Pada 8 November, di aula utama konferensi
HighLoad ++ 2018 , dalam kerangka kerja bagian DevOps dan Operasi, sebuah laporan dibuat berjudul Databases and Kubernetes. Ini berbicara tentang ketersediaan tinggi database dan pendekatan toleransi kesalahan untuk Kubernetes dan dengannya, serta pilihan praktis untuk menempatkan DBMS di cluster Kubernetes dan solusi yang ada untuk ini (termasuk Stolon untuk PostgreSQL).

Secara tradisi, kami senang menyajikan
video dengan laporan (sekitar satu jam,
jauh lebih informatif
daripada artikel) dan penekanan utama dalam bentuk teks. Ayo pergi!
Teori
Laporan ini muncul sebagai jawaban atas salah satu pertanyaan paling populer yang selama beberapa tahun terakhir kami telah ditanyai tanpa lelah di berbagai tempat: komentar di Habr atau YouTube, jejaring sosial, dll. Kedengarannya sederhana: "Apakah mungkin untuk menjalankan database di Kubernetes?", Dan jika kita biasanya menjawab "secara umum ya, tapi ...", maka jelas tidak ada cukup penjelasan untuk ini "secara umum" dan "tetapi", tetapi untuk mencocokkannya dalam pesan singkat tidak berhasil.
Namun, sebagai permulaan, saya meringkas masalah dari "database [data]" menjadi stateful secara keseluruhan. DBMS hanya merupakan kasus khusus dari keputusan negara, daftar yang lebih lengkap yang dapat direpresentasikan sebagai berikut:
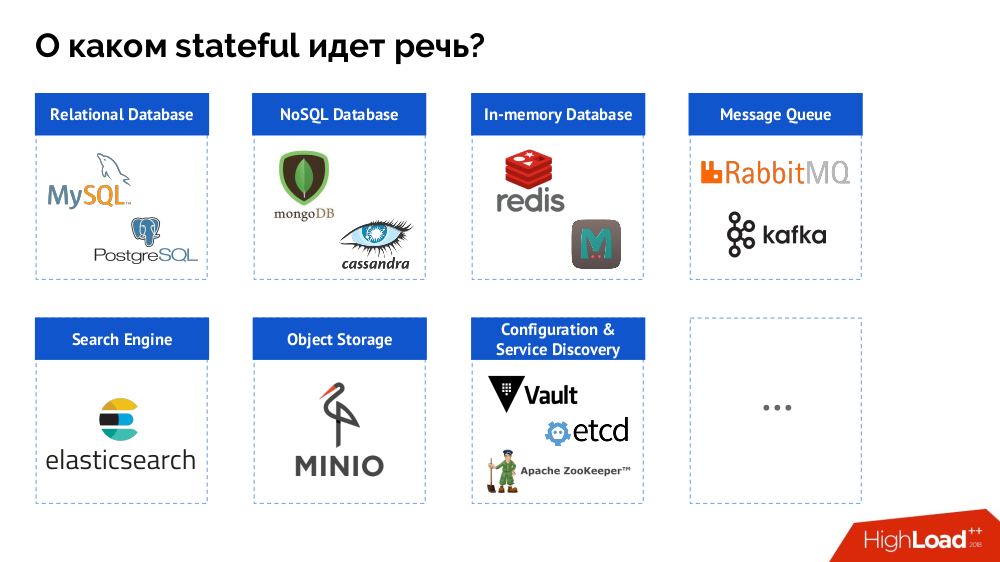
Sebelum melihat kasus-kasus tertentu, saya akan berbicara tentang tiga fitur penting dari pekerjaan / penggunaan Kubernetes.
1. Filosofi Ketersediaan Tinggi Kubernetes
Semua orang tahu analogi "hewan peliharaan dan
ternak " dan mengerti bahwa jika Kubernetes adalah cerita dari dunia kawanan, maka DBMS klasik hanyalah hewan peliharaan.
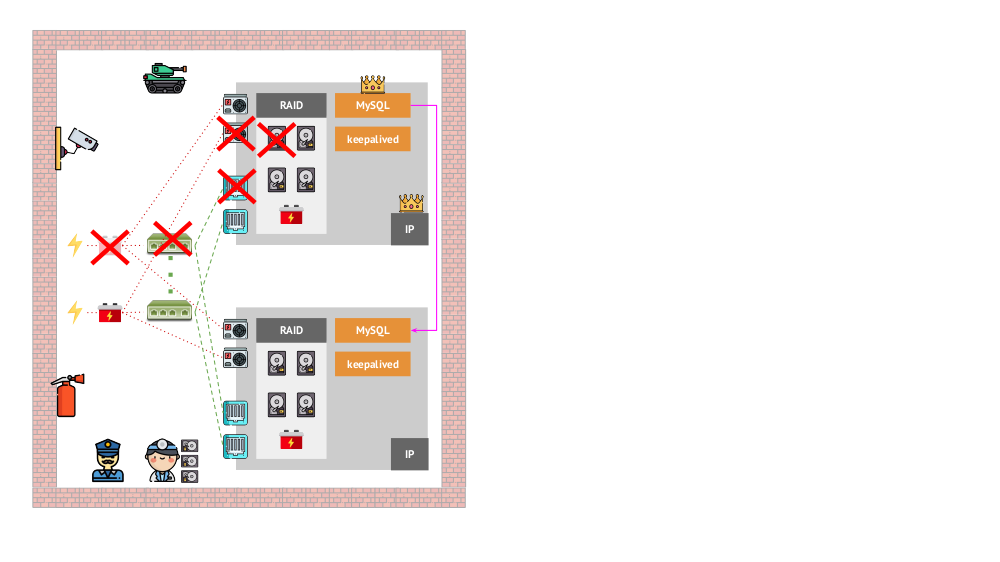
Dan seperti apa arsitektur "hewan peliharaan" terlihat dalam versi "tradisional"? Contoh klasik menginstal MySQL adalah replikasi pada dua server besi dengan daya redundan, disk, jaringan ... dan yang lainnya (termasuk seorang insinyur dan berbagai alat bantu), yang akan membantu kita memastikan bahwa proses MySQL tidak akan gagal, dan jika ada masalah dengan masalah kritis apa pun untuk komponen-komponennya, toleransi kesalahan akan dihormati:
Bagaimana tampilan yang sama di Kubernetes? Di sini, biasanya ada jauh lebih banyak server besi, mereka lebih sederhana dan mereka tidak memiliki daya dan jaringan yang berlebihan (dalam arti bahwa kehilangan satu mesin tidak mempengaruhi apa pun) - semua ini digabungkan menjadi sebuah cluster. Toleransi kesalahannya disediakan oleh perangkat lunak: jika sesuatu terjadi pada node, Kubernetes mendeteksi dan memulai instance yang diperlukan pada node lain.
