Salah satu fungsi
situs iklan kami yang tidak mencolok namun penting adalah untuk menyimpan dan menampilkan jumlah penayangannya. Situs kami telah menonton penayangan iklan selama lebih dari 10 tahun. Implementasi teknis fungsi berhasil berubah beberapa kali selama waktu ini, dan sekarang ini adalah layanan (mikro) di Go, bekerja dengan Redis sebagai antrian cache dan tugas, dan dengan MongoDB sebagai penyimpanan persisten. Beberapa tahun yang lalu, ia belajar bekerja tidak hanya dengan jumlah penayangan iklan, tetapi juga dengan statistik untuk setiap hari. Tetapi dia belajar untuk melakukan semua ini dengan sangat cepat dan andal baru-baru ini.

Secara total, layanan memproses ~ 300 ribu permintaan baca dan ~ 9 ribu permintaan tulis per menit, 99% di antaranya dieksekusi hingga 5ms. Ini, tentu saja, bukan indikator astronomi dan bukan peluncuran roket di Mars - tetapi juga bukan tugas sepele seperti penyimpanan angka yang sederhana. Ternyata melakukan semua ini, memastikan penyimpanan data lossless dan membaca nilai-nilai yang konsisten dan relevan, memerlukan beberapa upaya, yang akan kita bahas di bawah ini.
Tugas dan Gambaran Umum Proyek
Meskipun penghitung tampilan tidak begitu penting untuk bisnis seperti, katakanlah, memproses pembayaran atau
permintaan pinjaman , mereka pertama-tama penting bagi pengguna kami. Orang-orang terpesona dengan melacak popularitas iklan mereka: beberapa bahkan memanggil dukungan ketika mereka melihat informasi tampilan yang tidak akurat (ini terjadi dengan salah satu implementasi layanan sebelumnya). Selain itu, kami menyimpan dan menampilkan statistik terperinci di akun pribadi pengguna (misalnya, untuk menilai efektivitas penggunaan layanan berbayar). Semua ini membuat kami berhati-hati dalam menyimpan setiap acara tontonan dan menampilkan nilai yang paling relevan.
Secara umum, fungsi dan prinsip proyek terlihat seperti ini:
- Halaman web atau layar aplikasi membuat permintaan di belakang penghitung tampilan iklan (permintaan biasanya tidak sinkron untuk memprioritaskan keluaran informasi dasar). Dan jika halaman iklan itu sendiri ditampilkan, klien akan meminta Anda untuk menambah dan mengembalikan jumlah tampilan yang diperbarui.
- Dengan memproses permintaan baca, layanan mencoba untuk mendapatkan informasi dari cache Redis, dan melengkapi yang tidak diketahui dengan menyelesaikan permintaan ke MongoDB.
- Permintaan tulis dikirim ke 2 struktur di lobak: antrian pembaruan tambahan (diproses di latar belakang, secara tidak serempak) dan cache dari jumlah total tampilan.
- Proses latar belakang dalam layanan yang sama membaca elemen dari antrian, menumpuknya di buffer lokal, dan secara berkala menulisnya ke MongoDB.
Rekam Tampilan Penghitung: Perangkap
Meskipun langkah-langkah yang dijelaskan di atas terlihat cukup sederhana, masalahnya di sini adalah organisasi interaksi antara database dan contoh layanan mikro sehingga data tidak hilang, tidak terduplikasi, dan tidak tertinggal.
Menggunakan hanya satu repositori (misalnya, hanya MongoDB) akan menyelesaikan beberapa masalah ini. Bahkan, layanan digunakan untuk bekerja sebelumnya, sampai kami menemukan masalah penskalaan, stabilitas dan kecepatan.
Implementasi naif data bergerak antara penyimpanan dapat menyebabkan, misalnya, ke anomali seperti:
- Kehilangan data saat kompetitif menulis ke cache:
- Proses A meningkatkan jumlah tampilan dalam cache Redis, tetapi menemukan bahwa masih belum ada data untuk entitas ini (bisa berupa deklarasi baru atau yang lama yang telah diekstrusi dari cache), jadi proses tersebut pertama-tama harus mendapatkan nilai ini dari MongoDB.
- Proses A mendapatkan jumlah tampilan dari MongoDB - misalnya, angka 5; kemudian menambahkan 1 ke dalamnya dan akan menulis ke Redis 6 .
