[bagian 2 dari 2]
[bagian 1 dari 2]

Bagaimana kami melakukannya?
Kami memutuskan untuk beralih ke GCP untuk meningkatkan kinerja aplikasi - sambil meningkatkan skala, tetapi tanpa biaya yang signifikan. Seluruh proses memakan waktu lebih dari 2 bulan. Untuk mengatasi masalah ini, kami telah membentuk kelompok insinyur khusus.
Dalam publikasi ini, kami akan berbicara tentang pendekatan yang dipilih dan implementasinya, serta bagaimana kami berhasil mencapai tujuan utama - untuk melaksanakan proses ini semulus mungkin dan mentransfer seluruh infrastruktur ke Google Cloud Platform, tanpa mengurangi kualitas layanan pengguna.
Perencanaan
- Daftar periksa terperinci telah disiapkan untuk mengidentifikasi setiap langkah yang mungkin. Diagram alir telah dibuat untuk menggambarkan urutan.
- Rencana reset telah dikembangkan yang kami, jika ada, dapat digunakan.
Beberapa sesi curah pendapat - dan kami telah mengidentifikasi pendekatan yang paling mudah dipahami dan paling sederhana untuk mengimplementasikan skema aktif-aktif. Terdiri dari fakta bahwa sekelompok kecil pengguna di-host di satu cloud, dan sisanya di host lain. Namun, pendekatan ini menyebabkan masalah, terutama di sisi klien (terkait dengan manajemen DNS), dan menyebabkan keterlambatan dalam replikasi database. Karena itu, hampir mustahil untuk mengimplementasikannya dengan aman. Metode yang jelas tidak memberikan solusi yang diperlukan, dan kami harus mengembangkan strategi khusus.
Berdasarkan diagram ketergantungan dan persyaratan keselamatan operasional, kami membagi layanan infrastruktur menjadi 9 modul.
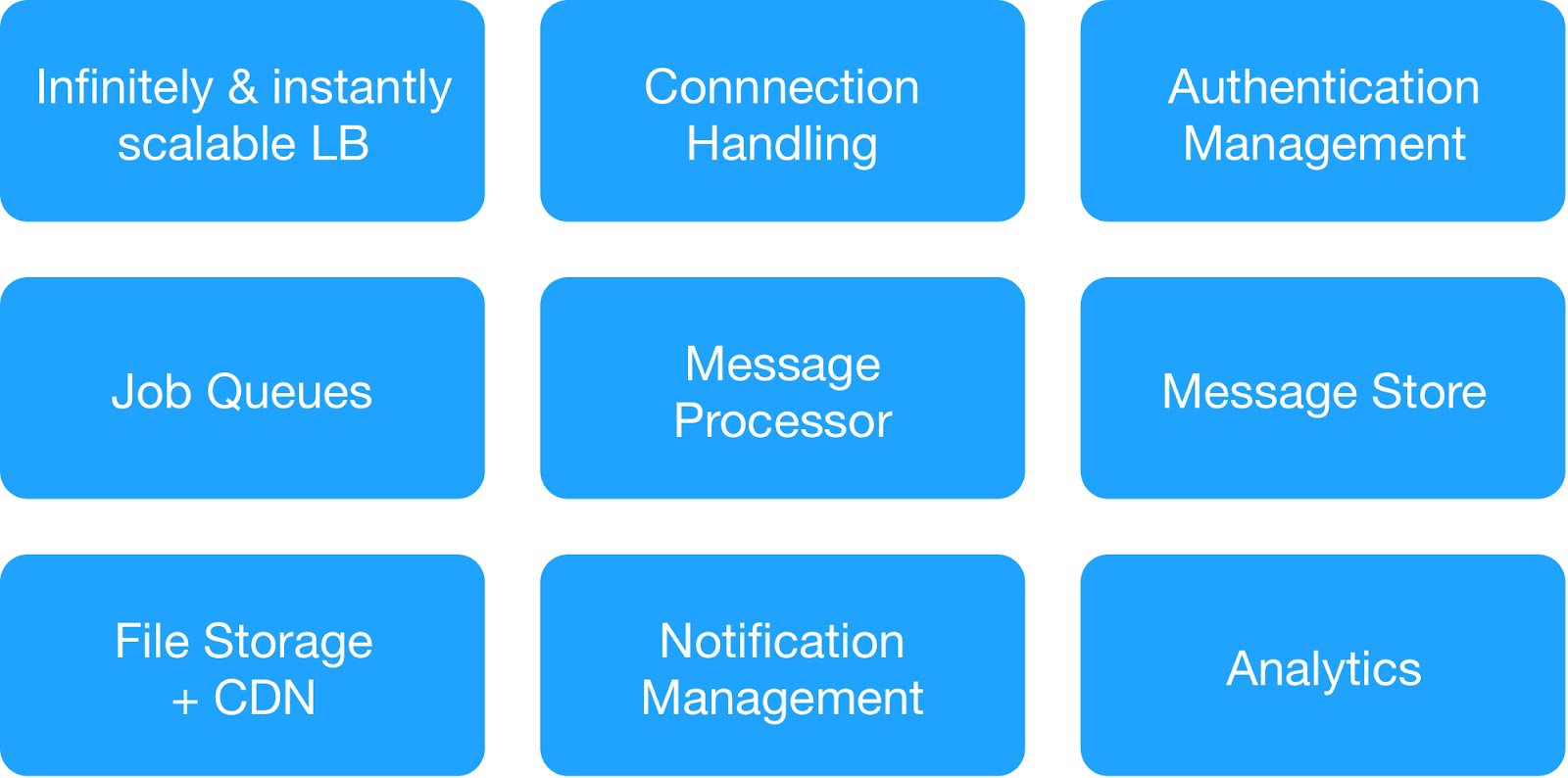
(Modul dasar untuk menggunakan infrastruktur hosting)
Setiap kelompok infrastruktur mengelola layanan internal dan eksternal umum.
