Tentang permainan Revenge Montezuma tentang Habré ditulis tidak begitu banyak. Ini adalah permainan klasik yang kompleks yang sebelumnya sangat populer, tetapi sekarang dimainkan baik oleh mereka yang membangkitkan perasaan nostalgia, atau oleh para peneliti yang mengembangkan AI.
Musim panas ini,
dilaporkan bahwa DeepMind mampu mengajari AI-nya cara bermain game untuk Atari, termasuk Montezuma's Revenge. Menggunakan contoh game yang sama, pencipta OpenAI juga
mengajarkan perkembangan mereka. Sekarang Uber telah mengambil proyek serupa.
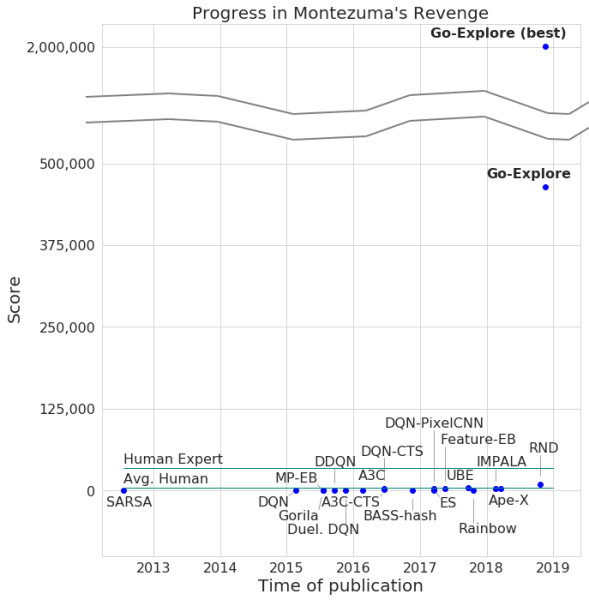
Para pengembang mengumumkan jalannya game dengan jaringan saraf mereka, dengan jumlah poin maksimum 2 juta. Benar, rata-rata, sistem memperoleh tidak lebih dari 400.000 untuk setiap upaya. Adapun bagian, komputer mencapai level 159.
Selain itu, Go-Explore belajar cara melewati Pitfall, dengan hasil yang sangat baik yang lebih unggul dari rata-rata pemain, belum lagi agen AI lainnya. Jumlah poin yang dicetak oleh Go-Explore dalam game ini adalah 21.000.
Perbedaan antara Go-Jelajahi dan "rekan-rekan" adalah bahwa jaringan saraf tidak perlu menunjukkan melewati tingkat yang berbeda untuk pelatihan. Sistem mempelajari semuanya sendiri selama permainan, menunjukkan hasil yang jauh lebih tinggi daripada yang ditunjukkan oleh jaringan saraf yang membutuhkan pelatihan visual. Menurut pengembang Go-Explore, teknologinya sangat berbeda dari yang lain, dan kemampuannya memungkinkan penggunaan jaringan saraf di sejumlah area, termasuk robot.
Sebagian besar algoritme merasa sulit untuk menangani Pembalasan Montezuma karena permainan tidak memiliki umpan balik yang sangat eksplisit. Misalnya, jaringan saraf yang "diasah" untuk menerima hadiah dalam proses melewati level lebih baik akan melawan musuh daripada melompat ke tangga yang mengarah ke pintu keluar dan memungkinkan Anda untuk bergerak maju lebih cepat. Sistem AI lainnya lebih suka menerima hadiah di sini dan sekarang, dan tidak maju dalam "harapan" untuk lebih.
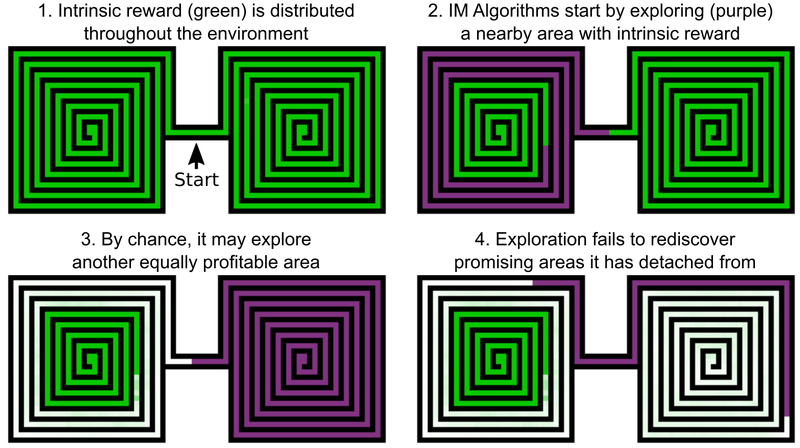
Salah satu keputusan insinyur Uber adalah menambahkan bonus untuk menjelajahi dunia game, ini bisa disebut motivasi internal AI. Tetapi bahkan elemen AI dengan motivasi intrinsik tambahan tidak dapat bekerja dengan baik dengan Revenge and Pitfall Montezuma. Masalahnya adalah bahwa AI "lupa" tentang lokasi yang menjanjikan setelah melewati mereka. Akibatnya, agen AI macet pada tingkat di mana segala sesuatu tampaknya telah diselidiki.
Contohnya adalah agen AI, yang perlu mempelajari dua labirin - timur dan barat. Dia mulai melalui salah satu dari mereka, tetapi kemudian tiba-tiba memutuskan bahwa mungkin untuk melewati yang kedua. Yang pertama tetap dipelajari di 50%, yang kedua di 100%. Dan agen tidak kembali ke labirin pertama - hanya karena dia "lupa" bahwa dia belum selesai sampai akhir. Dan karena lorong antara labirin timur dan barat telah dipelajari, AI tidak memiliki motivasi untuk kembali.
Solusi untuk masalah ini, menurut pengembang dari Uber, meliputi dua tahap: penelitian dan amplifikasi. Adapun bagian pertama, di sini AI membuat arsip berbagai status permainan - sel (sel) - dan berbagai lintasan yang mengarah ke sana. AI memilih peluang untuk mendapatkan jumlah poin maksimum saat mendeteksi lintasan optimal.
Sel adalah bingkai permainan yang disederhanakan - gambar berukuran 11 kali 8 dalam warna abu-abu dengan intensitas 8 piksel, dengan bingkai yang cukup berbeda - sehingga tidak menghalangi jalannya permainan lebih lanjut.

