
Proyek integrasi sistem yang khas bagi kami terlihat seperti ini: pelanggan memiliki kereta sistem untuk pelanggan akuntansi, tugasnya adalah mengumpulkan kartu pelanggan ke dalam satu basis data. Dan tidak hanya untuk mengumpulkan, tetapi juga untuk membersihkan duplikat dan sampah. Untuk mendapatkan kartu pelanggan yang bersih, terstruktur, dan lengkap.
Untuk pemula, saya akan menjelaskan bahwa migrasi berlangsung sesuai dengan skema ini:
sumber → konversi data (jawaban ETL atau bus ) → penerima .
Pada satu proyek, kami kehilangan tiga bulan hanya karena tim integrator pihak ketiga tidak mempelajari data dalam sistem sumber. Yang paling menyebalkan adalah hal ini bisa dihindari.
Mereka bekerja seperti ini:
- Integrator sistem menyesuaikan proses ETL.
- ETL mentransformasikan data sumber dan memberikannya kepada saya.
- Saya belajar membongkar dan mengirim kesalahan ke integrator.
- Integrator memperbaiki ETL dan memulai migrasi lagi.
Dalam artikel ini saya akan menunjukkan cara menganalisis data selama integrasi sistem. Saya mempelajari unggahan ETL, itu sangat berguna. Tetapi pada sumber data, teknik yang sama akan mempercepat pekerjaan dua kali.
Kiat akan berguna untuk penguji, pelaksana produk perusahaan, integrator sistem, dan analis. Resepsi bersifat universal untuk database relasional, dan mereka sepenuhnya diungkapkan pada volume dari satu juta pelanggan.
Tetapi pertama-tama, tentang salah satu mitos utama integrasi sistem.
Dokumentasi dan arsitek akan membantu (sebenarnya tidak)
Integrator sering tidak mempelajari data sebelum migrasi - mereka menghemat waktu. Mereka membaca dokumentasi, melihat strukturnya, berbicara dengan arsitek - dan itu sudah cukup. Setelah itu, mereka sudah merencanakan integrasi.
Ternyata buruk. Hanya analisis yang akan menunjukkan apa yang sebenarnya terjadi dalam database. Jika Anda tidak masuk ke data dengan lengan baju yang digulung dan kaca pembesar, migrasi akan serba salah.
Dokumentasi itu bohong. Sistem khas perusahaan berjalan 5-20 tahun. Selama ini, perubahan di dalamnya telah didokumentasikan oleh berbagai departemen dan kontraktor. Masing-masing dengan menara loncengnya sendiri. Oleh karena itu, tidak ada integritas dalam dokumentasi, tidak ada yang sepenuhnya memahami logika dan struktur penyimpanan data. Belum lagi tenggat waktu selalu ada dan tidak ada cukup waktu untuk dokumentasi.
Sebuah cerita umum: di tabel pelanggan ada bidang "GILA", di atas kertas itu sangat penting. Tetapi ketika saya melihat data, saya melihat - bidang itu kosong. Akibatnya, pelanggan setuju bahwa basis target akan dilakukan tanpa bidang untuk SNIL, karena masih belum ada data.
Kasus khusus dokumentasi adalah peraturan dan deskripsi proses bisnis: bagaimana data masuk ke dalam basis data, dalam keadaan apa, dalam format apa. Semua ini juga tidak akan membantu.
Proses bisnis sempurna hanya di atas kertas. Di pagi hari, operator mengantuk Anatoly datang ke kantor bank di pinggiran Vyksa. Di bawah jendela mereka berteriak sepanjang malam, dan di pagi hari Anatoly bertengkar dengan gadis itu. Dia membenci seluruh dunia.
Saraf belum ditertibkan, dan Anatoly sepenuhnya mendorong nama klien baru ke bidang nama belakang. Dia benar-benar lupa tentang hari ulang tahunnya - default "01.01.1900 g" tetap dalam formulir. Saya tidak peduli tentang peraturan ketika segala sesuatu di sekitarnya sangat menyebalkan !!!