- Proses B (dimulai, misalnya, oleh pengguna situs lain yang juga memasukkan iklan yang sama) secara bersamaan melakukan hal yang sama.
- Proses A menulis nilai 6 ke Redis.
- Proses B menulis nilai 6 ke Redis.
- Akibatnya, satu tampilan hilang karena balapan saat merekam data.
Skenarionya tidak begitu mustahil: misalnya, kami memiliki layanan berbayar yang menempatkan iklan di halaman utama situs. Untuk pengumuman baru, rangkaian peristiwa semacam itu dapat menyebabkan hilangnya banyak pandangan sekaligus karena arus masuknya yang tiba-tiba.
- Contoh skenario lain adalah kehilangan data saat memindahkan tampilan dari Redis ke MongoDb:
- Proses mengambil nilai yang tertunda dari Redis dan menyimpannya dalam memori untuk kemudian menulis ke MongoDB.
- Permintaan penulisan gagal (atau proses macet sebelum dijalankan).
- Data hilang lagi, yang akan menjadi jelas pada saat nilai yang di-cache didorong keluar dan diganti dengan nilai dari database.
Kesalahan lain dapat terjadi, alasan yang juga terletak pada sifat non-atom operasi antara database, misalnya, konflik saat menghapus dan meningkatkan pandangan dari entitas yang sama.
Merekam Jumlah Tampilan: Solusi
Pendekatan kami untuk menyimpan dan memproses data dalam proyek ini didasarkan pada harapan bahwa pada suatu saat MongoDB mungkin gagal lebih mungkin daripada Redis. Ini, tentu saja, bukan
aturan mutlak - setidaknya tidak untuk setiap proyek - tetapi di lingkungan kami, kami benar-benar terbiasa mengamati batas waktu berkala untuk kueri di MongoDB yang disebabkan oleh kinerja operasi disk, yang sebelumnya merupakan salah satu alasan hilangnya beberapa peristiwa.
Untuk menghindari banyak masalah yang disebutkan di atas, kami menggunakan antrian tugas untuk penyimpanan yang ditangguhkan dan skrip lua, yang memungkinkan untuk mengubah data secara atomis dalam beberapa struktur lobak sekaligus. Dengan mengingat hal ini, detail untuk menyimpan tampilan adalah sebagai berikut:
- Ketika permintaan tulis jatuh ke dalam microservice, ia menjalankan skrip lua IncrementIfExists untuk menambah penghitung hanya jika sudah ada dalam cache. Script segera mengembalikan -1 jika tidak ada data untuk entitas yang dilihat di lobak; jika tidak, itu meningkatkan nilai tampilan dalam cache melalui HINCRBY , menambahkan acara ke antrian untuk penyimpanan selanjutnya di MongoDB (disebut antrian tertunda oleh kami) melalui LPUSH , dan mengembalikan jumlah tampilan yang diperbarui.
- Jika IncrementIfExists mengembalikan angka positif, nilai ini dikembalikan ke klien dan permintaan berakhir.
Jika tidak, microservice mengambil penghitung tampilan dari MongoDb, menambahnya dengan 1 dan mengirimkannya ke lobak.
- Menulis ke lobak dilakukan melalui lua-script lain - Upsert - yang menyimpan jumlah tampilan ke cache jika masih kosong, atau meningkatkannya dengan 1 jika orang lain berhasil mengisi cache antara langkah 1 dan 3.
- Upsert juga menambahkan acara tampilan ke antrian yang tertunda, dan mengembalikan jumlah yang diperbarui, yang kemudian dikirim ke klien.
Karena fakta bahwa skrip lua
dieksekusi secara atom , kami menghindari banyak masalah potensial yang dapat disebabkan oleh penulisan yang kompetitif.
Detail penting lainnya adalah memastikan transfer pembaruan yang aman dari antrian yang tertunda ke MongoDB. Untuk melakukan ini, kami menggunakan templat "antrian yang dapat diandalkan" yang dijelaskan dalam
dokumentasi Redis , yang secara signifikan mengurangi kemungkinan kehilangan data dengan membuat salinan elemen yang diproses dalam antrian yang terpisah, yang lain hingga akhirnya disimpan dalam penyimpanan persisten.