Apa mekanisme ketersediaan tinggi di K8?
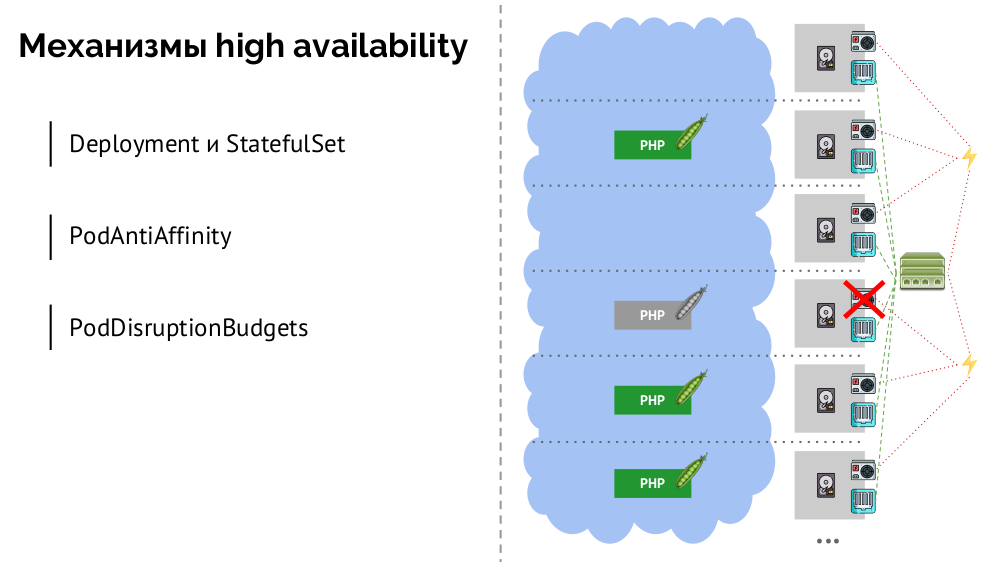
- Pengontrol Ada banyak, tetapi dua yang utama:
Deployment (untuk aplikasi stateless) dan StatefulSet (untuk aplikasi stateful). Mereka menyimpan semua logika tindakan yang diambil jika terjadi crash node (pod tidak dapat diaksesnya). PodAntiAffinity - kemampuan untuk menentukan pod tertentu sehingga tidak berada pada simpul yang sama.PodDisruptionBudgets - membatasi jumlah instance pod yang dapat dimatikan pada saat yang sama jika ada pekerjaan yang dijadwalkan.
2. Jaminan konsistensi Kubernetes
Bagaimana cara kerja skema toleransi kesalahan satu-induk yang sudah dikenal? Dua server (master dan siaga), salah satunya secara konstan diakses oleh aplikasi, yang pada gilirannya digunakan melalui penyeimbang beban. Apa yang terjadi jika terjadi masalah jaringan?
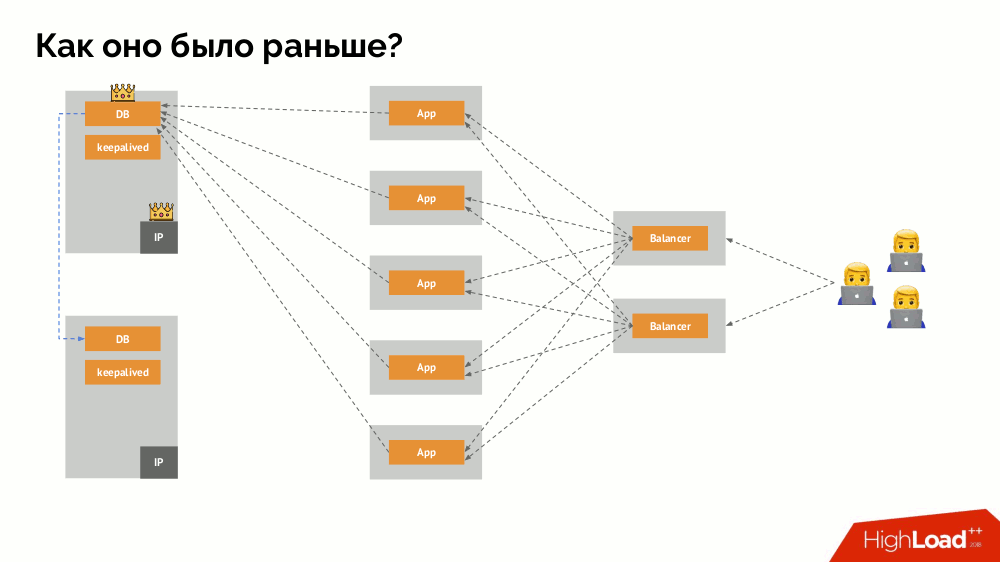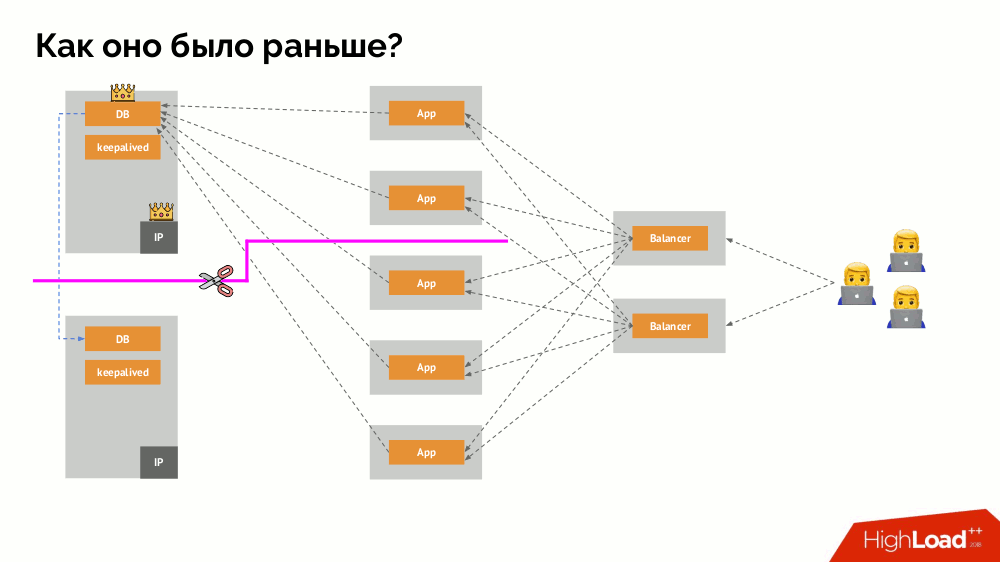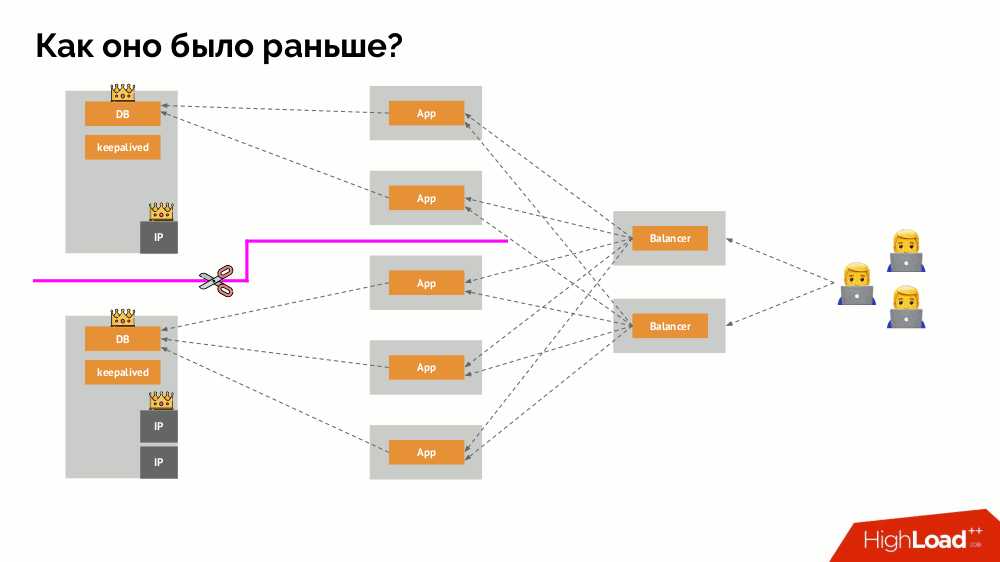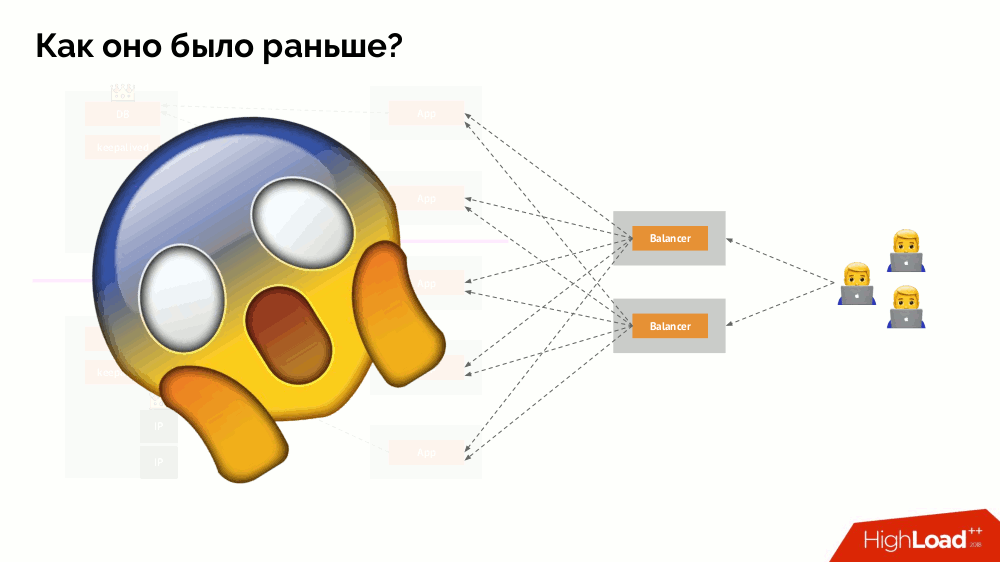
Klasik
