Dalam artikel ini saya ingin berbicara tentang hasrat lama saya - belajar dan bekerja dengan mic bidang jauh (array mikro) - array mikrofon.
Artikel ini akan menarik bagi mereka yang gemar membangun asisten suara mereka, itu akan menjawab beberapa pertanyaan kepada orang-orang yang menganggap teknik sebagai seni, dan juga yang ingin mencoba sendiri dalam peran Q ( Ini dari Bond ). Cerita saya yang sederhana, saya harap ini dapat membantu Anda memahami mengapa kolom asisten cerdas yang dibuat sesuai dengan tutorial hanya berfungsi dengan baik jika tidak ada suara sama sekali. Dan sangat buruk di mana mereka berada, misalnya di dapur.
Bertahun-tahun yang lalu, saya menjadi tertarik pada pemrograman, saya mulai menulis kode hanya karena guru yang bijak mengizinkan saya untuk bermain hanya permainan yang ditulis sendiri. Itu tahun jadi 87 dan itu adalah Yamaha MSX. Mengenai hal ini, ada juga startup pertama. Semuanya secara ketat sesuai dengan kebijaksanaan: "Pilih pekerjaan yang sesuai dengan Anda, dan Anda tidak perlu bekerja sehari pun dalam hidup Anda" (Konfusius).
Dan bertahun-tahun telah berlalu, dan saya masih menulis kode. Bahkan hobi dengan kode - yah, kecuali roller-skating, untuk menghangatkan otak dan "Aku tidak akan melupakan matan" ini bekerja dengan mic Far Fields (Mic array). Sia-sia para guru menghabiskan waktu bersama saya.
Apa itu dan di mana itu diterapkan?
Asisten suara yang mendengarkan Anda biasanya memiliki berbagai mikrofon. Kami menemukannya di sistem konferensi video. Dalam komunikasi kolektif, bagian terbesar perhatian diberikan pada pidato, tentu saja, kita tidak terus-menerus melihat pembicara ketika berkomunikasi, tetapi untuk berbicara dengan tepat dengan mikrofon atau headset adalah kendala dan tidak nyaman.
Hampir setiap orang, pelanggan yang dihormati, produsen ponsel menggunakan dari 2 atau lebih mikrofon dalam kreasi mereka (ya, ya, di belakang lubang ini ada mikrofon di belakang, atas, bawah, di belakang). Sebagai contoh, di iPhone 3G / 3GS ia adalah satu-satunya, di iPhone generasi keempat ada dua, dan di generasi kelima sudah ada tiga mikrofon. Secara umum, ini juga merupakan susunan mikrofon. Dan semua ini untuk kemampuan mendengar suara yang lebih baik.
Tetapi kembali ke asisten suara kami
Bagaimana cara meningkatkan rentang pendengaran?
"butuh telinga besar"
Sebuah ide sederhana: jika untuk mendengar yang terdekat, hanya satu mikrofon yang cukup, maka untuk mendengar dari jauh, Anda perlu menggunakan mikrofon yang lebih mahal dengan reflektor, mirip dengan telinga rubah fenech:

(Wikipedia)


 Sebenarnya, ini bukan bagian dari paket berbulu, tetapi perangkat serius untuk pemburu dan pengintai.
Sebenarnya, ini bukan bagian dari paket berbulu, tetapi perangkat serius untuk pemburu dan pengintai.

Hal yang sama, hanya pada tabung resonator

Di habitatnya.
(Diambil dari https://forum.guns.ru )
Diameter cermin dari 200mm hingga 1,5m
(selengkapnya lihat http://elektronicspy.narod.ru/next.html )
“Perlu lebih banyak mikrofon”
Atau mungkin jika Anda meletakkan banyak mikrofon murah, maka jumlahnya akan menjadi kualitas dan semuanya akan berhasil? Zerghrash hanya dengan mikrofon.
Aneh, tetapi bekerja dalam kehidupan nyata. Benar dengan banyak matan, tetapi berhasil. Dan kita akan membicarakan ini di bagian selanjutnya.
Dan bagaimana belajar mendengar lebih jauh tanpa tanduk yang indah?

