Ceph adalah penyimpanan objek yang dirancang untuk membantu membangun kluster failover. Tetap saja, kegagalan bisa terjadi. Setiap orang yang bekerja dengan Ceph tahu legenda tentang CloudMouse atau Rosreestr. Sayangnya, tidak lazim untuk berbagi pengalaman negatif dengan kami, penyebab kegagalan paling sering ditutup-tutupi, dan tidak memungkinkan generasi mendatang untuk belajar dari kesalahan orang lain.
Baiklah, mari kita buat gugus uji, tetapi dekat dengan yang asli, dan menganalisis bencana dengan tulang. Kami akan mengukur semua penarikan kinerja, menemukan kebocoran memori, dan menganalisis proses pemulihan layanan. Dan semua ini di bawah kepemimpinan Artemy Kapitula, yang menghabiskan hampir satu tahun mempelajari jebakan, menyebabkan kinerja cluster gagal nol dan latensi tidak melompat ke nilai tidak senonoh. Dan saya mendapat grafik merah, yang jauh lebih baik.
Selanjutnya, Anda akan menemukan versi video dan teks dari salah satu laporan terbaik
DevOpsConf Russia 2018.
Tentang pembicara: Arsitek sistem Artemy Kapitula RCNTEC. Perusahaan ini menawarkan solusi IP telephony (kolaborasi, organisasi kantor jarak jauh, sistem penyimpanan yang ditentukan perangkat lunak, dan sistem manajemen / distribusi daya). Perusahaan ini terutama bekerja di sektor perusahaan, oleh karena itu tidak terlalu terkenal di pasar DevOps. Namun demikian, beberapa pengalaman telah diakumulasikan dengan Ceph, yang dalam banyak proyek digunakan sebagai elemen dasar dari infrastruktur penyimpanan.
Ceph adalah repositori yang ditentukan perangkat lunak dengan banyak komponen perangkat lunak.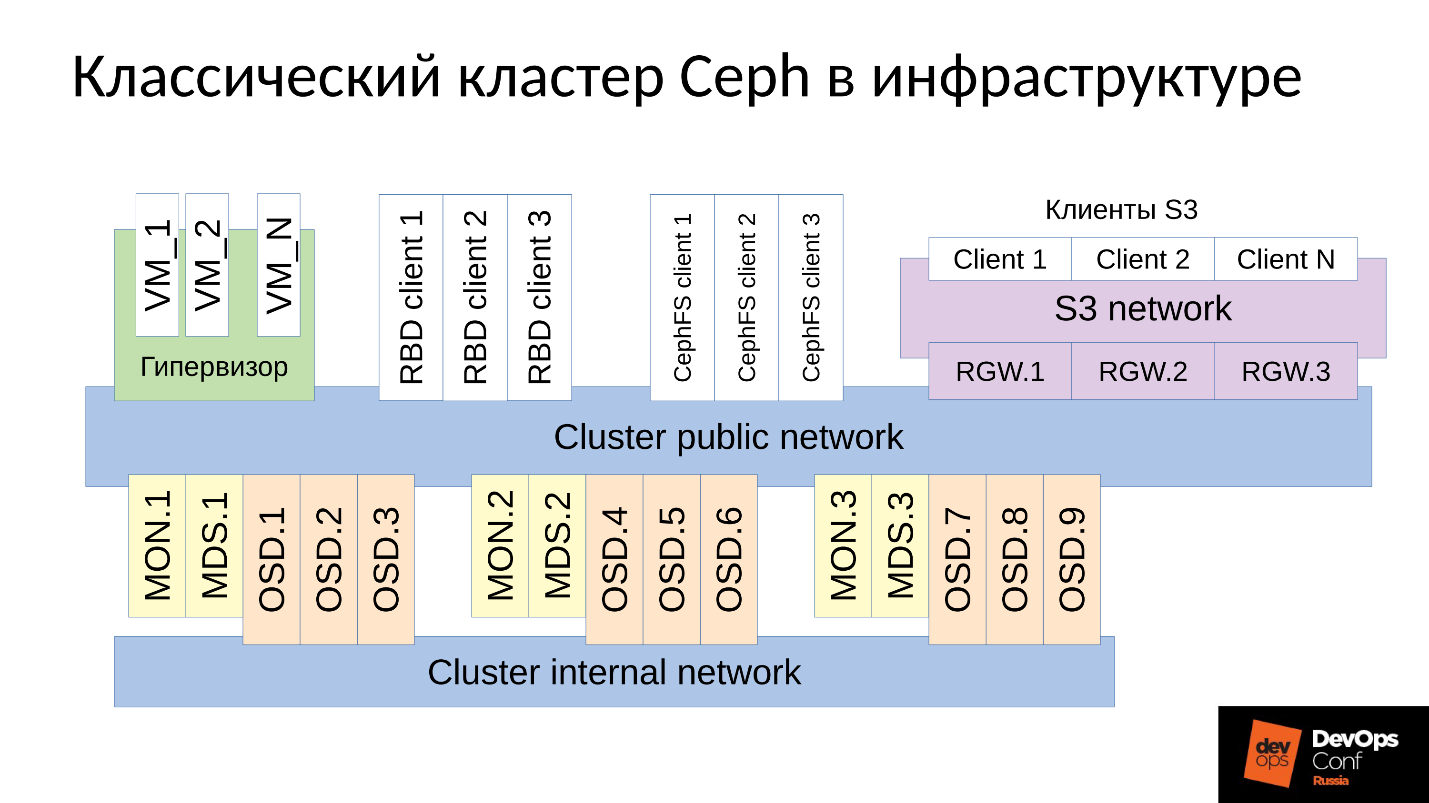
Dalam diagram:
- Level atas adalah jaringan cluster internal yang digunakan oleh cluster itu sendiri untuk berkomunikasi;
- Level bawah - sebenarnya Ceph - adalah seperangkat daemon Ceph internal (MON, MDS, dan OSD) yang menyimpan data.
Semua data, sebagai aturan, direplikasi. Dalam diagram, saya sengaja memilih tiga kelompok, masing-masing dengan tiga OSD, dan masing-masing kelompok ini biasanya berisi satu replika data. Akibatnya, data disimpan dalam tiga salinan.
Jaringan kluster tingkat yang lebih tinggi adalah jaringan yang melaluinya klien Ceph mengakses data. Melalui itu, klien berkomunikasi dengan monitor, dengan MDS (siapa yang membutuhkannya) dan dengan OSD. Setiap klien bekerja dengan masing-masing OSD dan dengan setiap monitor secara independen. Oleh karena itu,
sistem ini tidak memiliki satu titik kegagalan , yang sangat menyenangkan.
Pelanggan
● pelanggan S3
S3 adalah API untuk HTTP. Klien S3 bekerja melalui HTTP dan terhubung ke komponen Ceph Rados Gateway (RGW). Mereka hampir selalu berkomunikasi dengan komponen melalui jaringan khusus. Jaringan ini (saya menyebutnya jaringan S3) hanya menggunakan HTTP, pengecualian jarang.
● Hypervisor dengan mesin virtual
Kelompok pelanggan ini sering digunakan. Mereka bekerja dengan monitor dan dengan OSD, dari mana mereka menerima informasi umum tentang status cluster dan distribusi data. Untuk data, klien ini langsung pergi ke daemon OSD melalui jaringan publik Cluster.
● klien RBD
Ada juga host logam BR fisik, yang biasanya Linux. Mereka adalah klien RBD dan mendapatkan akses ke gambar yang disimpan di dalam cluster Ceph (gambar disk mesin virtual).
● klien CephFS
Kelompok keempat klien, yang masih belum banyak, tetapi semakin menarik, adalah klien sistem file CephFS cluster. Sistem cluster CephFS dapat dipasang secara bersamaan dari banyak node, dan semua node mendapatkan akses ke data yang sama, bekerja dengan masing-masing OSD. Artinya, tidak ada Gateway seperti itu (Samba, NFS dan lain-lain). Masalahnya adalah klien seperti itu hanya bisa Linux, dan versi yang cukup modern.