Kekacauan menaklukkan proses bisnis, sangat proporsional di atas kertas.
Seorang arsitek sistem tidak tahu segalanya. Lagi-lagi ini adalah masa hidup yang terhormat dari sistem perusahaan. Selama bertahun-tahun mereka bekerja, arsitek telah berubah. Bahkan jika Anda berbicara dengan yang sekarang, keputusan yang sebelumnya akan muncul sebagai kejutan selama proyek.
Dan pastikan: bahkan seorang arsitek yang menyenangkan dalam segala hal akan menjaga kepura-puraan dan kruknya dari rahasia sistem.
Integrasi "oleh instrumen" tanpa analisis data adalah kesalahan. Saya akan menunjukkan bagaimana kita di HFLabs mempelajari data melalui integrasi sistem. Dalam proyek terakhir, saya hanya menganalisis unggahan ETL. Tetapi ketika pelanggan memberikan akses ke sumber data, saya pasti memeriksanya sesuai dengan prinsip yang sama.
Bidang isian dan nilai nol
Pemeriksaan paling sederhana adalah pada kelengkapan tabel secara keseluruhan dan pada kelengkapan masing-masing bidang. Saya mulai dengan mereka.
Berapa total baris dalam tabel. Permintaan sesederhana mungkin.
SELECT COUNT(*) FROM <table_name>;
Saya mendapatkan hasil pertama.
Di sini saya melihat kecukupan data. Jika hanya dua juta pelanggan datang ke bongkar muat untuk bank besar, maka ada sesuatu yang jelas salah. Tapi sementara semuanya tampak seperti yang diharapkan, terus maju.
Berapa banyak baris yang diisi untuk setiap bidang secara terpisah. Saya memeriksa semua kolom tabel.
SELECT <column_name>, COUNT(*) AS <column_name> cnt FROM <table_name> WHERE <column_name> IS NOT NULL;
Yang pertama menemukan bidang ulang tahun yang bahagia, dan langsung penasaran: karena suatu alasan, datanya tidak datang sama sekali.
Jika semua nilai di lapangan adalah "NULL" dalam unggahan, hal pertama yang saya lihat adalah sistem sumber. Mungkin data disimpan di sana dengan benar, tetapi hilang selama migrasi.
Saya melihat bahwa dalam sistem sumber ulang tahun sudah ada. Saya pergi ke integrator: kawan, kesalahan. Ternyata dalam proses ETL, fungsi decode bekerja dengan tidak benar. Kode sudah diperbaiki, pada unggahan berikutnya kita akan memeriksa perubahannya.
Saya pergi lebih jauh ke lapangan dengan NPWP.
Ada 100 juta orang di database, dan hanya 65 ribu diisi dengan NPWP - ini 0,07%. Tingkat hunian yang lemah adalah sinyal bahwa bidang di dasar penerima mungkin tidak diperlukan sama sekali.
Saya memeriksa sistem sumber, semuanya benar: TIN mirip dengan yang sebenarnya, tetapi hampir tidak ada. Jadi, ini bukan tentang migrasi. Tetap mencari tahu apakah pelanggan membutuhkan bidang yang hampir kosong di bawah TIN dalam database target.
Saya sampai di bendera penghapusan klien.
Bendera kosong. Tapi apa, perusahaan tidak menghapus pelanggan? Saya melihat sistem sumber, berbicara dengan pelanggan. Ternyata ya: benderanya formal, alih-alih menghapus pelanggan, akun mereka dihapus. Tidak ada akun - seolah-olah klien telah dihapus.
Dalam sistem target, bendera klien jarak jauh diperlukan, ini adalah fitur arsitektur. Jadi, jika klien memiliki nol akun di sistem penerima, itu perlu ditutup melalui logika tambahan atau tidak diimpor sama sekali. Lalu bagaimana pelanggan memutuskan.
