GitHub menggunakan MySQL sebagai gudang data primer untuk segala sesuatu yang tidak terkait dengan git , sehingga ketersediaan MySQL adalah kunci untuk operasi normal GitHub. Situs itu sendiri, API GitHub, sistem otentikasi, dan banyak fitur lainnya memerlukan akses ke database. Kami menggunakan beberapa cluster MySQL untuk menangani berbagai layanan dan tugas. Mereka dikonfigurasikan sesuai dengan skema klasik dengan satu simpul utama yang tersedia untuk merekam dan replikanya. Replika (node cluster lainnya) secara asinkron mereproduksi perubahan ke simpul utama dan menyediakan akses baca.
Ketersediaan situs host sangat penting. Tanpa simpul utama, cluster tidak mendukung perekaman, yang berarti Anda tidak dapat menyimpan perubahan yang diperlukan. Memperbaiki transaksi, mendaftarkan masalah, membuat pengguna baru, repositori, ulasan, dan banyak lagi akan menjadi mustahil.
Untuk mendukung perekaman, diperlukan simpul yang dapat diakses yang sesuai - simpul utama dalam gugus. Namun, kemampuan untuk mengidentifikasi atau mendeteksi simpul semacam itu sama pentingnya.
Dalam hal kegagalan simpul utama saat ini, penting untuk memastikan tampilan prompt dari server baru untuk menggantinya, serta untuk dapat dengan cepat memberi tahu semua layanan tentang perubahan ini. Total waktu henti terdiri dari waktu yang diperlukan untuk mendeteksi kegagalan, kegagalan, dan memberi tahu tentang simpul utama baru.

Publikasi ini menjelaskan solusi untuk memastikan ketersediaan tinggi MySQL di GitHub dan menemukan layanan utama, yang memungkinkan kami melakukan operasi yang mencakup beberapa pusat data dengan andal, mempertahankan pengoperasian ketika beberapa pusat ini tidak tersedia, dan menjamin waktu henti minimum jika terjadi kegagalan.
Sasaran Ketersediaan Tinggi
Solusi yang dijelaskan dalam artikel ini adalah versi baru, versi lebih tinggi dari solusi ketersediaan tinggi (HA) sebelumnya yang diterapkan pada GitHub. Ketika kita tumbuh, kita perlu mengadaptasi strategi MySQL HA untuk berubah. Kami berusaha untuk mengikuti pendekatan serupa untuk MySQL dan layanan lainnya di GitHub.
Untuk menemukan solusi yang tepat untuk ketersediaan tinggi dan penemuan layanan, Anda harus terlebih dahulu menjawab beberapa pertanyaan spesifik. Berikut adalah contoh daftar mereka:
- Apa downtime maksimum yang tidak penting bagi Anda?
- Seberapa andal alat pendeteksi kesalahan? Apakah positif palsu (pemrosesan kegagalan prematur) penting bagi Anda?
- Seberapa andalkah sistem failover? Di mana kegagalan bisa terjadi?
- Seberapa efektif solusi di beberapa pusat data? Seberapa efektif solusi dalam jaringan latensi rendah dan tinggi?
- Apakah solusi akan terus bekerja jika terjadi kegagalan data center (DPC) yang lengkap atau isolasi jaringan?
- Mekanisme apa (jika ada) yang mencegah atau mengurangi konsekuensi dari munculnya dua server utama di cluster yang merekam secara independen?
- Apakah kehilangan data penting bagi Anda? Jika demikian, sampai sejauh mana?
Untuk menunjukkan, mari kita pertimbangkan solusi sebelumnya dan diskusikan mengapa kami memutuskan untuk mengabaikannya.
Penolakan untuk menggunakan VIP dan DNS untuk penemuan
Sebagai bagian dari solusi sebelumnya, kami menggunakan:
- orkestra untuk deteksi kesalahan dan kegagalan;
- VIP dan DNS untuk penemuan host.
Dalam kasus itu, klien menemukan simpul rekaman dengan namanya, misalnya, mysql-writer-1.github.net . Nama itu digunakan untuk menentukan alamat IP virtual (VIP) dari simpul utama.