-otak : aplikasi mulai mengakses kedua contoh DBMS, masing-masing menganggap dirinya sebagai yang utama. Untuk menghindari ini, keepalived diganti dengan corosync dengan sudah tiga contoh untuk mencapai kuorum saat memberikan suara untuk master. Namun, bahkan dalam kasus ini ada masalah: jika turunan DBMS jatuh mencoba untuk "bunuh diri" dengan segala cara yang mungkin (menghapus alamat IP, menerjemahkan database menjadi read-only ...), maka bagian lain dari cluster tidak tahu apa yang terjadi pada master - itu bisa terjadi, bahwa simpul itu benar-benar masih berfungsi dan permintaan sampai ke sana, yang berarti bahwa kita masih tidak bisa mengganti wizard.
Untuk mengatasi situasi ini, ada mekanisme untuk mengisolasi node untuk melindungi seluruh cluster dari operasi yang salah - proses ini disebut
pagar . Esensi praktis bermuara pada kenyataan bahwa kita mencoba dengan beberapa cara eksternal untuk "membunuh" mobil yang jatuh. Pendekatannya bisa berbeda: dari mematikan mesin melalui IPMI dan memblokir port pada sakelar hingga mengakses API penyedia cloud, dll. Dan hanya setelah operasi ini Anda dapat beralih wizard. Ini memastikan jaminan
paling banyak yang menjamin
konsistensi kami.