Salah satu masalah dengan sistem klakson adalah Anda dapat dengan jelas mendengar apa yang ada dalam fokus. Tetapi jika Anda perlu mendengar sesuatu dari arah yang berbeda, maka Anda perlu melakukan "tipuan dengan telinga Anda" dan secara fisik mengarahkan sistem ke arah lain.
Dan tentang rasio signal-to-noise dalam sistem dengan matriks mikrofon, entah bagaimana itu lebih baik dibandingkan dengan mikrofon konvensional.
Dalam susunan mikrofon, dan juga kerabat terdekat mereka - PAR (antena array bertahap), Anda tidak perlu mengubah apa pun. Baca lebih lanjut di bagian Beamforming. Mudah dilihat:

Mikrofon yang tidak fokus (gambar kiri) merekam semua suara dari semua arah, bukan hanya yang Anda butuhkan.
Dari mana datangnya rentang yang bagus? Pada gambar kanan, mikrofon mendengarkan dengan penuh perhatian hanya ke satu sumber. Seolah fokus, ia menerima sinyal hanya dari sumber yang dipilih, dan bukan kekacauan dari sumber kebisingan yang mungkin, dan sinyal murni hanya diperkuat (dibuat lebih keras) tanpa menggunakan teknik pengurangan kebisingan canggih. Agak seperti corong, tetapi pada traksi matte.
Apa yang salah dengan pengurangan noise?
Ketika menerapkan pengurangan kebisingan yang kompleks, banyak kelemahan berarti bahwa bagian dari sinyal akan hilang, bersama dengan bagian dari sinyal, suara akan berubah, dan di telinga itu terlihat seperti pewarnaan karakteristik suara dengan pengurangan kebisingan dan sebagai akibat dari keterbacaan yang tidak terbaca. Ketidak terbaca ini terlihat oleh penutur bahasa Rusia yang ingin mendengar desis ini dari lawan bicara. Yah, dan sebagai tambahan - sebagai akibat dari pengurangan kebisingan, pendengar tidak mendengar sinyal identifikasi yang menghubungkannya dengan lawan bicara (bernapas, mengendus dan suara-suara lain yang menyertai pidato langsung). Ini menciptakan beberapa masalah, karena dalam percakapan sehari-hari semua ini terdengar, dan itu hanya membantu untuk menilai keadaan dan sikap lawan bicara terhadap Anda. Tidak adanya mereka (noise) saat kita mendengar suara menyebabkan sensasi yang tidak menyenangkan dan mengurangi tingkat persepsi, pemahaman dan identifikasi. Nah, jika asisten suara mendengarkan Anda, pengurangan noise membuatnya sulit untuk mengenali frasa kunci dan ucapan setelahnya. Benar, ada hack seumur hidup - Anda perlu melatih pengenal pada sampel yang direkam dengan mempertimbangkan distorsi dari pengurangan kebisingan yang digunakan.
Mereka yang terbiasa dengan kata-kata masalah pesta koktail masih bisa pergi untuk minum kopi atau koktail, dan melakukan percobaan lapangan, mereka yang berminat membaca, melanjutkan.

Secara singkat tentang matan di mana ia bekerja:
DOA (penentuan arah, dan, jika mungkin, pelokalan ke sumber):
Saya akan singkat, karena topiknya sangat luas, ini dilakukan dengan bantuan sihir putih, abu-abu atau gelap (tergantung pada topik yang disukai dalam IDE) dan matan. yang utama Cara yang sering dilakukan untuk bermain DOA adalah dengan menganalisis korelasi dan hal-hal lain di antara pasangan mikrofon (biasanya berdiameter berlawanan).
Life hack: untuk penelitian lebih baik memilih array dengan susunan mikrofon melingkar. Keuntungannya adalah mudah untuk mengumpulkan statistik dari pasangan dengan jarak yang berbeda antara mikrofon - berdiameter maksimum, dan minimum di antara mikrofon - jika Anda mengambil pasangan dalam akor, dan dengan azimuth (arah) yang berbeda ke sumber.
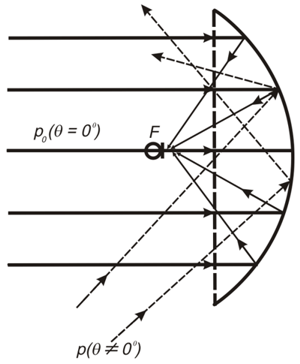
Formasi balok - Cara termudah dan termudah untuk dipahami adalah -delay & jumlah (DAS dan FDAS) - pembentukan balok berdasarkan penundaan dan jumlah.
Untuk visual:
(Diambil dari http://www.labbookpages.co.uk/audio/beamforming/delaySum.html )
Peretasan kehidupan: Jangan lupa tentang panjang gelombang yang berbeda dan untuk setiap frekuensi kami menghitung perbedaan fase kami tn
Pola radiasi perkiraan akan terlihat seperti ini
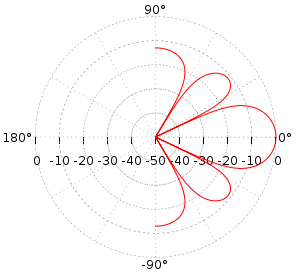
Detail dan dengan rumus
Mereka yang tidak lupa bagaimana cara mengisap matan dapat mengambil bagian dalam JIO-RLS (Joint Iterative Subspace Adaptive mengurangi kuadrat kuadrat terkecil). Sangat mirip dengan rasa gradient descent, lho.