⊹ Layanan pesan infrastruktur : MQTT, HTTPs, Hemat, server Gunicorn, modul antrian, klien Async, server Jetty, cluster Kafka.
⊹ Layanan Gudang Data : Cluster Terdistribusi MongoDB, Redis, Cassandra, Hbase, MySQL, dan MongoDB.
⊹ Layanan analisis infrastruktur : Kafka cluster, cluster data warehouse (HDFS, HIVE).
Mempersiapkan hari yang penting:
✓ Rencana terperinci untuk beralih ke GCP untuk setiap layanan: urutan, gudang data, rencana pengaturan ulang.
✓ Jejaring lintas proyek (shared cloud private virtual VPC [XPN]) di GCP untuk mengisolasi berbagai bagian infrastruktur, mengoptimalkan manajemen, meningkatkan keamanan dan konektivitas.
✓ Beberapa terowongan VPN antara GCP dan virtual private cloud (VPC) yang sedang berjalan untuk menyederhanakan transfer sejumlah besar data melalui jaringan selama replikasi, serta untuk kemungkinan penyebaran selanjutnya dari sistem paralel.
✓ Mengotomatiskan pemasangan dan konfigurasi seluruh tumpukan menggunakan sistem Chef.
✓ Skrip dan alat otomatisasi untuk penyebaran, pemantauan, pencatatan, dll.
✓ Konfigurasikan semua subnet yang diperlukan dan aturan firewall yang dikelola untuk aliran sistem.
✓ Replikasi di beberapa pusat data (Multi-DC) untuk semua sistem penyimpanan.
✓ Konfigurasikan penyeimbang beban (GLB / ILB) dan grup instance terkelola (MIG).
✓ Skrip dan kode untuk mentransfer wadah penyimpanan objek ke Penyimpanan Cloud GCP dengan pos-pos pemeriksaan.
Segera, kami memenuhi semua prasyarat yang diperlukan dan menyiapkan daftar elemen untuk memindahkan infrastruktur ke platform GCP. Setelah berbagai diskusi, serta mempertimbangkan jumlah layanan dan diagram ketergantungan mereka, kami memutuskan untuk mentransfer infrastruktur cloud ke GCP dalam tiga malam untuk mencakup semua layanan sisi server dan penyimpanan data.