Akibatnya, AI mengingat lokasi yang menjanjikan dan kembali ke sana setelah memeriksa bagian lain dari dunia game. "Keinginan" untuk menjelajahi dunia game dan lokasi yang menjanjikan di Go-Explore lebih kuat daripada keinginan untuk menerima penghargaan di sini dan sekarang. Go-Jelajahi juga menggunakan informasi tentang sel-sel di mana agen AI dilatih. Untuk Montezuma's Revenge, ini adalah data piksel seperti koordinat X dan Y, ruang saat ini, dan jumlah kunci yang ditemukan.
Tahap amplifikasi berfungsi sebagai perlindungan terhadap "noise". Jika solusi AI tidak stabil untuk "noise", maka AI memperkuatnya dengan bantuan jaringan saraf multi-level, yang beroperasi pada contoh neuron otak manusia.

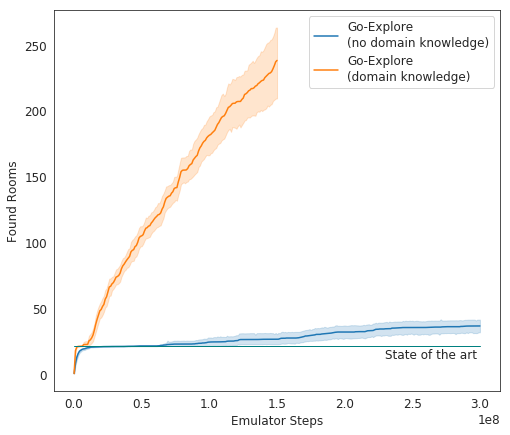
Dalam tes, Go-Explore berkinerja sangat baik - rata-rata, AI mempelajari 37 kamar dan memecahkan 65% dari teka-teki tingkat pertama. Ini jauh lebih baik daripada upaya sebelumnya untuk menaklukkan permainan - maka AI rata-rata mempelajari 22 kamar di tingkat pertama.

Ketika menambahkan gain ke algoritma yang ada, AI mulai berhasil menyelesaikan rata-rata 29 level (bukan kamar) dengan skor rata-rata 469,209.
Inkarnasi terakhir AI Uber mulai menjalankan permainan jauh lebih baik daripada agen AI lainnya, dan lebih baik daripada manusia. Sekarang pengembang memperbaiki sistem mereka sehingga menunjukkan hasil yang lebih mengesankan.