Perusahaan kami bekerja di pasar korporat, dan di sana bola dikuasai oleh ESXi, HyperV, dan lainnya. Oleh karena itu, cluster Ceph, yang entah bagaimana digunakan di sektor korporasi, diperlukan untuk mendukung teknik yang sesuai. Ini tidak cukup bagi kami di Ceph, jadi kami harus memperbaiki dan memperluas cluster Ceph dengan komponen kami, bahkan membangun sesuatu yang lebih dari Ceph, platform kami sendiri untuk menyimpan data.
Selain itu, pelanggan di sektor korporasi tidak di Linux, tetapi kebanyakan dari mereka Windows, kadang-kadang Mac OS, tidak dapat pergi ke cluster Ceph sendiri. Mereka harus melalui semacam gateway, yang dalam hal ini menjadi kemacetan.
Kami harus menambahkan semua komponen ini, dan kami mendapat klaster yang sedikit lebih luas.

Kami memiliki dua komponen utama:
grup Gateway SCSI , yang menyediakan akses ke data dalam cluster Ceph melalui FibreChannel atau iSCSI. Komponen-komponen ini digunakan untuk menghubungkan HyperV dan ESXi ke cluster Ceph. Pelanggan PROXMOX masih bekerja dengan caranya sendiri - melalui RBD.
Kami tidak membiarkan klien file langsung ke jaringan cluster, beberapa Gateway toleran-kesalahan dialokasikan untuk mereka. Setiap Gateway menyediakan akses ke sistem cluster file melalui NFS, AFP, atau SMB. Dengan demikian, hampir semua klien, apakah itu Linux, FreeBSD atau bukan hanya klien, server (OS X, Windows), mendapat akses ke CephFS.
Untuk mengelola semua ini, kami harus benar-benar mengembangkan orkestra Ceph kami sendiri dan semua komponen kami, yang jumlahnya banyak di sana. Tetapi membicarakannya sekarang tidak masuk akal, karena ini adalah perkembangan kita. Sebagian besar mungkin akan tertarik pada "telanjang" Ceph itu sendiri.
Ceph banyak digunakan di mana, dan kadang-kadang terjadi kegagalan. Tentunya semua orang yang bekerja dengan Ceph tahu legenda tentang CloudMouse. Ini adalah legenda urban yang mengerikan, tetapi semuanya tidak begitu buruk di sana seperti yang terlihat. Ada dongeng baru tentang Rosreestr. Ceph berputar di mana-mana, dan di mana-mana itu gagal. Di suatu tempat itu berakhir fatal, di suatu tempat berhasil dengan cepat menghilangkan konsekuensinya.
Sayangnya, tidak lazim bagi kami untuk berbagi pengalaman negatif, semua orang berusaha menyembunyikan informasi yang relevan. Perusahaan asing sedikit lebih terbuka, khususnya DigitalOcean (penyedia terkenal yang mendistribusikan mesin virtual) juga mengalami kegagalan Ceph selama hampir satu hari, yaitu 1 April - hari yang indah! Mereka memposting beberapa laporan, log pendek di bawah ini.

Masalahnya dimulai pukul 7 pagi, jam 11 mereka mengerti apa yang terjadi, dan mulai menghilangkan kegagalan. Untuk melakukan ini, mereka mengalokasikan dua perintah: satu karena beberapa alasan berlari di sekitar server dan memasang memori di sana, dan yang kedua untuk beberapa alasan secara manual memulai satu server demi satu dan dengan hati-hati memonitor semua server. Mengapa Kita semua terbiasa dengan semua yang dihidupkan dengan satu klik.
Apa yang pada dasarnya terjadi dalam sistem terdistribusi ketika sistem itu secara efektif dibangun dan bekerja hampir pada batas kemampuannya?Untuk menjawab pertanyaan ini, kita perlu melihat bagaimana cluster Ceph bekerja dan bagaimana kegagalan terjadi.

Skenario Kegagalan Ceph
Pada awalnya, cluster berfungsi dengan baik, semuanya berjalan dengan baik. Kemudian sesuatu terjadi, setelah itu daemon OSD, tempat data disimpan, kehilangan kontak dengan komponen pusat dari cluster (monitor). Pada titik ini, batas waktu terjadi dan seluruh kluster mendapat taruhan. Cluster berdiri untuk sementara sampai menyadari bahwa ada sesuatu yang salah dengan itu, dan setelah itu mengoreksi pengetahuan internalnya. Setelah itu, layanan pelanggan dipulihkan sampai batas tertentu, dan gugus kembali bekerja dalam mode terdegradasi. Dan lucunya adalah ia bekerja lebih cepat daripada dalam mode normal - ini adalah fakta yang luar biasa.
Maka kita menghilangkan kegagalan itu. Misalkan kita kehilangan daya, rak itu benar-benar dipotong. Listrik datang berjalan, mereka semua pulih, mereka memasok daya, server dihidupkan dan kemudian
kesenangan dimulai .
Semua orang terbiasa dengan fakta bahwa ketika server gagal, semuanya menjadi buruk, dan ketika kita menghidupkan server, semuanya menjadi baik. Semuanya benar-benar salah di sini.
Cluster praktis berhenti, melakukan sinkronisasi primer, dan kemudian memulai pemulihan yang lancar dan lambat, secara bertahap kembali ke mode normal.