Transisi
Strategi Transfer Load Balancer:
Kami mengganti cluster yang dikelola HAProxy yang sebelumnya digunakan dengan penyeimbang beban global untuk memproses puluhan juta koneksi pengguna aktif setiap hari.
⊹ Tahap 1:
- MIG dibuat dengan aturan penerusan paket untuk meneruskan semua lalu lintas ke alamat IP MQTT di cloud yang ada.
- Penyeimbang SSL dan TCP Proxy telah dibuat dengan MIG sebagai bagian server.
- Untuk MIG, HAProxy diluncurkan dengan server MQTT sebagai bagian server.
- Dalam DNS, kebijakan perutean berbasis berat telah menambahkan alamat IP GLB eksternal.
Koneksi pengguna secara bertahap digunakan saat melacak kinerjanya.
⊹ Langkah 2: Transisi tonggak sejarah, mulailah mengerahkan layanan di GCP.
⊹ Tahap 3: Tahap akhir transisi, semua layanan ditransfer ke GCP.
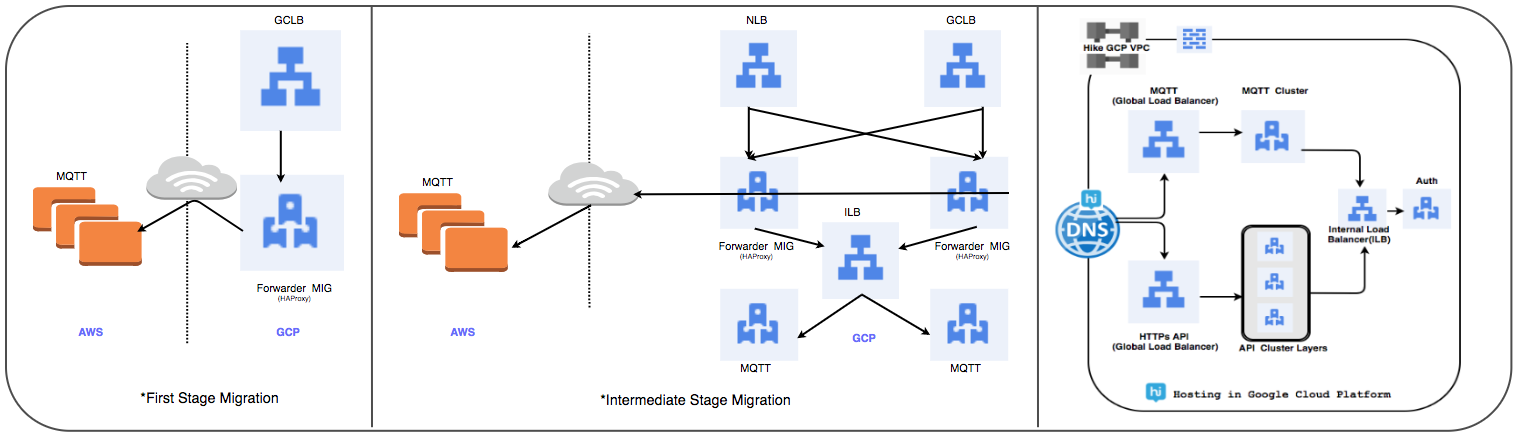
(Tahapan transfer penyeimbang beban)
Pada tahap ini, semuanya berjalan seperti yang diharapkan. Segera, tiba saatnya untuk menyebarkan beberapa layanan HTTP internal dalam GCP dengan routing - mengingat bobot dari koefisien. Kami memantau dengan cermat semua indikator. Ketika kami mulai meningkatkan lalu lintas secara bertahap, sehari sebelum transisi yang direncanakan, penundaan interaksi VPC melalui VPN (penundaan 40 ms - 100 ms dicatat, meskipun sebelumnya mereka kurang dari 10 ms) meningkat.