Untuk lebih memahami seluruh langkah proses, kami telah menyiapkan visualisasi kecil. Pertama, mari kita lihat skenario normal dan sukses (langkah-langkahnya diberi nomor di sudut kanan atas dan dijelaskan secara rinci di bawah):
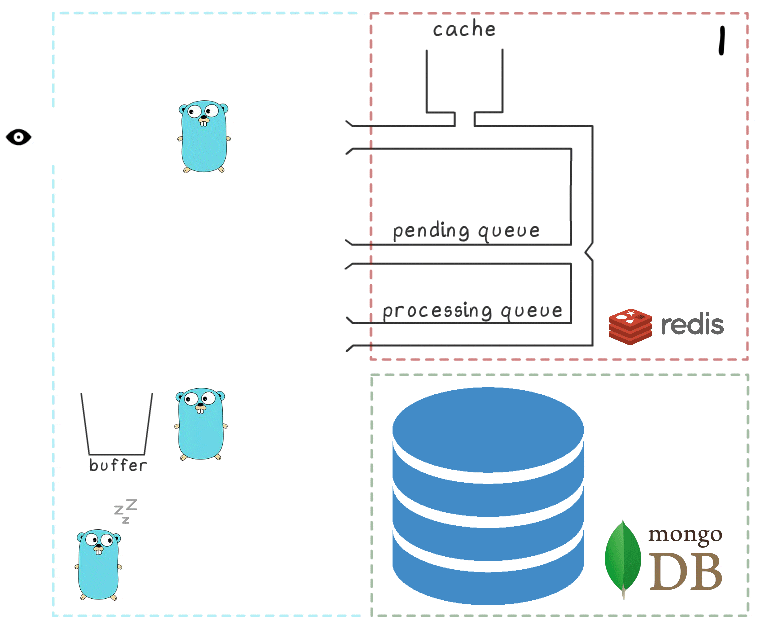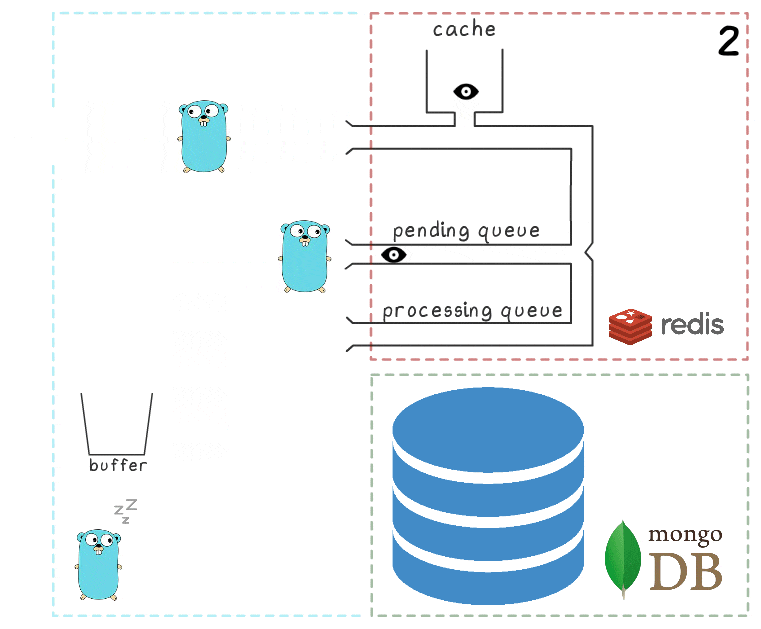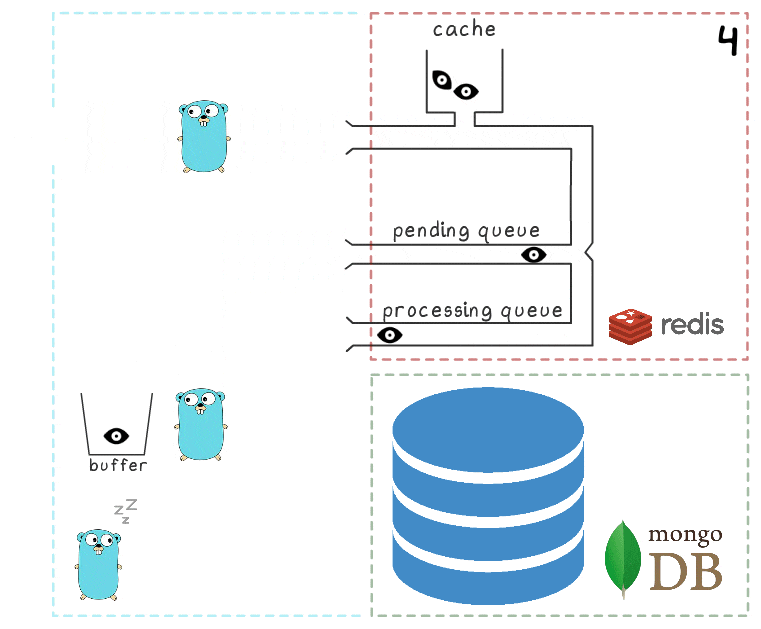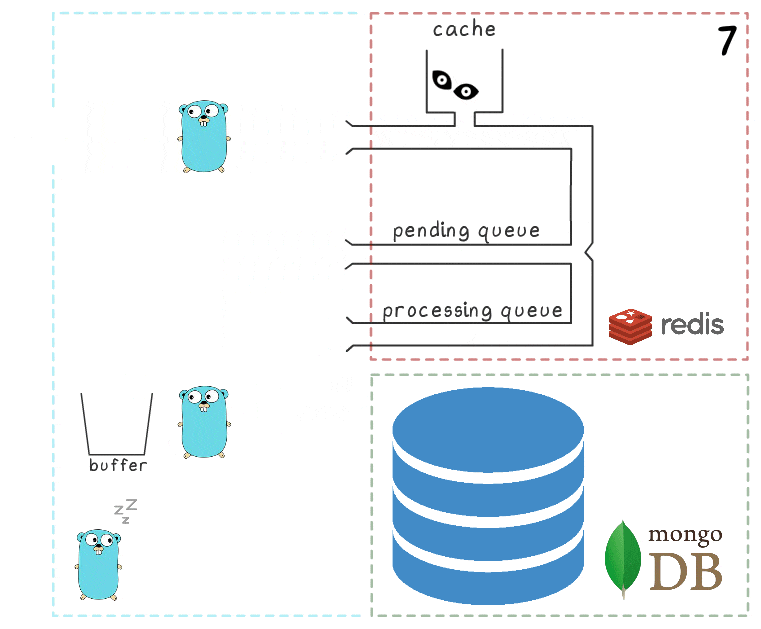
- Layanan mikro menerima permintaan tulis
- Penangan permintaan meneruskannya ke skrip lua yang menulis pencarian ke cache (segera membuatnya dapat dibaca) dan ke antrian untuk diproses lebih lanjut.
- Goroutine latar belakang (secara berkala) melakukan operasi BRPopLPush , yang secara atomis memindahkan elemen dari satu antrian ke antrian (kami menyebutnya "antrian pemrosesan" - antrian dengan elemen yang sedang diproses). Elemen yang sama kemudian disimpan dalam buffer di memori proses.
- Permintaan tulis lain tiba dan sedang diproses, yang membuat kami memiliki 2 elemen dalam buffer dan 2 elemen dalam antrian pemrosesan.
- Setelah beberapa waktu habis, proses latar belakang memutuskan untuk menyiram buffer di MongoDB. Menulis beberapa nilai dari buffer dilakukan oleh satu permintaan, yang secara positif memengaruhi throughput. Selain itu, sebelum merekam, proses mencoba menggabungkan beberapa tampilan menjadi satu, merangkum nilainya untuk iklan yang sama.
Pada masing-masing proyek kami, 3 instance microservice digunakan, masing-masing dengan buffernya sendiri, yang disimpan ke database setiap 2 detik. Selama waktu ini, sekitar 100 elemen terakumulasi dalam satu buffer.
- Setelah penulisan berhasil, proses menghapus item dari antrian pemrosesan, menandakan bahwa pemrosesan telah selesai dengan sukses.
Ketika semua subsistem dalam urutan, beberapa langkah ini mungkin tampak berlebihan. Dan pembaca yang penuh perhatian mungkin juga memiliki pertanyaan tentang apa yang dilakukan gopher yang tidur di sudut kiri bawah.