Selanjutnya adalah pelat alamat. Biasanya ada yang salah dengan tabel seperti itu, karena alamat adalah hal yang rumit, mereka dimasukkan dengan cara yang berbeda.
Saya memeriksa kelengkapan komponen alamat.
Alamat tidak diisi secara seragam, tetapi terlalu dini untuk menarik kesimpulan: pertama saya akan bertanya kepada pelanggan apa tujuan mereka. Jika untuk segmentasi berdasarkan negara, semuanya baik-baik saja: ada cukup data. Jika untuk milis, maka masalahnya adalah: rumah-rumah hampir kosong, tidak ada apartemen.
Akibatnya, pelanggan melihat bahwa ETL mengambil alamat dari tablet yang lama dan tidak relevan. Dia di pangkalan seperti monumen. Tetapi ada tabel lain, baru dan bagus, data harus diambil darinya.
Selama analisis, saya mengisi bidang yang menghubungkan ke direktori dengan kekhasan. Kondisi "BUKAN NULL" tidak berfungsi dengan mereka: alih-alih "NULL", sel biasanya "0". Oleh karena itu, periksa bidang referensi secara terpisah.
Perubahan dalam mengisi bidang. Jadi, saya memeriksa keseluruhan hunian dan hunian masing-masing bidang. Menemukan masalah, integrator memperbaiki proses ETL dan memulai migrasi lagi.
Saya menjalankan pembongkaran kedua untuk semua langkah yang tercantum di atas. Saya menulis statistik ke file yang sama untuk melihat perubahannya.
Kelengkapan semua bidang.
Di antara unggahan, 5 juta catatan menghilang. Saya pergi ke integrator, mengajukan pertanyaan khas:
- "Mengapa catatan hilang?";
- "Data apa yang disaring?";
- "Data apa yang kamu tinggalkan?"
Ternyata tidak ada masalah: mereka hanya menghapus pelanggan "teknis" dari bongkar muat baru. Mereka ada dalam database untuk tes, mereka bukan orang hidup. Tetapi dengan probabilitas yang sama, data bisa hilang karena kesalahan, ini terjadi.
Tapi ulang tahun di bongkar muat baru muncul, seperti yang saya harapkan.
Tapi! Belum tentu bagus ketika data yang sebelumnya hilang tiba-tiba muncul di unggahan baru. Misalnya, ulang tahun dapat diisi dengan tanggal standar - tidak ada yang perlu disukacitakan. Karena itu, saya selalu memeriksa data mana yang datang.
Singkatnya, apa yang harus diperiksa.
- Jumlah total entri dalam tabel. Apakah kuantitas ini memadai untuk harapan?
- Jumlah baris yang diisi di setiap bidang.
- Rasio jumlah baris yang diisi di setiap bidang dengan jumlah baris dalam tabel. Jika terlalu kecil, ini adalah kesempatan untuk berpikir apakah akan menyeret bidang ke basis target.
Ulangi tiga langkah pertama untuk setiap unggahan. Ikuti dinamika: di mana dan mengapa itu meningkat atau menurun.Panjang nilai dalam bidang string
Saya mengikuti salah satu aturan dasar pengujian - saya memeriksa nilai batas.
Nilai mana yang terlalu pendek. Di antara nilai-nilai terpendek penuh dengan sampah, sehingga menarik untuk digali di sini.
SELECT * FROM <table_name> WHERE LENGTH(<column_name>) < 3;
Dengan cara ini, saya memeriksa nama, nomor telepon, TIN, OKVED, alamat situs web. Omong kosong muncul seperti "A * 1", "0", "11", "-" dan "...".