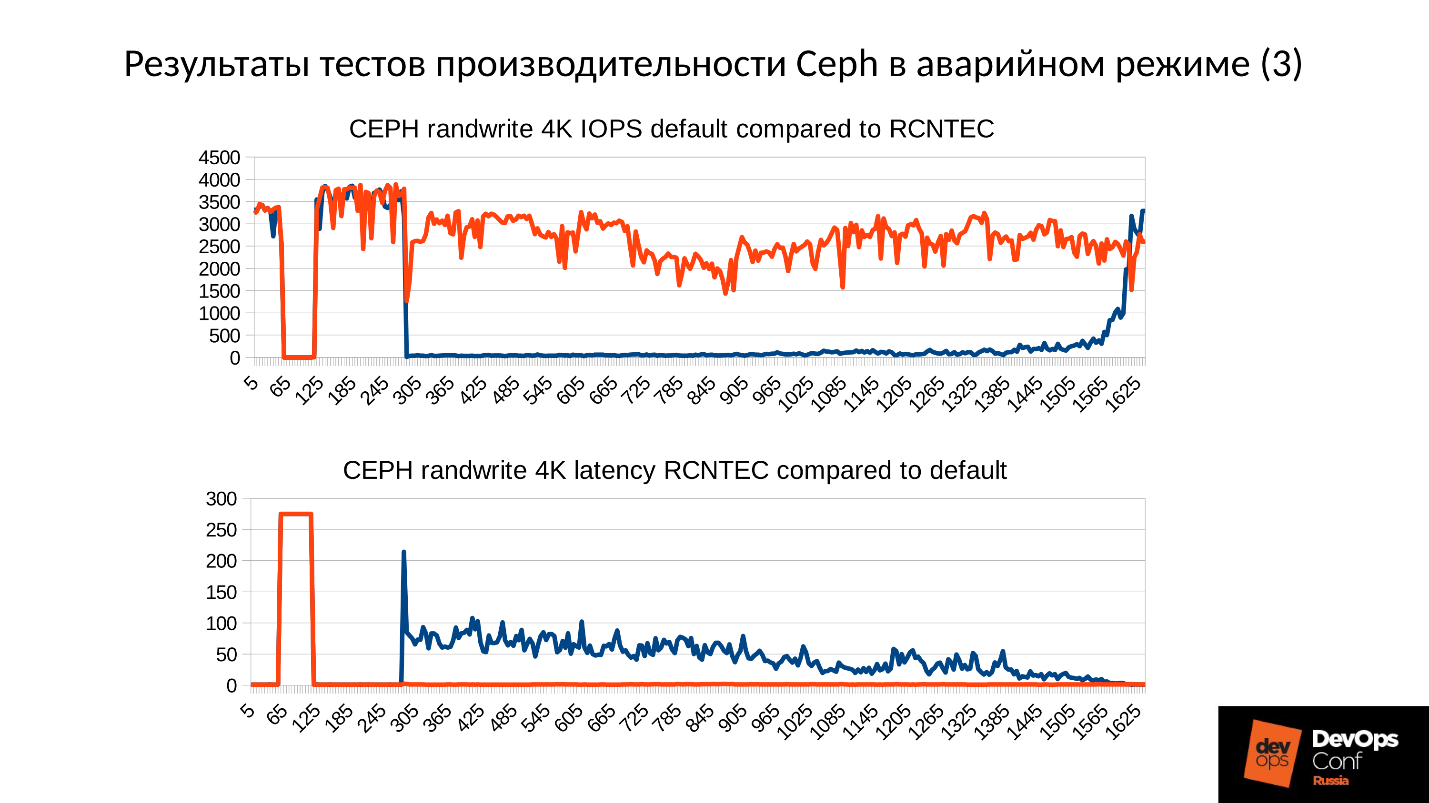
Di atas adalah grafik kinerja cluster Ceph sebagai kegagalan berkembang. Harap perhatikan bahwa di sini interval yang kami bicarakan sangat jelas dilacak:
- Pengoperasian normal hingga sekitar 70 detik;
- Kegagalan selama satu menit hingga sekitar 130 detik;
- Sebuah dataran tinggi yang terasa lebih tinggi dari operasi normal adalah pekerjaan dari cluster terdegradasi;
- Kemudian kita nyalakan simpul yang hilang - ini adalah cluster pelatihan, hanya ada 3 server dan 15 SSD. Kami memulai server di suatu tempat sekitar 260 detik.
- Server dihidupkan, memasuki cluster - IOPS'y jatuh.
Mari kita coba mencari tahu apa yang sebenarnya terjadi di sana. Hal pertama yang menarik minat kami adalah penurunan di awal grafik.
Kegagalan OSD
Pertimbangkan contoh cluster dengan tiga rak, beberapa node di masing-masing. Jika rak kiri gagal, semua daemon OSD (bukan host!) Ping sendiri dengan pesan Ceph pada interval tertentu. Jika ada beberapa pesan yang hilang, sebuah pesan dikirim ke monitor: "Saya, OSD begini dan begitu, tidak dapat mencapai OSD begini dan begini."