Semuanya dijelaskan ketika mempertimbangkan skenario ketika MongoDB tidak tersedia:
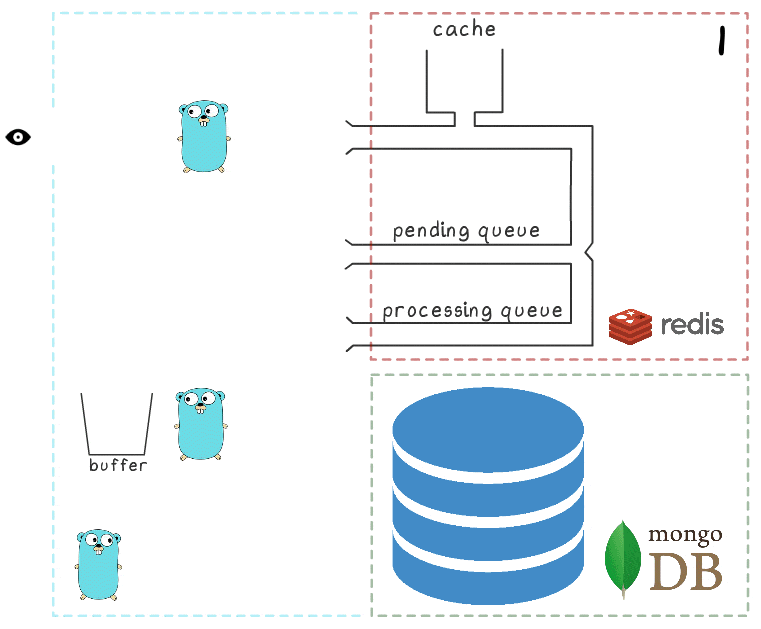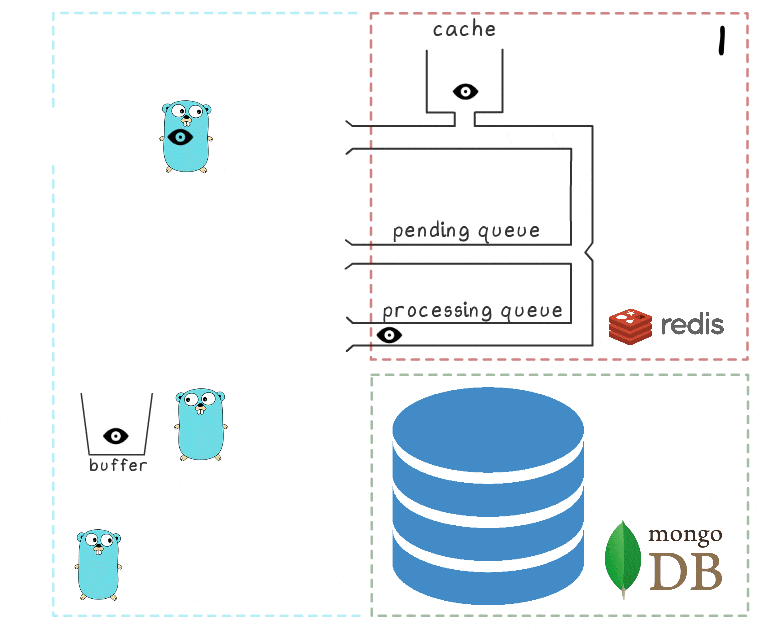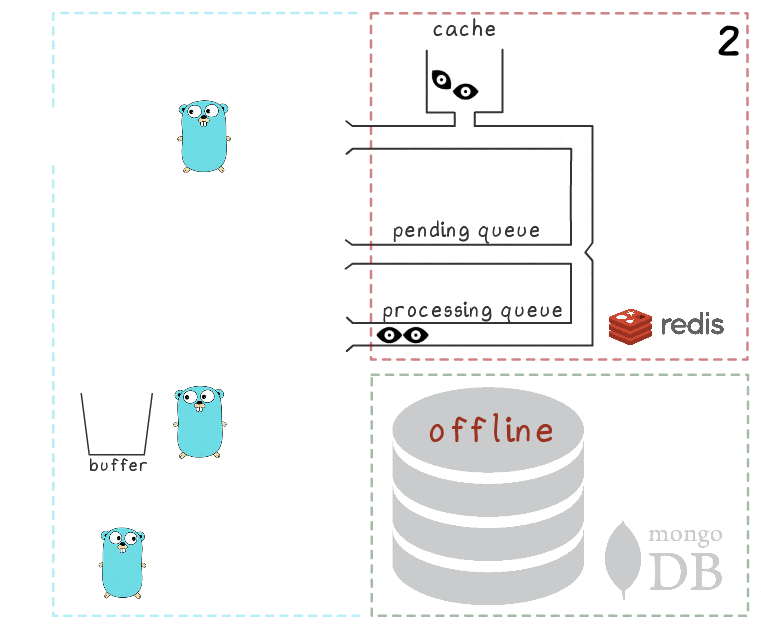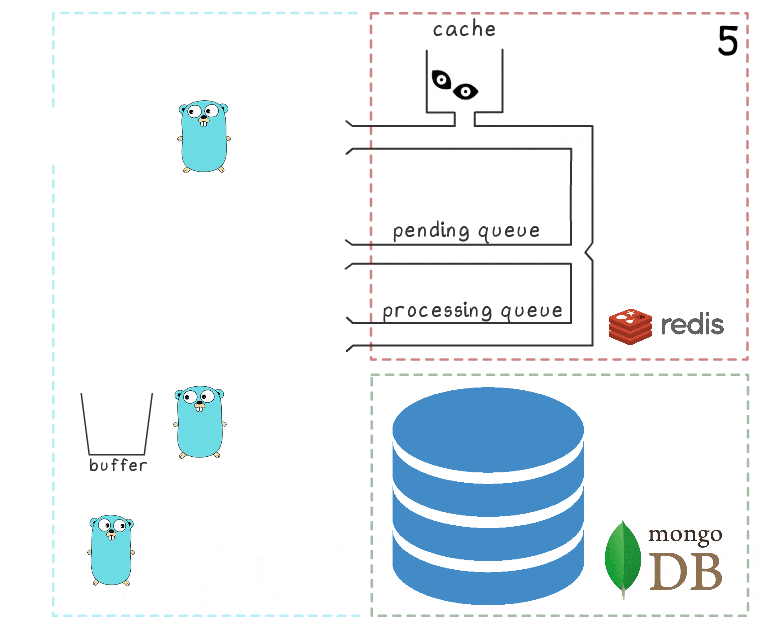
- Langkah pertama identik dengan peristiwa dari skenario sebelumnya: layanan menerima 2 permintaan untuk merekam pandangan dan memprosesnya.
- Proses kehilangan koneksi dengan MongoDB (proses itu sendiri, tentu saja, belum tahu tentang ini).
Pawang Gorutin, seperti sebelumnya, sedang mencoba memasukkan buffer ke dalam basis data - tetapi kali ini tidak berhasil. Dia kembali menunggu iterasi berikutnya.
- Goroutine latar belakang lain bangun dan memeriksa antrian pemrosesan. Dia menemukan bahwa unsur-unsur telah ditambahkan padanya sejak lama; menyimpulkan bahwa pemrosesan mereka gagal, ia memindahkan mereka kembali ke antrian yang tertunda.
- Setelah beberapa saat, koneksi dengan MongoDB dipulihkan.
- Goroutine latar belakang pertama lagi mencoba melakukan operasi penulisan - kali ini berhasil - dan pada akhirnya menghapus item dari antrian pemrosesan secara permanen.
Dalam skema ini, ada beberapa batas waktu penting dan heuristik yang diperoleh melalui pengujian dan akal sehat: misalnya, elemen dipindahkan kembali dari antrian pemrosesan ke antrian tertunda setelah 15 menit tidak aktif. Selain itu, goroutine yang bertanggung jawab untuk tugas ini melakukan
