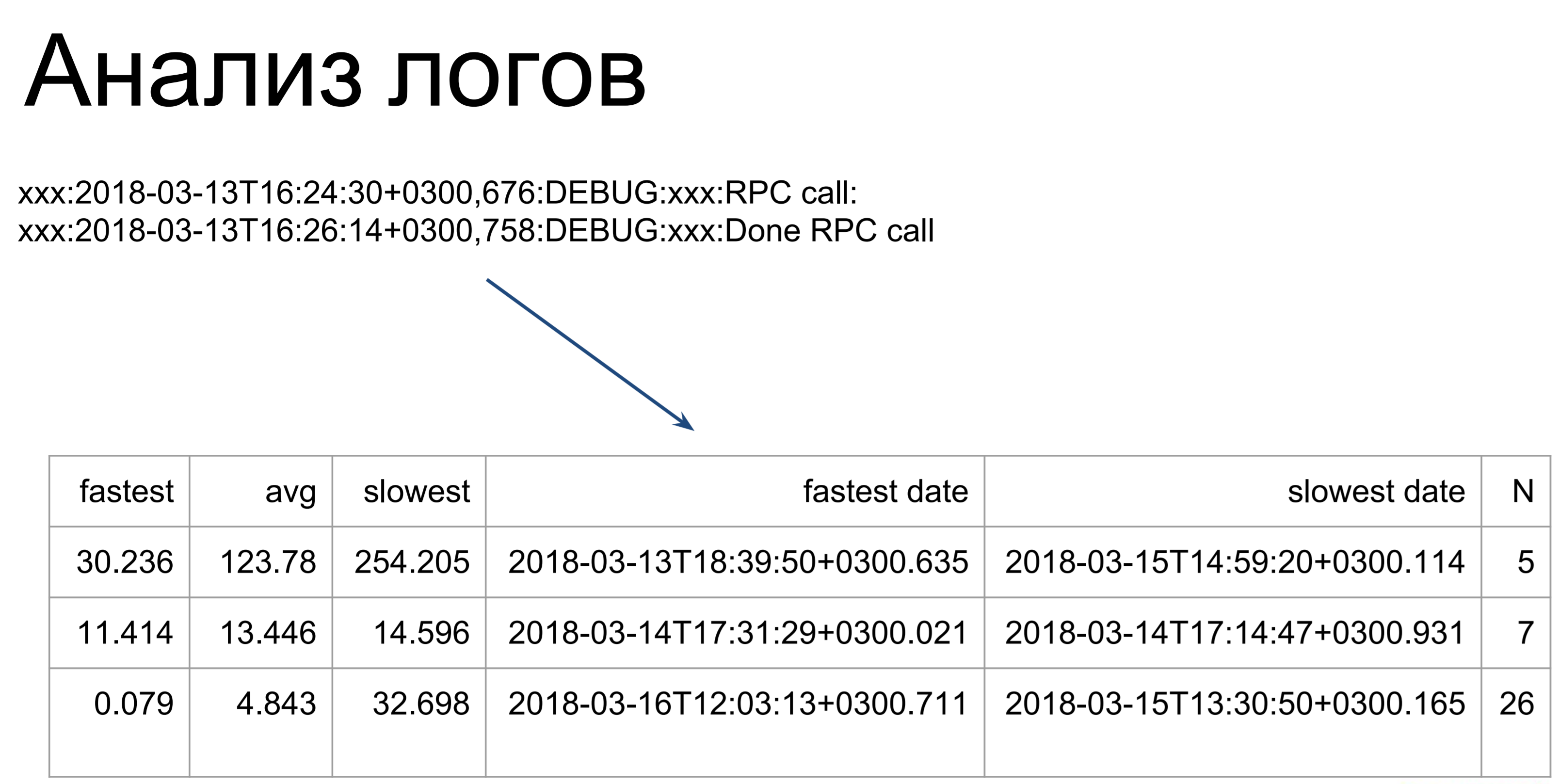
Apa yang dapat dilakukan selanjutnya jika Anda tidak memiliki telemetri? Anda dapat menganalisis log. Di sini, skrip yang cukup sederhana memeriksa log kami dan mengubahnya menjadi tabel seperti itu, menggambarkan waktu eksekusi perintah tercepat, paling lambat, dan rata-rata. Mulai dari sini, kita sudah bisa melihat di mana kita memiliki lelucon: tim mana yang membutuhkan waktu lebih lama untuk mengeksekusi, mana yang lebih cepat.

Satu-satunya hal yang perlu diperhatikan adalah ketika menganalisis log, kami hanya mempertimbangkan waktu eksekusi dari perintah-perintah ini di server. Ini adalah tahap pertama - yang ditandai sebagai t2. t1 - ini adalah bagaimana klien akan melihat waktu eksekusi tim kami: masuk ke antrian, menunggu, eksekusi di server. Waktu ini akan lebih lama, jadi kami mengoptimalkan waktu t2, dan kemudian menggunakan waktu t1 untuk menentukan apakah kami telah mencapai tujuan.
t1 adalah metrik kualitas kinerja kami.

Dengan demikian, ini adalah bagaimana kami membuat profil semua tim - yaitu, kami mengambil log dari server, mengendarainya melalui skrip kami, melihat dan mengidentifikasi komponen yang bekerja paling lambat. Server dibangun cukup modular, komponen terpisah bertanggung jawab untuk setiap perintah, dan kami dapat membuat profil komponen secara terpisah - dan membuat tolok ukur untuknya. Jadi di sini kami memiliki kelas - untuk setiap komponen bermasalah yang kami tulis di mana dalam code_under_test () kami melakukan beberapa kegiatan yang menggambarkan penggunaan komponen tempur. Dan ada dua metode: profil () dan bangku (). Panggilan pertama cProfile, menunjukkan berapa kali apa yang dipanggil, di mana kemacetan berada.
bench () dijalankan beberapa kali dan dianggap metrik yang berbeda untuk kami - ini adalah cara kami mengevaluasi kinerja.
Tapi ternyata ini bukan masalahnya!

Masalah utama adalah jumlah permintaan basis data. Ada banyak permintaan, dan untuk memahami mengapa ada begitu banyak, mari kita lihat bagaimana semuanya diatur.
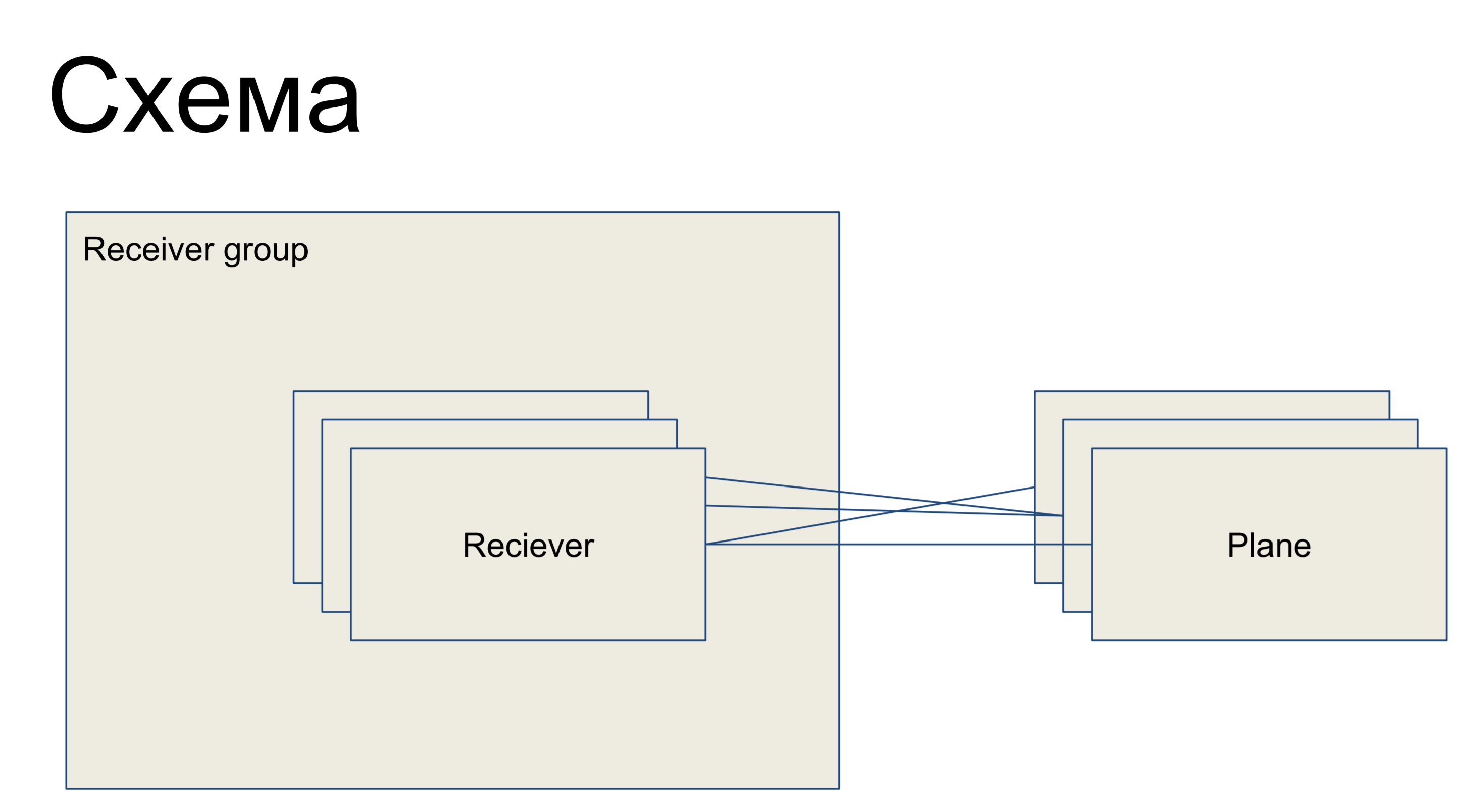
Di depan kita ada sepotong sirkuit sederhana yang mewakili penerima kita, disajikan dalam bentuk kelas Penerima. Mereka disatukan dalam beberapa grup - grup penerima. Dan, dengan demikian, ada beberapa bidang konfigurasi - potongan konfigurasi, yang merupakan bagian dari konfigurasi yang bertanggung jawab untuk satu "peran" penerima ini. Misalnya saja untuk routing - routing plane. Dataran dengan penerima dapat dihubungkan dalam urutan apa pun - yaitu, ini adalah hubungan banyak-ke-banyak.