Dalam hal ini, pesan biasanya dikelompokkan berdasarkan host, yaitu, jika dua pesan dari OSD yang berbeda tiba di host yang sama, mereka digabungkan menjadi satu pesan. Dengan demikian, jika OSD 11 dan OSD 12 melaporkan bahwa mereka tidak dapat mencapai OSD 1, ini akan ditafsirkan sebagai Host 11 mengeluh tentang OSD 1. Ketika OSD 21 dan OSD 22 dilaporkan, ia ditafsirkan sebagai Host 21 tidak puas dengan OSD 1 Setelah itu monitor menganggap bahwa OSD 1 berada dalam kondisi turun dan memberi tahu semua anggota cluster (dengan mengubah peta OSD), pekerjaan berlanjut dalam mode terdegradasi.
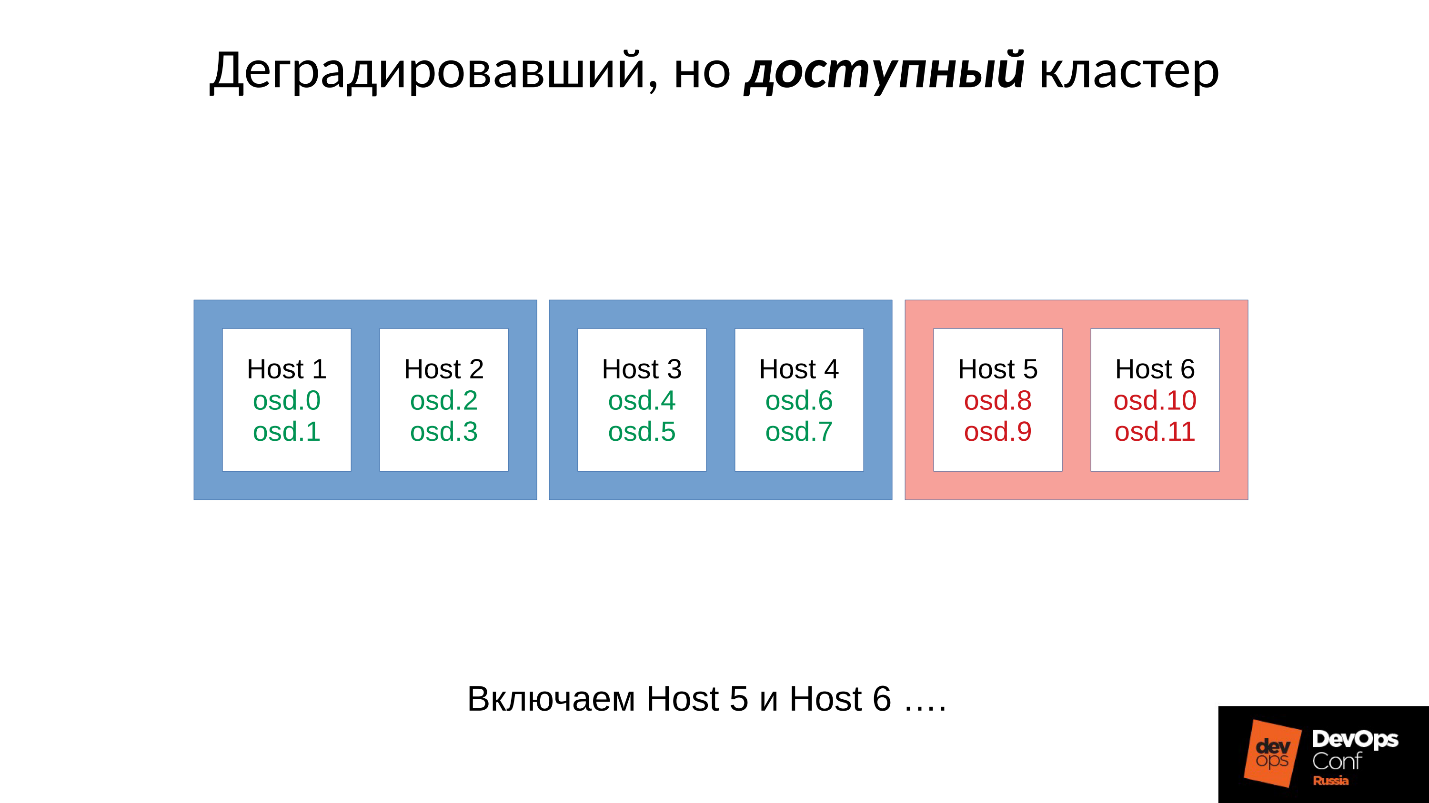
Jadi, inilah rak kami dan rak gagal (Host 5 dan Host 6). Kami menyalakan Host 5 dan Host 6, saat daya muncul, dan ...
Perilaku internal Ceph
Dan sekarang bagian yang paling menarik adalah kita memulai
sinkronisasi data awal . Karena ada banyak replika, mereka harus sinkron dan berada di versi yang sama. Dalam proses memulai OSD mulai:
- OSD membaca versi yang tersedia, riwayat yang tersedia (pg_log - untuk menentukan versi objek saat ini).
- Setelah itu menentukan OSD mana versi terbaru dari objek terdegradasi (missing_loc) aktif, dan yang di belakang.
- Di mana versi mundur disimpan, sinkronisasi diperlukan, dan versi baru dapat digunakan sebagai referensi untuk membaca dan menulis data.
Sebuah cerita digunakan yang dikumpulkan dari semua OSD, dan cerita ini bisa sangat banyak; lokasi sebenarnya dari set objek di cluster di mana versi yang sesuai berada ditentukan. Berapa banyak objek dalam cluster, berapa banyak catatan yang diperoleh, jika cluster telah berdiri lama dalam mode terdegradasi, maka ceritanya panjang.
Sebagai perbandingan: ukuran tipikal sebuah objek saat kami bekerja dengan gambar RBD adalah 4 MB. Ketika kami bekerja dalam penghapusan kode - 1MB. Jika kami memiliki disk 10 TB, kami mendapatkan sejuta megabyte objek di disk. Jika kita memiliki 10 disk di server, maka sudah ada 10 juta objek, jika ada 32 disk (kami sedang membangun cluster yang efisien, kami memiliki alokasi yang ketat), maka 32 juta objek harus disimpan dalam memori. Selain itu, pada kenyataannya, informasi tentang setiap objek disimpan dalam beberapa salinan, karena setiap salinan menunjukkan bahwa di tempat ini terletak di versi ini, dan ini - di sini.
Ternyata sejumlah besar data, yang terletak di RAM:
- semakin banyak objek, semakin besar sejarah missing_loc;
- semakin banyak PG - semakin banyak pg_log dan peta OSD;
sebagai tambahan:
- semakin besar ukuran disk;
- semakin tinggi kepadatan (jumlah disk di setiap server);
- semakin tinggi beban pada cluster dan semakin cepat cluster Anda;
- semakin lama OSD turun (dalam kondisi Offline);
dengan kata lain, semakin
curam cluster yang kami bangun, dan semakin lama bagian cluster tidak merespons, semakin banyak RAM yang dibutuhkan saat startup .
Optimalisasi ekstrim adalah akar dari semua kejahatan
"... dan OOM hitam datang ke anak laki-laki dan perempuan jahat di malam hari dan membunuh semua proses kiri dan kanan"
Legenda sysadmin kota
Jadi, RAM membutuhkan banyak, konsumsi memori tumbuh (kami mulai segera di sepertiga dari cluster) dan sistem secara teori dapat masuk ke SWAP, jika Anda membuatnya tentu saja. Saya pikir ada banyak orang yang berpikir bahwa SWAP itu buruk dan mereka tidak menciptakannya: “Mengapa? Kami memiliki banyak memori! " Tapi ini pendekatan yang salah.