kunci sebelum eksekusi sehingga beberapa instance dari layanan microser tidak mencoba untuk mengembalikan tampilan "beku" pada saat yang sama.
Sebenarnya, bahkan langkah-langkah ini tidak memberikan jaminan yang terbukti secara teoritis (misalnya, kami mengabaikan skenario seperti proses membeku selama 15 menit) - tetapi dalam praktiknya itu bekerja dengan cukup andal.
Juga dalam skema ini, setidaknya ada 2 kerentanan yang diketahui oleh kita yang penting untuk diperhatikan:
- Jika microservice mogok segera setelah berhasil menyimpan ke MongoDb, tetapi sebelum membersihkan daftar antrian pemrosesan, maka data ini akan dianggap tidak disimpan - dan setelah 15 menit akan disimpan lagi.
Untuk mengurangi kemungkinan skenario seperti itu, kami telah melakukan upaya berulang kali untuk menghapus dari antrian pemrosesan jika terjadi kesalahan. Pada kenyataannya, kami belum mengamati kasus-kasus seperti ini dalam produksi.
- Saat me-reboot, lobak dapat kehilangan tidak hanya cache, tetapi juga beberapa tampilan yang belum disimpan dari antrian, karena dikonfigurasi untuk secara berkala menyimpan snapshot RDB setiap beberapa menit.