Ini adalah bagian dari garis besar yang saya presentasikan di sini sehingga contoh-contoh dapat dipahami lebih lanjut.
Apa yang ingin dilakukan setiap kosmonot arsitektur ketika dia melihat API orang lain? Dia ingin menyembunyikannya, abstrak dan menulis antarmuka-nya agar dapat menghapus API ini, atau lebih tepatnya menyembunyikannya.
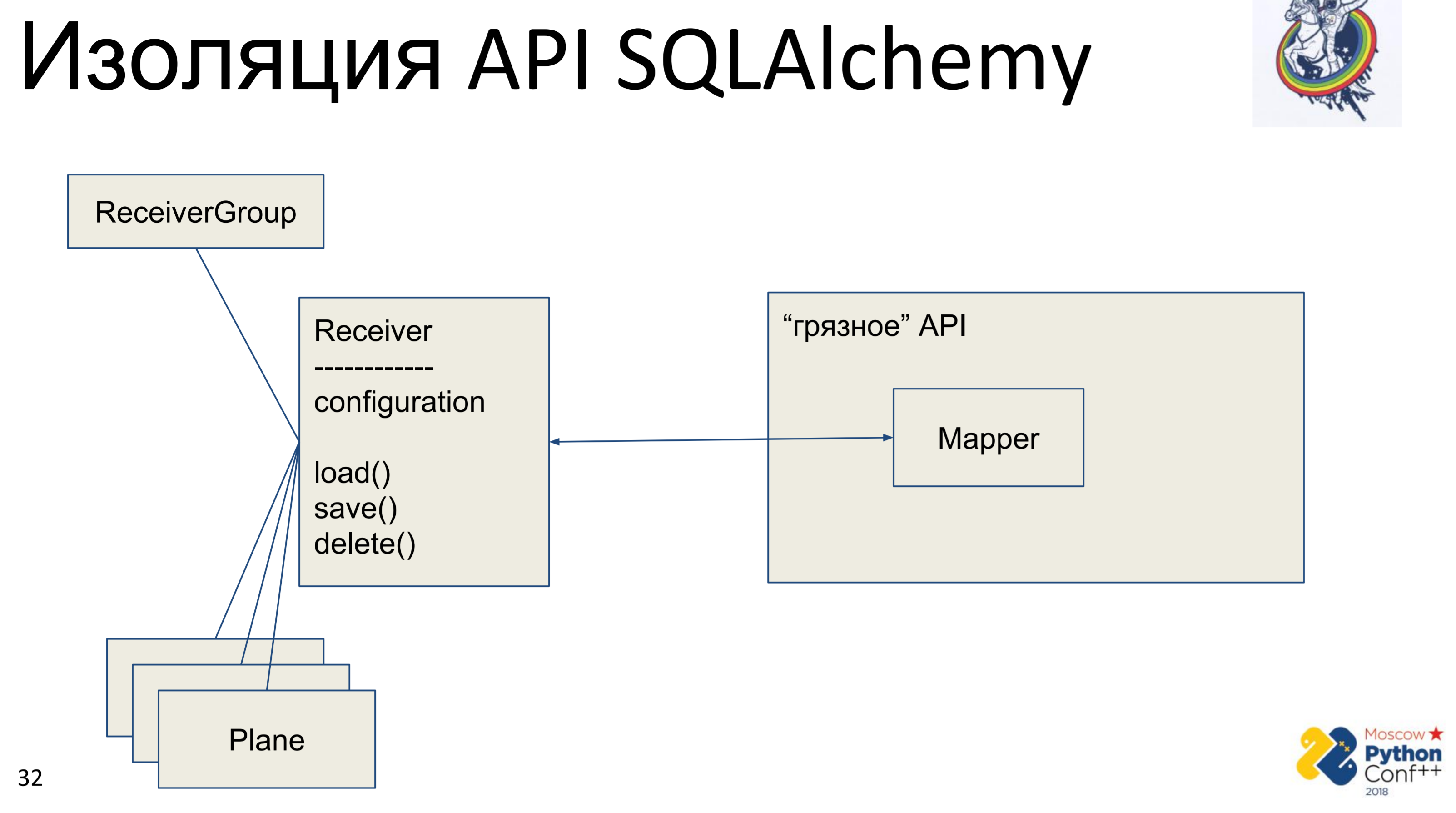
Oleh karena itu, ada API alkimia "kotor", di mana ada, pada kenyataannya, pemetaan dan kelas "murni" kami - Receiver, di mana beberapa konfigurasi disimpan dan ada metode: load (), save (), save (), delete (). Dan semua kelas lain yang terkait dengannya. Kami mendapatkan grafik objek Python, yang entah bagaimana terhubung satu sama lain - masing-masingnya memiliki metode load (), save (), delete (), yang mengacu pada mapper alkimia, yang, pada gilirannya, memanggil API.

Implementasinya di sini sangat sederhana. Kami memiliki metode memuat yang membuat kueri ke database dan untuk setiap objek yang diterima membuat objek Python sendiri. Ada metode simpan yang melakukan operasi yang berlawanan - terlihat jika ada objek dalam database menggunakan kunci utama, jika tidak - itu membuat, menambah, dan kemudian kita menyimpan keadaan objek ini. hapus pada kunci utama menerima dan menghapus objek dari database.

Masalah utama segera terlihat - ini adalah pemetaan. Pertama, kita melakukannya sekali dari objek Python ke mapper, lalu mapper ke pangkalan. Pemetaan tambahan adalah satu atau dua panggilan, yang mungkin belum menakutkan. Masalah utama adalah sinkronisasi manual. Kami memiliki dua objek antarmuka "bersih" dan salah satunya mengubah atribut - bagaimana kita melihat bahwa atribut telah berubah di yang lain? Tidak mungkin. Hal ini diperlukan untuk menggabungkan perubahan ke dalam basis data dan mendapatkan atribut di objek lain. Tentu saja, jika kita tahu bahwa objek hadir dalam konteks yang sama, kita dapat melacaknya. Tetapi jika kita memiliki dua sesi di tempat yang berbeda - hanya melalui pangkalan, atau memblokir pangkalan di memori, yang tidak kita lakukan.
Load / save / delete ini adalah mapper lain yang sepenuhnya menduplikasi bagian dalam alkimia, yang ditulis dengan baik, diuji. Alat ini sudah berumur bertahun-tahun, ada banyak bantuan di internet dan menggandakannya juga tidak terlalu bagus.
Lihat ikon di sudut kanan atas? Jadi saya akan menandai slide di mana sesuatu dilakukan untuk "kemurnian", untuk meningkatkan tingkat abstraksi, untuk astronotika arsitektur. Artinya, slide tanpa ikon ini bersifat pragmatis dan membosankan, tidak menarik dan tidak bisa dibaca.
Apa yang harus dilakukan jika banyak pertanyaan lambat. Berapa banyak? Sebenarnya banyak. Bayangkan sebuah rantai warisan: satu objek, ia memiliki satu orangtua, bahwa satu memiliki orangtua lain. Kami menyinkronkan objek anak - untuk melakukan ini, Anda harus terlebih dahulu menyinkronkan orang tua. Untuk menyinkronkan induk, Anda perlu menyinkronkan induknya. Yah, semua orang disinkronkan. Faktanya, tergantung pada bagaimana kita telah membangun grafik, kita dapat berjalan dan menyinkronkan semua objek ini seratus kali - karenanya sejumlah besar permintaan.
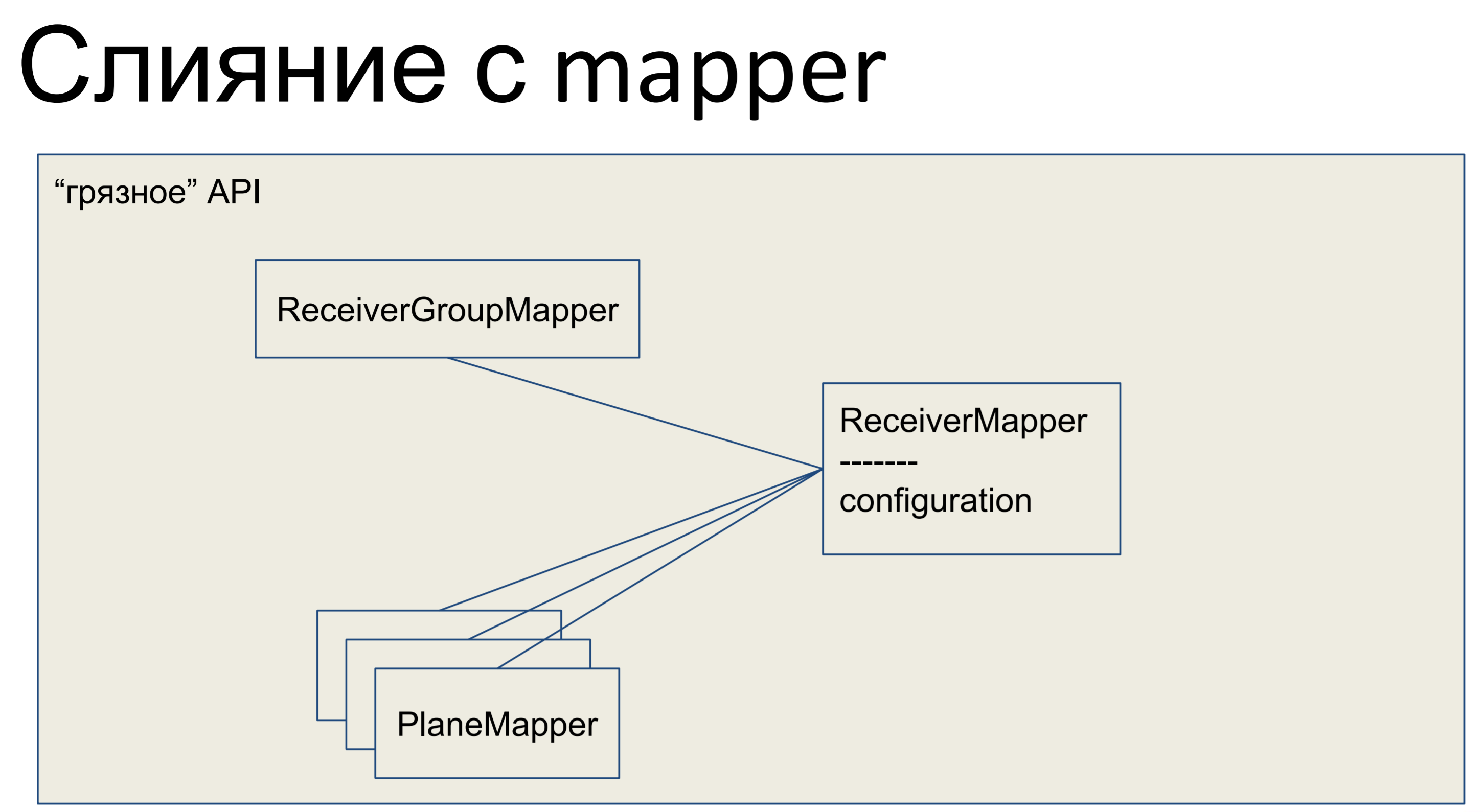
Apa yang telah kita lakukan Kami mengambil semua logika bisnis kami dan memasukkannya ke mapper. Semua objek lain di sini juga bergabung dengan pemetaan, dan seluruh API kami, seluruh lapisan abstraksi data, ternyata kotor.