Jika file SWAP belum dibuat sebelumnya, karena diputuskan bahwa Linux akan bekerja lebih efisien, maka cepat atau lambat akan terjadi kehabisan memori pembunuh (OOM-killer). Dan bukan fakta bahwa itu akan membunuh orang yang memakan semua memori, bukan orang yang pertama kali sial. Kami tahu apa lokasi yang optimis - kami meminta memori, mereka menjanjikannya kepada kami, kami mengatakan: "Sekarang beri kami satu", sebagai tanggapan: "Tapi tidak!" - dan keluar dari memory killer.
Ini adalah pekerjaan Linux biasa, kecuali jika dikonfigurasi di area memori virtual.
Proses keluar dari memory killer dan jatuh dengan cepat dan tanpa ampun. Lagipula, tidak ada proses lain yang dia mati tidak tahu. Dia tidak punya waktu untuk memberi tahu siapa pun tentang sesuatu, mereka hanya menghentikannya.
Maka prosesnya, tentu saja, akan dimulai kembali - kita memiliki systemd, itu juga meluncurkan, jika perlu, OSD yang telah jatuh. OSD yang jatuh mulai, dan ... reaksi berantai dimulai.
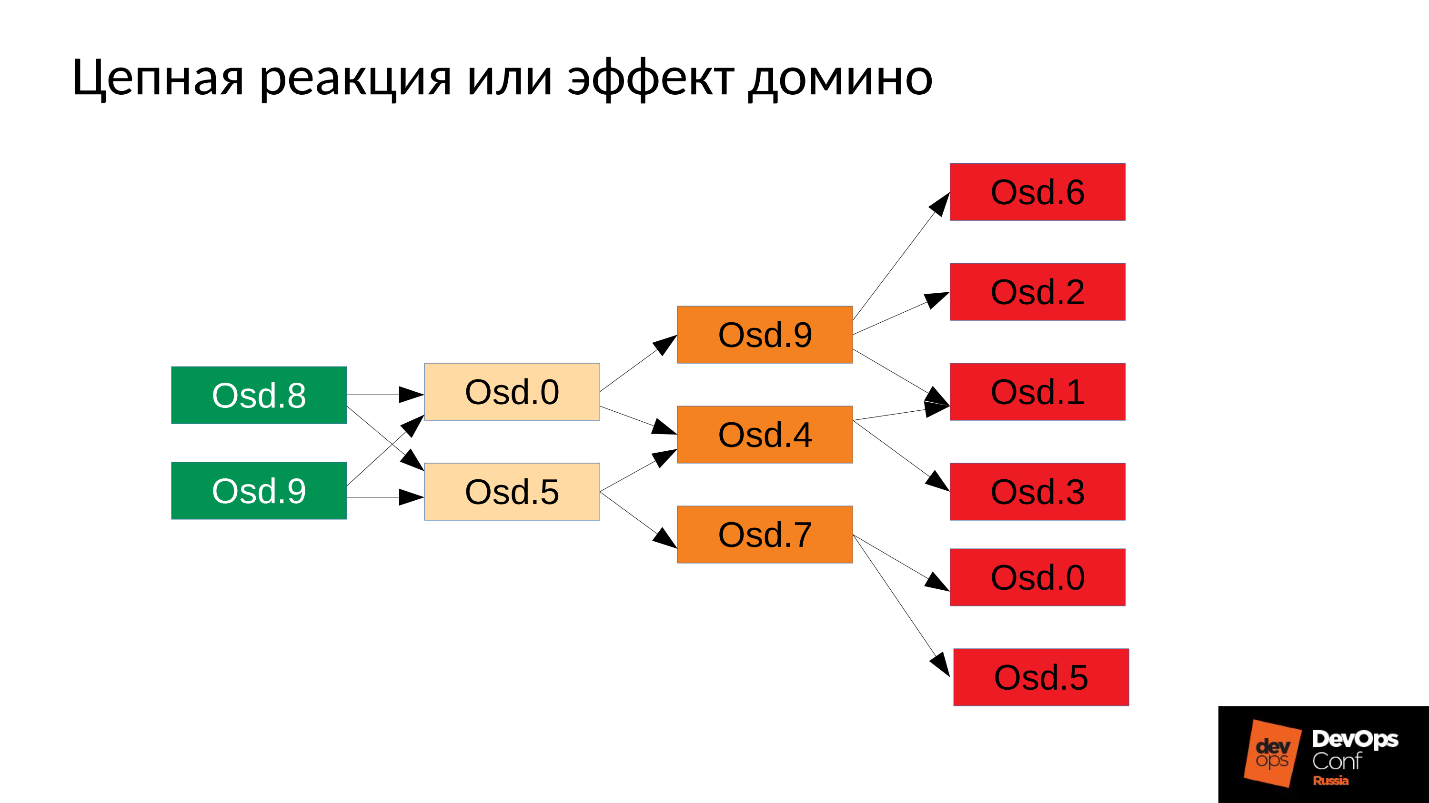
Dalam kasus kami, kami memulai OSD 8 dan OSD 9, mereka mulai menghancurkan segalanya, tetapi tidak beruntung OSD 0 dan OSD 5. Pembunuh kehabisan memori terbang ke mereka dan menghentikan mereka. Mereka memulai kembali - mereka membaca data mereka, mulai menyinkronkan dan menghancurkan sisanya. Tiga lagi sial (OSD 9, OSD 4 dan OSD 7). Ketiganya dimulai kembali, mulai memberi tekanan pada seluruh cluster, paket berikutnya adalah sial.
Gugusan mulai berantakan secara harfiah di depan mata kita . Degradasi terjadi dengan sangat cepat, dan "sangat cepat" ini biasanya dinyatakan dalam menit, maksimum puluhan menit. Jika Anda memiliki 30 node (10 node per rak), dan kurangi rak karena kegagalan daya - setelah 6 menit, setengah dari cluster terletak.
Jadi, kami mendapat sesuatu seperti berikut ini.
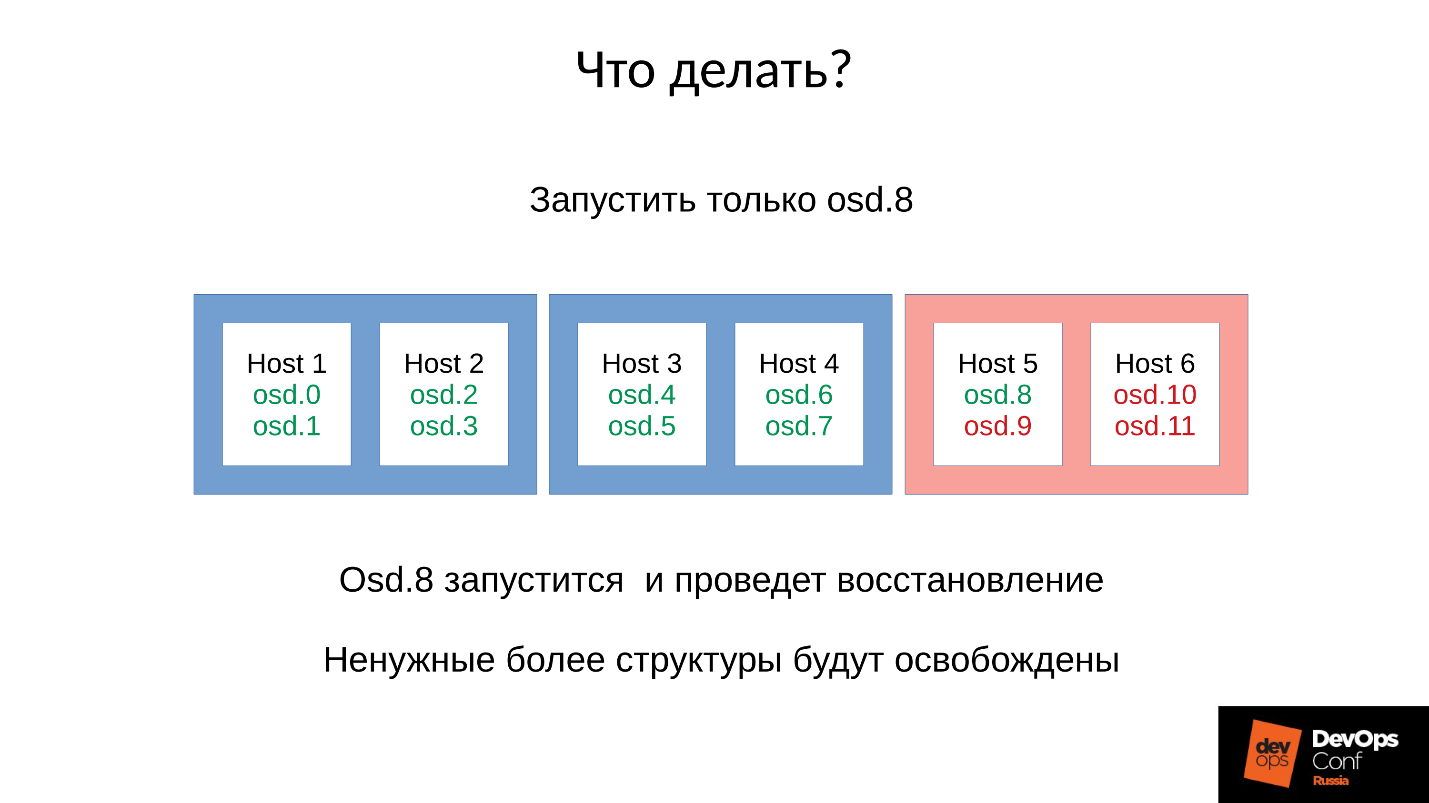
Di hampir setiap server, kami memiliki OSD yang gagal. Dan jika pada setiap server, yaitu, di setiap domain kegagalan yang kami miliki untuk OSD yang gagal, maka
sebagian besar data kami tidak dapat diakses . Setiap permintaan diblokir - untuk ditulis, untuk dibaca - tidak ada bedanya. Itu saja! Kami bangun.
Apa yang harus dilakukan dalam situasi seperti itu? Lebih tepatnya,
apa yang harus dilakukan ?
Jawaban: Jangan memulai cluster segera, yaitu, seluruh rak, tetapi hati-hati mengangkat satu setan masing-masing.
Tapi kami tidak tahu itu. Kami segera mulai, dan mendapatkan apa yang kami dapatkan. Dalam hal ini, kami meluncurkan salah satu dari empat daemon (8, 9, 10, 11), konsumsi memori akan meningkat sekitar 20%. Sebagai aturan, kita berdiri lompatan seperti itu. Kemudian, konsumsi memori mulai berkurang, karena beberapa struktur yang digunakan untuk menyimpan informasi tentang bagaimana cluster terdegradasi meninggalkan. Yaitu, bagian dari Grup Penempatan telah kembali ke keadaan normal, dan semua yang diperlukan untuk mempertahankan kondisi terdegradasi dibebaskan -
dalam teori ia dibebaskan .
Mari kita lihat sebuah contoh. Kode C di kiri dan kanan hampir identik, perbedaannya hanya pada konstanta.