Meskipun secara teori ini bisa menjadi masalah serius (terutama jika proyek berurusan dengan data yang sangat kritis), dalam praktiknya node sangat jarang dimulai kembali. Pada saat yang sama, menurut pemantauan, elemen menghabiskan antrian kurang dari 3 detik, yaitu, jumlah kemungkinan kerugian sangat terbatas.
Tampaknya ada lebih banyak masalah daripada yang kita inginkan. Namun, pada kenyataannya, ternyata skenario yang kami pertahankan awalnya - kegagalan MongoDB - memang merupakan ancaman yang jauh lebih nyata, dan skema pemrosesan data baru berhasil memastikan ketersediaan layanan dan mencegah kerugian.
Salah satu contoh nyata dari hal ini adalah ketika instance MongoDB di salah satu proyek bukan kepalang tersedia sepanjang malam. Selama ini, jumlah penghitungan terakumulasi dan diputar dalam lobak dari satu antrian ke antrian yang lain, sampai akhirnya disimpan dalam database setelah menyelesaikan insiden; sebagian besar pengguna bahkan tidak melihat kegagalan.
Jumlah tampilan baca
Permintaan baca jauh lebih sederhana daripada permintaan tulis: microservice terlebih dahulu memeriksa cache di lobak; segala sesuatu yang tidak ditemukan dalam cache diisi dengan data dari MongoDb dan dikembalikan ke klien.
Tidak ada penulisan end-to-end ke cache selama operasi baca untuk menghindari biaya perlindungan terhadap penulisan kompetitif. Hitrate cache tetap bagus, karena lebih sering daripada tidak, itu akan menjadi hangat berkat permintaan tulis lainnya.
Statistik tampilan harian dibaca langsung dari MongoDB, seperti yang diminta lebih jarang, dan caching lebih sulit. Ini juga berarti bahwa ketika database tidak tersedia, membaca statistik berhenti berfungsi; tetapi hanya mempengaruhi sebagian kecil pengguna.
Skema penyimpanan data MongoDB
Skema pengumpulan MongoDB untuk proyek didasarkan pada
rekomendasi ini dari pengembang basis data itu sendiri , dan terlihat seperti ini:
- Tampilan disimpan dalam 2 koleksi: di satu ada jumlah totalnya, di yang lain - statistik per hari.
- Data dalam pengumpulan statistik disusun berdasarkan satu dokumen per iklan per bulan . Untuk pengumuman baru, dokumen yang diisi dengan tiga puluh satu nol untuk bulan berjalan dimasukkan ke dalam koleksi; Menurut artikel yang disebutkan di atas, ini memungkinkan Anda untuk segera mengalokasikan cukup ruang untuk dokumen pada disk sehingga database tidak harus memindahkannya saat menambahkan data.
Item ini membuat proses membaca statistik sedikit canggung (permintaan harus dibuat berbulan-bulan di sisi layanan mikro), tetapi secara keseluruhan skema ini tetap cukup intuitif.
- Operasi upsert digunakan untuk merekam, untuk memperbarui dan, jika perlu, membuat dokumen untuk entitas yang diinginkan dalam permintaan yang sama.
Kami tidak menggunakan kemampuan transaksional MongoDb untuk memperbarui beberapa koleksi secara bersamaan, yang berarti bahwa kami berisiko bahwa data dapat ditulis hanya untuk satu koleksi. Untuk saat ini, kami cukup login dalam kasus seperti itu; jumlahnya sedikit, dan sejauh ini tidak ada masalah signifikan yang sama dengan skenario lainnya.
Pengujian
Saya tidak akan percaya kata-kata saya sendiri bahwa skenario yang dijelaskan benar-benar berfungsi jika mereka tidak dicakup oleh tes.
Karena sebagian besar kode proyek bekerja erat dengan lobak dan MongoDb, sebagian besar tes di dalamnya adalah tes integrasi. Lingkungan pengujian didukung melalui komposisi buruh pelabuhan, yang berarti dapat digunakan dengan cepat, memberikan reproduksibilitas dengan mengatur ulang dan memulihkan keadaan pada setiap awal, dan memungkinkan untuk bereksperimen tanpa memengaruhi basis data orang lain.
Dalam proyek ini, ada 3 bidang utama pengujian:
- Validasi logika bisnis dalam skenario tipikal, yang disebut jalan bahagia Tes-tes ini menjawab pertanyaan - ketika semua subsistem dalam urutan, apakah layanan bekerja sesuai dengan persyaratan fungsional?