Ini adalah tampilannya di Python - mapper kami memiliki semacam logika bisnis, ada deskripsi deklaratif dari plat ini di sana. Kolom terdaftar, hubungan. Di sini kita memiliki kelas seperti itu.

Tentu saja, dari sudut pandang astronot mana pun, API yang kotor adalah kelemahannya. Logika bisnis dalam deskripsi deklaratif dari pangkalan. Skema dicampur dengan logika bisnis. Fiuh. Jelek.
Deskripsi sirkuit berantakan. Ini sebenarnya masalah - jika logika bisnis tidak memiliki dua baris, tetapi volume yang lebih besar, maka di kelas ini kita perlu menggulir atau mencari waktu yang sangat lama untuk mendapatkan deskripsi spesifik. Sebelum itu, semuanya indah: di satu tempat deskripsi dasar, deklaratif, deskripsi skema, di tempat lain logika bisnis. Dan kemudian sirkuit itu berantakan.
Tetapi, di sisi lain, kami segera mendapatkan mekanisme alkimia: unit kerja, yang memungkinkan Anda untuk melacak objek mana yang kotor dan relay mana yang perlu diperbarui; kami mendapatkan hubungan yang memungkinkan kami untuk menyingkirkan pertanyaan tambahan dalam database, tanpa memastikan bahwa koleksi yang relevan diisi; dan peta identitas yang paling membantu kami. Peta identitas memastikan bahwa dua objek Python akan menjadi objek Python yang sama jika mereka memiliki kunci utama yang sama.
Oleh karena itu, kami segera mengurangi kompleksitas menjadi linier.

Ini adalah hasil antara. Kinerja segera meningkat 10 kali lipat, jumlah permintaan ke database turun sekitar 40-80 kali dan RPS naik menjadi 1-5. Bagus Tapi APInya kotor. Apa yang harus dilakukan
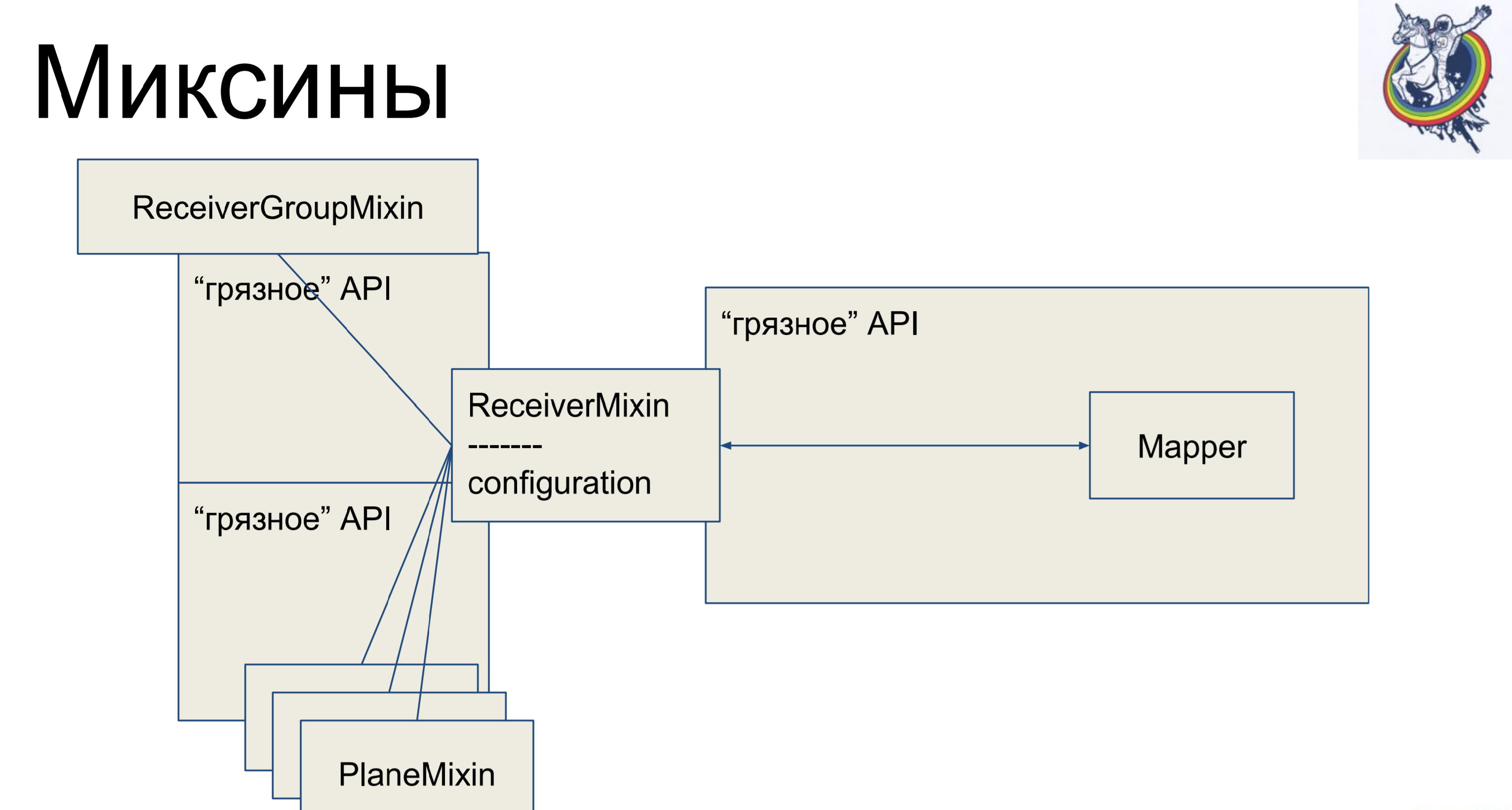
Mixin. Kami mengambil logika bisnis, sekali lagi kami menghapusnya dari mapper kami, tetapi agar tidak ada pemetaan lagi, kami akan mewarisi mapper kami di dalam alkimia dari mixin kami. Kenapa tidak sebaliknya? Ini tidak akan bekerja dalam alkimia, dia akan bersumpah dan berkata: "Anda memiliki dua kelas yang berbeda mengacu pada satu tablet, tidak ada polyformism - pergi dari sini." Jadi - itu mungkin.
Dengan demikian, kami memiliki deskripsi deklaratif di mapper, yang diwarisi dari mixin dan menerima semua logika bisnis. Sangat nyaman Dan kelas-kelas lainnya persis sama. Tampaknya - keren, semuanya bersih. Tetapi ada satu peringatan - koneksi dan relay tetap di dalam alkimia, dan ketika kita, katakanlah, bergabung melalui tabel sekunder plat menengah, maka mapper dari plat ini entah bagaimana akan ada dalam kode klien, yang tidak terlalu indah.
Alkimia tidak akan menjadi kerangka kerja yang baik, terkenal, jika itu tidak memberi saya kesempatan untuk melawan ini.

Seperti apa bentuk mixin. Dia memiliki logika bisnis, pemetaan secara terpisah, deskripsi deklaratif piring. Koneksi tetap dalam alkimia, tetapi logika bisnis terpisah.
Seperti apakah garis besar umum itu?