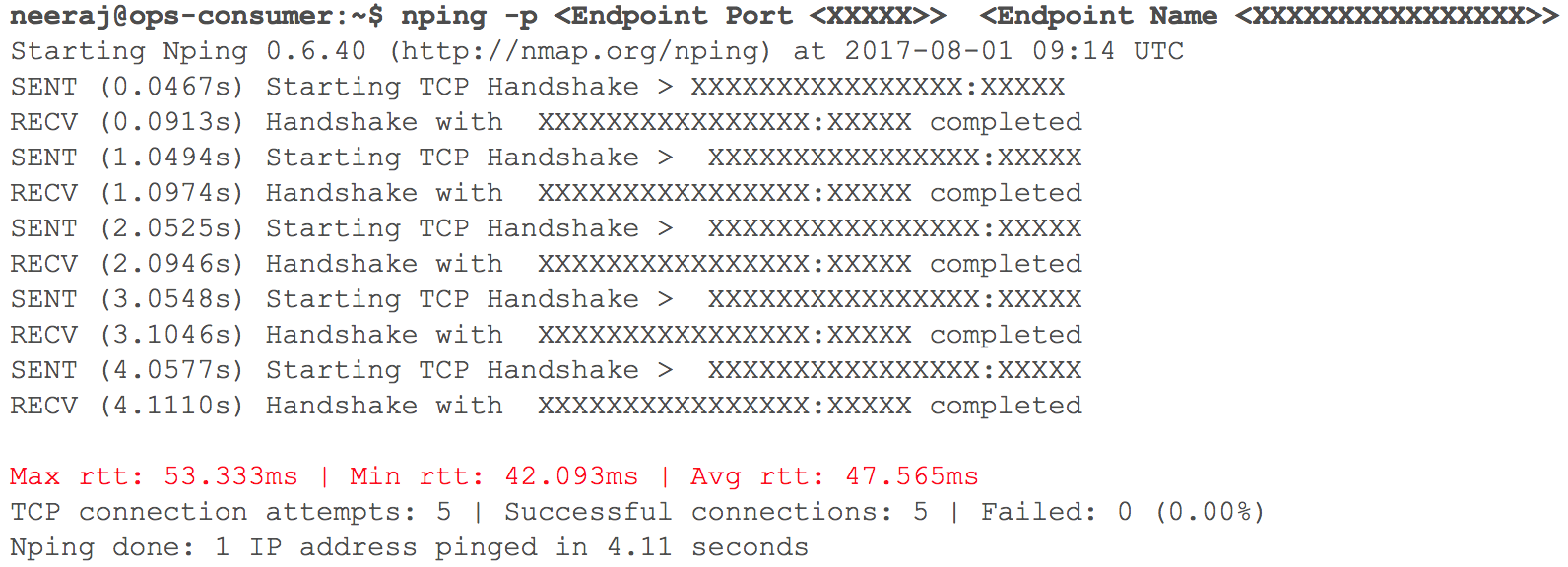
(Jepretan memeriksa keterlambatan jaringan saat dua VPC berinteraksi)
Pemantauan jelas menunjukkan: ada sesuatu yang salah dengan kedua saluran jaringan cloud menggunakan terowongan VPN. Bahkan throughput terowongan VPN tidak mencapai tanda optimal. Situasi ini mulai berdampak negatif pada beberapa layanan pengguna kami. Kami segera mengembalikan semua layanan HTTP yang sebelumnya dimigrasikan ke keadaan semula. Kami menghubungi tim pendukung TAM dan layanan cloud, memberikan data awal yang diperlukan dan mulai memahami mengapa penundaan bertambah. Spesialis dukungan sampai pada kesimpulan bahwa bandwidth jaringan maksimum di saluran cloud antara dua penyedia layanan cloud telah tercapai. Karenanya pertumbuhan keterlambatan jaringan selama transfer sistem internal.
Peristiwa ini memaksa untuk menunda transisi ke cloud. Penyedia layanan cloud tidak dapat menggandakan bandwidth dengan cukup cepat. Karena itu, kami kembali ke tahap perencanaan dan merevisi strategi. Kami memutuskan untuk mentransfer infrastruktur cloud ke GCP dalam satu malam, bukan tiga dan termasuk dalam rencana semua layanan dari bagian server dan penyimpanan data. Ketika jam "X" tiba, semuanya berjalan lancar: beban kerja berhasil ditransfer ke Google Cloud tanpa disadari oleh pengguna kami!