Apakah semuanya baik-baik saja dengan nilai maksimum. Bidang tertutup adalah penanda fakta bahwa data tidak cocok selama transfer, dan data terputus secara otomatis. MySQL memecahkan masalah ini dengan terkenal tanpa peringatan. Pada saat yang sama, tampaknya migrasi berjalan lancar.
SELECT * FROM <table_name> WHERE LENGTH(<column_name>) = 65;
Dengan cara ini, saya menemukan di lapangan dengan jenis dokumen baris "Sertifikat pendaftaran aplikasi imigran untuk pengakuannya." Dia mengatakan kepada integrator, panjang bidang dikoreksi.
Bagaimana nilai-nilai didistribusikan sepanjang. Di HFLabs, kami memanggil tabel distribusi panjang untuk baris.
SELECT LENGTH(<column_name>), COUNT(<column_name>) FROM <table_name> GROUP BY LENGTH(<column_name>);
Di sini saya mencari anomali dalam distribusi sepanjang. Misalnya, ini adalah frekuensi untuk tabel dengan alamat surat.
Nilai dengan panjang 125 terlalu banyak. Saya melihat basis data sumber dan menemukan bahwa karena suatu alasan, beberapa alamat terputus menjadi 125 karakter tiga tahun lalu. Di tahun-tahun lainnya, semuanya baik-baik saja. Saya setuju dengan masalah ini kepada pelanggan dan integrator, kami mengerti.
Singkatnya, apa yang harus diperiksa.
- Nilai terpendek dalam bidang string. Seringkali baris dengan karakter kurang dari tiga adalah sampah.
- Nilai yang "berbatasan" di sepanjang panjang bidang. Seringkali mereka disunat.
- Anomali dalam distribusi baris sepanjang.
Nilai Populer
Saya membagi menjadi tiga kategori nilai-nilai yang termasuk dalam populer teratas:
- sangat umum , seperti nama "Tatyana" atau nama tengah "Vladimirovich". Di sini harus diingat bahwa dalam kasus umum, Tatyana tidak boleh 100 kali lebih populer daripada Anna, dan Ismail hampir tidak bisa lebih populer daripada Egor;
- sampah , seperti ".", "1", "-" dan sejenisnya;
- Default pada formulir input, sebagai "01/01/1900" untuk tanggal.
Dua dari tiga kasus adalah penanda masalah, akan berguna untuk mencarinya.
Saya mencari nilai-nilai populer di tiga jenis bidang:
- Bidang string biasa.
- Bidang string referensi. Ini adalah bidang string biasa, tetapi jumlah nilai yang berbeda di dalamnya tentu saja diatur. Bidang-bidang ini menyimpan negara, kota, bulan, jenis telepon.
- Bidang pengklasifikasi - berisi tautan ke entri di tabel pengklasifikasi pihak ketiga.
Saya mempelajari bidang masing-masing jenis ini sedikit berbeda.
Untuk bidang string - berapakah 100 nilai populer teratas. Jika mau, Anda bisa mengambil lebih banyak, tetapi dalam seratus nilai pertama semua anomali biasanya ditempatkan.
SELECT * FROM (SELECT <column_name>, COUNT(*) cnt FROM <table_name> GROUP BY <column_name> ORDER BY 2 DESC) WHERE ROWNUM <= 100;
Saya memeriksa bidang dengan cara ini:
- Nama lengkap, serta nama belakang, nama depan, dan patronimik yang terpisah;
- tanggal lahir dan umumnya tanggal apa pun;
- alamat Alamat lengkap dan komponen individualnya, jika disimpan dalam basis data;
- Telepon
- seri, nomor, jenis, tempat penerbitan dokumen.
Hampir selalu di antara nilai tes populer dan standar, beberapa bertopik.

Terjadi bahwa masalah yang ditemukan bukan masalah sama sekali. Suatu ketika saya menemukan nomor telepon yang mencurigakan populer di database. Ternyata klien menunjukkan nomor ini sebagai pekerja, dan dalam database hanya ada banyak karyawan dari satu organisasi.