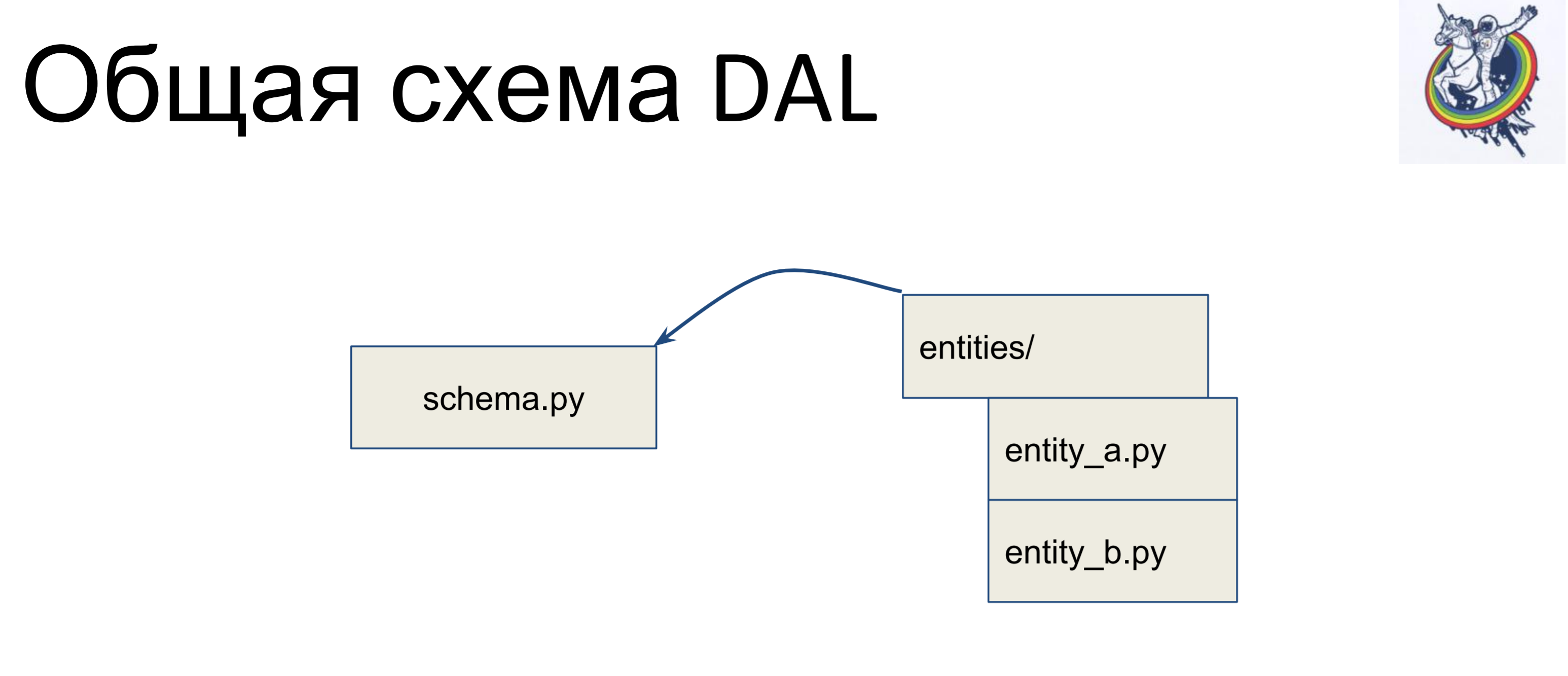
Kami memiliki file dengan skema di mana semua kelas deklaratif kami dikumpulkan - sebut saja schema.py. Dan kami memiliki entitas dalam logika bisnis, secara terpisah. Dan, entitas ini diwarisi di dalam file skema - kami menulis kelas terpisah untuk setiap entitas, dan mewarisinya dalam skema. Dengan demikian, logika bisnis terletak di satu tumpukan, skema di yang lain dan mereka dapat diubah secara independen.
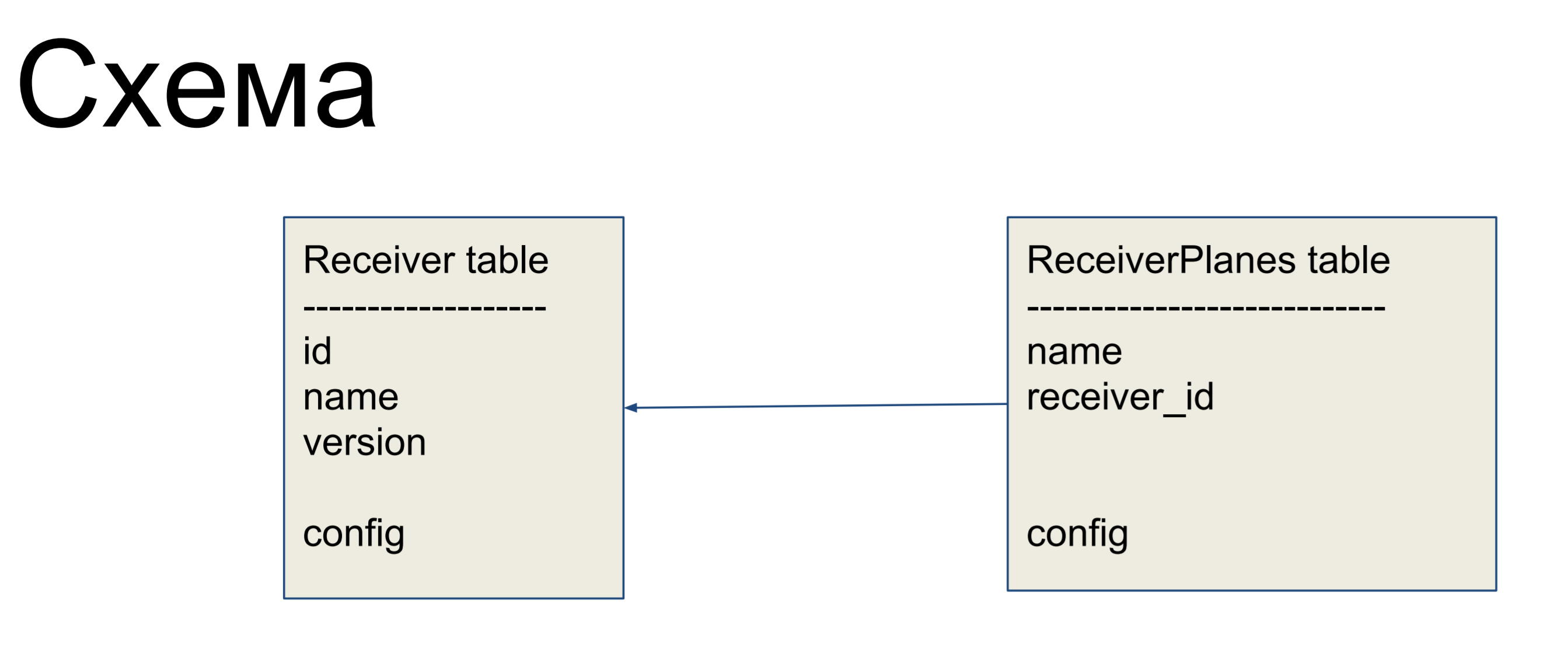
Sebagai contoh peningkatan, kami akan mempertimbangkan skema sederhana dari dua label: penerima (tabel Receiver) dan potongan konfigurasi (tabel ReceiverPlanes). Irisan konfigurasi banyak-ke-satu dikaitkan dengan label receiver. Tidak ada yang rumit.
Untuk menyembunyikan hubungan di dalam antarmuka alkimia yang "kotor", kami menggunakan hubungan dan koleksi.

Mereka memungkinkan kita untuk menyembunyikan pembuat peta kita dari kode klien.

Secara khusus, dua koleksi yang sangat berguna adalah association_proxy dan atribut_mapped_collection. Kami menggunakannya bersama. Bagaimana hubungan klasik bekerja dalam alkimia: kita memiliki hubungan - ini adalah kumpulan, daftar, pemetaan tertentu. Pemetaan adalah objek hubungan ujung-jauh. Attribute_mapped_collection memungkinkan Anda mengganti daftar ini dengan dict, kunci yang akan menjadi beberapa atribut pemetaan, dan nilainya adalah pemetaan itu sendiri.
Ini adalah langkah pertama.
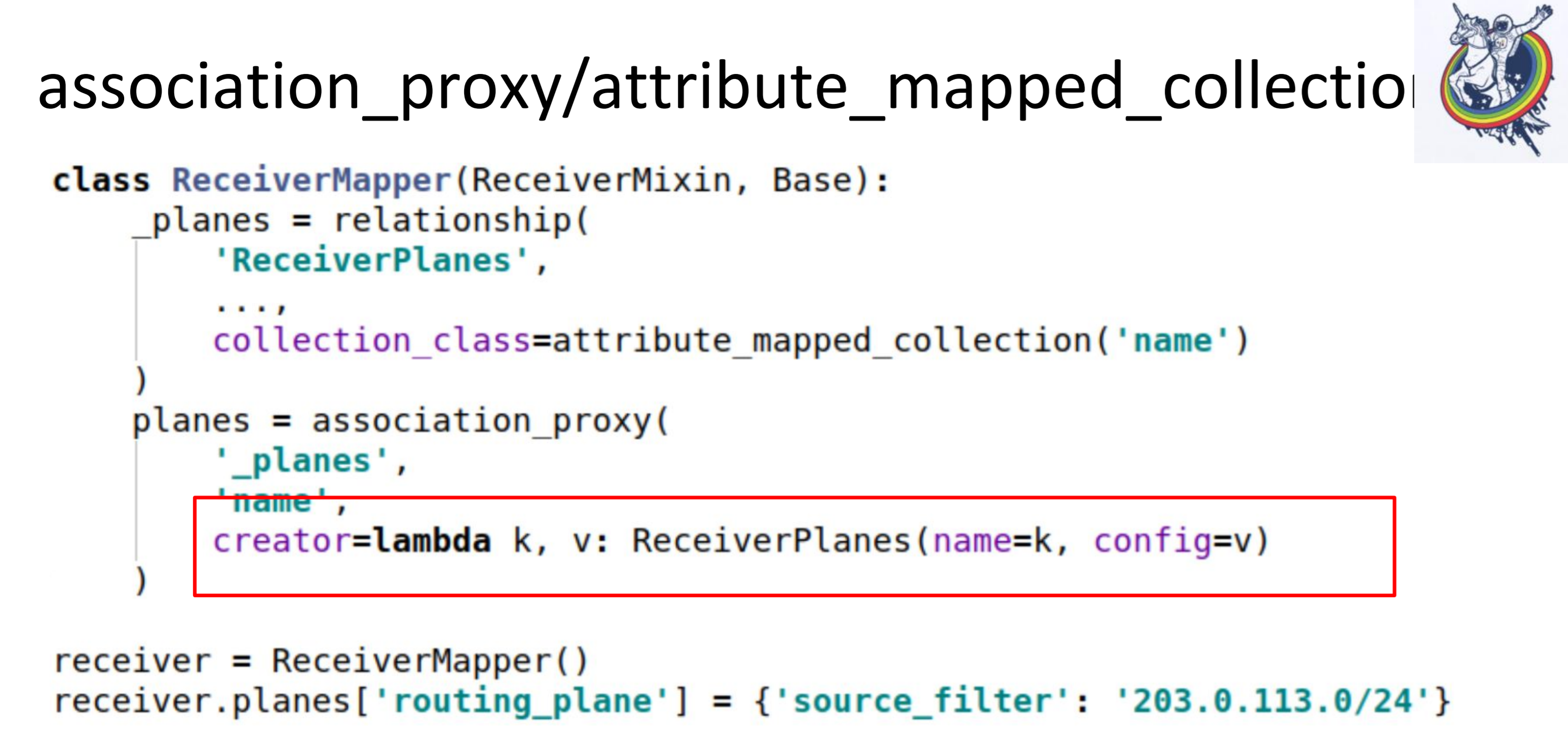
Langkah kedua, kami melakukan asosiasi_proksi atas hubungan ini. Ini memungkinkan kita untuk tidak meneruskan mapper ke koleksi, tetapi untuk memberikan beberapa nilai yang nantinya akan digunakan untuk menginisialisasi mapper kita, ReceiverPlanes.