Dengan demikian, dalam situasi normal, pelanggan hanya perlu menyelesaikan nama dan terhubung ke alamat IP yang diterima, di mana simpul utama sudah menunggu mereka.
Pertimbangkan topologi replikasi berikut yang mencakup tiga pusat data yang berbeda:
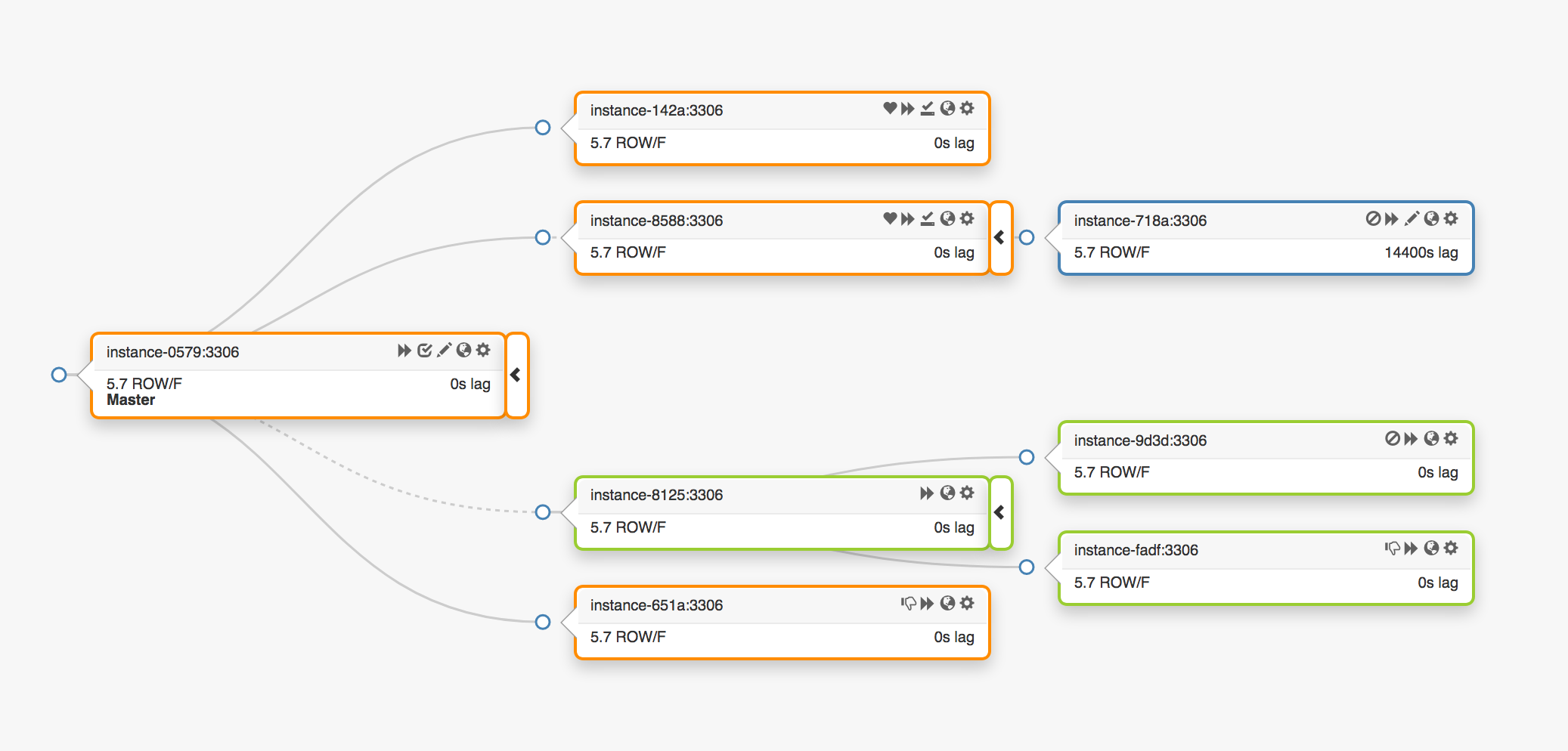
Dalam hal terjadi kegagalan simpul utama, server baru harus ditugaskan ke tempatnya (salah satu replika).
orchestrator mendeteksi kegagalan, memilih master node baru, dan kemudian menetapkan nama / VIP. Klien sebenarnya tidak tahu identitas simpul utama, mereka hanya tahu nama, yang sekarang harus menunjuk ke simpul baru. Namun, perhatikan hal ini.