Jadi kami meringkas: menggunakan metode konvensional, mencapai kualitas yang sebanding dengan mikrofon matriks sulit. Setelah menerapkan definisi arah ke sumber, dan sebagai akibatnya, kami hanya mendengar sumber yang diperlukan, kami menghilangkan kebisingan dan gema media, bahkan yang kurang terdengar (efek Haas).
Asisten Suara - Bagaimana Kelihatannya Di Dalam
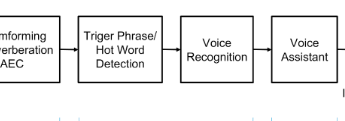
Jadi, seperti apa skema pemrosesan suara asisten suara berpengalaman:

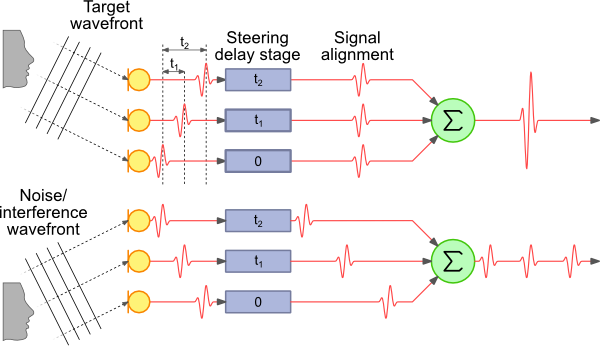
Sinyal dari array mikrofon diumpankan ke perangkat di mana kami membentuk balok ke sumber suara (beamforming), sehingga menghilangkan gangguan. Kemudian kita mulai mengenali suara balok ini, biasanya itu tidak cukup untuk pengenalan sumber daya perangkat yang berkualitas tinggi, dan paling sering sinyal masuk ke cloud untuk pengakuan (Microsoft, Google, Amazon pilih).
Pembaca yang penuh perhatian akan memperhatikan: Dan dalam gambar dengan deskripsi ada semacam persegi kata Tidak, dan mengapa tidak segera dikenali, seperti yang dijanjikan?
Mengapa ini mungkin persegi ekstra yang digambar pada diagram?
Dan karena Anda terus-menerus menyiarkan sinyal dari semua sumber derau ke Internet mendengarkan pengakuan sumber daya apa pun tidak cukup. Oleh karena itu, kami mulai mengenali hanya ketika mereka menyadari bahwa mereka pasti menginginkannya dari kami - dan untuk ini mereka mengucapkan mantra khusus - ok Google, Siri atau Alex, atau mereka menyebut saya cortan. Dan classifier kata Notifier paling sering adalah neuron dan bekerja langsung pada perangkat. Dalam konstruksi classifier ada juga banyak hal menarik, tetapi hari ini bukan tentang itu.