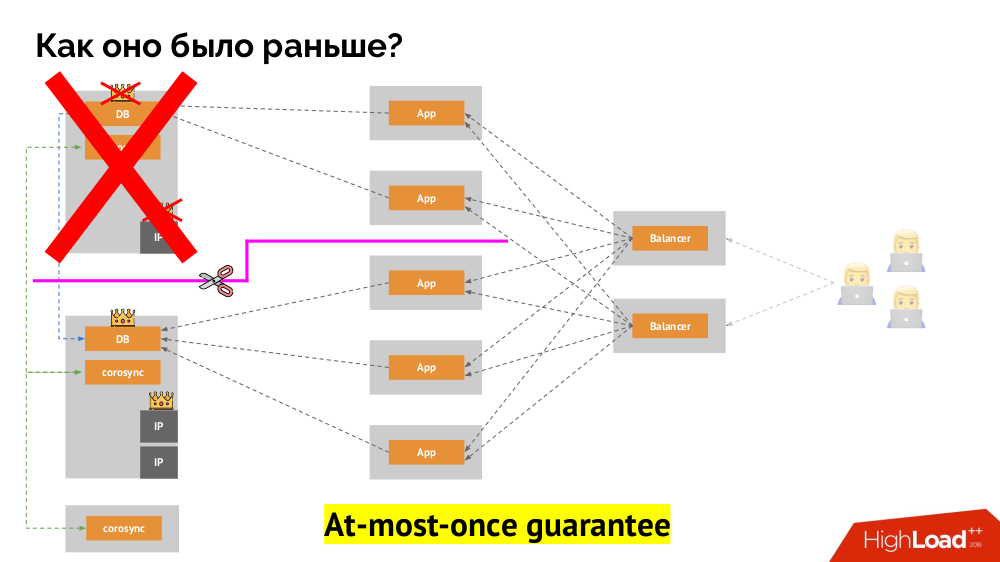
Bagaimana cara mencapai hal yang sama di Kubernetes? Untuk melakukan ini, ada pengendali yang telah disebutkan, perilaku yang dalam hal node tidak dapat diakses berbeda:
Deployment : "Saya diberi tahu bahwa seharusnya ada 3 pod, dan sekarang hanya ada 2 pod - saya akan membuat yang baru";StatefulSet : "Pod pergi?" Saya akan menunggu: apakah simpul ini akan kembali, atau mereka akan menyuruh kita untuk membunuhnya, " wadah itu sendiri (tanpa tindakan operator) tidak diciptakan kembali. Begitulah jaminan yang sama paling banyak sekali dicapai.
Namun, di sini, dalam kasus terakhir, pagar diperlukan: kita membutuhkan mekanisme yang mengkonfirmasi bahwa simpul ini sudah tidak ada. Membuatnya otomatis, pertama, sangat sulit (banyak implementasi yang diperlukan), dan kedua, bahkan lebih buruk, biasanya membunuh node secara lambat (mengakses IPMI dapat mengambil detik atau puluhan detik, atau bahkan beberapa menit). Hanya sedikit orang yang puas dengan menunggu per menit untuk mengalihkan pangkalan ke master baru. Tetapi ada pendekatan lain yang tidak memerlukan mekanisme pagar ...
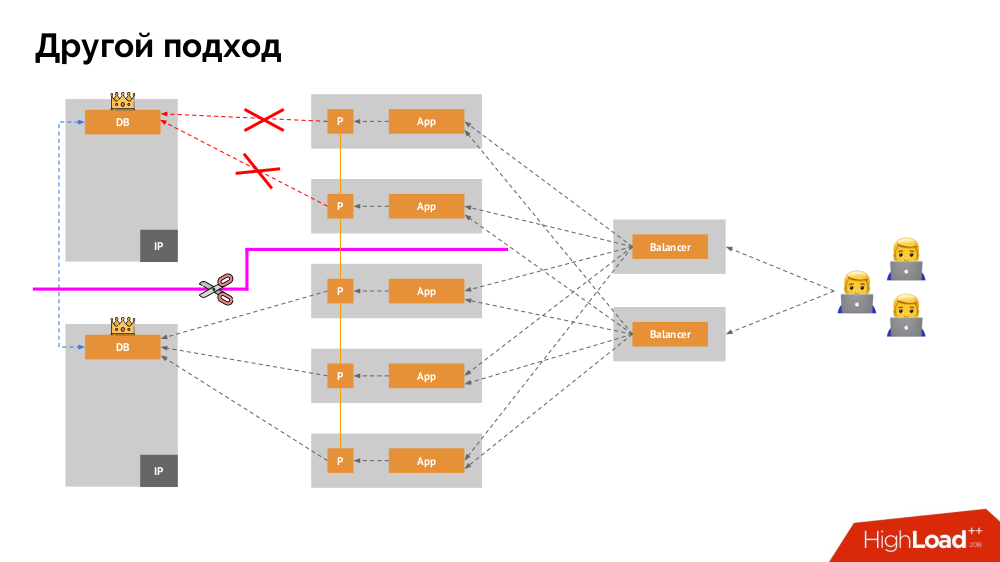
Saya akan memulai deskripsinya di luar Kubernetes. Ia menggunakan penyeimbang beban khusus di mana backend mengakses DBMS. Spesifisitasnya terletak pada fakta bahwa ia memiliki sifat konsistensi, yaitu perlindungan terhadap kegagalan jaringan dan split-brain, karena memungkinkan Anda untuk menghapus semua koneksi ke master saat ini, tunggu sinkronisasi (replika) pada node lain dan beralih ke itu. Saya tidak menemukan istilah yang mapan untuk pendekatan ini dan menyebutnya
Konsisten Peralihan .