Alamat VIP dibagikan, server database sendiri yang meminta dan memilikinya. Untuk menerima atau melepaskan VIP, server harus mengirim permintaan ARP. Server yang memiliki VIP terlebih dahulu harus melepaskannya sebelum master baru dapat mengakses alamat ini. Pendekatan ini mengarah pada beberapa konsekuensi yang tidak diinginkan:
- Dalam mode normal, sistem failover pertama-tama akan menghubungi simpul utama yang gagal dan memintanya untuk melepaskan VIP, dan kemudian beralih ke server utama baru dengan permintaan untuk penugasan VIP. Tetapi apa yang harus dilakukan jika simpul utama pertama tidak tersedia atau menolak permintaan untuk melepaskan alamat VIP? Mengingat bahwa server saat ini dalam keadaan gagal, kecil kemungkinannya ia akan dapat menanggapi permintaan tepat waktu atau meresponsnya sama sekali.
- Akibatnya, situasi dapat muncul ketika dua host mengklaim hak mereka untuk VIP yang sama. Klien yang berbeda dapat terhubung ke salah satu server ini tergantung pada jalur jaringan terpendek.
- Operasi yang benar dalam situasi ini tergantung pada interaksi dua server independen, dan konfigurasi seperti itu tidak dapat diandalkan.
- Sekalipun simpul utama pertama merespons permintaan, kami membuang waktu yang berharga: beralih ke server utama yang baru tidak terjadi saat kami menghubungi yang lama.
- Selain itu, bahkan dalam kasus penugasan kembali VIP, tidak ada jaminan bahwa koneksi klien yang ada di server lama akan terputus. Sekali lagi, kami menghadapi risiko berada dalam situasi dengan dua node utama yang independen.
Di sana-sini, di dalam lingkungan kita, alamat VIP dikaitkan dengan lokasi fisik. Mereka ditugaskan ke switch atau router. Oleh karena itu, kami dapat menetapkan kembali alamat VIP hanya ke server yang berada di lingkungan yang sama dengan host asli. Secara khusus, dalam beberapa kasus, kami tidak akan dapat menetapkan server VIP di pusat data lain dan perlu melakukan perubahan pada DNS.
- Mendistribusikan perubahan ke DNS membutuhkan waktu lebih lama. Klien menyimpan nama DNS untuk jangka waktu yang telah ditentukan. Kegagalan yang melibatkan beberapa pusat data memerlukan waktu henti yang lebih lama, karena dibutuhkan lebih banyak waktu untuk menyediakan semua pelanggan dengan informasi tentang simpul utama baru.
Pembatasan ini cukup untuk memaksa kami memulai pencarian solusi baru, tetapi kami juga harus mempertimbangkan yang berikut:
- Simpul utama mentransmisikan secara independen paket pulsa melalui
pt-heartbeat untuk mengukur pengaturan penundaan dan beban . Layanan harus ditransfer ke simpul utama yang baru diangkat. Jika memungkinkan, seharusnya dinonaktifkan di server lama. - Demikian pula, node utama secara independen mengontrol operasi Pseudo-GTID . Itu perlu untuk memulai proses ini pada simpul utama baru dan lebih baik berhenti pada yang lama.
- Node master baru menjadi dapat ditulis. Node lama (jika mungkin) seharusnya memiliki
read_only (read-only).
Langkah-langkah tambahan ini menyebabkan peningkatan waktu henti keseluruhan dan menambahkan poin kegagalan dan masalah mereka sendiri.
Solusinya berhasil, dan GitHub berhasil menangani kegagalan MySQL di latar belakang, tetapi kami ingin meningkatkan pendekatan kami ke HA sebagai berikut:
- memastikan independensi dari pusat data tertentu;
- menjamin pengoperasian jika terjadi kegagalan pusat data;
- Tinggalkan alur kerja kolaboratif yang tidak dapat diandalkan
- mengurangi total waktu henti;
- Lakukan, sejauh mungkin, gagal tanpa kehilangan.
