Ada berbagai cara untuk menangani kesalahan dalam bahasa pemrograman:
- pengecualian standar untuk banyak bahasa (Java, Scala dan JVM lainnya, python, dan banyak lainnya)
- kode status atau bendera (Go, bash)
- berbagai struktur data aljabar, yang nilainya dapat berupa hasil yang berhasil dan deskripsi kesalahan (Scala, haskell dan bahasa fungsional lainnya)
Pengecualian digunakan sangat luas, di sisi lain mereka sering dikatakan lambat. Tetapi lawan dari pendekatan fungsional sering menarik kinerja.
Baru-baru ini, saya telah bekerja dengan Scala, di mana saya dapat menggunakan pengecualian dan berbagai tipe data untuk penanganan kesalahan, jadi saya ingin tahu pendekatan mana yang akan lebih mudah dan lebih cepat.
Kami akan segera membuang penggunaan kode dan bendera, karena pendekatan ini tidak diterima dalam bahasa JVM dan, menurut pendapat saya, terlalu rentan kesalahan (saya minta maaf atas permainan kata-kata). Karenanya, kami akan membandingkan pengecualian dan berbagai jenis ADT. Selain itu, ADT dapat dianggap sebagai penggunaan kode kesalahan dalam gaya fungsional.
UPDATE : pengecualian tanpa jejak tumpukan ditambahkan ke perbandingan
Kontestan
Sedikit lebih banyak tentang tipe data aljabarBagi mereka yang tidak terlalu terbiasa dengan ADT ( ADT ) - tipe aljabar terdiri dari beberapa nilai yang mungkin, yang masing-masing dapat menjadi nilai majemuk (struktur, catatan).
Contohnya adalah tipe Option[T] = Some(value: T) | None Option[T] = Some(value: T) | None , yang digunakan sebagai pengganti nol: nilai dari jenis ini dapat berupa Some(t) jika ada nilai, atau None jika tidak.
Contoh lain adalah Try[T] = Success(value: T) | Failure(exception: Throwable) Try[T] = Success(value: T) | Failure(exception: Throwable) , yang menjelaskan hasil perhitungan yang dapat diselesaikan dengan sukses atau dengan kesalahan.
Jadi para kontestan kami:
- Pengecualian lama yang bagus
- Pengecualian tanpa jejak tumpukan, karena mengisi jejak tumpukan adalah operasi yang sangat lambat
Try[T] = Success(value: T) | Failure(exception: Throwable) Try[T] = Success(value: T) | Failure(exception: Throwable) - pengecualian yang sama, tetapi dalam pembungkus fungsionalEither[String, T] = Left(error: String) | Right(value: T) Either[String, T] = Left(error: String) | Right(value: T) - jenis yang berisi hasil atau deskripsi kesalahanValidatedNec[String, T] = Valid(value: T) | Invalid(errors: List[String]) ValidatedNec[String, T] = Valid(value: T) | Invalid(errors: List[String]) - jenis dari pustaka Kucing , yang dalam hal kesalahan dapat berisi beberapa pesan tentang kesalahan yang berbeda (tidak cukup List digunakan di sana, tetapi itu tidak masalah)
CATATAN pada dasarnya, pengecualian dibandingkan dengan jejak tumpukan, tanpa dan ATD, tetapi beberapa jenis dipilih, karena Scala tidak memiliki pendekatan tunggal dan menarik untuk membandingkan beberapa.
Selain pengecualian, string digunakan untuk menggambarkan kesalahan, tetapi dengan keberhasilan yang sama dalam situasi nyata, kelas yang berbeda akan digunakan ( Either[Failure, T] ).
Masalah
Untuk menguji penanganan kesalahan, kami mengambil masalah penguraian dan validasi data:
case class Person(name: String, age: Int, isMale: Boolean) type Result[T] = Either[String, T] trait PersonParser { def parse(data: Map[String, String]): Result[Person] }
yaitu memiliki data mentah Map[String, String] Anda harus mendapatkan Person atau kesalahan jika data tidak valid.
Lempar
Sebuah solusi untuk dahi menggunakan pengecualian (selanjutnya saya hanya akan memberikan fungsi person , Anda dapat melihat kode lengkap di github ):
Throwparser.scala
def person(data: Map[String, String]): Person = { val name = string(data.getOrElse("name", null)) val age = integer(data.getOrElse("age", null)) val isMale = boolean(data.getOrElse("isMale", null)) require(name.nonEmpty, "name should not be empty") require(age > 0, "age should be positive") Person(name, age, isMale) }
di sini string , integer dan boolean memvalidasi keberadaan dan format tipe sederhana dan melakukan konversi.
Secara umum, ini cukup sederhana dan dapat dimengerti.