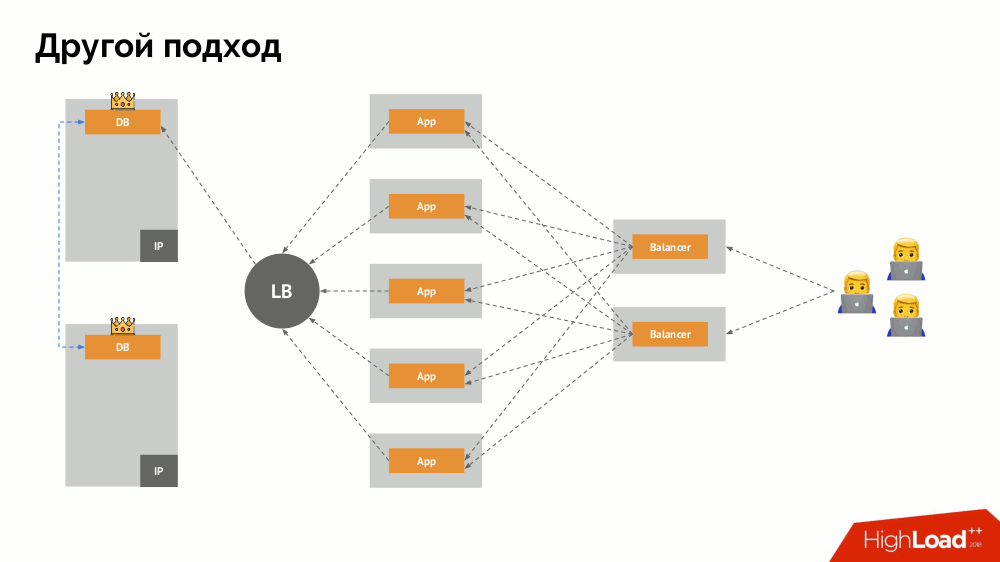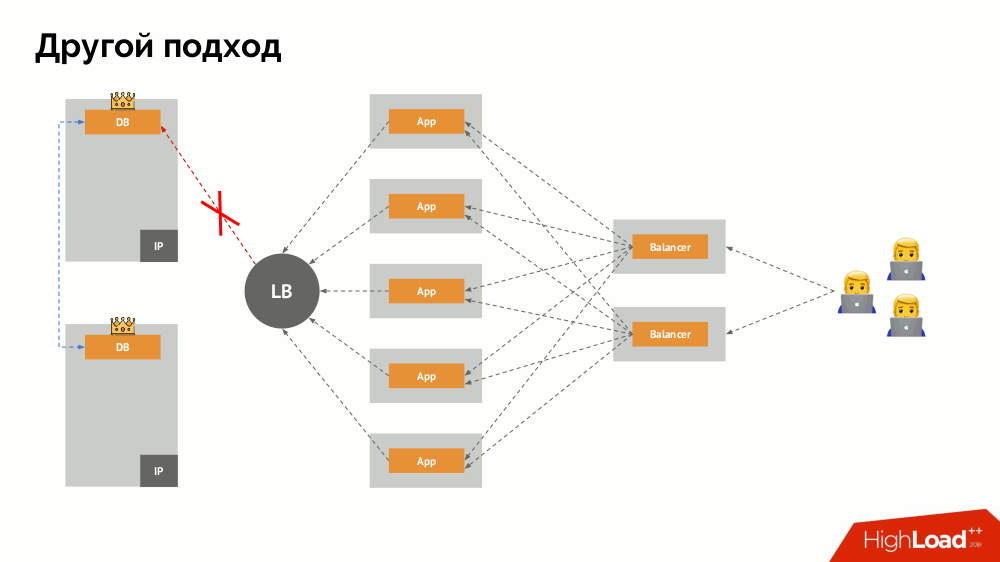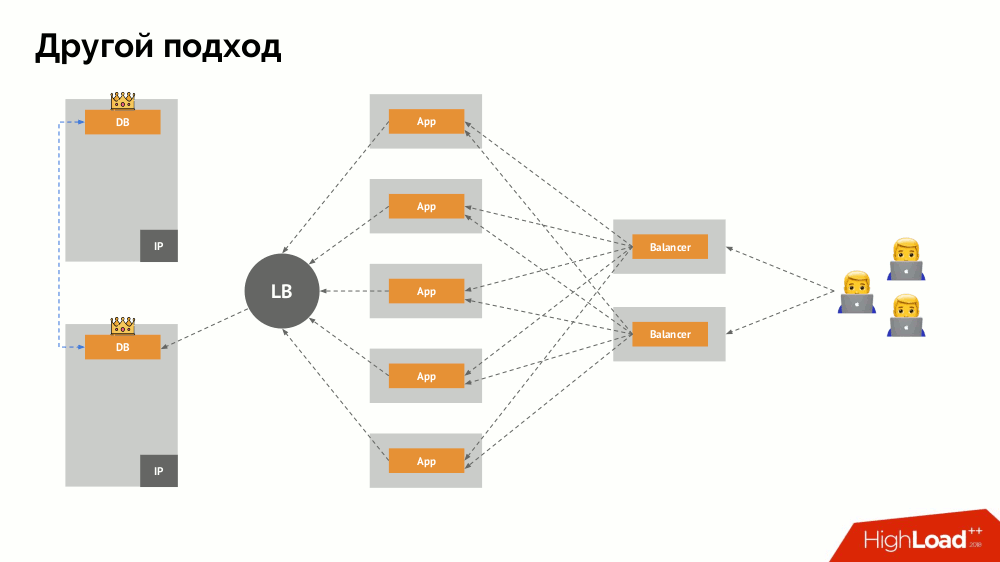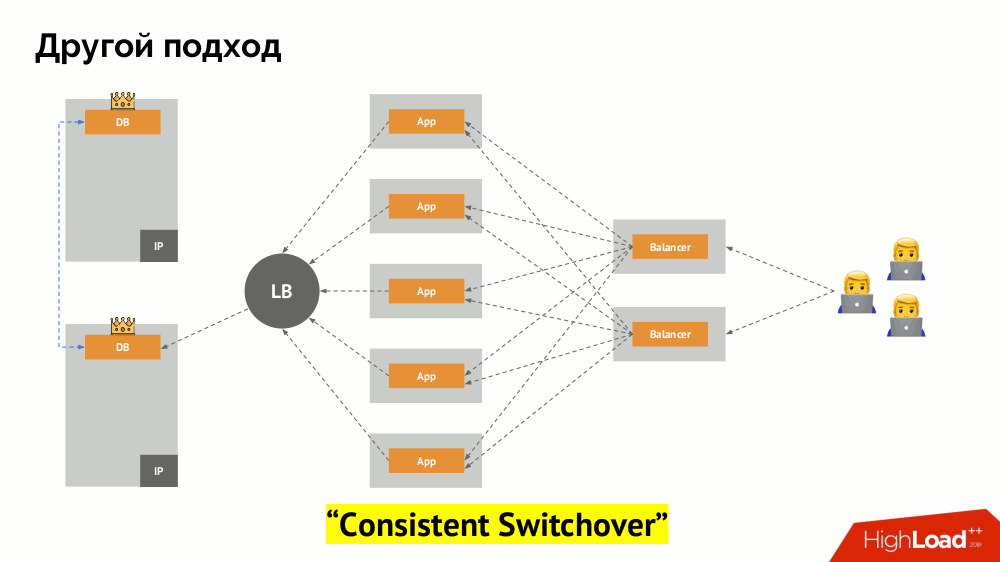
Pertanyaan utama bersamanya adalah bagaimana membuatnya universal, memberikan dukungan untuk penyedia cloud dan instalasi pribadi. Untuk ini, server proxy ditambahkan ke aplikasi. Masing-masing dari mereka akan menerima permintaan dari aplikasinya (dan meneruskannya ke DBMS), dan kuorum akan dikumpulkan dari semuanya. Segera setelah beberapa bagian gugus gagal, proksi yang kehilangan kuorum segera menghapus koneksi mereka ke DBMS.