Strategi Migrasi Basis Data:
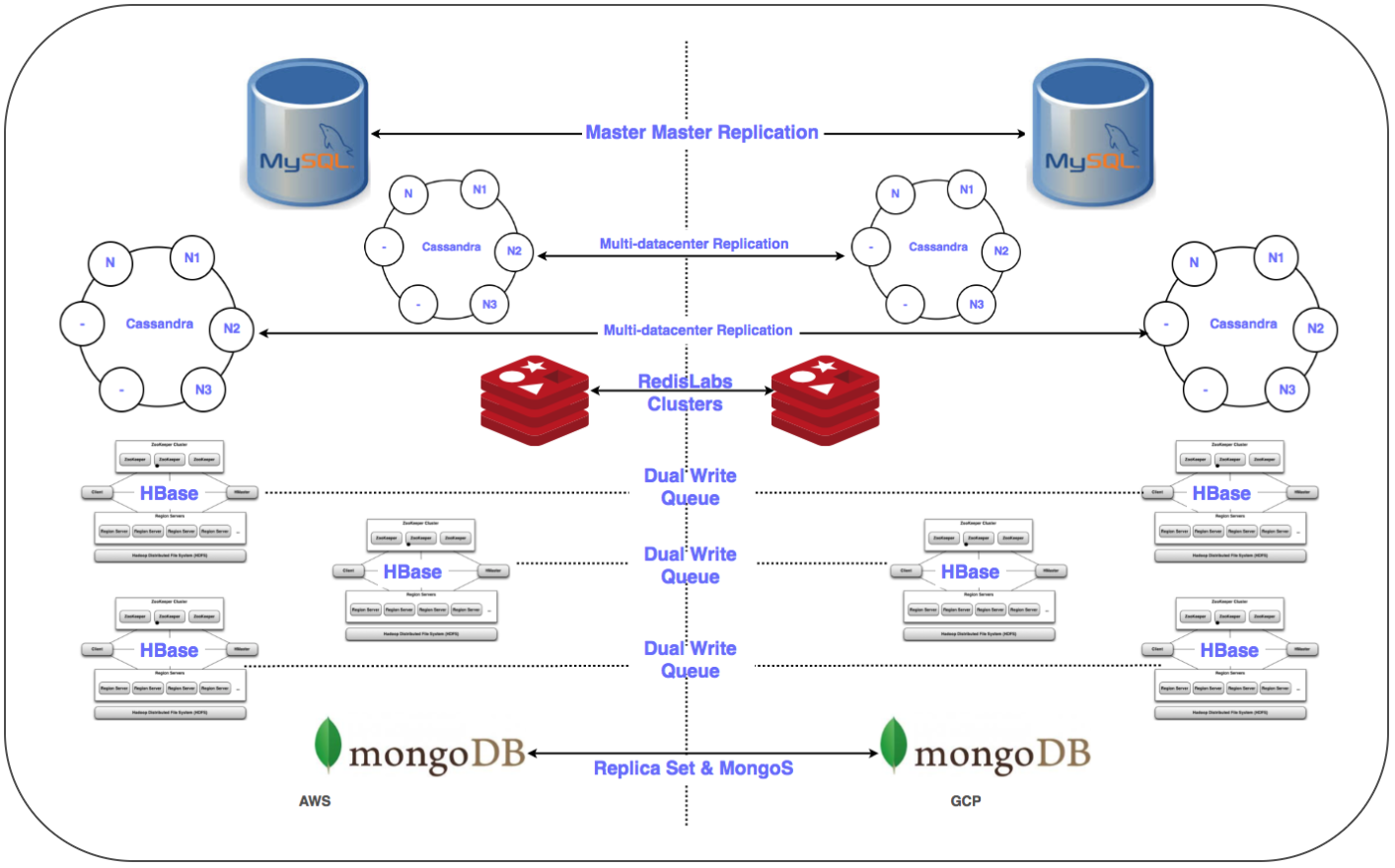
Itu diperlukan untuk mentransfer lebih dari 50 titik akhir basis data untuk DBMS relasional, penyimpanan dalam-memori, serta NoSQL dan cluster yang terdistribusi dan terukur dengan latensi rendah. Kami telah menempatkan replika semua database di GCP. Ini dilakukan untuk semua penyebaran kecuali HBase.