Di sini kita memiliki lambda, di mana kita memberikan kunci dan nilai. Kunci berubah menjadi nama irisan konfigurasi, dan nilai menjadi nilai irisan konfigurasi. Akibatnya, dalam kode klien, semuanya terlihat seperti ini.

Kami hanya menempatkan semacam dikte dalam semacam kamus. Semuanya berfungsi: tidak ada pemetaan, tidak ada alkimia, tidak ada database.
Benar, ada jebakan.

Jika kita menetapkan nilai yang berbeda, atau bahkan satu, ke kunci yang sama dua kali - lambda dipanggil untuk setiap item set tersebut, sebuah objek dibuat - seorang mapper. Dan, tergantung pada bagaimana skema disusun, ini dapat menyebabkan berbagai konsekuensi, dari "pelanggaran konstanta" hingga konsekuensi yang tidak terduga. Misalnya, Anda semacam menghapus objek dari koleksi, tetapi masih ada di sana: Anda hanya menghapus satu. Ketika saya mulai, saya menghabiskan banyak waktu untuk hal-hal seperti itu.
Dan sedikit sinkronisasi implisit. Association_proxy dan atribut_mapped_collection mungkin sedikit tertunda: ketika kita membuat objek mapper - itu ditambahkan ke database, tetapi belum hadir dalam atribut koleksi. Itu akan muncul di sana hanya ketika atribut berakhir pada sesi ini. Ketika kedaluwarsa, sinkronisasi baru dengan database akan terjadi dan itu akan sampai di sana.
Untuk mengatasi ini, kami menggunakan koleksi kami sendiri yang ditulis sendiri. Ini bahkan bukan alkimia - Anda bisa membuat koleksi sendiri untuk mengatasi semua ini.
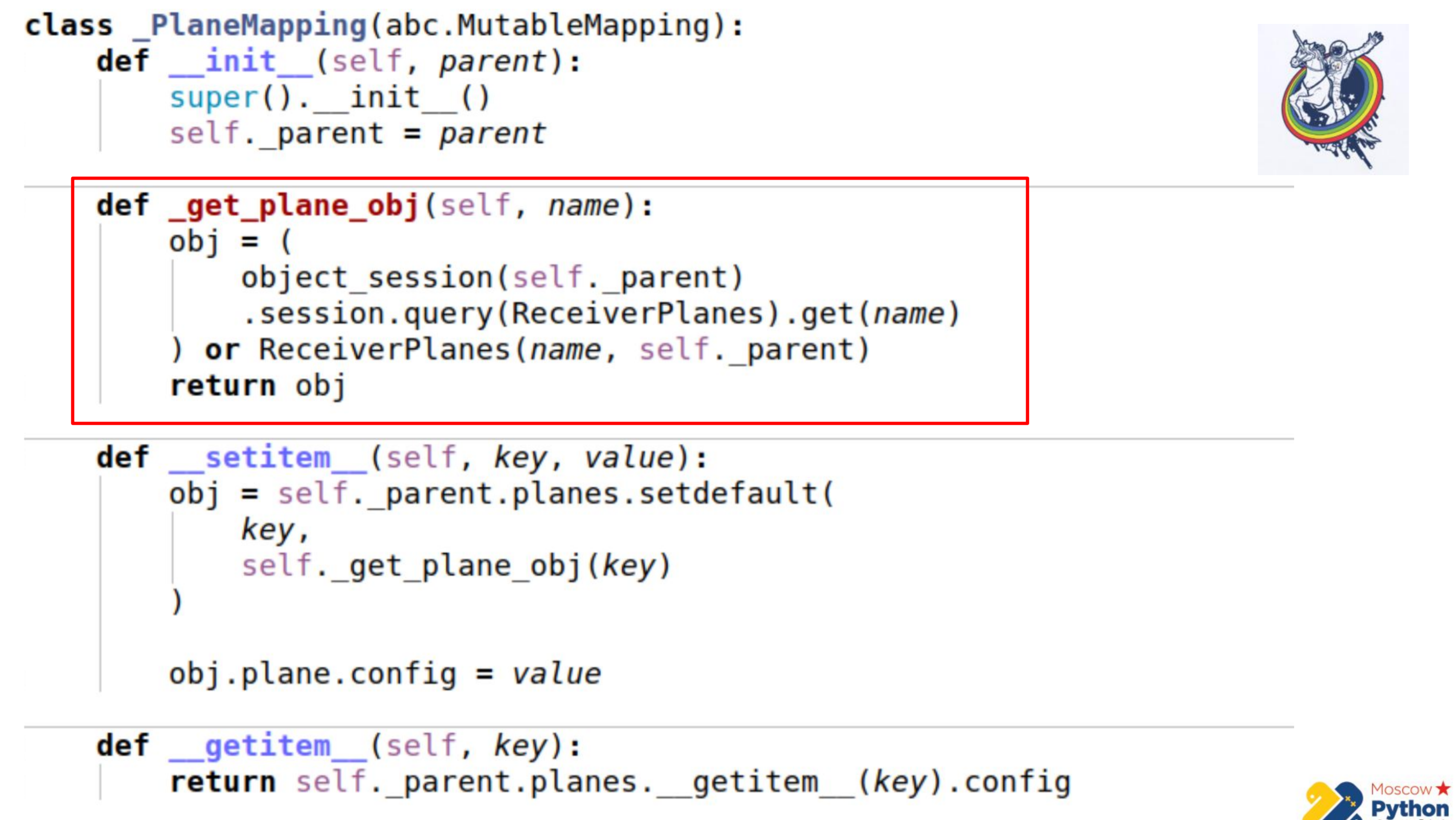
Ada lebih banyak kode dan bagian terpenting disorot. Kami memiliki koleksi tertentu yang diwarisi dari pemetaan bisu - ini adalah dict, di mana Anda dapat mengubah nilainya. Dan ada metode _get_plane_obj - untuk mendapatkan objek konfigurasi slice.
Di sini kami melakukan hal-hal sederhana - kami mencoba untuk mendapatkannya dengan nama, dengan beberapa kunci utama dan, jika tidak, maka kami membuat dan mengembalikan objek ini.
Selanjutnya, kami mendefinisikan ulang hanya dua metode: __setitem__ dan __getitem__
Dalam __setitem__, kami menempatkan benda-benda ini dalam koleksi kami, dalam suatu hubungan. Satu-satunya hal adalah kami memberikan nilai di bagian paling akhir. Jadi, kami menerapkan mekanisme yang sama dengan associ_proxy - meneruskan nilainya, dict sana, dan ditugaskan ke atribut yang sesuai.
__getitem__ melakukan manipulasi balik. Ini menerima dengan kunci beberapa objek dari relay dan mengembalikan atributnya. Ada juga jebakan kecil di sini - jika Anda cache koleksi di dalam pemetaan kami, mungkin untuk keluar dari sinkronisasi sedikit. Karena ketika atribut koleksi kedaluwarsa dalam alkimia, koleksi diganti dengan yang lain, setelah kedaluwarsa. Oleh karena itu, kami dapat menyimpan referensi ke koleksi lama dan tidak tahu bahwa yang lama telah kedaluwarsa dan yang baru telah muncul. Oleh karena itu, pada bagian terakhir, kita langsung menuju contoh alkimia, sekali lagi kita mendapatkan koleksi melalui __getattr__ dan kita melakukan __getitem__ dengan itu. Artinya, kami tidak dapat men-cache koleksi Planes di sini.