3. Penyimpanan Data dan Kubernet
Mekanisme utamanya adalah drive jaringan
Network Block Device (alias SAN) dalam berbagai implementasi untuk opsi cloud yang diinginkan atau bare metal. Namun, menempatkan basis data yang dimuat (misalnya, MySQL, yang membutuhkan 50 ribu IOPS) ke cloud (AWS EBS) tidak akan berfungsi karena
latensi .
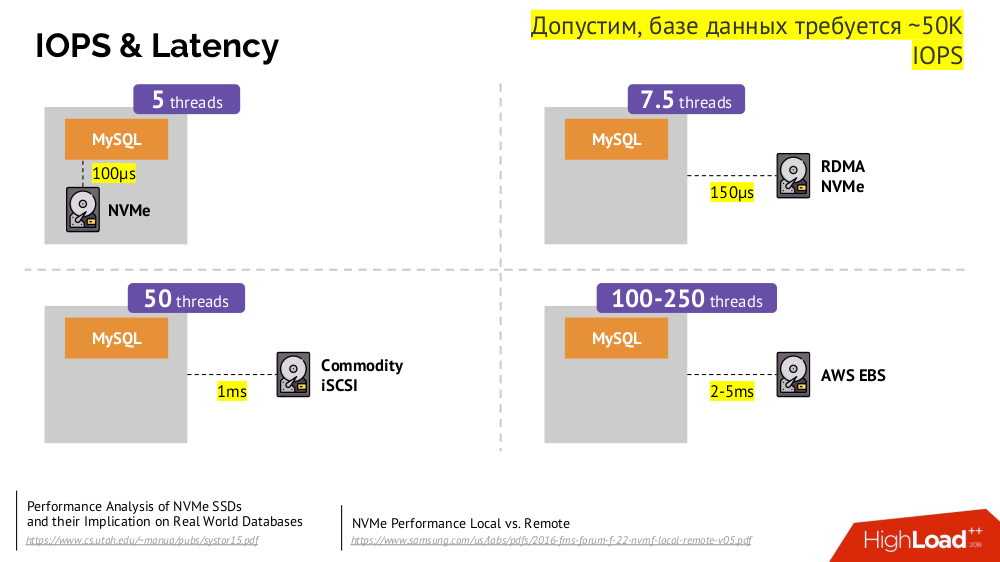
Kubernetes untuk kasus semacam itu memiliki kemampuan untuk menghubungkan hard drive
lokal -
Penyimpanan Lokal . Jika terjadi kegagalan (disk tidak lagi tersedia di pod), maka kami terpaksa memperbaiki mesin ini - mirip dengan skema klasik jika terjadi kegagalan satu server yang dapat diandalkan.
Kedua opsi (
Perangkat Blok Jaringan dan
Penyimpanan Lokal ) milik kategori
ReadWriteOnce : penyimpanan tidak dapat dipasang di dua tempat (pod) - untuk penskalaan ini, Anda harus membuat disk baru dan menghubungkannya ke pod baru (ada mekanisme K8 bawaan untuk ini) , dan kemudian isi dengan data yang diperlukan (sudah dilakukan oleh pasukan kami).
Jika kita memerlukan mode
ReadWriteMany , maka implementasi
Network File System (atau NAS) tersedia: untuk cloud publik ini adalah
AzureFile dan
AWSElasticFileSystem , dan untuk instalasi mereka CephFS dan Glusterfs untuk penggemar sistem terdistribusi, serta NFS.

Berlatih
1. Standalone
Opsi ini adalah tentang kasus ketika tidak ada yang mencegah Anda memulai DBMS dalam mode server terpisah dengan penyimpanan lokal. Tidak ada pertanyaan tentang ketersediaan tinggi ... meskipun dapat sampai batas tertentu (mis., Cukup untuk aplikasi ini) diimplementasikan pada tingkat besi. Ada banyak kasus untuk aplikasi ini. Pertama-tama, ini semua jenis lingkungan pementasan dan pengembangan, tetapi tidak hanya: layanan sekunder juga jatuh di sini, menonaktifkannya selama 15 menit tidak kritis. Di Kubernetes, ini diterapkan oleh
StatefulSet dengan satu pod:
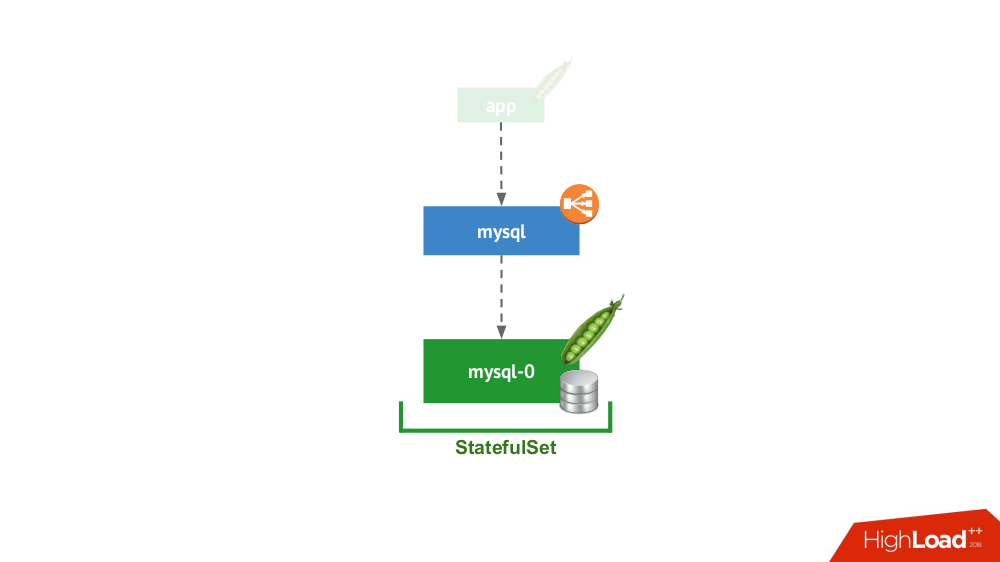
Secara umum, ini adalah opsi yang layak, yang, dari sudut pandang saya, tidak memiliki kekurangan dibandingkan dengan menginstal DBMS pada mesin virtual yang terpisah.
