
Toko online Ozon memiliki segalanya: lemari es, makanan bayi, laptop seharga 100.000, dll. Ini berarti bahwa semua ini juga ada di gudang perusahaan - dan semakin lama barang ada, semakin mahal perusahaan tersebut. Untuk mengetahui berapa banyak dan apa yang ingin dipesan orang, dan Ozon perlu membeli, kami menggunakan pembelajaran mesin.
Prakiraan Penjualan: Tantangan
Sebelum mempelajari pernyataan masalah, kita mulai dengan sebuah contoh. Ini adalah jadwal penjualan Ozon yang sebenarnya untuk sementara waktu. Pertanyaan: kemana dia akan pergi selanjutnya?
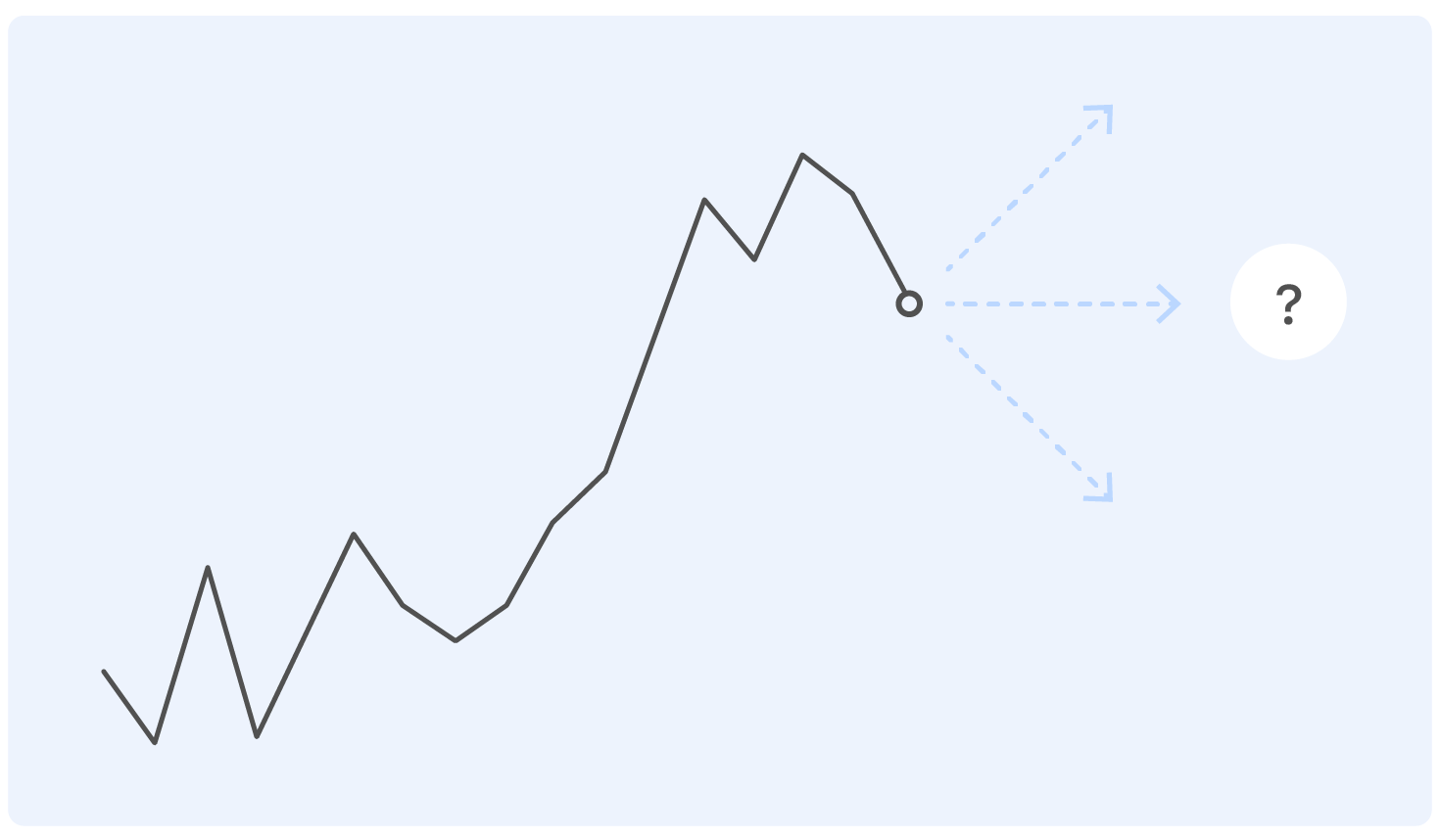
Seseorang dengan pendidikan yang hampir teknis untuk perumusan masalah akan memiliki pertanyaan: Di mana kapak? Dan produk apa? Dan di unit apa? Dari institusi mana Anda lulus? - dan banyak lainnya yang tidak termasuk dalam artikel ini karena alasan etis.
Bahkan, tidak ada yang bisa menjawab pertanyaan dengan benar dalam pernyataan seperti itu, dan jika seseorang bisa, maka kemungkinan besar dia akan salah.
Tambahkan beberapa informasi lebih lanjut ke bagan ini: sumbu dan perubahan harga di situs web Ozon (biru) dan situs web pesaing (oranye).