Sepanjang jalan, analisis semacam itu akan menampilkan bidang referensi tersembunyi. Logikanya, bidang-bidang ini tidak seharusnya menjadi direktori, tetapi sebenarnya mereka ada di database. Misalnya, saya memilih nilai-nilai populer dari bidang "Posisi", dan hanya ada lima.
Mungkin perusahaan hanya melayani lima profesi. Tidak terlalu benar, bukan? Alih-alih, dalam bentuk untuk operator, alih-alih baris, mereka membuat direktori dan lupa untuk membuang nilai. Pertanyaan penting di sini adalah: apakah bijak mengisi posting melalui direktori? Jadi melalui analisis data, saya mencari kemungkinan masalah dengan perangkat lunak operator.
Untuk bidang referensi dan pengklasifikasi, saya memeriksa popularitas semua nilai. Untuk memulainya, saya mencari tahu bidang mana yang merupakan direktori. Anda tidak dapat bertahan dengan skrip, saya mengambil dokumentasi dan berpura-pura. Biasanya, direktori dibuat untuk nilai yang jumlahnya terbatas dan relatif kecil:
- negara
- bahasa
- mata uang
- bulan
- kota.
Di dunia yang ideal, isi bidang referensi jelas dan konsisten. Tapi dunia kita tidak seperti itu, jadi saya periksa dengan permintaan.
SELECT <column_name>, COUNT(*) cnt FROM <table_name> GROUP BY <column_name> ORDER BY 2 DESC;
Biasanya di bidang string direktori terletak ini.
Masalah umum:
- kesalahan ketik;
- spasi
- kasus yang berbeda.
Setelah menemukan kekacauan, saya pergi ke integrator dengan contoh di tangan. Biarkan mereka meninggalkan sampah di sumbernya, dan menghilangkan perbedaan. Kemudian dalam database target untuk rigor, dimungkinkan untuk mengubah garis referensi menjadi pengklasifikasi.
Saya memeriksa nilai-nilai populer di bidang classifier untuk menangkap kurangnya pilihan. Menghadapi kasus seperti itu.
Penggolong seperti itu terlihat sangat aneh, mereka harus ditunjukkan kepada pelanggan. Setiap kali saya memiliki kesalahan di balik kasus-kasus seperti itu: entah ada sesuatu yang salah dalam database, atau data diunduh dari tempat yang salah.
Singkatnya, apa yang harus diperiksa.
- Bidang string mana yang menjadi referensi dan mana yang bukan.
- Untuk bidang string sederhana, nilai teratas populer. Biasanya di bagian atas sampah dan data default.
- Untuk bidang referensi string, distribusi semua nilai berdasarkan popularitas. Seleksi akan menunjukkan perbedaan dalam nilai referensi.
- Untuk pengklasifikasi - apakah ada cukup opsi dalam database.
Konsistensi dan Rekonsiliasi Lintas
Dari analisis data di dalam tabel, saya beralih ke analisis hubungan.
Apakah data terikat atau tidak. Kami menyebut parameter ini "konsistensi". Saya mengambil tabel bawahan, misalnya, dengan telepon. Untuk itu dalam pasangan - tabel induk klien. Dan saya melihat berapa banyak klien dalam tabel bawahan adalah pengidentifikasi yang tidak ada dalam induk.
SELECT COUNT(*) FROM ((SELECT <ID1> FROM <table_name_1>) MINUS (SELECT <ID2> FROM <table_name_2>));
Jika permintaan memberi delta, artinya tidak berhasil - ada data yang tidak terkait dalam unggahan. Jadi saya memeriksa tabel dengan telepon, kontrak, alamat, tagihan dan sebagainya. Suatu ketika, selama proyek, dia menemukan 23 juta angka yang menggantung di udara.