Solusi GitHub HA: orkestra, Konsul, GLB
Strategi baru kami, bersama dengan perbaikan yang menyertainya, menghilangkan sebagian besar masalah yang disebutkan di atas, atau mengurangi konsekuensinya. Sistem HA kami saat ini terdiri dari elemen-elemen berikut:
- orkestrator untuk deteksi kesalahan dan failover. Kami menggunakan skema orkestra / rakit dengan beberapa pusat data, seperti yang ditunjukkan pada gambar di bawah ini;
- Konsul Hashicorp untuk penemuan layanan;
- GLB / HAProxy sebagai lapisan proxy antara klien dan rekaman node. Kode sumber untuk Direktur GLB terbuka;
- teknologi
anycast untuk routing jaringan.
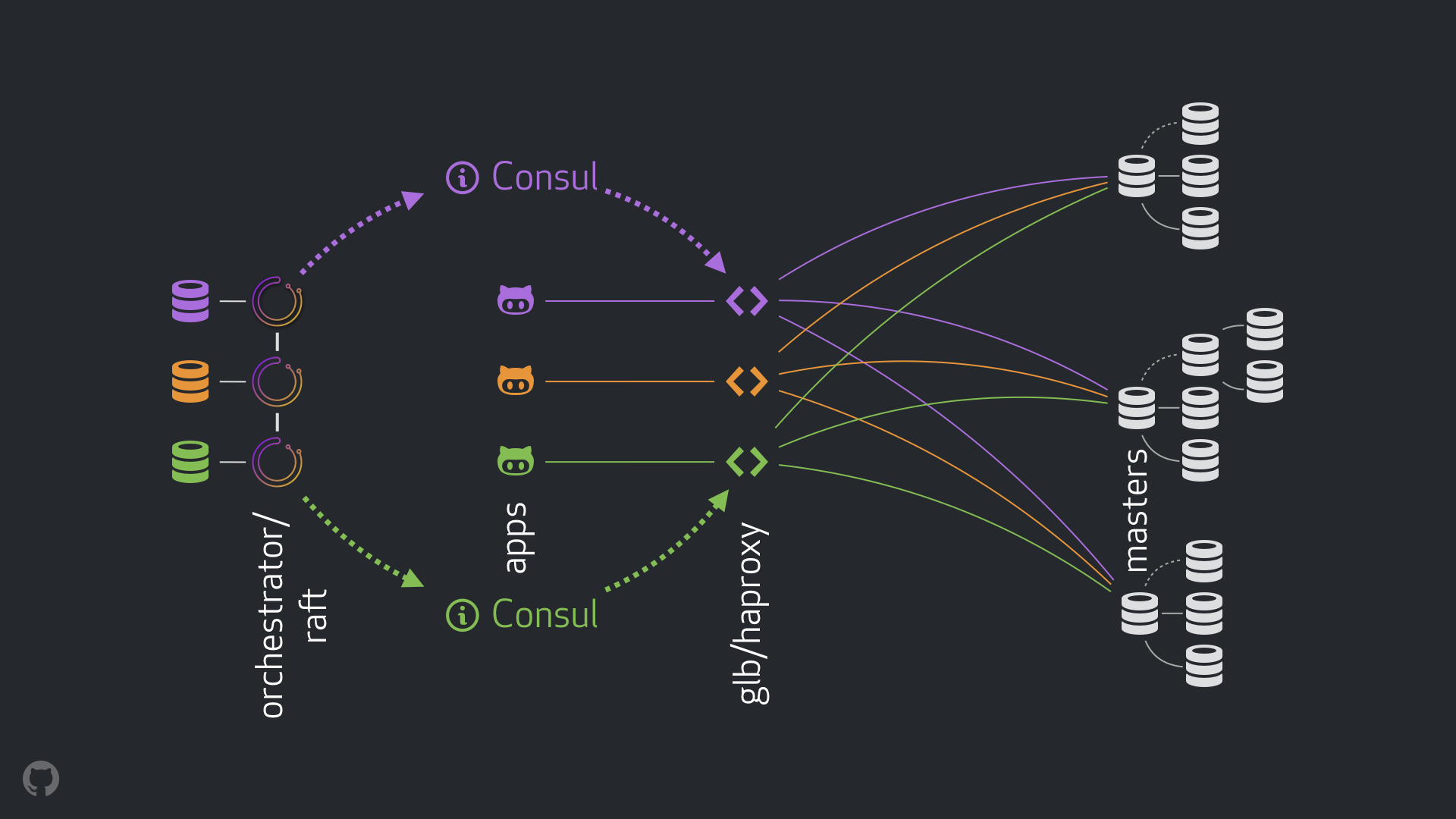
Skema baru diizinkan untuk sepenuhnya meninggalkan perubahan pada VIP dan DNS. Sekarang ketika memperkenalkan komponen baru, kita dapat memisahkannya dan menyederhanakan tugas. Selain itu, kami mendapat kesempatan untuk menggunakan solusi yang andal dan stabil. Analisis terperinci dari solusi baru diberikan di bawah ini.