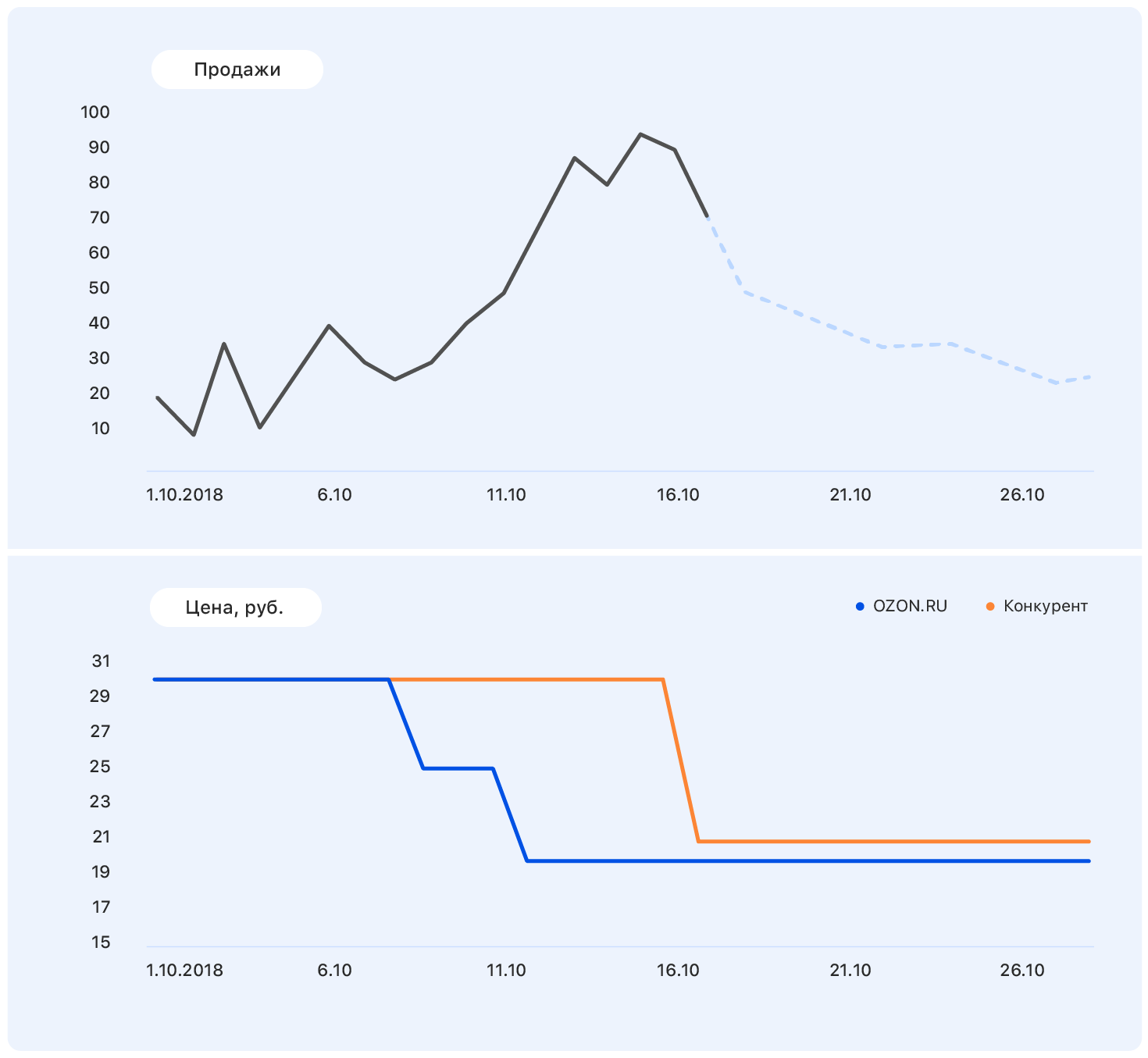
Harga kami turun di beberapa titik, tetapi persaingan tetap sama - dan penjualan Ozon naik. Kita tahu rencana penetapan harga: harga kita akan tetap pada tingkat yang sama, tetapi pesaing, mengikuti Ozon, menurunkan harganya ke hampir kita.
Data ini cukup untuk membuat asumsi yang bermakna - misalnya, bahwa penjualan akan kembali ke tingkat sebelumnya. Dan jika Anda melihat grafiknya, ternyata memang demikian.
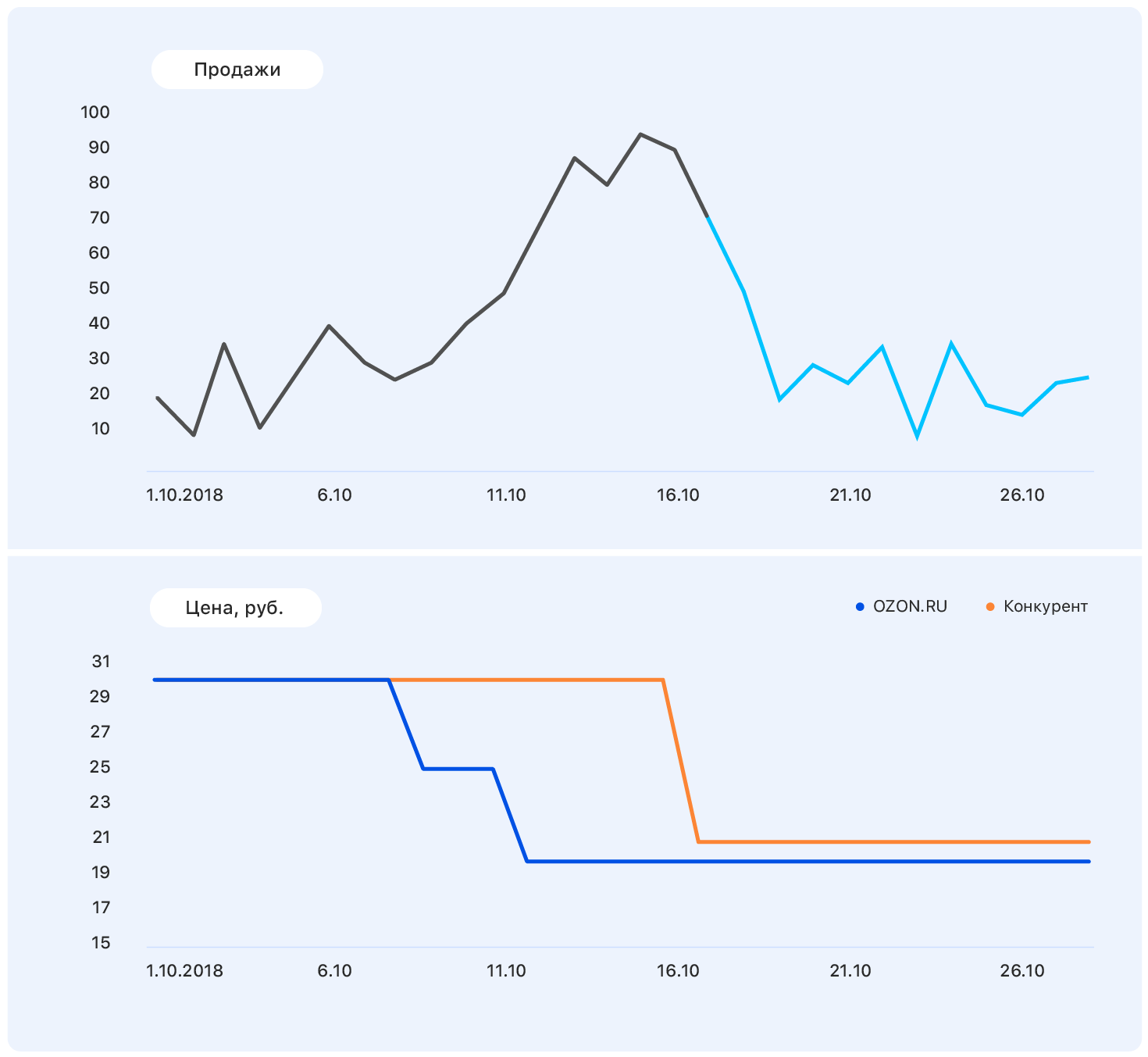
Masalahnya adalah bahwa pada kenyataannya, permintaan untuk produk ini tidak begitu banyak dipengaruhi oleh harga, dan pertumbuhan penjualan disebabkan, antara lain, oleh tidak adanya sebagian besar pesaing produk ini di toko kami. Masih ada banyak faktor yang tidak kami perhitungkan: apakah barang diiklankan di TV? atau mungkin itu manis, dan segera 8 Maret?