Ini juga bekerja dalam arah yang berlawanan - Saya mencari klien yang karena alasan tertentu tidak memiliki kontrak tunggal, alamat, nomor telepon. Terkadang ini normal - yah, klien tidak memiliki alamat, apa yang salah. Di sini Anda perlu mencari tahu dari pelanggan, dokumentasi akan dengan mudah menipu.
Apakah ada duplikasi kunci utama dalam tabel yang berbeda. Terkadang entitas identik disimpan dalam tabel yang berbeda. Misalnya, pelanggan heteroseksual. (Tidak ada yang tahu mengapa, karena Brezhnev masih mengklaim strukturnya.) Tetapi tabel di penerima adalah tunggal, dan ketika bermigrasi, pengidentifikasi klien akan mengalami konflik.
Saya menghidupkan kepala saya dan melihat struktur pangkalan: di mana fragmentasi entitas serupa mungkin terjadi. Ini bisa berupa tabel pelanggan, telepon kontak, paspor dan sebagainya.
Jika ada beberapa tabel dengan entitas yang serupa, saya melakukan pemeriksaan silang: Saya memeriksa persimpangan pengidentifikasi. Intersect - lem patch. Misalnya, kami mengumpulkan pengidentifikasi untuk tabel tunggal sesuai dengan skema "nama tabel sumber + ID".
Singkatnya, apa yang harus diperiksa.
- Berapa banyak data yang tidak terkait dalam tabel yang ditautkan.
- Adakah potensi konflik kunci primer?
Apa lagi yang perlu diperiksa
Apakah ada karakter Latin yang bukan miliknya? Misalnya, dalam nama keluarga.
SELECT <column_name> FROM <table_name> WHERE REGEXP_LIKE(<column_name>, '[AZ]', 'i');
Jadi saya menangkap huruf Latin yang indah "C", yang bertepatan dengan Cyrillic. Kesalahannya tidak menyenangkan, karena sesuai dengan nama dengan "C" Latin operator tidak akan pernah menemukan klien.
Apakah ada karakter asing di bidang string yang dimaksudkan untuk angka? SELECT <column_name> FROM <table_name> WHERE REGEXP_LIKE(<column_name>, '[^0-9]');
Masalah muncul di bidang dengan nomor paspor Federasi Rusia atau TIN. Ponsel sama, tetapi di sana saya mengizinkan plus, tanda kurung dan tanda hubung. Permintaan juga akan mengungkapkan huruf "O", yang ditetapkan bukan nol.
Seberapa memadai data tersebut. Anda tidak pernah tahu di mana masalah akan muncul, jadi saya selalu waspada. Saya bertemu dengan beberapa kasus:
- Apakah "Sofya Vladimirovna" klien 50.000 telepon - apakah ini normal? Jawab: tidak normal. Klien itu teknis, mereka memasukkan nomor telepon "tanpa pemilik" padanya untuk melakukan sms-mail. Tidak perlu menarik klien ke pangkalan baru;
- Nomor identifikasi wajib pajak diisi, pada kenyataannya, kolom berisi "79853617764", "89109462345", "4956780966" dan seterusnya. Telepon macam apa, okuda? Dimana penginapannya? Jawab: angka seperti apa - tidak diketahui siapa yang menyebutkannya - tidak jelas. Tidak ada yang menggunakannya. NPWP saat ini disimpan di bidang lain dari tabel lain, diambil dari sana;
- bidang “address in one line” tidak sesuai dengan bidang di mana alamat disimpan di bagian-bagian. Mengapa alamatnya berbeda? Jawab: begitu operator mengisi alamat dengan satu baris, dan sistem eksternal mengurutkan alamat ke dalam bidang yang berbeda. Untuk segmentasi. Seiring waktu berlalu, orang-orang mengubah alamat. Operator secara teratur memperbaruinya, tetapi hanya sebagai string: alamat tetap lama di beberapa bagian.