Aliran normal
Dalam situasi normal, aplikasi terhubung ke node perekaman melalui GLB / HAProxy.
Aplikasi tidak menerima identitas server utama. Seperti sebelumnya, mereka hanya menggunakan nama. Sebagai contoh, simpul utama untuk cluster1 adalah mysql-writer-1.github.net . Namun, dalam konfigurasi kami saat ini, nama ini memutuskan ke alamat IP apa pun.
Berkat teknologi anycast , namanya diselesaikan ke alamat IP yang sama di mana saja, tetapi lalu lintas diarahkan secara berbeda, mengingat lokasi klien. Secara khusus, beberapa contoh GLB, penyeimbang beban kami yang sangat tersedia, digunakan di masing-masing pusat data kami. Lalu lintas di mysql-writer-1.github.net selalu dialihkan ke gugus GLB dari pusat data lokal. Karena hal ini, semua klien dilayani oleh proxy lokal.
Kami menjalankan GLB di atas HAProxy . Server HAProxy kami menyediakan kumpulan penulisan : satu untuk setiap kluster MySQL. Selain itu, setiap kumpulan hanya memiliki satu server (simpul utama gugus). Semua instance GLB / HAProxy di semua pusat data memiliki kumpulan yang sama, dan semuanya menunjuk ke server yang sama di kumpulan ini. Jadi, jika aplikasi ingin menulis data ke database di mysql-writer-1.github.net , maka tidak masalah server GLB mana yang terhubung. Dalam kedua kasus tersebut, pengalihan ke simpul utama gugus simpul sebenarnya akan dilakukan.
Untuk aplikasi, penemuan berakhir pada GLB, dan penemuan kembali tidak diperlukan. GLB mengarahkan lalu lintas ke tempat yang tepat.
Di mana GLB mendapatkan informasi tentang server mana yang harus didaftar? Bagaimana kita membuat perubahan pada GLB?
Penemuan melalui Konsul
Layanan Konsul dikenal luas sebagai solusi penemuan layanan, dan juga menggunakan fungsi DNS. Namun, dalam kasus kami, kami menggunakannya sebagai penyimpanan nilai kunci (KV) yang sangat mudah diakses.
Dalam repositori KV di Konsul, kami merekam identitas node cluster utama. Untuk setiap cluster, ada satu set catatan KV yang menunjuk ke data dari simpul utama yang sesuai: alamat fqdn , port, ipv4 dan ipv6.
Setiap node GLB / HAProxy meluncurkan template-konsul , layanan yang melacak perubahan dalam data Konsul (dalam kasus kami, perubahan dalam data dari node utama). Layanan consul-template membuat file konfigurasi dan dapat memuat ulang HAProxy saat mengubah pengaturan.
Karena itu, informasi tentang mengubah identitas node utama di Konsul tersedia untuk setiap instance GLB / HAProxy. Berdasarkan informasi ini, konfigurasi instance dilakukan, node utama baru diindikasikan sebagai satu-satunya entitas dalam kumpulan server cluster. Setelah itu, instance dimuat ulang agar perubahan diterapkan.
