Entri
Sebagai bagian dari program pinjaman, bank bekerja sama dengan banyak toko ritel.
Salah satu elemen kunci dari aplikasi pinjaman adalah foto peminjam - agen toko mitra memotret pembeli; foto semacam itu jatuh ke dalam "file pribadi" klien dan digunakan di masa depan sebagai salah satu cara untuk mengkonfirmasi kehadirannya pada saat mengajukan pinjaman.
Sayangnya, selalu ada risiko perilaku tidak jujur dari seorang agen yang dapat mentransfer foto yang tidak akurat ke bank - misalnya, gambar pelanggan dari jejaring sosial atau paspor.
Biasanya, bank menyelesaikan masalah ini dengan memverifikasi karyawan kantor foto melihat foto dan mencoba mengidentifikasi gambar yang tidak akurat.
Kami ingin mencoba mengotomatiskan proses dan memecahkan masalah menggunakan jaringan saraf.
Formalisasi tugas
Kami hanya memeriksa foto di mana ada orang. Gambar tanpa wajah dapat
dipotong menggunakan perpustakaan
Dlib terbuka.
Untuk lebih jelasnya, kami memberikan contoh foto (pegawai bank digambarkan):
 Gambar 1. Foto dari titik penjualan
Gambar 1. Foto dari titik penjualan Gambar 2. Foto dari jejaring sosial
Gambar 2. Foto dari jejaring sosial Gambar 3. Foto paspor
Gambar 3. Foto pasporJadi, kami perlu menulis model yang menganalisis latar belakang foto itu. Hasil karyanya adalah untuk menentukan kemungkinan bahwa foto itu diambil di salah satu tempat penjualan mitra kami. Kami mengidentifikasi tiga cara untuk mengatasi masalah ini: segmentasi, perbandingan dengan foto lain pada titik penjualan yang sama, klasifikasi. Mari kita pertimbangkan masing-masing secara lebih rinci.
A) Segmentasi
Hal pertama yang terlintas dalam pikiran adalah untuk menyelesaikan masalah ini dengan membuat segmentasi gambar, mengidentifikasi area dengan latar belakang toko mitra.
Cons:
- Persiapan sampel pelatihan terlalu banyak waktu.
- Layanan yang dibangun pada model ini tidak akan berfungsi dengan cepat.
Diputuskan untuk kembali ke metode ini hanya jika meninggalkan opsi alternatif. Spoiler: tidak kembali.
B) Membandingkan dengan foto lain pada titik penjualan yang sama
Bersama dengan foto tersebut, kami menerima informasi tentang toko ritel mana yang dibuat. Artinya, kami memiliki kelompok gambar yang diambil pada titik penjualan yang sama. Jumlah total foto dalam setiap grup bervariasi dari beberapa unit hingga beberapa ribu.
Gagasan lain muncul: untuk membangun model yang akan membandingkan dua foto dan memprediksi kemungkinan bahwa mereka diambil pada satu titik penjualan. Kemudian kita dapat membandingkan foto yang baru diterima dengan foto yang ada di toko yang sama. Jika ternyata mirip dengan mereka, maka gambarnya pasti dapat diandalkan. Jika gambar tidak disertakan, kami juga mengirimnya untuk verifikasi manual.
Cons:
- Sampling tidak seimbang.
- Layanan ini akan bekerja untuk waktu yang lama jika ada banyak foto di titik penjualan.
- Ketika titik penjualan baru muncul, Anda perlu melatih ulang model.
Meskipun kekurangan, kami menerapkan model dari
artikel menggunakan blok jaringan saraf VGG-16 dan ResNet-50. Dan ... mereka menerima persentase jawaban yang benar tidak jauh lebih tinggi dari 50% dalam kedua kasus :(
B) Klasifikasi!
Gagasan yang paling menggoda adalah membuat pengelompokan sederhana yang akan membagi foto menjadi 3 kelompok: foto dari tempat penjualan, dari paspor dan dari jejaring sosial. Tetap hanya memverifikasi apakah pendekatan ini berhasil. Nah, habiskan juga waktu menyiapkan data untuk pelatihan.
Persiapan data
Dalam dataset gambar dari jejaring sosial menggunakan pustaka Dlib, hanya foto-foto yang dipilih yang memiliki orang.
Foto-foto paspor harus dipangkas secara berbeda, hanya menyisakan wajah. Di sini sekali lagi Dlib datang untuk menyelamatkan. Prinsip kerja ternyata seperti ini: menggunakan perpustakaan menemukan koordinat wajah -> memotong foto paspor, meninggalkan wajah.
Di masing-masing dari 3 kelas tersisa 40.000 foto. Jangan lupa tentang
augmentasi dataModel
Digunakan ResNet-50. Mereka memecahkan masalah sebagai masalah klasifikasi multikelas dengan kelas disjoint. Artinya, diyakini bahwa foto hanya bisa dimiliki satu kelas.
model = keras.applications.resnet50.ResNet50() model.layers.pop() for layer in model.layers: layer.trainable=True last = model.layers[-1].output x = Dense(3, activation="softmax")(last) resnet50_1 = Model(model.input, x) resnet50_1.compile(optimizer=Adam(lr=0.00001), loss='categorical_crossentropy', metrics=[ 'accuracy'])
Hasil
Dalam sampel uji, 24.000 gambar tersisa, yaitu 20%. Matriks kesalahan adalah sebagai berikut:
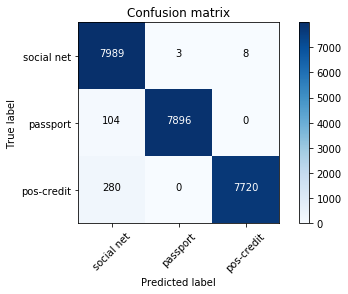
jejaring sosial - jejaring sosial;
paspor - paspor;
pos-kredit - tempat penjualan, mitra yang memberikan pinjaman.
Persentase total kesalahan adalah 1,6%, untuk foto dari tempat penjualan - 1,2%. Sebagian besar gambar yang salah didefinisikan adalah gambar yang mirip dengan dua kelas pada saat yang sama. Misalnya, hampir semua foto yang salah diidentifikasi dari kelas pos-kredit diambil dari sudut yang tidak berhasil (terhadap dinding putih, hanya wajah yang terlihat). Oleh karena itu, mereka juga mirip dengan foto-foto dari kelas jejaring sosial. Foto-foto tersebut memiliki probabilitas maksimum yang rendah.
Kami telah menambahkan ambang batas untuk probabilitas maksimum. Jika nilai akhir lebih tinggi - kami mempercayai classifier, lebih rendah - kami mengirim gambar untuk verifikasi manual.
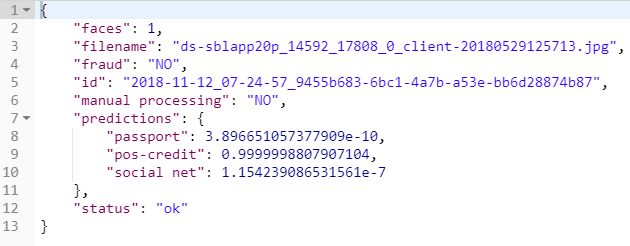
Akibatnya, hasil dari layanan untuk fotografi

terlihat seperti ini:
Ringkasan
Jadi, dengan menggunakan model sederhana, kami belajar cara menentukan secara otomatis bahwa foto diambil di salah satu tempat penjualan mitra kami. Ini memungkinkan kami untuk mengotomatisasi sebagian dari proses besar dalam menyetujui aplikasi pinjaman.