Dan faktanya, diagramnya terlihat seperti ini:
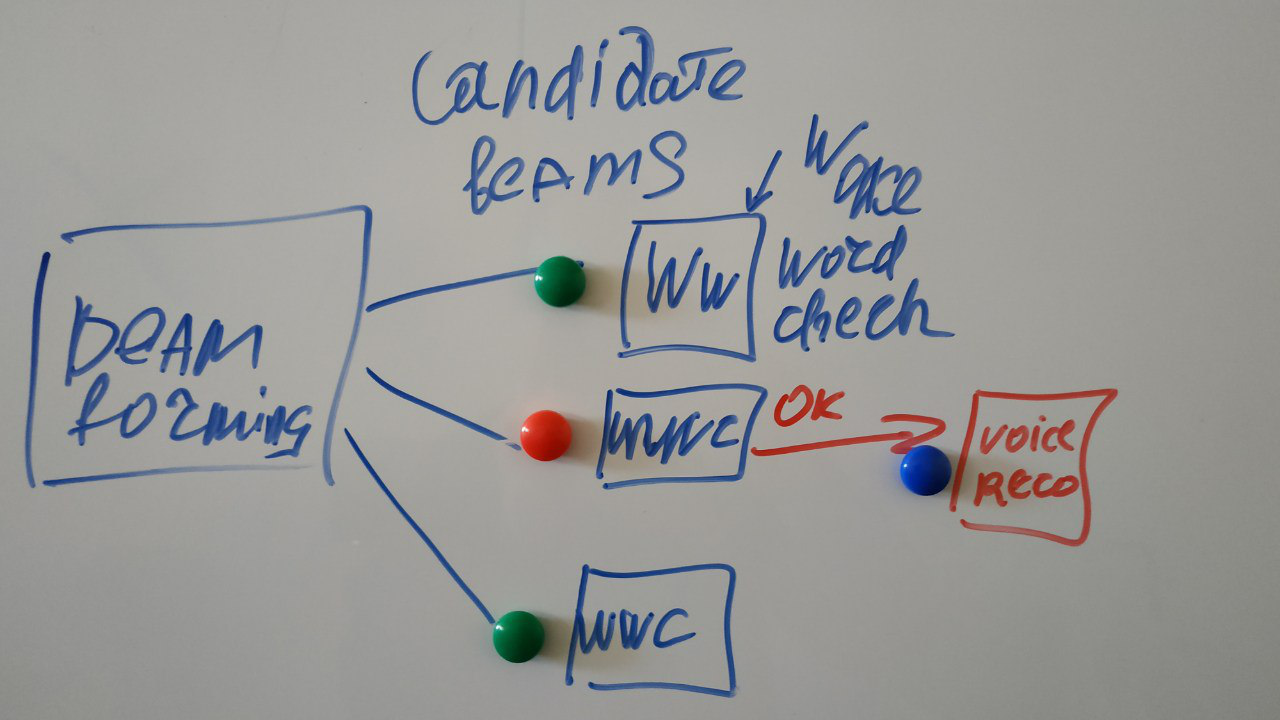
(coretan saya)
Beberapa sinar dapat dibentuk pada sumber sinyal yang berbeda, dan kami sedang mencari kata khusus di masing-masingnya. Tetapi selanjutnya kita akan memproses orang yang mengatakan kata yang benar.
Langkah selanjutnya adalah pengenalan di cloud, berulang kali dibahas di Internet, ada banyak tutorial di atasnya.
Bagaimana Anda bisa bergabung dengan matana liburan ini
Cara termudah untuk membeli papan dev. Gambaran umum dari devboards yang ada: salah satu yang paling lengkap - dengan referensi .
Yang paling ramah untuk pemula:
https://www.seeedstudio.com/ReSpeaker-4-Mic-Array-for-Raspberry-Pi-p-2941.html
https://www.seeedstudio.com/ReSpeaker-Mic-Array-v2-0-p-3053.html
berdasarkan XMOS XVF-3000.
Saya menerapkannya sendiri
Dibuat sesuka saya - FPGA dengan antarmuka terbuka mengontrol mikrofon matriks, berkomunikasi dengannya melalui SDA.
Prestasi saya untuk melintasi Android Things dan Mic Array:
Tentu saja ada banyak contoh untuk papan ini (Suara), tetapi hanya nyaman bagi saya untuk menggunakannya di bawah Things.
Argumen untuk Hal:
Anda dapat membangun alat yang fleksibel dan kuat:
- nyaman bahwa Anda dapat menggunakan layar sebagai perangkat terpisah