Yang Anda butuhkan hanyalah SQL dan Excel
Untuk menganalisis data, perangkat lunak yang mahal tidak diperlukan. Excel tua yang cukup baik dan pengetahuan tentang SQL.
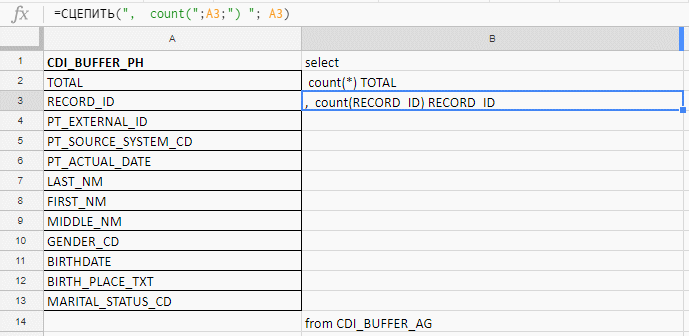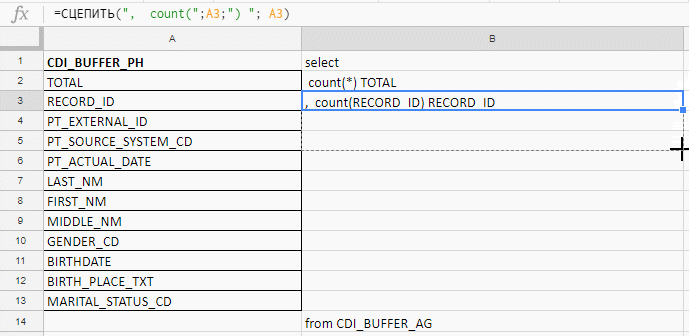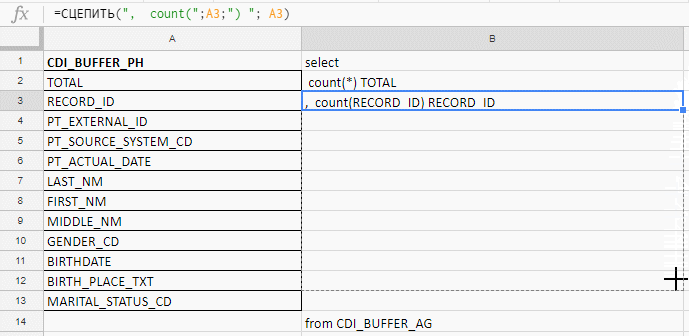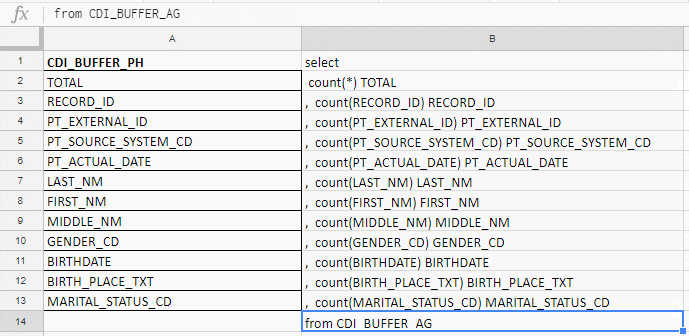
Excel saya gunakan untuk mengkompilasi permintaan panjang. Sebagai contoh, saya memeriksa kolom untuk kelengkapan, dan ada 140 di tabel. Saya akan menulis dengan tangan saya di depan konspirasi wortel, jadi saya mengumpulkan permintaan dengan formula di excel-plate.
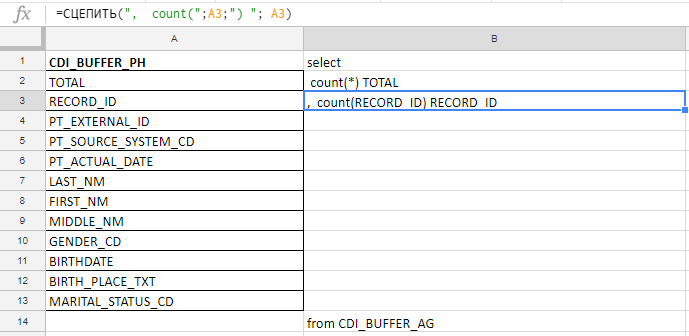 Di kolom "A" saya memasukkan nama-nama bidang, saya membawanya dalam dokumentasi atau tabel layanan. Di kolom "B" - formula untuk menempelkan permintaan
Di kolom "A" saya memasukkan nama-nama bidang, saya membawanya dalam dokumentasi atau tabel layanan. Di kolom "B" - formula untuk menempelkan permintaanSaya memasukkan nama-nama bidang, menulis rumus pertama di kolom "B", tarik sudut - dan Anda selesai.
 Bekerja di Excel, dan di Google Documents, dan di Excel Online (tersedia di Yandex.Disk)
Bekerja di Excel, dan di Google Documents, dan di Excel Online (tersedia di Yandex.Disk)Analisis data menghemat waktu dan menghemat keberanian para manajer. Dengan itu lebih mudah untuk memenuhi tenggat waktu. Jika proyek ini besar, analitik akan menghemat jutaan rubel dan reputasi.
Bukan angka, tapi kesimpulan
Dia merumuskan aturan untuk dirinya sendiri: untuk tidak menunjukkan nomor telanjang kepada pelanggan, Anda masih tidak akan mendapatkan efeknya. Tugas saya adalah menganalisis data dan menarik kesimpulan, dan melampirkan angka sebagai bukti. Kesimpulannya adalah primer, angka adalah sekunder.
Apa yang saya kumpulkan untuk laporan:
- kata-kata dari masalah dalam bentuk hipotesis atau pertanyaan : "TIN penuh 0,07%. Bagaimana Anda menggunakan data ini, seberapa relevan itu, bagaimana menafsirkannya? Apakah hanya ada satu INN di satu meja? ” Anda tidak dapat menyalahkan: "TIN Anda tidak terisi sama sekali." Sebagai tanggapan, Anda hanya akan menerima agresi;
- contoh masalah. Ini adalah tablet yang ada begitu banyak di artikel;
- opsi untuk bagaimana melakukannya: "Mungkin perlu menghapus TIN dari basis target agar tidak menghasilkan bidang kosong."
Saya tidak punya hak untuk memutuskan apa yang harus dipilih dari sumber database dan bagaimana mengubah data selama migrasi. Oleh karena itu, dengan laporan tersebut, saya pergi ke pelanggan atau ke integrator, dan kami mencari tahu bagaimana untuk melanjutkan.
Terkadang pelanggan, melihat masalahnya, menjawab: “Jangan khawatir, jangan perhatikan. Kami akan membeli memori terabyte ekstra, itu saja. Itu lebih murah daripada mengoptimalkan. " Anda tidak dapat menyetujui hal ini: jika Anda mengambil semuanya dalam satu baris, tidak akan ada kualitas pada penerima. Semua data redundan sampah yang sama sedang dimigrasi.
Oleh karena itu, kami dengan lembut tetapi terus bertanya: "Beri tahu kami bagaimana Anda akan menggunakan data khusus ini dalam sistem target." Bukan "mengapa Anda perlu", yaitu "bagaimana Anda akan menggunakannya." Jawaban "maka kita akan datang dengan" atau "berjaga-jaga" tidak cocok. Cepat atau lambat, pelanggan mengerti data apa yang bisa diberikan.
Hal utama adalah menemukan dan menyelesaikan semua masalah sampai sistem diluncurkan di prod. Untuk mengubah arsitektur dan model data hidup, Anda akan kehilangan akal.
Itu semua dengan cek dasar, pelajari data!