Kami telah menggunakan mesin virtual Konsul di setiap pusat data, dan setiap mesin virtual menyediakan ketersediaan tinggi. Namun, contoh-contoh ini tidak saling tergantung satu sama lain. Mereka tidak mereplikasi dan tidak bertukar data apa pun.
Di mana Konsul mendapatkan informasi tentang perubahan dan bagaimana itu didistribusikan di antara pusat data?
orkestra / rakit
Kami menggunakan skema orchestrator/raft : simpul orchestrator berkomunikasi satu sama lain melalui konsensus rakit . Di setiap pusat data, kami memiliki satu atau dua node orchestrator .
orchestrator bertanggung jawab untuk mendeteksi kegagalan, kegagalan MySQL, dan mentransfer data master node yang diubah ke Konsul. Failover dikelola oleh satu orchestrator/raft host orchestrator/raft , tetapi perubahan , berita bahwa cluster sekarang menjadi master baru, disebarkan ke semua node orchestrator menggunakan mekanisme raft .
Ketika node orchestrator menerima berita tentang perubahan data dari node utama, masing-masing node menghubungi instance Consul lokal mereka sendiri dan memulai rekaman KV. Pusat data dengan banyak instance orchestrator akan menerima beberapa rekaman (identik) di Konsul.
Tampilan umum dari seluruh aliran
Jika master node gagal:
- simpul
orchestrator mendeteksi kegagalan; orchestrator/raft master orchestrator/raft memulai pemulihan. Master node baru ditugaskan;- skema
orchestrator/raft mentransfer data tentang perubahan node utama ke semua node cluster raft ; - setiap instance
orchestrator/raft menerima pemberitahuan tentang perubahan node dan menulis identitas node master baru ke penyimpanan KV lokal di Konsul; - pada setiap instance GLB / HAProxy, layanan
consul-template diluncurkan, yang memantau perubahan dalam repositori KV di Consul, mengkonfigurasi ulang dan me-restart HAProxy; - Lalu lintas klien diarahkan ke node master baru.
Untuk setiap komponen, tanggung jawab didistribusikan dengan jelas, dan seluruh struktur didiversifikasi dan disederhanakan. orchestrator tidak berinteraksi dengan load balancers. Konsul tidak memerlukan informasi tentang asal-usul informasi tersebut. Server proxy hanya berfungsi dengan Konsul. Klien hanya bekerja dengan server proxy.
Selain itu:
- Tidak perlu melakukan perubahan pada DNS dan menyebarkan informasi tentang mereka;
- TTL tidak digunakan;
- utas tidak menunggu tanggapan dari tuan rumah dalam keadaan kesalahan. Secara umum, ini diabaikan.
Untuk menstabilkan aliran, kami juga menerapkan metode berikut:
- Parameter
hard-stop-after HAProxy diatur ke nilai yang sangat kecil. Ketika HAProxy reboot dengan server baru di kumpulan penulisan, server secara otomatis mengakhiri semua koneksi yang ada ke node master yang lama.
- Pengaturan parameter
hard-stop-after memungkinkan Anda untuk tidak menunggu tindakan dari klien, di samping itu, konsekuensi negatif dari kemungkinan terjadinya dua node utama dalam cluster diminimalkan. Penting untuk dipahami bahwa tidak ada sihir di sini, dan dalam beberapa kasus, beberapa waktu berlalu sebelum ikatan lama terputus. Tetapi ada saat dimana kita bisa berhenti menunggu kejutan yang tidak menyenangkan.
- Kami tidak memerlukan ketersediaan layanan Konsul yang berkelanjutan. Faktanya, kita membutuhkannya hanya tersedia selama failover. Jika layanan Konsul tidak merespons, maka GLB terus bekerja dengan nilai-nilai terakhir yang diketahui dan tidak mengambil tindakan drastis.
- GLB dikonfigurasikan untuk memverifikasi identitas node master yang baru ditugaskan. Seperti kumpulan MySQL kami yang peka konteks , pemeriksaan dilakukan untuk mengonfirmasi bahwa server memang dapat ditulisi. Jika kita secara tidak sengaja menghapus identitas simpul utama di Konsul, maka tidak akan ada masalah, catatan kosong akan diabaikan. Jika kami keliru menulis nama server lain (bukan yang utama) ke Konsul, maka dalam hal ini tidak apa-apa: GLB tidak akan memperbaruinya dan akan terus bekerja dengan status terakhir yang valid.