ThrowNST (Tanpa Jejak Jejak)
Kode ini sama seperti pada kasus sebelumnya, tetapi pengecualian digunakan tanpa jejak stack jika memungkinkan: ThrowNSTParser.scala
Coba
Solusi menangkap pengecualian sebelumnya dan memungkinkan menggabungkan hasil via for (jangan bingung dengan loop dalam bahasa lain):
TryParser.scala
def person(data: Map[String, String]): Try[Person] = for { name <- required(data.get("name")) age <- required(data.get("age")) flatMap integer isMale <- required(data.get("isMale")) flatMap boolean _ <- require(name.nonEmpty, "name should not be empty") _ <- require(age > 0, "age should be positive") } yield Person(name, age, isMale)
sedikit lebih tidak biasa untuk mata yang rapuh, tetapi karena penggunaan for , ini sangat mirip dengan versi dengan pengecualian, di samping itu, validasi kehadiran bidang dan penguraian jenis yang diinginkan terjadi secara terpisah ( flatMap dapat dibaca di sini saat and then )
Baik
Di sini, tipe Either tersembunyi di belakang alias Result karena jenis kesalahan diperbaiki:
EitherParser.scala
def person(data: Map[String, String]): Result[Person] = for { name <- required(data.get("name")) age <- required(data.get("age")) flatMap integer isMale <- required(data.get("isMale")) flatMap boolean _ <- require(name.nonEmpty, "name should not be empty") _ <- require(age > 0, "age should be positive") } yield Person(name, age, isMale)
Karena standar Either seperti Try membentuk monad di Scala, kode keluar persis sama, perbedaannya di sini adalah bahwa string muncul di sini sebagai kesalahan dan pengecualian minimal digunakan (hanya untuk menangani kesalahan ketika mengurai angka)
Divalidasi
Di sini pustaka Kucing digunakan untuk mendapatkan bukan hal pertama yang terjadi, tetapi sebanyak mungkin (misalnya, jika beberapa bidang tidak valid, hasilnya akan berisi kesalahan parsing untuk semua bidang ini)
ValidatedParser.scala
def person(data: Map[String, String]): Validated[Person] = { val name: Validated[String] = required(data.get("name")) .ensure(one("name should not be empty"))(_.nonEmpty) val age: Validated[Int] = required(data.get("age")) .andThen(integer) .ensure(one("age should be positive"))(_ > 0) val isMale: Validated[Boolean] = required(data.get("isMale")) .andThen(boolean) (name, age, isMale).mapN(Person) }
kode ini sudah kurang mirip dengan versi aslinya dengan pengecualian, tetapi verifikasi pembatasan tambahan tidak diceraikan dari bidang parsing dan kami masih mendapatkan beberapa kesalahan, bukan satu, sepadan!
Pengujian
Untuk pengujian, kumpulan data dihasilkan dengan persentase kesalahan yang berbeda dan diuraikan dalam masing-masing cara.
Hasil pada semua persentase kesalahan:

Secara lebih rinci, dengan persentase kesalahan yang rendah (waktunya berbeda di sini karena sampel yang lebih besar digunakan):
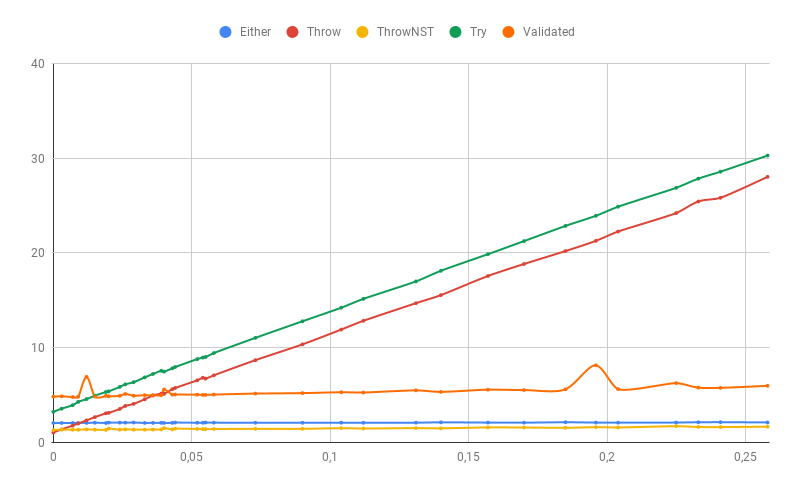
Jika beberapa bagian dari kesalahan masih merupakan pengecualian dengan jejak tumpukan (dalam kasus kami, kesalahan penguraian nomor akan menjadi pengecualian yang tidak kami kontrol), maka tentu saja kinerja metode penanganan kesalahan "cepat" akan menurun secara signifikan. Validated sangat terpengaruh, karena mengumpulkan semua kesalahan dan sebagai hasilnya menerima pengecualian lambat lebih dari yang lain:

Kesimpulan
Seperti yang ditunjukkan percobaan, pengecualian dengan jejak tumpukan benar-benar sangat lambat (100% kesalahannya adalah perbedaan antara Throw dan Either lebih dari 50 kali!), Dan ketika hampir tidak ada pengecualian, menggunakan ADT memiliki harga. Namun, menggunakan pengecualian tanpa jejak tumpukan sama cepat (dan dengan persentase kesalahan yang rendah lebih cepat) seperti ADT, namun, jika pengecualian tersebut melampaui batas validasi yang sama, melacak sumbernya tidak akan mudah.
Secara total, jika probabilitas pengecualian lebih dari 1%, maka pengecualian tanpa jejak tumpukan bekerja paling cepat, Validated atau reguler. Either hampir sama cepat. Dengan sejumlah besar kesalahan, Either bisa sedikit lebih cepat daripada Validated hanya karena semantik gagal-cepat.
Menggunakan ADT untuk penanganan kesalahan memberikan keuntungan lain dari pengecualian: kemungkinan kesalahan ditransfer ke dalam tipe itu sendiri dan lebih sulit untuk dilewatkan, seperti ketika menggunakan Option bukan nol.