Baru-baru ini, Yegor Budnikov, seorang analis sistem di departemen teknologi ABBYY, berbicara di Yandex pada konferensi
Data & Science: Manajemen Hukum dan Catatan . Dia mengatakan bagaimana visi komputer bekerja, pengolah kata terjadi, apa yang penting untuk diperhatikan ketika mengekstraksi informasi dari dokumen hukum dan banyak lagi.
- Perusahaan mungkin telah mengembangkan metodologi untuk analisis data dan manajemen dokumen elektronik, sementara dokumen yang dibuat dalam Word dapat berasal dari pelanggan atau dari departemen tetangga ke perusahaan, saat dicetak, difotokopi, dipindai, dan dibawa ke flash drive.
Apa yang harus dilakukan dengan aliran dokumen, yang sekarang, dengan dokumen "kotor", dengan penyimpanan kertas, hingga fakta bahwa dokumen dapat disimpan hingga 70 tahun sebelum dipindai dan harus diakui?
ABBYY sedang mengembangkan teknologi kecerdasan buatan untuk tugas-tugas bisnis. Kecerdasan buatan harus dapat melakukan kira-kira sama dengan yang dilakukan seseorang dalam kegiatan sehari-hari atau profesional, yaitu: membaca informasi tentang dunia nyata dari gambar atau aliran gambar. Ini tidak hanya visi komputer, tetapi juga pendengaran atau pengenalan data dari sensor, misalnya, dari sensor asap atau suhu. Selanjutnya, data dari sensor ini memasuki sistem dan harus berpartisipasi dalam pengambilan keputusan. Agar berhasil menerapkan fungsi ini, sistem harus mencegah kesalahan logis bodoh, seperti pada gambar:
Teks-teks sulit untuk dianalisis: keragaman dan perkembangan bahasa membuatnya indah dan ekspresif, tetapi ini mempersulit tugas pemrosesan otomatis mereka. Biasanya, ambiguitas kata-kata diatasi oleh fakta bahwa kita dapat menentukan berdasarkan konteks apa arti kata, tetapi terkadang konteks memberi ruang untuk interpretasi. Dalam frasa "
Jenis baja ini ada dalam stok " tidak mungkin dipahami dengan akurasi mutlak dalam konteks konteks: apakah orang-orang di ruangan itu yang makan siang, atau ini adalah beberapa jenis baja yang disimpan di gudang. Untuk mengatasi ambiguitas ini, diperlukan konteks yang lebih luas.
Bagian bawah kolase adalah bingkai dari film "Operation" Y "dan petualangan Shurik lainnya."Dalam kasus umum, kecerdasan buatan atau robot pintar harus dapat bergerak di ruang angkasa dan berhasil berinteraksi dengan objek - misalnya, mengambil kotak itu berulang-ulang, yang dijatuhkan instruktur dari tangannya.
Akhirnya, kecerdasan umum dan representasi pengetahuan: pengetahuan berbeda dari informasi karena bagian-bagiannya secara aktif berinteraksi satu sama lain, menghasilkan pengetahuan baru. Untuk mengatasi masalah pencampuran koktail secara efektif, Anda dapat melakukannya dengan cara sederhana: buat daftar bahan-bahan dan tunjukkan cara mencampurnya. Dalam hal ini, sistem tidak akan dapat menjawab pertanyaan sewenang-wenang tentang subjek yang diminati. Misalnya, apa yang terjadi jika Anda mengganti jus tomat dengan nanas. Agar sistem menguasai materi lebih dalam, basis data, taksonomi (pohon konsep saling berhubungan secara logis), prosedur inferensi logis harus ditambahkan. Dalam hal ini, kita dapat benar-benar mengatakan bahwa sistem memahami apa yang dilakukannya, dan akan dapat menjawab pertanyaan sewenang-wenang tentang prosesnya.
Kecerdasan buatan yang dikembangkan oleh ABBYY memproses dokumen, yaitu mengubah kertas, pindaian, dan media elektronik menjadi informasi terstruktur yang diambil dari dokumen-dokumen ini. Mari kita membahas dua komponen, seperti visi komputer dan pemrosesan kata. Visi komputer memungkinkan Anda mengubah PDF, gambar yang dipindai, gambar menjadi format teks yang dapat diedit. Mengapa ini tugas yang sulit? Pertama, dokumen dapat memiliki struktur sewenang-wenang.
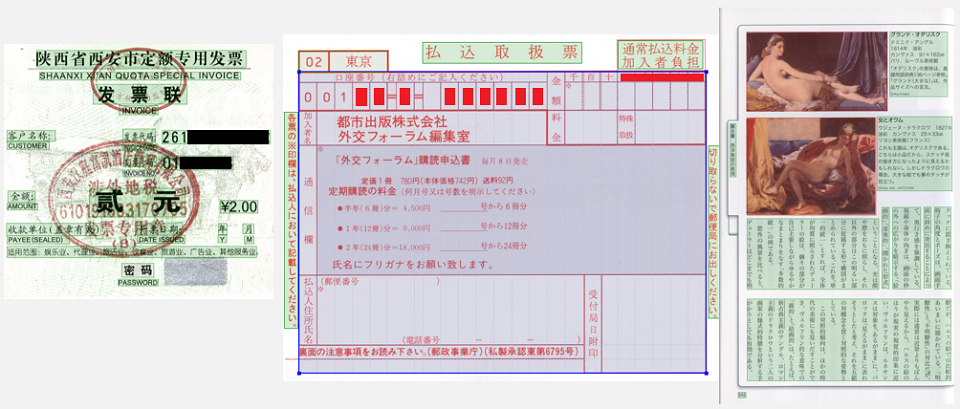
Ini berarti bahwa pertama-tama Anda perlu menyelesaikan masalah analisis struktural dokumen: untuk memahami di mana blok teks, gambar, tabel, daftar berada, dan kemudian untuk menentukan bagaimana mereka berinteraksi satu sama lain. Kedua, dokumen bisa dalam berbagai bahasa. Ini berarti bahwa perlu untuk mendukung deteksi berbagai jenis tulisan dan kemampuan untuk mengenali kata dan karakter yang dapat sangat berbeda satu sama lain. Ketiga, gambar datang kepada kita dari dunia nyata, yang berarti bahwa apa pun bisa terjadi padanya. Mereka mungkin terdistorsi, difoto dengan perspektif yang salah, mereka mungkin memiliki noda kopi, goresan dari printer dan kemudian dari pemindai. Semua ini harus dikelola entah bagaimana untuk kemudian mengekstraksi informasi.
Bagaimana cara kerja pengenalan gambar dengan kami? Pada tahap pertama, kami menerima dan memproses gambar. Dokumen diratakan, distorsi diperbaiki. Kemudian dilakukan analisis struktur halaman, pada tahap ini jenis-jenis blok ditemukan dan ditentukan. Ketika blok didefinisikan, baris atau kolom disejajarkan, Anda dapat membagi garis-garis ini menjadi kata-kata dan simbol - misalnya, dengan histogram vertikal dan horizontal dari distribusi warna hitam.
Dengan demikian, adalah mungkin untuk menentukan di mana batas-batas simbol dan kata-kata, dan kemudian mengenali apa simbol dan kata-kata ini. Akhirnya, blok yang dikenali disintesis menjadi dokumen teks tunggal dan diekspor.
Anda dapat melihat proses ini dari sudut pandang entitas dari berbagai tingkatan. Pertama, kami memiliki dokumen yang diberi nomor halaman. Maka halaman-halaman ini harus dibagi menjadi blok-blok, blok-blok menjadi garis-garis, garis-garis menjadi kata-kata, kata-kata menjadi karakter, dan kemudian karakter-karakter ini harus dikenali. Setelah itu, kami mengumpulkan karakter yang dikenali menjadi kata-kata, kata-kata menjadi garis, garis ke dalam blok, blok ke halaman, halaman ke dalam dokumen. Selain itu, dalam perjalanan kembali, partisi awal dapat bervariasi. Contoh paling sederhana adalah jika blok yang awalnya rusak milik daftar nomor yang sama, jadi mereka akhirnya harus menjadi blok yang sama dengan tipe daftar terstruktur. Dengan kata lain, langkah-langkah yang berdekatan dapat saling memengaruhi untuk meningkatkan kualitas pengakuan.
Dokumen itu dikenali, maka Anda perlu mengambil informasi darinya. Dokumen dapat dibagi menjadi yang lebih terstruktur dan kurang terstruktur. Semakin terstruktur termasuk kartu nama, cek, faktur. Yang kurang terstruktur termasuk surat kuasa, piagam, artikel di majalah. Jika jenis dokumen diperbaiki, lebih atau kurang terstruktur dan dokumen dalam jenis ini sedikit berbeda satu sama lain dalam struktur, Anda dapat menerapkan metode yang belajar untuk secara langsung mengekstraksi atribut yang diperlukan dari dokumen teks menggunakan atribut teks dan grafik. Misalnya, menggunakan jaringan saraf berulang, Anda dapat mengekstraksi item produk dari faktur. Faktur adalah dokumen di mana posisi barang dan deskripsi metode pembayaran untuk barang-barang ini disajikan.

Contoh lain adalah cek. Menggunakan jaringan saraf convolutional, Anda dapat mengambil atribut tunggal, seperti TIN, nomor cek, tanggal-waktu, skor total. Terus terang, kedua metode dan cek digunakan dalam cek dan faktur, tetapi untuk tujuan yang berbeda. Jaringan saraf convolutional baik untuk atribut tunggal yang memiliki semacam posisi, dan jaringan berulang untuk elemen berulang.
Jika dokumen kurang terstruktur, pemrosesan bahasa alami, pemrosesan bahasa alami, atau metode NLP ikut bermain. Mengapa ini sulit? Saya sudah berbicara tentang polisemi kata-kata. Kata alamat, misalnya, dapat berarti alamat perusahaan, atau dapat berarti komitmennya untuk menyelesaikan beberapa masalah pelanggan.
Juga, teks sering dihilangkan, tetapi kata-kata tersirat. Untuk mengekstraksi informasi, Anda perlu memulihkan kata-kata yang hilang ini. Efek dalam linguistik ini disebut "elipsis."
Bahasa beragam, dan biasanya ada banyak cara untuk mengekspresikan satu dan pemikiran yang sama. Untuk memproses teks secara otomatis, penting untuk mengurangi variabilitas ini: penggunaan sinonim dan konstruksi serupa untuk mengganti satu kata atau ungkapan; permutasi kata-kata atau perubahan suara tata bahasa. Misalnya, "perusahaan membuat perjanjian" dan "perjanjian dibuat di antara perusahaan" untuk mengatakan hal yang sama. Dalam kasus sinonim, orang dapat memperkenalkan apa yang disebut ruang semantik, ruang vektor di mana kata-kata direpresentasikan sebagai titik. Poin dekat menunjukkan konsep terkait, poin jauh menunjukkan konsep lebih jauh. Untuk mengurangi variabilitas formulasi, Anda dapat memperkenalkan pohon parse sintaksis dan semantik. Dalam kasus ini, masalah yang sama juga diselesaikan, dan algoritma ekstraksi informasi dapat mengekstraksi informasi, bahkan jika itu menghadapi konstruksi atau kata-kata yang sebelumnya tidak ditemukan dalam set pelatihan.
Bagaimana informasi diekstraksi? Pada tahap pertama, analisis leksikal dokumen dilakukan. Teks ini dibagi menjadi paragraf, paragraf menjadi kalimat, kalimat menjadi kata-kata. Ini mungkin tidak sepele: Anda yang terbiasa dengan NLP mungkin tahu bahwa bahkan tugas yang tampaknya sederhana seperti memecah teks menjadi kalimat bisa sulit: titik tidak selalu menunjukkan akhir kalimat. Ini mungkin singkatan yang tidak diketahui, oleh karena itu, dalam analisis leksikal, kami mencoba untuk memilah semua opsi yang mungkin untuk memecah kalimat menjadi kata-kata dan meninggalkan yang paling mungkin. Masalah ini, sebagai suatu peraturan, kami temui dalam bahasa-bahasa di mana sejumlah kecil atau sama sekali tidak ada ruang, seperti Jepang atau Cina. Atau yang memiliki susunan kata yang kaya. Misalnya, ini adalah bahasa seperti Jerman: ia memiliki kata-kata yang sangat panjang yang terdiri dari beberapa kata (kata-kata seperti itu disebut komposit). Juga, untuk semua kata-kata ini, semua interpretasi yang mungkin dihitung. Misalnya, jika "g" muncul dalam teks dengan titik, itu bisa sangat berarti: kota, tahun, gram, tuan, dan bahkan paragraf keempat (a, b, c, d).

Kemudian dilakukan segmentasi, yaitu pencarian bagian-bagian yang menarik bagi kami. Ini dibuat karena berbagai alasan, misalnya, untuk mempercepat pemrosesan dokumen atau menemukan informasi yang menarik bagi kami; untuk menemukan beberapa bagian dari dokumen yang menjelaskan kewajiban partai. Atau ini adalah percepatan pemrosesan, misalnya, dokumen kami dapat terdiri dari beberapa puluh atau bahkan ratusan halaman dalam kasus-kasus tingkat lanjut, sementara informasi menarik hanya terkandung dalam beberapa halaman. Segmentasi memungkinkan Anda menemukan karya-karya menarik ini dan hanya menganalisisnya. Kemudian, analisis semantik dokumen dapat dilakukan atau tidak dilakukan, tergantung pada tugas, dan pada tahap ini pencarian dilakukan untuk interpretasi kalimat terbaik, semua kalimat dokumen atau hanya yang kita temukan pada tahap sebelumnya. Fitur semantik untuk pengklasifikasi juga dihasilkan pada langkah berikutnya.
Akhirnya, tahap ekstraksi atribut secara langsung. Model yang dilatih mesin digunakan di sini atau pola-pola sederhana ditulis. Dengan satu atau lain cara, mereka bergantung pada tanda yang dihasilkan oleh langkah sebelumnya. Ini adalah fitur struktural, baik leksikal dan semantik. Bergantung pada kerumitan tugas, kami menggunakan banyak metode berbeda: metode pembelajaran mesin dan metode penulisan templat. Pada tahap ini, kami mencari atribut yang menarik bagi kami. Itu bisa berupa nama-nama pihak, kewajiban, tanggal penandatanganan, dll.
Akhirnya, beberapa atribut mungkin memerlukan post-processing. Membawa ke bentuk normal atau casting ke templat tanggal. Beberapa atribut dapat dihitung pada prinsipnya, mereka tidak diekstraksi dari kontrak, tetapi dihitung berdasarkan atribut-atribut yang diekstraksi dari kontrak. Misalnya, durasi kontrak berdasarkan pada awal tindakan dan akhirnya.
Pertimbangkan ini dalam salah satu skenario, yang disebut "Membuka akun dengan badan hukum." Apa tantangannya? Badan hukum, atau lebih tepatnya, perwakilannya, datang ke bank dan membawa setumpuk dokumen. Dalam kasus yang baik, ia telah memindai dokumen-dokumen ini, tetapi tidak jelas dengan kualitas apa. Untuk mengoptimalkan proses, mengurangi jumlah kesalahan dalam memasukkan informasi ini ke dalam sistem, mempercepat proses ini, dan karenanya, mempercepat pengambilan keputusan dan meningkatkan loyalitas pelanggan, skema berikut ini diusulkan:
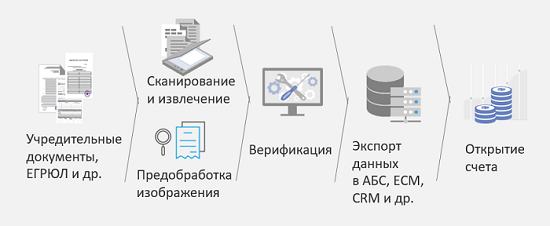
Dokumen konstituen, yang mencakup banyak jenis berbeda, pertama kali dipindai, kemudian dikenali. Selain itu, setelah pengakuan, mereka diklasifikasikan berdasarkan jenis yang berbeda, dan tergantung pada jenisnya, algoritma yang berbeda dapat digunakan untuk mengenali dan mengekstrak informasi. Kemudian informasi yang diekstraksi ini, jika perlu, dikirim ke orang-orang untuk verifikasi, dan setelah itu sudah dimungkinkan untuk membuat keputusan: membuka akun, atau beberapa dokumen tambahan lainnya diperlukan. Hasil utama dari keputusan ini adalah untuk membagi dua biaya entri data saat membuka akun. Hasil berdasarkan pengukuran klien kami.
Atribut apa yang perlu Anda ambil? Banyak hal. Misalkan kita memiliki semacam piagam yang masuk. Pertama kita mengenalinya. Seperti yang kita ingat, ini bisa sangat bermasalah jika itu adalah pemindaian atau foto. Kemudian kami menentukan jenis dokumen, dan ini penting karena informasi yang kami butuhkan dapat dimuat dalam bab atau sub-klausa tertentu, dan oleh karena itu pengetahuan tentang kapan bab atau sub-klausul ini dimulai atau berakhir sangat membantu algoritma ekstraksi informasi.
Kemudian mesin mengambil semua entitas dasar yang dapat dijangkau:
Ini diperlukan agar pada tahap selanjutnya mengekstraksi atribut atau mendefinisikan peran, algoritma tidak hanya dapat menggunakan konteks, tetapi juga karakteristik yang dihasilkan pada tahap sebelumnya. Sebagai contoh, ini dapat sangat menyederhanakan tugas menentukan siapa yang merupakan direktur suatu badan hukum, informasi bahwa ini adalah semacam orang. Dengan demikian, di antara sekumpulan orang yang muncul dalam dokumen, kita harus mengklasifikasikan mereka, direktur atau bukan direktur. Ketika kita memiliki sejumlah objek, ini sangat menyederhanakan tugas.
Selama dua tahun terakhir, kami telah menghadapi beberapa tugas klien dan berhasil menyelesaikannya. Misalnya, pemantauan media untuk risiko perusahaan.
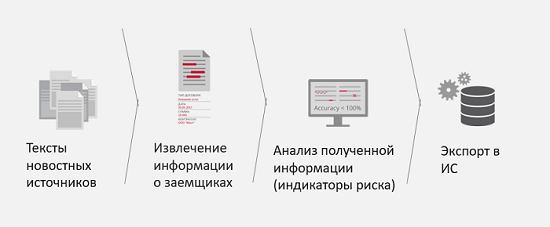
Apa tantangan bisnis di sini? Misalnya, Anda memiliki mitra potensial atau klien yang ingin mengambil pinjaman dari Anda. Untuk mempercepat pemrosesan data klien ini dan mengurangi risiko kemitraan yang buruk, atau kebangkrutan badan hukum ini di masa mendatang, disarankan agar media dimonitor untuk referensi ke individu atau badan hukum ini dan untuk kehadiran apa yang disebut indikator risiko dalam berita. Yaitu, jika, misalnya, dalam berita selalu muncul bahwa badan hukum terlibat dalam proses hukum atau perusahaan dipecah oleh konflik pemegang saham, lebih baik untuk mengetahuinya lebih awal untuk meneruskan informasi ini kepada analis atau sistem analisis dan memahami seberapa buruk atau baiknya bisnis Anda . Hasil dari penyelesaian masalah ini adalah mendapatkan informasi yang lebih lengkap dan akurat tentang peminjam, dan jumlah waktu untuk mendapatkan informasi ini juga berkurang.

Contoh lain dari aplikasi di mana perlu untuk mengurangi jumlah rutin dan jumlah kesalahan saat memasukkan informasi ke dalam sistem adalah ekstraksi data dari kontrak. Diusulkan agar kontrak mengenali, mengekstrak informasi dari mereka dan mengirimkannya segera ke sistem. Setelah itu, departemen personalia mengucapkan terima kasih dengan penuh air mata dan hangat menyambut Anda di setiap pertemuan.
Departemen sumber daya manusia tidak hanya menderita dari banyak pekerjaan rutin dengan dokumentasi yang masuk, tetapi juga departemen akuntansi, departemen penjualan, dan departemen pembelian. Karyawan harus menghabiskan banyak waktu memasukkan informasi dari faktur, tindakan masuk, dan sebagainya.
Bahkan, semua dokumen ini terstruktur, dan karena itu mudah untuk mengenali dan mengekstrak informasi dari mereka. Kecepatan entri data meningkat hingga 5 kali, dan jumlah kesalahan berkurang, karena faktor manusia dikecualikan. Dengan syarat, jika seorang karyawan kembali setelah makan siang, ia mungkin mulai memasukkan data tanpa perhatian. , , , , , , 95%, 90%. , , .
- , – , - – , , , : «, ». , . : , .
, .
. -, , , , , . -, , , , , , , , .. , , , - .
, , , , .
. , Excel, , , - . .
, , , , , , . , . Terima kasih