Dua contoh ini meminta jumlah memori yang berbeda dari sistem:
- kiri - 2048 buah masing-masing 1 MB;
- kanan - 2097152 buah 1 Kbyte.
Kemudian kedua contoh menunggu kami untuk memotret mereka di atas. Dan setelah menekan ENTER, mereka membebaskan memori - semuanya kecuali bagian terakhir. Ini sangat penting - bagian terakhir tetap ada. Dan lagi mereka menunggu kita untuk memotret mereka.
Di bawah ini adalah apa yang sebenarnya terjadi.

- Pertama, kedua proses dimulai dan memakan memori. Kedengarannya seperti kebenaran - RSS 2 GB.
- Tekan ENTER dan kaget. Program pertama yang menonjol dalam potongan besar mengembalikan memori. Tetapi program kedua tidak kembali.
Jawaban mengapa ini terjadi terletak di Linux malloc.
Jika kami meminta memori dalam potongan besar, itu dikeluarkan menggunakan mekanisme mmap anonim, yang diberikan ke ruang alamat prosesor, dari mana memori kemudian dipotong kepada kami. Ketika kita bebas (), memori dibebaskan dan halaman dikembalikan ke halaman cache (sistem).
Jika kami mengalokasikan memori dalam potongan kecil, kami melakukan sbrk (). sbrk () menggeser pointer ke ekor heap; secara teori, ekor yang bergeser dapat dikembalikan kembali dengan mengembalikan halaman memori ke sistem jika memori tidak digunakan.
Sekarang lihat ilustrasinya. Kami memiliki banyak catatan dalam sejarah lokasi objek terdegradasi, dan kemudian datang sesi pengguna - objek berumur panjang. Kami menyinkronkan dan semua struktur tambahan hilang, tetapi objek yang berumur panjang tetap ada, dan kami tidak dapat memindahkan sbrk () kembali.