Pada bagian berikut, kami melihat masalah dan menganalisis tujuan ketersediaan tinggi.
Deteksi kecelakaan dengan orkestra / rakit
orchestrator mengambil pendekatan komprehensif untuk deteksi kesalahan, yang memastikan keandalan alat yang tinggi. Kami tidak menemukan hasil positif palsu, kegagalan prematur tidak dilakukan, yang berarti downtime yang tidak perlu dikecualikan.
orchestrator/raft sirkuit orchestrator/raft juga mengatasi situasi isolasi jaringan lengkap dari pusat data (pagar pusat data). Isolasi jaringan dari pusat data dapat menyebabkan kebingungan: server di dalam pusat data dapat berkomunikasi satu sama lain. Bagaimana memahami siapa yang benar-benar terisolasi - server di dalam pusat data yang diberikan atau semua pusat data lainnya ?
Dalam skema orchestrator/raft , master orchestrator/raft gagal. Node menjadi pemimpin, yang menerima dukungan mayoritas dalam kelompok (kuorum). Kami telah menggunakan node orchestrator sedemikian rupa sehingga tidak ada pusat data tunggal yang dapat menyediakan mayoritas, sementara setiap pusat data n-1 dapat menyediakannya.
Dalam kasus isolasi jaringan lengkap dari pusat data, node orchestrator di pusat ini terputus dari node serupa di pusat data lainnya. Akibatnya, node orchestrator di pusat data yang terisolasi tidak dapat menjadi yang terdepan dalam cluster raft . Jika simpul tersebut adalah master, maka ia kehilangan status ini. Host baru akan diberi salah satu node dari pusat data lainnya. Pemimpin ini akan mendapat dukungan dari semua pusat data lainnya yang dapat berinteraksi satu sama lain.
Dengan cara ini, master orchestrator akan selalu berada di luar pusat data yang diisolasi oleh jaringan. Jika master node berada di pusat data yang terisolasi, orchestrator memulai failover untuk menggantinya dengan server salah satu pusat data yang tersedia. Kami mengurangi dampak isolasi pusat data dengan mendelegasikan keputusan ke kuorum pusat data yang tersedia.
Pemberitahuan lebih cepat
Total waktu henti dapat dikurangi dengan mempercepat pemberitahuan perubahan di simpul utama. Bagaimana cara mencapai ini?
Ketika orchestrator memulai failover, itu mempertimbangkan sekelompok server, salah satunya dapat ditugaskan sebagai yang utama. Dengan adanya aturan replikasi, rekomendasi, dan batasan, ia mampu membuat keputusan berdasarkan informasi tentang tindakan terbaik.
Menurut tanda-tanda berikut, ia juga dapat memahami bahwa server yang dapat diakses adalah kandidat ideal untuk penunjukan sebagai yang utama:
- tidak ada yang mencegah server menjadi terangkat (dan mungkin pengguna merekomendasikan server ini);
- diharapkan server akan dapat menggunakan semua server lain sebagai replika.
Dalam hal ini, orchestrator pertama mengkonfigurasi server sebagai dapat ditulis dan segera mengumumkan peningkatan statusnya (dalam kasus kami, itu menulis catatan ke repositori KV di Konsul). orchestrator , .
, , GLB , , . : !
MySQL , . : , , , .
, . , , . , , , .
: 500 . . ( ), .
( ) . , .
, . , , . , , , .
, / pt-heartbeat / , . , pt-heartbeat , read_only , .
pt-heartbeat , . . . , pt-heartbeat .
orchestrator
orchestrator :
- Pseudo-GTID;
- , ;
- (
read_only ), .
, . , , , . orchestrator .
- , , . , -, .
, .
, , , - . . STONITH . , , , «» - . , , .
: Consul , . . , , , , .
orchestrator/GLB/Consul :
- ;
- ;
- ;
- ;
- , ( );
- ;
10-13 .
20 , — 25 .
Kesimpulan
«// » , , . . , .