Satu hal yang jelas: membuat ramalan "berlutut" tidak akan berhasil. Kami mengikuti jalur standar
rake dan kruk untuk membangun algoritma ML. Dan begitulah adanya.
Pemilihan Metrik
Memilih metrik adalah tempat untuk memulai jika setidaknya satu orang selain Anda akan menggunakan perkiraan Anda.
Pertimbangkan sebuah contoh: kami memiliki tiga opsi perkiraan. Mana yang lebih baik?
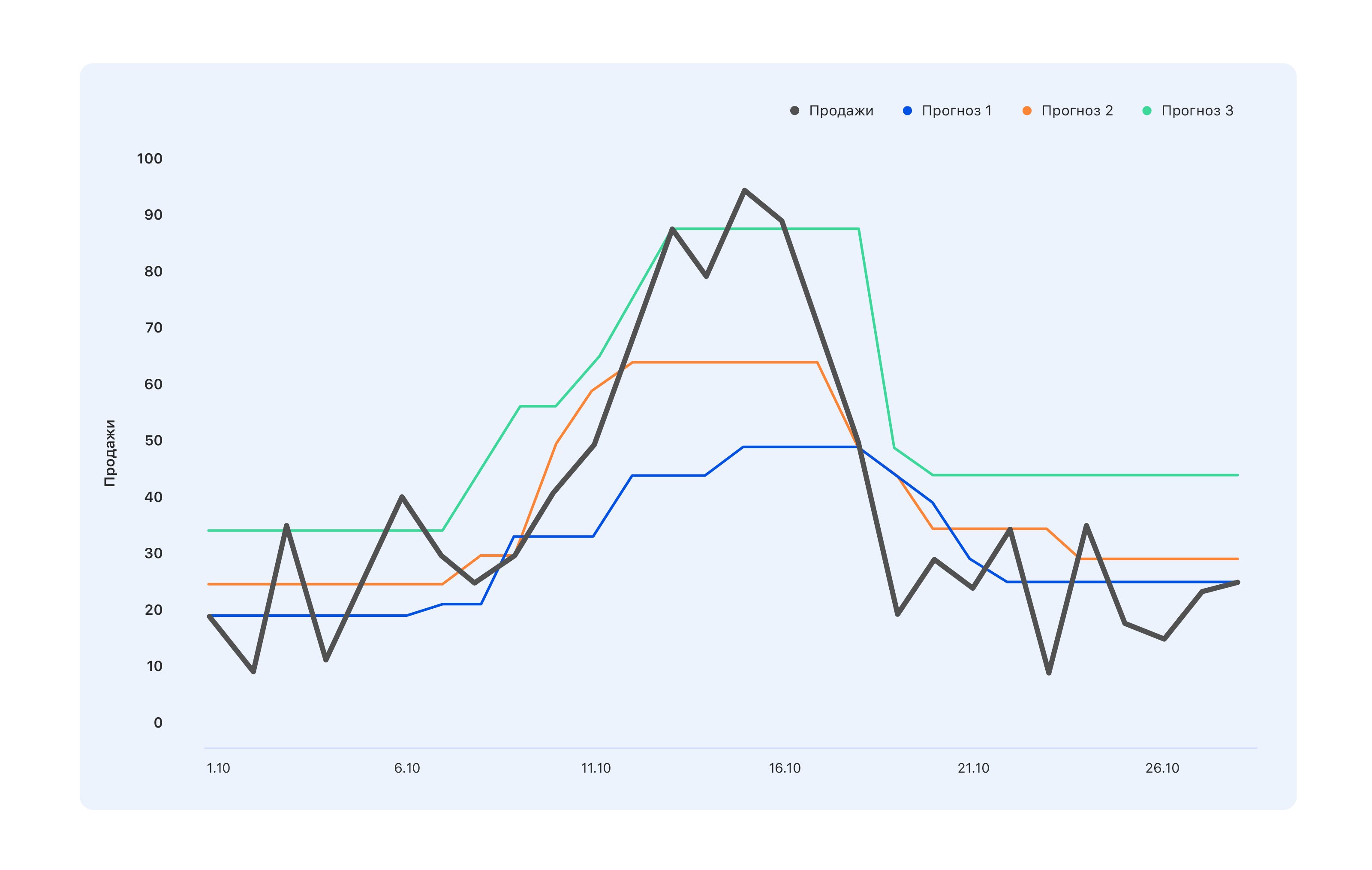
Dari sudut pandang spesialis di gudang, kami membutuhkan perkiraan biru - kami akan membeli sedikit lebih sedikit, dan biarkan kami melewatkan puncaknya pada pertengahan Oktober, tetapi tidak ada yang tersisa di gudang. Para ahli yang terikat KPI dengan penjualan memiliki pendapat yang berlawanan: bahkan perkiraan turquoise tidak cukup benar, tidak semua lompatan permintaan telah tercermin - lanjutkan memodifikasinya. Tetapi dari sudut pandang seseorang, dari luar, sesuatu yang lebih baik umumnya teratur - sehingga semua orang akan merasa baik atau sebaliknya.
Karena itu, sebelum membuat perkiraan, perlu untuk menentukan siapa yang akan menggunakannya dan mengapa. Yaitu, pilih metrik dan pahami apa yang diharapkan dari ramalan yang dibangun di atas metrik tersebut. Dan tunggu saja.