Kami masih memiliki banyak ruang yang tidak terpakai yang dapat dibebaskan jika kami memiliki SWAP. Tapi kami pintar - kami menonaktifkan SWAP.
Tentu saja, kemudian beberapa bagian dari memori dari awal tumpukan akan digunakan, tetapi ini hanya sebagian, dan sisanya yang sangat signifikan akan tetap ditempati.
Apa yang harus dilakukan dalam situasi seperti itu? Jawabannya ada di bawah ini.
Peluncuran terkendali
- Kami memulai satu daemon OSD.
- Kami menunggu saat disinkronkan, kami memeriksa anggaran memori.
- Jika kita mengerti bahwa kita akan selamat dari permulaan iblis berikutnya, kita mulai yang berikutnya.
- Jika tidak, maka cepat restart daemon yang mengambil sebagian besar memori. Dia mampu turun untuk waktu yang singkat, dia tidak memiliki banyak sejarah, hilang locs dan hal-hal lain, sehingga dia akan memakan lebih sedikit memori, anggaran memori akan meningkat sedikit.
- Kami berlari di sekitar cluster, mengendalikannya, dan secara bertahap meningkatkan segalanya.
- Kami memeriksa apakah mungkin untuk melanjutkan ke OSD berikutnya, pergi ke sana.
DigitalOcean sebenarnya melakukan ini:
"Tim Datacenter kami melakukan penambahan memori sementara tim lain perlahan melanjutkan memunculkan node sambil mengelola secara manual anggaran memori masing-masing host."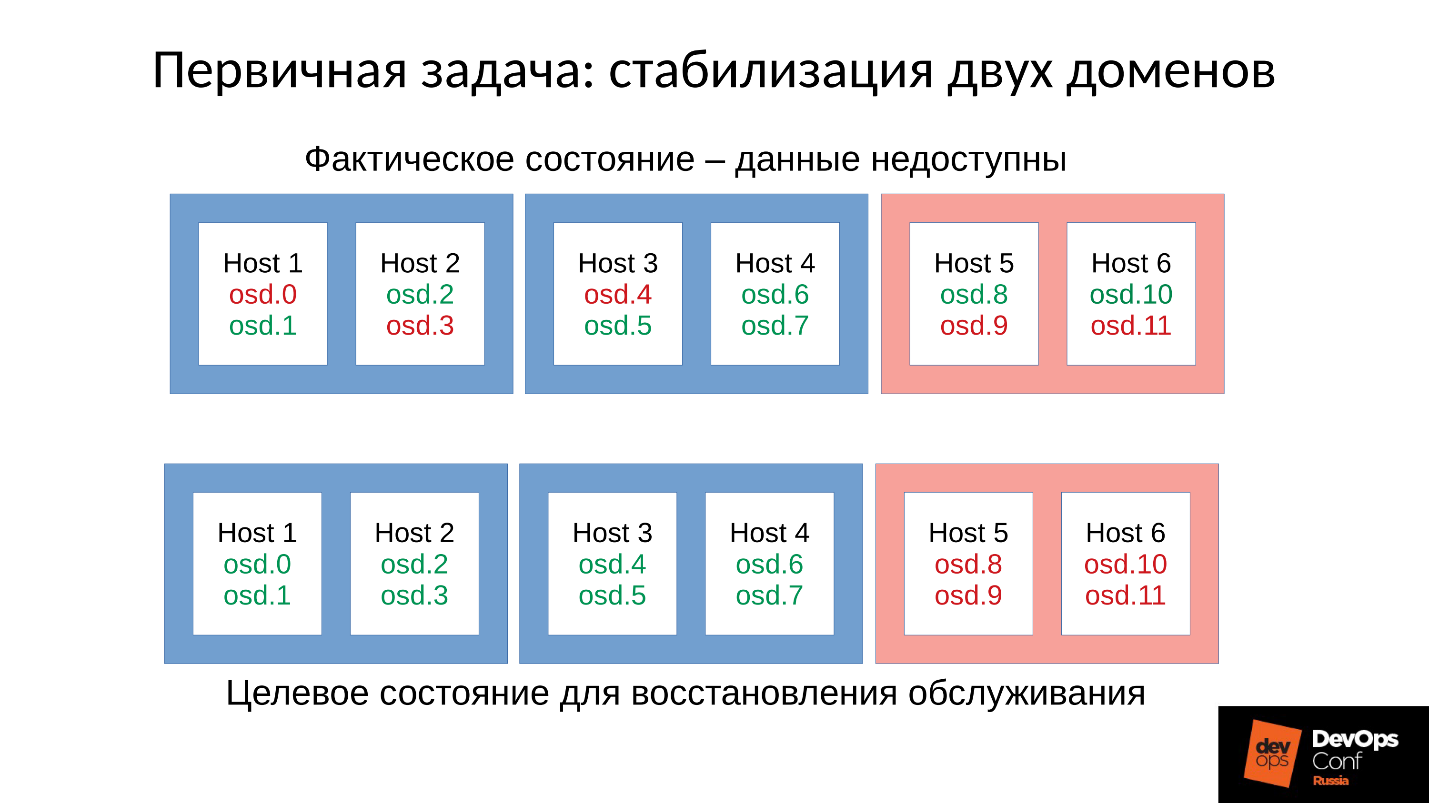
Mari kita kembali ke konfigurasi dan situasi kita saat ini. Sekarang kami memiliki cluster yang runtuh setelah reaksi berantai dari pembunuh memori. Kami melarang restart otomatis OSD di domain merah, dan satu per satu kami memulai node dari domain biru. Karena
tugas pertama kami adalah selalu mengembalikan layanan , tanpa memahami mengapa ini terjadi. Kami akan mengerti nanti, ketika kami mengembalikan layanan. Dalam operasi, ini selalu terjadi.
Kami membawa cluster ke status target untuk memulihkan layanan, dan kemudian kami mulai menjalankan satu OSD demi satu sesuai dengan metodologi kami. Kami melihat yang pertama, jika perlu, restart yang lain untuk menyesuaikan anggaran memori, berikutnya - 9, 10, 11 - dan cluster tampaknya akan disinkronkan dan siap untuk memulai pemeliharaan.
Masalahnya adalah bagaimana
pemeliharaan tulis dilakukan
di Ceph .
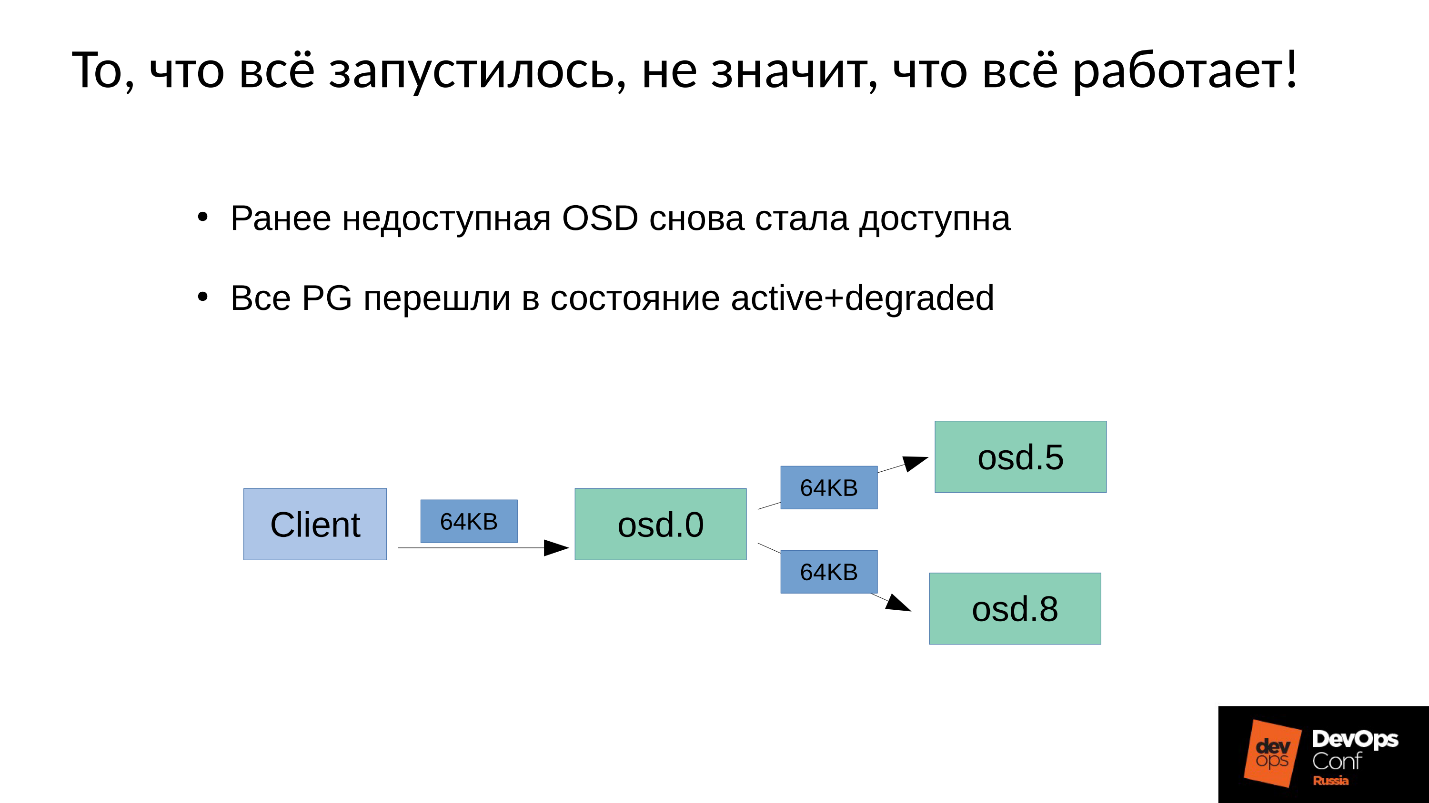
Kami memiliki 3 replika: satu master OSD dan dua budak untuk itu. Kami akan mengklarifikasi bahwa master / budak di setiap Grup Penempatan memiliki sendiri, tetapi masing-masing memiliki satu master dan dua budak.
Operasi tulis atau baca jatuh pada master. Saat membaca, jika master memiliki versi yang tepat, ia akan memberikannya kepada klien. Perekaman sedikit lebih rumit, rekaman harus diulang pada semua replika. Dengan demikian, ketika klien menulis 64 KB di OSD 0, 64 KB yang sama dalam contoh kita pergi ke OSD 5 dan OSD 8.
Tetapi kenyataannya adalah bahwa OSD 8 kami sangat rusak, karena kami memulai kembali banyak proses.