⊹ Replikasi Master-slave: diimplementasikan untuk cluster MySQL, Redis, MongoDB, dan MongoS.
Replikasi Multi Multi-DC: diterapkan untuk cluster Cassandra.
⊹ Cluster Ganda: Cluster paralel telah dikonfigurasi untuk Gbase di GCP. Data yang ada dimigrasikan, entri ganda dikonfigurasi sesuai dengan strategi menjaga konsistensi data di kedua cluster.
Dalam kasus HBase, masalahnya ada pada Ambari. Kami mengalami beberapa kesulitan ketika menempatkan cluster di beberapa pusat data, misalnya, ada masalah dengan DNS, skrip pengenalan rak, dll.
Langkah terakhir (setelah memindahkan server) termasuk memindahkan replika ke server utama dan mematikan basis data lama. Sesuai rencana, menentukan prioritas transfer database, kami menggunakan Zookeeper untuk konfigurasi yang diperlukan dari cluster aplikasi.
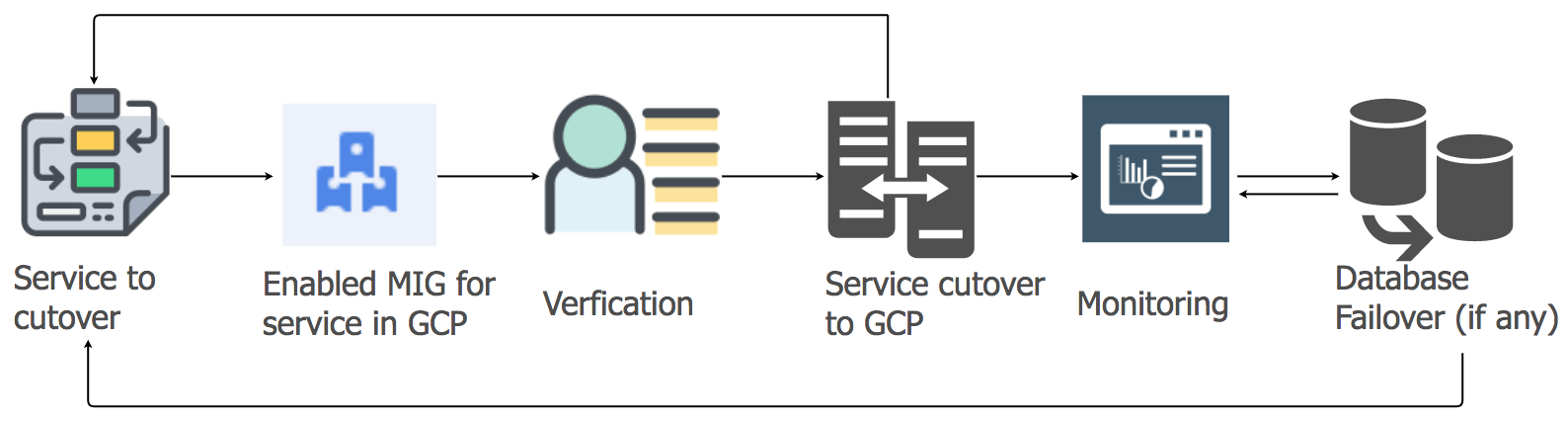
Strategi Migrasi Layanan Aplikasi
Untuk mentransfer beban kerja layanan aplikasi dari hosting saat ini ke cloud GCP, kami menggunakan pendekatan lift-and-shift. Untuk setiap layanan aplikasi, kami membuat grup instance yang dikelola (MIG) dengan penskalaan otomatis.