Kami memilih MAE - kesalahan absolut rata-rata. Metrik ini cocok untuk sampel pelatihan kami yang sangat tidak seimbang. Karena bermacam-macam sangat luas (1,5 juta item), setiap produk secara individual di wilayah tertentu dijual dalam jumlah kecil. Dan jika secara total kami menjual ratusan gaun hijau, maka gaun hijau khusus dengan kucing dijual dengan harga 2-3 per hari. Akibatnya, sampel bergeser ke nilai yang kecil. Di sisi lain, ada iPhone, pemintal, buku baru karya Olga Buzova (lelucon), dll. - dan mereka dijual di kota mana pun dalam jumlah besar. MAE memungkinkan Anda untuk tidak mendapatkan denda besar pada iPhone bersyarat dan umumnya bekerja dengan baik pada sebagian besar barang.
Langkah pertama
Kami mulai dengan membuat ramalan paling bodoh yang bisa berupa: angka acak dari 0 hingga 1000 akan dijual selama minggu depan dan mendapatkan metrik MAE = 496. Mungkin, ini bisa lebih buruk, tetapi ini sudah sangat buruk. Jadi kami mendapat pedoman: jika kami mendapatkan nilai metrik yang demikian, maka jelas kami melakukan sesuatu yang salah.
Kemudian kami mulai bermain orang-orang yang tahu cara membuat perkiraan tanpa pembelajaran mesin, dan mencoba memprediksi penjualan barang selama minggu depan sama dengan penjualan rata-rata untuk semua minggu terakhir, dan mendapatkan metrik MAE = 1,45 - yang jauh lebih baik.
Melanjutkan dengan alasan, kami memutuskan bahwa penjualan minggu lalu tidak akan lebih relevan untuk memperkirakan penjualan untuk minggu berikutnya. Untuk perkiraan seperti itu, MAE adalah 1,26. Pada putaran pemikiran prognostik berikutnya, kami memutuskan untuk memperhitungkan kedua faktor dan memperkirakan penjualan untuk minggu berikutnya sebagai jumlah 50% dari penjualan rata-rata dan 50% dari penjualan selama seminggu terakhir - kami mendapat MAE = 1,23.
Tapi bagi kami itu kelihatannya terlalu sederhana, dan kami memutuskan untuk mempersulit. Kami mengumpulkan sampel pelatihan kecil di mana tanda-tanda sudah lewat dan penjualan rata-rata, dan targetnya adalah penjualan selama minggu berikutnya, dan kami melatihnya dengan regresi linier sederhana. Kami mendapat bobot 0,46 dan 0,55 untuk rata-rata dan minggu terakhir dan MAE pada sampel uji sama dengan 1,2.
Kesimpulan: data kami memiliki potensi prediksi.
Rekayasa fitur
Setelah memutuskan bahwa membuat ramalan dengan dua alasan bukanlah level kami, kami duduk untuk menghasilkan fitur kompleks yang baru. Ini adalah informasi tentang penjualan sebelumnya - 1, 2, 3, 4 minggu lalu, seminggu tepat setahun yang lalu, dll. Dan tampilan selama beberapa minggu terakhir, penambahan ke keranjang, konversi tampilan dan penambahan ke keranjang dalam pesanan - dan semua ini untuk periode yang berbeda.
Kami perlu memberikan model pengetahuan tentang bagaimana produk secara keseluruhan dijual, bagaimana dinamika penjualannya telah berubah belakangan ini, bagaimana minat di dalamnya berkembang, bagaimana penjualannya bergantung pada harga dan faktor-faktor lain yang, menurut pendapat kami, dapat bermanfaat.
Ketika ide-ide kami habis, kami pergi ke ahli departemen penjualan. Di sana, misalnya, kami belajar bahwa tahun berikutnya adalah tahun babi, oleh karena itu, barang-barang yang setidaknya menyerupai babi akan sangat populer. Atau, misalnya, bahwa "tidak beku" yang tidak dibeli orang-orang kami sebelumnya, tetapi tepat pada hari salju pertama - jadi harap, perhitungkan ramalan cuaca. Secara umum, semua orang puas. Kami - karena kami menerima banyak ide baru yang tidak akan pernah kami pikirkan tentang diri kami, dan pengusaha - bahwa segera mungkin untuk melakukan sesuatu yang lebih menarik daripada perkiraan penjualan.
Tapi itu masih terlalu sederhana - dan kami telah menambahkan gejala gabungan:
- konversi dari tampilan ke penjualan - bagaimana itu, bagaimana itu berubah;
- rasio penjualan lebih dari 4 minggu dengan penjualan selama seminggu terakhir (jika angka ini sangat berbeda dari 4, saat ini permintaan untuk produk ini tunduk pada "turbulensi");
- rasio penjualan produk dengan penjualan di seluruh kategori - jika angka ini mendekati satu, maka produk tersebut adalah "perusahaan monopoli".
Pada tahap ini, Anda harus membuat sebanyak mungkin - membuang tanda-tanda non-informatif di tahap pelatihan.
Hasilnya, kami mendapat 170 tanda. Ke depan, fitur terpenting yang dimiliki
- Penjualan selama seminggu terakhir (untuk dua, tiga dan empat).
- Ketersediaan produk minggu lalu adalah persentase waktu produk hadir di situs.
- Koefisien sudut jadwal penjualan barang selama 7 hari terakhir.
- Rasio harga masa lalu ke masa depan - dengan diskon besar, mulai membeli barang lebih aktif.
- Jumlah pesaing langsung dalam situs kami. Jika, misalnya, pena ini adalah satu-satunya dalam kategorinya, penjualan akan cukup stasioner.
- Dimensi produk - ternyata panjang dan lebar secara signifikan memengaruhi prediktabilitas penjualan. Untuk beberapa alasan, untuk objek yang panjang dan sempit - payung atau pancing, misalnya - jadwalnya jauh lebih tidak stabil. Kami belum tahu bagaimana menjelaskannya.
- Jumlah hari dalam setahun - ini menunjukkan apakah Tahun Baru akan datang, 8 Maret, awal kenaikan musiman dalam penjualan, dll.