Karena di Ceph perubahan apa pun adalah transisi dari versi ke versi, pada OSD 0 dan OSD 5 kita akan memiliki versi baru, pada OSD 8 - yang lama. , , ( 64 ) OSD 8 — 4 ( ). 4 OSD 0, OSD 8, , . , 64 .
— .

:
- 4 1 , 1000 / 1 .
- 4 ( ) 22 , 45 /.
, , , , .
— .

4 22 , 22 , 1 4 . 45 SSD, 1 —
45 .
, .
- , — (45+1) / 2 = 23 .
- 75% , (45 * 3 + 1) / 4 = 34 .
- 90% —(45 * 9 + 1) / 10 = 41 — 40 , .
Ceph, . , , , .
Ceph .

- — : , , , , .
- — latency. latency , . 100% ( , ). Latency 60 , .

, . 10 , 1 200 /, 300 , , . 10 SSD — 300 , — , - 300 .
, .
, . 900 / ( SSD). 2 500 128 ( , ESXi HyperV 128 ). degraded, 225 . file store, object store, ( ), 110 , - .
SSD 110 — !
?1: —
.

: ; PG;
.
:
- , 45 — .
- ( . ), 14 .
- , 8 ( 10% PG).
, , , , , .
2: —
(order, objectsize) .
, , , 4 2 1 . , , . :
:
(32 ) — !
3: —
Ceph .
, -,
Ceph . , , . .
, — Latency. — , — . Latency 30% , , .
Community , preproduction . , . , .
Kesimpulan
- , . , Ceph - , , .
●
- .
, . ,
. . , , production. , , , DigitalOcean , . , , , .
, , . , : « ! ?!» , , . , : , , down time.
●
(OSD)., , — , , - , .
OSD — — . , .
●
.OSD .
, . , , , .
●
RAM OSD.●
SWAP.SWAP Ceph' , Linux' . .
●
.100%, 10%. , , , .
●
RBD Rados Getway., .
SWAP — . , SWAP — , , , , .
— DevOpsConf Russia. . , youtube , DevOps-.