Sesuai dengan rencana terperinci, kami mulai memigrasi layanan ke GCP, dengan mempertimbangkan urutan dan dependensi gudang data. Semua layanan tumpukan perpesanan dimigrasikan ke GCP tanpa downtime. Ya, ada beberapa gangguan kecil, tetapi kami segera menanganinya.
Di pagi hari, saat aktivitas pengguna meningkat, kami dengan cermat mengikuti semua dasbor dan indikator untuk mengidentifikasi masalah dengan cepat. Beberapa kesulitan benar-benar muncul, tetapi kami dapat dengan cepat menghilangkannya. Salah satu masalah adalah karena keterbatasan penyeimbang beban internal (ILB), yang dapat menangani tidak lebih dari 20.000 koneksi bersamaan. Dan kami membutuhkan 8 kali lebih banyak! Oleh karena itu, kami menambahkan ILB tambahan ke lapisan manajemen koneksi kami.
Pada jam-jam pertama beban puncak setelah transisi, kami mengontrol semua parameter terutama dengan hati-hati, karena seluruh beban tumpukan pesan ditransfer ke GCP. Ada beberapa gangguan kecil yang kami tangani dengan sangat cepat. Saat memigrasi layanan lain, kami mengambil pendekatan yang sama.
Migrasi penyimpanan objek:
Kami menggunakan layanan penyimpanan objek terutama dalam tiga cara.
⊹ Penyimpanan file media yang dikirim ke obrolan pribadi atau grup. Periode penyimpanan ditentukan oleh kebijakan manajemen siklus hidup.
⊹ Penyimpanan gambar dan thumbnail profil pengguna.
⊹ Penyimpanan file media dari bagian "History" dan "Timeline" dan gambar mini yang sesuai.
Kami menggunakan alat transfer penyimpanan Google untuk menyalin objek lama dari S3 ke GCS. Kami juga menggunakan MIG berbasis Kafka khusus untuk mentransfer objek dari S3 ke GCS ketika logika khusus diperlukan.
Transisi dari S3 ke GCS mencakup langkah-langkah berikut:
● Untuk case use pertama dari object store, kami mulai menulis data baru untuk S3 dan GCS, dan setelah berakhirnya kami mulai membaca data dari GCS menggunakan logika di sisi aplikasi. Mentransfer data lama tidak masuk akal, dan pendekatan ini hemat biaya.
● Untuk kasus penggunaan kedua dan ketiga, kami mulai menulis objek baru ke GCS dan mengubah jalur untuk membaca data sehingga pencarian pertama kali dilakukan dalam GCS dan hanya kemudian, jika objek tidak ditemukan, dalam S3.
Butuh berbulan - bulan untuk merencanakan, memverifikasi kebenaran konsep, menyiapkan dan membuat prototipe, tetapi kemudian kami memutuskan transisi dan mengimplementasikannya dengan sangat cepat. Kami menilai risiko dan menyadari bahwa migrasi cepat lebih disukai dan hampir tidak terlihat.
Proyek berskala besar ini telah membantu kami mendapatkan posisi yang kuat dan meningkatkan produktivitas tim di banyak bidang, karena sebagian besar operasi manual tentang pengelolaan infrastruktur cloud sekarang ada di masa lalu.
● Mengenai pengguna, sekarang kami telah menerima semua yang diperlukan untuk memastikan kualitas tertinggi dari layanan mereka. Downtime hampir menghilang, dan fitur-fitur baru sedang diterapkan lebih cepat.
● Tim kami menghabiskan lebih sedikit waktu untuk tugas pemeliharaan dan dapat fokus pada proyek otomatisasi dan membuat alat baru.
● Kami mendapat akses ke seperangkat alat yang belum pernah ada sebelumnya untuk bekerja dengan data besar, serta fungsionalitas siap pakai untuk pembelajaran dan analisis mesin. Lihat detailnya di sini.
● Komitmen Google Cloud untuk bekerja dengan proyek sumber terbuka Kubernetes juga sejalan dengan rencana pengembangan kami untuk tahun ini.