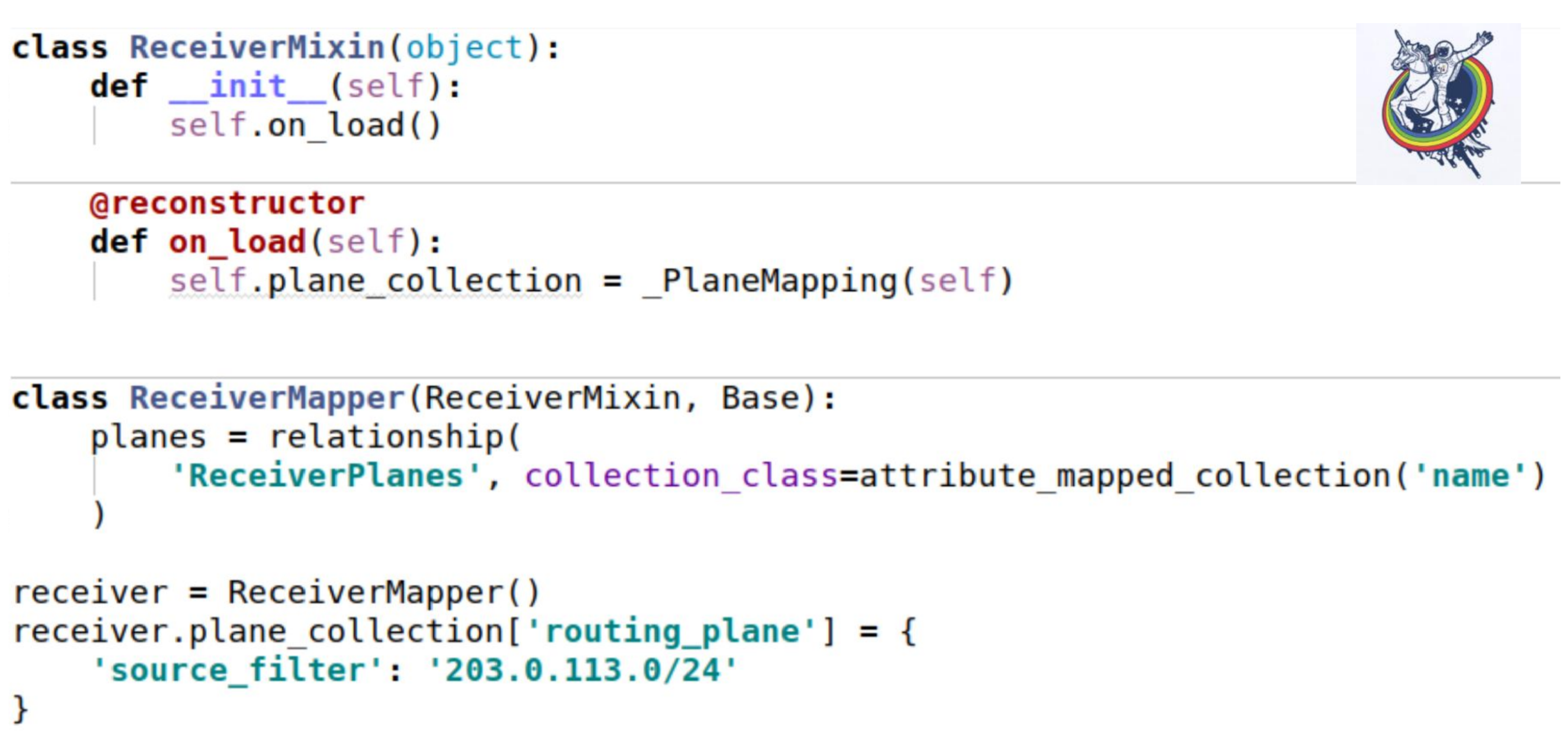
Bagaimana koleksi ini menampar mixin kami? Seperti biasa - mengatur atribut koleksi. Satu-satunya tempat yang menarik adalah ketika kita memuat instance dari database, metode __init__ tidak dipanggil. Semua atribut diganti ex post.
Alchemy memberikan dekorator pengarah standar, yang memungkinkan Anda menandai beberapa metode yang dipanggil setelah memuat objek dari basis data. Dan saat boot kita harus menginisialisasi koleksi kita. Diri hanyalah contoh itu. Penggunaannya persis sama seperti pada contoh sebelumnya.
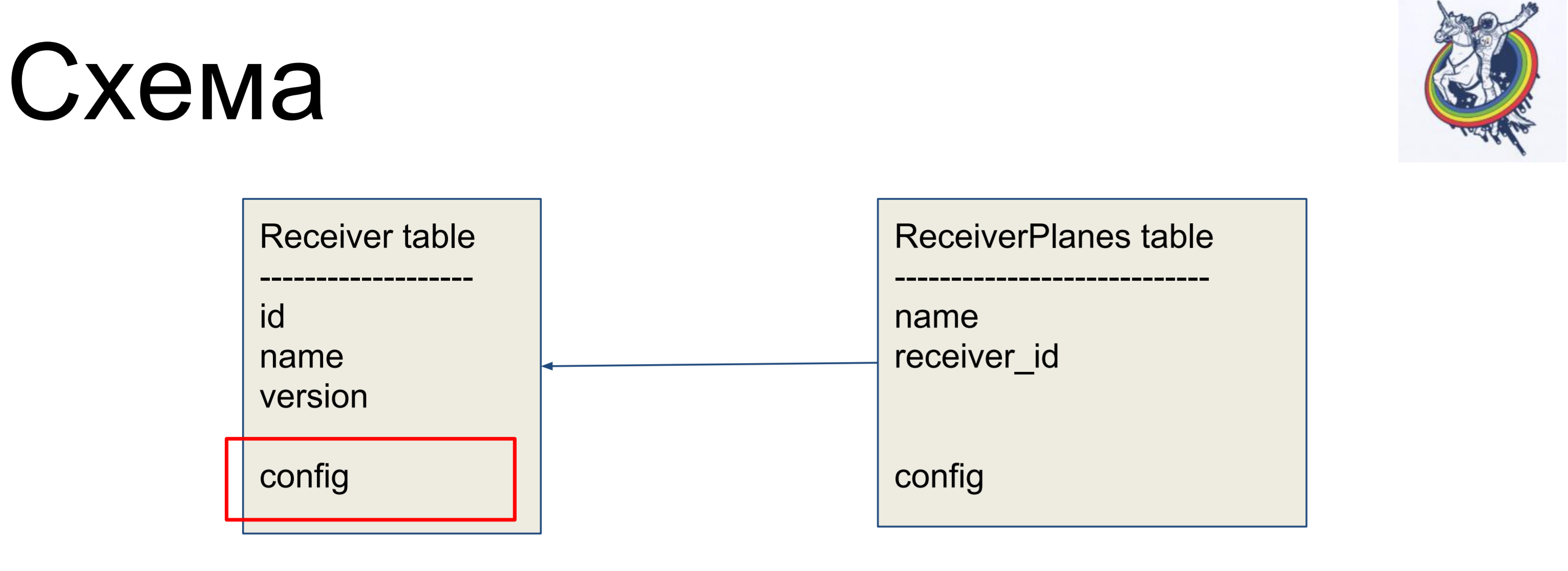
Namun dalam skema kami, telinga basis data masih terlihat - ini adalah konfigurasi. Jenis konfigurasi apa? Apakah itu varchar atau itu gumpalan? Faktanya, klien tidak tertarik.
Dia harus bekerja dengan entitas abstrak dari levelnya. Untuk ini, alkimia menyediakan jenis dekorasi. Contoh sederhana. Basis data kami menyimpan IPAddress sebagai varchar. Kami menggunakan kelas TypeDecorator, yang merupakan bagian dari alkimia, yang memungkinkan, pertama, untuk menunjukkan tipe database yang mendasari yang akan digunakan untuk tipe ini dan, kedua, untuk mendefinisikan dua parameter: process_bind_param mengonversi nilai ke tipe database dan process_result_value saat kami menilai dari jenis database, konversikan ke objek Python.Atribut dari alamat mengambil tipe python IPAddress. Dan kita bisa memanggil metode jenis ini, dan menetapkan objek jenis ini untuknya, dan semuanya bekerja untuk kita. Dan itu disimpan dalam database ... Saya tidak tahu apa yang disimpan, varchar (45), tetapi kita bisa mengganti garis itu dan gumpalan itu akan disimpan. Atau jika beberapa tipe asli mendukung alamat IP, maka Anda dapat menggunakannya.Kode klien tidak tergantung pada ini, tidak perlu ditulis ulang.
Contoh sederhana. Basis data kami menyimpan IPAddress sebagai varchar. Kami menggunakan kelas TypeDecorator, yang merupakan bagian dari alkimia, yang memungkinkan, pertama, untuk menunjukkan tipe database yang mendasari yang akan digunakan untuk tipe ini dan, kedua, untuk mendefinisikan dua parameter: process_bind_param mengonversi nilai ke tipe database dan process_result_value saat kami menilai dari jenis database, konversikan ke objek Python.Atribut dari alamat mengambil tipe python IPAddress. Dan kita bisa memanggil metode jenis ini, dan menetapkan objek jenis ini untuknya, dan semuanya bekerja untuk kita. Dan itu disimpan dalam database ... Saya tidak tahu apa yang disimpan, varchar (45), tetapi kita bisa mengganti garis itu dan gumpalan itu akan disimpan. Atau jika beberapa tipe asli mendukung alamat IP, maka Anda dapat menggunakannya.Kode klien tidak tergantung pada ini, tidak perlu ditulis ulang.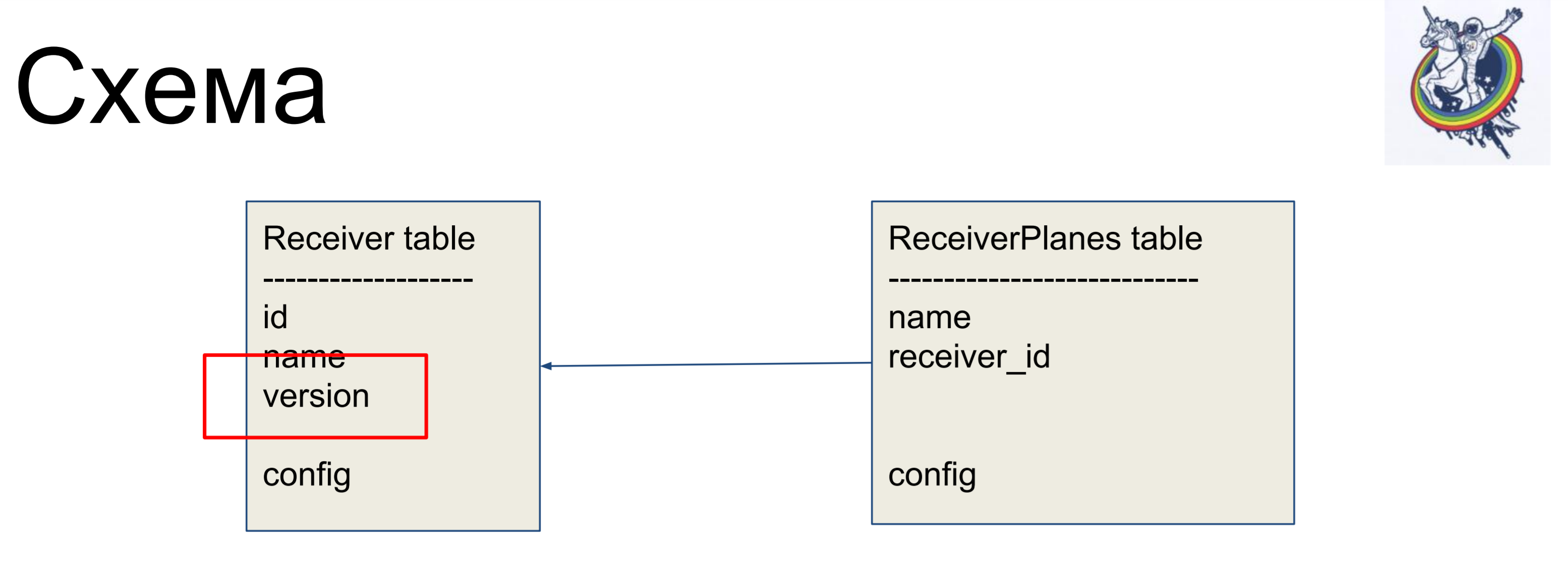 Hal lain yang menarik adalah kami memiliki versi. Kami ingin itu segera setelah kami mengubah objek kami, versi segera meningkat. Kami memiliki beberapa penghitung versi, kami mengubah objek - ia telah berubah, versinya telah meningkat. Kami melakukan ini secara otomatis agar tidak lupa.