- dapat digunakan sebagai perangkat tanpa kepala, mis. melakukan transfer melalui jaringan (buat api untuk ditransfer ke perangkat lain)
- debugging yang nyaman
- banyak perpustakaan, termasuk untuk transmisi melalui jaringan;
- alat analisis - banyak.
- dan jika itu tampak sedikit, maka mungkin untuk menghubungkan perpustakaan Sishnoy
Sebagai contoh, saya menggunakan:
- analisis file suara
- HRTF,
- Pelatihan \ membangun pengklasifikasi.
Dan kemudian jika Anda harus mem-port / menulis ulang kode dalam semacam embed, lebih mudah melakukannya dengan kode Java.
Sayangnya, contoh dari penulis board for Things agak tidak bekerja, jadi saya melakukan proyek demo saya (tentu saja - saya bisa).
Singkatnya, apa yang ada - semua ilmu hitam dari mikrofon polling cepat, kita lakukan FFT di C ++, dan visualisasi, analisis, interaksi jaringan - di Jawa.
Rencana pengembangan masa depan
Sumber rencana dan inspirasi pada saat yang sama: ODAS .
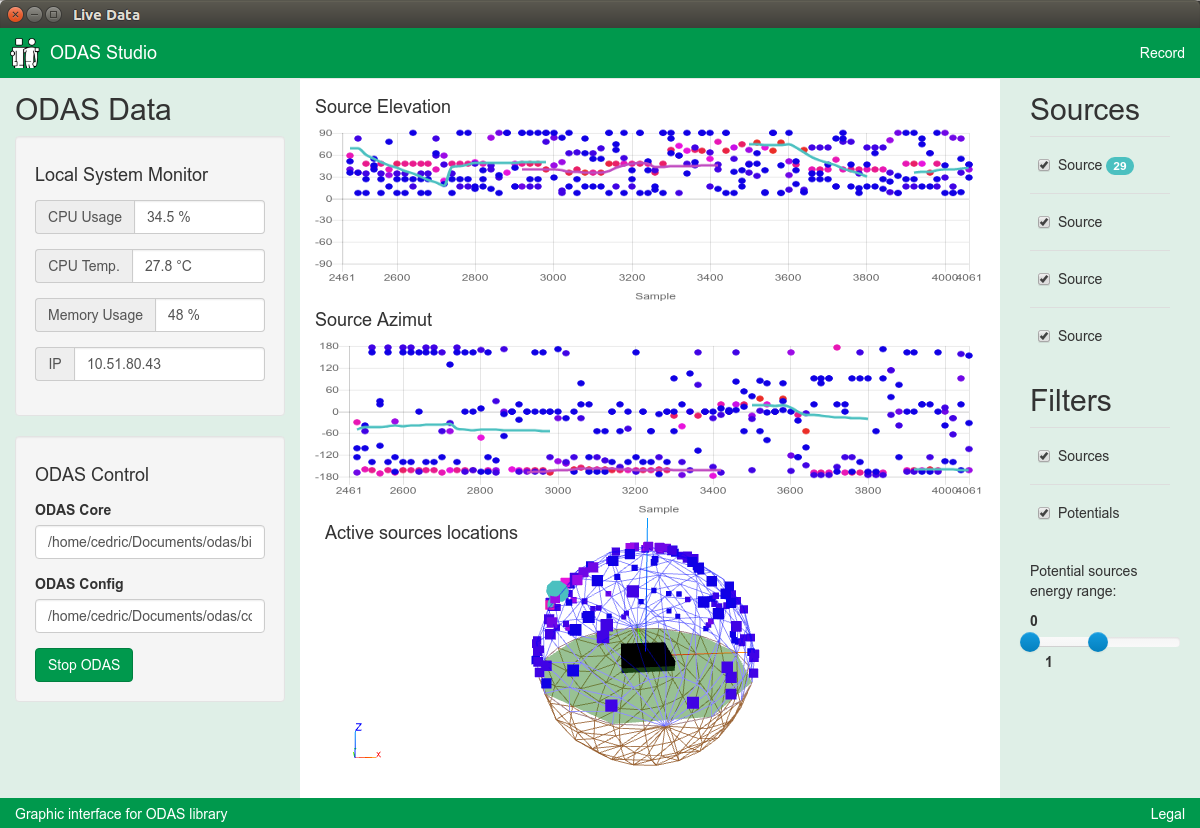
Jadi saya ingin melakukan hal yang sama, hanya pada Things dan tanpa gangguan.
- Karena ODAS agak tidak nyaman untuk digunakan.
- Saya membutuhkan alat normal untuk bekerja
- Karena saya bisa dan saya suka topik ini
- Alat perangkat keras yang digunakan memenuhi kompleksitas tugas.
Paket saya didasarkan pada repositori (milik saya) ini .
Dan ingatkan
"Jika Anda memiliki sesuatu untuk ditambahkan atau dikritik, jangan ragu untuk menuliskannya di komentar, karena satu kepala lebih buruk dari dua, dua lebih buruk dari tiga, dan n-1 lebih buruk daripada n" nikitasius