- Memeriksa skenario negatif di mana layanan diharapkan untuk melanjutkan pekerjaannya. Misalnya, apakah layanan benar-benar tidak kehilangan data saat MongoDb lumpuh?
Apakah kami yakin bahwa informasi tersebut tetap konsisten dengan batas waktu berkala, macet, dan operasi perekaman kompetitif? - Memeriksa skenario negatif di mana kami tidak mengharapkan layanan untuk melanjutkan, tetapi tingkat fungsionalitas minimum masih harus disediakan. Misalnya, tidak ada kemungkinan bahwa layanan akan terus menyimpan dan mengembalikan data ketika lobak atau mongo tidak tersedia - tetapi kami ingin memastikan bahwa dalam kasus seperti itu tidak macet, tetapi mengharapkan pemulihan sistem dan kemudian kembali bekerja.
Untuk memeriksa skenario yang gagal, kode logika bisnis layanan bekerja dengan antarmuka klien basis data, yang dalam pengujian yang diperlukan diganti dengan implementasi yang mengembalikan kesalahan dan / atau mensimulasikan penundaan jaringan. Kami juga mensimulasikan operasi paralel beberapa instance layanan menggunakan pola "
objek lingkungan ". Ini adalah varian dari pendekatan "inversi kontrol" yang terkenal, di mana fungsi tidak mengakses dependensi itu sendiri, tetapi menerimanya melalui objek lingkungan yang diteruskan dalam argumen. Di antara kelebihan lainnya, pendekatan ini memungkinkan Anda untuk mensimulasikan beberapa salinan independen dari layanan dalam satu tes, yang masing-masing memiliki kumpulan koneksi ke database dan kurang lebih secara efisien mereproduksi lingkungan produksi. Beberapa tes menjalankan setiap instance secara paralel dan memastikan bahwa mereka semua melihat data yang sama, dan tidak ada kondisi balapan.
Kami juga melakukan tes stres yang belum sempurna, tetapi masih cukup berguna berdasarkan
pengepungan , yang secara kasar membantu memperkirakan beban yang diizinkan dan kecepatan respons dari layanan.
Tentang kinerja
Untuk 90% permintaan, waktu pemrosesan sangat kecil, dan yang paling penting - stabil; Berikut adalah contoh pengukuran pada salah satu proyek selama beberapa hari:
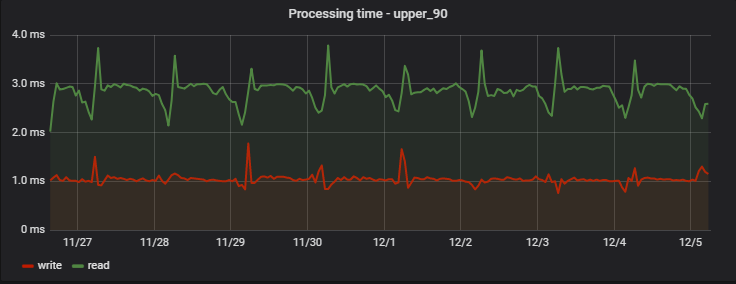
Menariknya, catatan (yang sebenarnya merupakan operasi tulis + baca, karena mengembalikan nilai yang diperbarui) sedikit lebih cepat daripada membaca (tetapi hanya dari sudut pandang klien yang tidak mengamati penulisan yang tertunda sebenarnya).
Peningkatan penundaan reguler di pagi hari adalah efek samping dari pekerjaan tim analitik kami, yang mengumpulkan statistiknya sendiri setiap hari berdasarkan data layanan, menciptakan "muatan berlebihan artifisial" bagi kami.
: ( — MongoDB), ( ), :
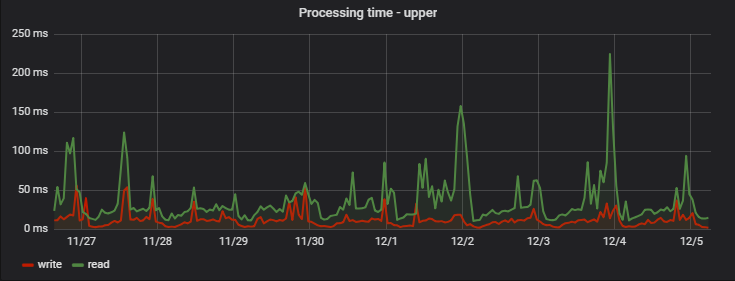
Kesimpulan
, - , , Redis .
, 95% , . , . 5.
Go, Redis MongoDB . , . , — .