Hal lain yang menarik adalah kami memiliki versi. Kami ingin itu segera setelah kami mengubah objek kami, versi segera meningkat. Kami memiliki beberapa penghitung versi, kami mengubah objek - ia telah berubah, versinya telah meningkat. Kami melakukan ini secara otomatis agar tidak lupa. Untuk ini, kami menggunakan acara. Peristiwa adalah peristiwa yang terjadi pada berbagai tahap kehidupan mapper dan mereka dapat dipicu ketika atribut berubah, ketika suatu entitas berubah dari satu negara ke yang lain, misalnya, "dibuat", "disimpan ke database", "dimuat dari database", "dihapus"; dan juga - pada acara tingkat sesi, sebelum kode sql dipancarkan ke database, sebelum komit, setelah komit, dan juga setelah rollback.Alkimia memungkinkan kita untuk menetapkan penangan untuk semua peristiwa ini, tetapi urutan penangan dieksekusi untuk acara yang sama tidak dijamin. Artinya, itu spesifik, tetapi tidak diketahui yang mana. Karena itu, jika perintah eksekusi penting bagi Anda, maka Anda perlu melakukan mekanisme pendaftaran.
Untuk ini, kami menggunakan acara. Peristiwa adalah peristiwa yang terjadi pada berbagai tahap kehidupan mapper dan mereka dapat dipicu ketika atribut berubah, ketika suatu entitas berubah dari satu negara ke yang lain, misalnya, "dibuat", "disimpan ke database", "dimuat dari database", "dihapus"; dan juga - pada acara tingkat sesi, sebelum kode sql dipancarkan ke database, sebelum komit, setelah komit, dan juga setelah rollback.Alkimia memungkinkan kita untuk menetapkan penangan untuk semua peristiwa ini, tetapi urutan penangan dieksekusi untuk acara yang sama tidak dijamin. Artinya, itu spesifik, tetapi tidak diketahui yang mana. Karena itu, jika perintah eksekusi penting bagi Anda, maka Anda perlu melakukan mekanisme pendaftaran.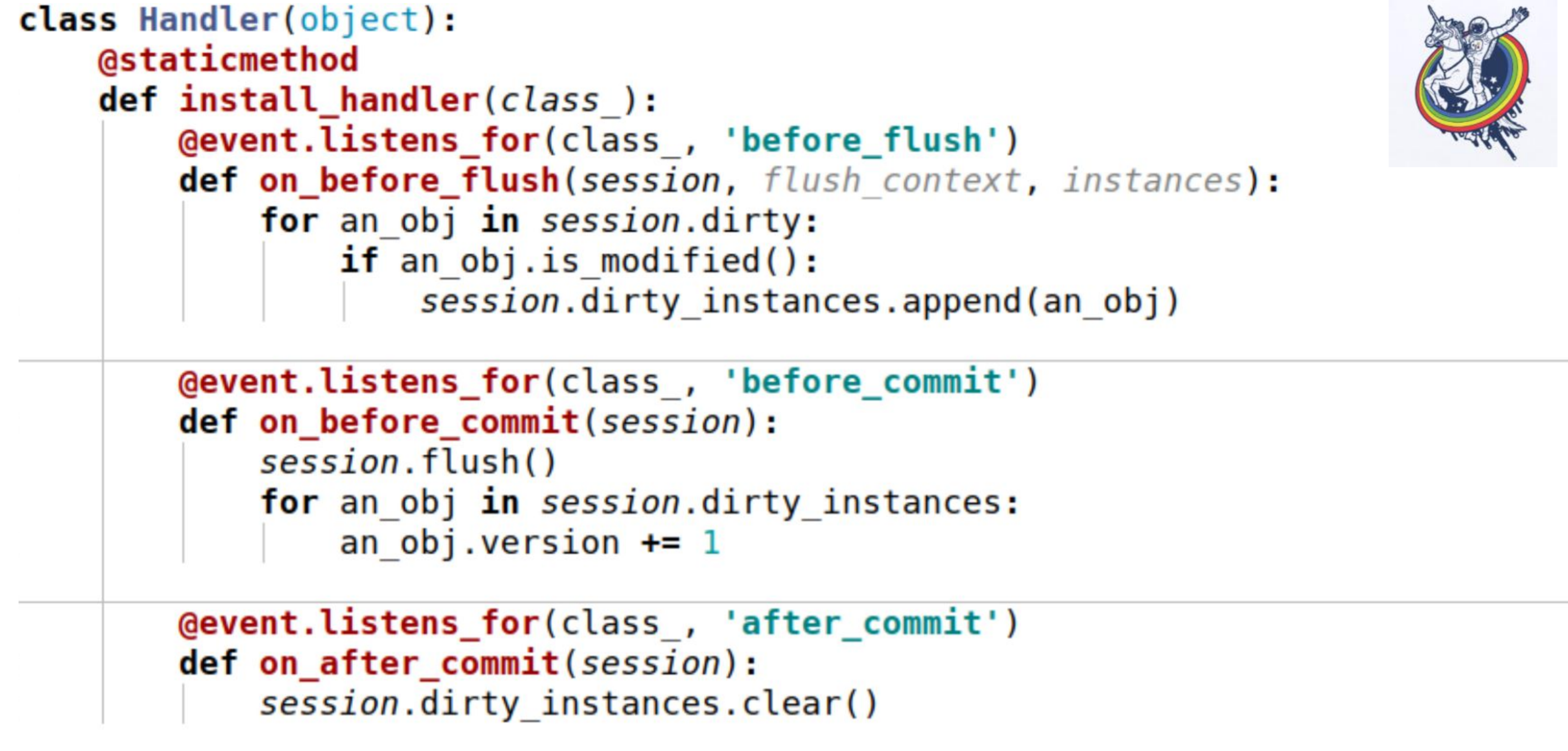 Berikut ini sebuah contoh. Tiga acara digunakan di sini:on_before_flush - sebelum kode sql dipancarkan ke database, kita melihat semua objek yang alkimia ditandai sebagai kotor dalam sesi ini dan memeriksa apakah objek ini dimodifikasi atau tidak. Mengapa ini perlu jika alkimia telah menandai segalanya? Alkimia menandai sebuah objek kotor segera setelah beberapa atribut berubah. Jika kami memberikan nilai yang sama untuk atribut ini, atribut itu akan ditandai sebagai kotor. Ada metode sesi is_modified untuk ini - ini digunakan secara internal, saya tidak menggambarnya. Lebih jauh, dari sudut pandang semantik kita, dari sudut pandang logika bisnis kita, bahkan jika atributnya telah berubah, objeknya masih dapat tetap tidak dimodifikasi. Misalnya, ada daftar tertentu di mana dua elemen dipertukarkan - dari sudut pandang alkimia, atribut telah berubah, tetapi itu tidak masalah untuk logika bisnis jika, katakanlah,semacam.Dan, pada akhirnya, kami memanggil metode lain khusus untuk setiap objek untuk memahami apakah objek tersebut dimodifikasi atau tidak. Dan kami menambahkannya ke variabel tertentu yang terkait dengan sesi yang kami ajukan sendiri - ini adalah variabel dirty_inances kami, di mana kami menambahkan objek ini.Acara berikut terjadi sebelum komit - before_commit. Ada juga jebakan kecil: jika kita tidak memiliki satu flush untuk seluruh transaksi, maka flush akan dipanggil sebelum komit - dalam kasus saya, pawang dipanggil sebelum komit sebelum flush.Seperti yang Anda lihat, apa yang kami lakukan pada paragraf sebelumnya mungkin tidak membantu kami dan session.dirty_inances akan kosong. Oleh karena itu, di dalam handler, kami kembali membuat flush sehingga semua penangan dipanggil sebelum flush dan hanya menambah versi satu per satu.after_commit, after_soft_rollback - setelah komit, kami hanya membersihkannya sehingga tidak ada kelebihan di waktu berikutnya.Jadi, Anda lihat - metode install_handler ini menginstal penangan untuk tiga acara sekaligus. Sebagai sebuah kelas, kami melewati sesi di sini, karena ini adalah acara levelnya.
Berikut ini sebuah contoh. Tiga acara digunakan di sini:on_before_flush - sebelum kode sql dipancarkan ke database, kita melihat semua objek yang alkimia ditandai sebagai kotor dalam sesi ini dan memeriksa apakah objek ini dimodifikasi atau tidak. Mengapa ini perlu jika alkimia telah menandai segalanya? Alkimia menandai sebuah objek kotor segera setelah beberapa atribut berubah. Jika kami memberikan nilai yang sama untuk atribut ini, atribut itu akan ditandai sebagai kotor. Ada metode sesi is_modified untuk ini - ini digunakan secara internal, saya tidak menggambarnya. Lebih jauh, dari sudut pandang semantik kita, dari sudut pandang logika bisnis kita, bahkan jika atributnya telah berubah, objeknya masih dapat tetap tidak dimodifikasi. Misalnya, ada daftar tertentu di mana dua elemen dipertukarkan - dari sudut pandang alkimia, atribut telah berubah, tetapi itu tidak masalah untuk logika bisnis jika, katakanlah,semacam.Dan, pada akhirnya, kami memanggil metode lain khusus untuk setiap objek untuk memahami apakah objek tersebut dimodifikasi atau tidak. Dan kami menambahkannya ke variabel tertentu yang terkait dengan sesi yang kami ajukan sendiri - ini adalah variabel dirty_inances kami, di mana kami menambahkan objek ini.Acara berikut terjadi sebelum komit - before_commit. Ada juga jebakan kecil: jika kita tidak memiliki satu flush untuk seluruh transaksi, maka flush akan dipanggil sebelum komit - dalam kasus saya, pawang dipanggil sebelum komit sebelum flush.Seperti yang Anda lihat, apa yang kami lakukan pada paragraf sebelumnya mungkin tidak membantu kami dan session.dirty_inances akan kosong. Oleh karena itu, di dalam handler, kami kembali membuat flush sehingga semua penangan dipanggil sebelum flush dan hanya menambah versi satu per satu.after_commit, after_soft_rollback - setelah komit, kami hanya membersihkannya sehingga tidak ada kelebihan di waktu berikutnya.Jadi, Anda lihat - metode install_handler ini menginstal penangan untuk tiga acara sekaligus. Sebagai sebuah kelas, kami melewati sesi di sini, karena ini adalah acara levelnya. Baik di sini. Saya akan mengingatkan Anda apa yang telah kami capai - kecepatan 30-40 detik untuk tim yang kompleks dan besar. Tidak sama sekali, beberapa diselesaikan dalam sedetik, yang lain dalam 200 milidetik, seperti yang Anda lihat di RPS. Permintaan basis data mulai dihitung dalam ratusan.
Baik di sini. Saya akan mengingatkan Anda apa yang telah kami capai - kecepatan 30-40 detik untuk tim yang kompleks dan besar. Tidak sama sekali, beberapa diselesaikan dalam sedetik, yang lain dalam 200 milidetik, seperti yang Anda lihat di RPS. Permintaan basis data mulai dihitung dalam ratusan. Hasilnya adalah sistem yang cukup seimbang. Namun, ada satu peringatan. Beberapa permintaan datang dari kami dalam batch, emisi. Yaitu, sekitar 30 permintaan tiba dan masing-masing seperti itu! (pembicara menunjukkan jempol)Jika kami memprosesnya satu detik setiap kali, maka permintaan terakhir dalam antrian akan berfungsi selama 30 detik. Yang pertama, yang kedua, dan seterusnya.
Hasilnya adalah sistem yang cukup seimbang. Namun, ada satu peringatan. Beberapa permintaan datang dari kami dalam batch, emisi. Yaitu, sekitar 30 permintaan tiba dan masing-masing seperti itu! (pembicara menunjukkan jempol)Jika kami memprosesnya satu detik setiap kali, maka permintaan terakhir dalam antrian akan berfungsi selama 30 detik. Yang pertama, yang kedua, dan seterusnya. Karena itu, kita masih perlu berakselerasi. Apa yang akan kita lakukanPadahal, alkimia memiliki dua bagian. Yang pertama adalah abstraksi atas database sql yang disebut SQLAlchemy Core. Yang kedua adalah ORM, pemetaan aktual antara database relasional dan representasi objek. Oleh karena itu, inti alkimia adalah sekitar 1-1 bertepatan dengan sql - jika Anda tahu yang terakhir, maka Anda tidak akan memiliki masalah dengan inti. Jika Anda tidak tahu sql - pelajari sql.Selain itu, inti merupakan overhead terkecil. Praktis tidak ada pemompaan - kueri dihasilkan menggunakan generator kueri, dan kemudian dieksekusi. Overhead over dbapi minimal.Kami dapat membangun permintaan dengan kompleksitas apa pun, apa pun jenisnya, kami dapat mengoptimalkannya untuk tugas tersebut. Yaitu, jika dalam kasus umum ORM tidak peduli bagaimana skema database dibangun - ada beberapa deskripsi tabel, itu menghasilkan beberapa pertanyaan, tidak mengetahui bahwa dalam kasus ini akan, misalnya, optimal untuk dipilih dari sini, di lain - dari sana, seperti terapkan filternya, dan di sana - lainnya, maka di sini kita bisa membuat permintaan untuk tugas tersebut.Kerugiannya adalah kita kembali ke sinkronisasi manual. Semua acara, relay - semua ini pada intinya tidak berfungsi. Kami membuat pilihan, objek datang kepada kami, kami melakukan sesuatu dengan mereka, kemudian memperbarui, masukkan ... Anda perlu meningkatkan versi dengan tangan Anda, periksa konstanta sendiri. Core tidak memungkinkan semua ini dilakukan dengan nyaman, pada level tinggi.Yah, kita tidak hidup di hari pertama.
Karena itu, kita masih perlu berakselerasi. Apa yang akan kita lakukanPadahal, alkimia memiliki dua bagian. Yang pertama adalah abstraksi atas database sql yang disebut SQLAlchemy Core. Yang kedua adalah ORM, pemetaan aktual antara database relasional dan representasi objek. Oleh karena itu, inti alkimia adalah sekitar 1-1 bertepatan dengan sql - jika Anda tahu yang terakhir, maka Anda tidak akan memiliki masalah dengan inti. Jika Anda tidak tahu sql - pelajari sql.Selain itu, inti merupakan overhead terkecil. Praktis tidak ada pemompaan - kueri dihasilkan menggunakan generator kueri, dan kemudian dieksekusi. Overhead over dbapi minimal.Kami dapat membangun permintaan dengan kompleksitas apa pun, apa pun jenisnya, kami dapat mengoptimalkannya untuk tugas tersebut. Yaitu, jika dalam kasus umum ORM tidak peduli bagaimana skema database dibangun - ada beberapa deskripsi tabel, itu menghasilkan beberapa pertanyaan, tidak mengetahui bahwa dalam kasus ini akan, misalnya, optimal untuk dipilih dari sini, di lain - dari sana, seperti terapkan filternya, dan di sana - lainnya, maka di sini kita bisa membuat permintaan untuk tugas tersebut.Kerugiannya adalah kita kembali ke sinkronisasi manual. Semua acara, relay - semua ini pada intinya tidak berfungsi. Kami membuat pilihan, objek datang kepada kami, kami melakukan sesuatu dengan mereka, kemudian memperbarui, masukkan ... Anda perlu meningkatkan versi dengan tangan Anda, periksa konstanta sendiri. Core tidak memungkinkan semua ini dilakukan dengan nyaman, pada level tinggi.Yah, kita tidak hidup di hari pertama. Kasing sederhana. Setiap mapper secara internal berisi objek __table__, yang digunakan dalam inti. Selanjutnya Anda melihat - kita pilih biasa, daftar kolom, bergabung dua piring, menunjukkan kiri dan kanan, ditunjukkan dengan kondisi apa kita bergabung, baik, untuk rasa kita tambahkan pesanan beli. Kemudian kami memasukkan permintaan yang dihasilkan ini ke dalam sesi dan mengembalikannya kepada kami, di mana objek seperti ketuk diindeks baik dengan nama kolom dan nomor. Nomornya sesuai dengan urutan daftar mereka pilih.
Kasing sederhana. Setiap mapper secara internal berisi objek __table__, yang digunakan dalam inti. Selanjutnya Anda melihat - kita pilih biasa, daftar kolom, bergabung dua piring, menunjukkan kiri dan kanan, ditunjukkan dengan kondisi apa kita bergabung, baik, untuk rasa kita tambahkan pesanan beli. Kemudian kami memasukkan permintaan yang dihasilkan ini ke dalam sesi dan mengembalikannya kepada kami, di mana objek seperti ketuk diindeks baik dengan nama kolom dan nomor. Nomornya sesuai dengan urutan daftar mereka pilih. Itu menjadi jauh lebih baik. Kinerja dalam kasus terburuk turun menjadi 2-4 detik, permintaan paling kompleks dan terpanjang berisi 14 perintah dan RPS 10-15. Itu solid.
Itu menjadi jauh lebih baik. Kinerja dalam kasus terburuk turun menjadi 2-4 detik, permintaan paling kompleks dan terpanjang berisi 14 perintah dan RPS 10-15. Itu solid. Apa yang ingin saya katakan sebagai kesimpulan.Jangan menghasilkan entitas di mana mereka tidak diperlukan - jangan sekrup Anda di mana ada yang siap.Gunakan SQLA ORM - ini adalah alat yang sangat nyaman yang memungkinkan Anda untuk melacak peristiwa di tingkat tinggi, merespons berbagai peristiwa yang terkait dengan database, menyembunyikan semua telinga alkimia.Jika semuanya gagal, kinerja tidak cukup - gunakan SQLA Core. Ini masih lebih baik daripada menggunakan SQL mentah murni karena menyediakan abstraksi relasional atas database. Secara otomatis lolos dari parameter, tidak mengikat dengan benar, tidak masalah apa pun basis data di bawahnya - itu dapat diubah dan Core mendukung dialek yang berbeda.
Apa yang ingin saya katakan sebagai kesimpulan.Jangan menghasilkan entitas di mana mereka tidak diperlukan - jangan sekrup Anda di mana ada yang siap.Gunakan SQLA ORM - ini adalah alat yang sangat nyaman yang memungkinkan Anda untuk melacak peristiwa di tingkat tinggi, merespons berbagai peristiwa yang terkait dengan database, menyembunyikan semua telinga alkimia.Jika semuanya gagal, kinerja tidak cukup - gunakan SQLA Core. Ini masih lebih baik daripada menggunakan SQL mentah murni karena menyediakan abstraksi relasional atas database. Secara otomatis lolos dari parameter, tidak mengikat dengan benar, tidak masalah apa pun basis data di bawahnya - itu dapat diubah dan Core mendukung dialek yang berbeda. Sangat nyaman.
Itu saja yang ingin saya sampaikan kepada Anda hari ini.