2. Pasangan yang direplikasi dengan perpindahan manual
StatefulSet digunakan lagi, tetapi skema umum terlihat seperti ini:
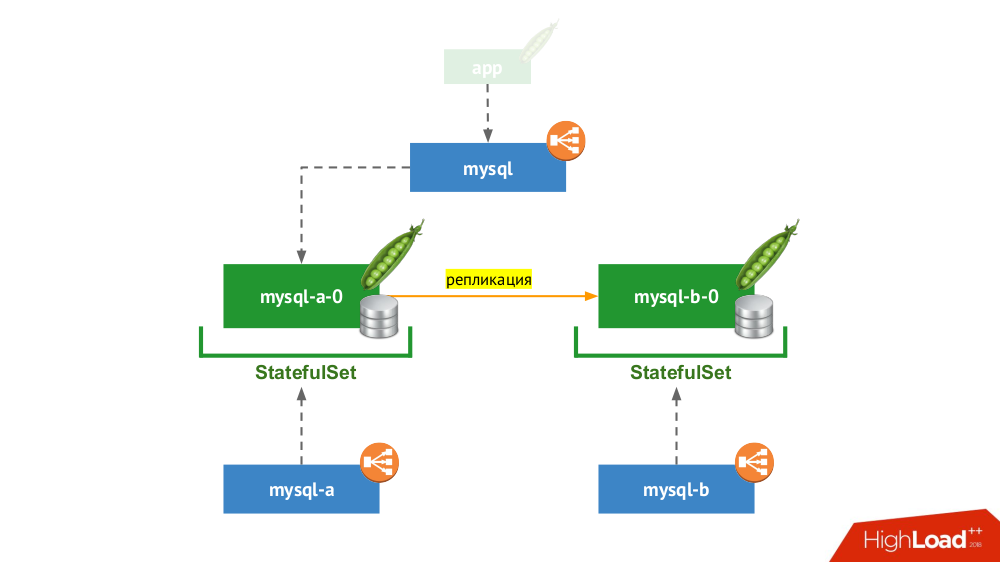
Jika salah satu node mogok (
mysql-a-0 ), keajaiban tidak terjadi, tetapi kami memiliki replika (
mysql-b-0 ) yang dapat digunakan untuk mengalihkan lalu lintas. Dalam hal ini, bahkan sebelum mengalihkan lalu lintas, penting untuk tidak lupa tidak hanya menghapus permintaan DBMS dari layanan
mysql , tetapi juga untuk masuk ke DBMS secara manual dan memastikan bahwa semua koneksi selesai (bunuh), dan juga pergi ke simpul kedua dari DBMS dan konfigurasikan ulang replika dalam arah yang berlawanan.
Jika Anda saat ini menggunakan versi klasik dengan dua server (master + standby) tanpa
failover otomatis, maka solusi ini setara dengan di Kubernetes. Cocok untuk MySQL, PostgreSQL, Redis dan produk lainnya.
3. Penskalaan beban baca
Faktanya, kasus ini tidak bersifat negara, karena kita hanya berbicara tentang membaca. Di sini, server DBMS utama berada di luar skema yang dipertimbangkan, dan dalam kerangka Kubernetes, "server server slave" dibuat, yang hanya-baca. Mekanisme umum - penggunaan wadah init untuk mengisi data DBMS pada setiap pod baru di tambak ini (menggunakan hot dump atau yang biasa dengan tindakan tambahan, dll. - tergantung pada DBMS yang digunakan). Untuk memastikan bahwa setiap instance tidak ketinggalan terlalu jauh dari master, Anda dapat menggunakan tes liveness.

4. Klien yang cerdas
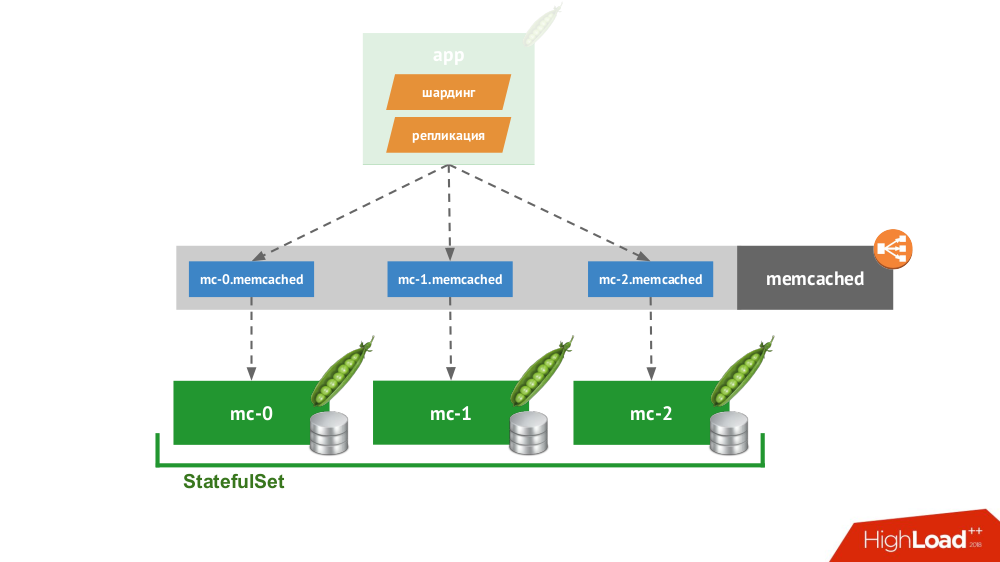
Jika Anda membuat
StatefulSet dengan tiga memcached, Kubernetes memiliki layanan khusus yang tidak akan menyeimbangkan permintaan, tetapi akan membuat setiap pod untuk domainnya sendiri. Klien akan dapat bekerja dengan mereka jika dia sendiri mampu sharding dan replikasi.