Sampling
Sampel pelatihan adalah nyeri. Kami mengumpulkannya selama sekitar 4 minggu, dua di antaranya hanya pergi ke penjaga data yang berbeda dan meminta untuk melihat apa yang mereka miliki. Ini terjadi setiap kali Anda membutuhkan data untuk jangka waktu yang lama. Bahkan dalam sistem pengumpulan data yang ideal, untuk waktu yang lama, sesuatu akan terjadi dalam semangat "kami dulu berpikir seperti ini, tapi kemudian kami mulai berpikir secara berbeda dan menulis data dalam kolom yang sama". Atau satu atau dua tahun lalu server macet, tetapi tidak ada yang menuliskan kapan tepatnya - dan nol tidak lagi berarti bahwa tidak ada penjualan.
Akibatnya, kami mendapat informasi tentang apa yang dilakukan orang di situs, apa, dan dalam jumlah berapa, mereka ditambahkan ke favorit dan keranjang, dan dibeli. Kami mengumpulkan sampel sekitar 15 juta sampel masing-masing 170 fitur, targetnya adalah jumlah penjualan untuk minggu depan.
Kami menulis 2 ribu baris kode di Spark. Ini bekerja lambat, tetapi memungkinkan untuk mengunyah sejumlah besar data. Sepertinya menghitung kemiringan garis lurus itu sederhana. Dan untuk melakukannya 10kk kali ketika penjualan ditarik dari beberapa pangkalan - tugasnya bukan untuk menjadi lemah hati.
Untuk satu minggu lagi, kami terlibat dalam pembersihan data sehingga model tersebut tidak terganggu oleh emisi dan fitur pengambilan sampel lokal, tetapi hanya mengekstraksi ketergantungan nyata yang melekat dalam penjualan Ozon. Di sini 3 sigma dan lebih banyak metode licik untuk mencari anomali akan muncul. Kasus yang paling sulit adalah mengembalikan penjualan selama periode kekurangan barang dalam persediaan. Solusi paling sederhana adalah membuang minggu-minggu ketika produk keluar selama minggu "target".
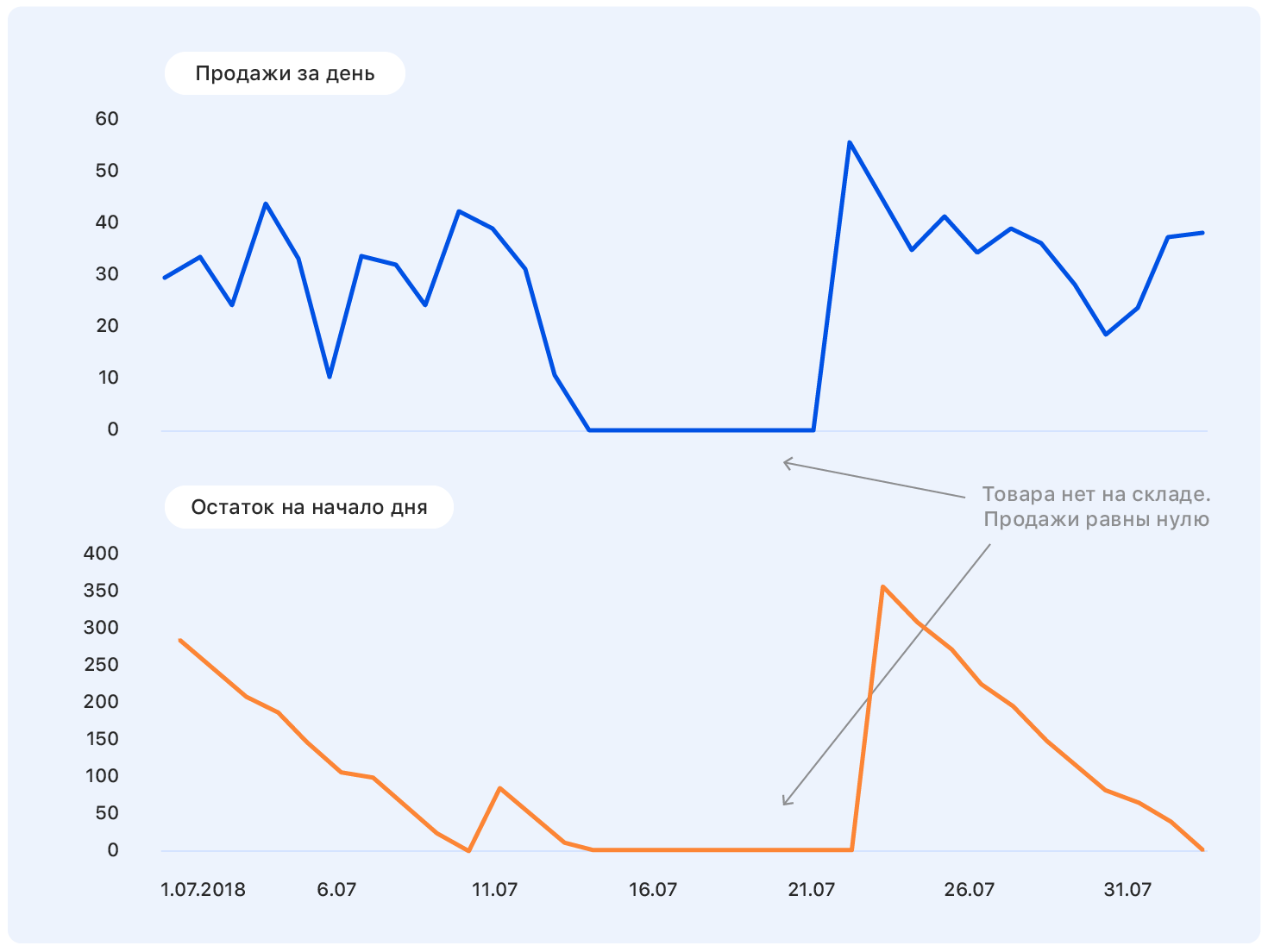
Akibatnya, dari 15 juta sampel, 10 juta tetap. Penting di sini untuk tidak terbawa dan tidak kehilangan kelengkapan sampel (pada kenyataannya, kurangnya barang di gudang adalah karakteristik tidak langsung dari pentingnya bagi perusahaan; mengeluarkan barang-barang dari sampel tidak sama dengan membuang sampel acak) )
Waktu ML
Pada sampel yang bersih dan mulai melatih model. Secara alami, kami mulai dengan regresi linier dan mendapat MAE = 1,15. Tampaknya ini adalah peningkatan yang sangat kecil, tetapi ketika Anda memiliki sampel 10 juta di mana nilai rata-rata 5-10, bahkan perubahan kecil dalam nilai metrik memberikan peningkatan yang tidak dapat dibandingkan dalam kualitas visual perkiraan. Dan karena Anda pada akhirnya harus menghadirkan solusi untuk pelanggan bisnis, meningkatkan tingkat kegembiraan mereka adalah faktor penting.
Berikutnya adalah sklearn.ensemble.RandomForestRegressor, yang setelah pemilihan singkat hyperparameters menunjukkan MAE = 1,10. Selanjutnya kami mencoba XGBoost (di mana tanpanya) - semuanya akan baik-baik saja dan MAE = 1.03 - hanya dalam waktu yang sangat lama. Sayangnya, kami tidak memiliki akses ke GPU untuk pelatihan XGBoost, dan pada prosesor, satu model dilatih untuk waktu yang sangat lama. Kami mencoba menemukan sesuatu yang lebih cepat, dan menggunakan LightGBM - ia berlatih dua kali lebih cepat dan menunjukkan MAE bahkan sedikit kurang - 1,01.
Kami membagi semua produk menjadi 13 kategori, seperti dalam katalog di situs: tabel, laptop, botol, dan untuk setiap kategori kami melatih model dengan kedalaman perkiraan yang berbeda - dari 5 hingga 16 hari.
Pelatihan ini memakan waktu sekitar lima hari, dan untuk ini kami meningkatkan cluster komputasi besar. Kami mengembangkan saluran pipa seperti itu: pencarian acak bekerja untuk waktu yang lama, memberikan 10 set hyperparameter teratas, dan kemudian ilmuwan bekerja dengan mereka secara manual - membangun metrik kualitas tambahan (kami menghitung MAE untuk rentang target yang berbeda), membangun kurva belajar (misalnya, kami membuang sebagian pelatihan) sampel dan dilatih lagi, memeriksa untuk melihat apakah data baru mengurangi kerugian pada sampel uji) dan grafik lainnya.
Contoh analisis terperinci untuk salah satu set hiperparameter:
Metrik kualitas terperinciSet kereta:
| Set tes:
|
| Untuk target = 0, MAE = 0.142222484602 | Untuk 0 MAE = 0.141900737761 |
| Untuk target> 0, MAPE = 45.168530676 | Untuk> 0 MAPE = 45.5771812826 |
| Kesalahan lebih besar dari 0 - 67,931341691% | Kesalahan lebih besar dari 0 - 51.6405939896% |
| Kesalahan lebih besar dari 1 - 19.0346986379% | Kesalahan lebih besar dari 1 - 12.1977096603% |
| Kesalahan lebih dari 2 - 8,94313926245% | Kesalahan lebih dari 2 - 5,16977226441% |
| Kesalahan lebih dari 3 - 5,42406856507% | Kesalahan lebih dari 3 - 3,12760834969% |
Kesalahan lebih dari 4 - 3,67938161595%
| Kesalahan lebih dari 4 - 2,10263125679% |
Kesalahan lebih dari 5 - 2,67322988948%
| Kesalahan lebih dari 5 - 1,56473158807%
|
Kesalahan lebih dari 6 - 2,0618556701%
| Kesalahan lebih dari 6 - 1,19599209102%
|
| Kesalahan lebih dari 7 - 1,65887701209% | Kesalahan lebih besar dari 7 - 0,949300173983%
|
Kesalahan lebih dari 8 - 1,36821095777%
| Kesalahan lebih dari 8 - 0,78310772461% |
| Kesalahan lebih dari 9 - 1,15368611519% | Kesalahan lebih besar dari 9 - 0,659205318158%
|
| Kesalahan lebih dari 10 - 0,99199395014% | Kesalahan lebih dari 10 - 0,554593106723% |
| Kesalahan lebih dari 11 - 0,863969667827% | Kesalahan lebih dari 11 - 0,490045146476%
|
Kesalahan lebih dari 12 - 0,764347266082%
| Kesalahan lebih dari 12 - 0,428835873827%
|
| Kesalahan lebih dari 13 - 0,68086818247% | Kesalahan lebih dari 13 - 0,386545830907%
|
| Kesalahan lebih dari 14 - 0,613446089087% | Kesalahan lebih dari 14 - 0,343884822697%
|
Kesalahan lebih dari 15 - 0,556297016335%
| Kesalahan lebih dari 15 - 0,316433391328%
|
Untuk target = 0, MAE = 0.142222484602
| Untuk target = 0, MAE = 0.141900737761
|
Untuk target = 1, MAE = 0,63978556493
| Untuk target = 1, MAE = 0,660823509405 |
| Untuk target = 2, MAE = 1.01528075312 | Untuk target = 2, MAE = 1.01098070566 |
| Untuk target = 3, MAE = 1.43762342295 | Untuk target = 3, MAE = 1.44836233499 |
Untuk target = 4, MAE = 1.82790678437
| Untuk target = 4, MAE = 1.86539223382
|
Untuk target = 5, MAE = 2.15369976552
| Untuk target = 5, MAE = 2.16017884573 |
Untuk target = 6, MAE = 2.51629758129
| Untuk target = 6, MAE = 2.51987403661
|
Untuk target = 7, MAE = 2.80225497415
| Untuk target = 7, MAE = 2.97580015564
|
Untuk target = 8, MAE = 3.09405048248
| Untuk target = 8, MAE = 3.21914648525
|
Untuk target = 9, MAE = 3.39256765159
| Untuk target = 9, MAE = 3.54572928241
|
| Untuk target = 10, MAE = 3.6640339953 | Untuk target = 10, MAE = 3.84409605282
|
Untuk target = 11, MAE = 4.02797747118
| Untuk target = 11, MAE = 4.21828735273
|
Untuk target = 12, MAE = 4.17163467899
| Untuk target = 12, MAE = 3,92536509115
|
Untuk target = 14, MAE = 4.78590364522
| Untuk target = 14, MAE = 5.11290428675 |
Untuk target = 15, MAE = 4.89409916994
| Untuk target = 15, MAE = 5.20892023117
|
Kehilangan kereta = 0,535842111392
Kehilangan uji = 0,895529959873
Prediksi grafik (target) untuk set pelatihan Prediksi grafik (target) untuk sampel uji Kesalahan prediksi dari waktu ke waktu Urutkan kesalahan naik pada sampel uji Jika tidak ada yang cocok, cari lagi secara acak. Inilah cara kami melatih model selama 5 atau 5 hari dengan kecepatan industri. Kami sedang bertugas, seseorang di malam hari, seseorang bangun di pagi hari, melihat 10 parameter teratas, memulai kembali atau menyelamatkan model dan pergi tidur lebih jauh. Dalam mode ini, kami bekerja selama seminggu dan melatih 130 model - 13 jenis barang dan 10 kedalaman perkiraan, masing-masing memiliki 170 fitur. MAE rata-rata untuk seri waktu 5 kali lipat cv yang kami dapatkan sama dengan 1.
Mungkin terlihat bahwa ini tidak terlalu keren - dan memang demikian, kecuali jika Anda memiliki bagian besar dalam pemilihan unit. Sebagai analisis hasil menunjukkan, unit diprediksi terburuk dari semua - fakta bahwa suatu produk dibeli seminggu sekali tidak mengatakan apa-apa tentang apakah ada permintaan untuk itu. Setelah apa pun dapat dijual - ada seseorang yang akan membeli patung porselen dalam bentuk dokter gigi, dan ini tidak mengatakan apa-apa tentang penjualan di masa depan atau tentang yang di masa lalu. Secara umum, kami tidak menjadi sangat sedih tentang hal ini.
Kiat dan trik
Apa yang salah dan bagaimana ini bisa dihindari?
Masalah pertama adalah pemilihan parameter. Kami mulai menggunakan RandomizedSearchCV - alat yang terkenal dari sklearn untuk menyortir hiperparameter. Di sinilah kejutan pertama menunggu kita.
Seperti inifrom sklearn.model_selection import ParameterSampler
from sklearn.model_selection import RandomizedSearchCV
estimator = lightgbm.LGBMRegressor(application='regression_l1', is_training_metric = True, objective = 'regression_l1', num_threads=72)
param_grid = {'boosting_type': boosting_type, 'num_leaves': num_leaves, 'max_depth': max_depth, 'learning_rate':learning_rate, 'n_estimators': n_estimators, 'subsample_for_bin': subsample_for_bin, 'min_child_samples': min_child_samples, 'colsample_bytree': colsample_bytree, 'reg_alpha': reg_alpha, 'max_bin': max_bin}
rscv = RandomizedSearchCV(estimator, param_grid, refit=False, n_iter=100, scoring='neg_mean_absolute_error', n_jobs=1, cv=10, verbose=3, pre_dispatch='1*n_jobs', error_score=-1, return_train_score='warn')
rscv .fit(X_train.values, y_train['target'].values)
print('Best parameters found by grid search are:', rscv.best_params_)
Perhitungannya hanya berhenti (yang penting, tidak jatuh, tetapi terus bekerja, tetapi pada jumlah inti yang lebih kecil dan pada titik tertentu itu hanya berhenti).
Saya harus memparalelkan proses karena RandomizedSearchCVestimator = lightgbm.LGBMRegressor(application='regression_l1', is_training_metric = True, objective = 'regression_l1', num_threads=1)
rscv = RandomizedSearchCV(estimator, param_grid, refit=False, n_iter=100, scoring='neg_mean_absolute_error', n_jobs=72, cv=10, verbose=3, pre_dispatch='1*n_jobs', error_score=-1, return_train_score='warn')
rscv .fit(X_train.values, y_train['target'].values)
print('Best parameters found by grid search are:', rscv.best_params_)
Tapi RandomizedSearchCV meraih hampir seluruh dataset untuk setiap "pekerjaan". Oleh karena itu, perlu untuk memperluas jumlah RAM, mungkin mengorbankan jumlah core.
Siapa yang akan memberi tahu kami tentang hal-hal luar biasa seperti hyperopt! Karena kami belajar, kami hanya menggunakannya.
Trik lain yang muncul di benak kami menjelang akhir proyek adalah memilih model yang memiliki parameter colsample_bytree (ini adalah parameter LightGBM, yang mengatakan berapa persen fitur yang harus diberikan kepada setiap lerner) di wilayah 0,2-0,3, karena ketika mobil Ini berfungsi dalam produksi, mungkin tidak ada tabel, dan fitur individual mungkin tidak dihitung dengan benar. Pengaturan seperti itu memungkinkan Anda untuk memastikan bahwa fitur-fitur yang tidak terhitung ini memengaruhi setidaknya tidak semua lerner dalam model.
Secara empiris, kita sampai pada kesimpulan bahwa kita perlu melakukan lebih banyak penaksir dan memutar peraturan menjadi lebih sulit. Ini bukan aturan kerja dengan LightGBM, tetapi skema seperti itu berhasil bagi kami.
Yah dan, tentu saja, Spark. Misalnya, ada bug yang diketahui Spark: jika Anda mengambil beberapa kolom dari sebuah tabel dan membuat yang baru, dan kemudian mengambil yang lain dari tabel yang sama dan membuat yang baru, dan kemudian menyetel tabel yang Anda terima, semuanya akan pecah, meskipun seharusnya tidak. Anda dapat diselamatkan hanya dengan menyingkirkan semua perhitungan malas. Kami bahkan menulis fungsi khusus - bumb_df, mengubah Bingkai Data menjadi RDD kembali menjadi Bingkai Data. Artinya, me-reset semua perhitungan malas. Ini dapat melindungi diri Anda dari sebagian besar masalah Spark.
bumb_dfdef bump_df(df):
# to avoid problem: AnalysisException: resolved attribute(s)
df_rdd = df.rdd
if df_rdd.isEmpty():
df = df_rdd.toDF(schema=df.schema)
return df
else:
return df_rdd.toDF(schema=df.schema)
Ramalan sudah siap: berapa banyak yang akan kami pesan?
Peramalan penjualan adalah murni tugas matematika, dan jika distribusi normal kesalahan nol-rata adalah kemenangan bagi ahli matematika, maka bagi pedagang yang memiliki setiap rubel di akun mereka, ini tidak dapat diterima.
Jika satu iPhone tambahan atau satu pakaian modis di gudang tidak menjadi masalah, tetapi lebih merupakan stok asuransi, maka tidak adanya iPhone yang sama di gudang adalah kehilangan setidaknya margin, dan sebagai maksimum gambar, dan ini tidak dapat diizinkan.
Untuk mengajarkan algoritma membeli sebanyak yang diperlukan, kami harus menghitung biaya pembelian kembali dan pembelian di bawah setiap produk dan melatih model sederhana untuk meminimalkan kemungkinan kerugian dalam uang.
Model menerima perkiraan penjualan pada input, menambahkan suara acak, yang terdistribusi normal ke input tersebut (kami mensimulasikan ketidaksempurnaan pemasok), dan belajar untuk menambahkan sebanyak mungkin perkiraan untuk setiap produk tertentu untuk meminimalkan kerugian uang.
Dengan demikian, pesanan adalah persediaan + prakiraan keamanan, yang menjamin jangkauan kesalahan prakiraan dan ketidaksempurnaan dunia luar.
Seperti dalam prod
Ozon memiliki kluster komputasi yang agak besar sendiri, di mana setiap malam sebuah pipa (kami menggunakan aliran udara) dari lebih dari 15 pekerjaan diluncurkan. Ini terlihat seperti ini:

Setiap malam, algoritma diluncurkan, menarik sekitar 20 GB data dari berbagai sumber ke HDF lokal, memilih pemasok untuk setiap produk, mengumpulkan fitur untuk setiap produk, membuat perkiraan penjualan dan menghasilkan pesanan berdasarkan jadwal pengiriman. Pada 6-7 pagi, kami memberikan kepada orang-orang meja yang bertanggung jawab untuk bekerja dengan pemasok meja siap pakai yang terbang dengan mengklik tombol ke pemasok.
Tidak ada satu pun ramalan
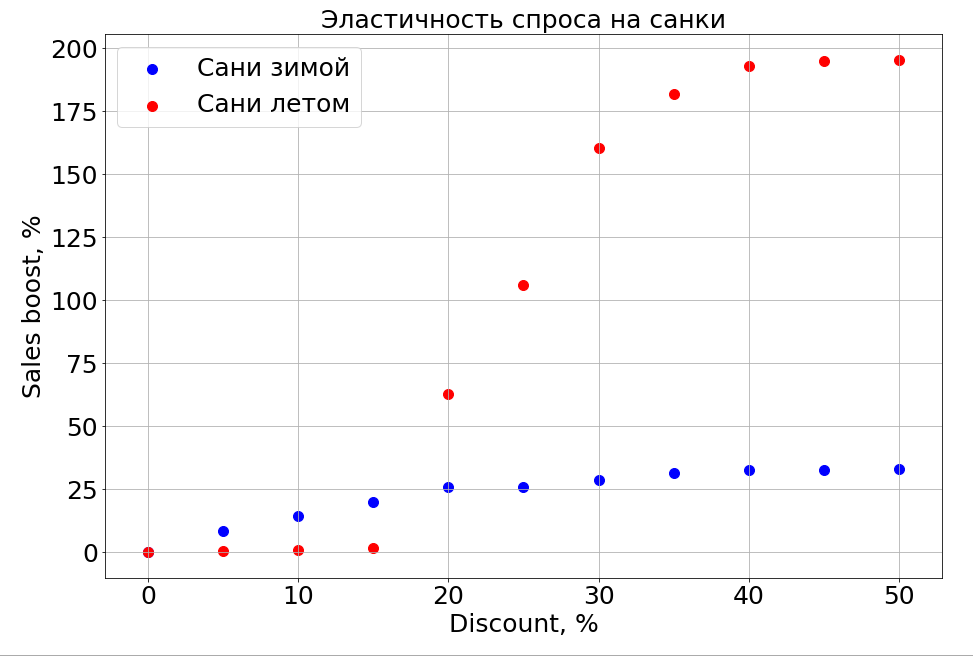
Model yang terlatih tahu tentang ketergantungan prakiraan pada fitur apa pun dan, sebagai hasilnya, jika Anda membekukan tanda N-1 dan mulai mengubahnya, Anda dapat mengamati bagaimana hal itu memengaruhi prakiraan. Tentu saja, hal yang paling menarik tentang ini adalah bagaimana penjualan bergantung pada harga.
Penting untuk dicatat bahwa permintaan tidak hanya bergantung pada harga. Misalnya, jika Anda membuat diskon kecil untuk kereta luncur di musim panas, itu tetap tidak membantu mereka menjual. Kami membuat diskon lebih banyak, dan orang-orang muncul yang "menyiapkan kereta luncur di musim panas." Tetapi sampai tingkat diskon tertentu, kita masih tidak dapat mencapai bagian otak yang bertanggung jawab untuk perencanaan. Di musim dingin, ia berfungsi seperti untuk produk apa pun - Anda membuat diskon dan menjualnya lebih cepat.
Paket
Sekarang kami secara aktif mempelajari pengelompokan deret waktu untuk mendistribusikan barang di antara kluster berdasarkan sifat kurva yang menggambarkan penjualan mereka. Misalnya, musiman, populer secara tradisional di musim panas atau, sebaliknya, di musim dingin. Saat kami mempelajari cara memisahkan produk dengan riwayat penjualan yang panjang, kami berencana untuk menyoroti fitur berbasis item yang akan memberi tahu Anda seperti apa pola penjualan untuk produk yang baru saja muncul - untuk saat ini, ini adalah tugas utama kami.
Jaringan saraf, dan model parametrik deret waktu, dan semua ini dalam ansambel, pasti akan lebih jauh.
Khususnya, berkat sistem peramalan yang baru, Ozon beralih dari pembelian barang dengan stok ke pengiriman siklus, ketika kami membeli dari satu suplai ke suplai lain dan tidak menyimpan saldo dalam stok.
Sekarang kita harus memutuskan bagaimana cara mengajarkan algoritma untuk memprediksi penjualan produk baru dan seluruh kategori. Tahun depan, perusahaan berencana untuk meningkatkan penjualan x10 dalam kategori dan x2.5 di bidang pemenuhan. Dan kita perlu memberi tahu para model bahwa data lama ini relevan, tetapi untuk toko sebelumnya yang berbeda. Dan sementara kami berpikir bagaimana melakukannya.
Yang kedua secara alami hal yang tidak rasional yang harus kita pelajari untuk diprediksi adalah mode. Bagaimana orang bisa memprediksi bahwa seorang pemintal akan menjual seperti itu? Bagaimana cara memprediksi penjualan buku baru Dan Brown jika salah satu bukunya terjual habis dan yang lainnya tidak? Sementara kami sedang mengerjakannya.
Jika Anda tahu cara melakukan yang lebih baik, atau Anda memiliki cerita tentang menggunakan pembelajaran mesin dalam pertempuran di komentar, kami akan membahasnya.