Anda tidak perlu melangkah jauh untuk contoh: ini adalah cara penyimpanan sesi bekerja dalam PHP di luar kotak. Untuk setiap permintaan sesi, permintaan dilakukan secara bersamaan ke semua server, setelah itu jawaban yang paling relevan dipilih dari mereka (mirip dengan catatan).
5. Solusi Cloud Asli
Ada banyak solusi yang awalnya berfokus pada kegagalan node, yaitu mereka sendiri dapat melakukan
failover dan pemulihan node, memberikan jaminan
konsistensi . Ini bukan daftar lengkap dari mereka, tetapi hanya bagian dari contoh populer:

Semuanya ditempatkan di
StatefulSet , setelah itu node saling menemukan dan membentuk sebuah cluster. Produk itu sendiri berbeda dalam bagaimana mereka menerapkan tiga hal:
- Bagaimana simpul belajar tentang satu sama lain? Ada metode seperti API Kubernetes, catatan DNS, konfigurasi statis, node khusus (seed), penemuan layanan pihak ketiga ...
- Bagaimana cara klien terhubung? Melalui load balancer yang mendistribusikan ke host, atau klien perlu tahu tentang semua host, dan ia akan memutuskan bagaimana untuk melanjutkan.
- Bagaimana penskalaan horizontal dilakukan? Tidak mungkin, penuh atau sulit / dengan batasan.
Terlepas dari solusi yang dipilih untuk masalah ini, semua produk tersebut bekerja dengan baik dengan Kubernetes, karena mereka awalnya diciptakan sebagai "
ternak" .
6. Stolon PostgreSQL
Stolon sebenarnya memungkinkan Anda untuk mengubah PostgreSQL, yang dibuat sebagai
hewan peliharaan , menjadi
ternak . Bagaimana ini dicapai?
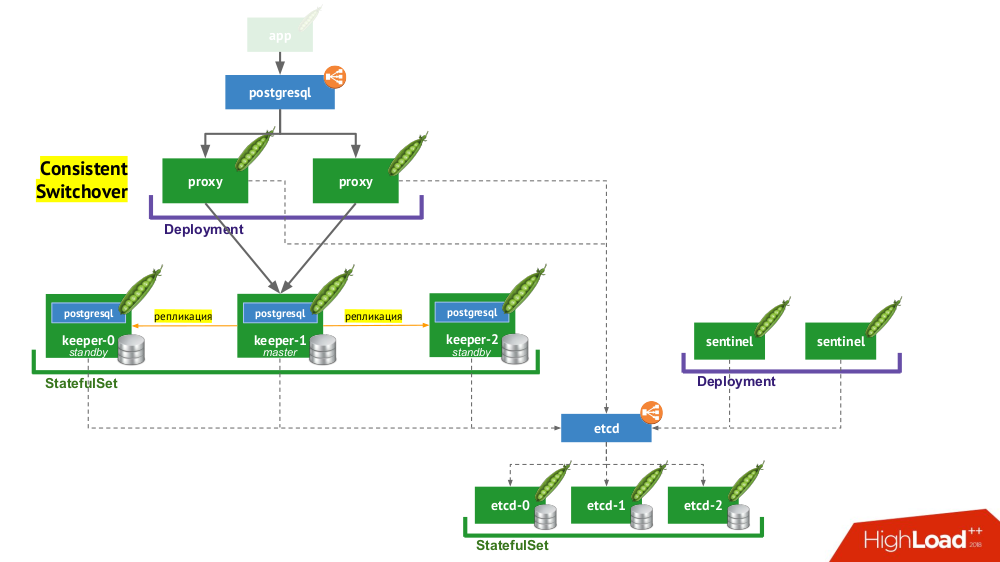
- Pertama, kita membutuhkan penemuan layanan, yang perannya mungkin etcd (opsi lain tersedia) - sekelompok dari mereka ditempatkan di
StatefulSet . - Bagian lain dari infrastruktur adalah
StatefulSet dengan instance PostgreSQL. Selain DBMS yang tepat, di sebelah setiap instalasi juga ada komponen yang disebut keeper , yang melakukan konfigurasi DBMS. - Komponen lain, sentinel, digunakan sebagai
Deployment dan memonitor konfigurasi cluster. Dialah yang memutuskan siapa yang akan menjadi tuan dan siaga, menulis informasi ini ke etcd. Dan penjaga membaca data dari etcd dan melakukan tindakan yang sesuai dengan status saat ini dengan turunan dari PostgreSQL. - Komponen lain yang digunakan dalam
Deployment dan menghadapi instance PostgreSQL, proxy, adalah implementasi dari pola Peralihan Konsisten yang telah disebutkan sebelumnya. Komponen-komponen ini terhubung ke etcd, dan jika koneksi ini hilang, proksi segera membunuh koneksi keluar, karena sejak saat itu ia tidak tahu peran servernya (apakah sekarang master atau standby?). - Akhirnya, instance proxy menghadapi
LoadBalancer LoadBalancer yang biasa.
Kesimpulan
Jadi apakah mungkin untuk berbasis di Kubernet? Ya, tentu saja, itu mungkin, dalam beberapa kasus ... Dan jika sesuai, itu dilakukan seperti ini (lihat alur kerja Stolon) ...
Semua orang tahu bahwa teknologi berkembang dalam gelombang. Awalnya, setiap perangkat baru bisa sangat sulit digunakan, tetapi seiring waktu, semuanya berubah: teknologi menjadi tersedia. Kemana kita akan pergi Ya, itu akan tetap ada di dalam, tetapi kami tidak akan tahu cara kerjanya. Kubernetes secara aktif mengembangkan
operator . Sejauh ini tidak ada banyak dari mereka dan mereka tidak begitu baik, tetapi ada gerakan ke arah ini.
Video dan slide
Video dari kinerja (sekitar satu jam):
Penyajian laporan:
PS Kami juga menemukan di internet sangat singkat (!)
Pemerasan tekstual dari laporan ini - terima kasih untuk itu untuk Nikolai Volynkin.
PPS
Laporan lain di blog kami:
Anda mungkin juga tertarik dengan publikasi berikut: